Efficient Video Frame Interpolation Using Generative Adversarial Networks

Abstract
:Featured Application
Abstract
1. Introduction
2. Related Works
2.1. Generative Adversarial Networks
2.2. Image Generation and Video Frame Generation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Method | Application | Dataset | Result |
|---|---|---|---|---|
| Santurkar et al. [7] | Process data in the z-domain with a CNN based network and a GAN. The framework also transmits every N-th frame for further improvement. | Image/video compression. | For Mcode (video compression framework): the KTH actions dataset. | The videos reach PSNR/SSIM of 22.85 dB/0.611 while skipping the alternate frame in compression. |
| Wen et al. [8] | Concatenate two GANs for generation with the additional input data obtained by the linear interpolation operation. | Generate N frame(s) between given ones (N ≥ 1). | The KTH actions dataset; the UCF101 dataset; he Google Robotic Push dataset. | Generate seven frames between two given ones from the UCF101 dataset with the PSNR in the range of 28 dB to 30 dB. |
| Koren et al. [29] | Utilize CNN and GAN for generation and refinement, respectively. | Generate a frame in-between two given ones. | Xiph.org Video Test Media: ‘Bus’, ‘Football’, ‘News’, and ‘Stefan’. | Correct in structure and most of the details, but not close to the ground truth, particularly motion. |
| Amersfoort et al. [30] | Propose a multi-scale GAN that includes a multi-scale residual estimation module and a CNN based refinement network. | Frame interpolation. | Collection of 60 fps videos from Youtube-8m. | Achieve visual quality comparable to SepConv [1] at x47 faster runtime. |
| Meyer et al. [31] | Use a phase-based deep learning method that consists of a neural network decoder. | Frame interpolation for challenging scenarios, coping with large motion (larger than existing methods). | DAVIS video dataset. | Produce preferable output in challenging cases containing motion blurs and brightness changes. May produce more disturbing artifacts. |
3. The Proposed Method
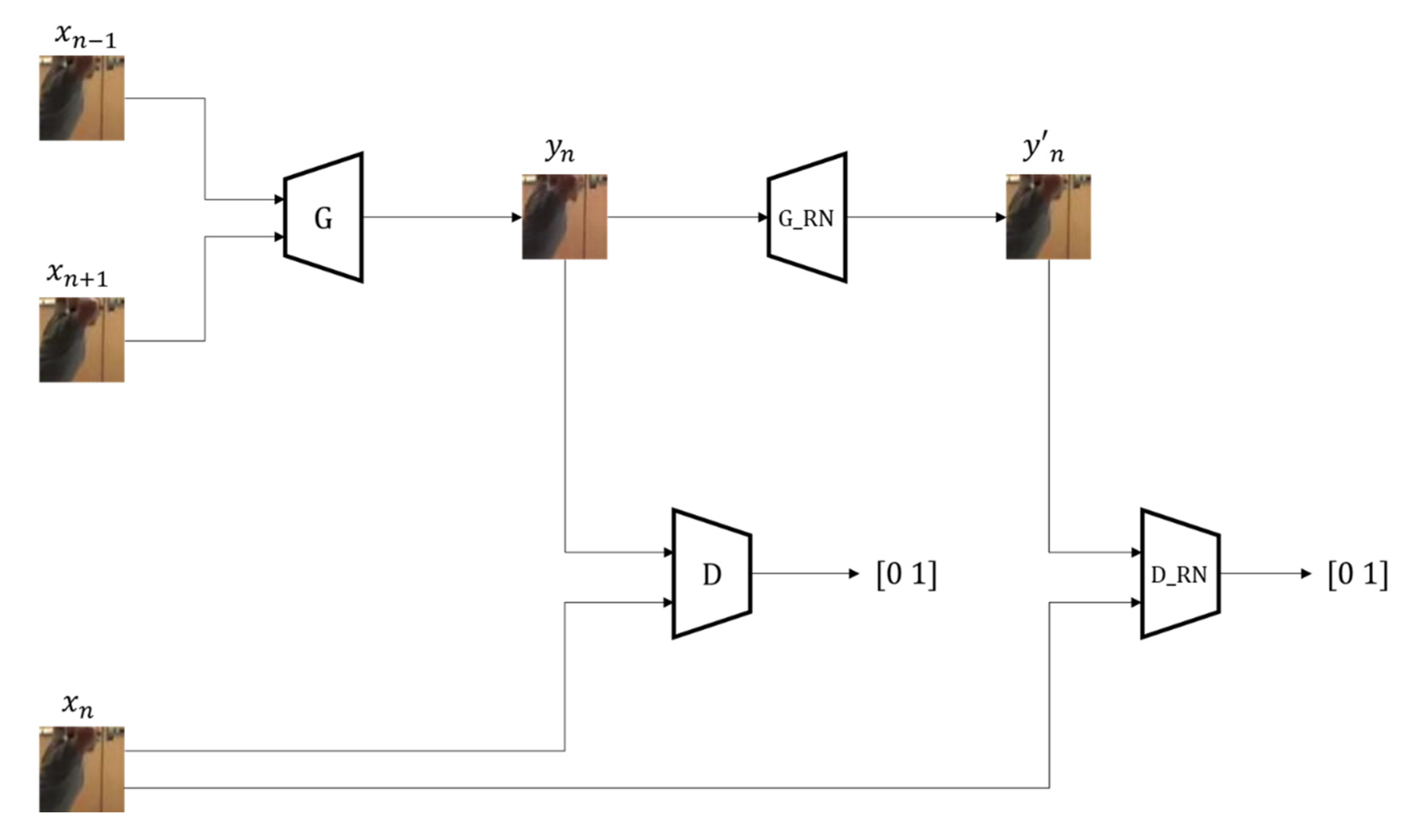
3.1. Network Architecture
3.2. Loss Functions
4. Experimental Results and Analyses
4.1. Dataset
4.2. Implementation and Training
4.3. Objective Evaluation
4.4. Subjective Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Activity Diagram


References
- Niklaus, S.; Mai, L.; Liu, F. Video Frame Interpolation via Adaptive Separable Convolution. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Liu, Z.; Yeh, R.A.; Tang, X.; Liu, Y.; Agarwala, A. Video Frame Synthesis Using Deep Voxel Flow. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Niklaus, S.; Liu, F. Context-Aware Synthesis for Video Frame Interpolation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434v2. [Google Scholar]
