Pedestrian Detection at Night in Infrared Images Using an Attention-Guided Encoder-Decoder Convolutional Neural Network

Abstract
:1. Introduction
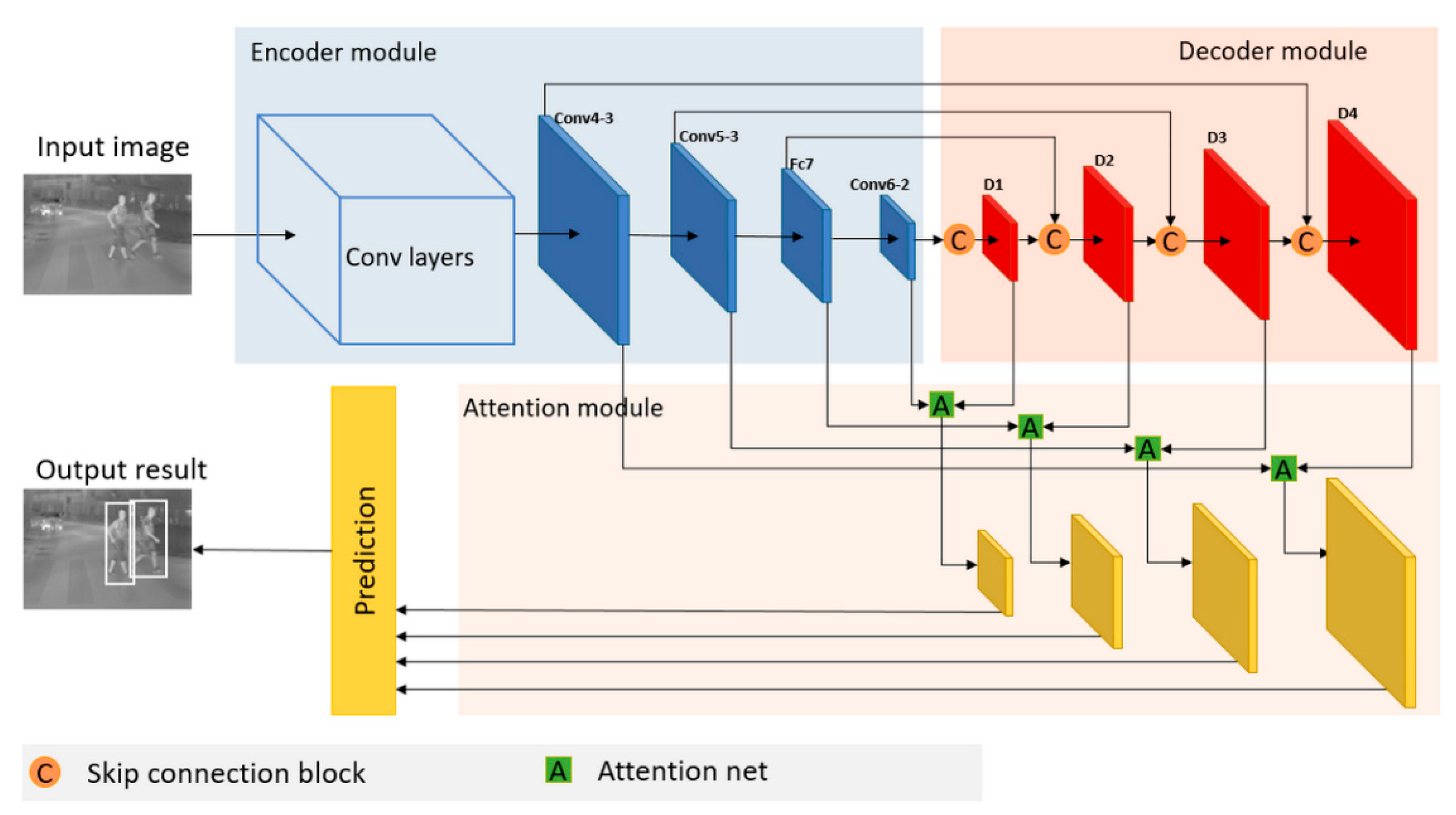
- First, novel encoder-decoder modules are proposed to generate multi-scale features. We add an additional decoder module at the end of the single shot multibox detector (SSD) [16] architecture (encoder module) to form an encoder-decoder module, in which a new skip connection block is incorporated into each layer of the decoder to integrate the feature maps from the encoder and decoder modules. The proposed encoder-decoder modules effectively enrich the feature maps via integrating the high-level semantically strong features with low-resolution and low-level detailed features with high-resolution. This method is effective to extract discriminative features even from low-resolution and noisy IR images.
