1. Introduction
Nowadays, the World Wide Web is an environment where the users can create and share the information with almost minimal restrictions. The majority of the users use the web responsibly and effectively. However, there is a group of users, which act with the type of behaviour, that could be described as anti-social. Numerous definitions of the anti-social behaviour currently exist [
1], but there are two major types of such behaviour present:
Misinformation spreading—this type of actions usually include creation and sharing of misleading content in various forms, e.g., hoaxes, fake or biased news, fake reviews, etc.
User reactions—this type of behaviour usually occurs in user conversations and has many different forms, e.g., discussion manipulation, cyber-bullying, hate speech, trolling, spamming and other.
Both forms of anti-social behaviour present a serious issue, as their consequences can be significant, also in the real-world. Internet users often communicate with each other in real-time; the discussions usually involve a considerable number of users. Such massive communication supported by modern technologies which enable partial anonymity also leads to the new threats in form non-proper user reactions. Anti-social user reactions in online discussions are often related to the use of abusive language. There are numerous different definitions of such behaviour and it could be difficult to find the exact definition of such phenomenon and is even a more significant challenge to do so in the online environment [
2]. However, toxic comments in an online discussion, in general, can be defined as a response in an aggressive way, which forces the offended participants to abandon it (e.g., personal attacks, verbal bullying) [
3]. As the vast majority of those data are in the form of text, various techniques of natural language processing (NLP) can be utilized to their processing.
With a growing number of textual data generated in online environments, there is a strong need to detect and eliminate the various forms of anti-social behaviour effectively. Currently, manual techniques are still frequently used in the detection of such behaviour in online communities (discussion forums, social networks, etc.). Using human moderators responsible for finding and revealing the anti-social behaviour in online environments can be very time consuming and also biased by moderators themselves. In general, there is a strong need to design and implement the new methods able to detect the anti-social behaviour from the content automatically using the NLP, machine learning and artificial intelligence techniques. The overall goal of these approaches is to utilize the results of such methods for both, prevention and elimination of negative impacts of anti-social behaviour in online communities, for example by enabling the fully-automated detection and prediction of different types of anti-social behaviour from the user-created content. However, ML and NLP methods can still suffer from learning from the data which are often human-labelled. Measurement and mitigation of unintended bias is a non-trivial problem, which has been also studied in the area of toxicity detection [
4,
5].
The work presented in this paper focuses on exploring the use of currently popular deep learning architectures to predict the toxicity in the comments. While several studies were dealing with the problem of using deep learning to predict the toxicity of the comments, they are inconsistent in terms of pre-processing, model application and evaluation. Toxic comments are often written in specific language and style from both perspectives, content and form. Texts are relatively short, written using non-standard language, often using offensive language with a lot of grammatical and spelling errors and punctuation marks. Some of them represent just the common typos, but many of them are written purposely by their authors, to avoid the automatic on-line filtering of the abusive language [
6]. In other sentiment analysis tasks, the effect of the pre-processing is well studied and proven, that the right selection of pre-processing may lead to performance improvement [
7,
8,
9]. In this particular domain, we can assume, that it would require minimal pre-processing techniques to ensure that the information contained in the comment text and form would be preserved. On the other hand, there are word embeddings, as a way of text representations, which are currently frequently being used when training deep learning models. Those embeddings are usually pre-trained using various sets of text corpora. Some of the pre-trained embeddings are built using mostly clean, regular words and are more suitable for processing of standard texts while other ones fit better to short on-line communication. In the toxic comments classification task, it would also be interesting to train the word embeddings from scratch using the dataset related to the task. Therefore, in this research, we aimed to compare multiple currently popular deep learning methods and transformer language models and study the effects of different text representations and basic pre-processing techniques applied in the data preparation.
The paper is organized as follows:
Section 2. provides an overview of the abusive language and toxic comments field and application of different machine learning methods to their detection.
Section 3 describes the deep learning methods used for text classification. The following section presents the data used in the experiments and their preparation;
Section 5 then describes the performance metrics used in the experiments, followed by the section describing implemented models and their settings. The next section is dedicated to the experimental evaluation and describes achieved results.
2. Toxic Comments Classification
Sentiment analysis in general considered a research area which combines NLP and text mining to automatically detect and identify the opinions contained in the text and determine the writer’s opinion or attitude with regards to a particular topic [
10]. Although multiple approaches have been applied in this field, most of them are based on the application of machine learning methods. A specific sub-section of sentiment analysis is a detection of abusive language in the conversational content. Use of aggressive or offensive language in online discussions may occur in various forms. Various studies address different aspects of the abusive language in the online discussions, often differentiated by the types of aggression expressed. Therefore, when considering the abusive language detection from the texts, various related tasks are explored, including detection of cyber-bullying, hate or hate speech, online harassment, flaming, toxic comments, extremism, etc. Those tasks are often not clearly distinguishable, often are overlapping, and despite the differences between the concepts, often similar methods are utilized to tackle those problems [
11]. However, there are studies trying to establish the common typology of the different abusive language detection tasks [
12].
Toxic comments detection can be considered as a specific sub-task of approaches mentioned above, which aims to detect and identify the toxicity in the conversational text. It is usually solved as a text classification task, where the input features are extracted from the piece of text. As multiple types of toxicity could be contained in the text (e.g., insults, obscene language, hate, etc.), therefore toxic comments detection is usually considered as a multi-class classification task where the target class describe the particular type of the toxicity contained in the text. In this case, the problem of unbalanced data is a common issue, as the frequency of occurrence of the different toxicity types may vary.
