1. Introduction
Emotion recognition is an important component in affect-related human-machine interaction systems [
1,
2], as emotion can provide implicit feedback about human experience and conditions that are not easily captured by the explicit input. Audio-visual emotion recognition is a common type of emotion recognition [
3,
4]. The comprehensive overview can be found in the surveys [
5,
6,
7,
8,
9,
10]. Recent works have successfully applied it for many areas, such as disease diagnosis [
11,
12], affective tutoring system [
13,
14], marketing [
15,
16], and entertainment [
17,
18]. One challenge of audio-visual emotion recognition is how to extract feature representations with an acceptable size from audio and visual data that are effective for emotion recognition. A number of previous works [
19,
20,
21,
22,
23,
24,
25,
26,
27] have been proposed to tackle this challenge. Although progresses have been made by previous works, they usually suffer from the following two limitations.
First and foremost, these conventional strategies usually cannot efficiently utilize common information between different modalities by correlation analysis. For example, in [
19,
20,
21], the common information is captured by combining the features that are learned from each modality into a feature vector. This technique often fails to exploit the complex dependencies and interactions between different modalities. Motivated by this concern, approaches [
22,
23,
24] that are based on canonical correlation analysis (CCA) and some variant methods, such as kernel probabilistic CCA [
25], sparse local discriminative CCA [
26], and low-rank representation [
27], are proposed. Although these methods have made some performance improvements, they may suffer from numerical issues [
28,
29]. This instability arises in that they need to use the inverse of the empirical covariance matrix, which easily become singular over some mini-batches. As a workaround, such methods often limit the feature dimensionality to be relatively small in order to ensure stability, which is undesirable for the complex audio-visual emotion recognition task.
Besides, some previous works use heuristic features [
22,
23,
24,
25,
27] or the features learned from shallow neural network structures [
19,
20,
21,
26] for emotion recognition. For example, the widely used audio heuristic features include prosody features and voice quality features [
9], while typical visual heuristic features include Gabor features and HOG-TOP features [
30]. Recently, convolutional neural networks (CNNs) have become popular for extracting audio and visual features for emotion recognition [
19,
20,
21]. However, due to the high-dimensional emotional data, the learned representations using such methods with shallow structures are not expressive enough to predict emotions, which may lead to limited performance.
To address the above two problems, we propose an deep learning framework for audio-visual emotion recognition by efficiently utilizing common information between audio data, visual data, and the corresponding emotion labels.
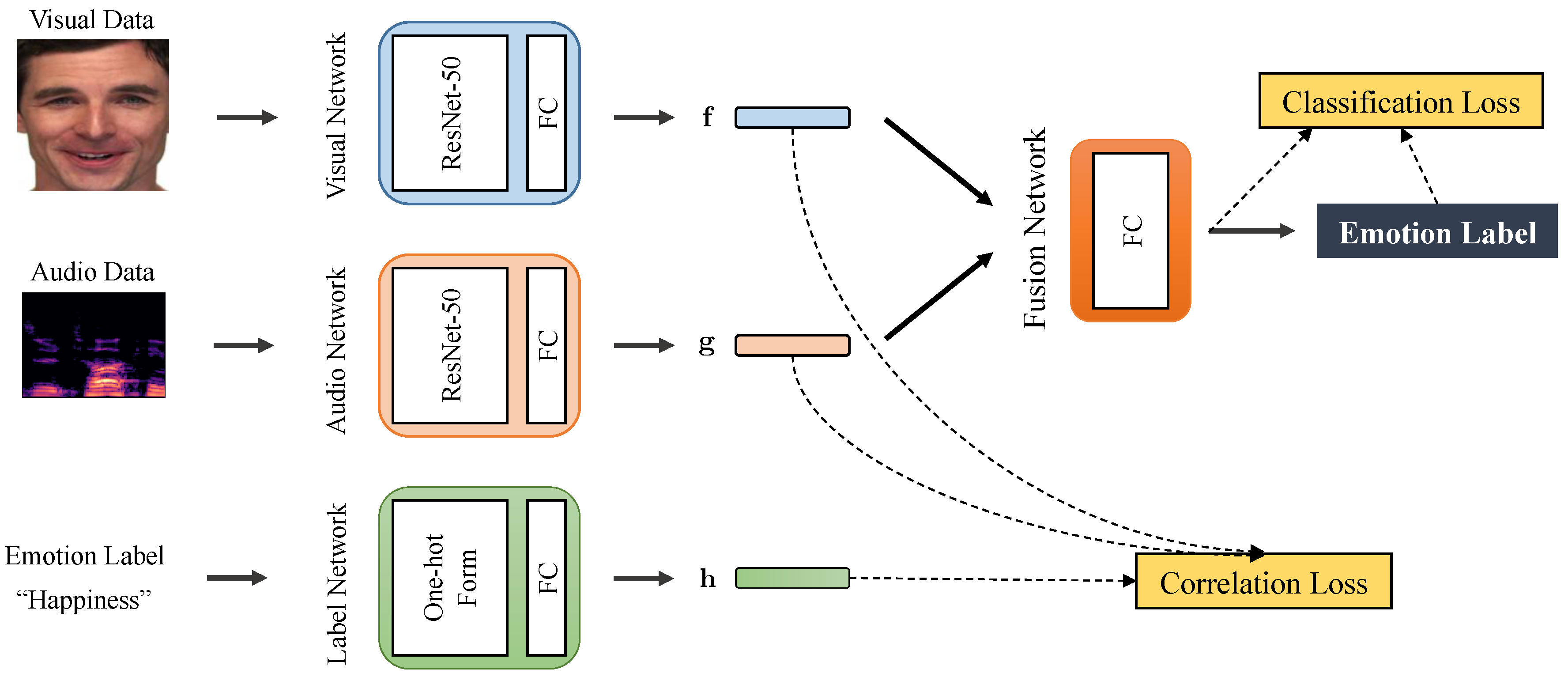
Figure 1 presents the structure of our system, which satisfies: (i) the highly non-linear correlation of the feature representations among audio data, visual data, and the corresponding labels should be fully analyzed in order to capture the common information, and (ii) the learned audio and visual features should have enough expressiveness to classify the emotions. By considering these two goals together, we can learn the feature representations that are fully discriminative for the emotion recognition task.
