A Framework for Identifying Influential People by Analyzing Social Media Data

 ,
,  ,
,  ,
,  and
and 
Abstract
:1. Introduction
1.1. Background
1.2. Motivation
- the large data set storage problem and
- the large data set processing problem.
1.3. Problem Statement
1.4. Contributions
- We develop a mechanism to identify influential people.
- We use an efficient method to store and process large data.
- We effectively apply the skyline query and top-k query to handle Facebook data.
1.5. Organization of the Paper
2. Related Work and Discussion
2.1. Work Related to Social Networks
2.2. Work Related to Apache Spark
2.3. Work Related to Skyline Query
2.4. Work Related to the Top-k Query
3. The Proposed Methodology on Selecting Influential People
3.1. Dataset Description
3.2. Performance Metrics
3.2.1. Friend Score ()
3.2.2. Follower Score ()
3.2.3. Reaction Score ()
3.2.4. Comment Score ()
3.2.5. Group Score ()
3.2.6. Share Score ()
3.2.7. Pages Liked Score ()
3.2.8. Check-in Score ()
3.2.9. Mention Score ()
3.2.10. Event Score ()
3.3. Table Construction
| Algorithm 1 Friend score calculation. |
|
| Algorithm 2 Group score calculation. |
|
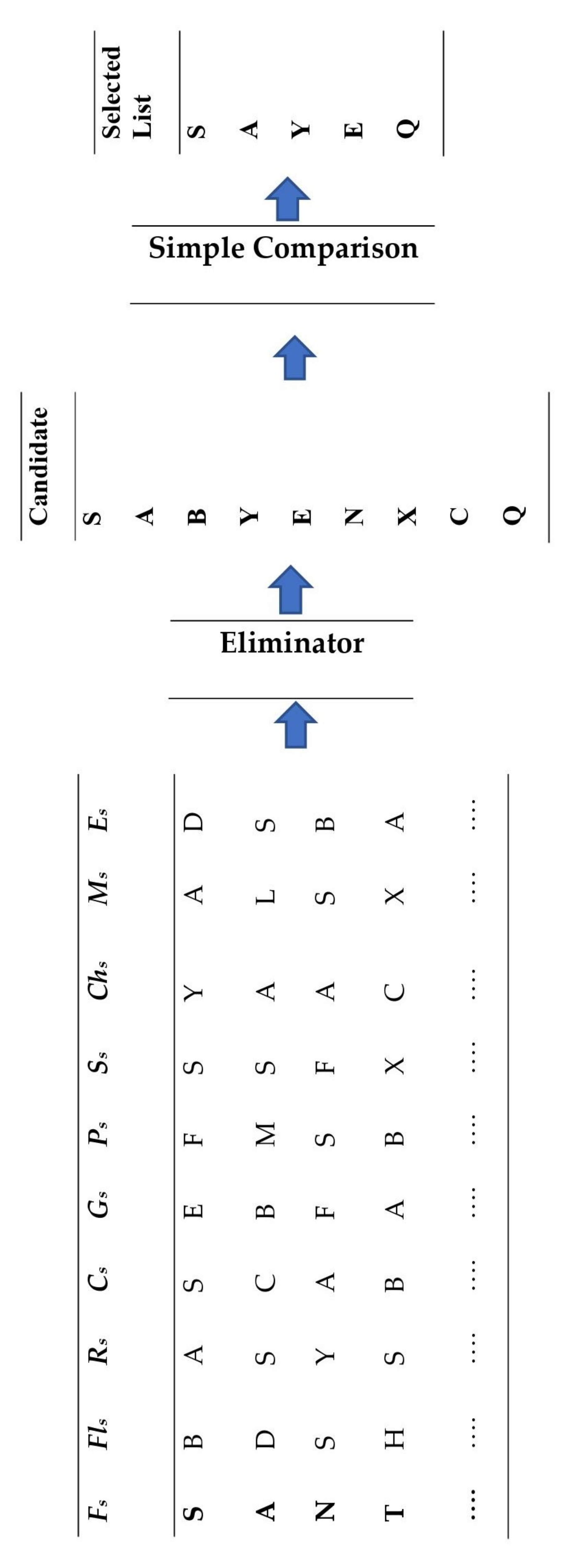
3.4. Influential People Selection
3.4.1. Skyline Query
3.4.2. Top-k Query
- Compute the total score by adding all the attribute values (given in Table 9) using the SQL query in PySpark.
