1. Introduction
How to reduce the production cycle and improve the utilization rate of resources is an important problem under the constraints of workshop production, such as delivery time, technical requirements and resource status, etc. Most enterprises adopt workshop scheduling technology to solve this problem. An effective scheduling optimization method can take advantage of many production resources in the workshop. The research and application of a workshop scheduling optimization method has become one of the basic contents of advanced manufacturing technology [
1,
2,
3].
Batch processing machines (BPMs) are widely applied in many enterprises, for example, steel casting, chemical and mineral processing, and so on [
4,
5,
6]. BPMs scheduling problem is a hot topic in workshop scheduling problem. In the traditional scheduling problem, each machine can only process, at most, one job at a time [
7]. However, BPMs can process a number of jobs simultaneously as a batch and all jobs in a batch have the same processing time [
8]. The processing time of one batch is equal to the maximum processing time of all the jobs processed by the batch [
9].
In this paper, we analyze the parallel batch processing machine scheduling problem where the jobs have arbitrary size and the machines have different capacities. We give a set of
jobs
and a set of
parallel batch machines
, and we let all the jobs be released simultaneously (release time of job is 0). Let
and
denote the processing time and the size of job
(
), respectively, where
and
. Machine
(
) has a finite capacity
. Without loss of generality, we assume
and
for each job
in order to ensure job
can be processed by at least one machine. However, there might be
for some
and
. Machine
(
) can handle multiple jobs at the same time, but the total size of these jobs cannot exceed
. The longest processing time of all jobs in a batch determines the processing time of a batch. The purpose of this problem is to allot each job to a batch and to schedule the batch on the machine to minimize the maximum completion time of the schedule,
, where
represents the completion time of job
in the schedule [
10,
11]. Using the notations proposed in [
12,
13], this problem can be denoted as
.
The notations used in this paper are summarized in
Table 1.
Before we move on, let us introduce some useful notations and terminologies. Let , and ; when , was used, but it was meaningless, so we set . It is possible that for some . We have . Let denote the index of a machine with the minimum capacity that can process the job , and then can be assigned to each machine in where . are called the golden machines for job , is the golden machines set, is called the golden job for , and all of the jobs that can be processed by are called the golden jobs set for . In a scheduling process, the running time of the machine is equal to the total processing time of batches scheduled on this machine.
The structure of the paper is as follows.
Section 2 reviews the previous research in related areas.
Section 3 gives the definition of the research problem. In
Section 4, a novel fast 4.5-approximation algorithm is proposed for problem
. In
Section 5, a fast 2-approximation algorithm is proposed for problem
.
Section 6 designs several computational experiments to show the effectiveness of fast algorithms. Finally, conclusions are given in
Section 7.
2. Literature Review
Since the 1980s, scholars have studied the job scheduling problem of parallel batch machines extensively [
1]. In this section, we review the results of research dealing with different job sizes and minimization of the maximum completion time [
14,
15,
16,
17,
18,
19,
20].
In the one-machine case of problem
, we denote
. Uzsoy [
21] proved that
is a strong NP-hard (non-deterministic polynomial) problem, and presented four heuristics. Zhang et al. [
22] also proposed a 1.75-approximation algorithm for
. Dupont and Flipo presented a branch and bound method for
. Dosa et al. [
23] presented a 1.7-approximation algorithm for
. Li et al. [
24] presented a
-approximation algorithm for
(the more general case where jobs have different release times), where
is a number greater than 0 and is arbitrarily small.
The special case of
is where all
(
) is represented as
. Chang et al. [
25] studied
and provided an algorithm that is based on the simulated annealing approach.
Dosa et al. [
23] demonstrated that although the processing time for all jobs is the same (unless P = NP),
cannot be approximated to a ratio less than 2. Dosa et al. presented a
-approximation algorithm. Cheng et al. [
26] presented a 8/3-approximation algorithm for
with running time
. Chung et al. [
27] developed a mixed integer programming model and some heuristic algorithms for
(the problem where jobs have different release times). A 2-approximation algorithm for
(the special case of
where all jobs have the same processing times) was given by Ozturk et al. [
28]. Li [
29] obtained a
-approximation algorithm for
.
