Development of Cost and Schedule Data Integration Algorithm Based on Big Data Technology



Abstract
:1. Introduction
2. Literature Review
2.1. Current Status of Cost and Schedule Integration
2.2. Challenges in Cost and Schedule Integration
2.3. Cost and Schedule Integration Models
2.4. Big Data Technology in Construction Project
3. Cost-Schedule Integration and Big Data Technology
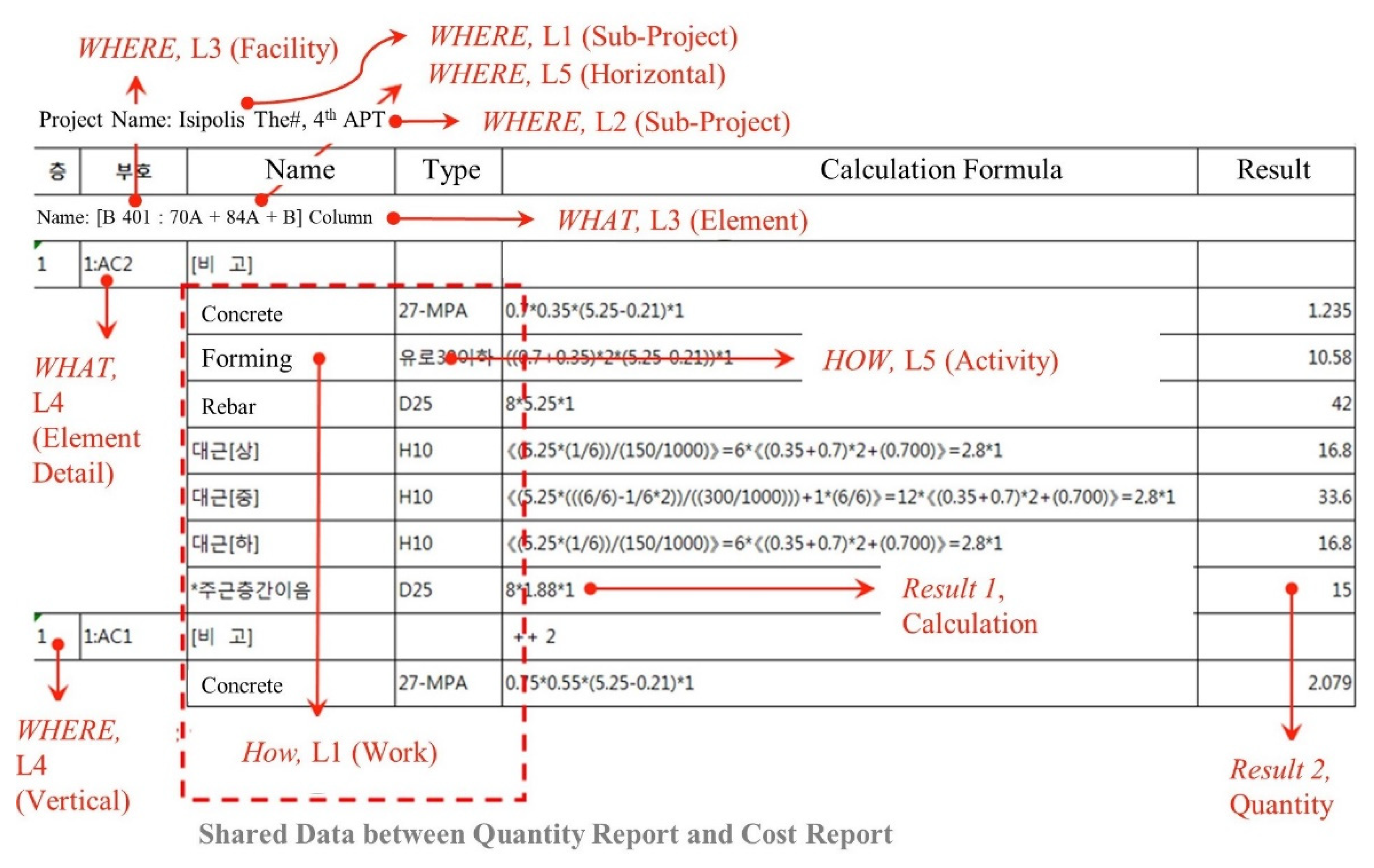
3.1. Characteristics of Cost and Schedule Data
- Mismatched level of cost and schedule data: As addressed in Section 2.2, cost data and schedule data in construction projects consist of different information units at different LODs that are mismatched to each other [8]. In practice, schedules at various levels are created and utilized, such as overall schedules, monthly schedules, weekly schedules, and subcontractor schedules. Each of them requires cost assignment and aggregation at the appropriate level for corresponding the activity levels addressed in the schedule. To support it, the database structure needs to be flexible to various schedules; it is essential for achieving data consistency in the integrated management of project cost and schedule.
- A vast amount of data: For cost-schedule integrated management, multiple dimensional data for construction projects need to be defined as lowest-level information units. The dimensions cover unit quantities of materials, spaces, building elements, activities, organization, and time. Each dimension contains multiple levels, and activity data associated with quantities needs to be connected to unit and unit pricing (unit material, unit labor, unit equipment). According to the authors’ case studies, around 10 million building elements exist in a 90-million-dollar building project located in Korea, such as structure, envelope, fire safety, mechanical, electrical, and plumbing. Each element needs to be decomposed into lowest-level information units and linked to (1) space data (project, section, floor, zone, room); (2) activity data (i.e., forming, reinforcing, concrete curing); (3) working organization data (subcontractors, crew); (4) management organization data (contractors, management team, manager, construction manager); (5) time data (year, quarter, month, week, day); and (6) unit pricing data. The level of data decomposition can vary according to the required information level and management level. However, it has been identified that approximately one billion data cells should be prepared for achieving high data consistency for cost-schedule integrated management.
- Variable data: The lowest-level information units are generated while operating a construction project. They are updated from time to time as design, construction methods, material, pricing, or contracts change. These updates need to be reflected in the database for cost-schedule integrated management in order to keep data integrity.
