1. Introduction
Human activity recognition (HAR) is one of the most essential topics of computer vision concerning the last two decades and has been used in various areas such as video-based surveillance systems [
1], elderly care [
2], education [
3], and healthcare [
4,
5,
6,
7]. HAR provides information about human physical activity and aims to discover simple or complex procedures in a very realistic environment. To recognize human activities at the highest accuracy, HAR presents the right diagnosis of activity models obtained from various sensors. Sensors used in HAR applications consist of three clusters that are cameras, wearable sensors, and gyro sensors [
8,
9,
10,
11,
12]. General approaches address a HAR problem in two main categories as vision-based and non-vision based systems. Vision-based HAR systems combine different methods with advanced applications using image processing. However, non-vision based HAR systems extract the relevant features coming from the sensor and recognize the activity using a proper machine learning classifier. Both methods have positive and negative sides compared to each other. For instance, non-vision based systems work better in terms of environmental conditions such as fixed scenes and lack of lighting and occlusion. On the other hand, vision-based sensors are much cost effective and are more useful in daily life applications (video surveillance systems) [
13]. For this study, we decided on using the vision-based sensor since vision-based sensors fit more for daily life use and are more affordable. There have been various studies for vision-based human activity recognition in the literature. Despite the fact that there exist human activity recognition systems based on RGB cameras, researches indicate that dark environment and illumination changes are still challenging problems. In order to overcome this issue, illumination-invariant systems have been developed using depth sensors. In this regard, a human posture recognition system based on a single depth camera was presented in [
14] where skeleton information is articulated with rotated Gaussian kernels and indexed in tree structure. Another study conducting the same issue is also presented in [
15] where 3D transformations of each skeletal joint are indexed in twist and exponential maps to construct a deformation model to be employed for the recognition and pose tracking of the objects within the range of a single depth camera. In addition, spatiotemporal behavior of human activities is extracted by depth sensors using the cosine distances among 3D skeleton joints [
16]. Similarly, in [
17], 3D pose estimation system is proposed in which multiple body joints are constructed in a per-pixel classification problem by combining confidence scored intermediate body parts.
Different from RGB cameras and depth sensors, various sensors have been employed to achieve human activity recognition such as multiple accelerometers, pyroelectric sensors, and wearable sensors. In [
18], authors use wearable sensors to perform human behavior analysis. In [
19], motion sensors are employed to analyze daily motion activities. Another study employed pyroelectric sensors to recognize abnormal human activities [
20]. In [
21], smart phones are used for human activity recognition based on the analysis of signals that come from motion sensors. Additionally, internet of things (IoT) technology is used for human activity recognition by employing different machine learning methods [
7].
On the other hand, various feature types, data structures and machine learning approaches were employed to obtain better performance in human activity recognition. In [
6], a healthcare application based on a single camera is proposed in which multiple features are classified by means of a Hidden Markov Model (HMM). In other study, spatial-temporal features are extracted and analyzed in [
22,
23]. In [
24], graph structure is employed for abnormal human activity recognition. Additionally, a system based on weighted segmentation of the red channel is proposed to control background noise in which feature selection is performed by averaging and ranking the correlation coefficients of background and foreground weights [
25]. Moreover, deep learning methods, especially long short-term memory (LSTM) networks, are widely used in human activity recognition [
26,
27,
28,
29]. However, they require big training data and high-dimensional feature vectors to perform well in classification tasks.
In previous study [
10], LSTM showed dramatically the worst performance with low dimensional feature vectors among the other machine learning classifiers, which are not deep learning-based methods. In order to boost the performance of LSTMs in low dimensional feature space, in this paper, a novel scale and rotation invariant human activity recognition system, which employs LSTM network with low-dimensional 3D posture data, is presented. Since angles are used, proposed system is already scale invariant. In order to provide rotation invariance, body relative direction in egocentric coordinates is calculated. Different from the previous study [
10], 3D joint angles are not employed as the feature vector. Instead, the angle of each limb vector with
X,
Y, and
Z axes of the proposed egocentric coordinate system is employed as the feature vector. Additionally, several compression methods such as averaging filter, Haar wavelet transform (HWT), and discrete cosine transform (DCT) are employed to reduce dimension in feature vectors. This is an essential operation to attain real-time processing speed. Finally, RNN-LSTM network is employed to recognize five classes of human activities, namely, walking, standing, clapping, punching, and lifting. Experimental and benchmarking results show that proposed method dramatically (around 30%) increases the accuracy of LSTM classification in low dimensional feature space compared to the previous method. The rest of the paper is organized as follows:
Section 2 describes the methodology,
Section 3 presents the experiment, experiment results, and evaluation; and conclusions are presented in
Section 4.
2. Materials and Methods
Real-time human activity recognition systems require two main performance metrics, i.e., high accuracy and high processing speed. Since human activity recognition is a time series classification problem, LSTM’s are well known for its excellent performance on time series classification. However, LSTM’s have two disadvantages, i.e., requires high dimensional feature vectors and high number of instances in the training set. Even though it is possible to employ a big data set and high dimensional feature vectors in LSTM networks, the training and the processing speed (frame per second) of classification in real time may become dramatically low. In order to solve this problem, dimension reduction is an inevitable preprocessing stage to speed up the LSTM network. However, dimension reduction leads to loss of information, which causes low accuracy in the classification.