More recently, several research groups have focused on the scheduling problems on parallel batch machines with different capacities and applications in many fields [
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40,
41]. The special case of
, where all
(i.e., all jobs can be assigned to any machine), is denoted as
. Costa et al. [
30] studied
and developed a genetic algorithm for it. Wang and Chou [
31] proposed a metaheuristic for
(the problem where jobs have different release times). Damodaran et al. [
32] proposed a PSO method for
. Jia et al. [
33] presented a heuristic and a metaheuristic for
. Wang and Leung [
34] analyzed the problem
where each job has its own unit processing time. They designed a 2-approximation algorithm for the problem. They also obtained an algorithm with asymptotic approximation ratio 3/2. Li [
35] proposed a fast 5-approximation algorithm and a
-approximation algorithm for
, but the presented
-approximation algorithm has high time complexity when
is small. Jia et al. [
36] presented several heuristics for
(the problem where jobs have different release times) and evaluated the validity of the heuristics by computational experiments. Other methods have also been proposed in the literature [
42,
43,
44,
45,
46,
47,
48,
49,
50,
51,
52,
53].
In this paper, a novel fast 4.5-approximation algorithm was developed for problem
, and we evaluate the algorithm performance via computational experiments. We also provide a simple and fast 2-approximation algorithm for the case that all jobs have the same processing time, (
), improving upon and generalizing the results in [
54,
55,
56,
57]. The approximation ratio of the 2-approximation algorithm in this paper is equal to the presented algorithm in [
26], but is now simpler to understand and easier to implement.
4. 5-Approximation Algorithm for
We denote the optimal makespan of the problem as . The main focus of the research is to develop a fast scheduling model to get a minimized makespan as close to as possible.
To solve the problem
, we used the MBLPT (modified longest processing time batch) rule [
35], a modification of the BLPT (longest processing time batch) rule. For a given jobs set
that can be assigned to machine
, we apply the MBLPT rule, which sorts jobs to get
. We build a batch
on machine
, and then the rule repeatedly pops the first job from
and assigns it to
until the sum of all the jobs assigned to
just exceeds the capacity of
. Batch
is called the one-job-overfull batch. Once the one-job-overfull batch exists, a new batch should be built on the same machine, unless the machine runs out of maximum completion time (maximum completion time is in the initialization parameters of the algorithm). We repeat the above job assignment procedure until the job list
is empty.
Let
denote the set of batches generated using the MBLPT rule to
and machine
, and
is the total number of batches scheduled on machine
. Let
and
denote the longest processing time (the processing time of batch
is equal to the longest processing time of jobs on it) and the shortest processing time of the jobs in batch
, respectively, such that
. The batches
are one-job-overfull batches, while
can be one-job-overfull or not. We have
(
). The Inequality (7) below (refer to [
27]) is easy to prove.
By the Inequality (7), we have
Lemma 1. We now propose the 4.5-approximation algorithm for
. Similar frameworks have been used in [
58,
59,
60,
61,
62]. In [
58], Ou et al. developed a 4/3 approximation algorithm to solve classical scheduling problems with minimized maximum completion time on parallel machines with processing set constraints. In [
59], Li proposed a 9/4-approximation algorithm for
(the special case of
where all
). The algorithm to be described extends the previous research by involving non-identical job sizes.
We first run the 5-approximation algorithm for
. The algorithm generates a feasible schedule with a maximum completion time of
in
time. Let the minimum completion time
. We have
. We use the binary search method to find the makespan of a feasible solution in the range of the
interval. Firstly, set
, and then classify both the jobs and batches into long, short, and median. A job
is long if
, median if
, or short if
. Similarly, a batch
is long if
, median if
, or short if
. Certainly, long batches may contain median and short jobs, and median batches may contain short jobs. After classification, we use the following SCMF-LPTJF (smallest capacity machine first processed and longest processing time job first processed) procedure to search for a schedule with a makespan at most
, which permits one-job-overfull batches. If our above operation fails, we will continue searching for the upper half of the interval and set
; otherwise, we will continue searching for the lower half of the interval, record
, and set
. The binary search method is then repeated in the new range of the
interval until
.