Specifically, we design an audio network and a visual network to learn the feature representations from audio and visual data, respectively, and then adopt a fusion network to combine the extracted audio and visual features for emotion prediction. Our neural network is trained by a joint loss function which is the linear combination of correlation loss and classification loss. The correlation loss is used to extract common information between audio data, visual data, and the corresponding emotion labels. We adopt common information here to describe the effectiveness of combining emotional information from different modalities by correlation analysis. It is implemented by a deep learning version of Hirschfeld-Gebelein-Rényi (HGR) maximal correlation [
31,
32,
33], a well-known measure of dependence, to learn the maximally correlated feature representations of different modalities. The classification loss is used in order to extract discriminative information from each modality for emotion prediction. Further, we generalize our framework to the semi-supervised learning scenario. We conduct experiments on three public audio-visual datasets: eNTERFACE’05 [
34], BAUM-1s [
35], and RAVDESS [
36]. The results demonstrate that, by capturing common information with HGR maximal correlation, our deep learning approach can significantly enhance the stability of features that are learned from different modalities and improve the emotion recognition performance.
To summarize, our main contributions are as follows:
We design a deep learning framework to learn the discriminative feature representations from the audio and visual data for emotion recognition.
We propose a correlation loss that is based on HGR maximal correlation to capture common information between audio data, visual data, and the corresponding emotion labels.
We generalize our framework to the semi-supervised learning scenario with common information.
We conduct experiments on the eNTERFACE’05, BAUM-1s, and RAVDESS datasets to demonstrate the effectiveness of our system.
To the best of our knowledge, our method is the first work to utilize HGR maximal correlation in order to extract common information between audio data, visual data, and the corresponding emotion labels for audio-visual emotion recognition. The remainder of this paper is organized, as follows. In
Section 2, we describe the related works. In
Section 3, we explain HGR maximal correlation. In
Section 4, we introduce our approach in detail. Subsequently, we perform extensive experiments on the eNTERFACE’05, BAUM-1s, and RAVDESS datasets in
Section 5. Finally, we draw conclusions and point out some future works in
Section 6.
3. Preliminary
HGR maximal correlation can be regarded as a generalization of Pearson’s correlation [
81]. For joint distributed random variables
X and
Y with ranges
and
, HGR maximal correlation with
k features is defined, as shown in Equation (
1):
where the supremum is taken from all Borel measurable functions. Besides,
, and
represents that
X is independent of
Y. HGR maximal correlation can help us to extract the non-linear feature representations,
and
. From the perspective of information theory,
learned from
X has the maximum information towards some aspects of
Y and vice versa, which can be used to extract the common information that is shared in
X and
Y [
28,
82].