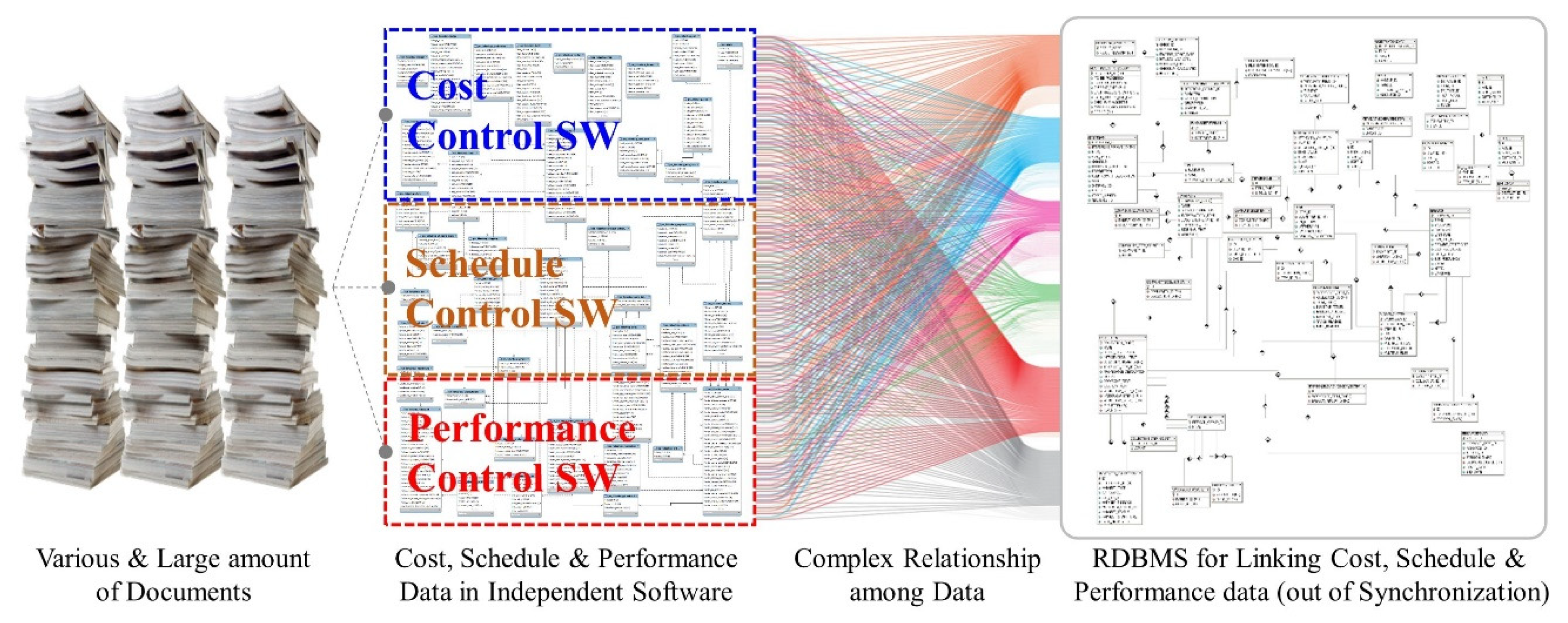
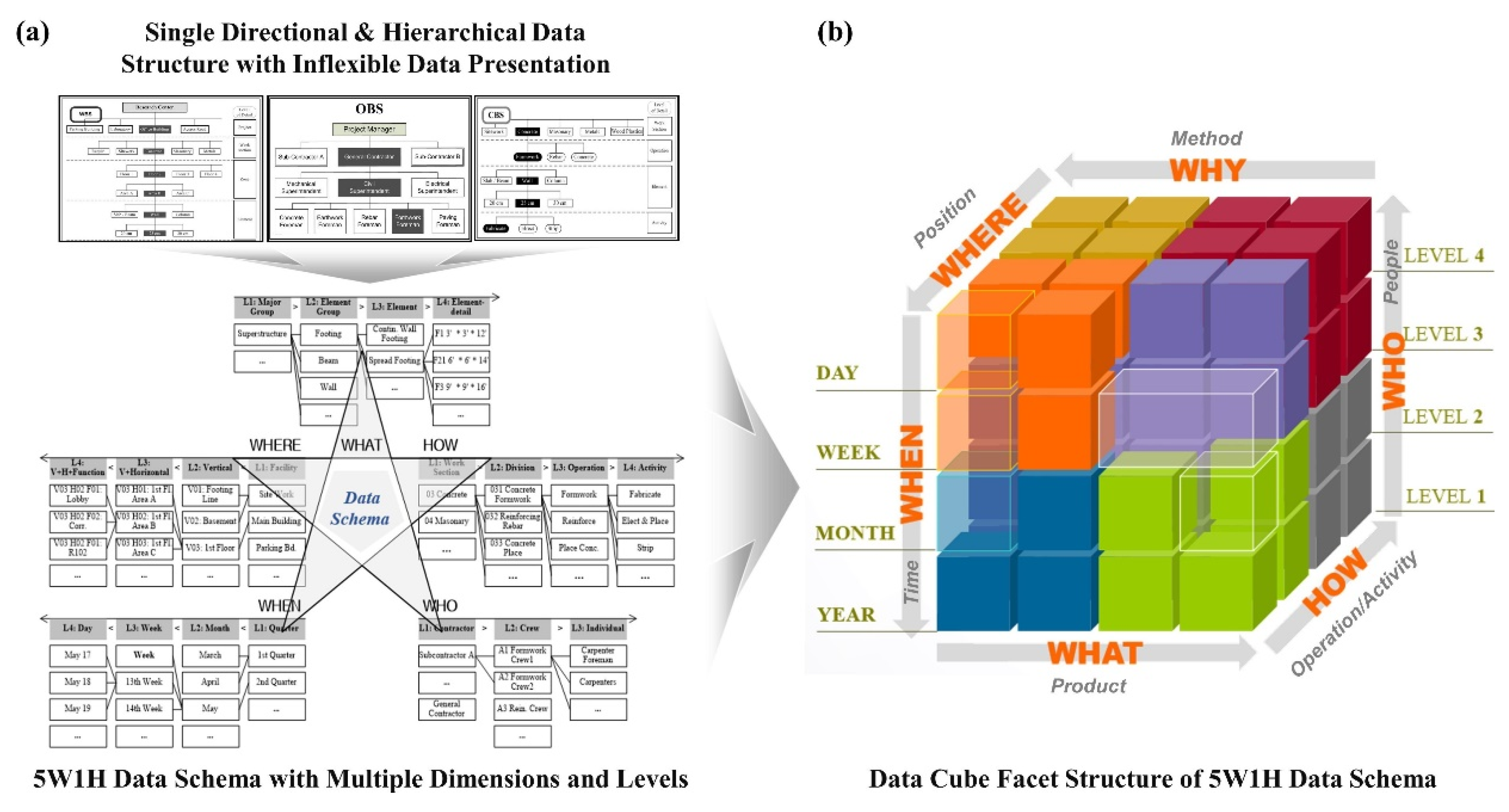
- Complicated data structure: There have been efforts to establish databases for lowest-level information units using WBS, CBS, and OBS. The hierarchical approaches in existing studies are not sufficient to incorporate required data at all levels from all dimensions and show limitations in providing enough flexibility and connectivity of data for cost-schedule integration. Consequently, the limited flexibility results in an enormous amount of lower data created by data decomposition at a higher level, which causes challenges in information management.
