Data-Driven Redundant Transform Based on Parseval Frames


Abstract
:1. Introduction
- We propose the DRTPF method by integrating redundant Parseval frames with sparse constraints. The DRTPF method consists of a forward transform and a backward transform, which correspond to a frame and its dual frame, respectively. In other words, DRTPF bridges synthesis and analysis models by assuming that two models share almost the same sparse coefficients.
- DRTPF outperforms traditional transforms and frames by learning from data which exploits the features of natural images, whereas traditional transforms and frames admit a uniform representation of various images, which tend to fail to characterize the intrinsic individual-specific features.
- Traditional transforms are usually orthogonal transforms and the signals remain isometric, yet they suffer from weak robustness due to their strict properties. In contrast, DRTPF preserves the signals in a bounded fashion, which admits higher robustness and flexibility.
- We propose a model for learning DRTPF and compare DRTPF with traditional transforms and sparse models in robustness analysis and image denoising experiments. Both qualitative and quantitative results demonstrate that DRTPF outperforms traditional transforms and sparse models.
2. Related Work
3. Data-Driven Redundant Transform Model Based on Tight Frame
3.1. Data-Driven Redundant Transform
3.2. Transform Learning for the Drtbf Model
3.2.1. Sparse Coding Phase
The Subproblem
The Subproblem
3.2.2. Transform Pair Update Phase
The Subproblem
| Algorithm 1: Sparse coding algorithm. |
Input and Initialization: Training data , iteration number r, initial value . Output: Sparse coefficients , and threshold values Process:
|
The Subproblem
| Algorithm 2: Transform pair learning algorithm. |
Input and Initialization: Training data , frame bound , iteration . Build frames and , either by using random entries or using N randomly chosen data. Output: Frames , Sparse coefficients , and thresholding values Process: For l=1: Sparse Coding Step:
Frame Update Step:
|
4. Image Denoising
| Algorithm 3: Denoising algorithm. |
Input: Training dictionaries , , iteration number r, a degraded image , set . Output: The high-quality image
|
5. Experimental Results
5.1. Robustness Analysis
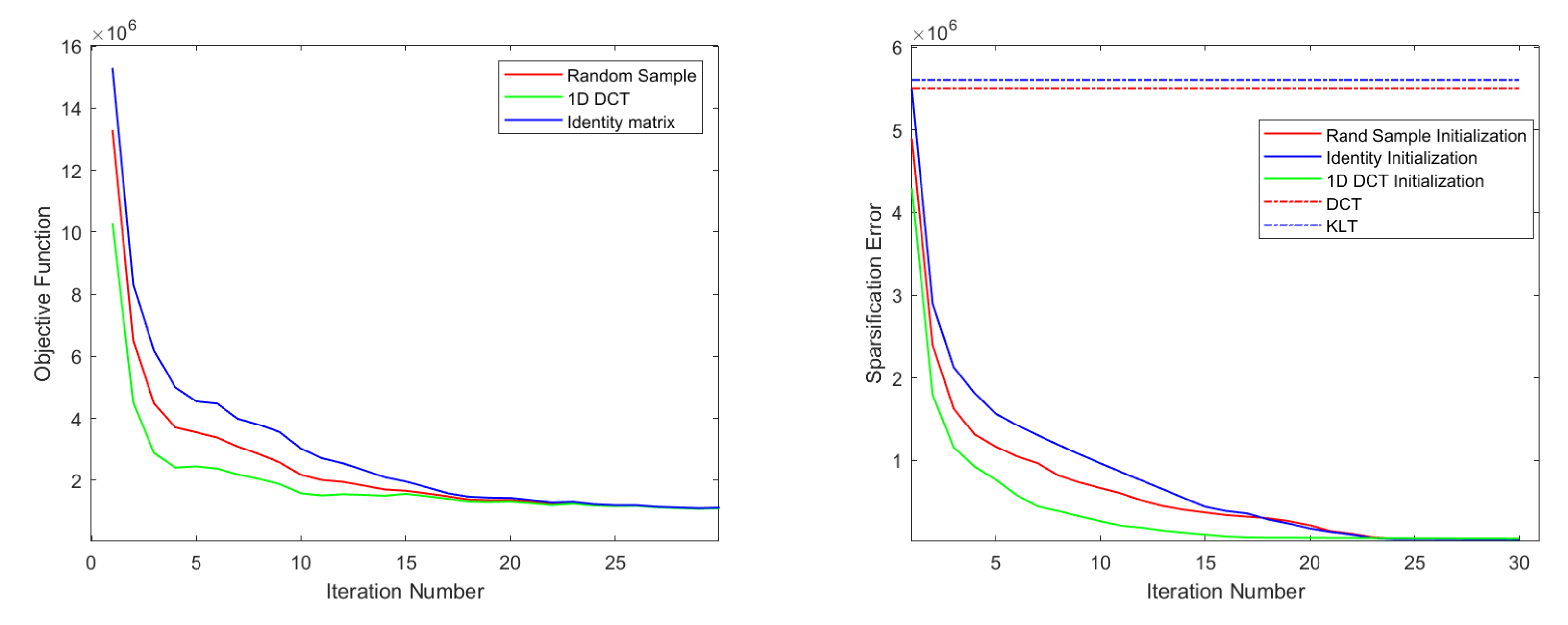
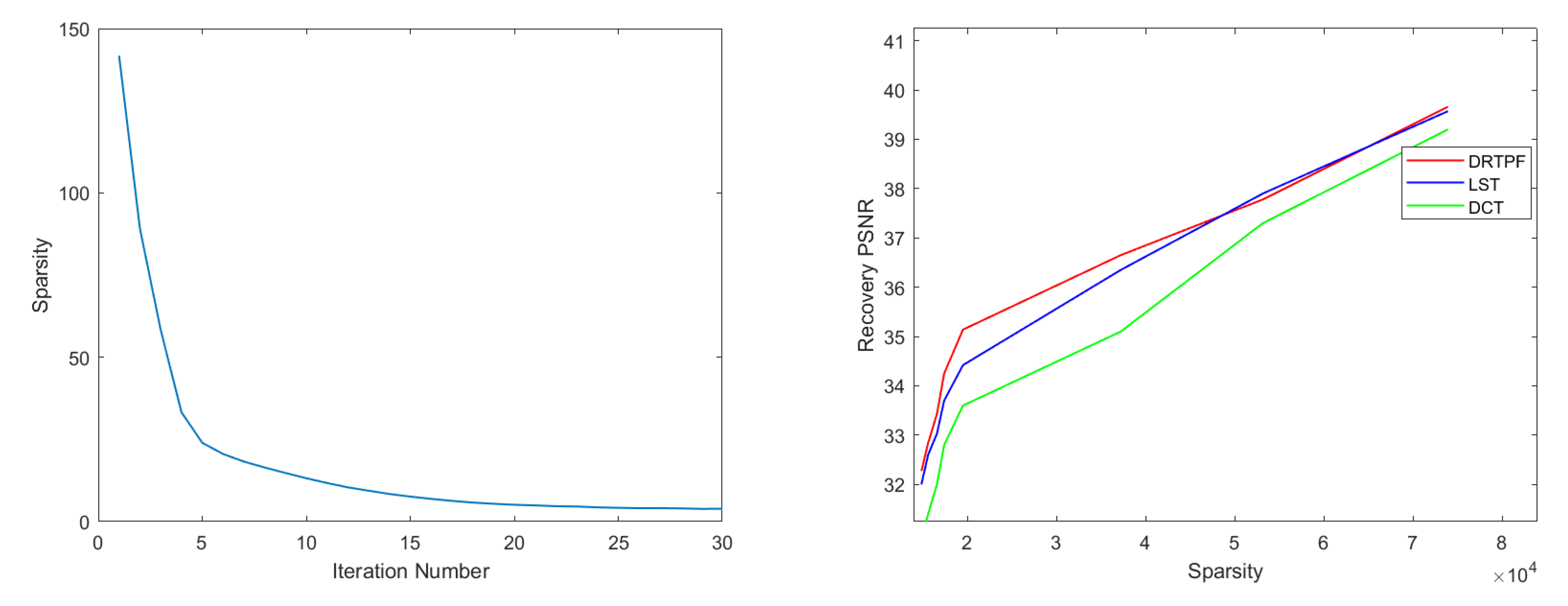
5.2. Sparsification of Nature Images
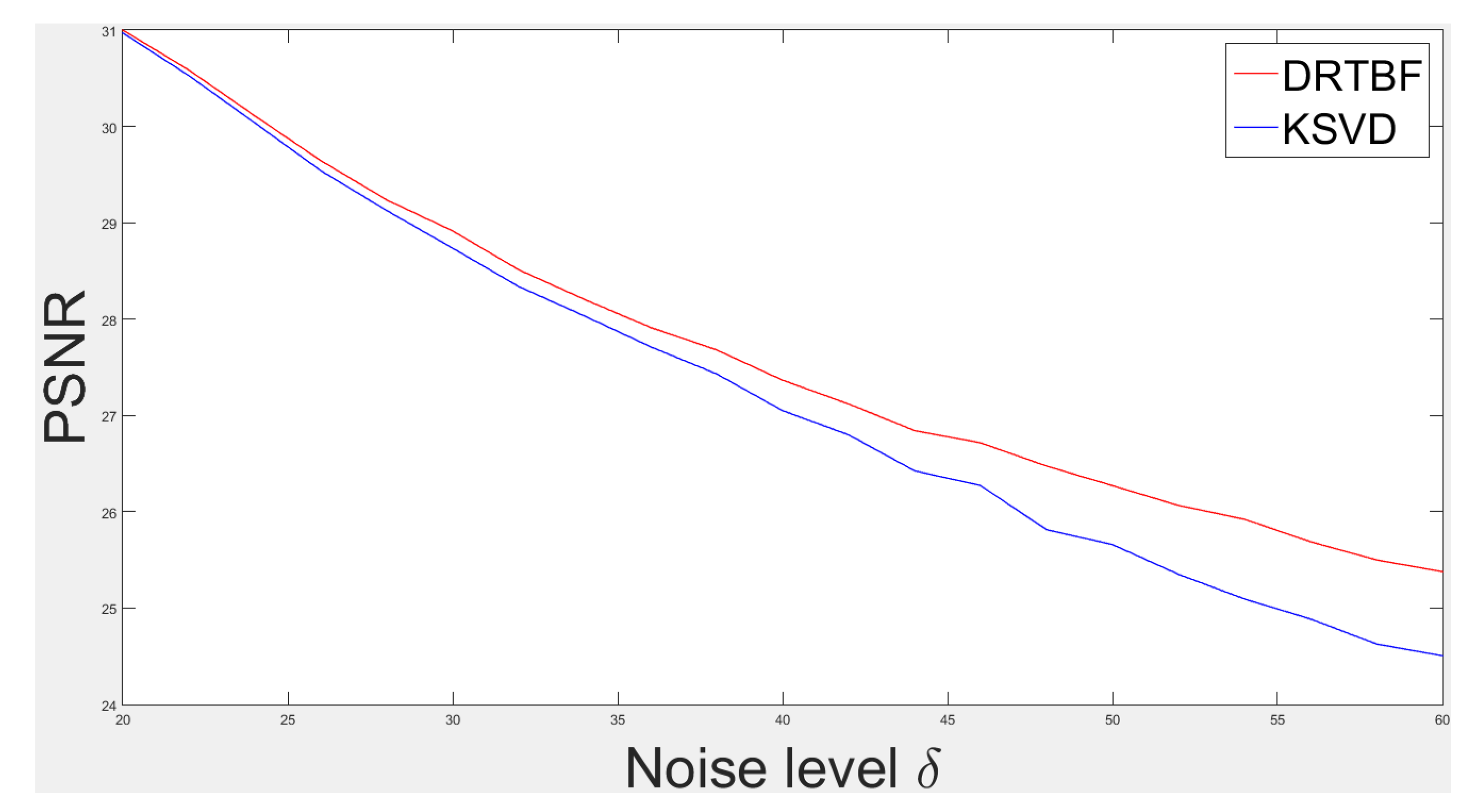
5.3. Image Denoising
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Marcellin, M.W.; Gormish, M.J.; Bilgin, A.B.; Boliek, M.P. An overview of jpeg-2000. In Proceedings of the DCC 2000. Data Compression Conference, Snowbird, UT, USA, 28–30 March 2000; pp. 523–541. [Google Scholar]
- Patel, K.; Kurian, N.; George, V. Time Frequency Analysis: A Sparse S Transform Approach. In Proceedings of the 2016 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Phuket, Thailand, 24–27 October 2016. [Google Scholar]
- Eksioglu, M.; Bayir, O. K-SVD Meets Transform Learning: Transform K-SVD. IEEE Signal Process. Lett. 2014, 21, 347–351. [Google Scholar] [CrossRef]
- Ravishankar, S.; Bresler, Y. Learning Sparsifying Transforms For Image Processing. In Proceedings of the 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012. [Google Scholar]
- Ravishankar, S.; Bresler, Y. Learning Doubly Sarse Transforms for Image Representation. In Proceedings of the 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012. [Google Scholar]
- Mallat, S.; Lepennec, E. Sparse geometric image representation with bandelets. IEEE Trans. Image Process 2005, 14, 423–438. [Google Scholar]
- Elad, M.; Aharon, M. Image denoising via sparse and redundant representations over learned dictionaries. IEEE Trans. Image Process 2006, 15, 3736–3745. [Google Scholar] [CrossRef]