Recently, the essential source of the data used to build the toxicity detection models come from social networks. Data are usually extracted from the discussions, comments or social network posts and typically represent the user reactions to a particular topic [
13]. During recent years, several datasets became publicly available, containing labelled data from different social platforms and areas, e.g., Twitter dataset [
14] contains 25,000 manually annotated tweets containing hate speech. Youtube dataset [
15] consists of 3221 manually labelled comments from YouTube discussions [
16] or very popular Wikipedia talk page corpus also used in this work. However, different datasets are often labelled non-consistently, which could be the effect of the different problem understanding and will require a more integrated approach when collecting the data in the future [
17].
To detect the toxicity in the conversational data, both traditional machine learning methods, as well as advanced deep learning techniques, have been utilized. Traditional machine learning approaches include the use of various classifiers, e.g., Decision Trees [
18], Logistic Regression [
19], Support Vector Machine models [
15] or Ensemble Models [
20]. Traditional machine learning models are frequently used and popular in the detection of other types of anti-social behaviour, such as fake reviews detection. For example, work Naive Bayes and Random Forests have been used in the detection of the fake reviews obtained from Amazon [
21] using data describing the seller, website, product, reviewer and review content. Authors in [
22] answered interesting questions, if the performance of the classification methods for fake reviews filtering are affected when they are used in real-world scenarios that require online learning. Regarding the toxicity detection, authors in [
23] monitored and analyzed the most recently published comments to detect whether an aggressive action emerges in a discussion thread. The authors experimented with various forms of representations of input texts in combination with Radial Basis Function, Support Vector Machines and Hidden Markov Model classifiers. The work [
24] is focused on fake reviews detection and the influence of a length of the text data on a measure of the effectiveness of the learned models. The results of experiments showed that the models learned from the whole body of texts are more effective than models learned only from the headlines. Similarly, in [
25] authors have examined the influence of a length of the text data on the effectiveness of machine learning models trained for recognition of authors of toxic posts. The paper describes an approach to suspicious authors identification based on the training a specialized dictionary of the toxic author and also the training of Naive Bayes and Support Vector Machine models.
However, recently, deep learning techniques proved to be successful in the detection of various types of anti-social behaviour on the web. For example, deep neural networks were used to detect the cyber-bullying within the user posts on the Twitter [
26]. Multiple topologies of Convolutional Neural Networks (CNN) were evaluated to find the most suitable model when handling this task [
27]. Besides tweets, other data sources can be utilized to train the cyber-bullying detectors. Authors in [
28] used transfer learning within different datasets of conversational data (e.g., Wikipedia, Twitter) and then compared the performance of deep learning models. Multiple deep networks were successfully used also in hate speech detection [
29], including deep learning ensemble models [
30]. Multi-label toxic comments classification was also addressed by different deep learning models [
31]. In [
32], authors used CNN for multi-label classification of the comments and experimented with different word embeddings, in [
33], authors compared the performance of CNN to Long Short-Term Memory (LSTM) network, and authors in [
34] presented the capsule network approach. When monitoring social networks, an interesting aspect would be tracking the temporal aspects of toxicity in the comments. In [
35] authors present the CNN model able to detect the toxic tweets. Authors also utilize the hashtags from the tweets related to toxic tweets and also are able to monitor the toxicity propagation over time. Several previous works approached toxicity detection as the binary classification problem. However, deep learning models are also used in more complex, ensemble approaches. In [
36] an ensemble model consisting of CNN, BiLSTM and GRU is presented, which determines whether the text is toxic or not in the first step and then classifies the toxic comments into a more specific category representing the particular type of the toxicity.
3. Deep Learning Methods for Text Processing
Neural networks are considered to be one of the best-performing machine learning algorithms. They have brought great success in the field of artificial intelligence, such as in the field of computer vision, where their task is image processing and pattern recognition, and, for example, in sound processing and speech recognition. In this section, we took a closer look at how neural networks can be used to work with the textual data.
3.1. Feedforward Neural Network
Deep forward neural networks known as the feedforward neural networks (FFNN) or multilayer perceptrons are basic models of deep learning. Feedforward networks became popular in 1986 when Rumelhart, Hinton, and Williams introduced a method of training forward neural networks using the error back-propagation [
37]. The goal of feedforward neural networks is to approximate the function
. For example, the function
maps the input
x to the value
y. FFNN defines the mapping
and finds the value of the parameters
, which leads to the best approximation of the function. The flow of information in FFNN is forward; in practice, this means that the computational model represents an acyclic graph.
The basic model of a neuron is called perceptron. The perceptron receives input signals
via synaptic weights, which form the vector
The perceptron output is given as the scalar product of the input vectors transformed using the activation function
f, to which the bias is added. Bias
b is a constant that does not depend on the input parameters and serves to influence the activation function [
38,
39].
For the best classifiers in our work are used following hyper-parameters and settings:
Activation function on input and hidden layers: ReLU:
In proposed solution we used ReLU (Rectified Linear Unit) [
40] activation function. ReLU belongs to one of the most frequently used activation functions applied in deep networks. It is defined as:
which means, that it transforms negative inputs to 0 and leaves positive inputs without transformation.
Loss function: binary cross entropy
Error function is used to estimate the error of the model during the training. Using the error backpropagation [
41], the neuron weights in particular layer are updated in such manner, that the error rate decreases in following evaluation. We used Binary Cross-Entropy (BCE), which can be defined as:
where
y represents the ground truth and
represents predicted value.