| Algorithm 1. SCMF-LPTJF (smallest capacity machine first processed and longest processing time job first processed) |
Input: ,
Output:—best found solution, —running time |
| 1: | , // denote the jobs have been assigned to batch as |
| 2: | for do |
| 3: | Sort according to the rule that processing time of jobs is not increased, denote |
| 4: | end for |
| 5: | for do |
| 6: | |
| 7: | Apply the MBLPT rule to and , get |
| 8: | Sort according to the rule that processing time of batches is not increased, denote |
| 9: | Denote long batches set, median batches set, and short batched set as , , and |
| 10: | , , |
| 11: | for batch in do // classify batches into long, median and short. |
| 12: | if then |
| 13: | append to |
| 14: | else if then |
| 15: | append to |
| 16: | else |
| 17: | append to |
| 18: | end if |
| 19: | end for |
| 20: | if then |
| 21: | // the longest processing time batch in |
| 22: | schedule on ; remove from ; remove jobs assigned to from and add these jobs to |
| 23: | // is the processing time of batch |
| 24: | end if |
| 25: | for batch in do |
| 26: | if then |
| 27: | schedule on ; remove from ; remove jobs assigned to from and add these jobs to |
| 28: | // the processing time of batch |
| 29: | end if |
| 30: | end for |
| 31: | for batch in do |
| 32: | if then |
| 33: | schedule on ; remove from ; remove jobs assigned to from and add these jobs to |
| 34: | // the processing time of batch |
| 35: | end if |
| 36: | end for |
| 37: | Update // append the batches scheduled on to |