In previous study [
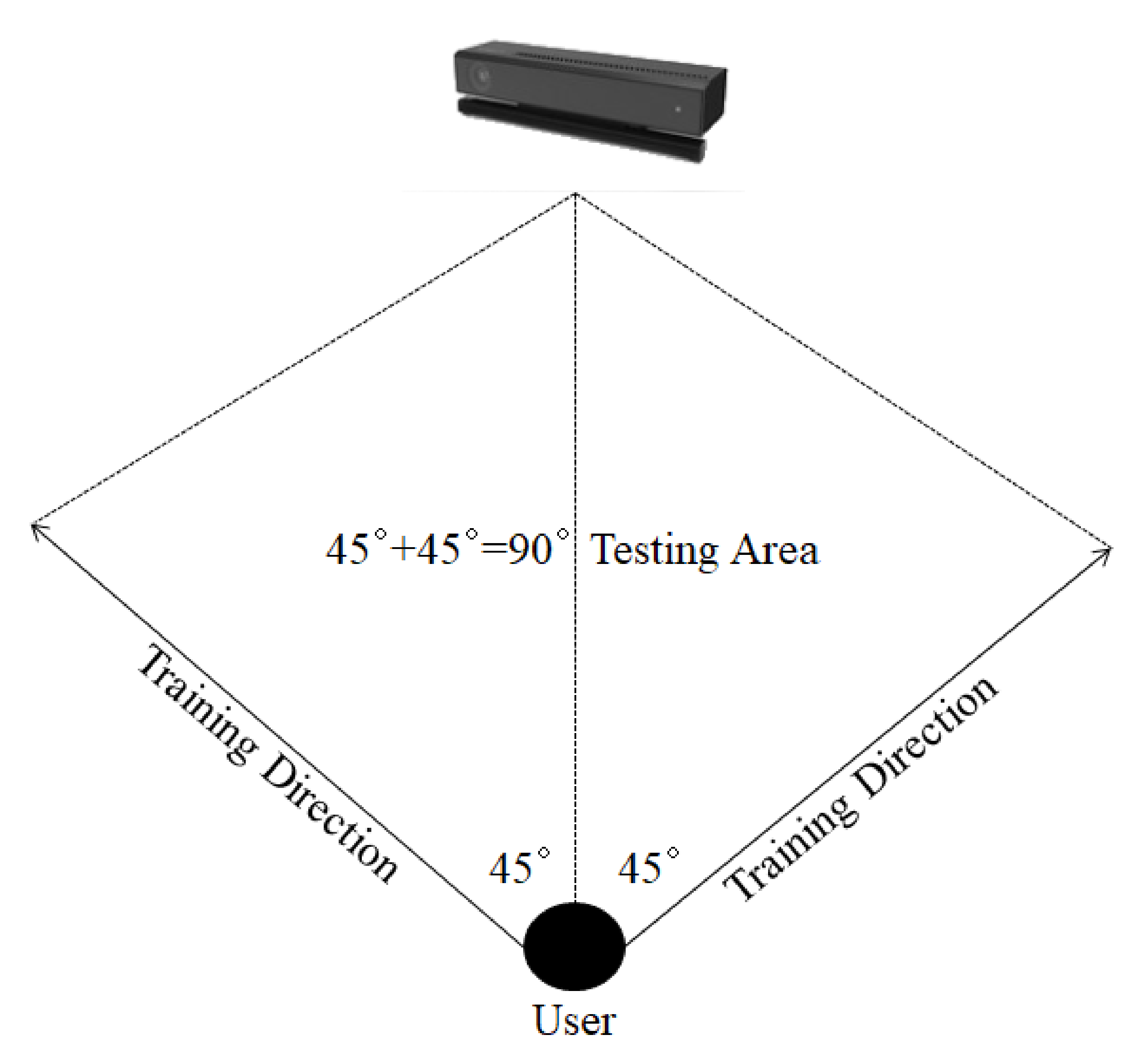
10], we have experimented that LSTM’s accuracy is dramatically lower than the other classifiers when the dimension reduction is applied to the feature vectors. Besides, rotation invariance has been achieved up to 90 degrees by training the users in different posture angles by providing 45 degrees of freedom in training session. Additionally, it requires too much time and effort to train the users, which is not automatic by the system and the posture angles are sometimes different on different users that creates lower performance in the classification. On the other hand, in previous study [
10], 3D angles among the joints were employed as the feature vector, which are calculated with respect to global coordinate system’s axes. Therefore, scale and rotation invariance could not be achieved truly, which caused low performance in LSTM classification with low dimensional feature vectors. The construction of rotation invariance in previous study [
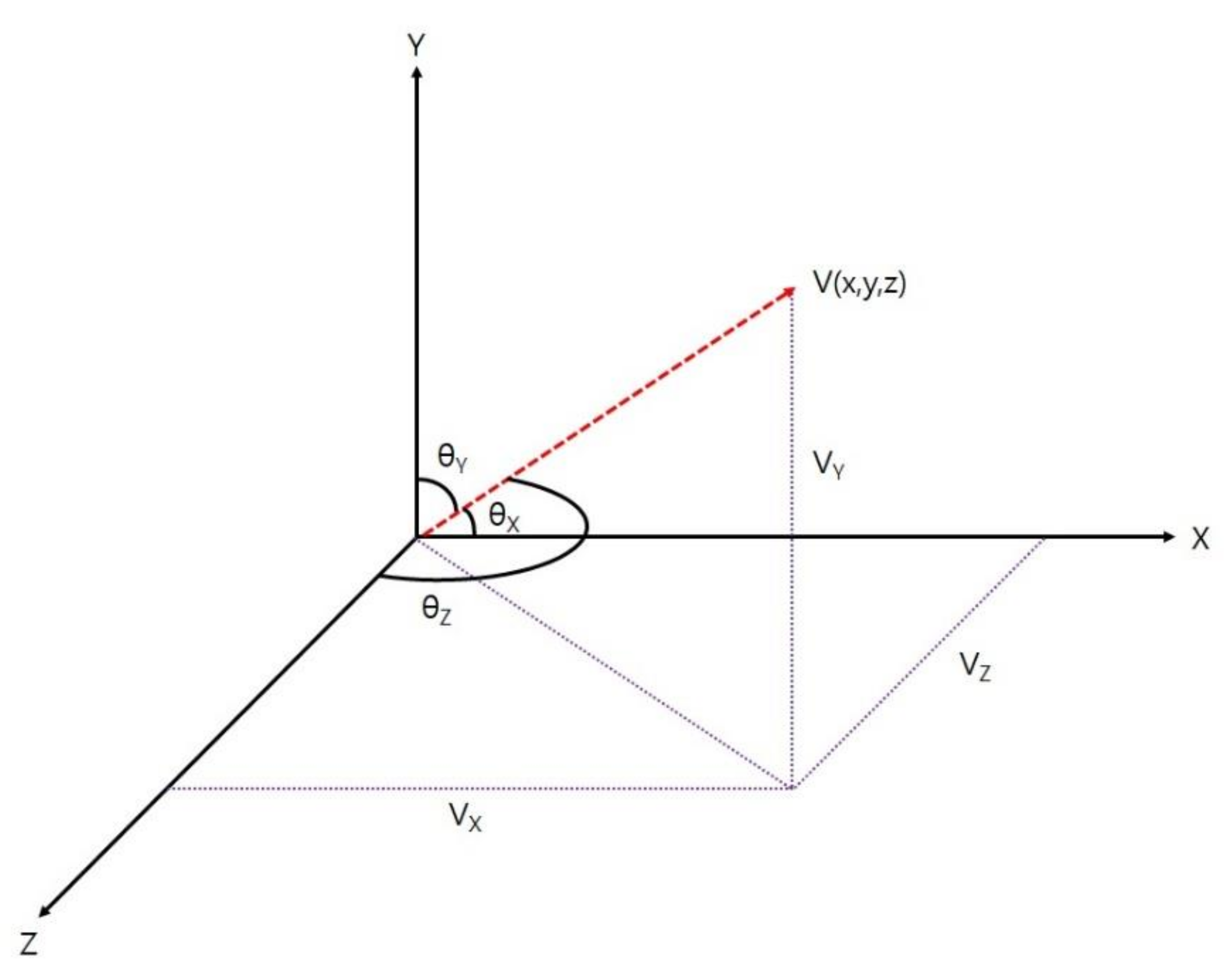
10] is illustrated in
Figure 1.
In order to solve these problems, in this study, which firstly presented briefly in [
30], a scale and rotation invariant human activity recognition system based on body relative direction in egocentric coordinates is proposed. In the proposed system, Kinect depth sensor is employed to obtain skeleton joints. Instead of using joint angles, the angle of each limb with
X,
Y, and
Z axes of the proposed local coordinate system is employed as feature vector. Since angles are used, proposed system is already scale invariant. In order to provide rotation invariance, body relative direction in egocentric coordinates is calculated. The 3D vector between right hip and left hip is used to get the horizontal axis and its cross product with the vertical axis of global coordinate system is assumed to be the depth axis of the proposed local coordinate system.