Optimization: Adam
To minimize the error rate of the model in the prediction, optimization function is used. We used Adam (Adaptive Moment Estimation) [
42]. Adam is an optimization function, which computes the learning estimation for each parameter. In addition to storing an exponentially decaying average of past squared gradients
like RMSprop [
43], Adam also keeps an exponentially decaying average of past gradients
, similar to momentum [
44]. Both moving averages are initialized to 0, which leads to the moments’ estimation biased towards zero. Such situation occurs mostly during the initial phases when decay parameters (
1,
2) have values close to 1. Such biased can be removed using modified estimations
a
:
The parameters are updated according to the formula:
Default setting for the parameter is 0.9 and , learning rate and for the parameter. Adam is considered as a suitable optimization method in practical tasks. When comparing Adam to other methods, its advantage is faster convergence and training speed is also higher. It also removes certain issues of other optimization techniques, such as slow convergence, or high variance of the parameters, which could lead to variations in the error function.
Regularization: dropout
The main idea of the dropout is the random removal of specific neurons (along with their connections) from the neural network during the model training [
45]. Ignoring, or ”dropping-out” of specific neurons can prevent their over-adaptation, which could lead to over-fitting. In each iteration, a new sub-network is created, which contains different neurons than during the previous iteration. The output of such a process is a set of sub-networks, which have a higher chance to capture the random phenomena in the data compared to the single robust network. While using this technique, it is necessary to set the parameter defining the probability of selection of a number of neurons, which will be dropped out from the network.
Output activation function: sigmoid
Sigmoid function is a bounded, differentiable real function. It is defined for all real values and has a non-negative derivative in each point [
39]. It is mostly used because of its non-linearity and simplicity of the computation. The function is defined as:
The output of the sigmoid activation function is in the range between 0 and 1, which makes it suitable for use in the classification tasks.
3.2. Convolutional Neural Network
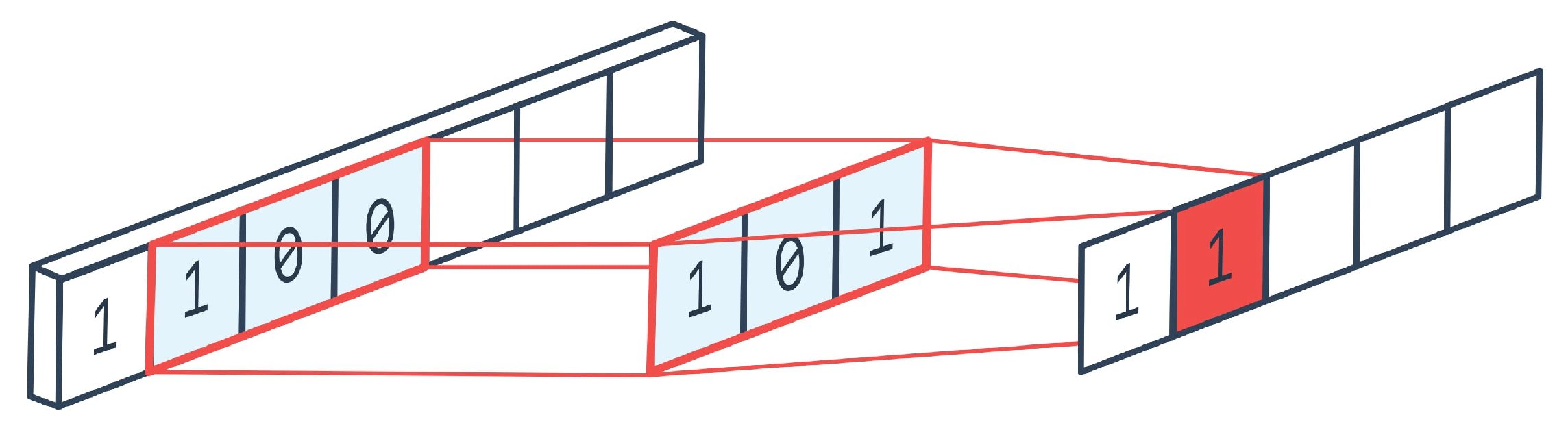
Convolutional neural networks (CNN) represent a specific type of forward neural networks, which contain a layer of neurons for the convolution operation. The inspiration for the architecture of this network was the function of the ocular nerve. Neurons respond to the input of the surrounding neurons’ activations according to a specified size of the convolutional kernel, also called filter. Convolution consists of shifting the convolution kernel over the whole set of values. In this case, the convolution operation represents the multiplication of the convolution kernel and input values (see
Figure 1) [
38].
Pooling layers in convolutional networks are designed to reduce the number of outputs, to reduce the computational complexity, and to prevent the network over-fitting. The sampling layers are usually applied just behind the convolution layers, as the duplicate data are created when the convolution kernels are shifting through the individual inputs. Excess data is removed using the pooling layers.
In our work, we use the Global pooling layer, in which we distinguish between the Global average pooling layer and the Global max pooling layer. These layers work according to the same principle as the traditional average pooling (max pooling) layer. The difference is, that the average (maximum) is not calculated only for a given area, but for the entire input.