| 38: | end for |
| 39: | return , |
Lemma 2. If, then the SCMF-LPTJF algorithm will generates an optimal schedule forwith one-job-overfull batches whose makespan is at most.
Proof. Let be an optimal schedule whose makespan is . Let be the set of long jobs and median jobs. □
In , each machine can process up to three median batches or one long batch and one median batch. On the other hand, the SCMF-LPTJF program will allocate a long batch on the machine as much as possible. After it assigns a long batch on a machine, this machine still has enough time (at least time) to handle at least two median batches. Note that the SCMF-LPTJF procedure forms batches greedily. (It overfills each batch with the longest currently unassigned jobs.) Therefore, the SCMF-LPTJF procedure allocates more processing times for long jobs and median jobs on the machines with smaller capacities than does. Equivalently, we claim that is the lower limit of the overall processing time in a long working state, and the median job arranged on machines in , . Hence, if , then all long and median jobs will be allocated by SCMF-LPTJF.
Therefore, if there is , but there is still a job when executing to the end of the SCMF-LPTJF process, then job must be a short job. When job is assigned, all of machines have a load greater than . Let be the largest index such that machine has a load less than or equal to . If all of the machines have load greater than , then set . Therefore, all of machines have load greater than . There is room on the machine for scheduling any short job. Hence, by the rule of the SCMF-LPTJF procedure, no short job from can be assigned to machines .
