Defragmenting Research Areas with Knowledge Visualization and Visual Text Analytics



Abstract
:1. Introduction
2. Related Work
2.1. Visual Text Analytics of Research Paper Collections
2.2. Cognitive Data Visualization
2.3. Literature-Based Discovery
2.4. Distributional Similarity
2.5. Methodology Transfer
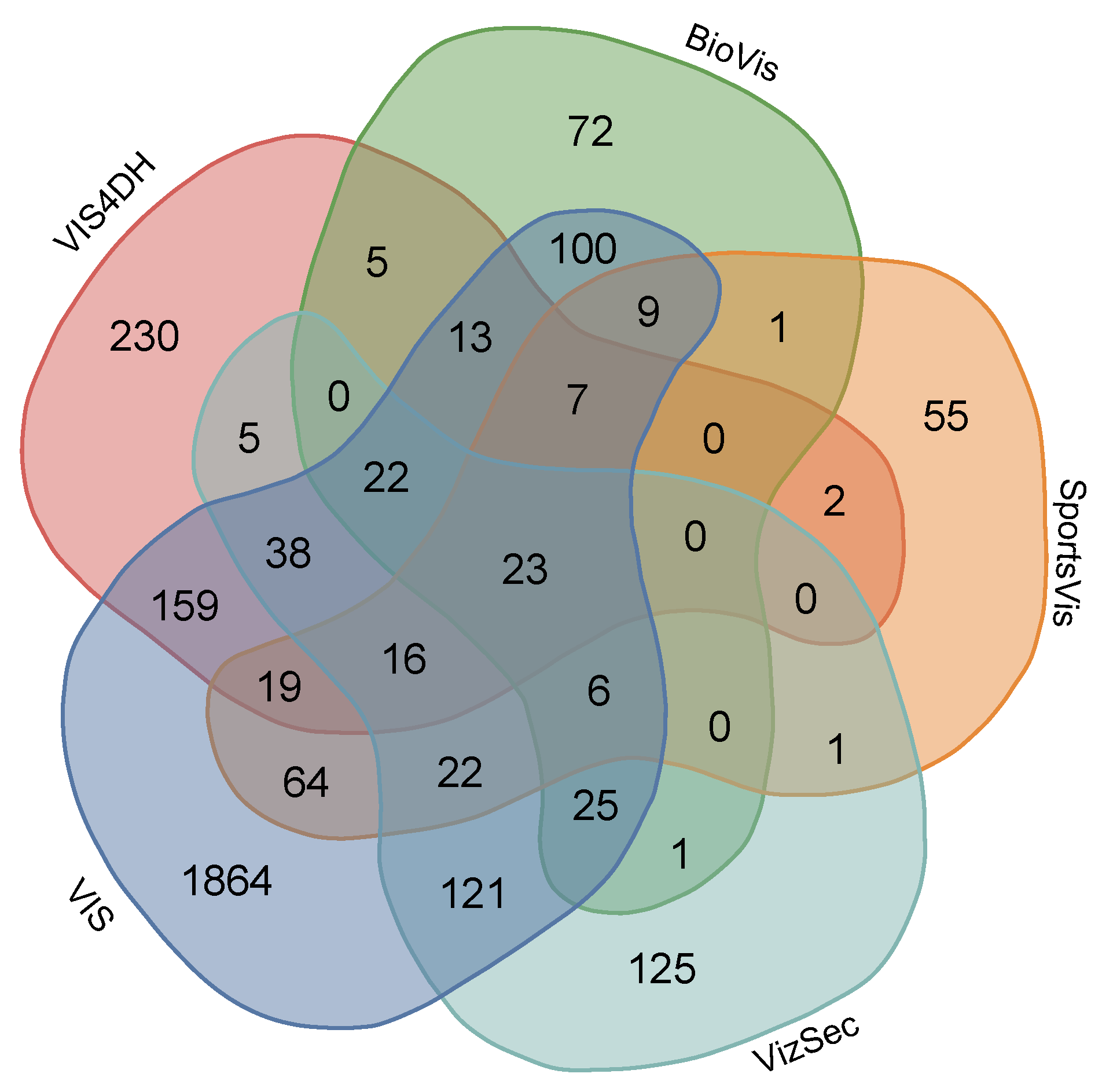
3. Data Description
3.1. Domain-Specific Literatures
3.1.1. VIS4DH
3.1.2. BioVis
3.1.3. SportsVis
3.1.4. VizSec
3.2. Visualization Literature
4. Method
4.1. Data Processing
4.2. Embedding Generation
4.3. Distance Matrix
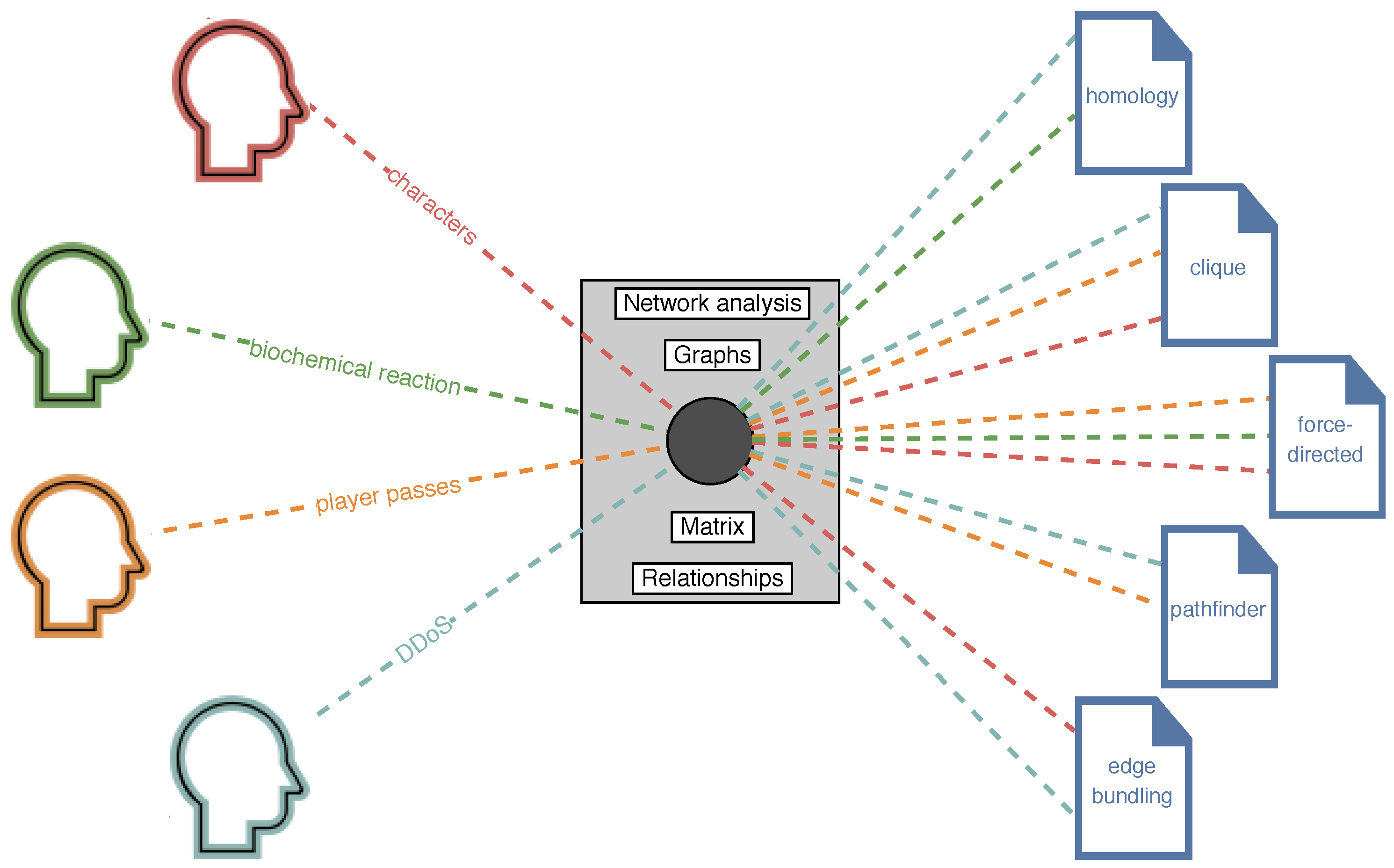
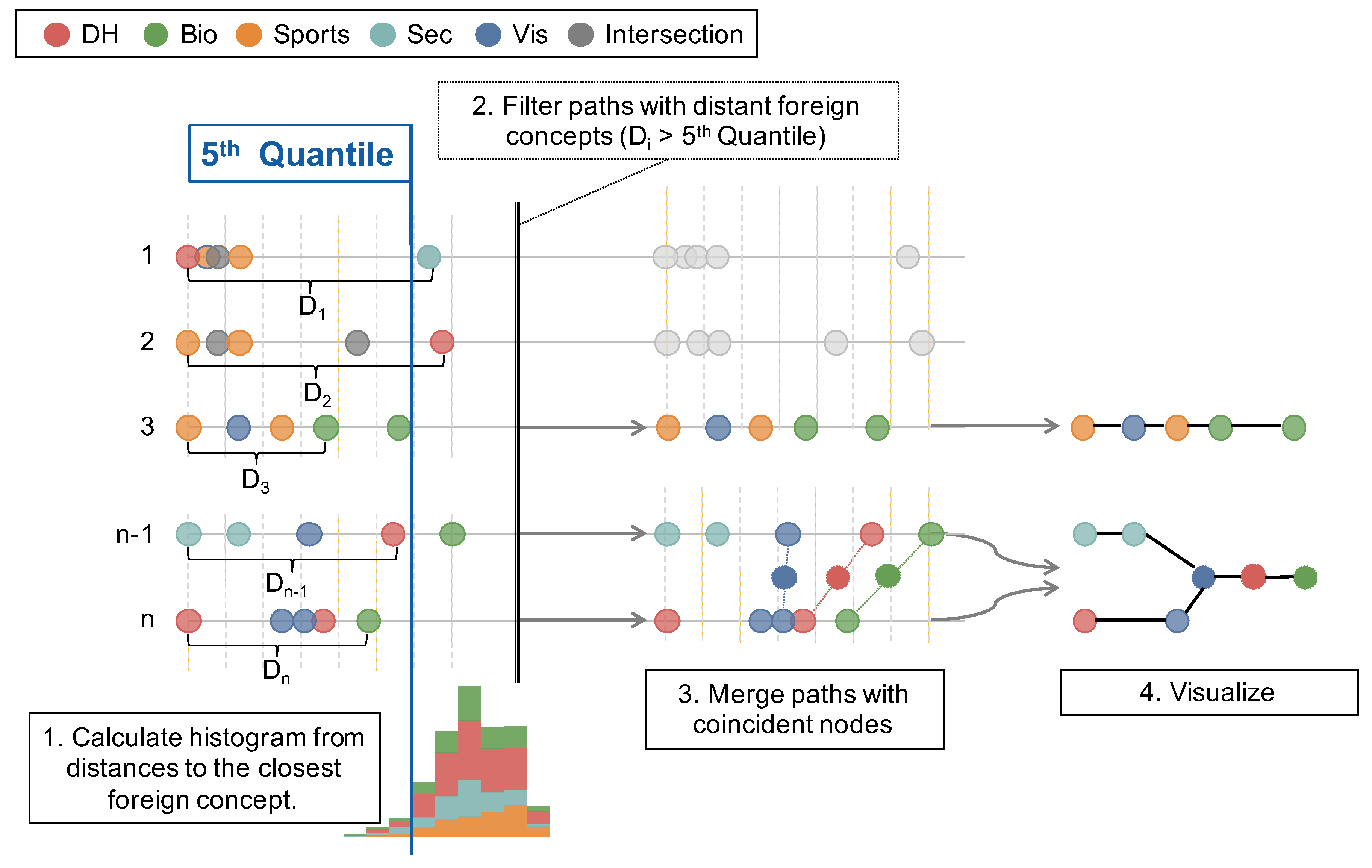
4.4. Finding Interdisciplinary Connections
5. Visualization
6. Use Cases
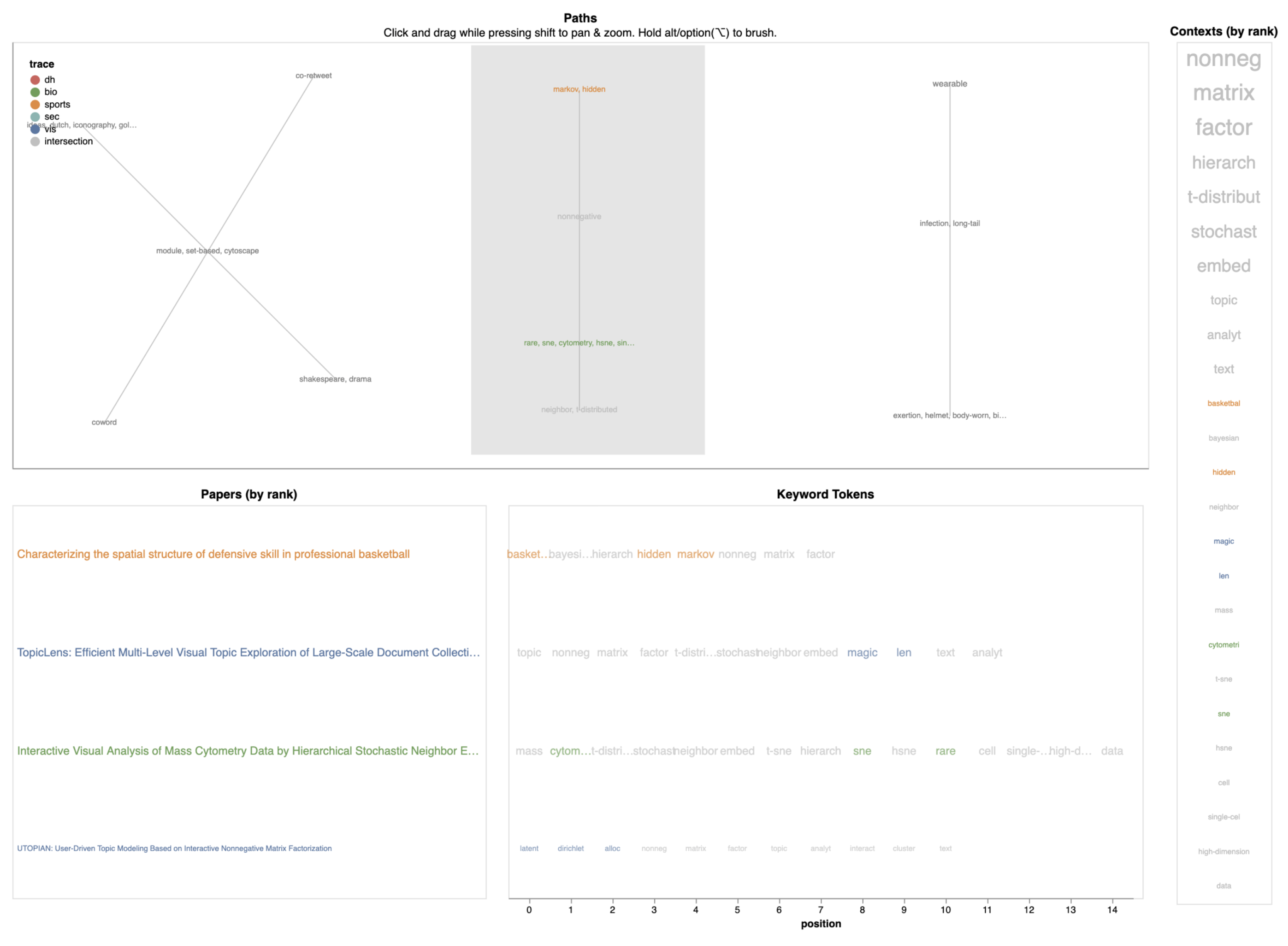
6.1. Case Study #1: Games and Virtual Reality
6.2. Case Study #2: Topic Models and Interaction Techniques
7. Future Work
8. Summary
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| PDVR | Problem-Driven Visualization Research |
| LBD | Literature-Based Discovery |
| MT | Methodology Transfer |
| MTM | Methodology Transfer Model |
| VTA | Visual Text Analytics |
| DH | Digital Humanities |
References
- Simon, S.; Mittelstädt, S.; Keim, D.A.; Sedlmair, M. Bridging the Gap of Domain and Visualization Experts with a Liaison. In Proceedings of the Eurographics Conference on Visualization (EuroVis); The Eurographics Association: Cagliari, Italy, 2015; Volume 2015. [Google Scholar]
- Brehmer, M.; Munzner, T. A Multi-Level Typology of Abstract Visualization Tasks. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2376–2385. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Miller, M.; Schäfer, H.; Kraus, M.; Leman, M.; Keim, D.A.; El-Assady, M. Framing Visual Musicology through Methodology Transfer. In Proceedings of the 4th Workshop on Visualization for the Digital Humanities (VIS4DH), Vancouver, BC, Canada, 20 October 2019. [Google Scholar]
