1. Introduction
Maintenance is a relevant factor for the competitiveness of an organization, since the actions carried out at this level have a direct impact on aspects such as the cost, deadlines and quality of the products produced or services provided [
1,
2]. Maintenance is a support to the operational area of a company and cannot be dissociated from it, given the implication it has in terms of the efficiency of productive assets. These two areas, operation and maintenance, must operate in parallel in order to guarantee the availability and the rapid response of human and material resources to operational problems, thus ensuring the achievement of objectives with the maximization of available resources. Thus, it becomes important not only to achieve the proposed objectives, but also to achieve them with the minimum consumption or use of resources [
2].
It is in this context of constant transformation that Industry 4.0 arises [
1]. Industry 4.0 implements the tools provided by advances in information and communication technologies in order to increase the levels of automation and digitalization in industrial and production processes [
1,
3]. The objective is to manage the entire value chain process, improving production efficiency and creating superior products and services. One of the key points of this technological evolution is the data, which is now more easily read, processed, stored, analyzed and shared between machines and human beings [
4]. Additionally, the Internet of Things (IoT) is defined as an ecosystem in which the objects and equipment inserted in it are equipped with sensors and other digital devices, thus being able to gather and exchange information with each other, in a networked system [
1].
In recent years, a drop in cost and an increase in the reliability of sensors, data transmission and storage devices have promoted the emergence of condition monitoring systems for industrial equipment. Simultaneously, the IoT allows real-time transmission of this information about the conditions of the systems captured by different monitoring devices. This development offers an excellent opportunity to use condition monitoring data intelligently within predictive maintenance, combining the ability to collect data with an effective and integrated analysis of it [
5].
In this sense, the potential of Artificial Intelligence tools, more specifically Machine Learning, allows us to aim for an improvement in the availability of systems, reducing maintenance costs, increasing operational performance and safety, and the ability to support decision making in relation to the ideal time and the ideal action for carrying out the maintenance intervention [
4,
5,
6,
7].
Machine Learning can be defined as “the field of study that gives the computer the ability to learn without being explicitly programmed”. It can be said that “Machine Learning algorithms use computational methods to learn information directly from data without using predefined equations as a model” [
8].
The main objective of this work is to apply Artificial Intelligence tools, more specifically Machine Learning, to a set of data, coming from different sources, available online [
9]. Furthermore, we seek to analyze the specificities of this implementation and the definition of methodologies, in order to provide information and tools to the maintenance area.
2. Machine Learning Process Workflow and Techniques
One of the main difficulties of applying a Machine Learning process to maintenance data is the choice of the right workflow, as in literature there are many different approaches to this problem, depending on the origin of the data and the objectives of the analysis [
10,
11,
12,
13]. As the different applications are difficult to compare, in this work it was decided to explore a simple but complete framework and to use a set of data that can be used by other researchers, as the data set is publicly available.
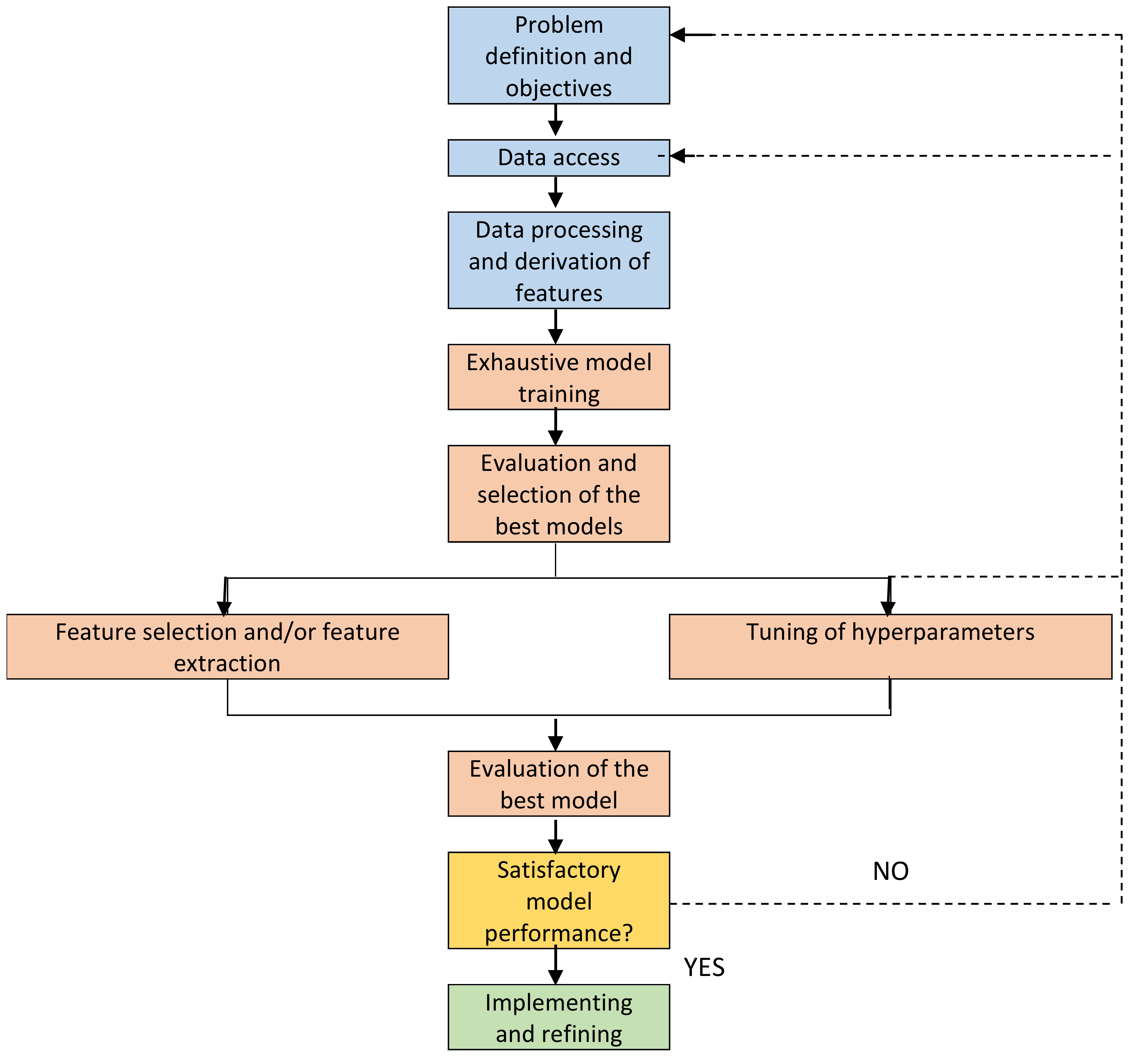
In the present work, the workflow presented in [
14], represented in
Figure 1, will be followed. From our point of view, a Machine Learning project must always start with the establishment of rigorous and clear definition of the objectives, since such a system fulfills a very specific task and the definition of vague objectives can mean that the model developed is not able to predict exactly what it is intended to.