In [
28,
49], based on HGR maximal correlation, an objective function that can be directly used for deep learning is proposed, as shown in Equation (
2):
where
and
represent the covariance matrix of
and
, respectively.
represents the matrix trace operator. It is shown in [
28] that Equation (
2) can implement HGR maximal correlation equivalently. Inspired by this, we can design the loss function of our system based on HGR maximal correlation in order to extract the common information between different modalities.
HGR maximal correlation is appealing to multimodal learning. On the one hand, it can extract the maximally non-linear correlated features of different modalities, but the Pearson’s correlation cannot. On the other hand, it has strong efficiency in deep learning frameworks. These factors inspire us to integrate HGR maximal correlation into the deep learning model for audio-visual emotion recognition.
5. Experiments
In this section, we evaluate our system in the following aspects: (i) to show our approach achieves higher performance than the previous works, (ii) to show our approach can enhance the stability of features learned from audio and visual data for emotion recognition, and (iii) to show that our approach can be easily generalized to the semi-supervised learning scenario.
5.1. Datasets
We perform experiments on three audio-visual emotional datasets to evaluate the effectiveness of our approach, including eNTERFACE’05, BAUM-1s, and RAVDESS, because they are available to the research community and widely used in audio-visual emotion recognition.
The eNTERFACE’05 dataset [
34] has 1287 English video samples from 42 subjects coming from 14 different nationalities. Each subject are first told to listen to six different situations, with each of them eliciting one of the following emotions: anger, disgust, fear, happiness, sadness, and surprise. They then react to each of the situations and two human experts judged whether the reaction expressed the emotion in an unambiguous way. Happiness has 213 samples, and each of the other five emotions has 216 samples. The frame rate is 25 frames per second. The audio sample rate is 48,000 Hz. In all the samples, the shortest duration is 1.12 s and the longest duration is 106.92 s. 95% samples have the duration more than 1.56 s.
The BAUM-1s dataset [
35] is a spontaneous audio-visual Turkish database that contains expressions of affective as well as mental states. It has 1134 video samples from 31 subjects. The subjects are first shown a sequence of images and short video clips, which are not only meticulously fashioned, but also timed to evoke a set of emotions and mental states. Subsequently, they express their feelings and ideas about the images and video clips they have watched in their own words, without using predetermined scripts. The subjects are not guided in any way regarding how to perform the emotion. The database contains recordings reflecting the six basic emotions (anger, disgust, fear, happiness, sadness, and surprise) as well as boredom and contempt. The database also contains several mental states, namely unsure, thinking, concentrating, and bothered. Following [
4], our work focuses on recognizing the six basic emotions, which have 521 video clips. To be specific, anger, disgust, fear, happiness, sadness, and surprise have 56, 80, 37, 173, 134, and 41 samples, respectively. The frame rate is 29.97 frames per second. The audio sample rate is 48,000 Hz. In all the samples, the shortest duration is 0.43 s and longest duration is 29.2 s. 95% samples have the duration more than 1.03 s.
The RAVDESS dataset [
36] is a validated multimodal database of emotional speech and song. It is gender-balanced consisting of 24 professional actors (12 female, 12 male), vocalizing lexically-matched statements in a neutral North American accent. Emotional expressions are elicited while using techniques the actors are trained in, including method acting or emotional memory techniques. Here, we consider the speech video clips, which are recorded in audio-visual format with 1440 samples. It includes calm, happy, sad, angry, fearful, surprise, disgust, and neutral expressions. Each expression is produced at two levels of emotional intensity. Ratings are provided by 247 individuals who are characteristic of untrained research participants from North America. Analogously, we only consider recognizing the six basic emotions as the eNTERFACE’05 and BAUM-1s datasets, each of which has 192 samples. The frame rate is 29.97 frames per second. The audio sample rate is 48,000 Hz. In all samples, the shortest duration is 2.99 s and longest duration is 5.31 s. 95% samples have the duration more than 3.24 s.