By Lemma 1, for
, we have
It follows that
In , all the short jobs in have to be processed on machines . In addition, we have also proved that the overall processing time of the planned long and median jobs on machines in as a lower bound. Therefore, the above inequality shows that cannot make all of the jobs done in the time, which is a contradiction.
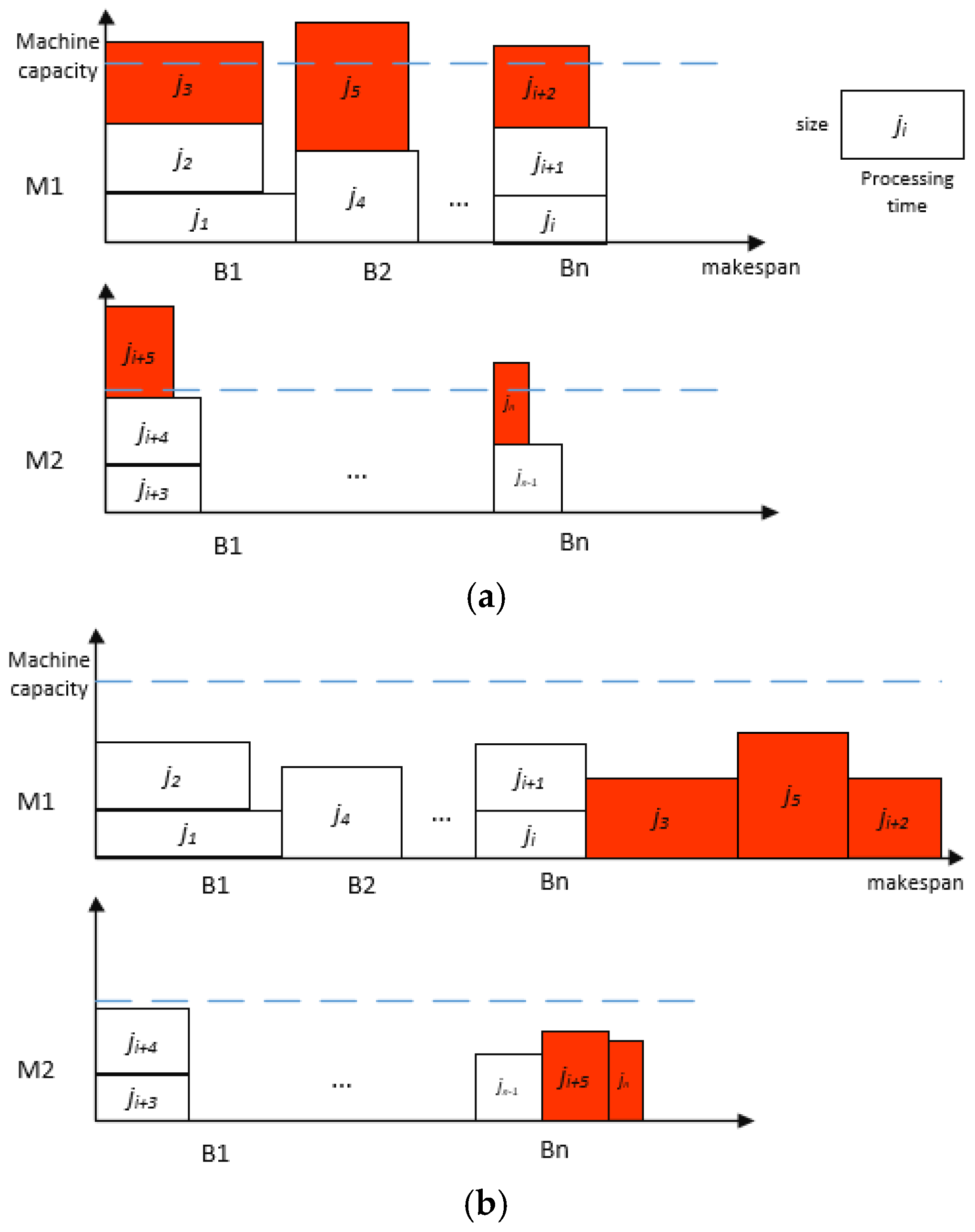
The algorithm performs a binary search within the range
. Finally, we will get a schedule with one-job-overfull batches (
Figure 1a) whose makespan is at most
. We can turn it into a viable scheduling solution (
Figure 1b), where the maximum completion time is
, as follows: for each one-job-overfull batch, move the last packed job into a new batch and calculate the new batch on the same machine. Since the iterative number could be
, then the following theorems are obtained.
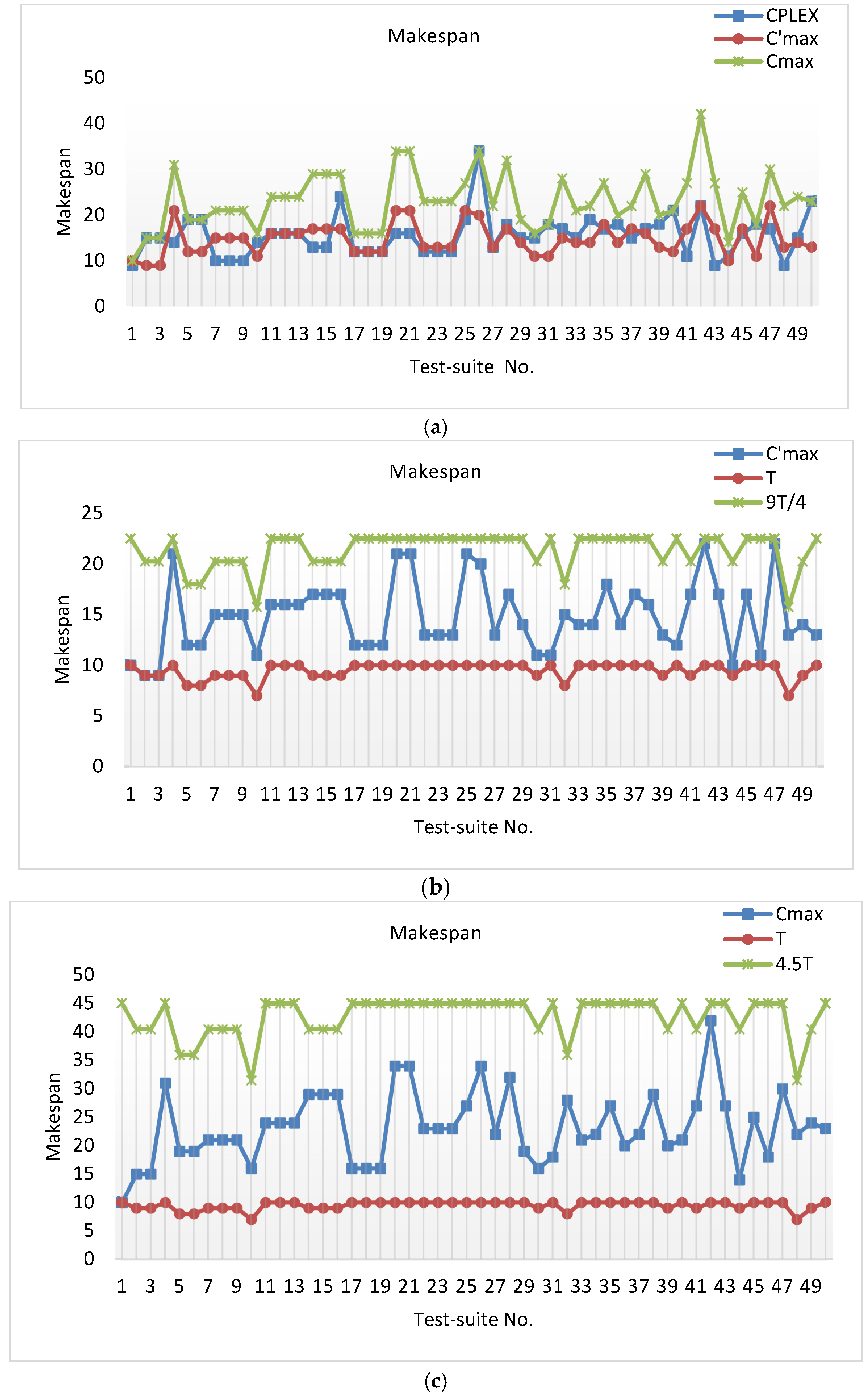
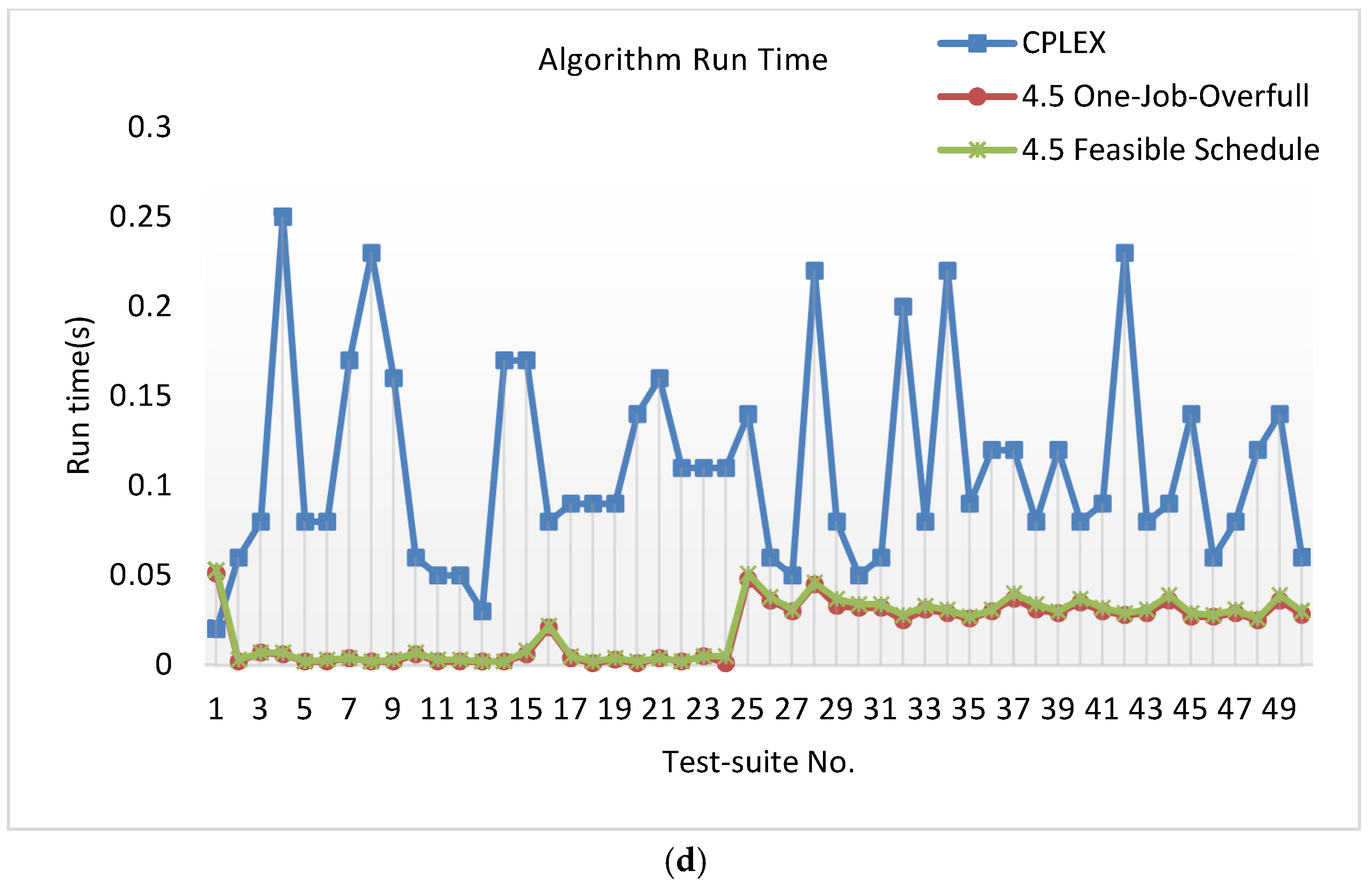
Theorem 1. There is a 4.5-approximation algorithm forthat runs intime, where.
In order to achieve a strongly polynomial time algorithm, we use a technique described to modify the above algorithm slightly. Therefore, the following theorems are obtained.
Theorem 2. There is a-approximation algorithm forthat runs intime, wherecan be made arbitrarily small.
5. A 2-Approximation Algorithm for
