1. Introduction
The classical
closed loop variant of
travelling salesman problem (TSP) visits all the nodes and then returns to the start node by minimizing the length of the tour.
Open loop TSP is slightly different variant, which skips the return to the start node. They are both NP-hard problems [
1], which means that finding optimal solution fast can be done only for very small size inputs.
The open loop variant appears in mobile-based orienteering game called
O-Mopsi (
http://cs.uef.fi/o-mopsi/) where the goal is to find a set of real-world
targets with the help of smartphone navigation [
2]. This includes three challenges: (1) Deciding the order of visiting the targets, (2) navigating to the next target, and (3) physical movement. Unlike in classical orienteering where the order of visiting the targets is fixed, O-Mopsi players optimize the order while playing. Finding the optimal order is not necessary but desirable if one wants to minimize the tour length. However, the task is quite challenging for humans even for short problem instances. In [
2], only 14% of the players managed to solve the best order among those who completed the tour. Most players did not even realize they were dealing with TSP problem.
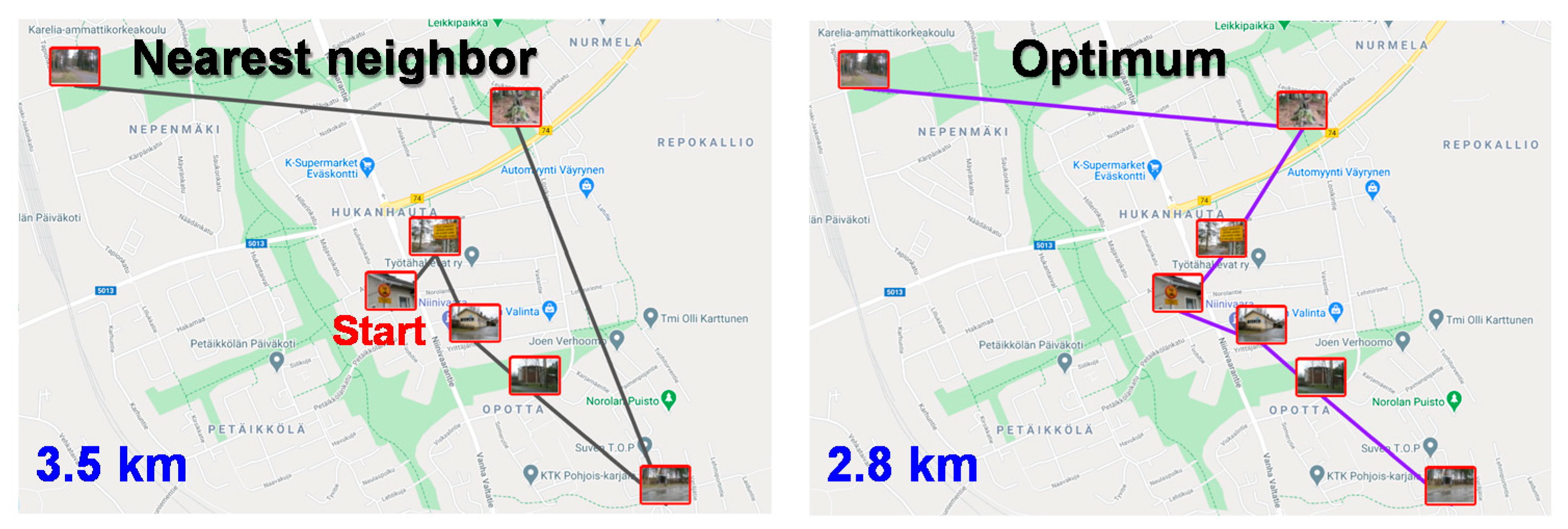
Minimum spanning tree (MST) and TSP are closely related algorithmic problems. In specific, open loop TSP solution is also a spanning tree but not necessarily the minimum spanning tree; see
Figure 1. The solutions have the same number of links (
n 1) and they both minimize the total weight of the selected links. The difference is that TSP does not have any branches. This connection is interesting for two reasons. First, finding optimal solution for TSP requires exponential time while optimal solution for MST can be found in polynomial time using greedy algorithms like
Prim and
Kruskal, with time complexity very close to O(
n2) with appropriate data structure.