- Sort all user IDs based on their scores in descending order.
- Return the first k highest scored user IDs.
4. Experiments and Performance Evaluation
4.1. Experiment Setup
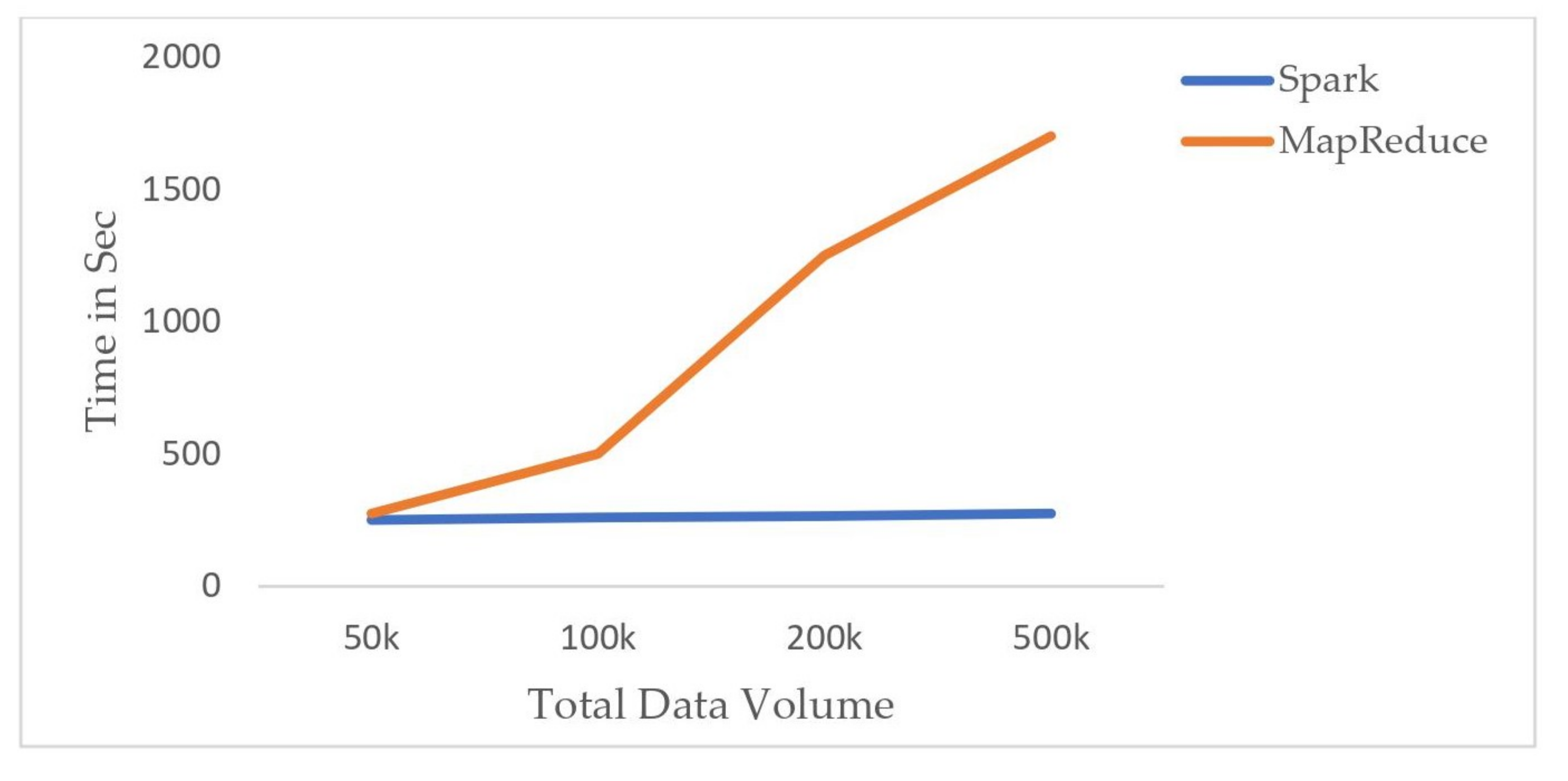
4.2. Performance on Score Calculation
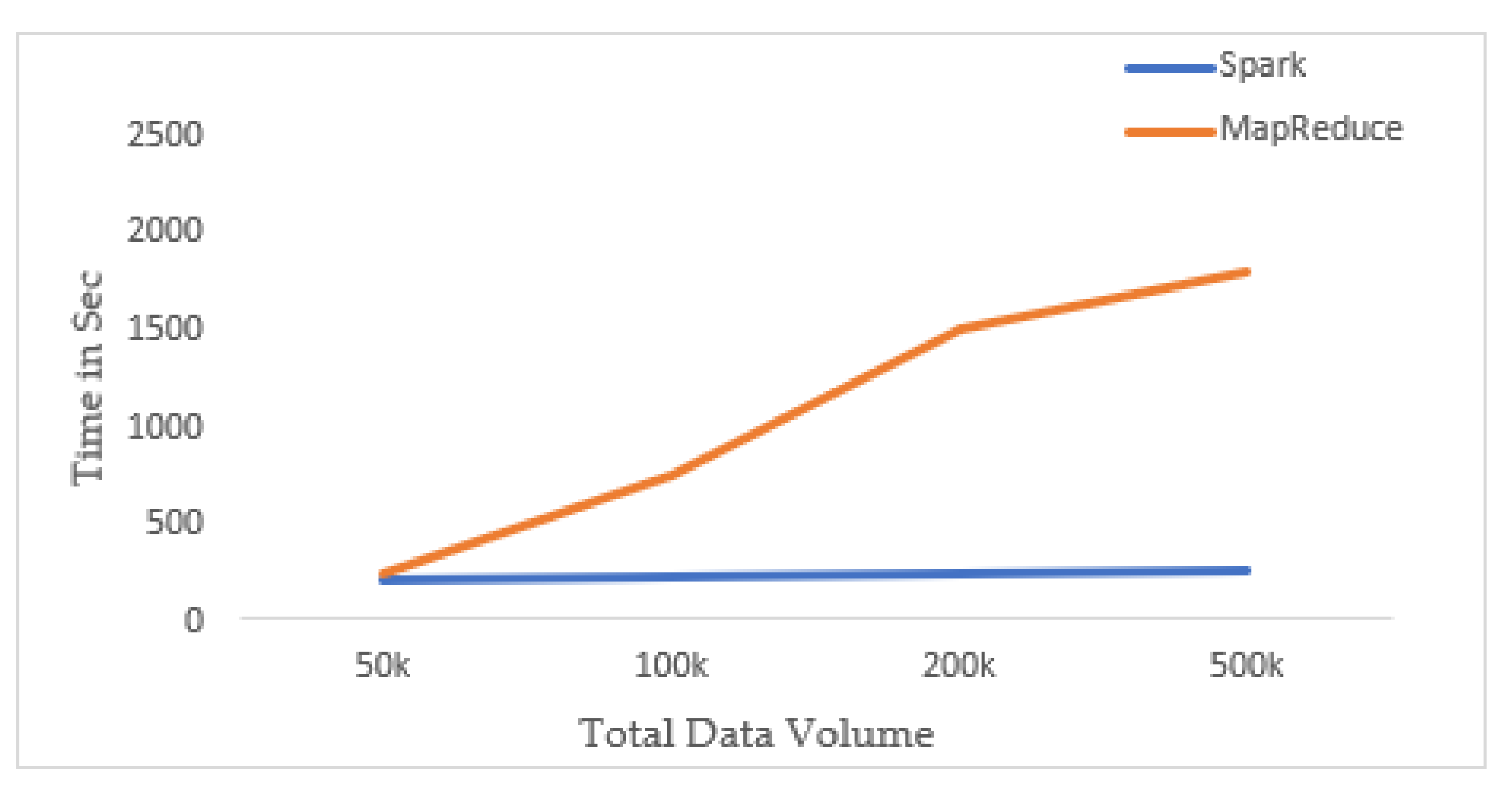
4.3. Performance on Skyline Queries
4.4. Effect of New Metrics in Skyline Computation
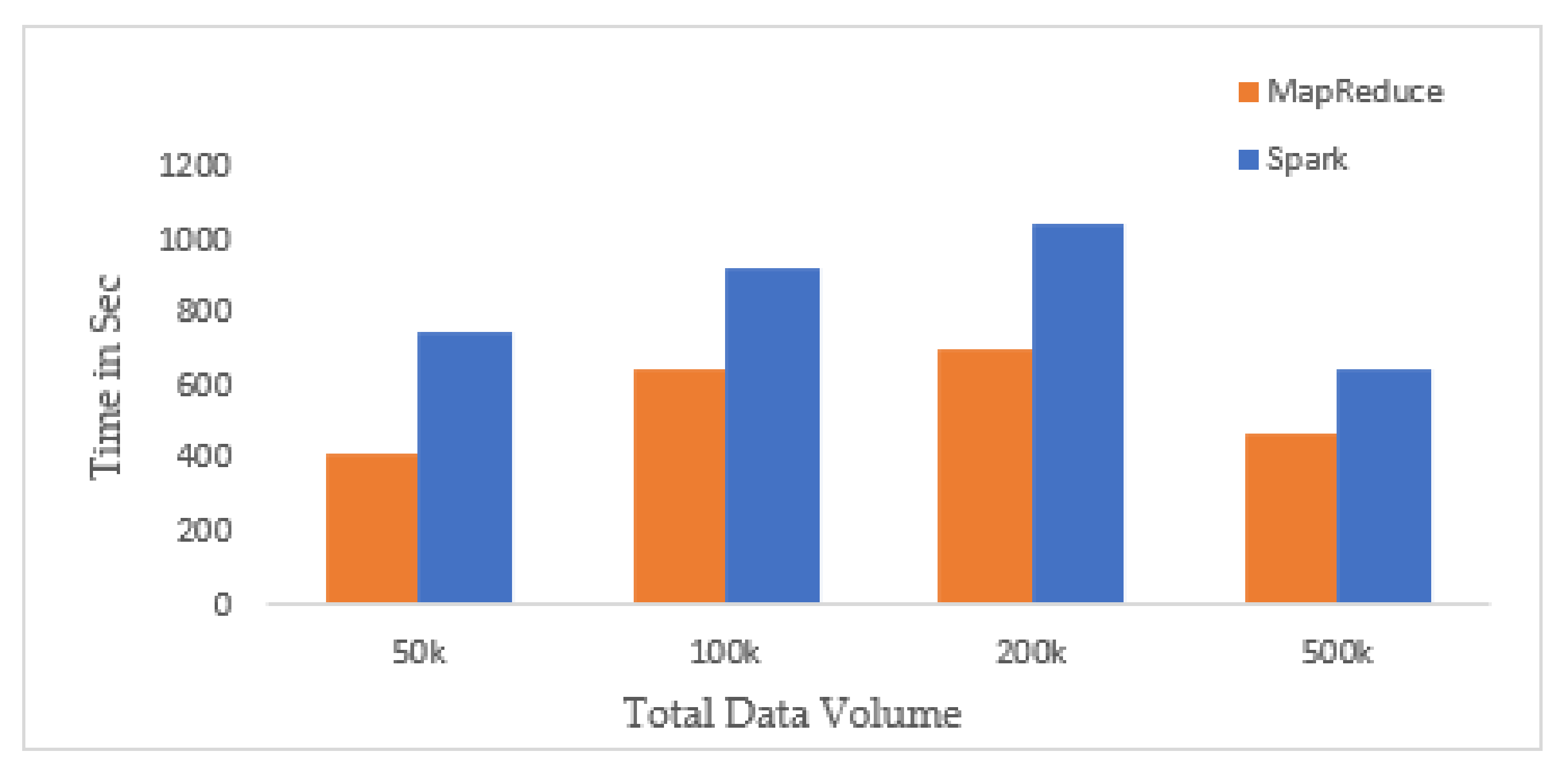
4.5. Performance on Top-k Queries
5. Conclusions and Future Research Directions
Author Contributions
Funding
Conflicts of Interest
References
- Mahbub, S.; Pardede, E.; Kayes, A.; Rahayu, W. Controlling astroturfing on the internet: A survey on detection techniques and research challenges. Int. J. Web Grid Serv. 2019, 15, 139–158. [Google Scholar] [CrossRef]
- Lu, L.; Dong, H.; Yang, C.; Wan, L. A novel mass data processing framework based on Hadoop for electrical power monitoring system. In Proceedings of the 2012 Asia-Pacific Power and Energy Engineering Conference, Shanghai, China, 27–29 March 2012; pp. 1–4. [Google Scholar]
- Tu, D.Q.; Kayes, A.; Rahayu, W.; Nguyen, K. IoT streaming data integration from multiple sources. Computing 2020, 102, 2299–2329. [Google Scholar] [CrossRef]
- Apache Hadoop. Available online: https://Hadoop.Apache.org/ (accessed on 1 October 2020).