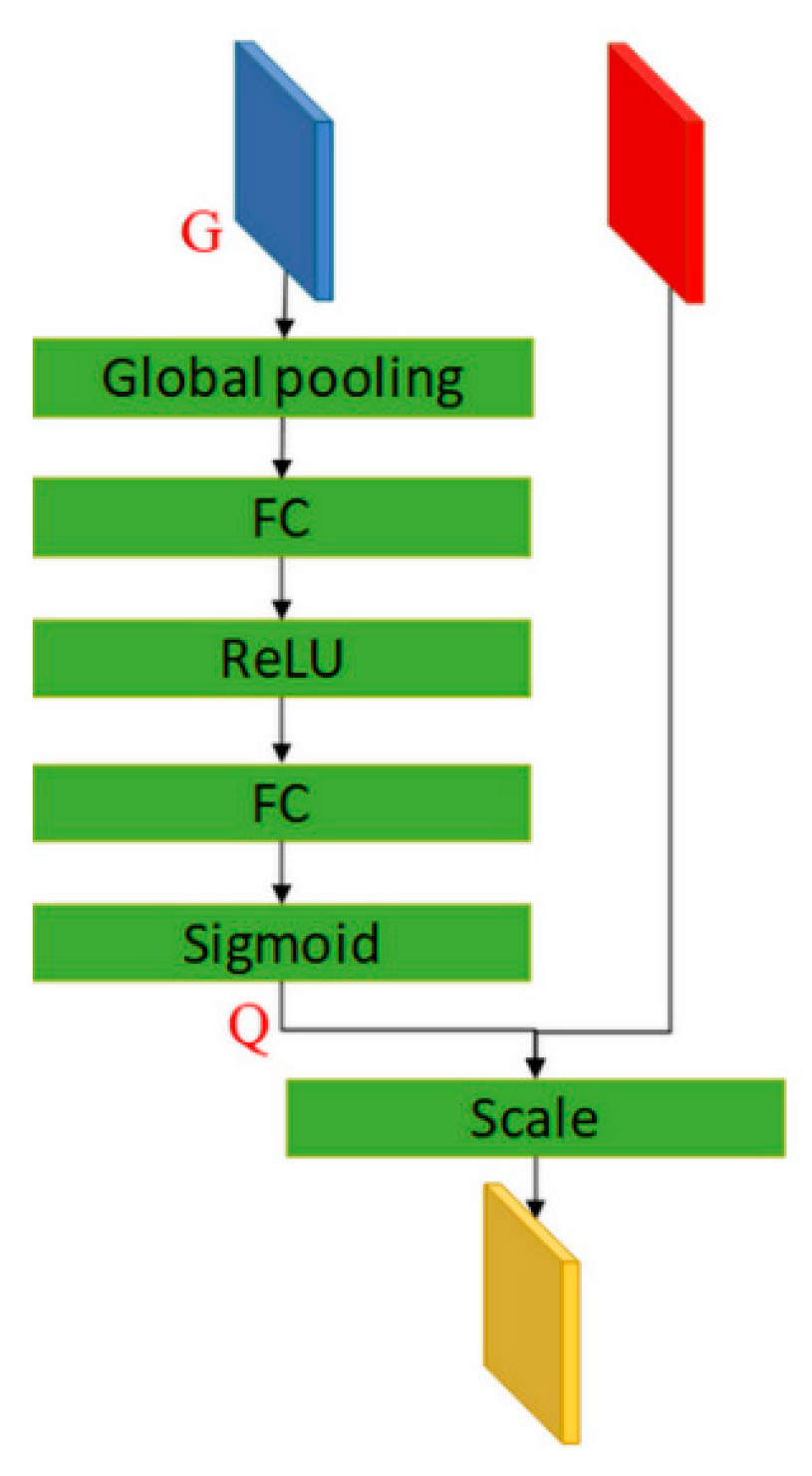
- Second, we propose an attention module that re-weights the multi-scale features generated from the encoder-decoder module. By adding the attention mechanism, the network selectively emphasizes useful information and suppresses ineffective information while re-weighting the features from the encoder-decoder modules. The attention module significantly eliminates background interference while highlighting pedestrians so that there is a boost in the detection performance of the IR pedestrian detector, even when the brightness is similar among the pedestrians and backgrounds.