The connection between the two problems have inspired researchers to develop heuristic algorithms for the TSP by utilizing the minimum spanning tree. Classical schoolbook algorithm is
Christofides [
3,
4], which first creates an MST. More links are then added so that the Euler tour can be constructed. Travelling salesman tour is obtained from the Euler tour by removing nodes that are visited repeatedly. This algorithm is often used as classroom example because it provides upper limit how far the solution can be from the optimal solution in the worst case. Even if the upper limit, 50%, is rather high for real life applications, it serves as an example of the principle of
approximation algorithms.
MST has also been used to estimate lower limit for the optimal TSP solution in [
5], and to estimate the difficulty of a TSP instance by counting the number of branches [
6]. Prim’s and Kruskal’s algorithms can also been modified to obtain sub-optimal solutions for TSP. Class of
insertion algorithms were studied in [
7]. They iteratively add new nodes to the current path. The variant that adds a new node to either end of the existing path can be seen as modification of the Prim’s algorithm where additions are allowed only to the ends of the path. Similarly, algorithm called
Kruskal-TSP [
8] modifies Kruskal’s algorithm so that it allows to merge two spanning trees (paths in case of TSP) only by their end points.
In this paper, we introduce a more sophisticated approach to utilize the minimum spanning tree to obtain solution for travelling salesman problem. The algorithm, called
MST-to-TSP, creates a minimum spanning tree using any algorithm such as Prim or Kruskal. However, instead of adding redundant links like Chirstofides, we detect branching nodes and eliminate them by a series of link swaps, see
Figure 2.
Branching node is a node that connects more than two other nodes in the tree [
6]. We introduce two strategies. First, a simple
greedy variant removes the longest of all links connecting to any of the branching nodes. The resulting sub-trees are then reconnected by selecting the shortest link between leaf nodes. The second strategy,
all-pairs, considers all possible removal and reconnection possibilities and selects the best pair.
We test the algorithm with two datasets consisting of open loop problem instances with known ground truth: O-Mopsi [
2] and Dots [
9]. Experiments show that the all-pairs variant provide average gaps of 1.69% (O-Mopsi) and 0.61% (Dots). These are clearly better than those of the existing MST-based variants including Christofides (12.77% and 9.10%), Prim-TSP (6.57% and 3.84%), and Kruskal-TSP (4.87% and 2.66%). Although sub-optimal, the algorithm is useful to provide reasonable estimate for the TSP solution. It is also not restricted to complete graphs with triangular inequality like Christofides. In addition, we also test repeated randomized variant of the algorithm. It reaches results very close to the optimum; averages of 0.07% (O-Mopsi) and 0.02% (Dots).
One of the main motivations for developing heuristics algorithms earlier has been to have a polynomial time approximation algorithm for TSP. Approximation algorithms guarantee that the gap between the heuristic and optimal results has a proven upper limit but these limits are usually rather high: 67% [
10], 62% [
11], 50% [
4], 50%-ε [
12], and 40% [
13]. The variant in [
14] was speculated to have limit as low as 25% based on empirical observations. The results generalize to the open-loop case so that if there exists α-approximation for the closed-loop TSP there exists α+ε approximation for the open-loop TSP [
15,
16]. However, for practical purpose, all of these are high. Gaps between 40% to 67% are likely to be considered insufficient for industrial applications.
The second motivation for developing heuristic algorithms is to provide initial solution for more complex algorithms. For example, the efficiency of local search and other metaheuristics highly depends on the initial solution. Starting from a poor-quality solution can lead to much longer iterations, or even prevent reaching a high-quality solution with some methods. Optimal algorithms like branch-and-cut also strongly depend on the quality of initialization. The better the starting point, the more can be cut out by branch-and-cut. One undocumented rule of thumb is that the initial solution should be as good as ~1% gap in order to achieve significant savings compared to exhaustive search.
The rest of the paper is organized as follows.
Section 2 reviews the existing algorithms focusing on the those based on minimum spanning tree. The new MST-to-TSP algorithm is then introduced in
Section 3. Experimental results are reported in
Section 4 and conclusions drawn in
Section 5.