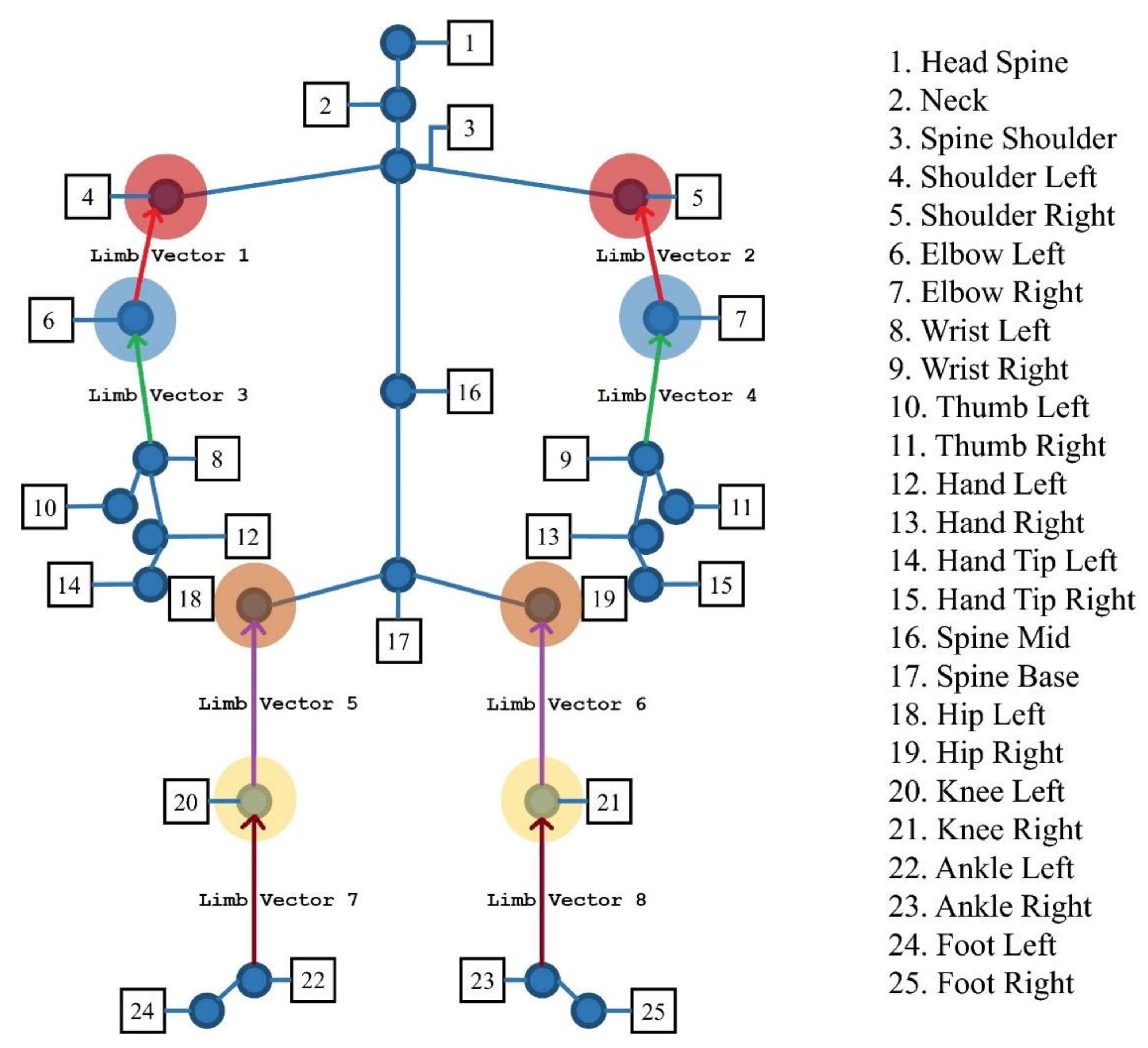
As the system parameters, 8 number of limbs and their corresponding 3D angles with
X,
Y, and
Z axes of the proposed coordinate system are employed as the feature vector. Since human activity recognition requires a period of time to recognize the action, n number of frames in a queue structure is employed as the period of action, which finally yields 8 × 3 × n features for each frame of the Kinect video. Even if the n = 10, which is assumed to be very small period, it creates 240 number of features at each frame of the video. Queue accumulation and formation of feature vectors are illustrated in
Table 1.
As seen in
Table 1, every single limb vector forms 3 number of angles with the egocentric axes. Since 8 number of limb vectors are employed in the system, each frame creates 8 × 3 = 24 number of angles. Later, these 24 number of angles are accumulated to the employed queue data structure within the system. In
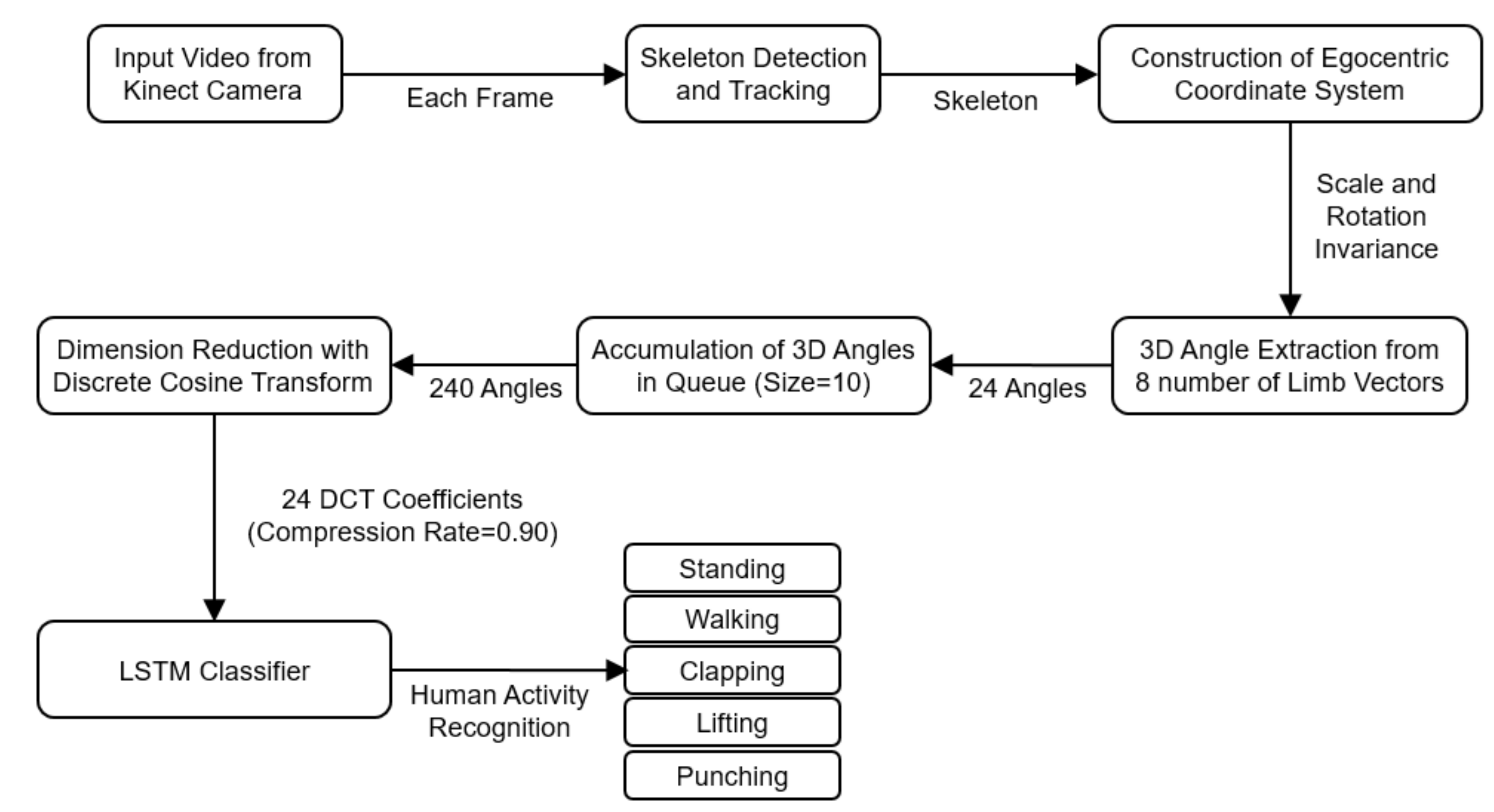
Table 1, queue size is 10 and First-In-First-Out (FIFO) structure of the queue allows us easy allocation of data frame by frame. In other words, queue keeps the last n = 10 items in memory and this allows us instantaneous classification in each frame. Depending on the queue size, which is assumed to be n, system will store 8 × 3 × n number of angles within each frame after the queue is fully filled. Considering the case of n = 10, system will create 8 × 3 × 10 = 240 number of features (angles) in each frame. This is a big number for real-time LSTM classification. Therefore, several dimension reduction methods such as averaging filter, Haar wavelet transform (HWT), and discrete cosine transform (DCT) are applied to reduce the dimension size and eliminate the high-frequency noise. Flow chart of the proposed system is illustrated in
Figure 2.