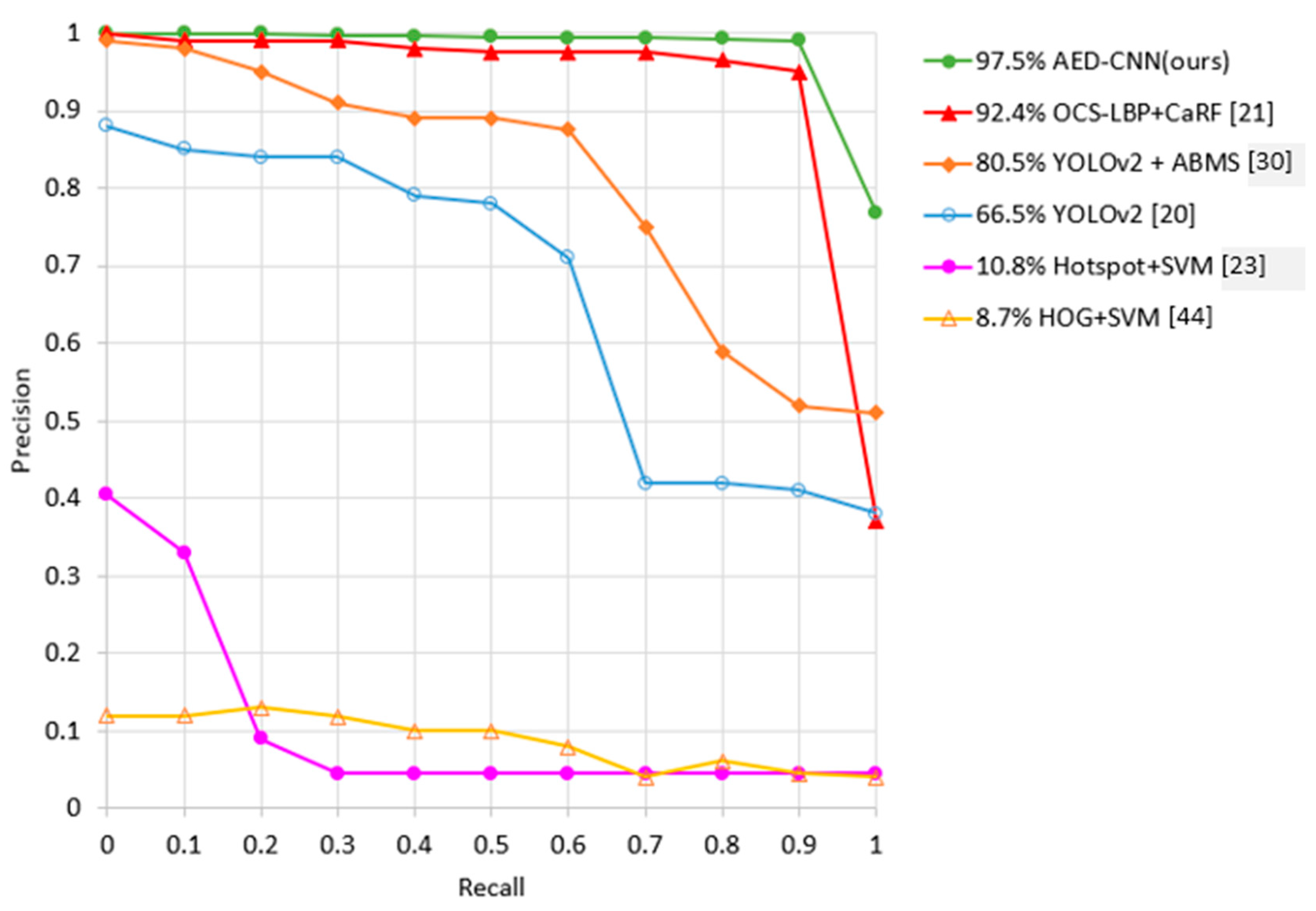
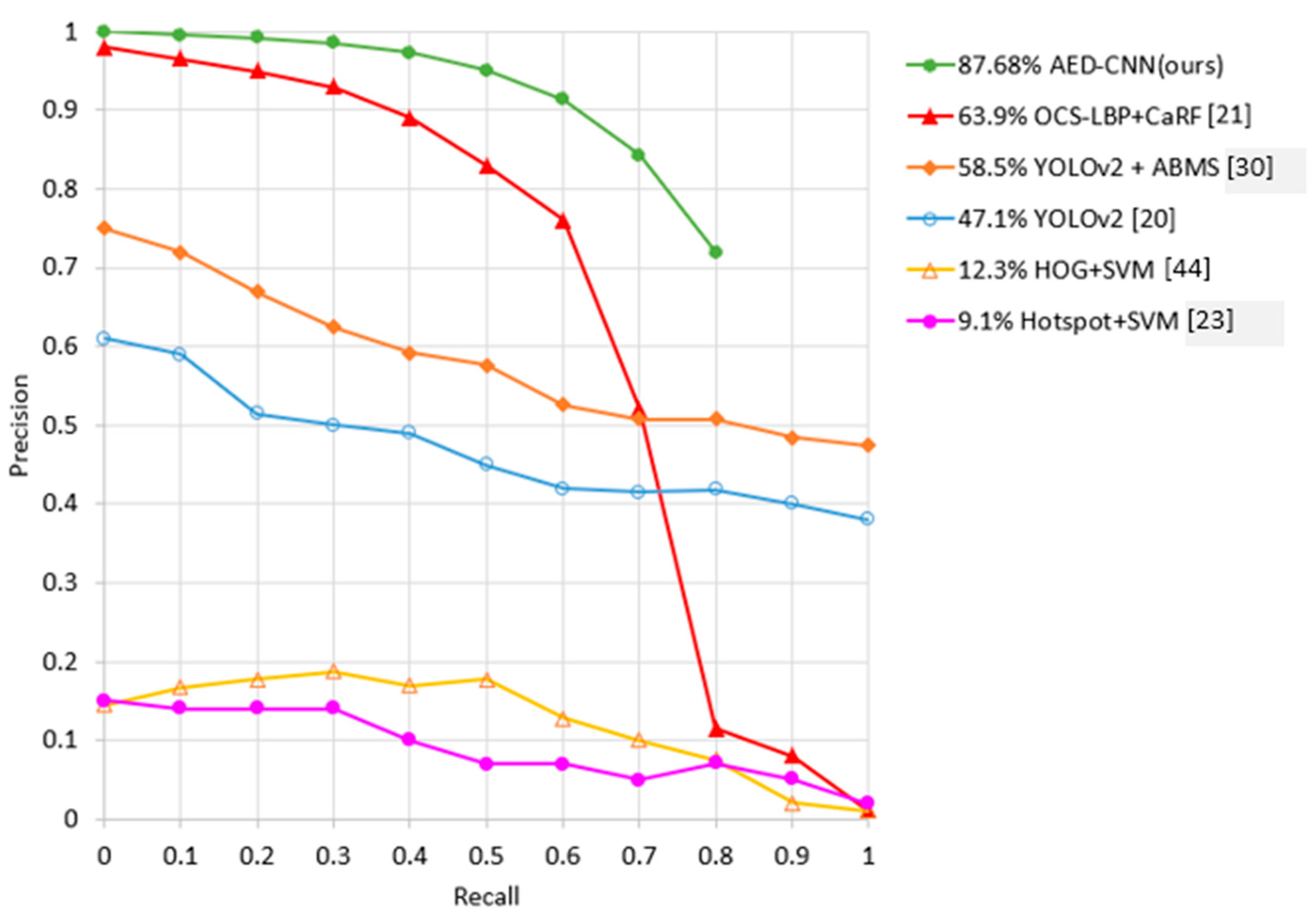
- Finally, experimental results on two challenging datasets demonstrate that our AED-CNN shows the best performance. Our approach outperforms in detection precision by 5.1% and 23.78% on the Keimyung University (KMU) [21] (the KMU pedestrian detection database [21] is downloaded from: https://cvpr.kmu.ac.kr/ for academic use) and Computer Vision Center (CVC)-09 [22] (the CVC-09 far infrared (FIR) sequence pedestrian dataset [22] (available online, 28 April 2016) is download from: http://adas.cvc.uab.es/elektra/enigma-portfolio/item-1/) pedestrian datasets, respectively, when compared with the state-of-the-art oriented center-symmetric local binary (OCS LBP) + cascade random forest (CaRF) [21] method.
2. Background
2.1. Infrared (IR) Pedestrian Detection
2.2. Convolutional Neural Network (CNN)-Based Object Detection
2.3. Attention Mechanism
3. Proposed Attention-Guided Encoder-Decoder Convolutional Neural Network (AED-CNN)
3.1. Overview of the Proposed AED-CNN Architecture
3.2. Encoder Module
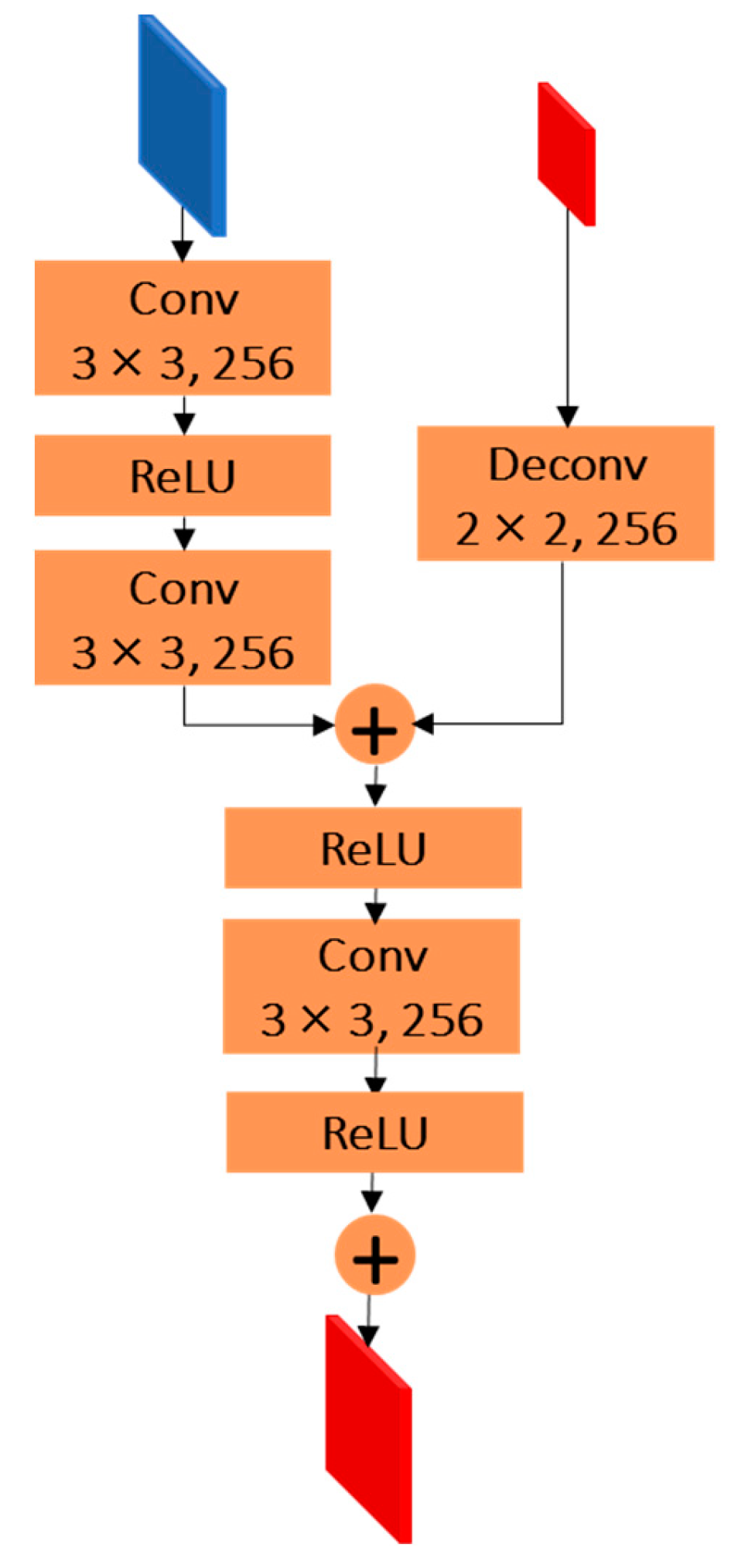
3.3. Decoder Module
Skip Connection Block
3.4. Attention Module
3.5. Training
3.5.1. Matching and Hard Negative Mining
3.5.2. Loss Function
3.5.3. Optimization
4. Experimental Results
4.1. Datasets and Processing Platform
4.2. Evaluation Metric
4.3. Comparison of the Detection Performance on the Keimyung University (KMU) Dataset
4.4. Comparison of the Detection Performance on the CVC-09 Dataset
4.5. Comparison of the Computational Speed
4.6. Ablation Experiments
4.6.1. Evaluation of the Encoder-Decoder Module