3.3. Long Short-Term Memory
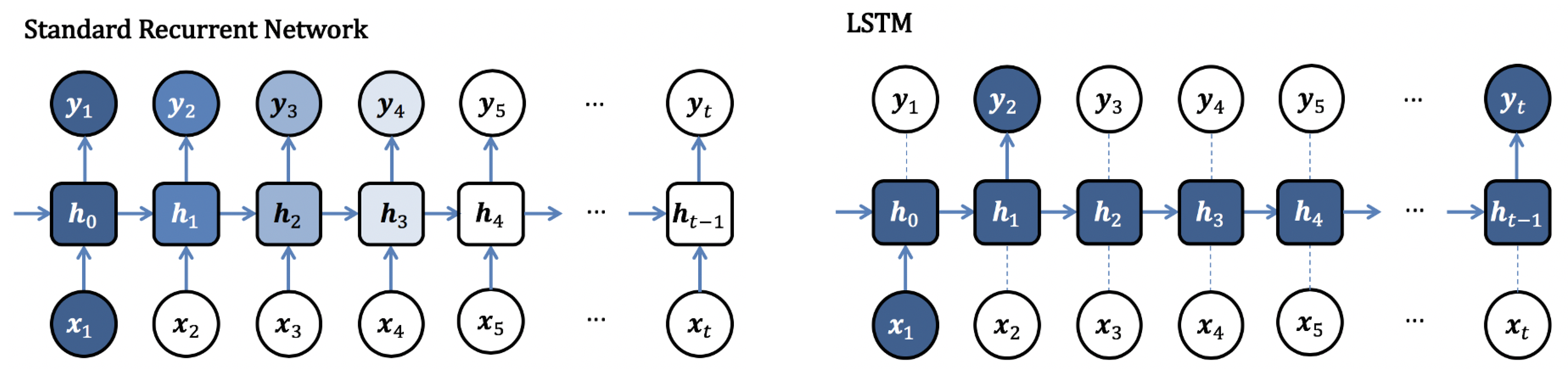
Long Short-Term Memory (LSTM) [
46] is a type of a recurrent neural network. LSTM has a more complex structure, which makes it suitable to deal with the vanishing gradient problem. Using the LSTM in any sequential task will ensure that long-term information and context is maintained (see
Figure 2).
Comparing to other types of neural networks, the LSTM network does not consist of interconnected neurons, but of memory blocks that are connected in layers. The block contains gateways that manage the state and output of the block and the flow of information. Gateways can learn which data in a sequence is important and needs to be preserved. There are four memory block elements performing the following functions (see
Figure 3):
Input gate—it is used to control the entry of information into the memory block.
Cell state—it is used to store long-term information.
Forget gate—it is used is to decide what information will be discarded and what information will be kept.
Output gate—based on the input and the memory unit it is used is to decide what operation to perform on the output.
Bidirectional Long Short-Term Memory network (BiLSTM) represents a specific type of LSTM network. BiLSTMs consists of two individual hidden layers. The first layer is used to process the input sequence forward, and on the other hand, the second hidden layer is used to process the sequence backwards. The hidden layers merge in the output layer, thanks to that the output layer can access to each point’s past and the future context in the sequence. LSTM and their bidirectional variants proved to be very suitable. They can learn how and when they can forget certain information and also they can learn not to use some gateways in their architecture. Faster learning rate and better performance are the advantages of a BiLSTM network [
49].
3.4. Gated Recurrent Unit
Cho et al. [
50] also tried to solve the vanishing gradient problem described in
Section 3.3 in the publication, where they presented the recurrent neural network called Gated Recurrent Unit (GRU). GRU can be considered as a variation of the LSTM network because both are designed in a similar fashion. GRU solves the vanishing gradient problem using an update and reset gates. The update gate helps the model to determine, how much of the previous information (from the previous time steps) needs to be used in the future, and the reset gate determines, how much of that information will be discarded. We also used a bidirectional variant of the GRU network (BiGRU) in our experiments.
3.5. Transformer Models
Transformer models are currently very popular methods used to solve various NLP tasks such as question answering, language understanding or summarization, but has been successfully used in text classification tasks [
51]. BERT (Bidirectional Encoder Representations from Transformers) is a language transformation model introduced by Google [
52]. BERT is is “deeply bidirectional”, which means, it learns the deep representation of texts by considering both, left and right contexts. It is a method used for training of general-purpose language models on very large corpuses and then using that model for the NLP tasks. So there are two steps involved in using BERT: pre-training and fine-tuning. During the pre-training phase, the BERT model is trained on unlabelled data. Then, the model is initialized with the pre-trained parameters and fine-tuned for specific NLP task. Fine-tuning of the BERT model is much less expensive on the computational resources. BERT uses the same architecture in different tasks. BERT is built using the Transformers [
53]. The model comes in two variants, BERT-base and BERT-large. BERT-base consists of 12 Transformer blocks, hidden size of 768 and 12 self-attention heads, BERT-large consists of 24 Transformer blocks, hidden size of 1024 and 16 self-attention heads. There are several BERT variations currently introduced, such as DistilBERT which aims to reduce the size of the BERT model, while retaining the performance [
54], RoBERTa, which optimizes BERT hyper-parameters to improve the performance [
55] or XLNet learns the bidirectional contexts over all permutations of the factorization order [
56].