- Burkhard, R. Learning from Architects: The Difference between Knowledge Visualization and Information Visualization. In Proceedings of the Eighth International Conference on Information Visualisation, London, UK, 16 July 2004; pp. 519–524. [Google Scholar] [CrossRef]
- Benito-Santos, A.; Therón, R. GlassViz: Visualizing Automatically-Extracted Entry Points for Exploring Scientific Corpora in Problem-Driven Visualization Research. 2020 IEEE Visualization Conference (VIS), 2020, p. To appear in IEEE VIS 2020 Conference Proceedings. Available online: https://arxiv.org/abs/2009.02094 (accessed on 16 October 2020).
- Satyanarayan, A.; Moritz, D.; Wongsuphasawat, K.; Heer, J. Vega-Lite: A Grammar of Interactive Graphics. IEEE Trans. Vis. Comput. Graph. 2017, 23, 341–350. [Google Scholar] [CrossRef] [Green Version]
- VanderPlas, J.; Granger, B.; Heer, J.; Moritz, D.; Wongsuphasawat, K.; Lees, E.; Timofeev, I.; Welsh, B.; Sievert, S. Altair: Interactive Statistical Visualizations for Python. J. Open Source Softw. 2018, 3, 1057. [Google Scholar] [CrossRef]
- Benito-Santos, A.; Therón Sánchez, R. Cross-Domain Visual Exploration of Academic Corpora via the Latent Meaning of User-Authored Keywords. IEEE Access 2019, 7, 98144–98160. [Google Scholar] [CrossRef]
- Benito-Santos, A.; Therón Sánchez, R. A Data-Driven Introduction to Authors, Readings and Techniques in Visualization for the Digital Humanities. IEEE Comput. Graph. Appl. 2020, 40, 45–57. [Google Scholar] [CrossRef]