4.6.2. Evaluation of the Attention Module
4.7. Discussion
4.7.1. Explanation of Results
4.7.2. Limitation of the Proposed Method
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Dollár, P.; Appel, R.; Belongie, S.; Perona, P. Fast feature pyramids for object detection. IEEE Trans. Pattern Anal. 2014, 36, 1532–1545. [Google Scholar] [CrossRef] [Green Version]
- Tian, Y.; Luo, P.; Wang, X.; Tang, X. Deep learning strong parts for pedestrian detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1904–1912. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 354–370. [Google Scholar]
- Xiao, F.; Liu, B.; Li, R. Pedestrian object detection with fusion of visual attention mechanism and semantic computation. Multimed. Tools Appl. 2019, 1–15. [Google Scholar] [CrossRef]
- Brazil, G.; Yin, X.; Liu, X. Illuminating pedestrians via simultaneous detection & segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4950–4959. [Google Scholar]
- Guo, Z.; Liao, W.; Xiao, Y.; Veelaert, P.; Philips, W. An occlusion-robust feature selection framework in pedestrian detection. Sensors 2018, 18, 2272. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Liang, X.; Shen, S.; Xu, T.; Feng, J.; Yan, S. Scale-aware fast r-cnn for pedestrian detection. IEEE Trans. Multimed. 2017, 20, 985–996. [Google Scholar] [CrossRef] [Green Version]
- Gu, J.; Lan, C.; Chen, W.; Han, H. Joint pedestrian and body part detection via semantic relationship learning. Appl. Sci. 2019, 9, 752. [Google Scholar] [CrossRef] [Green Version]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Liu, J.; Zhang, S.; Wang, S.; Metaxas, D.N. Multispectral deep neural networks for pedestrian detection. In Proceedings of the British Machine Vision Conference, York, UK, 19–22 September 2016; pp. 1–13. [Google Scholar]