2. Heuristic Algorithms for TSP
We review the common heuristic found in literature. We consider the following algorithms:
Nearest neighbor [
17,
18].
Nearest neighbor (NN) is one of the oldest heuristic methods [
17]. It starts from random node and then constructs the tour stepwise by always visiting the nearest unvisited node until all nodes have been reached. It can lead to inferior solutions like 25% worse than the optimum in the example in
Figure 3. The nearest neighbor strategy is often applied by human problem solvers in real-world environment [
6]. A variant of nearest neighbor in [
18] always selects the shortest link as long as new unvisited nodes are found. After that, it switches to the greedy strategy (see below) for the remaining unvisited nodes. In [
9], the NN-algorithm is repeated
N times starting from every possible node, and then selecting the shortest tour of all
n alternatives. This simple trick would avoid the poor choice shown in
Figure 3. In [
14], the algorithm is repeated using all possible
links as the starting point instead of all possible nodes. This increases the number of choices up to
n*(
n-1) in case of complete graph.
Greedy method [
17,
18] always selects the unvisited node having shortest link to the current tour. It is similar to the nearest neighbor except that it allows to add the new node to both ends of the existing path. We call this as
Prim-TSP because it constructs the solution just like Prim except it does not allow branches. In case of complete graphs, nodes can also be added in the middle of the tour by adding a detour via the newly added node. A class of
insertion methods were studied in [
7] showing that the resulting tour is no longer than twice of the optimal tour.
Kruskal-TSP [
8] also constructs spanning tree like Prim-TSP. The difference is that while Prim operates on a single spanning tree, Kruskal operates on a set of trees (spanning forest). It therefore always selects the shortest possible link as long as they merge to different spanning trees. To construct TSP instead of MST, it also restricts the connections only to the end points. However, while Prim-TSP has only two possibilities for the next connection, Kruskal-TSP has potentially much more; two for every spanning tree in the forest. It is therefore expected to make fewer sub-optimal selections, see
Figure 4 for an example. The differences between NN, Prim-TSP, and Kruskal-TSP are illustrated in
Figure 5.
Classical Christofides algorithm [
3,
4] includes three steps: (1) Create MST, (2) add links and create Euler tour, and (3) remove redundant paths by shortcuts. Links are added by detecting nodes with odd degree and creating new links between them. If there are
n nodes with odd degree (
odd nodes), then
n/2 new links are added. To minimize the total length of the additional links, perfect matching can be solved by
Blossom algorithm, for instance [
20]. Example of Christofides is shown in
Figure 6. In [
12], a variant of Christofides was proposed by generating alternative spanning tree that has higher cost than MST but fewer odd nodes. According to [
21], this reduces the number of odd nodes from 36–39% to 8–12% in case of TSPLIB and VLSI problem instances.
Most of the above heuristics apply both to the closed-loop and open-loop cases. Prim and Kruskal are even better suited for the open-loop cases as the last link in the closed loop case is forced and is typically a very long, sub-optimal choice. Christofides, on the other hand, was designed strictly for the closed-loop case due to the creation of the Euler tour. It therefore does not necessarily work well for the open-loop case, which can be significantly worse.
There are two strategies how to create open-loop solution from a closed-loop solution. A simple approach is to remove the longest link, but this does not guarantee an optimal result; see
Figure 7. Another strategy is to create additional
pseudo node, which has equal (large) distance to all other nodes [
9]. Any closed-loop algorithm can then be applied, and the optimization will be performed merely based on the other links except those two that will be connecting to the pseudo node which are all equal. These two will be the start and end nodes of the corresponding open-loop solution. If the algorithm provides optimal solution for the closed-loop problem, it was shown to be optimal also for the corresponding open-loop case [
1].
However, when heuristic algorithm is applied, the pseudo node strategy does may not always work as expected. First, if the weights to the pseudo node are small (e.g., zeros), then algorithms like MST would links all nodes to the pseudo node, which would make no sense for Christofides. Second, if we choose large weights to the pseudo node, it would be connected to MST last. However, as the weights are all equal, the choice would be arbitrary. As a result, the open loop case will not be optimized any better if we used the pseudo node than just removing the longest link. Ending up with a good open-loop solution by Christofides seems merely a question of luck. Nevertheless, we use the pseudo node strategy as it is the de facto standard due to it guaranteeing optimality for the optimal algorithm at least.