- Dong, W.; Zhang, L.; Shi, G.; Li, X. Nonlocally Centralized Sparse Representation for Image Restoration. IEEE Trans. Image Process 2013, 22, 1620–1630. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qi, N.; Shi, Y.; Sun, X.; Yin, B. TenSR: Multi-dimensional Tensor Sparse Representation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5916–5925. [Google Scholar]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G.; Zisserman, A. Non-local sparse models for image restoration. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2272–2279. [Google Scholar]
- Wang, S.; Zhang, D.; Liang, Y.; Pan, Q. Semi-Coupled Dictionary Learning with Applications to Image Super-Resolution and Photo-Sketch Synthesis. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2216–2223. [Google Scholar]
- Yang, J.; Wang, Z.; Lin, Z.; Cohen, S.; Huang, T. Coupled dictionary training for image super-resolution. IEEE Trans. Image Process 2012, 21, 3467–3478. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Wright, J.; Huang, T.; Ma, Y. Image superresolution via sparse representation. IEEE Trans. Image Process 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Skretting, K.; Engan, K. Recursive least squares dictionary learning algorithm. IEEE Trans. Signal Process 2010, 58, 2121–2130. [Google Scholar] [CrossRef]
- Yaghoobi, M.; Nam, S.; Gribonval, R.; Davies, M.E. Noise aware analysis operator learning for approximately cosparse signals. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 5409–5412. [Google Scholar]
- Ophir, B.; Elad, M.; Bertin, N.; Plumbley, M. Sequential minimal eigenvalues—An approach to analysis dictionary learning. In Proceedings of the 2011 19th European Signal Processing Conference, Barcelona, Spain, 29 August–2 September 2011; pp. 1465–1469. [Google Scholar]
- Rubinstein, R.; Peleg, T.; Elad, M. Analysis K-SVD: A Dictionary-Learning Algorithm for the Analysis Sparse Model. IEEE Trans. Signal Process. 2012, 61, 661–677. [Google Scholar] [CrossRef] [Green Version]
- Rubinstein, R.; Faktor, T.; Elad, M. K-SVD dictionary-learning for the analysis sparse model. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 5405–5408. [Google Scholar]
- Wen, B.; Ravishankar, S.; Bresler, Y. Learning Overcomplete Sparsifying Transforms With Block Cosparsity. In Proceedings of the ICIP, Paris, France, 27–30 October 2014. [Google Scholar]