- König, D.; Adam, M.; Jarvers, C.; Layher, G.; Neumann, H.; Teutsch, M. Fully convolutional region proposal networks for multispectral person detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 243–250. [Google Scholar]
- Chen, Y.; Xie, H.; Shin, H. Multi-layer fusion techniques using a CNN for multispectral pedestrian detection. IET Comput. Vis. 2018, 12, 1179–1187. [Google Scholar] [CrossRef]
- Li, C.; Song, D.; Tong, R.; Tang, M. Illumination-aware faster r-cnn for robust multispectral pedestrian detection. Pattern Recognit. 2019, 85, 161–171. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4203–4212. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Jeong, M.; Ko, B.C.; Nam, J.Y. Early detection of sudden pedestrian crossing for safe driving during summer nights. IEEE Trans. Circ. Syst. Video 2016, 27, 1368–1380. Available online: https://cvpr.kmu.ac.kr/ (accessed on 28 April 2016). [CrossRef]
- CVC-09 FIR Sequence Pedestrian Dataset. Available online: http://adas.cvc.uab.es/elektra/enigma-portfolio/item-1/ (accessed on 28 April 2016).
- Xu, F.; Liu, X.; Fujimura, K. Pedestrian detection and tracking with night vision. IEEE Trans. Intell. Trans. Syst. 2005, 6, 63–71. [Google Scholar] [CrossRef]
- Ko, B.; Kim, D.; Nam, J. Detecting humans using luminance saliency in thermal images. Opt. Lett. 2012, 37, 4350–4352. [Google Scholar] [CrossRef] [PubMed]