The existing MST-based algorithms take one of the two approaches: (1) Modify the MST solution to obtain TSP solution [
3,
4]; (2) modify the existing MST algorithm to design algorithm for TSP [
7,
8,
16,
17]. In this paper, we follow the first approach and take the spanning tree as our starting point.
Among other heuristics we mention
local search. It aims at improving an existing solution by simple operators. One obvious approach is
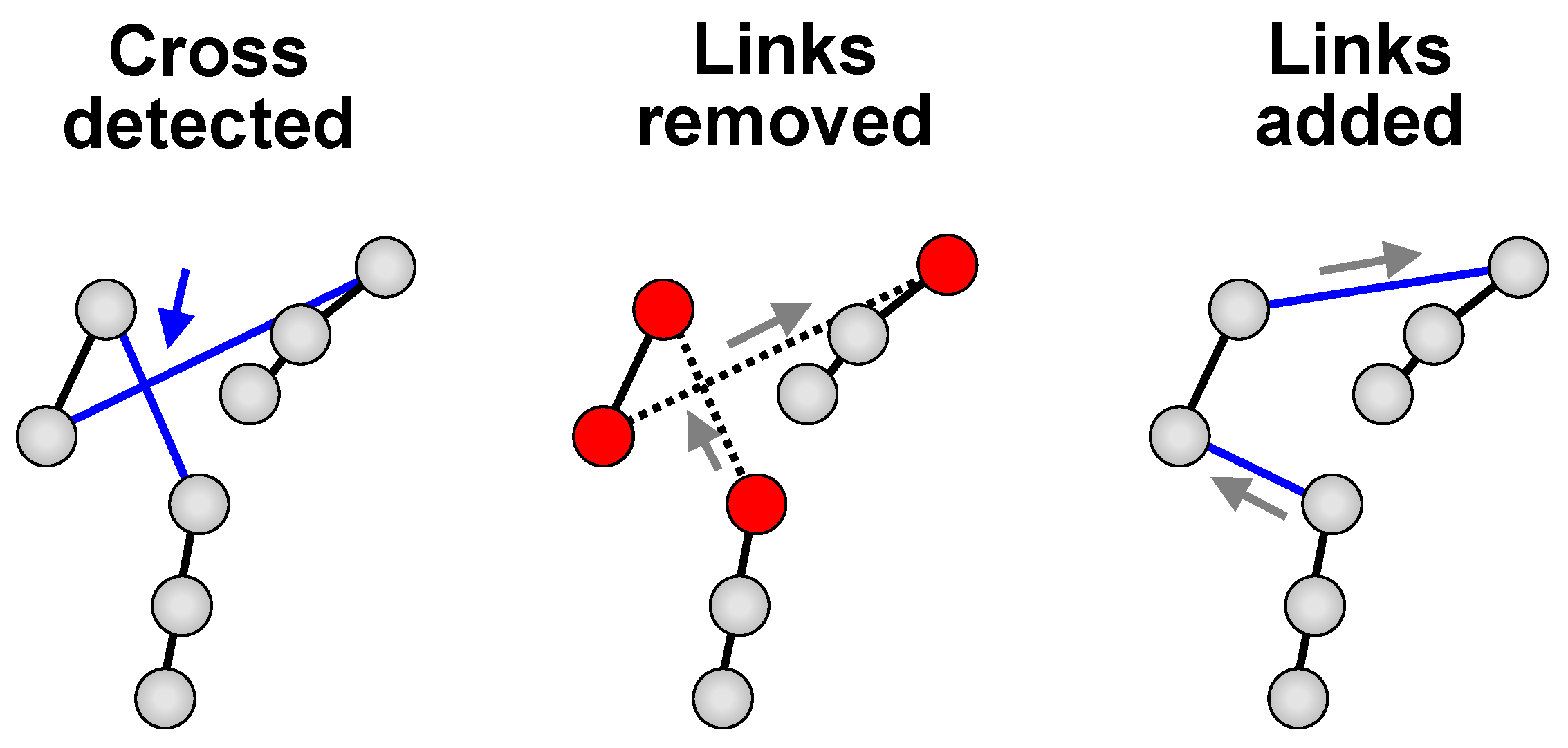
Cross removal [
19], which is based on the fact that optimal tour cannot cross itself. The heuristic simply detects any cross along the path, and if found, eliminates it by re-connecting the links involved as shown in
Figure 8. It can be shown that the cross removal is a special case of the more general
2-opt heuristic [
22]. Another well-known operator is
relocation that removes a node from the path and reconnects it to another part of the path. The efficiency of several operators has been studied in [
9] within an algorithm called
Randomized mixed local search.