- Semantic issues: The existing methods utilized construction classification standards and their codes for data standardization as well as data mining. Key data represented as a complicated combination of codes hinder intuitive understanding and communication of the data. From the technical perspective, these methods rely on a database to store and manage the codes, whose establishment requires significant time and effort. The specialized software and administrative information management procedures for database operation require significant installation and maintenance costs. These requirements and the nonintuitive codes have obstructed the active introduction of cost-schedule integrated management.
3.2. Feasibility of Big Data Technology on Cost-Schedule Integration
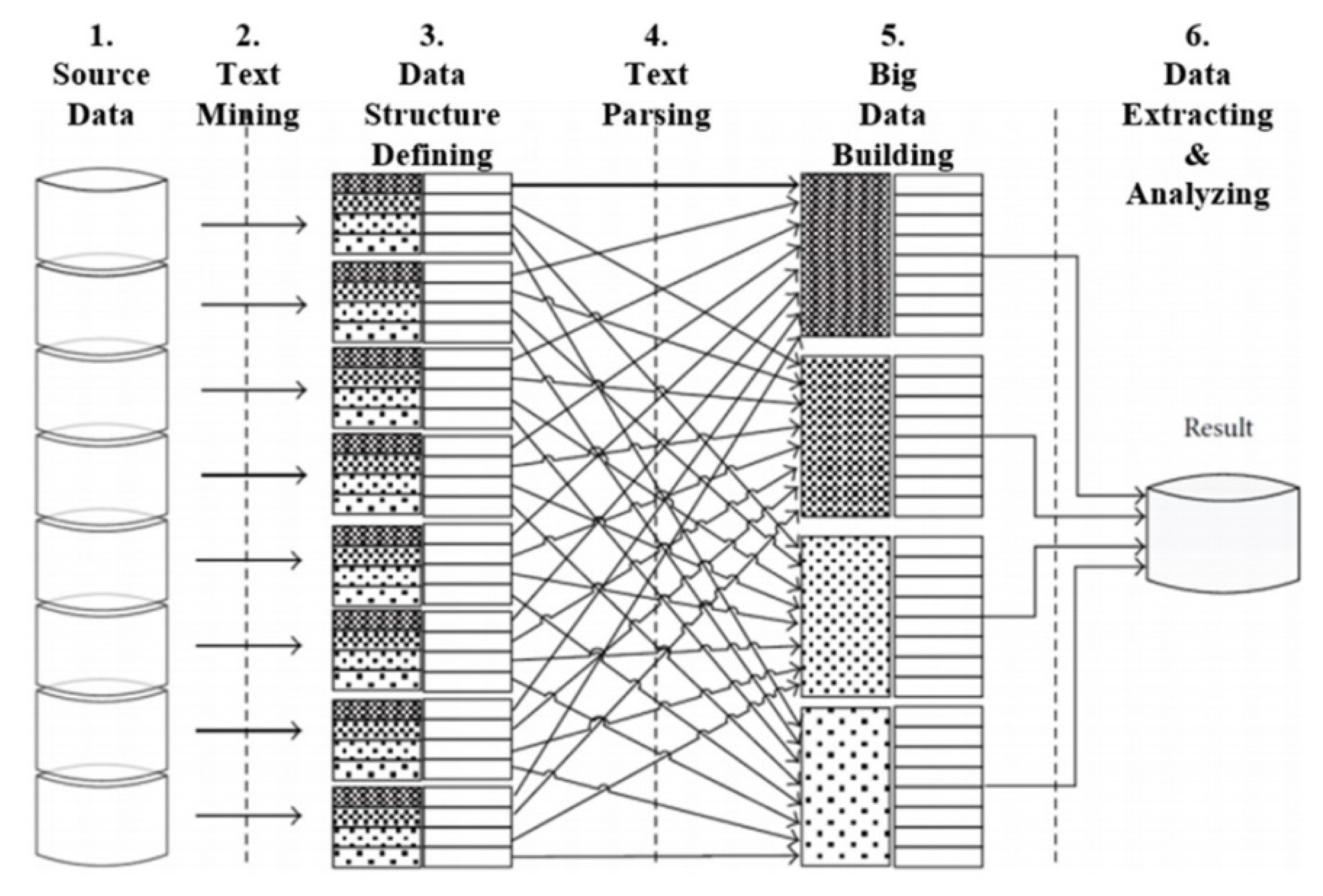
- As discussed in Section 3.1, the cost-schedule data is vast and created in different forms by different stakeholders in construction projects. Data including quantity, cost, schedule, payment, material, and labor are generated in varied formats (i.e., quantity calculation, bill of quantities, schedules) for multiple purposes and changed as the project proceeds. The 4Vs of big data clearly explain vital attributes of construction data, which is large, heterogeneous, and dynamic with value in decision making [25]. Big data technology can be regarded as a suitable method to integrate and manage the ‘big’ cost-schedule data in construction management.
- The data accumulated in construction firms are mostly associated with financial and schedule management. According to the survey with 89 firms in Korea in 2014, 76% and 49% of them have stored cost-related data and schedule-related data, respectively [26]. It infers that the available data for cost-schedule integration is accessible and easy to collect.
- The technical level of handling big data can be categorized according to a data structure (i.e., structured, semi-structured, unstructured), data type (i.e., text, log, sensor, image), data format (i.e., RDB, HTML, XML, Json). Most of the cost-schedule data is structured text data in document format; it facilitates data processing, transmission, storage, and evaluation. Technology for collecting, storing, analyzing, and visualizing data has been developed rapidly and published as open-source packages. The high accessibility of technology and the low difficulty in handling cost-schedule data indicate the possibility of the active application of big data technology to the integrated management of cost-schedule.
- Big data technology, which enhances the accuracy of analysis and prediction, is ideal for engineering analysis, including construction engineering [27]. From a statistical perspective, big data infer the patterns within a population using random sampling. The sampling technique is useful for analyzing limited data size, especially overcoming challenges in collecting and processing data; however, it might have the disadvantage of the overfitted prediction to sample, which leads to the failure to capture real patterns of the population.
3.3. Requirements for Cost-Schedule Integration
- Data integrity and flexibility: the integrity of lowest-level information units for cost and schedule data is fundamental for addressing mismatched information levels between them. It is essential to build a flexible data structure to accommodate various information units at different LODs from multiple dimensions. It should allow data decomposition and aggregation in response to purposes of construction management, including quantity, cost, schedule, productivity, labor, periodic payment, and material of construction projects.
- Efficiency in establishing and transforming data: The enormous time and effort required to develop the integrated database of cost and schedule data play a role as the root cause of the failure to adopt existing models in practice. A novel approach for efficiently and cost-effectively establishing and updating a database as projects proceed is necessary for its wide application in practice.
- Practicability: the new method needs to support a range of data extraction and analysis for practical cost and schedule control, and it should be easy to use for practitioners. In addition, the method should be fit for the work process and documentation in construction projects. The adoption of new technologies changes not only work activities but also work paradigm, including work processes, collaboration methods, information and administrative activities, working knowledge, and organization networks [28]. In this context, the new method should reflect sufficiently current construction management practices to minimize the changes to minimize practitioners’ hesitation to use.