- Ge, J.; Luo, Y.; Tei, G. Real-time pedestrian detection and tracking at nighttime for driver-assistance systems. IEEE Trans. Intell. Trans. Syst. 2009, 10, 283–298. [Google Scholar]
- Bertozzi, M.; Broggi, A.; Caraffi, C.; Del Rose, M.; Felisa, M.; Vezzoni, G. Pedestrian detection by means of far-infrared stereo vision. Comput. Vis. Image Underst. 2007, 106, 194–204. [Google Scholar] [CrossRef]
- O’Malley, R.; Jones, E.; Glavin, M. Detection of pedestrians in far-infrared automotive night vision using region-growing and clothing distortion compensation. Infrared Phys. Technol. 2010, 53, 439–449. [Google Scholar] [CrossRef]
- Zhao, X.; He, Z.; Zhang, S.; Liang, D. Robust pedestrian detection in thermal infrared imagery using a shape distribution histogram feature and modified sparse representation classification. Pattern Recognit. 2015, 48, 1947–1960. [Google Scholar] [CrossRef]
- Biswas, S.K.; Milanfar, P. Linear support tensor machine with LSK channels: Pedestrian detection in thermal infrared images. IEEE Trans. Image Process. 2017, 26, 4229–4242. [Google Scholar] [CrossRef] [Green Version]
- Heo, D.; Lee, E.; Ko, B.C. Pedestrian detection at night using deep neural networks and saliency maps. Electron. Imaging 2018, 17, 1–9. [Google Scholar] [CrossRef]
- Cao, Z.; Yang, H.; Zhao, J.; Pan, X.; Zhang, L.; Liu, Z. A new region proposal network for far-infrared pedestrian detection. IEEE Access 2019, 7, 135023–135030. [Google Scholar] [CrossRef]