5. Performance Metrics
To evaluate the models, we decided to use the standard metrics used in classification, e.g., accuracy, precision, recall and F1 score. Such metrics are easy and straightforward to obtain for a binary classification problems and can be computed as:
where:
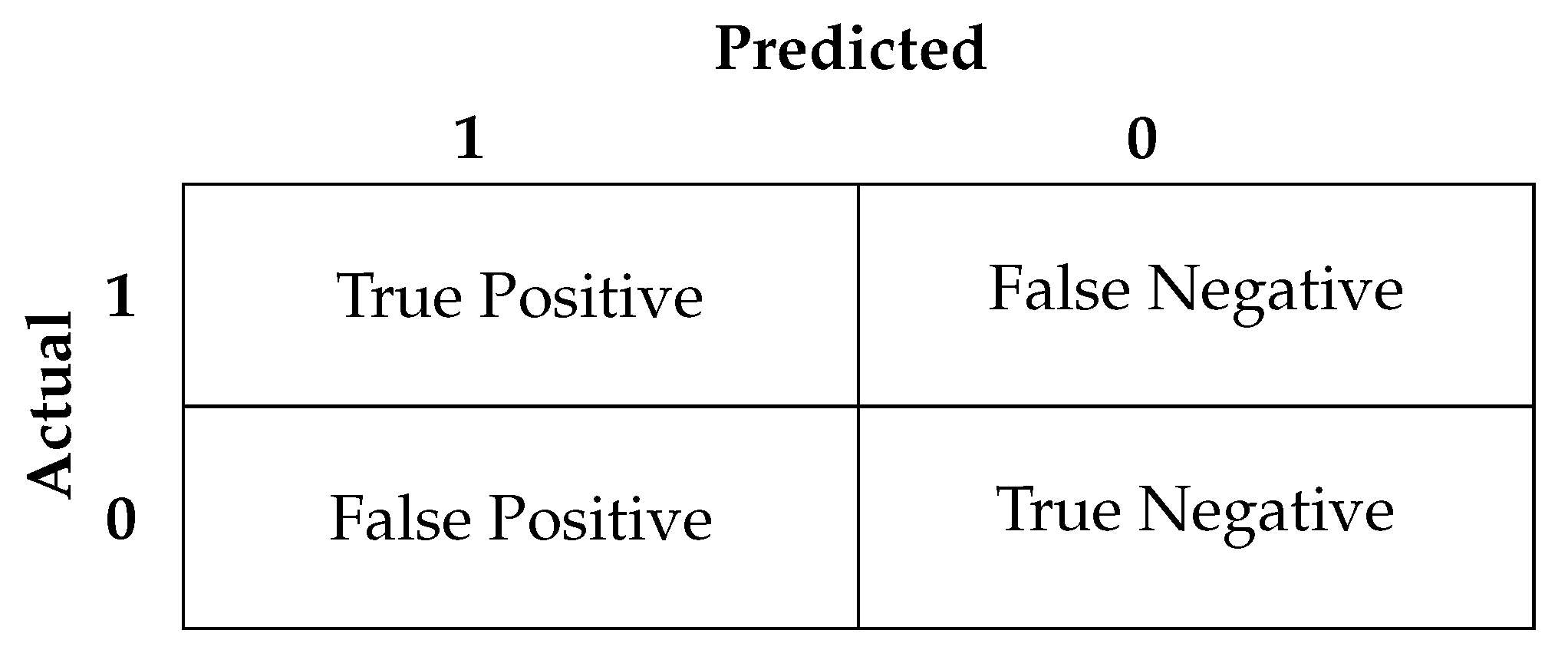
TP—True Positive examples are predicted to be positive and are positive;
TN—True Negative examples are predicted to be negative and are negative;
FP—False Positive examples are predicted to be positive but are negative;
FN—False Negative examples are predicted to be negative but are positive.
To apply such metrics in the multi-label classification, those metrics could be computed for each class (one-vs-rest approach). Usually, we need to compute the confusion matrix (see
Figure 7) for each class
. For each class
, the
i-th class is considered as positive, while the rest of other classes as a negative class. Then, to summarize the performance of the classifier on all classes, metrics can be micro or macro averaged [
61]. The use of micro or macro averaging is dependent on the particular use case. In the following formulas, we will use
,
, and
as the true positive, false positive, and false-negative rates associated with the class
i.
Micro-averaging at first computes the confusion matrix for all classes and then calculates the overall metrics. Micro-averaging may be preferred in case of class imbalance present in the data. Micro-averaged precision and recall metrics are computed as:
On the other hand, macro-averaging is based on the computation of precision and recall for each class and then averaging the overall metrics:
To compare the models, we also used the Area Under Curve (AUC) score to evaluate the models. AUC score computes the area under the Receiver Operating Characteristic (ROC) curve. Although the AUC score is not an ideal metric to compare the models trained on highly-imbalanced data, we used it to compare the models with other models from the relevant literature. The reason behind this is the fact, that the most studies use the AUC score, as it was specified as a criterion in the Toxic Comments Classification Challenge competition.
7. Experiments
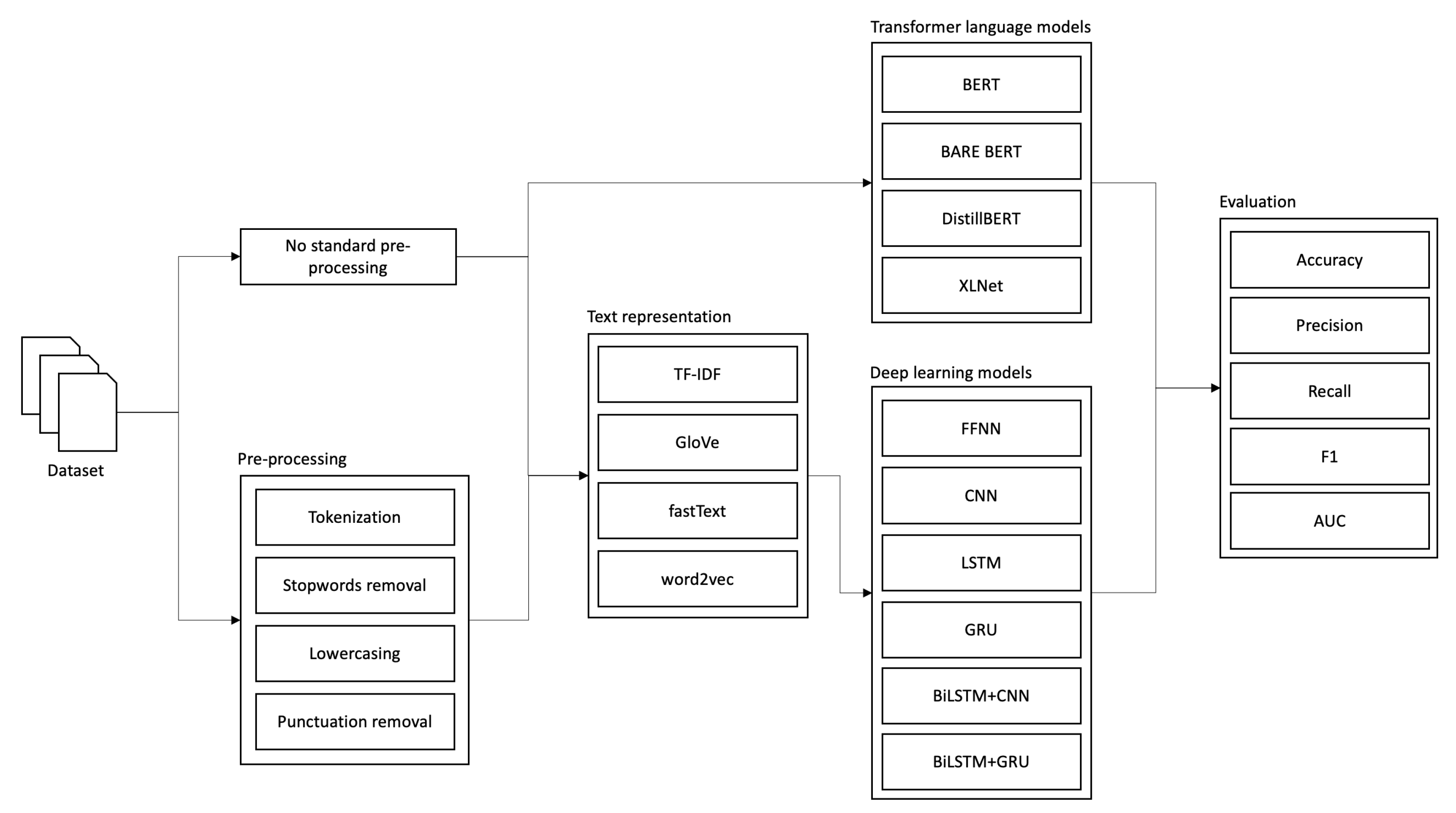
During the experiments, we aimed to compare the effect of different pre-processing techniques on the classification of the toxic comments. In comparison, we used the composed architecture model with different pre-processing methods applied to the data. We aimed to compare the models’ performance using:
TFIDF representation with standard pre-processing;
TFIDF representation without standard pre-processing;
Pre-trained embeddings with standard pre-processing (GloVe, fastText);
Pre-trained embeddings without standard pre-processing (GloVe, fastText);
Custom-trained embeddings with standard pre-processing (word2vec);
Custom-trained embeddings without standard pre-processing (word2vec);
Pre-trained BERT language representations;
Fine-tuning BERT language representations;
Pre-trained DistilBERT language representations;
Pre-trained XLNet language representations.
Figure 9 depicts the workflow of the experiments. It is important to note that due to extreme computational intensiveness of the models training, not every possible combination of the pre-processing and model was explored. Instead, we followed a methodology of the initial evaluation of the models using default settings to choose the best-performing model. Then, we followed with the optimization of hyper-parameters of the best-performing model using grid-search and cross-validation. And finally, we evaluated the fine-tuned model using different combinations of pre-processing and text representations techniques. A more detailed description of the particular steps will be described in the following subsections.