4. Big Data Algorithm for Integrated Cost-Schedule Data Management
4.1. Data Structure for Cost-Schedule Integration
4.2. Three Principles for Cost-Schedule Integration Algorithm
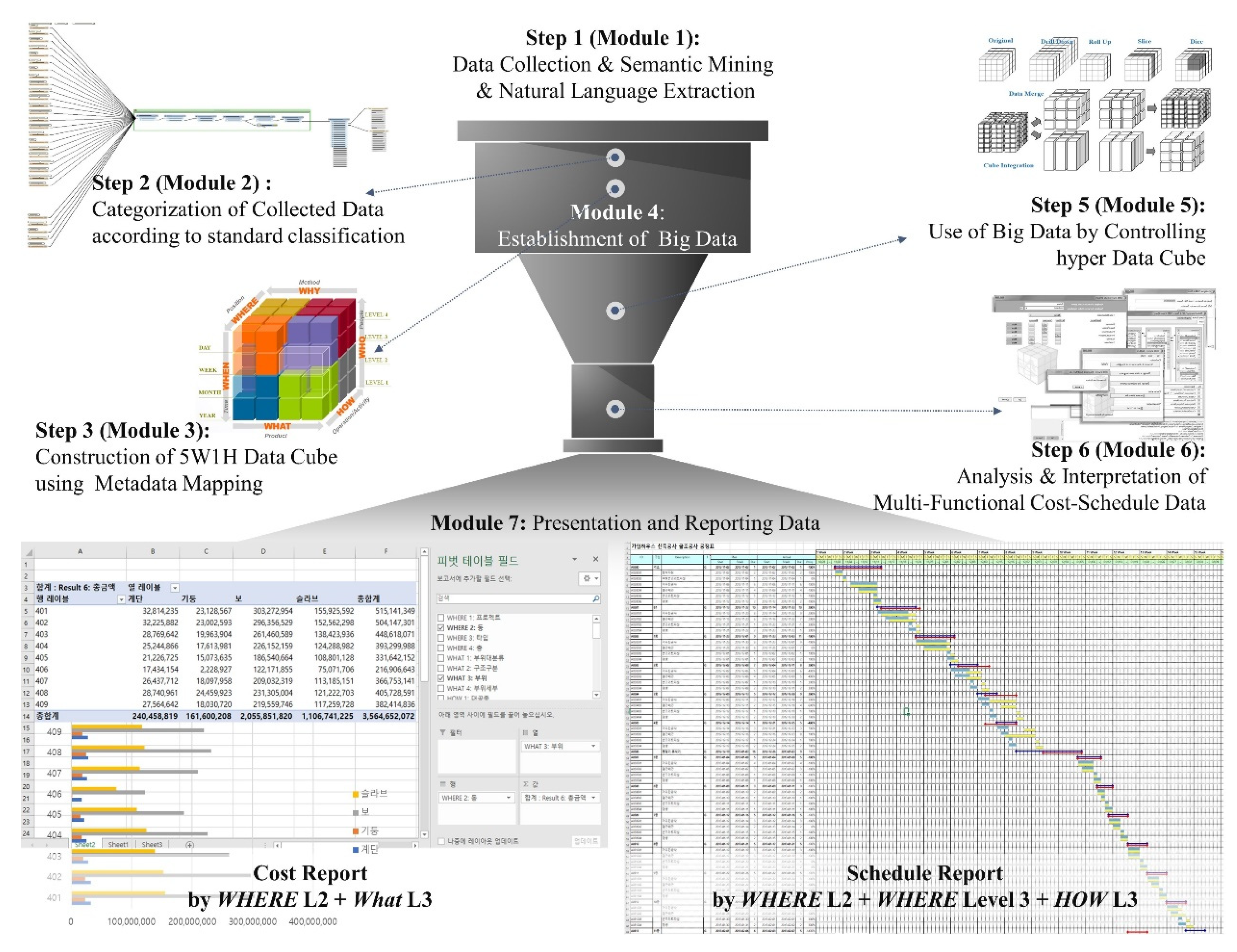
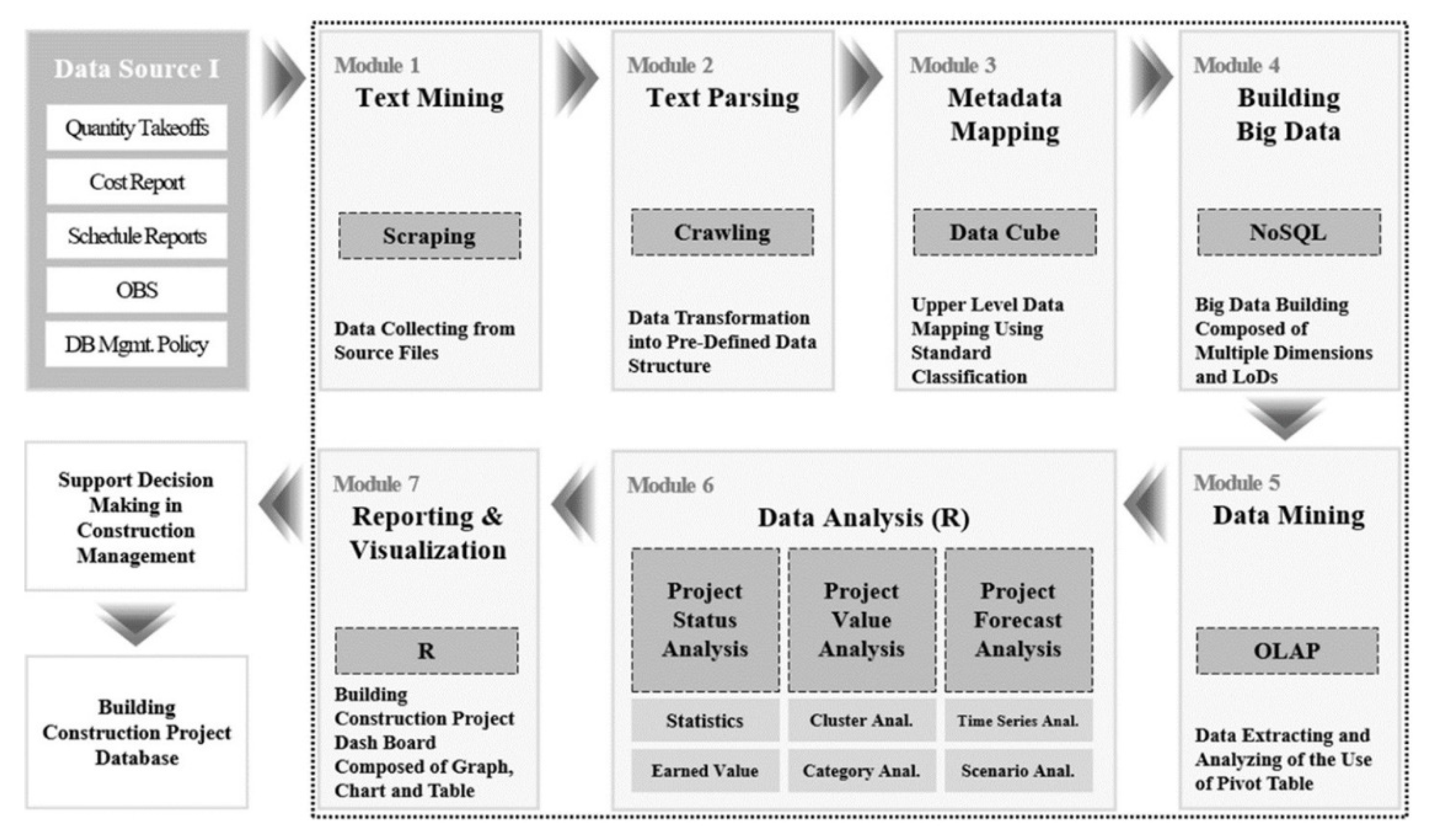
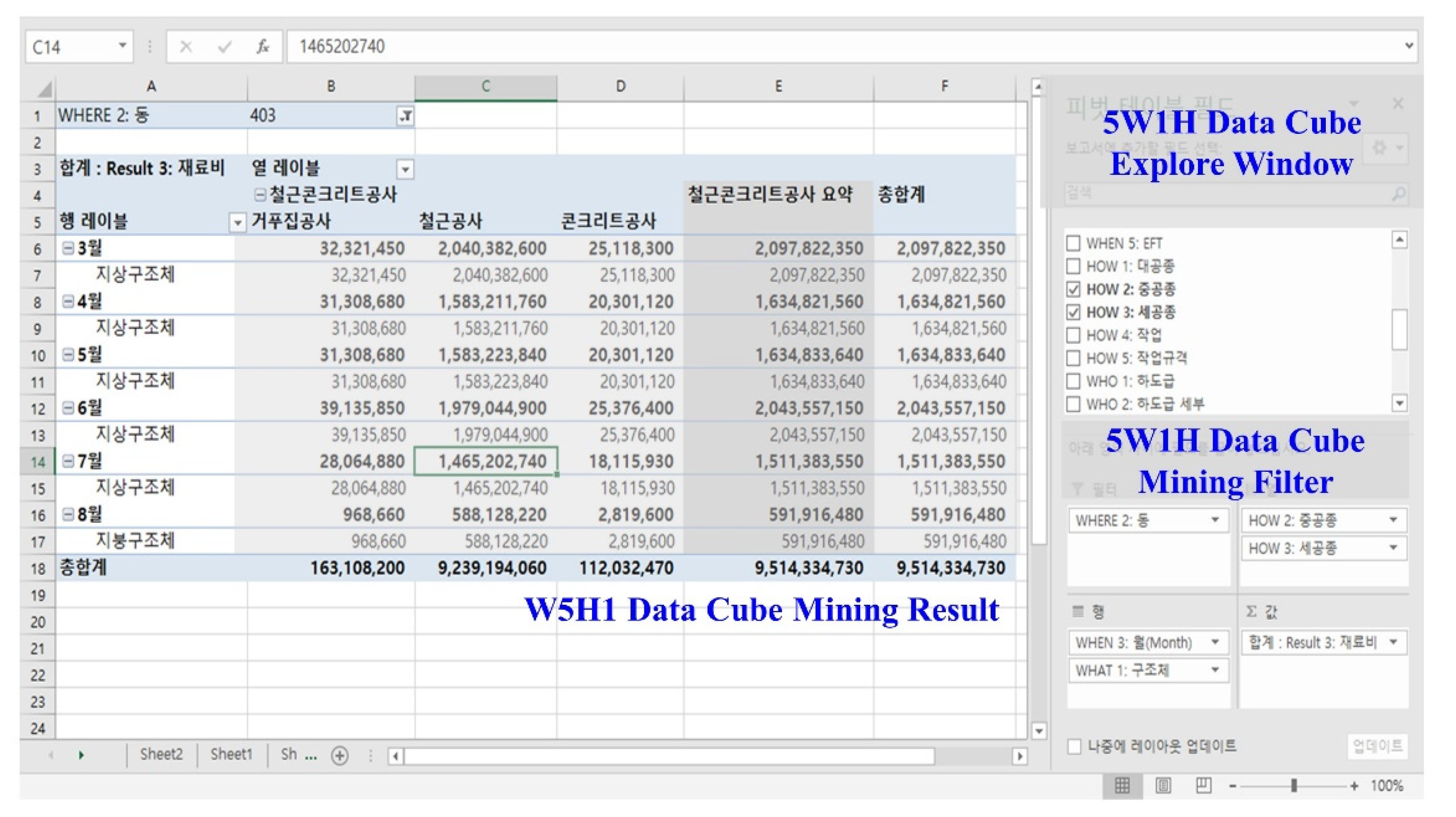
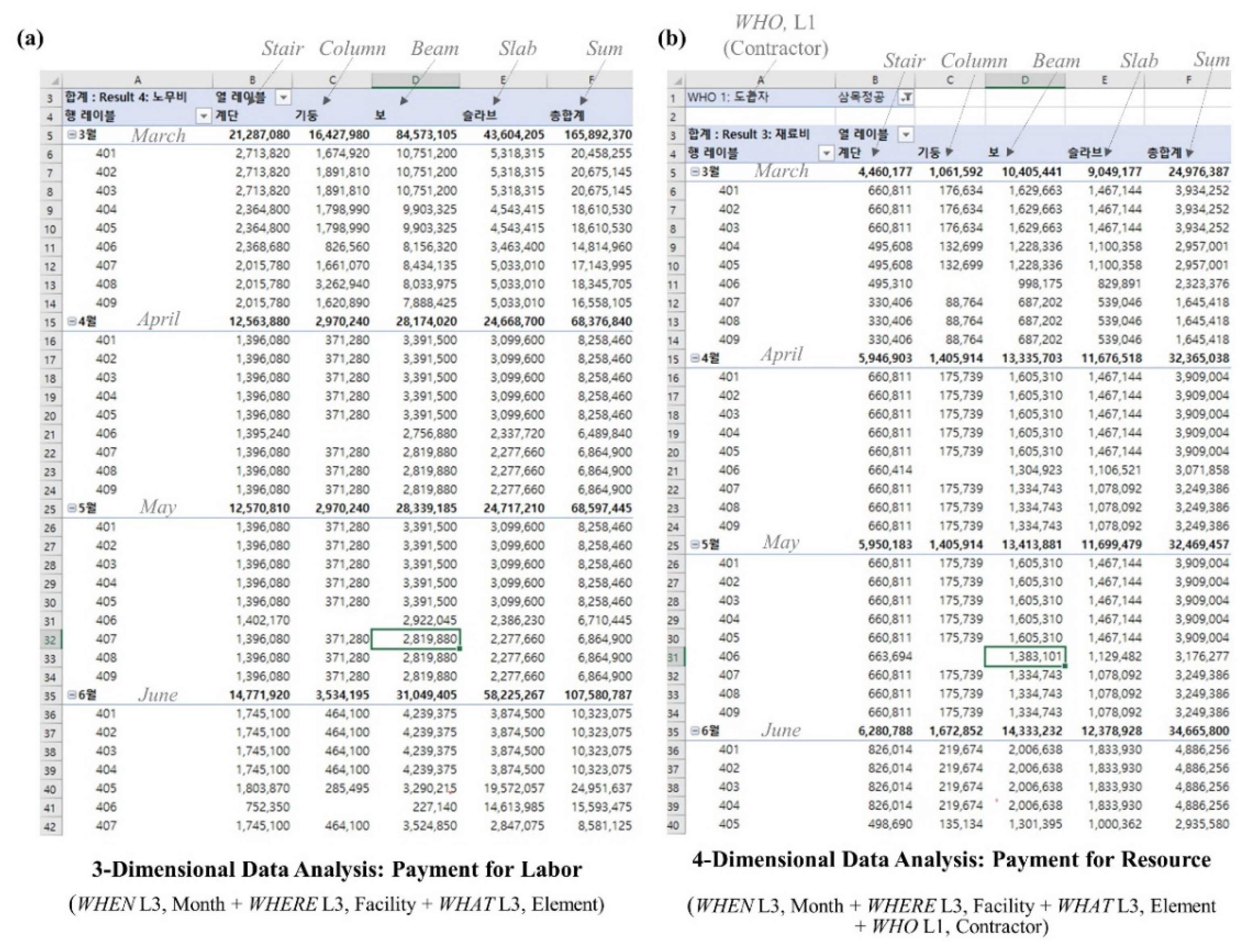
4.3. Big Data Technology-driven Algorithm for Cost-Schedule Integration
- building big data from various data sources based on the 5W1H data schema (Module 1–4),
- extracting data for users’ requirements (Module 5),
- analyzing data using extracted data (Module 6),
- visualizing analysis results by creating graphs, charts, and diagrams (Module 7).
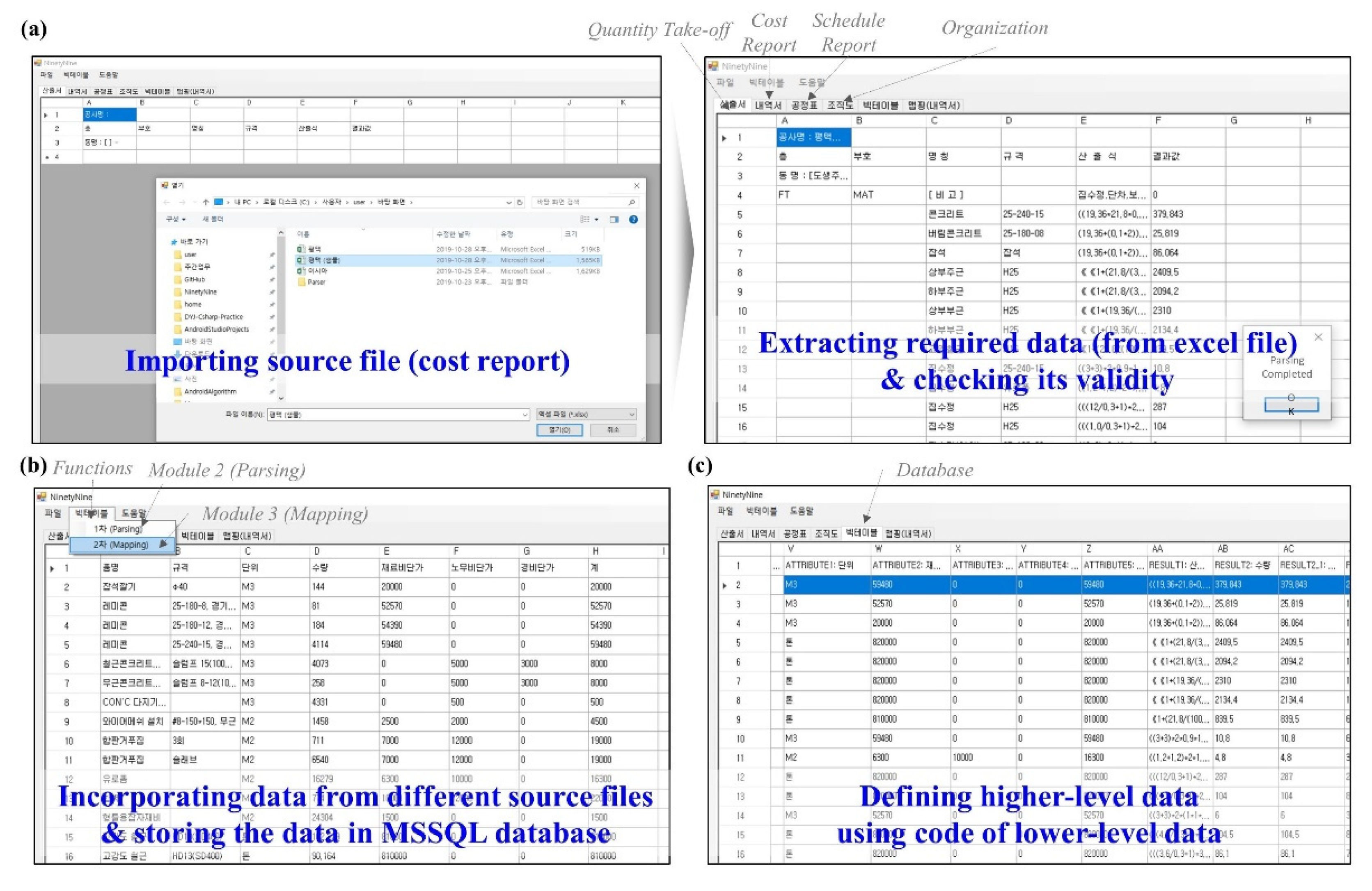
5. Case Study of Proposed Algorithm
5.1. Summary of Case Study
5.2. Verification and Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sivarajah, U.; Kamal, M.M.; Irani, Z.; Weerakkody, V. Critical analysis of Big Data challenges and analytical methods. J. Bus. Res. 2017, 70, 263–286. [Google Scholar] [CrossRef] [Green Version]
- Bilal, M.; Oyedele, L.O.; Qadir, J.; Munir, K.; Ajayi, S.O.; Akinade, O.O.; Owolabi, H.A.; Alaka, H.A.; Pasha, M. Big Data in the construction industry: A review of present status, opportunities, and future trends. Adv. Eng. Inform. 2016, 30, 500–521. [Google Scholar] [CrossRef]
- Rasdorf, W.J.; Abudayyeh, O.Y. Cost-and schedule-control integration: Issues and needs. J. Constr. Eng. Manag. 1991, 117, 486–502. [Google Scholar] [CrossRef] [Green Version]
- Cho, D.; Russell, J.S.; Choi, J. Database framework for cost, schedule, and performance data integration. J. Comput. Civ. Eng. 2013, 27, 719–731. [Google Scholar] [CrossRef]