- Ravishankar, S.; Bresler, Y. Learning Sparsifying Transforms. IEEE Trans. Signal Process. 2013, 61, 1072–1086. [Google Scholar] [CrossRef]
- Parekh, A.; Selesnick, W. Convex Denoising using Non-Convex Tight Frame Regularization. IEEE Signal Process. Lett. 2015, 22, 1786–1790. [Google Scholar] [CrossRef] [Green Version]
- Lin, J.; Li, S. Sparse recovery with coherent tight frames via analysis Dantzig selector and analysis LASSO. Appl. Comput. Harmon. Anal. 2014, 37, 126–139. [Google Scholar] [CrossRef]
- Liu, Y.; Zhan, Z.; Cai, J.; Guo, D.; Chen, Z.; Qu, X. Projected Iterative Soft-Thresholding Algorithm for Tight Frames in Compressed Sensing Magnetic Resonance Imaging. IEEE Trans. Med. Image 2016, 35, 2130–2140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chan, H.; Riemenschneider, D.; Shen, L.; Shen, A.Z. Tight frame: An efficient way for high-resolution image reconstruction. Appl. Comput. Anal. 2004, 17, 91–115. [Google Scholar] [CrossRef] [Green Version]
- Ron, A.; Shen, Z. Affine system in L2(Rd): The analysis of the analysis operator. J. Funct. Anal. 2013, 148, 408–447. [Google Scholar] [CrossRef] [Green Version]
- Candes, E. Ridgelets: Estimating with ridge functions. Ann. Statist. 1999, 31, 1561–1599. [Google Scholar] [CrossRef]
- Candes, E.J.; Donoho, D.L. Recovering edges in ill-posed inverse problems: Optimality of curvelet frames. Ann. Statist. 2002, 30, 784–842. [Google Scholar] [CrossRef]
- Kutyniok, G.; Labate, D. Construction of regular and irregular shearlet frames. J. Wavelet Theory Appl. 2007, 1, 1–10. [Google Scholar]
- Casazza, P.G.; Kutyniok, G.; Philipp, A.F. Introduction to Finite Frame Theory. In Finite Frames; Birkhäuser: Boston, MA, USA, 2012. [Google Scholar]
- Cao, C.; Gao, X. Compressed sensing image restoration based on data-driven multi-scale tight frame. J. Comput. Appl. Math. 2017, 309, 622–629. [Google Scholar] [CrossRef]