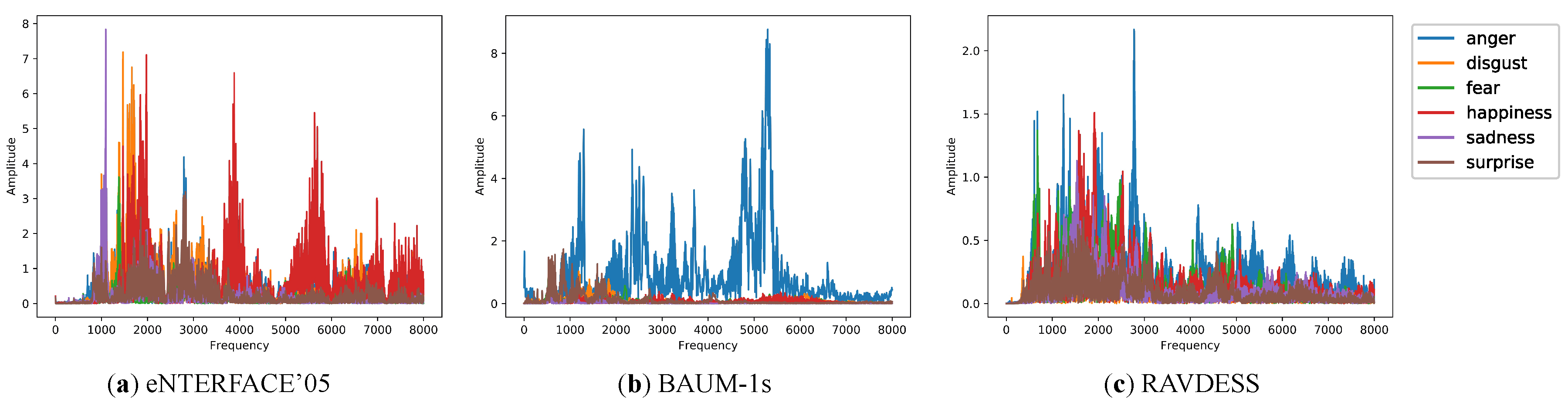
In
Figure 2, we show some cropped facial images in order to illustrate the visual information of eNTERFACE’05, BAUM-1s, and RAVDESS datasets. We can also further provide the audio information of each dataset. However, the spectrogram of each sample is visually indistinguishable. Here, we statistically average the spectrograms of different samples that belong to the same class, as shown in
Figure 3. It can be found that both visual information and audio information can differentiate emotions on the eNTERFACE’05, BAUM-1s, and RAVDESS datasets.
5.2. Implementation Details
5.2.1. Data Preprocessing
The audio and visual data need to be extracted from emotional video samples, which always vary in time duration. We consider splitting each emotional video sample into several segments with the same length and extract audio data and visual data from them. Some previous works [
4,
29] use a moving window with a fixed length to segment the video samples. Additionally, the moving step of the window should also be carefully determined. Because the number of segments for each video sample depends on the time length of the corresponding video sample and the time lengths for different video samples are very different, the distribution of segmented dataset may be different from that of the original video dataset. Because of this phenomenon, such an approach may affect the final performance of audio-visual emotion recognition.
Here, we propose to randomly obtain a segment from a given video sample with a window and repeat this operation 30 times. Therefore, we can obtain 30 segments belonging to the same video sample. The label of the given video sample is used as the labels for these 30 segments. This technique can effectively ensure the distribution of the segmented dataset is consistent with that of the original dataset, and it also has the data augmentation effect. The best window size for emotion recognition is still unclear and it is reported in [
85] that a segment longer than 0.25 s includes sufficient emotional information. Inspired by this, we set the window length to 0.5 s. The experimental results show that this length is suitable for emotion recognition.
Each segment usually contains several consecutive frames, which express the same emotion in a very similar way. Additionally, in [
86], it is said that at the start and end of the emotional videos, that the subject usually prepares to express the emotion from the neutral state or return to the neutral state after the emotion is shown. These factors motivate us to choose the central frame in each segment as the key frame and take all key frames as the visual data. This way can effectively make the visual data contain rich emotional information for emotion classification and avoid redundancy. Subsequently, we use the MTCNN (multi-task cascaded convolutional network), as proposed in [
87], to detect the human face from visual data with the squared size
. After the preprocessing, we feed the visual data into the visual network.
In addition, we extract the speech signals from all segments. Subsequently, we extract the log Mel-spectrogram from the speech signal for each segment as audio data. For each speech signal, we adopt 94 Mel-filter banks in order to obtain the log Mel-spectrogram with a 40 ms hanning window and a 10ms overlapping, resulting in the representation with size 94 × 94. Afterwards, we convert the representation into three channels by copying the original Mel-spectrogram to each channel. Finally, we send the audio data into the audio network.