- Sung, T.L.; Lee, H.J. Image-to-Image Translation Using Identical-Pair Adversarial Networks. Appl. Sci. 2019, 9, 2668. [Google Scholar] [CrossRef] [Green Version]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Santurkar, S.; Budden, D.; Shavit, N. Generative Compression. In Proceedings of the Picture Coding Symposium, San Francisco, CA, USA, 24–27 June 2018. [Google Scholar]
- Wen, S.; Liu, W.; Yang, Y.; Huang, T.; Zeng, Z. Generating Realistic Videos From Keyframes With Concatenated GANs. Trans. Circuits Syst. Video Technol. 2019, 29, 2337–2348. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; NIPS: Montreal, QC, Canada, 2014. [Google Scholar]
- Hong, M.; Choe, Y. Wasserstein Generative Adversarial Network Based De-Blurring Using Perceptual Similarity. Appl. Sci. 2019, 9, 2358. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.Y.; Krahenbuhl, P.; Shechtman, E.; Efros, A.A. Generative Visual Manipulation on the Natural Image Manifold. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; Volume 9099, pp. 597–613. [Google Scholar]
- Mathieu, M.; Couprie, C.; LeCun, Y. Deep multi-scale video prediction beyond mean square error. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Lin, J.; Liu, D.; Li, H.; Wu, F. Generative adversarial network-based frame extrapolation for video coding. In Proceedings of the International Conference on Visual Communications and Image Processing, Taichung, Taiwan, 9–12 December 2018. [Google Scholar]
- Kwon, Y.H.; Park, M.G. Predicting Future Frames using Retrospective Cycle GAN. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784v1. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Berthelot, D.; Schumm, T.; Metz, L. BEGAN: Boundary Equilibrium Generative Adversarial Networks. arXiv 2017, arXiv:1703.10717. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Huang, X.; Wang, X.; Metaxas, D. StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–19 October 2017. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. StackGAN++: Realistic Image Synthesis with Stacked Generative Adversarial Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1947–1962. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Pathak, D.; Krähenbühl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context Encoders: Feature Learning by Inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Cui, Y.; Wang, W. Colorless Video Rendering System via Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Artificial Intelligence and Computer Applications, Dalian, China, 29–31 March 2019. [Google Scholar]
- Xiang, P.; Wang, L.; Wu, F.; Cheng, J.; Zhou, M. Single-Image De-Raining With Feature-Supervised Generative Adversarial Network. IEEE Signal Process. Lett. 2019, 26, 650–654. [Google Scholar] [CrossRef]