- Jung, Y.; Gibson, G.E. Planning for computer integrated construction. J. Comput. Civ. Eng. 1999, 13, 217–225. [Google Scholar] [CrossRef]
- Oinas, M. The utilization of product model data in production and procurement planning. In Proceedings of the Life-Cycle of Construction IT Innovations—Technology Transfer from Research to Practice, Stockholm, Sweden, 3–5 June 1998; pp. 1–8. [Google Scholar]
- Davis, D. LEAN, Green and Seen (The Issues of Societal Needs, Business Drivers and Converging Technologies Are Making BIM An Inevitable Method of Delivery and Management of the Built Environment). J. Build. Inf. Model. 2007, Fall, 16–18. [Google Scholar]
- Perera, A.; Imriyas, K. An integrated construction project cost information system using MS AccessTM and MS ProjectTM. Constr. Manag. Econ. 2004, 22, 203–211. [Google Scholar] [CrossRef]
- Teicholz, P.M. Current needs for cost control systems. In Project Controls: Needs and Solutions; ASCE: New York, NY, USA, 1987; pp. 47–57. [Google Scholar]
- Hendrickson, C.; Hendrickson, C.T.; Au, T. Project Management for Construction: Fundamental Concepts for Owners, Engineers, Architects, and Builders; Prentice-Hall: Upper Saddle River, NJ, USA, 1989. [Google Scholar]
- Kim, J.J. An Object-Oriented Database Management System Approach to Improve Construction Project Planning and Control. Ph.D. Thesis, University of Illinois, Urbana, IL, USA, 1989. [Google Scholar]
- Fleming, Q.W.; Koppelman, J.M. Earned Value Project Management. 3. Painos; Project Management Institute: Newtown Square, PA, USA, 2005. [Google Scholar]
- Kang, L.S.; Paulson, B.C. Information management to integrate cost and schedule for civil engineering projects. J. Constr. Eng. Manag. 1998, 124, 381–389. [Google Scholar] [CrossRef]