While local search is still the state-of-the-art and focus has been mainly on operators such as 2-opt and its generalized variant
k-opt [
23,
24], other metaheuristics have been also considered. These include
tabu search [
25],
simulated annealing and combined variants [
26,
27,
28],
genetic algorithm [
29,
30],
ant colony optimization [
31], and
harmony search [
32].
3. MST-to-TSP Algorithm
The proposed algorithm resembles Christofides as it also generates minimum spanning tree to give first estimate of the links that might be needed in TSP. Since we focus on the open-loop variant, it is good to notice that the TSP solution is also a spanning tree, although not the minimum one. However, while Christofides adds redundant links to create Euler tour, which are then pruned by shortcuts, we do not add anything. Instead, we change existing links by a series of link swaps. In specific, we detect branches in the tree and eliminate them one by one. This is continued until the solution becomes a TSP path; i.e., spanning tree without any branches. Pseudo codes of the variants are sketched in Algorithm1 and Algorithm2.
| Algorithm 1: Greedy variant |
MST-to-TSP(X) → TSP:
T ← GenerateMST(X);
WHILE branches DO
e1 ← LongestBranchLink(T);
e2 ← ShortestConnection(T);
T ← SwapLink(T, e1, e2);
RETURN(T); |
| Algorithm 2:All-pairs variant |
MST-to-TSP(X) → TSP:
T ← GenerateMST(X);
WHILE branches DO
e1, e2← OptimalPair(T);
T ← SwapLink(e1, e2);
RETURN(T); |
Both variants start by generating minimum spanning tree by any algorithm such as Prim and Kruskal. Prim grows the tree from scratch. In each step, it selects the shortest link that connects a new node to the current tree while Kruskal grows a forest by selecting shortest link that connects two different trees. Actually, we do not need to construct
minimum spanning tree, but some sub-optimal spanning tree might also be suitable [
33]. For Christofides, it would be beneficial to have a tree with fewer nodes with odd degree [
12]. In our algorithm, having spanning tree with fewer branches might be beneficial. However, to keep the algorithm simple, we do not study this possibility further in this paper.
Both variants operate on the branches, which can be trivially detected during the creation of MST simply by maintaining the degree counter when links are added. Both algorithms also work sequentially by resolving the branches one by one. They differ only in the way the two links are selected for the next swap; all other parts of the algorithm variants are the same. The number of iterations equals the number of branches in the spanning tree. We will next study the details of the two variants.