- Li, J.; Zhang, W.; Zhang, H.; Li, L.; Yan, A. Data driven tight frames regularization for few-view image reconstruction. In Proceedings of the 13th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery, ICNC-FSKD 2017, Guilin, China, 29–31 July 2017; pp. 815–820. [Google Scholar]
- Cai, J.; Ji, H.; Shen, Z.; Ye, G. Data-driven tight frame construction and image denoising. Appl. Comput. Harmon. Anal. 2014, 37, 89–105. [Google Scholar] [CrossRef]
- Rubinstein, R.; Zibulevsky, M.; Elad, M. Efficient Implementation of the K-SVD Algorithm Using Batch Orthogonal Matching Pursuit; Technical Report CS-2008-08; Technion-Israel Institute of Technology: Haifa, Israel, 2008. [Google Scholar]
- Katkovnik, V.; Foi, A.; Egiazarian, K.; Astola, J. From local kernel to nonlocal multiple-model image denoising. Int. J. Comput. Vis. 2010, 86, 1–32. [Google Scholar] [CrossRef] [Green Version]
- Gu, S.; Zhang, L.; Zuo, W.; Feng, X. Weighted Nuclear Norm Minimization with Application to Image Denoising. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2862–2869. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image | Barbara | Boat | Couple | Hill | Lena | Man | Average | |
|---|---|---|---|---|---|---|---|---|
| 20 | K-SVD [14] | 31.01 | 30.50 | 30.15 | 30.27 | 32.51 | 30.26 | 30.78 |
| T.KSVD [3] | 30.02 | 29.30 | 29.25 | 29.21 | 31.45 | 29.01 | 29.71 | |
| DTF [33] | 31.07 | 30.35 | 30.20 | 30.31 | 32.56 | 30.07 | 30.76 | |
| SSM-NTF | 31.01 | 30.47 | 30.24 | 30.34 | 32.50 | 30.23 | 30.80 | |
| BM3D [35] | 32.01 | 31.02 | 30.88 | 30.85 | 33.19 | 30.83 | 31.47 | |
| WNNM [36] | 32.31 | 31.09 | 30.92 | 30.94 | 33.18 | 30.84 | 31.55 | |
| 30 | K-SVD [14] | 28.75 | 28.60 | 28.07 | 28.51 | 30.59 | 28.43 | 28.83 |
| T.KSVD [3] | 27.78 | 27.86 | 27.46 | 27.23 | 29.25 | 27.13 | 27.79 | |
| DTF [33] | 29.07 | 28.48 | 28.22 | 28.64 | 30.60 | 28.26 | 28.88 | |
| SSM-NTF | 29.00 | 28.63 | 28.24 | 28.66 | 30.73 | 28.49 | 28.96 | |
| BM3D [35] | 30.12 | 29.22 | 28.95 | 29.23 | 31.40 | 29.04 | 29.66 | |
| WNNM [36] | 30.32 | 29.30 | 29.02 | 29.33 | 31.50 | 29.10 | 29.76 | |