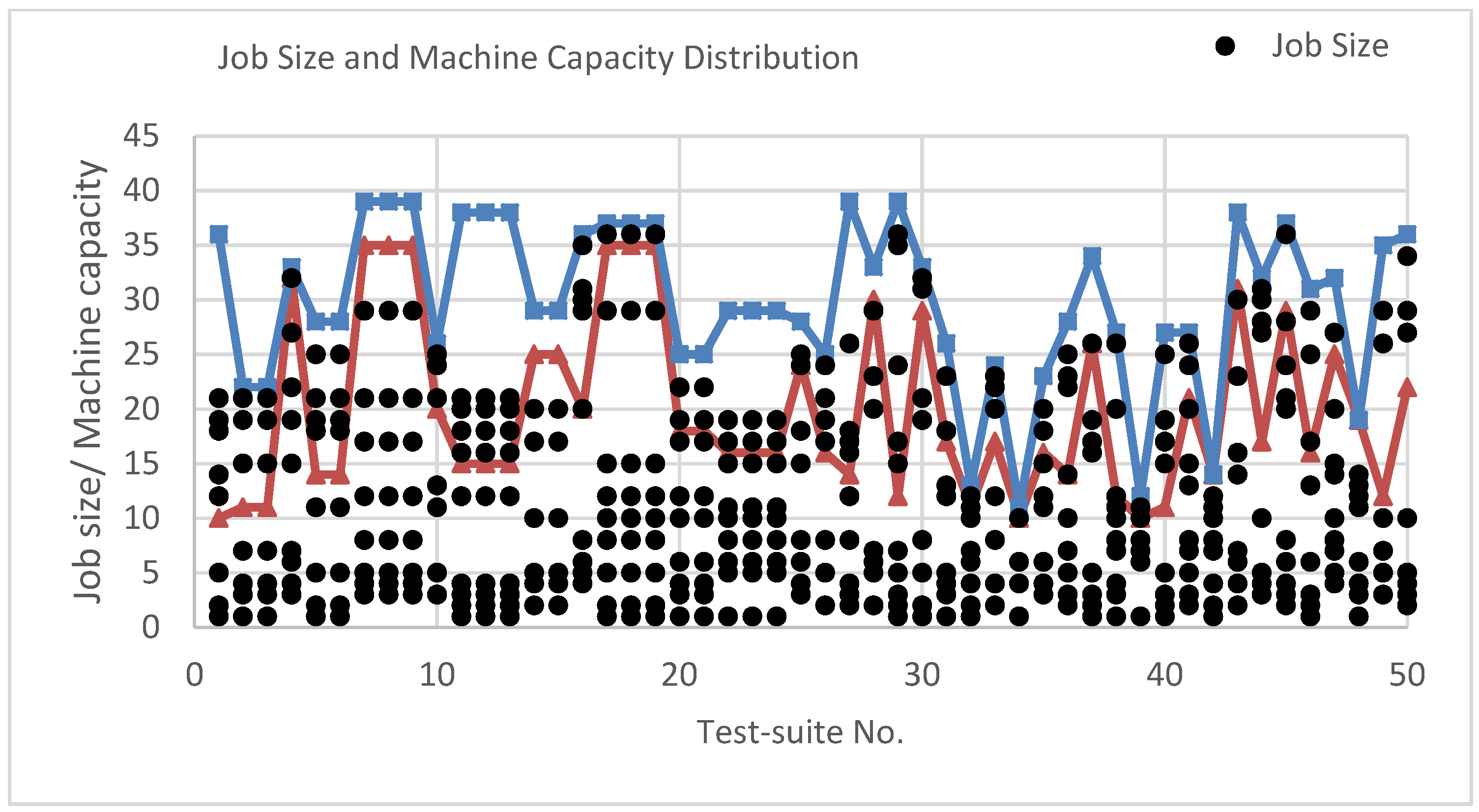
In this section, we study , i.e., the problem of minimizing the makespan with equal processing times (), arbitrary job sizes (may exceed the processing power of certain batches), and non-identical machine capacities.
The 2-approximation algorithm is called LIM (largest index machine first consider). It groups the jobs in
(this ordering is crucial), respectively, into batches greedily. During the run of the algorithm,
represents the load on machine
, i.e., the overall processing time of the batches on
,
. The algorithm dynamically maintains a variable
, which represents the currently largest index such that
. If there is no such index, then we can set
. We can assign the next generated batch to machine
.
| Algorithm 2. LIM (largest index machine first consider) |
| Input: |
| Output: —best found solution, —running time |
| 1: | //the jobs have been assigned to any batch |
| 2: | for do |
| 3: | // the load on machine , equals to the overall processing time of the batches on , |
| 4: | end for |
| 5: | x=m |
| 6: | for do |
| 7: | if and then |
| 8: | |
| 9: | end if |
| 10: | create new batch , |
| 11: | for job in do |
| 12: | if then |
| 13: | assign job to batch |
| 14: | |
| 15: | remove job from and add it to |
| 16: | else |
| 17: | schedule to |
| 18: | |
| 19: | initiate |
| 20: | end if |
| 21: | end for |
| 22: | if is not empty and then |
| 23: | while and is not empty do |
| 24: | get first job from |
| 25: | assign job to |
| 26: | |
| 27: | remove job from and add it to |