Quite possibly, the most important part of a Machine Learning project is the ability to understand the data used and how it relates to the task we want to solve. It will not be effective to randomly choose an algorithm, use the data set we have available and expect good results [
15]. It is necessary to understand what is happening in the data set before starting to build a model. When building a Machine Learning solution, we must answer or at least keep in mind the following questions: What questions are we trying to answer? Does the available data set allow you to answer these questions? What is the best way to paraphrase my question as a Machine Learning problem? Is the available data set sufficient to represent the problem we are trying to solve? What features (or attributes) have been extracted and will they be able to lead to the correct predictions? How to measure the success of the application of Machine Learning? How will the Machine Learning solution interact with the rest of the process?
Machine Learning algorithms and methods are only part of a larger process for solving a specific problem, and it is important to keep that in mind. Sometimes, a lot of time is spent building complex Machine Learning solutions, only to discover in the end that they do not solve the problem that we were waiting for [
16]. By deepening the technical aspects of Machine Learning, it is easy to lose sight of the final goals. It is important to keep in mind all the assumptions created, either explicitly or implicitly, when building Machine Learning models.
Typical machine learning algorithms, such as the hidden Markov models [
17], hidden semi-Markov models [
18], self-organizing neural network [
19], SVM [
20], multimodal deep support vector classification [
21], deep random forest [
22], genetic algorithms [
23], blind source separation [
24], fuzzy logic [
25], k-nearest neighbor algorithms [
26] and Bayesian algorithms [
27], etc., have been applied in fault diagnosis of dynamic equipment. To the best of our knowledge, there are two main categories of approach for fault diagnosis of gearboxes: Data-driven and physical model-based methods. Although these methods have been successfully applied in many applications, it is very difficult to know what is the best algorithm to apply to a particular data set.
A systematic review of the scientific literature was carried out in [
28], from which it is possible to draw several conclusions. Predictive maintenance strategies are being applied to the most diverse equipment, in multiple areas. The equipment where these methods are applied include, but are not limited to, turbines, engines, compressors, pumps. About 89% of the published papers use a set of real data, with 11% using synthetic data. Regarding the use of Machine Learning algorithms in scientific publications, the most used is Random Forest (RF)—33%, followed by methods based on Neural Networks (NN), such as Artificial NN, Convolution NN, Long Short-Term Memory Metwork (LSTM) and Deep Learning—27%, Support Vector Machine (SVM)—25% and k-means—13%. There was also a greater tendency to use vibration signals.
3. Application Example
3.1. Data Applied
Throughout this paragraph, the process of implementing Machine Learning algorithms to a set of maintenance data will be detailed and explained.
First, the data set is presented and the choice is justified. Then, the objectives of this Machine Learning application are rigorously and clearly established. Subsequently, the data set is processed through feature engineering, creating new features in order to seek better performance from the models. The data set used is key to solving Machine Learning problems. A sensible choice of what data to use and how to handle it is crucial to improving the performance of the algorithms. According to Domingos [
29], feature engineering is the key to Machine Learning projects and that, often, the measured signals are not suitable for the learning process, and it is necessary to build features from those that are.
Then, the data set is divided into training, validation and testing subsets and the first application of Machine Learning models was carried out, where a variety of algorithms were trained and evaluated. The training process of the algorithms is carried out in the training subset and the validation subset provides an impartial assessment of the fit of the models to the training data, while simultaneously fine-tuning the model and its hyper-parameters in order to seek better performance. Finally, the test set is used to obtain an estimate of the model’s performance, simulating its behavior for future data.
The implementation described in this chapter will be carried out using the Python programming language, using the packages Matplotlib, Numpy, Pandas and Scikit-Learn [
30,
31].
3.2. Data Sources
Despite the growth of this area, due to business competitiveness, sharing sensitive information of this nature is rare, which means that the number of publicly available datasets (relevant to this application) is very scarce.
Within an industrial environment, there is a very complete data set, made available by Microsoft, published in [
9], of relevance to the present project.
This dataset contains data from five different sources:
The data were acquired over a year (2015) for one hundred machines, except for the maintenance history, which also contains records for the year 2014.