- Park, J.; Chen, J.; Cho, Y.K.; Kang, D.Y.; Son, B.J. CNN-based person detection using infrared images for night-time intrusion warning systems. Sensors 2020, 20, 34. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767(1804). [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Li, X.; Zhao, L.; Wei, L.; Yang, M.H.; Wu, F.; Zhuang, Y.; Ling, H.; Wang, J. Deepsaliency: Multi-task deep neural network model for salient object detection. IEEE Trans. Image Process. 2016, 25, 3919–3930. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for largescale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Erhan, D.; Szegedy, C.; Toshev, A.; Anguelov, D. Scalable object detection using deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2147–2154. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Chia Laguna, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Xu, Y.; Xu, D.; Lin, S.; Han, T.X.; Cao, X.; Li, X. Detection of sudden pedestrian crossings for driving assistance systems. IEEE Trans. Syst. Man Cybern. B 2012, 42, 729–739. [Google Scholar]
- Wang, W.; Lai, Q.; Fu, H.; Shen, J.; Ling, H. Salient object detection in the deep learning era: An in-depth survey. arXiv 2019, arXiv:1904.09146. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Occlusion-aware r-cnn: Detecting pedestrians in a crowd. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 637–653. [Google Scholar]
- Wang, X.; Xiao, T.; Jiang, Y.; Shao, S.; Sun, J.; Shen, C. Repulsion loss: Detecting pedestrians in a crowd. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7774–7783. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | KMU Test Set | CVC09 Test Set | ||
|---|---|---|---|---|
| Speed (s/f) | Precision | Speed (s/f) | Precision | |
| Histogram-of-oriented-gradients (HOG) + Support vector machine (SVM) [44] | 0.09 | 8.7% | 0.09 | 12.3% |