In case of averaging filter, kernel size (queue size) determines the percentage of compression. If the total number of features in feature vector is 240 and kernel size (queue size) is 10, then, it reduces the number of features to 24, which is 90% compression. In case of HWT and DCT, low-frequency HWT and DCT coefficients are selected and high-frequency coefficients are discarded. In frequency domain, low frequency HWT and DCT coefficients are indexed towards the left while high frequency coefficients are indexed towards the right in one dimension. Therefore, a compression rate is employed as the system parameter to select the low-frequency coefficients. If the compression rate is 0.90, it means that the first 10% of the HWT and DCT coefficients are selected to be used as feature vector in the classifier. If the number of features is set to 240, the corresponding number of HWT and DCT coefficients is also 240, which is reduced to 24 when the compression rate is set to 0.90 in system settings. Finally, RNN-LSTM network is employed to recognize five classes of human activities, namely, walking, standing, clapping, punching, and lifting.
2.1. Egocentric Coordinate System Relative to Human Body Direction
In previous study [
10], global coordinate system was used in which rotation invariance has been achieved up to 90 degrees by training the users in different posture angles by providing 45 degrees of freedom in training session. Additionally, it requires too much time and effort to train the users which is not automatic by the system and the posture angles are sometimes different on different users which creates lower performance in the classification.
In this study, an egocentric coordinate system, which is relative to human body direction, is presented. Similar with the previous study [
10], Kinect depth sensor is employed to obtain skeleton joints. Since angles are used, proposed system is already scale invariant. In order to provide rotation invariance, body relative direction in egocentric coordinates is calculated. The 3D vector between right hip and left hip is used to get the horizontal axis, and its cross product with the vertical axis of global coordinate system is assumed to be the depth axis of the proposed local coordinate system. Different from the previous study [
10], 3D joint angles are not being used, instead, 8 number of limbs and their corresponding 3D angles with
X,
Y, and
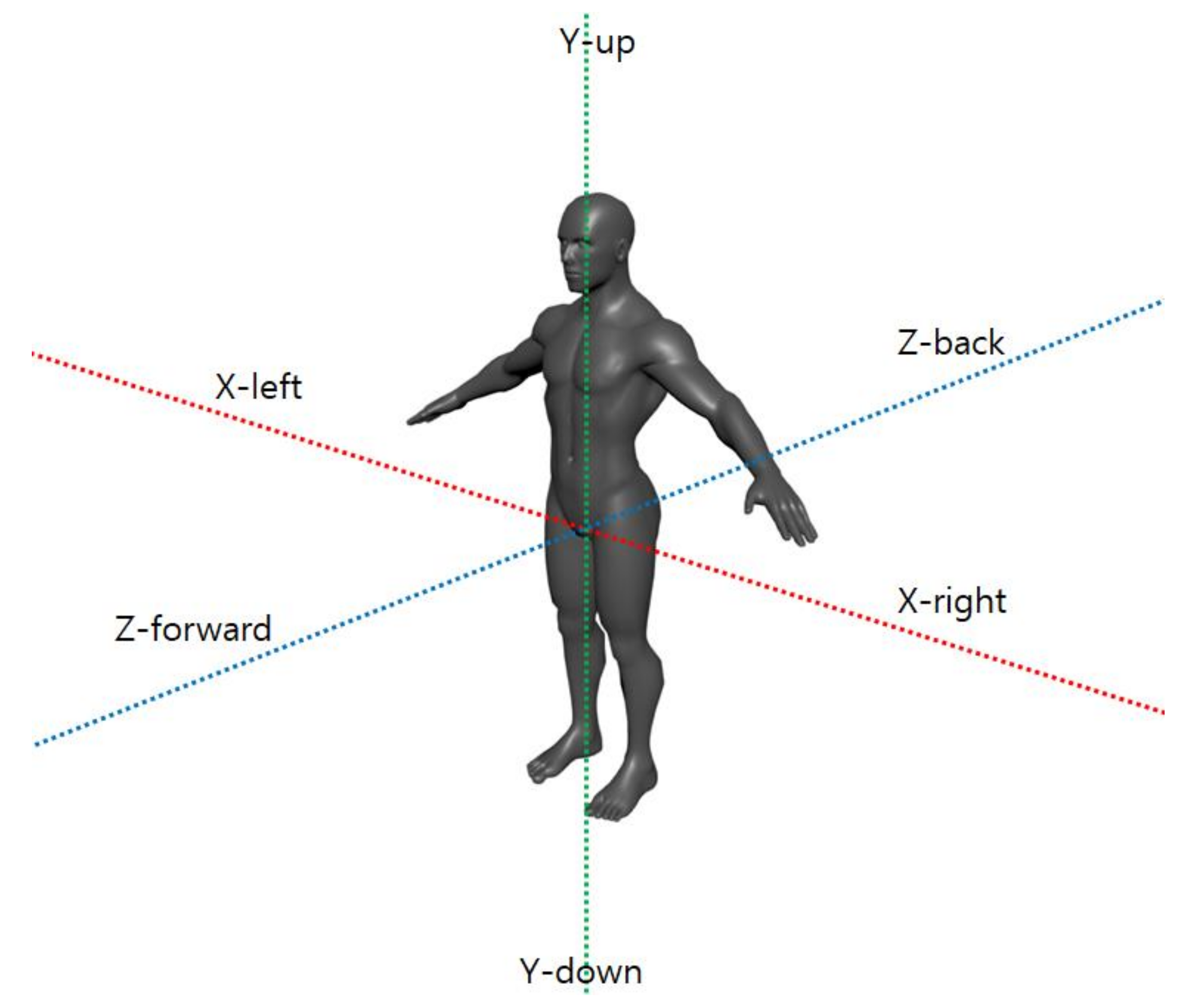
Z axes of the proposed coordinate system are employed as the feature vector. In order to construct egocentric coordinate system,
X axis is assumed as the normalized vector between the right hip and left hip. Additionally,
Y axis is assumed as the vertical unit vector of general coordinate system. Since horizontal and vertical axes are known, the depth axis
Z is constructed by taking the cross product of these two vectors.
Proposed egocentric coordinate system, employed limb vectors, and constructed 3D vectors are illustrated in
Figure 3,
Figure 4, and
Figure 5 as follows:
Mathematically speaking, let
is an unit vector denoted as
and
, where
is the unit vector along the
X axis,
is the unit vector along the
Y axis, and
is the unit vector along
Z axis. The third vector, which is orthogonal to both
and
, is found by the cross product of two vectors:
, where
is the angle between
and
. The calculation comes from the basic dot product formula shown below. The cosine angle between two vectors is actually the dot product of two vectors, which are normalized by dividing their components with the magnitude of each vector as follows:
Since all the axes (X, Y, and Z) and limb vectors are normalized, it is easy to find the angle between each limb vector and X axis, Y axis, and Z axis separately. Finally, arccosine of the dot product gives the 3D angle between two vectors in a range of .