- Jung, Y.; Woo, S. Flexible work breakdown structure for integrated cost and schedule control. J. Constr. Eng. Manag. 2004, 130, 616–625. [Google Scholar] [CrossRef]
- Ma, Y. Research on Technology Innovation Management in Big Data Environment. IOP Conf. Ser. Earth Environ. Sci. 2018, 113, 12141. [Google Scholar] [CrossRef]
- Holst, A. Big Data Market Size Revenue Forecast Worldwide from 2011 to 2027. 2018. Available online: https://www.statista.com/statistics/254266/global-big-data-market-forecast/ (accessed on 20 October 2019).
- Manyika, J.; Chui, M. Big Data: The Next Frontier for Innovation, Competition, and Productivity; McKinsey Global Institute, 2011; Available online: https://www.mckinsey.com/~/media/McKinsey/Business%20Functions/McKinsey%20Digital/Our%20Insights/Big%20data%20The%20next%20frontier%20for%20innovation/MGI_big_data_full_report.pdf (accessed on 25 October 2020).
- Ma, G.; Wu, M. A Big Data and FMEA-based construction quality risk evaluation model considering project schedule for Shanghai apartment projects. Int. J. Qual. Reliab. Manag. 2019. [Google Scholar] [CrossRef]
- Bilal, M.; Oyedele, L.O.; Kusimo, H.O.; Owolabi, H.A.; Akanbi, L.A.; Ajayi, A.O.; Akinade, O.O.; Davila Delgado, J.M. Investigating profitability performance of construction projects using big data: A project analytics approach. J. Build. Eng. 2019, 26, 100850. [Google Scholar] [CrossRef]
- Marzouk, M.; Amin, A. Predicting construction materials prices using fuzzy logic and neural networks. J. Constr. Eng. Manag. 2013, 139, 1190–1198. [Google Scholar] [CrossRef]
- Wang, D.; Fan, J.; Fu, H.; Zhang, B. Research on optimization of big data construction engineering quality management based on RNN-LSTM. Complexity 2018, 2018, 9691868. [Google Scholar] [CrossRef]