- Dirvanauskas, D.; Maskeliūnas, R.; Raudonis, V.; Damaševičius, R.; Scherer, R. HEMIGEN: Human Embryo Image Generator Based on Generative Adversarial Networks. Sensors 2019, 19, 3578. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mahajan, D.; Huang, F.; Matusik, W.; Ramamoorthi, R. Moving gradients: A path-based method for plausible image interpolation. ACM Trans. Graph. 2009, 28. [Google Scholar] [CrossRef]
- Fleet, D.J.; Jepson, A.D. Computation of component image velocity from local phase information. Int. J. Comput. Vis. 1990, 5, 77–104. [Google Scholar] [CrossRef]
- Koren, M.; Menda, K.; Sharma, A. Frame Interpolation Using Generative Adversarial Networks; Stanford University: Stanford, CA, USA, 2017. [Google Scholar]
- Amersfoort, J.V.; Shi, W.; Acosta, A.; Massa, F.; Totz, J.; Wang, Z.; Caballero, J. Frame Interpolation with Multi-Scale Deep Loss Functions and Generative Adversarial Networks. arXiv 2019, arXiv:1711.06045. [Google Scholar]
- Meyer, S.; Wang, O.; Zimmer, H.; Grosse, M.; Sorkine-Hornung, A. Phase-based frame interpolation for video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazırbas, C.; Golkov, V. FlowNet: Learning Optical Flow with Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Reda, F.A.; Sun, D.; Dundar, A.; Shoeybi, M.; Liu, G.; Shih, K.J.; Tao, A.; Kautz, J.; Catanzaro, B. Unsupervised Video Interpolation Using Cycle Consistency. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 27 October–2 November 2019. [Google Scholar]
- Bao, W.; Lai, W.S.; Ma, C.; Zhang, X.; Gao, Z.; Yang, M.H. Depth-Aware Video Frame Interpolation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Meyer, S.; Djelouah, A.; McWilliams, B.; Sorkine-Hornung, A.; Gross, M.; Schroers, C. PhaseNet for Video Frame Interpolation. arXiv 2018, arXiv:1804.00884. [Google Scholar]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss Functions for Image Restoration with Neural Networks. IEEE Trans. Comput. Imaging 2017, 3, 47–57. [Google Scholar] [CrossRef]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Action Classes from Videos in the Wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Lu, C.; Shi, J.; Jia, J. Abnormal Event Detection at 150 FPS in Matlab. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013. [Google Scholar]
- Janai, J.; Güney, F.; Wulff, J.; Black, M.J.; Geiger, A. Slow Flow: Exploiting High-Speed Cameras for Accurate and Diverse Optical Flow Reference Data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Pix2pix. Available online: https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix (accessed on 15 July 2020).
- Frame_interpolation_GAN. Available online: https://github.com/tnquang1416/frame_interpolation_GAN (accessed on 26 August 2020).