2.2. Dimension Reduction with DCT
Discrete cosine transform (DCT) is a spatial to frequency domain transformation method, which represents a sequence of data in the form of a sum of cosine functions that oscillate at different frequencies. The DCT is an orthonormal transform in which
and
are defined in [
31] as follows:
Similar to Haar wavelet transform (HWT) and discrete Fourier transform (DFT), DCT concentrates the signal energy on a small number of low-frequency DCT coefficients. In the frequency domain, compression (dimension reduction) is achieved by keeping the low-frequencyomponents (the most useful information) and discarding the high-frequency components that normally represent noise. Therefore, performing DCT can reduce the data size and noise level.
Table 2 demonstrates an example for the construction of DCT coefficients in frequency domain and indicates the lossy inverse transform as follows.
In the above table, an input vector composed of 10 number of angle values ranging from 0 to π are passed through DCT (discrete cosine transform) and resulting DCT coefficients in frequency domain are illustrated. Additionally, in order to show how the inverse DCT is a lossy method, the resulting values after inverse DCT are also illustrated in the table.
According to the table, values after inverse DCT operation are not exactly same with the input values, which indicates that DCT is a lossy compression method. On the other hand, frequency levels are sorted in ascending order from low frequency to high frequency in the frequency domain. In this regard, dimension reduction is achieved by keeping the low-frequency information and discarding the high-frequency information in the frequency domain. In other words, instead of employing the input vector in spatial domain, low-frequency DCT coefficients in frequency domain are used as the feature vector. By this method, the most useful information is kept and unnecessary information is discarded, which reduces not only the feature dimension but also the noise level at the same time.
2.3. Deep Learning with RNN-LSTM Network
Different from the conventional neural network, LSTM (long short-term memory) network is designed to learn long-term interactions and recall information for long period of time by avoiding the long-term dependency problem. It was first proposed in [
32] with a unique four layered communication structure, which consists of blocks of memory called cells where two number of states are transmitted to the next cell as the cell state and the hidden state. The cell state is the basic element of data stream, which provides forward transmission with little change in the data due to some linear transformations. Additionally, data can be manipulated (adding or removal of data) from the cell state by means of the sigmoid gates, which are actually designed as the series of matrix operations with varying individual weights. On the other hand, LSTMs are well known for their excellent performance on time series classification. LSTMs are capable of learning long-term dependencies and also prevent back-propagated errors from vanishing or exploding, thus avoiding the vanishing gradient problem.
Recurrent Neural Networks (RNNs) have the capability to capture temporal information from both sequential and spatial sequential data. Therefore, RNN-based LSTMs can simulate long windows of activity by replacing RNNs with LSTM storage locations [
33,
34]. The downside of RNNs is the problem of gradient explosion and decay, which interferes with the network’s ability to model the wide temporal relationships between input from a long contextual window and human activity [
35]. The structure of the LSTM neural network is shown in
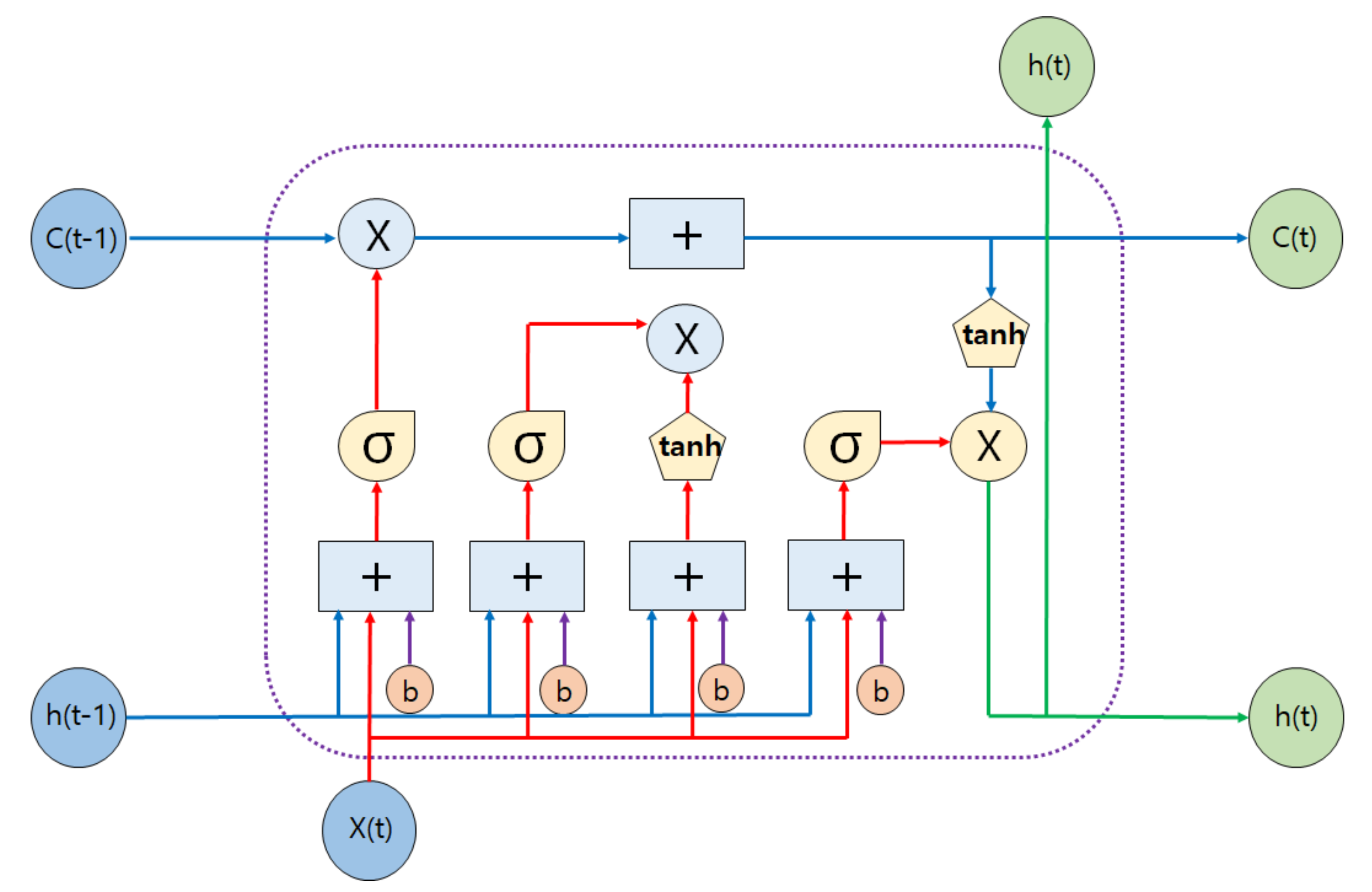
Figure 6 as follows.