| 28: | end while |
| 29: | schedule to |
| 30: | |
| 31: | end if |
| 32: | if then |
| 33: | if then |
| 34: | |
| 35: | else if then |
| 36: | |
| 37: | end if |
| 38: | end if |
| 39: | end for |
| 40: | for do |
| 41: | for batch in do |
| 42: | if then |
| 43: | create new batch |
| 44: | pop the last job from b and assign it to |
| 45: | schedule to |
| 46: | |
| 47: | end if |
| 48: | end for |
| 49: | Update // append the batches scheduled on to |
| 50: | end for |
| 51: | return ,. |
Theorem 3. Algorithm LIM is a 2-approximation algorithm for.
Proof. Let be the schedule with makespan generated by LIM after Step 2. In , all batches can be processed at the same time as they are assigned to a machine. During the running of the algorithm, the load on any machine is always less than or equal to the load on . Therefore, finishes last in . Let be the last batch assigned to . Let be the processing set of , which can be defined as the largest size processing set of the job in . In , let denote the start time of . We have: . □
Since we assigned to , at that moment must hold. Hence, machines are busy in the time interval . All the batches allocated to machines before are one-job-overfull batches. All jobs in these batches, together with the largest size job in , must be processed on machines in any feasible schedule. Hence, we get . So we can draw the conclusion that .
For a feasible schedule with makespan generated by LIM, we have .






{kind=link}
{kind=link}
{kind=link}
{kind=link}