| 40 | K-SVD [14] | 27.03 | 27.23 | 26.54 | 27.23 | 29.13 | 27.17 | 27.39 |
| T.KSVD [3] | 26.35 | 26.45 | 25.98 | 26.45 | 28.20 | 26.14 | 26.60 | |
| DTF [33] | 27.58 | 27.20 | 26.87 | 27.49 | 29.25 | 26.99 | 27.56 | |
| SSM-NTF | 27.50 | 27.39 | 27.00 | 27.56 | 29.35 | 27.34 | 27.69 | |
| BM3D [35] | 28.68 | 27.92 | 27.58 | 28.08 | 30.11 | 27.83 | 28.37 | |
| WNNM [36] | 28.85 | 27.99 | 27.64 | 28.18 | 30.25 | 27.90 | 28.47 | |
| 50 | K-SVD [14] | 25.71 | 26.05 | 25.42 | 26.29 | 27.92 | 26.18 | 26.26 |
| T.KSVD [3] | 25.10 | 25.56 | 25.03 | 25.89 | 27.01 | 25.40 | 25.67 | |
| DTF [33] | 26.45 | 26.15 | 25.84 | 26.63 | 28.15 | 26.09 | 26.55 | |
| SSM-NTF | 26.43 | 26.32 | 25.99 | 26.79 | 28.40 | 26.40 | 26.72 | |
| BM3D [35] | 27.48 | 26.89 | 26.49 | 27.20 | 29.06 | 26.94 | 27.34 | |
| WNNM [36] | 27.70 | 26.97 | 26.60 | 27.35 | 29.23 | 27.01 | 27.48 | |
| 60 | K-SVD [14] | 24.45 | 25.18 | 24.57 | 25.69 | 27.01 | 25.40 | 25.38 |
| T.KSVD [3] | 24.50 | 24.88 | 24.36 | 25.40 | 26.60 | 24.78 | 25.09 | |
| DTF [33] | 25.64 | 25.33 | 25.04 | 25.91 | 27.22 | 25.38 | 25.75 | |
| SSM-NTF | 25.50 | 25.45 | 25.14 | 26.03 | 27.33 | 25.67 | 25.85 | |
| BM3D [35] | 26.36 | 26.02 | 25.61 | 26.44 | 28.14 | 26.18 | 26.46 | |
| WNNM [36] | 26.59 | 26.12 | 25.74 | 26.60 | 28.33 | 26.26 | 26.61 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Shi, Y.; Qi, N.; Yin, B. Data-Driven Redundant Transform Based on Parseval Frames. Appl. Sci. 2020, 10, 2891. https://doi.org/10.3390/app10082891
Zhang M, Shi Y, Qi N, Yin B. Data-Driven Redundant Transform Based on Parseval Frames. Applied Sciences. 2020; 10(8):2891. https://doi.org/10.3390/app10082891
Chicago/Turabian StyleZhang, Min, Yunhui Shi, Na Qi, and Baocai Yin. 2020. "Data-Driven Redundant Transform Based on Parseval Frames" Applied Sciences 10, no. 8: 2891. https://doi.org/10.3390/app10082891
APA StyleZhang, M., Shi, Y., Qi, N., & Yin, B. (2020). Data-Driven Redundant Transform Based on Parseval Frames. Applied Sciences, 10(8), 2891. https://doi.org/10.3390/app10082891