In the above figure,
is current input,
is memory from the LSTM unit,
is output of last LSTM unit,
is new updated memory,
is current output,
is sigmoid layer,
is
layer,
is bias,
is scaling of information, and
is adding information. The equations of a typical LSTM network are given below:
Sigmoid function is employed for determining which information is not necessary and should be eliminated from the network. Therefore, it gets two arguments as the old output at time and new input at time t. Forget gate , which is a vector of values between 0 and 1, is employed to decide whether the old output should be modified or partially eliminated for each cell state with weight matrices and bias . For each new input, sigmoid layer and function are employed to determine the importance of information by giving 1 for update operation and 0 for ignorance. Additionally, values to be updated are quantized with weights between −1 and 1 depending on their level of importance. Finally, new cell state is updated from the old cell state using the prior information obtained from the network.
LSTM’s have two disadvantages, i.e., requires high dimensional feature vectors and high number of instances in the training set. Even though it is possible to employ a big data set and high dimensional feature vectors in LSTM networks, the training and the processing speed (frame per second) of classification in real time may become dramatically low.
3. Experimental Results
Different from the previous study’s dataset [
10], the dataset for this research was recreated by Kyungsung University, Department of Electronics Engineering since previous study’s dataset does not include global coordinate system’s axes information, which is a must to create our proposed model. Although there exists plenty of publicly available datasets [
36,
37,
38,
39], none of them includes the global axes’ coordinates, which is an obligatory information to create our proposed egocentric coordinate system. For the coding of the proposed system, previous study’s C# code [
10] was updated with the proposed method’s implementation. For this purpose, Microsoft Visual Studio 2019 was chosen as the C# coding editor. Additionally, several external libraries such as Microsoft Kinect SDK 2.0, Vitruvius, and Accord.NET were used. On the other hand, Python 3.8.3 with TensorFlow was also used for the LSTM network performance evaluation.
The dataset created for this study contains information regarding 10 number of users who differ in height, weight, and clothing. Each activity for each person was logged twice to create a training set and once to create a test set. This is because the test sequences contain different angle variations of the same activity that are used to judge the accuracy of the proposed system under real-life conditions. RNN-LSTM model was employed on the dataset generated from the proposed coordinate system, which was separated into 70:30 for training and testing for the k-fold cross-validation. For the k-fold cross-validation, k was selected as 10. Since each person runs the activity at a different pace, the number of instances for each activity is different. Number of instances in the training and testing datasets employed in our experiments are listed in
Table 3.
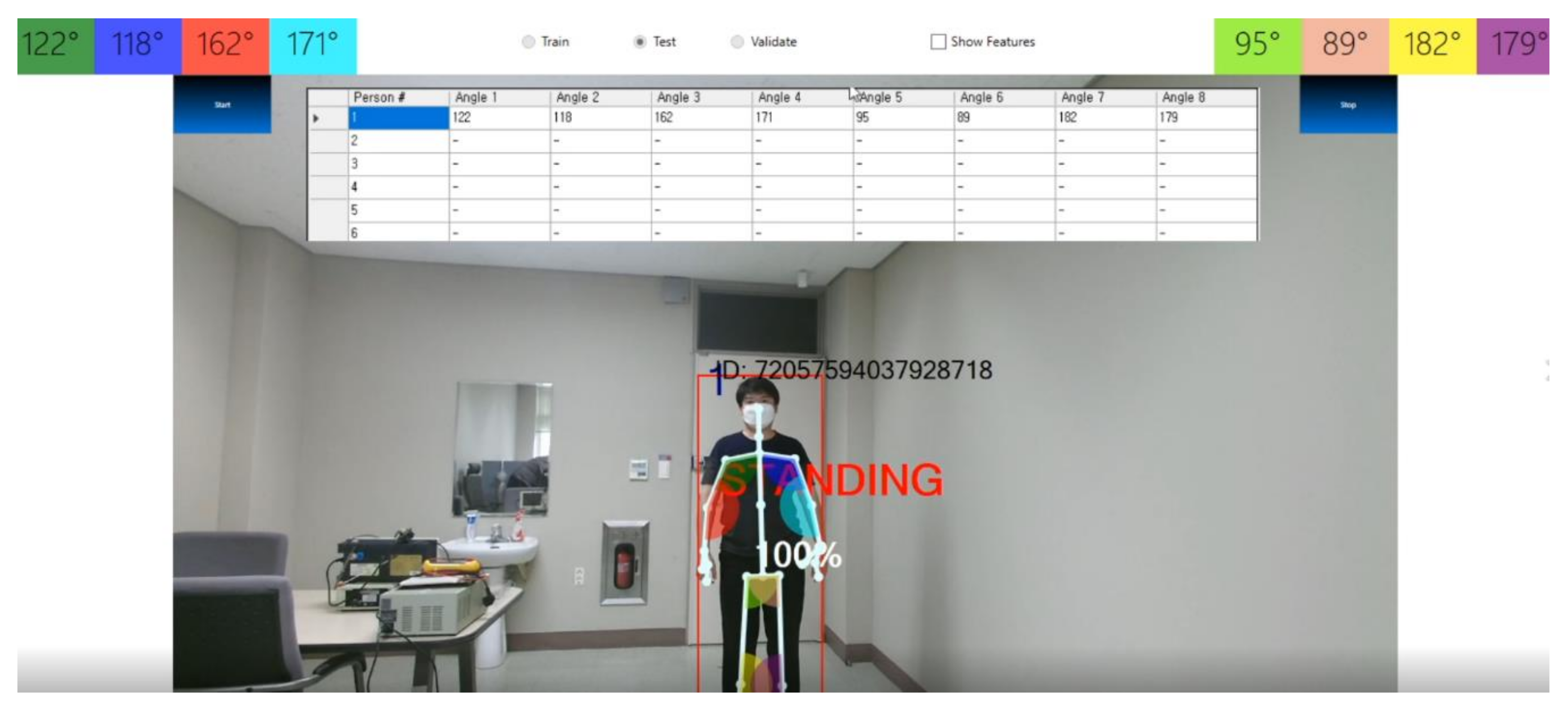
A sample snapshot from experimental environment is demonstrated in
Figure 7 as follows.
In previous study [
10], we have experimented that LSTM’s accuracy is dramatically lower than the other classifiers when the dimension reduction is applied to the feature vectors. Although high-dimensional feature vectors can be used in LSTM networks, the training duration may become high and classification speed (frames per second) can be significantly low in real time. In order to solve this problem, dimension reduction is an inevitable preprocessing stage to speed up the LSTM network. However, dimension reduction leads to loss of information which causes low accuracy in the classification.
In this study, an egocentric coordinate system is presented to boost the performance of LSTM in low-dimensional feature space. For this purpose, in the experimental setup, RNN-LSTM network is employed to recognize five classes of human activities, namely, walking, standing, clapping, punching, and lifting. Several compression methods such as averaging filter, Haar wavelet transform (HWT), and discrete cosine transform (DCT) are employed to reduce dimension in feature vectors. This is an essential operation to attain real-time processing speed. Besides, the effect of queue size on the performance of LSTM classification is observed with varying values.
Table 4 summarizes the experiment’s selected parameters as follows.