For a total of one hundred machines, from four different models, the data set contains 876,100 hourly telemetry records, that is, 8761 records per machine. The failure records contain 3919 entries and the maintenance history 3286. The failure history has 761 records, that is, on average, about 8 failure records per machine, throughout 2015. Each machine has 4 components of interest for analysis and also 4 sensors, which measure tension, pressure, vibration and rotation. A controller monitors the system and is able to alert you to the occurrence of 5 types of errors.
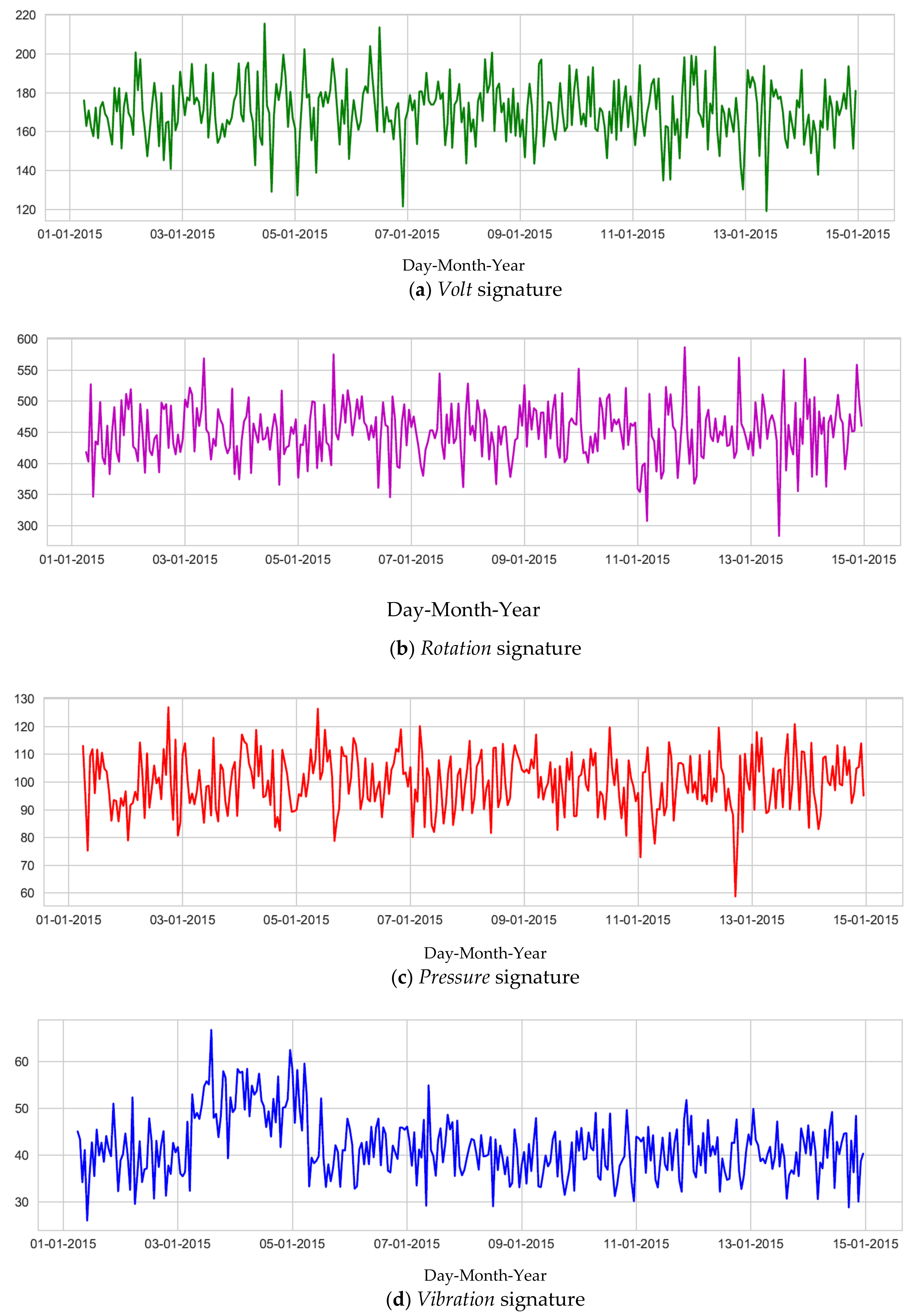
Thus, real-time telemetry data consists of measurements from different sensors (4 per machine), with the associated date and time. The measurements of voltage (“volt”), rotation (“rotate”), pressure (“pressure”) and vibration (“vibration”) are acquired in real time and the average of these measurements over an hour is recorded in
Table 1.
To better understand the behavior of each sensor, a simple statistical analysis is performed in
Table 2, where the mean, the standard deviation, and the minimum and maximum values are calculated for the parameters voltage (“volt”), rotation (“rotate”), pressure (“pressure”) and vibration (“vibration”) during 2015. As an example,
Figure 2 shows the graphical evolutions of the Tension signals (
Figure 2a), Rotation (
Figure 2b), Pressure (
Figure 2c) and Vibration (
Figure 2d), over the first fifteen days of January 2015, for machine 1 (machineID = 1).