- Isenberg, P.; Heimerl, F.; Koch, S.; Isenberg, T.; Xu, P.; Stolper, C.D.; Sedlmair, M.; Chen, J.; Möller, T.; Stasko, J. Vispubdata.Org: A Metadata Collection About IEEE Visualization (VIS) Publications. IEEE Trans. Vis. Comput. Graph. 2017, 23, 2199–2206. [Google Scholar] [CrossRef]
- Thomas, J.J.; Cook, K.A. A Visual Analytics Agenda. IEEE Comput. Graph. Appl. 2006, 26, 10–13. [Google Scholar] [CrossRef]
- Keim, D.A.; Mansmann, F.; Schneidewind, J.; Thomas, J.; Ziegler, H. Visual Analytics: Scope and Challenges. In Visual Data Mining: Theory, Techniques and Tools for Visual Analytics; Lecture Notes in Computer Science; Simoff, S.J., Böhlen, M.H., Mazeika, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 76–90. [Google Scholar] [CrossRef] [Green Version]
- Berger, M.; McDonough, K.; Seversky, L.M. Cite2vec: Citation-Driven Document Exploration via Word Embeddings. IEEE Trans. Vis. Comput. Graph. 2017, 23, 691–700. [Google Scholar] [CrossRef]
- Fried, D.; Kobourov, S.G. Maps of Computer Science. In Proceedings of the 2014 IEEE Pacific Visualization Symposium, Yokohama, Japan, 4–7 March 2014; pp. 113–120. [Google Scholar] [CrossRef]
- Shahaf, D.; Guestrin, C.; Horvitz, E. Metro Maps of Science. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; ACM: New York, NY, USA, 2012; pp. 1122–1130. [Google Scholar] [CrossRef]
- Török, Z.G.; Török, Á. Cognitive Data Visualization—A New Field with a Long History. In Cognitive Infocommunications, Theory and Applications; Topics in Intelligent Engineering and Informatics; Klempous, R., Nikodem, J., Baranyi, P.Z., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 49–77. [Google Scholar] [CrossRef]