7.1. Selection of Best Deep Learning Model
Initial experiments were aimed to select the most suitable method to explore the pre-processing impact. To do so, we compared the described NN architectures on commonly used embeddings (GloVe). When comparing the particular architectures, we obtained the accuracy performance of each model, cross-validated on the training set and evaluated on the testing set; the results are shown in
Table 4.
To compute the metrics (accuracy and loss), we transformed the class probabilities (output of the neural networks) into the crisp class predictions using a simple rule, which assigned the sample to a class if a probability of a given category was higher than 0.5. During this phase, we worked with this simplistic approach, in further evaluations of the best performing model, we also adopted a more advanced technique to identify the optimal threshold for each class.
The training phase of the deep learning models on the used dataset is very demanding on computational resources. The training process is very time-consuming, even on recent GPUs. We decided to optimize the hyper-parameters of the best model on 10% stratified sample of the dataset. We performed the fine-tuning of the hyper-parameters using a grid search with cross-validation. We tuned the best-performing model (biLSTM-CNN), which we used with the obtained parameters as the starting architecture for further experiments. Considered parameters used for the grid search are shown in
Table 5.
To gain a better understanding of the learning process and more importantly, to estimate the learning variance, we performed 10-fold cross-validation of the best performing model on the training data.
Table 6 summarizes the results of the particular folds during the cross-validation of the BiLSTM + CNN model. This step was important to estimate the learning variance. As we can observe that the overall variance of the learning is acceptable, we will not use the cross-validation during further experiments with pre-processing. This enabled us to reduce the total time needed to train and test all evaluated combinations of the pre-processing and text representation methods.
All models were implemented in Python language using Tensorflow [
62] and Keras [
63] libraries. The source codes are available on GitHub (
https://github.com/VieraMaslej/toxic_comments_classification). The experiments were conducted on a PC equipped with a 4-core Intel Xeon processor clocked at 4 GHz and NVIDIA Tesla K40c GPU with 12 GB memory.
7.2. Analysis of Text Representation and Pre-Processing Influence on Deep Learning Models
From the initial set of experiments, we selected a composed BiLSTM network architecture in combination with a convolution layer to be the most suitable to explore the effects of different pre-processing. During the following experiments, we focused on using different text representation and pre-processing settings. We computed commonly used metrics in classification, including accuracy, AUC score, precision, recall and F1. Interesting is an F1 score as it expresses the harmonic mean of precision and recall and describes the overall performance of the model better. We compared the performance of the model with a standard pre-processed text corpus and without pre-processing (only using simple tokenization). We also decided to compare different text representations, which we described in
Section 4.
In the first step, we explored how the model performs when using the TF-IDF data representation.