5.2.2. Network Architecture
We use ResNet-50 [
37] as the backbone architectures of the audio network and visual network. The fully connected layer before the softmax layer of ResNet-50 has 512 units, denoted as feature functions
and
in the visual network and audio network, respectively. Additionally, the weights of the two networks are initialized by copying the parameters of trained on the ImageNet dataset [
88]. Inspired by [
89], we first convert the emotion labels into one-hot form and then use a fully connected layer with 512 units as the label network to obtain the feature function
. We then concatenate
and
into the fusion network for emotion prediction. The fusion network has several fully connected layers. The last layer of the fusion network is the softmax layer. Each fully connected layer is followed by the ReLU function. These fully connected layers before the softmax layer in the fusion network correspond to the feature function
. Because common information in different layers of our deep learning model may have different performance, we consider different forms of the feature function,
. Specifically, we respectively make the fusion network has one, two, and four fully connected layers before the softmax layer, as shown in
Figure 4. We will report the performance of different settings in
Section 5.3.3. In this way, we can test the stability of common information in our deep learning model.
In [
4,
90], it is said that the pre-trained strategy can effectively enhance the expressiveness of the learned features. Accordingly, here, we firstly train audio and visual network separately with the cross-entropy loss function. In this way, the networks can contain sufficient discriminative information from each modality. Subsequently, we use their weights as the initial weights of our whole model for joint training.
After the emotion probabilities of each segment are predicted, the average results across all segments belonging to the same video samples are used in order to predict the video-level emotion labels.
5.2.3. Experimental Settings
In our experiments, 70% samples are used as training data, 15% samples are used as validation data, and the remaining 15% samples are used as test data. The segments that belong to the same original video sample are assigned together as the training data or validation data or test data. Each experiment is run five times and the average recognition accuracy (%) is reported as the final result. We train our model while using the Adam [
91] optimizer with the learning rate of 0.001. The batch size is set to 90. The number of epochs is set to 100. Pytorch [
92] is used to implement our proposed model. We run the experiments on a NVIDIA TITAN V GPU card.
5.3. Experimental Results
In this section, we first show the performance of unimodal emotion recognition, show the performance of audio-visual emotion recognition, give the stability analysis of common information, and finally describe how our approach can be used for semi-supervised learning.
5.3.1. Unimodal Performance
To show the effectiveness of the learned audio and visual feature representations, we report the performance of our method in audio emotion recognition and visual emotion recognition, respectively, as shown in
Table 1 and
Table 2, respectively. In these two scenarios, we only use the corresponding audio network and visual network to extract the feature representations for emotion prediction. At the same time, we compare our work with previous works, which are all based on the original datasets. Some of them use hand-crafted features and some use DNN-based features.
From
Table 1, we can see that our learned audio features are more discriminative for emotion recognition than the hand-crafted features [
93,
94] on the RAVDESS dataset and the features learned from DNN models with shallow structure [
20,
29] on the eNTERFACE’05 dataset. These results show that our network can effectively learn the audio features for emotion recognition. It is also worth noting that audio emotion recognition performs better on the RAVDESS dataset and eNTERFACE’05 dataset than on the BAUM-1s dataset, which indicate that the first two datasets may contain more emotional information.
From
Table 2, we can also observe that our visual network performs better than the methods [
20,
95,
96]. On the eNTERFACE’05 dataset, it can be found that our method achieves higher emotion recognition accuracy than the method [
95] with hand-crafted features as input and the method [
20] with raw data as input. On the RAVDESS dataset, our learned visual features yield better performance than the method [
96] while using shallow DNN models with raw data as input. These results also show the visual features learned from our network have more discriminative power than previous works.
5.3.2. Multimodal Performance
We report the performance of audio-visual emotion recognition on the eNTERFACE’05, BAUM-1s, and RAVDESS datasets in order to further demonstrate the effectiveness of our system. In the meanwhile, we make a comparison with previous works, which also conduct experiments on these original datasets.
Table 3 summarizes the results. To implement our architecture, we set
equal to 1 and make the fusion network have two fully connected layers on the eNTERFACE’05 dataset, set
equal to 1 and make the fusion network have one fully connected layer on the BAUM-1s dataset, set
equal to 0.1 and make the fusion network have one fully connected layer on the RAVDESS dataset.