- Shakhnov, V.; Zinchenko, L.; Makarchuk, V.; Verstov, V. Visual Analytics Support for the SOI VLSI Layout Design for Multiple Patterning Technology. In Proceedings of the 2015 6th IEEE International Conference on Cognitive Infocommunications (CogInfoCom), Gyor, Hungary, 19–21 October 2015; pp. 67–70. [Google Scholar] [CrossRef]
- Soós, S.; Vida, Z. Topic Overlay Maps and the Cognitive Structure of Policy-Related SSH. In Proceedings of the 2014 5th IEEE Conference on Cognitive Infocommunications (CogInfoCom), Vietri sul Mare, Italy, 5–7 November 2014; pp. 413–418. [Google Scholar] [CrossRef]
- Chen, C. Visualising Semantic Spaces and Author Co-Citation Networks in Digital Libraries. Inf. Process. Manag. 1999, 35, 401–420. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Kuljis, J.; Paul, R.J. Visualizing Latent Domain Knowledge. IEEE Trans. Syst. Man Cybern. Part Appl. Rev. 2001, 31, 518–529. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.T. The Development and Empirical Study of a Literature Review Aiding System. Scientometrics 2012, 92, 105–116. [Google Scholar] [CrossRef]
- Godwin, A. Visualizing Systematic Literature Reviews to Identify New Areas of Research. In Proceedings of the 2016 IEEE Frontiers in Education Conference (FIE), Erie, PA, USA, 12–15 October 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Thilakaratne, M.; Falkner, K.; Atapattu, T. A Systematic Review on Literature-Based Discovery. Acm Comput. Surv. (CSUR) 2019, 5, e235. [Google Scholar] [CrossRef] [Green Version]
- Swanson, D.R. Fish Oil, Raynaud’s Syndrome, and Undiscovered Public Knowledge. Perspect. Biol. Med. 1986, 30, 7–18. [Google Scholar] [CrossRef] [PubMed]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. In Advances in Neural Information Processing Systems 26; Burges, C.J.C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2013; pp. 3111–3119. [Google Scholar]