- Shvachko, K.; Kuang, H.; Radia, S.; Chansler, R. The Hadoop distributed file system. In Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST2010), Incline Village, NV, USA, 3–7 May 2010. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. In Proceedings of the OSDI 2004—6th Symposium on Operating Systems Design and Implementation, San Francisco, CA, USA, 6–8 December 2004; pp. 137–149. [Google Scholar] [CrossRef] [Green Version]
- Tu, D.Q.; Kayes, A.; Rahayu, W.; Nguyen, K. ISDI: A new window-based framework for integrating IoT streaming data from multiple sources. In Proceedings of the International Conference on Advanced Information Networking and Applications, Matsue, Japan, 27–29 March 2019; Springer: Berlin, Germany, 2019; pp. 498–511. [Google Scholar]
- Doan, Q.T.; Kayes, A.; Rahayu, W.; Nguyen, K. Integration of IoT Streaming Data With Efficient Indexing and Storage Optimization. IEEE Access 2020, 8, 47456–47467. [Google Scholar] [CrossRef]
- Sarker, I.H.; Kayes, A.; Badsha, S.; Alqahtani, H.; Watters, P.; Ng, A. Cybersecurity data science: An overview from machine learning perspective. J. Big Data 2020, 7, 1–29. [Google Scholar] [CrossRef]
- Apache Spark™—What is Spark. Available online: https://databricks.com/Spark/about (accessed on 1 October 2020).
- Apache Spark™—Unified Analytics Engine for Big Data. Available online: https://Spark.Apache.org/ (accessed on 1 October 2020).
- Zaman, A.; Siddique, M.A.; Morimoto, Y. Finding Key Persons on Social Media by Using MapReduce Skyline. Int. J. Netw. Comput. 2017, 7, 86–104. [Google Scholar] [CrossRef] [Green Version]
- Qiu, J.; Tang, J.; Ma, H.; Dong, Y.; Wang, K.; Tang, J. DeepInf: Social influence prediction with deep learning. In Proceedings of the Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018; pp. 2110–2119. [Google Scholar] [CrossRef] [Green Version]
- Cao, C.C.; Shej, J.; Tong, Y.; Chen, L. Whom to ask? Jury selection for decision making tasks on micro-blog services. Proc. VLDB Endow. 2012, 5, 1495–1506. [Google Scholar] [CrossRef]
- Demartini, G.; Gaugaz, J.; Nejdl, W. A vector space model for ranking entities and its application to expert search. In European Conference on Information Retrieval; Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5478 LNCS, pp. 189–201. [Google Scholar] [CrossRef]
- Lappas, T.; Liu, K.; Terzi, E. Finding a team of experts in social networks. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 467–475. [Google Scholar] [CrossRef] [Green Version]
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster computing with working sets. In Proceedings of the 2nd USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 2010), Boston, MA, USA, 22 June 2010. [Google Scholar]