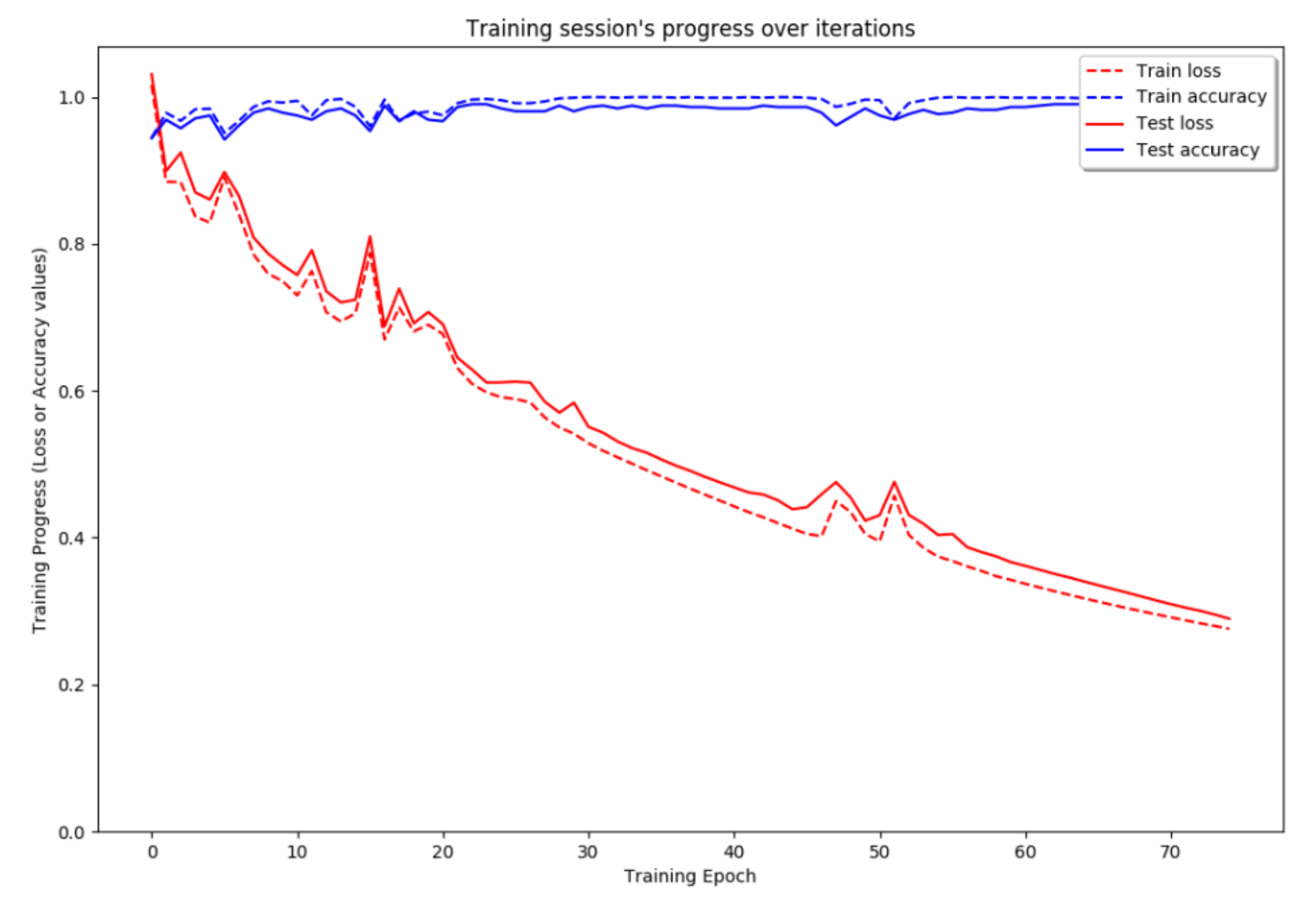
Additionally, in case of employing DCT compression rate of 90% (24 number of features),
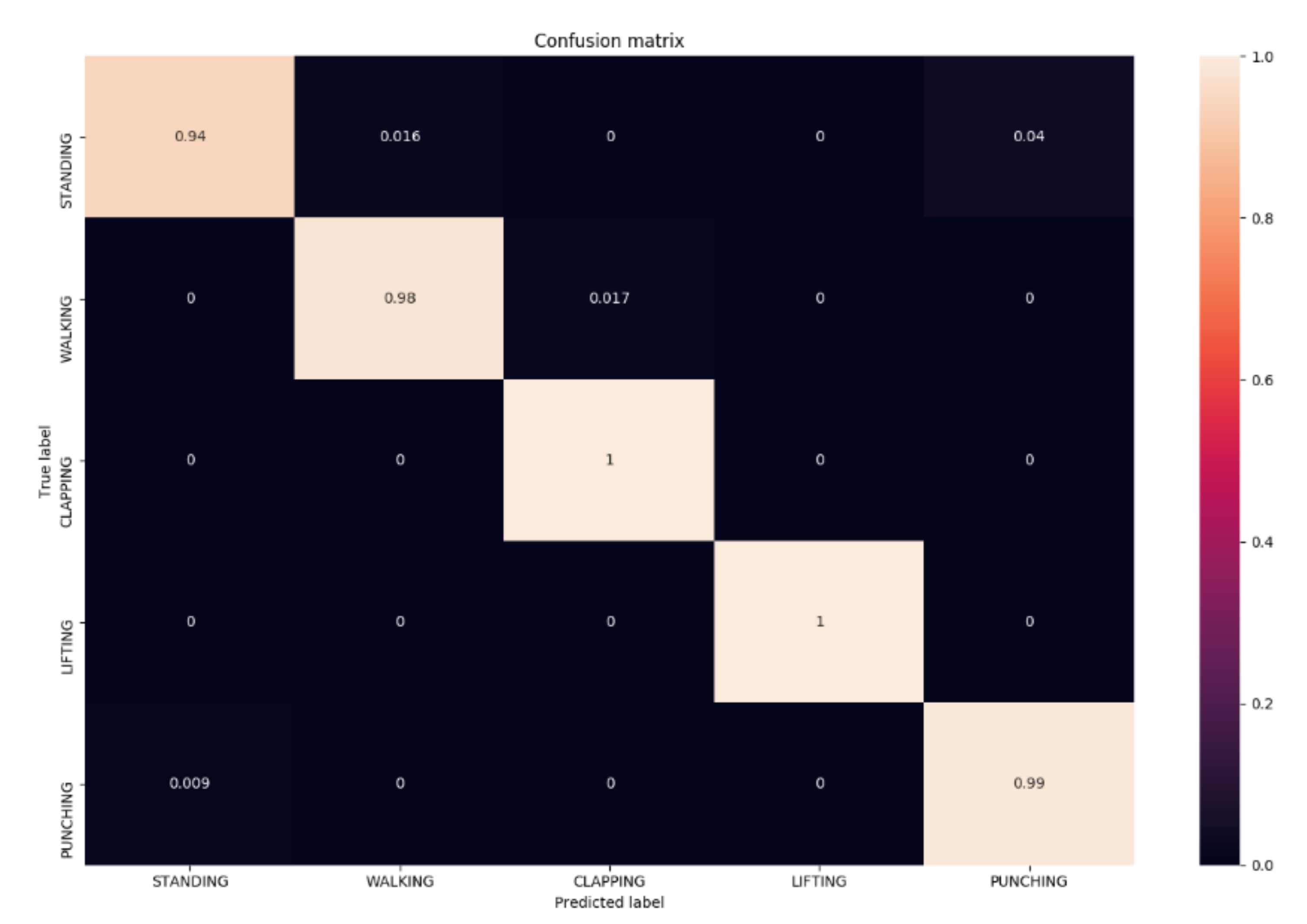
Figure 8 shows the graph of accuracy for both training and testing cost. The confusion matrix obtained after the cross-validation is presented in
Figure 9. Besides, employed performance metrics are listed in
Table 5.