- Guo, S.; Luo, H.; Yong, L. A big data-based workers behavior observation in China metro construction. Procedia Eng. 2015, 123, 190–197. [Google Scholar] [CrossRef] [Green Version]
- Carr, R.I. Cost, schedule, and time variances and integration. J. Constr. Eng. Manag. 1993, 119, 245–265. [Google Scholar] [CrossRef] [Green Version]
- Kitchin, R.; McArdle, G. What makes Big Data, Big Data? Exploring the ontological characteristics of 26 datasets. Big Data Soc. 2016, 3. [Google Scholar] [CrossRef]
- Aouad, G.; Kagioglou, M.; Cooper, R.; Hinks, J.; Sexton, M. Technology management of IT in construction: A driver or an enabler. Logist. Inf. Manag. 1999, 12, 130–137. [Google Scholar] [CrossRef]
- Kim, H.; Kim, W.; Yi, Y. Awareness on Big Data of Construction Firms and Future Directions; Construction & Economy Research Institute of Korea: Seoul, Korea, 2014. [Google Scholar]
- Sørensen, A.Ø.; Olsson, N.; Landmark, A.D. Big Data in Construction Management Research. In Proceedings of the CIB World Building Congress 2016, Tampere, Finland, 30 May–3 June 2016; pp. 405–416. [Google Scholar]
- Turk, Ž.; Klinc, R. A social–product–process framework for construction. Build. Res. Inf. 2020, 48, 747–762. [Google Scholar] [CrossRef]
- Cho, D. Construction Information Database Framework (CIDF) for Integrated Cost, Schedule, and Performance Control. Ph.D. Thesis, University of Wisconsin, Madison, WI, USA, 2009. [Google Scholar]
- Construction Specifications Institute (CSI) and Construction Specifications Canada (CSC). UniFormat; 2010; Available online: https://www.csiresources.org/standards/uniformat (accessed on 16 October 2020).
- The Construction Specifications Institute and Construction. MasterFormat; 2016; Available online: https://www.csiresources.org/standards/masterformat (accessed on 14 October 2020).