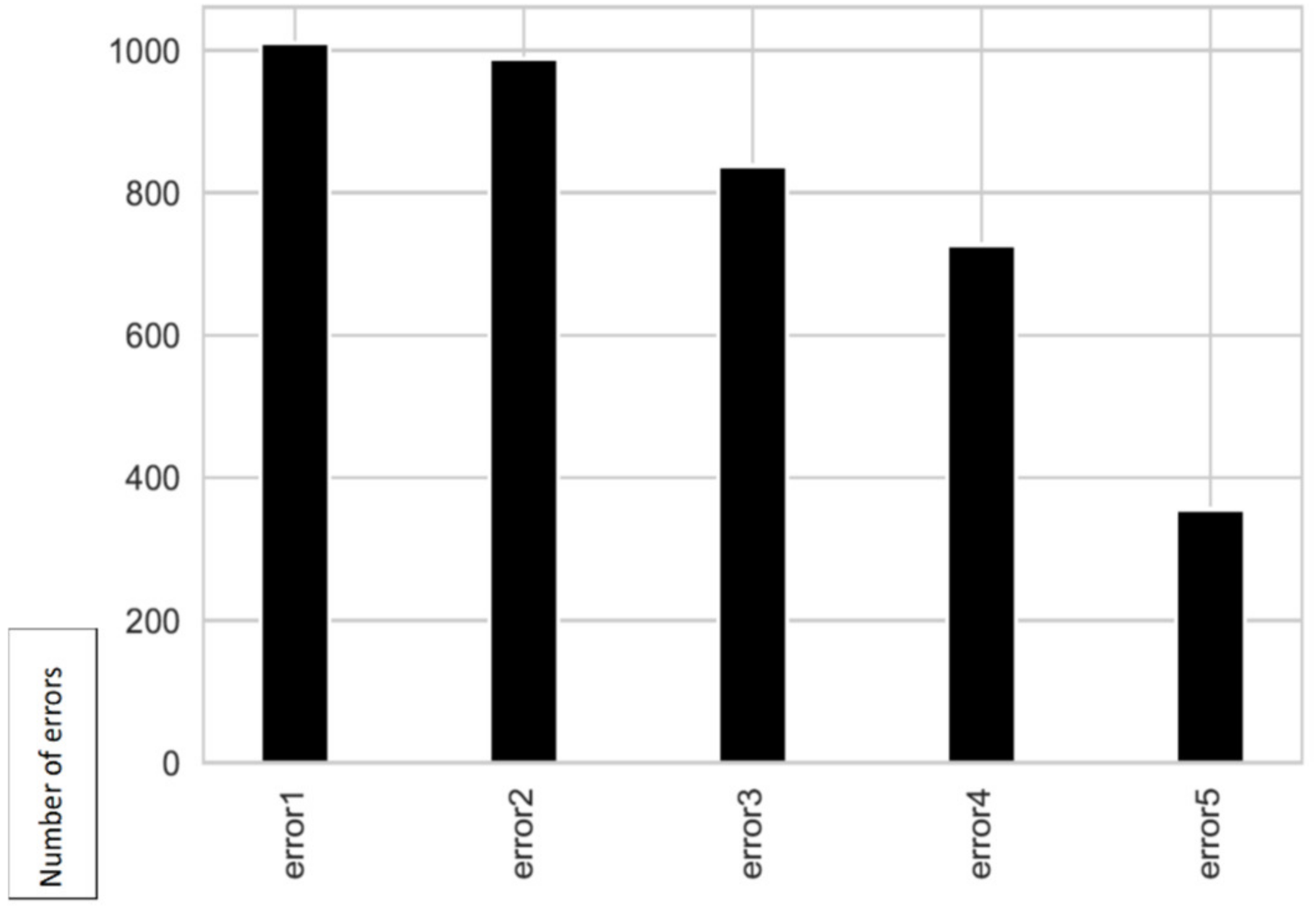
The second source of information is the error log. These are errors that did not immediately lead to a failure, as the machine remained operational. There are 5 types of errors: error1, error2, error3, error4, error5. The date and time are rounded to the nearest time. Each record consists of a date/time, machine and type of error—
Table 3. The total number of error records over the year 2015 is 3919. In
Figure 3 it is possible to observe the number of errors per type over the year 2015.
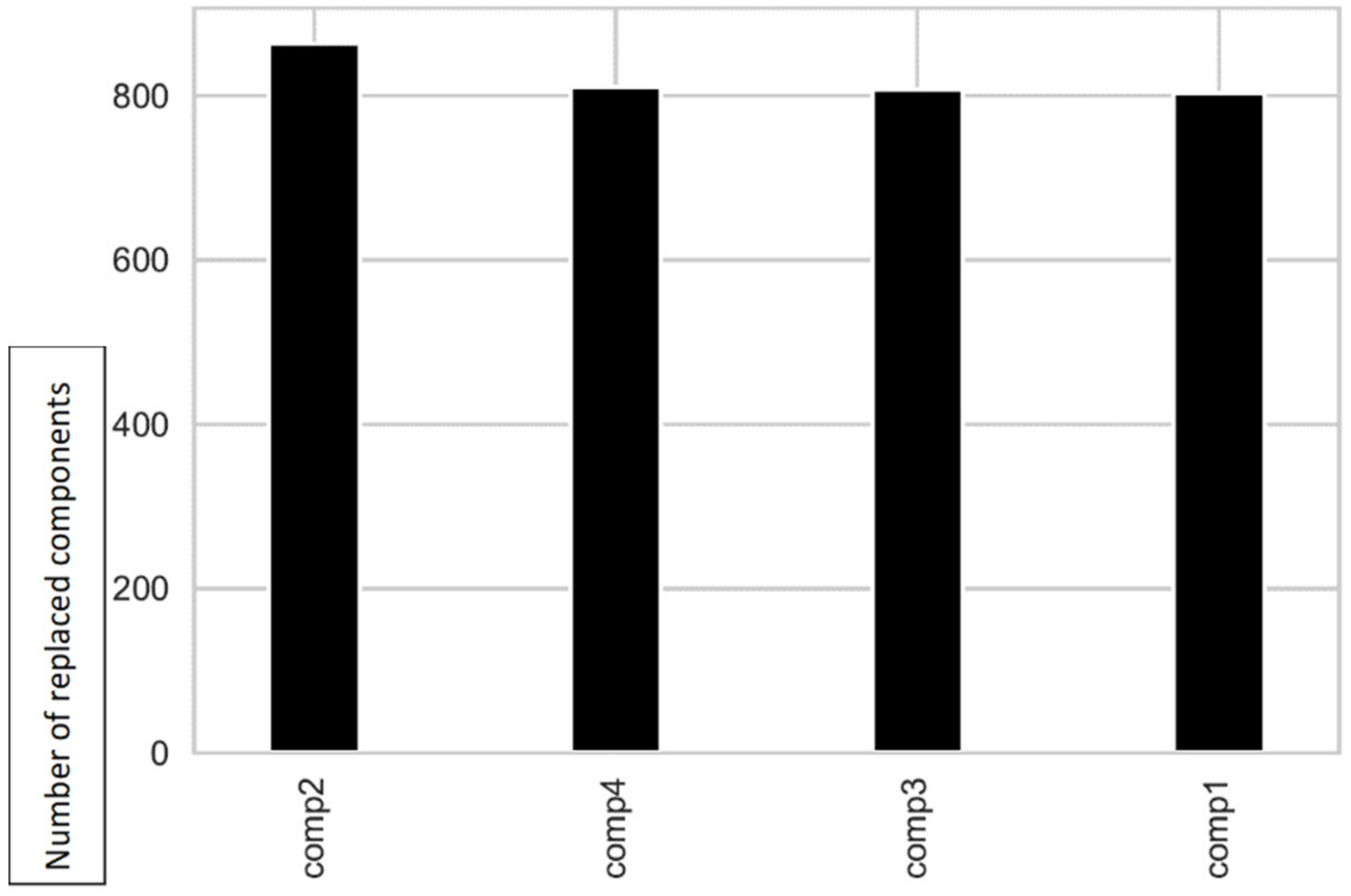
The maintenance records contain data of component replacements resulting from a scheduled or unscheduled maintenance intervention, periodic inspections, or performance