- Thilakaratne, M.; Falkner, K.; Atapattu, T. Automatic Detection of Cross-Disciplinary Knowledge Associations. In Proceedings of the ACL Student Research Workshop; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 45–51. [Google Scholar]
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by Latent Semantic Analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Levy, O.; Goldberg, Y. Neural Word Embedding as Implicit Matrix Factorization. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 2177–2185. [Google Scholar]
- Levy, O.; Goldberg, Y.; Dagan, I. Improving Distributional Similarity with Lessons Learned from Word Embeddings. Trans. Assoc. Comput. Linguist. 2015, 3, 211–225. [Google Scholar] [CrossRef]
- Heimerl, F.; Han, Q.; Koch, S.; Ertl, T. CiteRivers: Visual Analytics of Citation Patterns. IEEE Trans. Vis. Comput. Graph. 2016, 22, 190–199. [Google Scholar] [CrossRef]
- Günther, F.; Dudschig, C.; Kaup, B. Latent Semantic Analysis Cosines As a Cognitive Similarity Measure: Evidence from Priming Studies. Q. J. Exp. Psychol. 2016, 69, 626–653. [Google Scholar] [CrossRef]
- Eppler, M.J. Visuelle Kommunikation—Der Einsatz von graphischen Metaphern zur Optimierung des Wissenstransfers. In Wissenskommunikation in Organisationen: Methoden · Instrumente · Theorien; Reinhardt, R., Eppler, M.J., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 13–31. [Google Scholar] [CrossRef]
- Burkhard, R.A. Strategy Visualization: A New Research Focus in Knowledge Visualization and a Case Study. Proc. Know 2005, 5, 1–8. [Google Scholar]