Table 7 summarizes the results of the experiments. Basic document vector representation using TF-IDF did not prove to be very suitable for this task. The performance of the model using this representation suffered from poor recall. Although accuracy and AUC values gain reasonable values, those metrics are not very useful in imbalanced classes. To better understand the classifier performance, precision and recall provide better insight. In this case, it is clear that the minor classes failed to learn completely. On the other hand, we can observe that the standard pre-processing improves the classification (contrary to the expectations). In TF-IDF, the pre-processing may improve the created vector representation, as it is created from the corpus itself (not from pre-trained vectors, such embeddings).
Table 8 depicts the BiLSTM + CNN model performance using the word2vec embeddings. In both cases (with and without pre-processing), word2vec representations were trained from the dataset. word2vec representation brings massive improvement in comparison to TF-IDF, rapidly improving the performance metrics (both, micro and macro averaged). The results also demonstrate the influence of the pre-processing techniques applied in text preparation. The model gained slightly better performance on the not processed text, improving recall values (most importantly, macro-averaged recall).
Table 9 summarizes the model performance using pre-trained word embeddings, both with standard text pre-processing and a model with no pre-processing. We used two different GloVe pre-trained embeddings, Common Crawl (840 B tokens, 2.2 M vocab) and Twitter (2 B tweets, 27 B tokens). The model performer very similar using different GloVe and fastText embeddings. Although the averaged F1 metrics are very similar, we can observe some differences, how the models perform on precision and recall metrics. Skipping of the pre-processing in case of the CC GloVe embeddings causes recall drop and improvement of the precision, while in case of the Twitter GloVe embeddings it is otherwise. The difference may be caused by either size of the tokes, or how the embeddings were trained. It is possible that the Twitter embeddings are built using the data closer to the domain (as tweets may be similar to the comments). We used F1 metric to select the best performing model, Twitter GloVe embeddings without pre-processing was the best method from that point of view.
7.3. Selection of Best Transformer Model
Table 10 compares the performance of BERT model, bare BERT and its DistilBERT and XLNet variants. We compared the performance of these models with BiLSTM + CNN architecture. Regarding the pre-processing, it was a little bit different in this case. As the transformer models are available pre-trained on the text corpora in two different versions-cased and uncased (except the XLNet model, that doesn’t come with the uncased version). Furthermore, we used the BERT tokenizer, in which we used lowercasing of the input text (in cased versions) or did not use it (in uncased versions). As described in
Section 6.2, we trained two BERT-base for sequence classification models, two bare BERT-base models, two bare BERT-large models, two DistilBERT models and a single XLNet model. We used default hyper-parameters as depicted in
Table 11.
Table 10 summarizes the model’s performances using the cased and uncased version. We also tried to use a BERT-large version of the BERT sequence classification models, but it is probable that those models were over-fitting in the first epoch and the results were worse than in BERT-base version.
Based on the previous experiment, the BERT-base uncased model provided the best results among the transformer models. Following the initial experiments, we proceed with the fine-tuning of the model. We optimized the values of the hyper-parameters summarized in
Table 12. Optimization of the hyper-parameters did not lead to a significantly improved performance, however, for the combination of the accuracy and AUC metrics, the best combination of hyper-parameters turned out to be the settings: learning rate = 0.00002, batch size = 16, dropout = 0.15. The results of the fine-tuned model are shown in
Table 13. This model also achieved the best micro-averaged F1 metrics.
7.4. Evaluation
From the experiment results with deep learning models, we can consider the GloVe pre-trained embeddings without standard pre-processing as the most suitable representation. The results proved that omitting the traditional pre-processing techniques improve the classification results. This is especially important in the case of macro-averaged metrics, which are more informative in classification tasks with highly imbalanced data. Another important aspect (besides the improvement of the performance metrics) is the demand on resources and computational intensiveness-the pre-processing techniques represent a step in the overall data analysis process and skipping them can reduce the time of the total data preparation phase. On the other hand, pre-processing usually leads to the reduction of the training data dimensionality. When we leave out such a step, we could expect the more resource-demanding training of the models. Another crucial aspect is the deployment of the models in real-world scenarios, where the training time of the model is not essential. In such a case, the ability to process the data and prediction time is essential. Without pre-processing, it is sufficient to create word tokens from the text and apply a trained model to obtain the prediction.
Table 14,
Table 15 and
Table 16 depict the BiLSTM + CNN model (with GloVe Twitter and word2vec embeddings) and bare BERT-base uncased model performance on particular classes. In this task, the class imbalance is present and heavily influences the classification. Minor classes (e.g.,
severe_toxic or
threat) presented a real challenge to learn from the training data. Much better picture about the real quality of the classification into the particular classes is given by the Matthews Correlation Coefficient (MCC) [
64]. When considering this metric, both models perform in a similar fashion. Both models struggle with minor classes, with a model trained using GloVe Twitter embeddings performing better on a
severe_toxic class, while bare BERT handling better the
threat category. For some models (e.g., for BERT), the lack of training samples from minor classes may present a problem, as some of the BERT modifications were not able to learn some of the minor classes at all. Composed architecture with embeddings was able to learn minor classes; however, in both cases, with at least one metric severely lacking. There may be more reasons why most of the models fail to perform well, even in minor classes. For example analysis of the misclassifications revealed possible problems in the labelling of the data, where numerous comments labelled as
toxic did not fall into the proper definition of the toxic comments [
11]. Besides the questionable labelling, which may have influenced the evaluation of the trained patterns, several NLP-related phenomena may influence the classification, e.g., toxic comments written without any explicit language or written in ordinary style, comments containing sarcasm, irony or metaphors which require the deeper understanding of the content.