degradation. In case of maintenance intervention due to the failure of a component, a fault record is also generated, see next paragraph. For each machine, this data set contains information about 4 types of components: comp1, comp2, comp3, comp4. The date and time are rounded to the nearest time. Each record consists of a date/time, machine and the type of component replaced—
Table 4. The total number of maintenance records throughout 2015 is 3286. As previously mentioned, the maintenance records also contain entries for 2014.
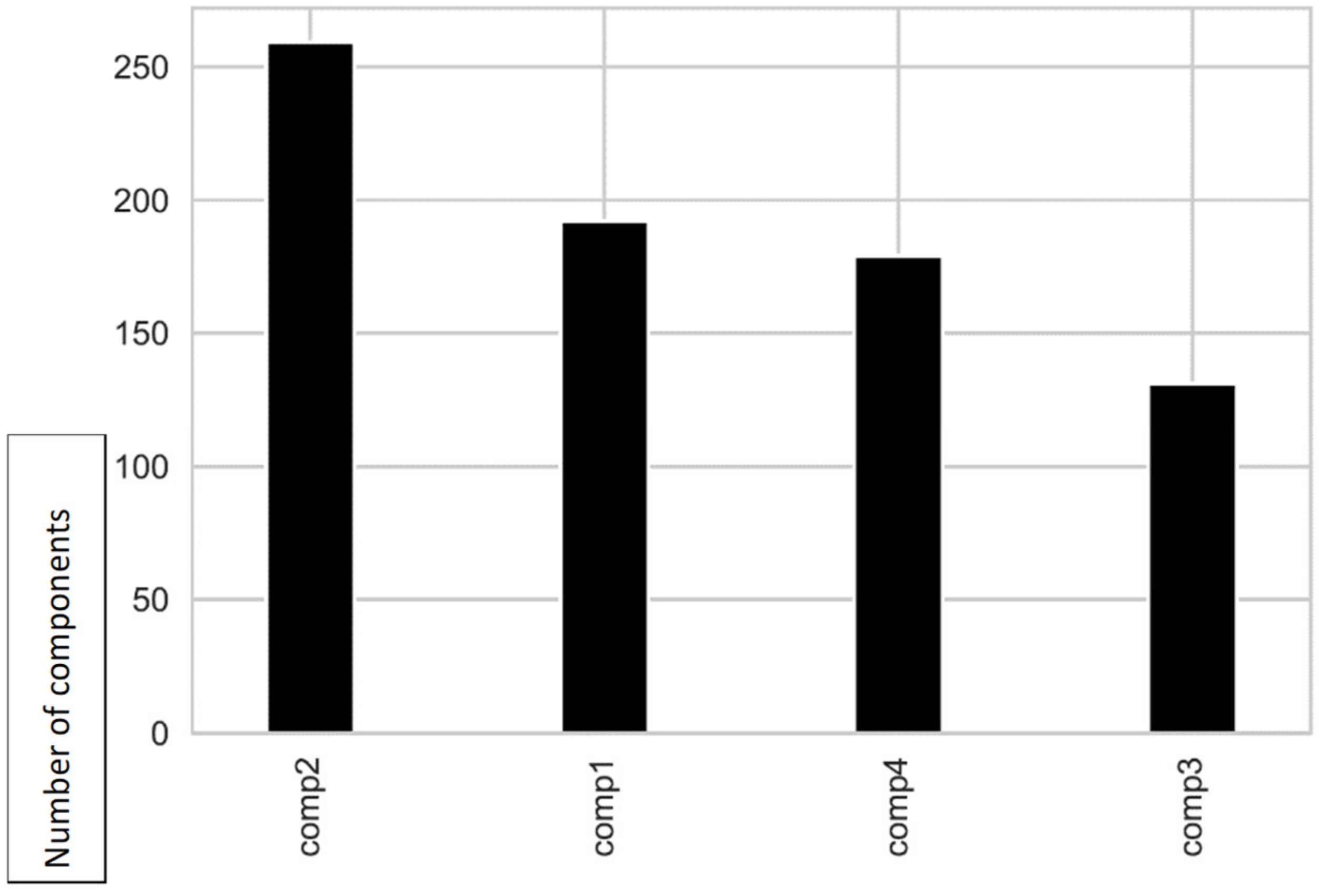
Figure 4 shows the number of components replaced, by type. It is possible to observe that in this case the number of substitutions is similar for the 4 types of components.