- Elouni, J.; Ltifi, H.; Ayed, M.B. Knowledge Visualization Model for Intelligent Dynamic Decision-Making. Hybrid Intelligent Systems; Advances in Intelligent Systems and Computing; Abraham, A., Han, S.Y., Al-Sharhan, S.A., Liu, H., Eds.; Springer International Publishing: Cham, Swizterland, 2016; pp. 223–235. [Google Scholar] [CrossRef]
- Fadiran, O.A.; van Biljon, J.; Schoeman, M.A. How Can Visualisation Principles Be Used to Support Knowledge Transfer in Teaching and Learning? In Proceedings of the 2018 Conference on Information Communications Technology and Society (ICTAS), Durban, South Africa, 8–9 March 2018; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Perin, C.; Vuillemot, R.; Stolper, C.D.; Stasko, J.T.; Wood, J.; Carpendale, S. State of the Art of Sports Data Visualization. Comput. Graph. Forum 2018, 37, 663–686. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Wang, X.; Collins, C.; Dou, W.; Ouyang, F.; El-Assady, M.; Jiang, L.; Keim, D. Bridging Text Visualization and Mining: A Task-Driven Survey. IEEE Trans. Vis. Comput. Graph. 2018, 25, 2482–2504. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aggarwal, C.C. Machine Learning for Text; Springer International Publishing: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Fruchterman, T.M.J.; Reingold, E.M. Graph Drawing by Force-Directed Placement. Softw. Pract. Exp. 1991, 21, 1129–1164. [Google Scholar] [CrossRef]
- Bier, E.A.; Stone, M.C.; Pier, K.; Buxton, W.; DeRose, T.D. Toolglass and Magic Lenses: The See-through Interface. In Proceedings of the 20th Annual Conference on Computer Graphics and Interactive Techniques; Association for Computing Machinery: New York, NY, USA, 1993; pp. 73–80. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Saul, N.; Grossberger, L. UMAP: Uniform Manifold Approximation and Projection. J. Open Source Softw. 2018, 3, 861. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Astels, S. Hdbscan: Hierarchical Density Based Clustering. J. Open Source Softw. 2017, 2, 205. [Google Scholar] [CrossRef]
- El-Assady, M.; Kehlbeck, R.; Collins, C.; Keim, D.; Deussen, O. Semantic Concept Spaces: Guided Topic Model Refinement Using Word-Embedding Projections. IEEE Trans. Vis. Comput. Graph. 2020, 26, 1001–1011. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | # Documents | # Unique Tokens | Avg. Keyword Tokens per Doc. | # Exclusive Tokens |
|---|---|---|---|---|
| VIS4DH | 221 | 539 | 230 (42.7%) | |
| BioVis | 69 | 284 | 72 (25.4%) | |
| SportsVis | 59 | 225 | 55 (24.4%) | |
| VizSec | 175 | 405 | 125 (30.9%) | |
| VIS | 2253 | 2508 | 1864 (74.3%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benito-Santos, A.; Therón Sánchez, R. Defragmenting Research Areas with Knowledge Visualization and Visual Text Analytics. Appl. Sci. 2020, 10, 7248. https://doi.org/10.3390/app10207248
Benito-Santos A, Therón Sánchez R. Defragmenting Research Areas with Knowledge Visualization and Visual Text Analytics. Applied Sciences. 2020; 10(20):7248. https://doi.org/10.3390/app10207248
Chicago/Turabian StyleBenito-Santos, Alejandro, and Roberto Therón Sánchez. 2020. "Defragmenting Research Areas with Knowledge Visualization and Visual Text Analytics" Applied Sciences 10, no. 20: 7248. https://doi.org/10.3390/app10207248
APA StyleBenito-Santos, A., & Therón Sánchez, R. (2020). Defragmenting Research Areas with Knowledge Visualization and Visual Text Analytics. Applied Sciences, 10(20), 7248. https://doi.org/10.3390/app10207248