| Hotspot + SVM [23] | 0.08 | 10.8% | 0.08 | 9.1% |
| Oriented center-symmetric local binary (OCS-LBP) + Cascade random forest (CaRF) [21] | 0.06 | 92.4% | 0.06 | 63.9% |
| You only look once version 2 (YOLOv2) [20] | 0.02 | 66.5% | 0.02 | 47.1% |
| YOLOv2 + Adaptive Boolean-map-based saliency (ABMS) [30] | 0.02 | 80.5% | 0.02 | 58.5% |
| Attention-guided encoder-decoder convolutional neural network (AED-CNN) (ours) | 0.03 | 97.5% | 0.03 | 87.68% |
| Methods | Average Precision on KMU Test Set |
|---|---|
| Single shot multibox detector (SSD) [16] | 92.04% |
| Encoder-decoder module | 95.36% |
| Encoder-decoder module + attention module (AED-CNN) | 97.50% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Shin, H. Pedestrian Detection at Night in Infrared Images Using an Attention-Guided Encoder-Decoder Convolutional Neural Network. Appl. Sci. 2020, 10, 809. https://doi.org/10.3390/app10030809
Chen Y, Shin H. Pedestrian Detection at Night in Infrared Images Using an Attention-Guided Encoder-Decoder Convolutional Neural Network. Applied Sciences. 2020; 10(3):809. https://doi.org/10.3390/app10030809
Chicago/Turabian StyleChen, Yunfan, and Hyunchul Shin. 2020. "Pedestrian Detection at Night in Infrared Images Using an Attention-Guided Encoder-Decoder Convolutional Neural Network" Applied Sciences 10, no. 3: 809. https://doi.org/10.3390/app10030809
APA StyleChen, Y., & Shin, H. (2020). Pedestrian Detection at Night in Infrared Images Using an Attention-Guided Encoder-Decoder Convolutional Neural Network. Applied Sciences, 10(3), 809. https://doi.org/10.3390/app10030809