The fault records contain the component replacement records, resulting from the maintenance intervention, due to the occurrence of a fault. The data is for the 4 types of components: comp1, comp2, comp3, comp4. The date and time are rounded to the nearest time. Each record consists of a date/time, machine and the type of replaced component—
Table 5. The total number of failure records during 2015 is 761. In
Figure 5, it is possible to observe the number of replacements, by type of component, during 2015, due to the occurrence of a failure.
Finally, this data set contains information about the model and number of years of service for each of the 100 machines—
Table 6.
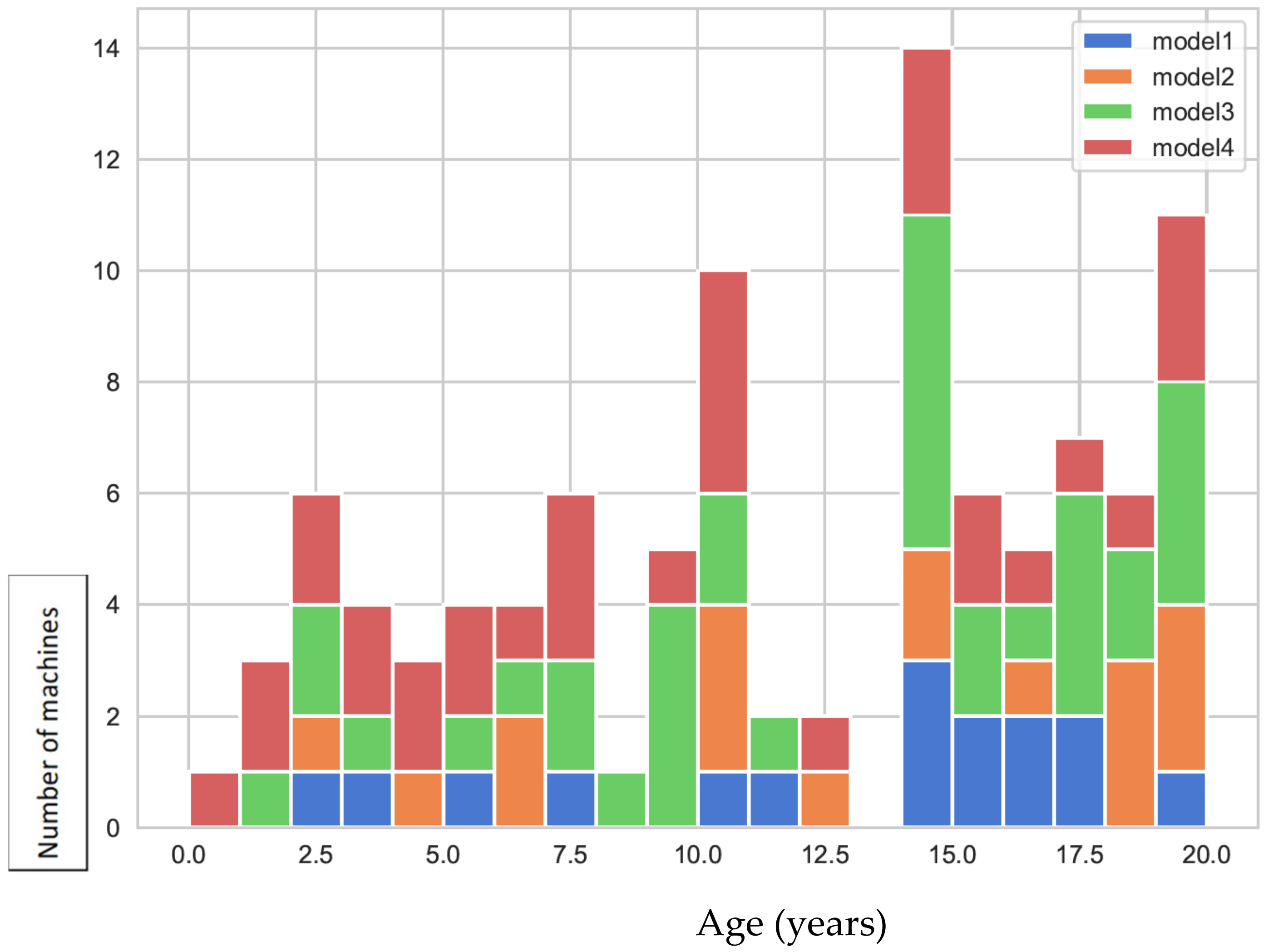
Figure 6 shows a histogram showing the distribution of the number of machines and service time, by model.