From
Table 3, we can find that our method is competitive with the compared works. To be specific, on the eNTERFACE’05 dataset, the performance of our method is at least 1% higher than that of the previous methods [
20,
21,
22,
27,
29,
95,
97,
98]. On the BAUM-1s dataset, we improve the performance of the method [
27] from 60.05% to 67.59%. On the RAVDESS dataset, our method performs much better than the methods [
99,
100] by more than 13%. It is worth noting that the method [
22] combines the audio and visual features that are based on CCA and the method [
27] utilizes a similar approach with low-rank representation. Our method performs better than these two methods, which show that the correlation loss we propose can learn the discriminative feature representations more effectively. Besides, most of the above methods are based on DNN models, while our method achieves better performance, which shows that the features learned from our deep learning model has more powerful expressiveness. To sum up, our deep learning method can efficiently extract the discriminative feature representations with common information in order to achieve the highest accuracies among all the compared methods.
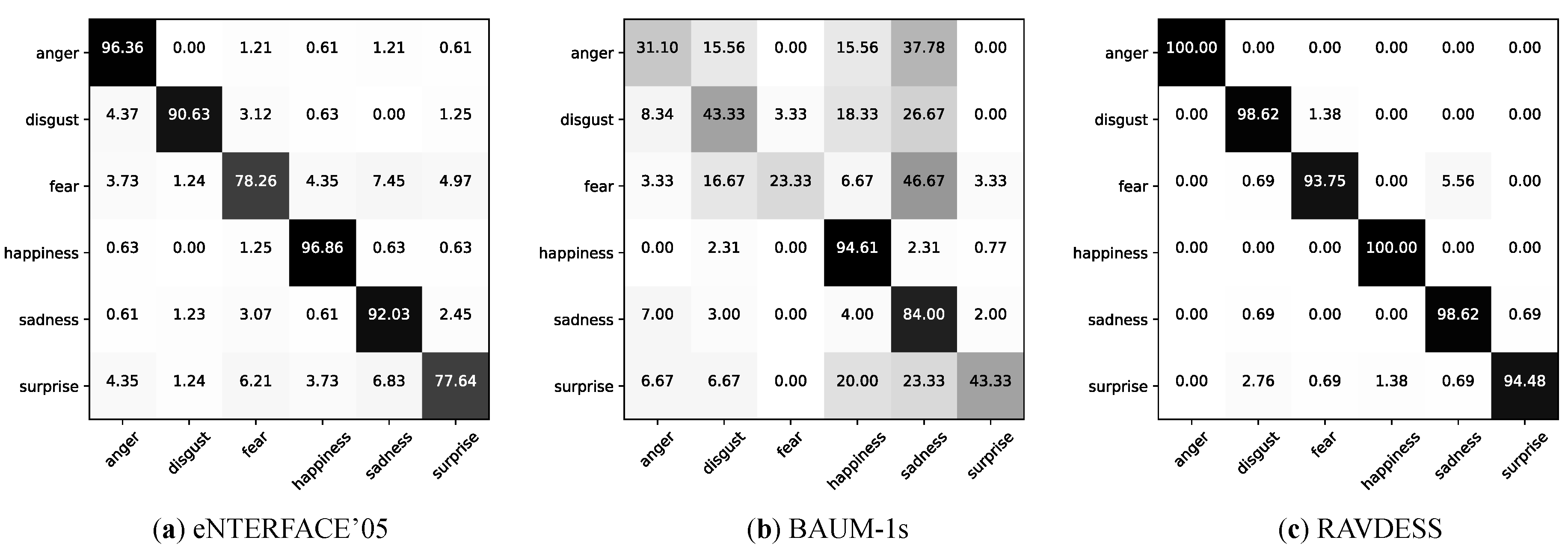
Figure 5 shows the classification confusion matrices using our method on the eNTERFACE’05, BAUM-1s, and RAVDESS datasets. It can be found that, on the eNTERFACE’05 dataset, “fear” and “surprise” are harder to be recognized when compared to other emotions. This indicates audio-visual cues of these two emotions contain less emotional information. On the BAUM-1s dataset, “happiness” achieves the highest recognition accuracy among the six emotions. However, “anger” and “fear” have lower recognition accuracies. This may be due to the small number of samples of “anger” and “fear” on the BAUM-1s dataset, which results in our model being unable to fully learn the features of “anger” and “fear” for emotion classification. On the RAVDESS dataset, both “anger” and “happiness” can be identified with 100% accuracy. Similar to the eNTERFACE’05 dataset, “fear” and “surprise” are more difficult to be recognized.