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing human actions: A local SVM approach. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 23–26 August 2004. [Google Scholar]











| Layers | Details | Output Size |
|---|---|---|
| 1 | Conv2d(3, 128, stride = 1) BatchNorm2d LeakyReLU | 128 × 64 × 64 |
| 2 | Conv2d(4, 128, stride = 2) BatchNorm2d LeakyReLU | 128 × 32 × 32 |
| 3 | Conv2d(4, 256, stride = 2) BatchNorm2d LeakyReLU | 256 × 16 × 16 |
| 4 | Conv2d(4, 512, stride = 2) BatchNorm2d LeakyReLU | 512 × 8 × 8 |
| 5 | TransposedConv2d(4, 256, stride = 2) BatchNorm2d LeakyReLU | 256 × 16 × 16 |
| 6 | TransposedConv2d (4, 128, stride = 2) BatchNorm2d LeakyReLU | 128 × 32 × 32 |
| 7 | TransposedConv2d (4, 64, stride = 2) BatchNorm2d LeakyReLU | 64 × 64 × 64 |
| 8 | TransposedConv2d (3, 3, stride = 1) tanh | 3 × 64 × 64 |
| Layers | Details | Output Size |
|---|---|---|
| 1 | Conv2d(4, 64, stride = 2) LeakyReLU | 64 × 32 × 32 |
| 2 | Conv2d(4, 128, stride = 2) BatchNorm2d LeakyReLU | 128 × 16 × 16 |
| 3 | Conv2d(4, 256, stride = 2) BatchNorm2d LeakyReLU | 256 × 8 × 8 |
| 4 | Conv2d(4, 512, stride = 2) BatchNorm2d LeakyReLU | 512 × 4 × 4 |
| 5 | Conv2d(4, 1, stride = 1) Sigmoid | 1 × 512 × 512 |
| Parameters | Values |
|---|---|
| Number of epochs | 400 |
| Batch size | 32 |
| Size of input image | 64 |
| Input’s channels | 3 |
| Learning rate | 0.0002 |
| Adam: β1 | 0.5 |
| Adam: β2 | 0.999 |
| Proposed Method (without Refinement) | Proposed Method (with Refinement) | |||
|---|---|---|---|---|
| Dataset | PSNR | SSIM | PSNR | SSIM |
| UCF101:Body Motion Only | 28.97 | 0.827 | 29.52 | 0.809 |
| UCF101:Human-Human Interaction | 27.50 | 0.789 | 27.60 | 0.762 |
| UCF101:Human-Object Interaction | 31.37 | 0.867 | 31.72 | 0.832 |
| UCF101:Playing Musical Instrument | 32.54 | 0.881 | 32.48 | 0.852 |
| UCF101:Sport | 29.10 | 0.821 | 29.42 | 0.797 |
| CUHK | 32.63 | 0.935 | 32.20 | 0.910 |
| Sintel | 32.64 | 0.914 | 33.11 | 0.912 |
| Approach | Training Time (Hours) | Processing Time (ms) | PSNR | SSIM | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Min | Max | Avg | Stdev | Min | Max | Avg | Stdev | |||
| SepConv [1] | 216 | 340 | 12.53 | 43.44 | 30.16 | 5.90 | 0.161 | 0.998 | 0.829 | 0.136 |
| Ours (w/o refinement) | 80 | 60 | 12.60 | 39.83 | 29.22 | 4.97 | 0.170 | 0.984 | 0.835 | 0.126 |
| Ours (with refinement) | 167 | 160 | 12.61 | 44.67 | 29.84 | 5.58 | 0.169 | 0.972 | 0.816 | 0.120 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tran, Q.N.; Yang, S.-H. Efficient Video Frame Interpolation Using Generative Adversarial Networks. Appl. Sci. 2020, 10, 6245. https://doi.org/10.3390/app10186245
Tran QN, Yang S-H. Efficient Video Frame Interpolation Using Generative Adversarial Networks. Applied Sciences. 2020; 10(18):6245. https://doi.org/10.3390/app10186245
Chicago/Turabian StyleTran, Quang Nhat, and Shih-Hsuan Yang. 2020. "Efficient Video Frame Interpolation Using Generative Adversarial Networks" Applied Sciences 10, no. 18: 6245. https://doi.org/10.3390/app10186245
APA StyleTran, Q. N., & Yang, S. -H. (2020). Efficient Video Frame Interpolation Using Generative Adversarial Networks. Applied Sciences, 10(18), 6245. https://doi.org/10.3390/app10186245