3.3. Definition of Objectives
As already mentioned, a Machine Learning project must start with the rigorous and clear establishment of objectives. In this case, the main objective of the models used will be to predict the probability of a failure occurring within the defined time window. More specifically, the probability of a machine failure occurring in the next 24 h (duration of the time window chosen for this application) related to one of the components (components 1, 2, 3 or 4).
Then, given that a particular and clear objective has already been set, more specific questions can be asked about Machine Learning itself: (1) Should supervised, unsupervised, or reinforcement learning models be chosen or, possibly, combinations of learning modes? (2) Whether supervised learning, classification, or regression? (3) Are models intended to train immediately as new data is obtained (batch learning or online learning)?
After analyzing the problem, and bearing in mind the proposed objective, we opted for supervised learning and, in particular, classification. Furthermore, taking into account the existence of 4 different components under analysis, the problem will be multi-class classification (“Multiclass Classification”). It was also considered that it will not be necessary, given the scope of the problem and the nature of the data, for models to train immediately as new data is obtained. Therefore, we are facing a problem of batch learning.
3.4. Feature Engineering
A feature is a predictive attribute for the model. The purpose of feature engineering is to seek to increase the predictive power of Machine Learning algorithms, creating new features from the available data. As a rule, feature engineering is carried out in the first place and then the selection of features occurs, eliminating irrelevant, redundant or highly correlated features. Starting from the different sources of information presented in the previous paragraphs, a single dataset will be created, which will be used for the application of predictive models.
The historical data that models have access to are individual moments in the past. In particular, for telemetry data, disturbances resulting from measurements, such as noise, are possible, thus making the predictive task more difficult. In this way, the data can be aggregated in time windows, thus allowing to “smooth” the values, minimizing the effects of noise on the features used by the models.
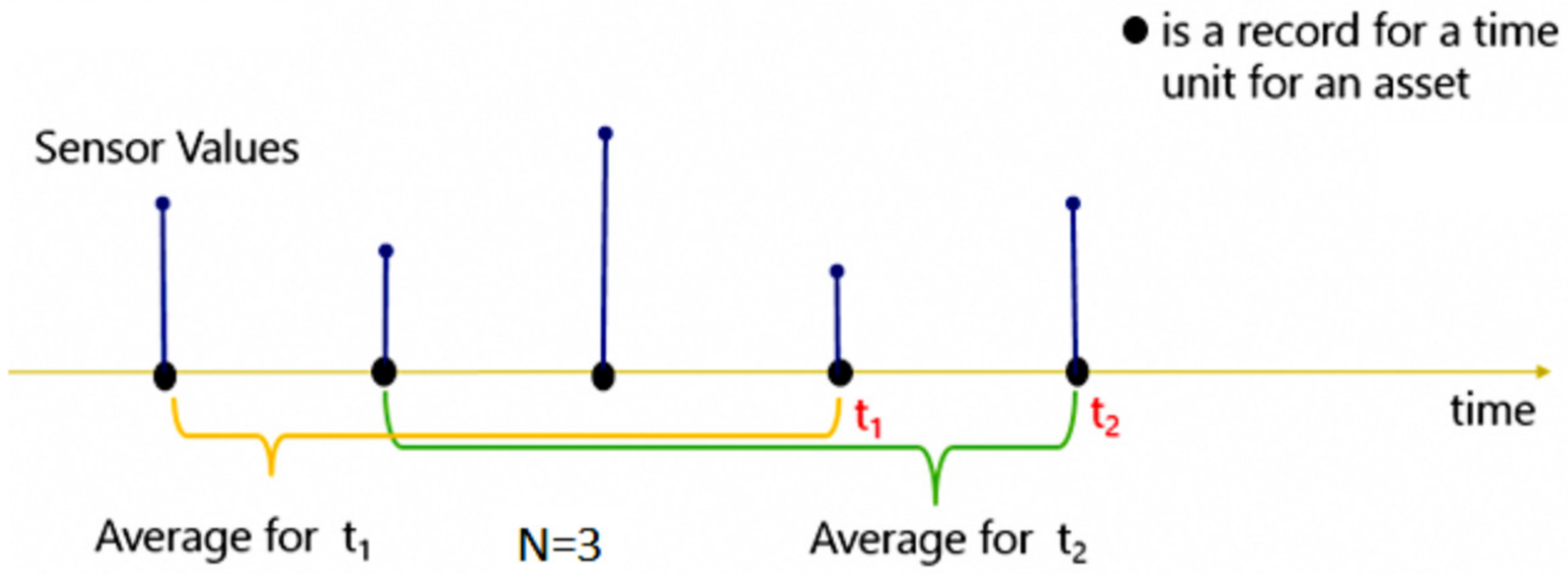
Bearing in mind how far in the future the model should be able to predict, according to the requirements of the project, it is important to define how far it should “look” to make these predictions. This interval of time passed to where the model should “look back” is called lag. Several features can be extracted from these time intervals—lag features. The data set used to generate lag features usually has a date/time associated with it.
For each record, a time window of dimension N is created and the lag features are calculated for the period N before the date/time of that record.
Figure 7 shows an example of this application for a t
i measurement with N = 3. The value of N is typically in minutes or hours, depending on the nature of the data.
Thus, two temporal windows were created. The first, of 3 h, in order to allow us to portray the behavior of telemetry data in the short term (
Table 7) and the second, of 24 h, in order to represent the long-term evolution (
Table 8). In each of these time intervals, two new parameters were calculated every 3 h for each of the features: the moving average and the standard deviation. Note that, in the case of N = 24 h (
Table 8), naturally the two new parameters are not available for the initial moments (first 24 h).