3.1. Greedy Variant
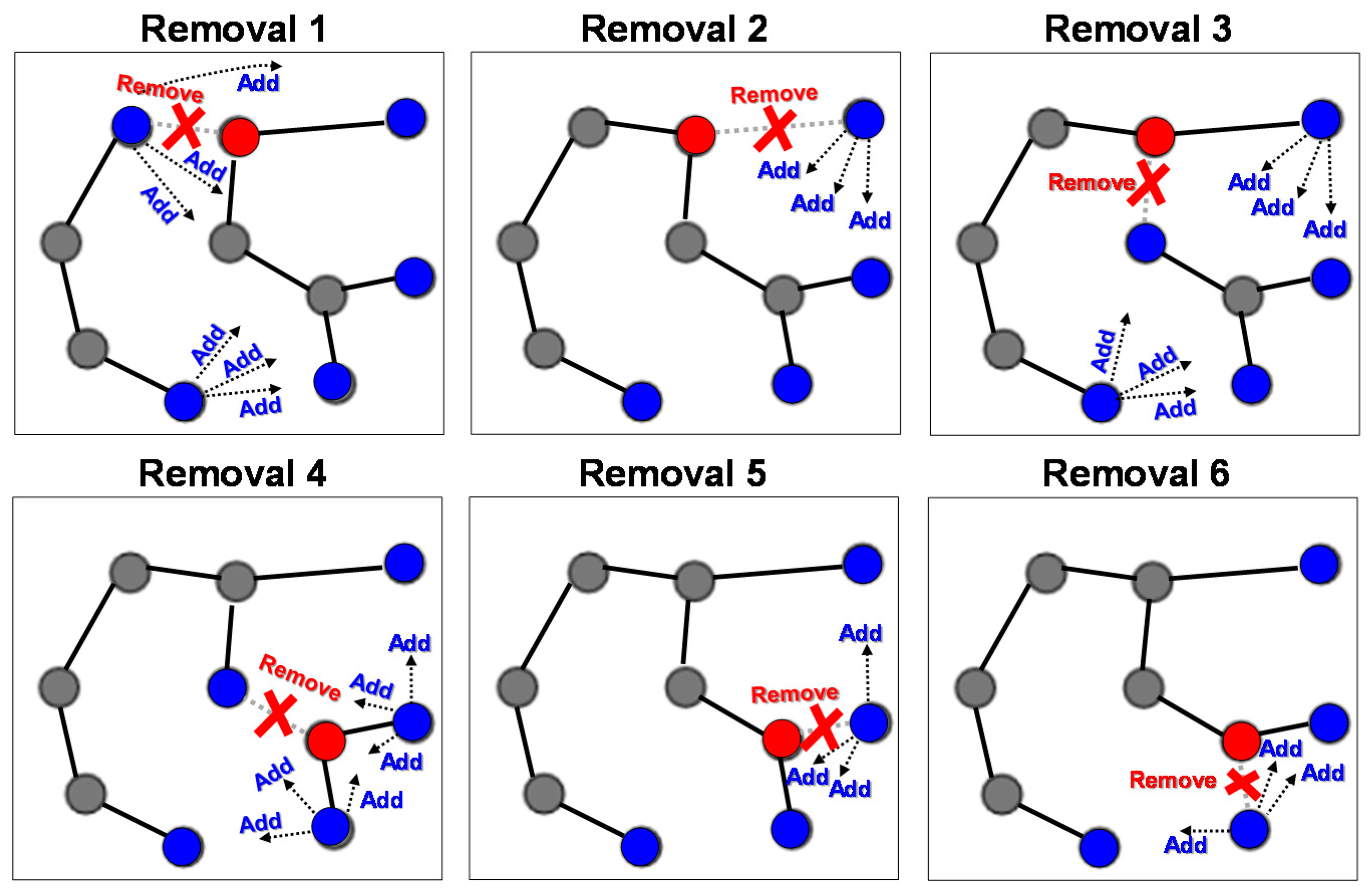
The simpler variant follows the spirit of Prim and Kruskal in a sense that it is also greedy. The selection is split into two subsequent choices. First, we consider all links connecting to any branching node, and simply select the longest. This link is then removed. As a result, we will have two disconnected trees. Second, we reconnect the trees by considering all pairs of leaf nodes so that one is from the first subtree and the other from the second subtree. The shortest link is selected.
Figure 9 demonstrates the algorithm for a graph with
n = 10 nodes. In total, there are two branching nodes and six links attached to them. The first removal creates subtrees of size
n1 = 9 (3 leaves) and
n2 = 1 (1 leaf) providing 3 possibilities for the re-connection. The second removal creates subtrees of size
n1 = 6 (2 leaves) and
n2 = 4 (2 leaves). The result is only slightly longer than the minimum spanning tree.