In addition, experimental and benchmarking results are shown in
Table 6,
Table 7, and
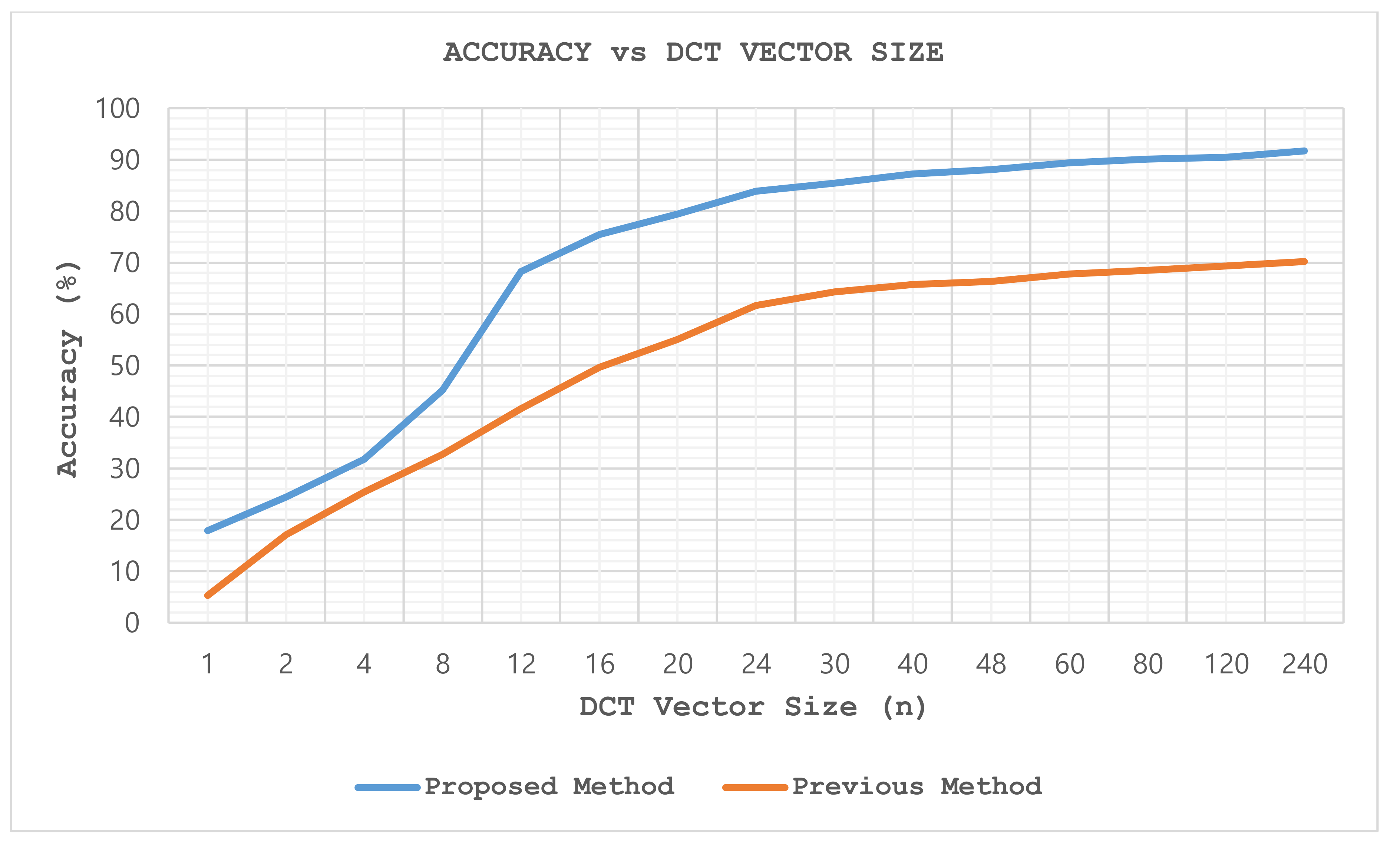
Table 8. Finally, the relationship between the LSTM’s accuracy and DCT vector size (n) is listed in
Table 9 and illustrated with a graph in
Figure 10, and evaluation of the experimental and benchmarking results is done at the end.
According to experimental results, DCT yields the highest accuracy among other dimension reduction methods. As expected, HWT yields lower accuracy than DCT and gives higher accuracy than averaging filter. Both cross-validation with training data and performance measurement with testing data indicate that accuracy is increasing by the increment of feature vectors’ size. Additionally, increment slope smoothly decreases by the increment of feature vectors’ size. However, an optimum threshold in terms of compression rate is required in order to judge the system whether it is applicable in real time. Therefore, the compression rate of 90% (240 number of features are reduced to 24) is chosen as the optimum value of compression, which yields 83.9% accuracy while it is being used with DCT. Here, it is assumed that accuracy greater than 80% is applicable and reasonable in real-time applications. On the other hand, the compression rate can be lowered to get higher accuracies depending on the performance of hardware in which the HAR system is running. If the performance of hardware is high enough to process the LSTM classification in real time without dimension reduction, proposed method yields 91.7% accuracy without dimension reduction, whereas previous method can achieve 70.2% accuracy only. This also proves that proposed method is dramatically (around 30%) better than previous method in terms of keeping higher information in feature vectors, which results in yielding higher accuracies in all the cases.
4. Conclusions
Human activity recognition (HAR) is a common time series classification task, which requires high accuracy with high processing speed in real-time applications. LSTM networks are widely used in time series classification problems, whereas they require big training data and high-dimensional feature vectors to get optimum performance, which dramatically increase the training duration and reduces the processing speed. Dimension reduction methods are generally employed to process LSTMs in low dimensional feature space, which usually yields low performance. In previous study [
10], LSTM showed dramatically the worst performance with low dimensional feature vectors among the other machine learning classifiers, which are not deep learning-based methods. The reason for that was the discrimination power of the feature vectors constructed using the 3D joint angles in global coordinate system was very weak to get high accuracy in LSTM network. In order to boost the performance of LSTMs in low dimensional feature space, in this paper, a novel egocentric coordinate system is presented. Based on the body relative direction of the users in the camera vision, proposed method provides a scale and rotation invariant human activity recognition system, which employs LSTM network with low-dimensional 3D posture data. In the proposed framework, Kinect depth sensor is employed to obtain skeleton joints. Since angles are used, proposed system is already scale invariant. In order to provide rotation invariance, body relative direction in egocentric coordinates is calculated. The 3D vector between right hip and left hip is used to get the horizontal axis and its cross product with the vertical axis of global coordinate system assumed to be the depth axis of the proposed local coordinate system. Instead of using 3D joint angles, 8 number of limbs and their corresponding 3D angles with
X,
Y, and
Z axes of the proposed coordinate system are employed as the feature vector. In terms of dimension reduction, averaging filter, HWT (Haar wavelet transform) and DCT (discrete cosine transform) are employed with varying kernel sizes. Sliding kernel’s functionality is achieved using a specific queue data structure. Finally, extracted features are trained and tested with LSTM (long short-term memory) network which is an artificial recurrent neural network (RNN) architecture. Experimental results indicate that DCT compression has the minimum loss of information among other dimension reduction methods and proposed framework dramatically increases the discrimination power of feature vectors. Using the proposed egocentric coordinate system, LSTM achieves outstanding results with 83.9% accuracy with an optimum DCT compression rate of 90%. Additionally, a benchmarking study is performed with the previous study’s method [
10] in which the highest accuracy is obtained with 61.6% where rotation invariance is satisfied while rotating by the 45 degrees of freedom in training session. Benchmarking results show that proposed method overwhelms the previous method dramatically (approximately 30% in accuracy) and yields excellent results. As the future work, other attempts to obtain different source of coordinate input will be tested instead of using the Kinect camera, e.g., such as from CCTV real time video without a depth sensor.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}