- Paulsson, J.; Paasch, J.M. 3D property research from a legal perspective. Comput. Environ. Urban Syst. 2013, 40, 7–13. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
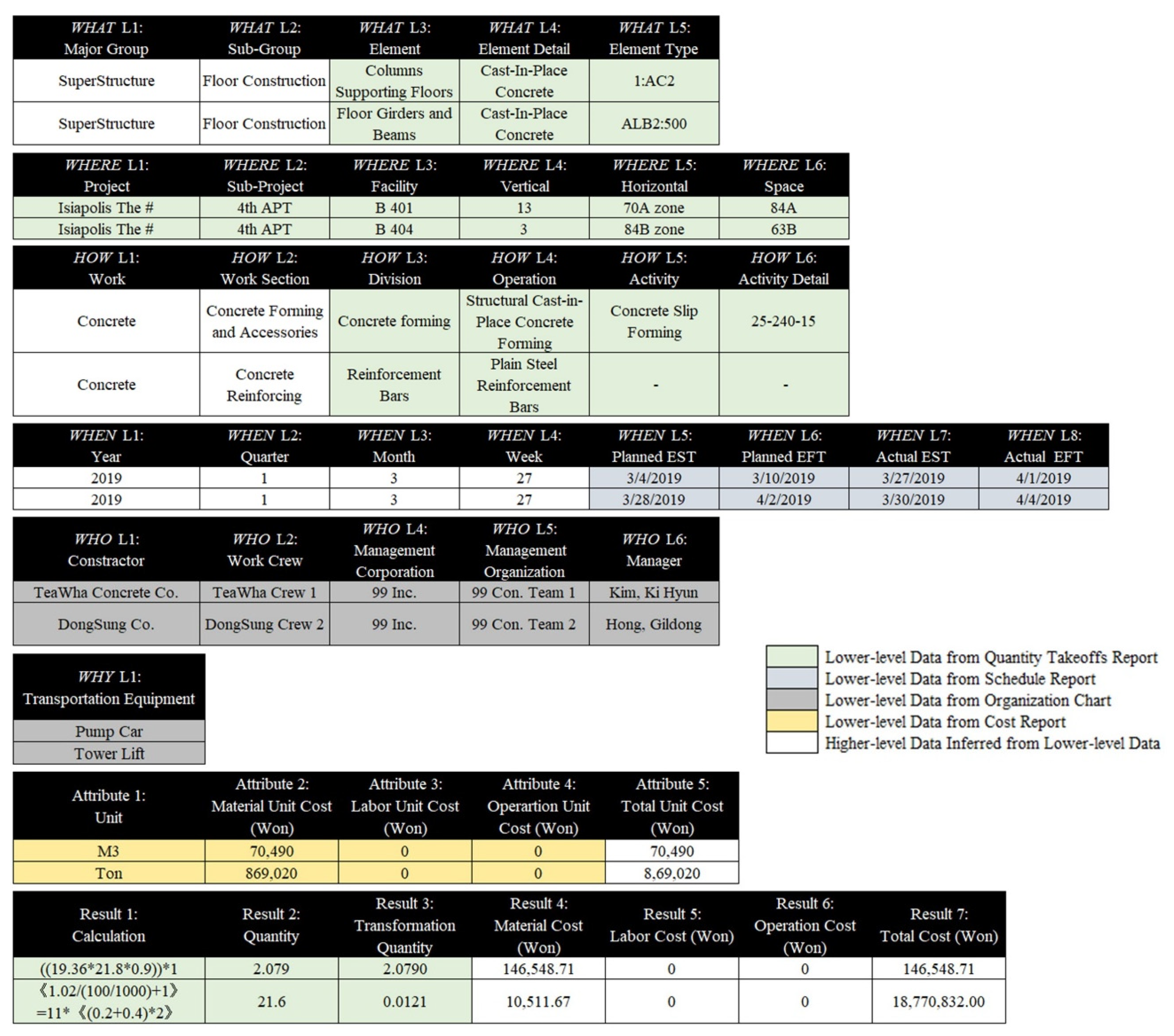
| Data Dimension | Level of Detail | |||||
|---|---|---|---|---|---|---|
| Level 1: L1 | Level 2: L2 | Level 3: L3 | Level 4: L4 | Level 5: L5 | Level 6: L6 | |
| WHAT | Major Group A10: Foundations | Sub-Group A1010: Standard Foundation | Element A1010.10: Wall Foundation | Element Detail A1010.10. CF: Continuous Footings | ||
| WHERE | Project XX Hospital Project | Sub-Project Surgical Ward Building | Facility Building A | Vertical V01: Baseline, 2nd Floor | Horizontal H01: B Zone | Space Operating Room |
| HOW | Work 03: Concrete | Work Section 031: Concrete Form & Accessories | Division 0311: Concrete Forming | Operation 031113: Structural Cast-in-Place Concrete Forming | Activity 031113.13: Concrete Slip Forming | |
| WHEN | Year 2019 | Quarter 1st Quarter | Month March | Week 12th Week | Planned EST 17 May | Planned EFT 23 March |
| WHO | Contractor Subcontractor A | Work Crew A01 Formwork Crew 1 | Individual 1 Carpenter Foreman, 4 Carpenters, 1 Laborer | Management Corporation M01: Management Firm A | Management Organization M01.01: Management Team A | Manager M01.01.01: Manager A |
| WHY | Transportation Equipment Tower Crane | |||||
| Independent Variables | Dependent Variables | |
|---|---|---|
| Levels of Dimension | Core Unit Attributes | Result |
| 5 Levels of WHAT Dimension | Attribute 1. Unit | Result 1. Calculation |
| 6 Levels of WHERE Dimension | Attribute 2. Material Unit Cost | Result 2. Quantity |
| 6 Levels of HOW Dimension | Attribute 3. Labor Unit Cost | Result 3. Transformation Quantity |
| 8 Levels of WHEN Dimension | Attribute 4. Operation Unit Cost | Result 4. Material Cost |
| 5 Levels of WHO Dimension | Attribute 5. Total Unit Cost | Result 5. Labor Cost |
| 1 Levels of WHY Dimension | - | Result 6. Operation Cost |
| - | - | Result 7. Total Cost |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cho, D.; Lee, M.; Shin, J. Development of Cost and Schedule Data Integration Algorithm Based on Big Data Technology. Appl. Sci. 2020, 10, 8917. https://doi.org/10.3390/app10248917
Cho D, Lee M, Shin J. Development of Cost and Schedule Data Integration Algorithm Based on Big Data Technology. Applied Sciences. 2020; 10(24):8917. https://doi.org/10.3390/app10248917
Chicago/Turabian StyleCho, Daegu, Myungdo Lee, and Jihye Shin. 2020. "Development of Cost and Schedule Data Integration Algorithm Based on Big Data Technology" Applied Sciences 10, no. 24: 8917. https://doi.org/10.3390/app10248917
APA StyleCho, D., Lee, M., & Shin, J. (2020). Development of Cost and Schedule Data Integration Algorithm Based on Big Data Technology. Applied Sciences, 10(24), 8917. https://doi.org/10.3390/app10248917