- Gopalani, S.; Arora, R. Comparing Apache Spark and Map Reduce with Performance Analysis using K-Means. Int. J. Comput. Appl. 2015, 113, 8–11. [Google Scholar] [CrossRef]
- Meng, X.; Bradley, J.; Yavuz, B.; Sparks, E.; Venkataraman, S.; Liu, D.; Freeman, J.; Tsai, D.B.; Amde, M.; Owen, S.; et al. MLlib: Machine learning in Apache Spark. J. Mach. Learn. Res. 2016, 17, 1235–1241. [Google Scholar]
- Gupta, A.; Thakur, H.K.; Shrivastava, R.; Kumar, P.; Nag, S. A Big Data Analysis Framework Using Apache Spark and Deep Learning. In Proceedings of the IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 9–16. [Google Scholar] [CrossRef] [Green Version]
- Nair, L.R.; Shetty, S.D. Streaming twitter data analysis using Spark for effective job search. J. Theor. Appl. Inf. Technol. 2015, 80, 349–353. [Google Scholar]
- Bentley, J.L.; Kung, H.T.; Schkolnick, M.; Thompson, C.D. On the Average Number of Maxima in a Set of Vectors and Applications. J. ACM (JACM) 1978, 25, 536–543. [Google Scholar] [CrossRef] [Green Version]
- Kung, H.T.; Luccio, F.; Preparata, F.P. On Finding the Maxima of a Set of Vectors. J. ACM (JACM) 1975, 22, 469–476. [Google Scholar] [CrossRef]
- Borzsonyil, S.; Kossmann, D.; Stocker, K. The Skyline Operator. In Proceedings of the 17th International Conference on Data Engineering, Heidelberg, Germany, 2–6 April 2001; pp. 421–430. [Google Scholar]
- Street, K.; York, N.; Canada, O.M.J. Skyline with Presorting Jan Chomicki, Parke Godfrey, Jarek Gryz and Dongming Liang; Department of Computer Science, York University: York, UK, October 2002. [Google Scholar]
- Tan, K.L.; Eng, P.K.; Ooi, B.C. Efficient progressive skyline computation. In Proceedings of the VLDB 2001—Proceedings of 27th International Conference on Very Large Data Bases, Roma, Italy, 11–14 September 2001; pp. 301–310. [Google Scholar]
- Chan, C.Y.; Jagadish, H.V.; Tan, K.L.; Tung, A.K.; Zhang, Z. Finding k-dominant skylines in high dimensional space. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Chicago, IL, USA, 27–29 June 2006; pp. 503–514. [Google Scholar] [CrossRef]
- Balke, W.T.; Güntzer, U.; Zheng, J.X. Efficient distributed skylining for web information systems. Lect. Notes Comput. Sci. (Incl. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.) 2004, 2992, 256–273. [Google Scholar] [CrossRef] [Green Version]
- Marian, A.; Bruno, N.; Gravano, L. Evaluating top-k queries over web-accessible databases. ACM Trans. Database Syst. 2004. [Google Scholar] [CrossRef] [Green Version]
- Chang, K.C.C.; Hwang, S.W. Minimal probing: Supporting expensive predicates for top-K queries. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Madison, WI, USA, 3–6 June 2002; pp. 346–357. [Google Scholar]