In addition to the classification confusion matrices, we show some misclassification examples on the eNTERFACE’05, BAUM-1s, and RAVDESS datasets, as shown in
Figure 6. For example, on the eNTERFACE’05 dataset, “disgust” is misclassified as “anger”, “fear” is misclassified as “sadness”. On the BAUM-1s dataset, “anger” is misclassified as “disgust”, “disgust” is misclassified as “sadness”. On the RAVDESS dataset, “disgust” is misclassified as “fear” and “fear” is misclassified as “sadness”. This indicates that similar emotions on these three datasets may be difficult to distinguish.
5.3.3. Stability Analysis of Common Information
From
Figure 1 and
Figure 4, we can see that our proposed correlation loss can make the input features of the fusion network,
and
, maximally correlated. The more fully connected layers in the fusion network, the farther common information is from the softmax output, which may lead to different emotion recognition performance. Besides, we know that
determines how the correlation loss works during the training process. Different
values will lead to different operating mechanisms of common information. Motivated by these two factors, we investigate the stability of common information in our deep learning model.
We do the following study with different settings on the eNTERFACE’05, BAUM-1s, and RAVDESS datasets, as shown in
Table 4,
Table 5 and
Table 6. We, respectively, make the fusion network has one, two and four fully connected layers before the softmax layer, which is shown in the setting column. The baseline in the method column means that we only use classification loss for training. We compare the performance of two forms of correlation loss, one is
, the other is
, which only computes the HGR maximal correlation between the features
and
. We set
to 0.01, 0.1, 1, and 10, respectively, to implement audio-visual emotion recognition to find how the common information works. For each setting, we report the performance of
method and
method, respectively.
We have the following observations on the three datasets: (1) the accuracy of baseline methods is higher than that of audio network and visual network, which indicates that baseline methods can combine the information of audio data and visual data to some extent to improve the emotion recognition performance. (2) When compared with the baseline method, can significantly improve the emotion recognition performance for different weight coefficients and different fully connected layers in the fusion network. This shows that the correlation loss we proposed, , is very stable in ing audio-visual emotion recognition. (3) It should be noted that the method can also improve emotion recognition performance, but it is weaker than method. For example, on the eNTERFACE’05 dataset, when the fusion network has one fully connected layer, methods with the weight coefficient of 0.1 perform worse than the baseline method. On the RAVDESS dataset, when the fusion network has four fully connected layers, method with the weight coefficient of 0.01 also performs worse than the baseline method. (4) On the eNTERFACE’05 dataset, the highest accuracy of 88.66% is achieved when we use and set with two fully connected layers in the fusion network. On the BAUM-1s dataset, the highest accuracy 67.59% is achieved when we use and set with one fully connected layer in the fusion network. On the RAVDESS dataset, the highest accuracy 97.57% is achieved when we use and set as 0.1 with one fully connected layer in the fusion network. These show that our method can benefit from common information with appropriate network settings. (5) When we set the weight coefficient to 0.1 or 1 and make the fusion network has one or two fully connected layers, our model performs better on all three datasets than models with other settings.
5.3.4. Robustness Analysis on Missing Modality
In our analysis above, we assume that audio and visual data are available during the testing stage. However, when generalizing the trained models to the real-world, we may encounter modality missing scenarios, which requires a good fusion model should perform well, even if missing modality occurs during the testing process. Motivated by this, we conduct the following study on the eNTERFACE’05 dataset in order to verify the robustness of our model in the testing process.
In our architecture, we concatenate the feature
of visual data and the feature
of audio data into the fusion network for emotion classification. In order to represent the modality missing problem during testing stage, we set the feature of one modality to
in order to indicate that this modality is missing, and then concatenate it with the feature of another modality to predict emotion. It should be noted that features of another modality is obtained by using the model we have trained. We consider three scenarios: only audio data are missing, only visual data are missing, and audio and visual data are missing. In each scenario, we, respectively, set 20%, 50%, and 80% of test data as missing. For the third scenario, the audio and visual data are missing at half of the missing rate, respectively. For example, the missing rate of 20% means that audio and visual data are missing with 10%, respectively. We compare the performance of three methods,
,
and baseline. They have the same network structure, with two fully connected layers in the fusion network. For the
and
methods, we set
. The baseline method means that we only use classification loss for training. For each setting, we report the emotion recognition accuracy, which is shown in
Figure 7.