3.2. All-Pairs Variant
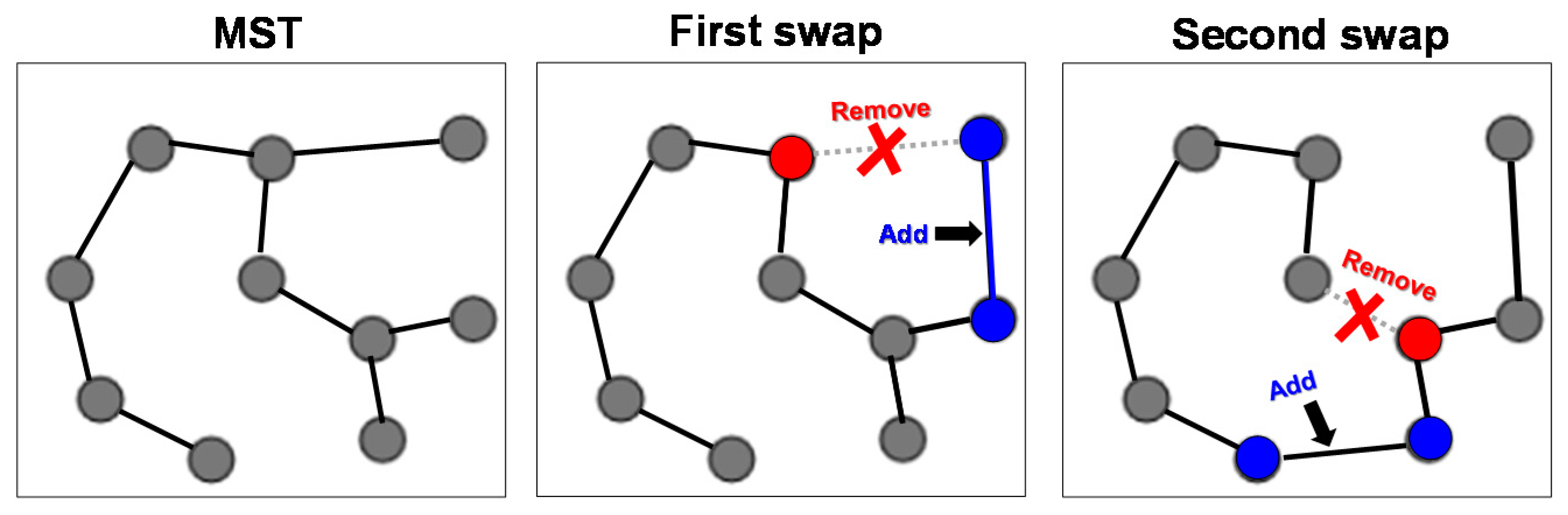
The second variant optimizes the removal and addition jointly by considering all pairs of links that would perform a valid swap.
Figure 10 demonstrates the process. There are 6 removal candidates, and they each have 3–6 possible candidates for the addition. In total, we have 27 candidate pairs. We choose the pair that increases the path length least. Most swaps increase the length of the path but theoretically it is possible that some swap might also decrease the total path; this is rare though.
The final result is shown in
Figure 11. With this example, the variant finds the same solution as the as the greedy variant. However, the
parallel chains example in
Figure 12 shows situation where the All-pairs variant works better than the greedy variant.
Figure 13 summarizes the results of the main MST-based algorithms. Nearest neighbor works poorly because it depends on the arbitrary start point. If considered all possible start points, it would reach the same result as Prim-TSP, Kruskal-TSP and the greedy variant of MST-to-TSP. In this example, the all-pairs variant of MST-to-TSP is the only heuristic that finds the optimal solution, which includes the detour in the middle of the longer route.
There are (2 3) + (1 3) + (2 3) + (2 3) + (1 3) + (1 3) = 27 candidates in total.
3.3. Randomized Variant
The algorithm can be further improved by repeating it several times. This improvement is inspired by [
34] where k-means clustering algorithm was improved significantly by repeating it 100 times. The only requirement is that the creation of the initial solution includes randomness so that it produces different results every time. In our randomized variant, the final solution is the best result out of the 100 trials. The idea was also applied for the Kruskal-TSP and called
Randomized Kruskal-TSP [
8].
There are several ways how to randomize the algorithm. We adopt the method from [
8] and randomize the creation of MST. When selecting the next link for the merge, we randomly choose one out of the three shortest links. This results in sub-optimal choices. However, as we have a complete graph, it usually has several virtually as good choices. Furthermore, the quality of the MST itself is not a vital for the overall performance of the algorithm; the branch elimination plays a bigger role than the MST. As a result, we will get multiple spanning trees producing different TSP solutions. Out of the 100 repeats, it is likely that one provides better TSP than using only the minimum spanning tree as starting point.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}