- Li, C.; Chang, K.C.C.; Ilyas, I.F.; Song, S. RankSQL: Query algebra and optimization for relational top-k queries. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Baltimore, MA, USA, 14–16 June 2005; pp. 131–142. [Google Scholar]
- Chaudhuri, S.; Gravano, L. Evaluating Top-k Selection Queries. Vldb 1999, 1, 397–410. [Google Scholar]
- Donjerkovic, D.; Ramakrishnan, R. Probabilistic Optimization of Top N Queries. Int. Conf. Very Large Databases (VLDB) 1999, 1, 411–422. [Google Scholar]
- PySpark. Available online: https://Spark.Apache.org/docs/2.1.0/api/python/PySpark.html (accessed on 1 October 2020).
- Pang, B.; Lee, L. Opinion mining and sentiment analysis. Found. Trends Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef] [Green Version]
- Cron Job. Available online: https://en.wikipedia.org/wiki/Cron (accessed on 1 October 2020).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
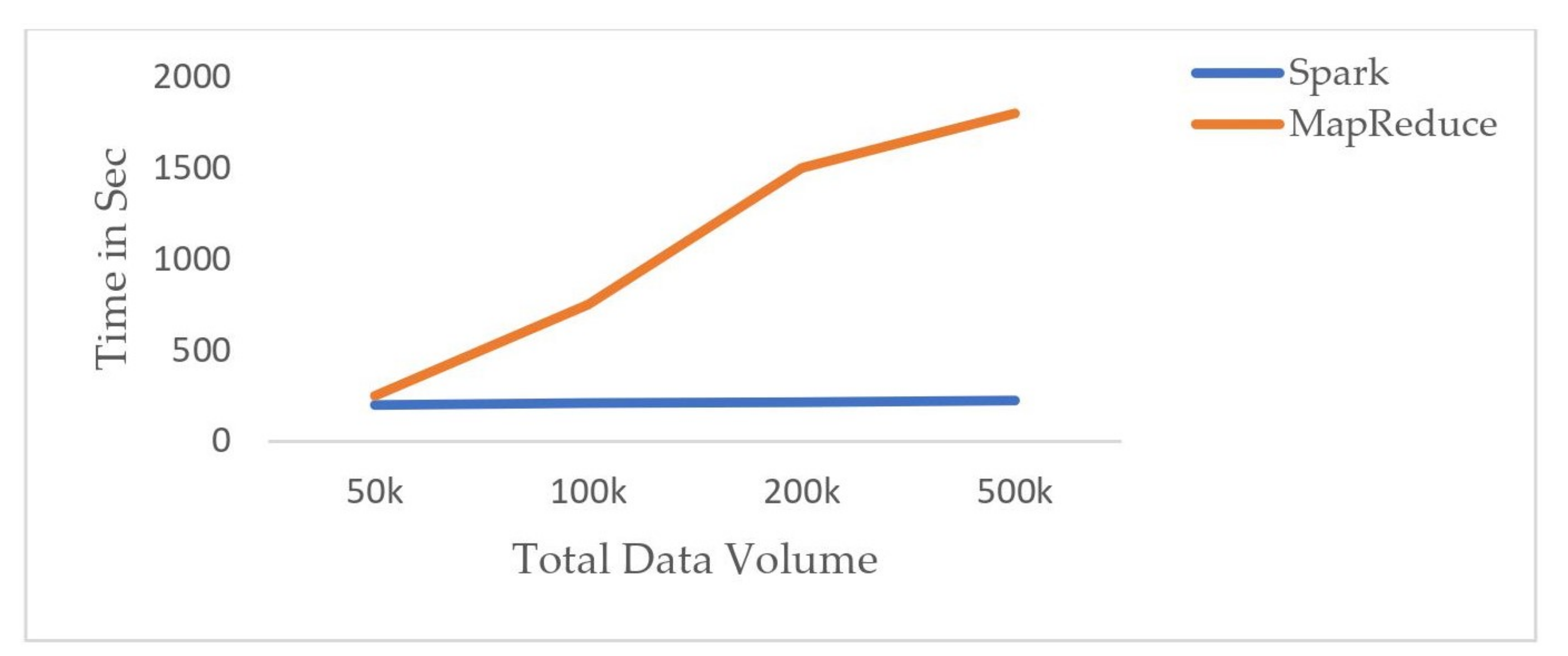{kind=link}
| User ID | Friends | Followers | Reactions | Comments | Groups | Shares | Pages Liked | Check-ins | Mentioned by | Events Attended |
|---|---|---|---|---|---|---|---|---|---|---|
| A | U, V, X, Z, …. | S, D, R, Y, …. | (1, T), (3, I), .... | (3, Z, Comment5), (6, E, Comment4), …. | G1, G3, G5, …. | (1,E), (8, C), …. | P1, P2, P3, …. | C1, C2, C5, …. | (B, 6), (M, 7), …. | E1, E2, …. |
| B | C, M, L, S, … | S, P, W, X, …. | (2, F), (9, C), …. | (5, E, Comment9), (2, P, Comment3), …. | G3, G7, G9, …. | (2, F), (3, D), …. | P8, P5, P7, …. | C3, C5, C9, …. | (E, 2), (C, 5), …. | E3, E5, …. |
| C | A, C, Y, U, I, … | M, J, K, L, …. | (16, I), (21, J), …. | (7, A, Comment8), (1, F, Comment2), …. | G12, G15, G19, …. | (7, S), (5, N), …. | P2, P4, P7, …. | C1, C9, C11, …. | (A, 12), (B, 17), …. | E4, E6, …. |
| D | M, K, S, O, P, … | P, W, T, I, …. | (1, E), (8, M), …. | (9, R, Comment7), (4, I, Comment12), …. | G2, G4, G6, …. | (11, I), (4, X), …. | P5, P6, P9, …. | C12, C19, C21, …. | (R, 2), (V, 9), …. | E7, E9, …. |
| … | ….. | …… | ….. | ……. | ……. | ……. | …. | …. | ….. | …... |
| Group | Total Members | Members Added the Last 7 Days | Total Posts Last 30 Days |
|---|---|---|---|
| G1 | 1270 | E,F,G.. | 200 |
| G2 | 2100 | D,E,F.. | 134 |
| G3 | 1700 | M,N,O.. | 305 |
| … | ….. | …. | ….. |
| Page | Followers | Comments | Reviews |
|---|---|---|---|
| P1 | A,B,C… | (5,Q,Comment1)… | (R,4)… |
| P2 | A,C,E… | (2,P,Comment3)… | (S,5)… |
| P3 | L,M,P…. | (1,T,Comment9)… | (U,3)… |
| …. | ….. | ….. | ….. |
| Place | Followers | Comments | Reviews |
|---|---|---|---|
| C1 | B,C,D… | (9,S,Comment2)… | (Q,5)… |
| C2 | W,E,R… | (7,E,Comment1)… | (A.3)… |
| C3 | T,Y,U…. | (3,Q,Comment5)… | (C,5)… |
| …. | ….. | ….. | ….. |
| Event | Going | Interested |
|---|---|---|