To further improve the best performing models, we fine-tuned the thresholds used to convert class probabilities to crisp values. The unbalanced number of samples in individual classes can have an impact on the resulting metrics when transforming the probabilities for each class in a similar manner. Therefore, to improve the model, we used optimization to find the best threshold for each class we trained a separate classifier, to find the optimal set of thresholds for the probabilities, specific for each class. We used the optimization implemented in scipy library, selected F1 as an optimization criterion. After then, we computed the overall metrics and metrics for particular classes.
Table 17 and
Table 18 show how the performance metrics improved after fine-tuning of the probability thresholds.
Regarding the interpretability of the trained models, we further explored, how the classifiers performed when predicting the actual class labels. We focused on examination of particular comments, especially those, which were classified correctly in multiple categories and on the other hand, the comments that were misclassified. Many comments were categorized correctly, based on the grammar and language used, e.g., the comment “u are a gigantic faggot” was correctly predicted as toxic, obscene, insult, and identity hate. On the other hand, we observed an inconsistency in comments labelling, which is a frequent issue in many hand-labelled datasets. For example, the comment “Bull... Your mom kicking your ass for not studying is influence of Custom. but then again, without all that comic mischief (such as a dead guy and a crying ilha), life would be pretty fukin boring ...” was predicted by the models as toxic and obscene, because of using an explicit language. However, in the testing data, the comment was assigned just with the toxic label. In similar fashion, a comment “oh, shutup, you douchey Wikipedia rent-a-cop” is clearly an insult and was correctly predicted as toxic and insult, but in the testing data was assigned only with the first label.
7.5. Comparison with Other Models from State-of-the-Art
To compare the models’ performance with other similar approaches presented in the literature, we have to consider several aspects. There are numerous studies, in which authors transformed the Kaggle toxic comments competition dataset labels to the binary values (representing toxic and non-toxic values) and solved the binary classification task of toxicity detection [
35,
65]. On the other hand, when solving the task as a multi-label classification, comparison of these approaches could still be inconsistent, as the evaluation of the models in the literature is not coherent, as multiple studies using different data for evaluation, e.g., a subset of training data (split to 80/20 train/test ratio), or separate labelled testing data, which became available later. Therefore, to compare with the different models, different evaluation of the models had to be implemented. To compare with the results presented in [
11,
36], we needed to compute the averaged precision and recall values for each class (as a separate classification problems, contrary to multi-label evaluation in previous experiments), and then compute the F1 metric. Overall performance of our approach is compared with several similar approaches using the accuracy, precision, recall, F1 score.
Table 19 summarizes the evaluation metrics of the models.
To analyze how well the models perform on a particular class, we compared the results with other similar approaches described in [
66].
Table 20 summarizes and compares our best-performing model with the best performing related models. This time, to be able to compare with the models from the study, we used the accuracy score computed for the specific categories. Please note that the table contains the results presented in one-vs-all approach (e.g., each class compared to the rest of the others), computed from individual confusion matrices for each specific category.
8. Conclusions
In work presented in this paper, we aimed to compare and evaluate different current state-of-the-art models for multi-label toxic comments classification. We experimentally evaluated the performance of deep learning models, including composed architectures with different methods of text representation and pre-processing. On top of that, currently, popular transformer language models, such as BERT and its modifications were compared as well. We aimed to explore the assumption that in tasks such as detection of anti-social behaviour in the online environments, the application of traditional pre-processing techniques could lead to loss of particular specific information characteristic for such behaviour. We aimed to explore the influence of different pre-processing and representation methods on the deep learning and transformer models also in multi-label task aimed to detect the specific type of anti-social behaviour (in this case, toxic comments). We experimentally evaluated composed architecture of BiLSTM + CNN network with different text representations, pre-trained embeddings and compared it with BERT and its variants.
Further evaluation of the various data preparation techniques confirmed the assumption, that in this type of task, using standard pre-processing may lead to influence the classifier performance. When comparing the network performance using different word embeddings, the results showed, that the application of traditional text preparation techniques does not bring any significant benefit in terms of evaluation metrics. When comparing the standard classification performance metrics, we face the problem of the class imbalance. The models often struggle to perform well in the minority classes. If the collection of more samples from such classes is not straightforward, more advanced approaches or using data augmentation techniques may be required. One of the possible strategies could be represented by the hierarchical ensemble model. In such an approach, different classifiers could be combined to either address the specific classes, or even to perform the classification on a different level of target attribute generalization. The particular model then could be used to distinguish between the toxic and non-toxic comments and particular toxicity type prediction could be handled by separate models. The class imbalance could be addressed by various techniques, e.g., weighting schemes in the ensemble.
It is also important to note that the presented comparison was carried out on a single dataset. Another limitation of the study is the use of pre-trained word embeddings and pre-trained transformer language models (except word2vec embeddings). Usually, pre-trained embeddings are build using corpora consisting of standard, clean forms of the words. Such representations do not cover the entire vocabulary used in the abusive comments, which results in the loss of information. In future work, we would like to focus on embedding custom-training for this particular domain. A very similar situation is with transfer learning models. In most of the NLP tasks, those models outperform the deep learning models. Pre-trained models may represent not an ideal solution in this case, and their further re-training may lead to superior results. Another factor is the computational intensiveness of the deep and transformer models training which practically prevents the ultimate comparison of all models, with all pre-processing settings, hyper-parameter fine-tuning using cross-validation technique. In our experiments, we decided to evaluate the models’ performance using standard, commonly used settings, then fine-tune the hyper-parameters of the best-performing architecture using grid search on sampled data. Similarly, we assumed the learning variance during the initial experiment using 10-fold cross-validation and did not perform the cross-validation of an entire set of pre-processing experiments, which would result in extreme time and resource-consuming setup.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}