From
Figure 7, we have the following observations: (1) as the missing rate increases, the emotion recognition accuracies of
,
and baseline methods decrease. (2) In the three data missing scenarios, the downward tendency of
method with the increase of missing rate is basically consistent with that of
method, but the performance of the
method is always lower than that of the
method. (3) When compared with the
method, the performance of the baseline method decreases faster with the increase of missing rate. The gap between
method and baseline method will become more apparent as the missing rate increases, especially in the scenario where only audio data are missing. This shows that the
method is more robust to deal with missing modality problem during the testing stage.
5.3.5. Semi-Supervised Audio-Visual Emotion Recognition
Semi-supervised learning has been used in many tasks when labeled data are scarce or difficult to obtain. It assumes that, during the training process, we have some labeled data and some unlabeled data. By using these two parts of data, semi-supervised learning can help us to perform better classification than supervised learning using only labeled data. Here, we show that our method can be easily adapted to semi-supervised audio-visual emotion recognition task. We conduct experiments on the RAVDESS dataset. Specifically, we mask the labels of some training data to indicate that they are unlabeled data. For the labeled data, audio modality, visual modality, and the corresponding emotion labels are available. For the unlabeled data, only audio modality and visual modality are available. We, respectively, set 20%, 50%, 80%, and 100% of the training data as labeled data. For each semi-supervised scenario, we compare the performance of different methods. The average accuracy of each method is reported in
Table 7.
In the method column of
Table 7, audio means that only the audio modality in the labeled data is trained for audio emotion recognition. Visual means that only the visual modality in the labeled data is trained for visual emotion recognition. Baseline means that audio and visual modalities in the labeled data are trained by our whole network with only classification loss for audio-visual emotion recognition.
means that whether labeled data or unlabeled data, we use the correlation loss
to compute the HGR maximal correlation between audio and visual modalities. In addition, for labeled data, we use Equation (
6) in order to compute the classification loss
.
means that we use Equation (
8) to compute the correlation loss
. Additionally, similar to
method, the classification loss
is also computed using labeled data. It is worth noting that, for the
method and
method, classification loss and correlation loss are combined in the form of Equation (
3) with the weight coefficient
to train our network together. Here, we make the fusion network have two fully connected layers to implement the baseline,
and
methods for audio-visual emotion recognition. By comparing with the baseline method that only uses labeled data, we can find that our proposed method
can effectively combine unlabeled and labeled data for audio-visual emotion recognition.
From
Table 7, we have the following observations: (1) the performance of baseline method is better than that of audio method and visual method, which shows the importance of combining information of different modalities to improve the emotion recognition accuracy. (2)
method achieves the highest accuracy among all methods, and it shows that it can significantly improve the performance of audio-visual emotion recognition for different weight coefficients and different percentages of labels. (3)
method can also contribute to improving the performance of audio-visual emotion recognition, but it is weaker than
method, especially when the labels are insufficient. To sum up, our method can effectively improve the performance of audio-visual emotion recognition, showing its potential for semi-supervised learning.
6. Conclusions
In this paper, we propose an efficient deep learning approach to exploit common information between audio data, visual data, and the corresponding emotion labels for emotion recognition on the eNTERFACE’05, BAUM-1s, and RAVDESS datasets. To be specific, we design an audio network and a visual network to learn the feature representations from audio data and visual data, respectively, and then use a fusion network to combine the audio and visual features for emotional recognition. The full loss function of our whole neural network is a linear combination of correlation loss and classification loss. The former is used to extract common information between audio data, visual data, and the corresponding emotion labels with HGR maximal correlation. The latter is used to extract discriminative information from different modalities. We further generalize our framework to the semi-supervised learning scenario. The experimental results demonstrate that by combining the common information with HGR maximal correlation, our deep learning approach can significantly enhance the stability of features that are learned from different modalities, and improve the emotion recognition performance.
In the future, we will investigate the performance of our method for emotion recognition in more datasets. It is worth noting that, in the real world, both audio data and visual data may be noisy. We will further consider audio-visual emotion recognition in the noisy environment. Besides, in addition to audio and visual data, physiological signals [
101,
102,
103] and text data [
104] are important modalities for characterizing human emotions. Therefore, we will consider combining the information of these modalities for multimodal emotion recognition.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}