| E1 | 180 | 350 |
| E2 | 305 | 751 |
| E3 | 200 | 500 |
| … | ….. | …… |
| Considered Metrics | Symbols |
|---|---|
| Friend Score | |
| Follower Score | |
| Reaction Score | |
| Comment Score | |
| Group Score | |
| Share Score | |
| Pages Liked Score | |
| Check-in Score | |
| Mention Score | |
| Event Score |
| User ID | Friends |
|---|---|
| A | U,V,X,Z,…. |
| B | C,M,L,S,… |
| C | A,C,Y,U,… |
| D | M,K,S,O,… |
| .... | ...... |
| User ID | Groups |
|---|---|
| A | G1,G3,G5,…. |
| B | G3,G7,G9,…. |
| C | G12,G15,G19,…. |
| D | G2,G4,G6,…. |
| .... | ...... |
| User ID | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| A | 1002 | 200 | 103 | 200 | 302 | 409 | 70 | 54 | 19 | 7 |
| B | 905 | 125 | 95 | 120 | 504 | 206 | 90 | 65 | 12 | 9 |
| C | 507 | 50 | 53 | 75 | 210 | 115 | 105 | 43 | 20 | 5 |
| D | 1506 | 500 | 150 | 240 | 270 | 101 | 320 | 29 | 45 | 11 |
| ….. | ….. | ….. | ….. | ….. | ….. | ….. | ….. | ….. | ….. | ….. |
| User ID | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| S | 701 | 305 | 80 | 107 | 192 | 446 | 92 | 60 | 28 | 11 |
| A | 1002 | 200 | 103 | 200 | 302 | 409 | 70 | 54 | 19 | 14 |
| B | 905 | 125 | 95 | 120 | 504 | 206 | 90 | 65 | 12 | 9 |
| Y | 1501 | 550 | 152 | 243 | 267 | 103 | 229 | 49 | 55 | 15 |
| E | 1056 | 210 | 109 | 254 | 304 | 550 | 96 | 65 | 67 | 12 |
| N | 654 | 120 | 19 | 63 | 113 | 90 | 65 | 38 | 4 | 1 |
| X | 700 | 99 | 40 | 45 | 101 | 112 | 70 | 56 | 8 | 2 |
| C | 507 | 50 | 53 | 75 | 210 | 115 | 105 | 43 | 20 | 5 |
| Q | 877 | 376 | 40 | 83 | 120 | 154 | 68 | 44 | 29 | 6 |
| User ID | Influential Score |
|---|---|
| S | 9006 |
| G | 8987 |
| J | 8970 |
| H | 8901 |
| L | 8890 |
| T | 8889 |
| K | 8850 |
| M | 8820 |
| Z | 8809 |
| X | 8805 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahsan, M.S.A.; Arefin, M.S.; Kayes, A.S.M.; Hammoudeh, M.; Aldabbas, O. A Framework for Identifying Influential People by Analyzing Social Media Data. Appl. Sci. 2020, 10, 8773. https://doi.org/10.3390/app10248773
Ahsan MSA, Arefin MS, Kayes ASM, Hammoudeh M, Aldabbas O. A Framework for Identifying Influential People by Analyzing Social Media Data. Applied Sciences. 2020; 10(24):8773. https://doi.org/10.3390/app10248773
Chicago/Turabian StyleAhsan, Md. Sabbir Al, Mohammad Shamsul Arefin, A. S. M. Kayes, Mohammad Hammoudeh, and Omar Aldabbas. 2020. "A Framework for Identifying Influential People by Analyzing Social Media Data" Applied Sciences 10, no. 24: 8773. https://doi.org/10.3390/app10248773
APA StyleAhsan, M. S. A., Arefin, M. S., Kayes, A. S. M., Hammoudeh, M., & Aldabbas, O. (2020). A Framework for Identifying Influential People by Analyzing Social Media Data. Applied Sciences, 10(24), 8773. https://doi.org/10.3390/app10248773