As with telemetry data, the error log also has a date/time associated with it. However, these data are categorical and not numerical. In this case, the number of errors of each type is added, every 3 h, for the time window N = 24 (
Table 9). Each line in the table represents the sum of the number of errors of each type in the 24 h prior to the indicated
datetime.
The maintenance log, which contains information related to the replacement of components, allows the generation of new potentially important features, such as, for example, how long ago a component was last replaced—
Table 10. It is expected that this feature relates well to the possible failures of the components, since, the longer the time of use of a component, the greater the expected degradation.
It is relevant to note that the creation of features based on maintenance data is not as linear as in the previous cases. However, this type of case-specific feature engineering is very common in predictive maintenance, where domain knowledge and experience play a crucial role in understanding and creating relevant features.
Finally, information about the machines can be used without further modifications, that is, information related to the model and number of years in service of each machine—
Table 6.
3.5. Feature Selection
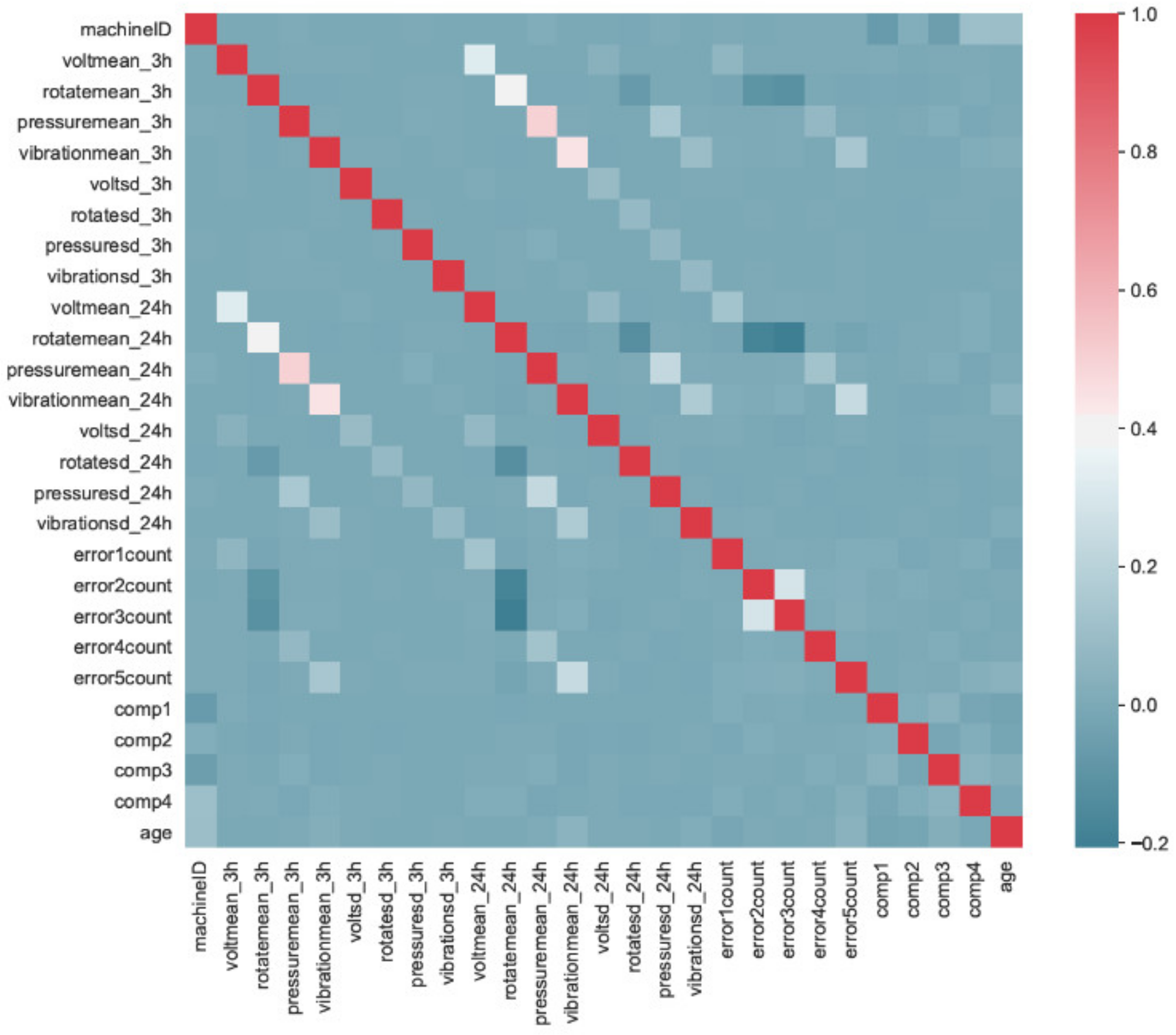
An analysis of the linear correlation between the variables was performed (
Figure 8). The correlation coefficient varies between −1 and 1. This coefficient makes it possible to see whether one variable justifies the linear variation of another. When it is close to 1, it means that there is a strong positive correlation, that is, if a given feature
A increases, then feature
B also increases and if
A decreases,
B it also decreases.
In this case, it appears that the correlation between the features is mostly low or nonexistent (correlation coefficient close to zero). Even so, in the case of the features pressuremean_3h and pressuremean_24h, the value of the correlation coefficient is approximately 0.5 and a more detailed analysis will be relevant.
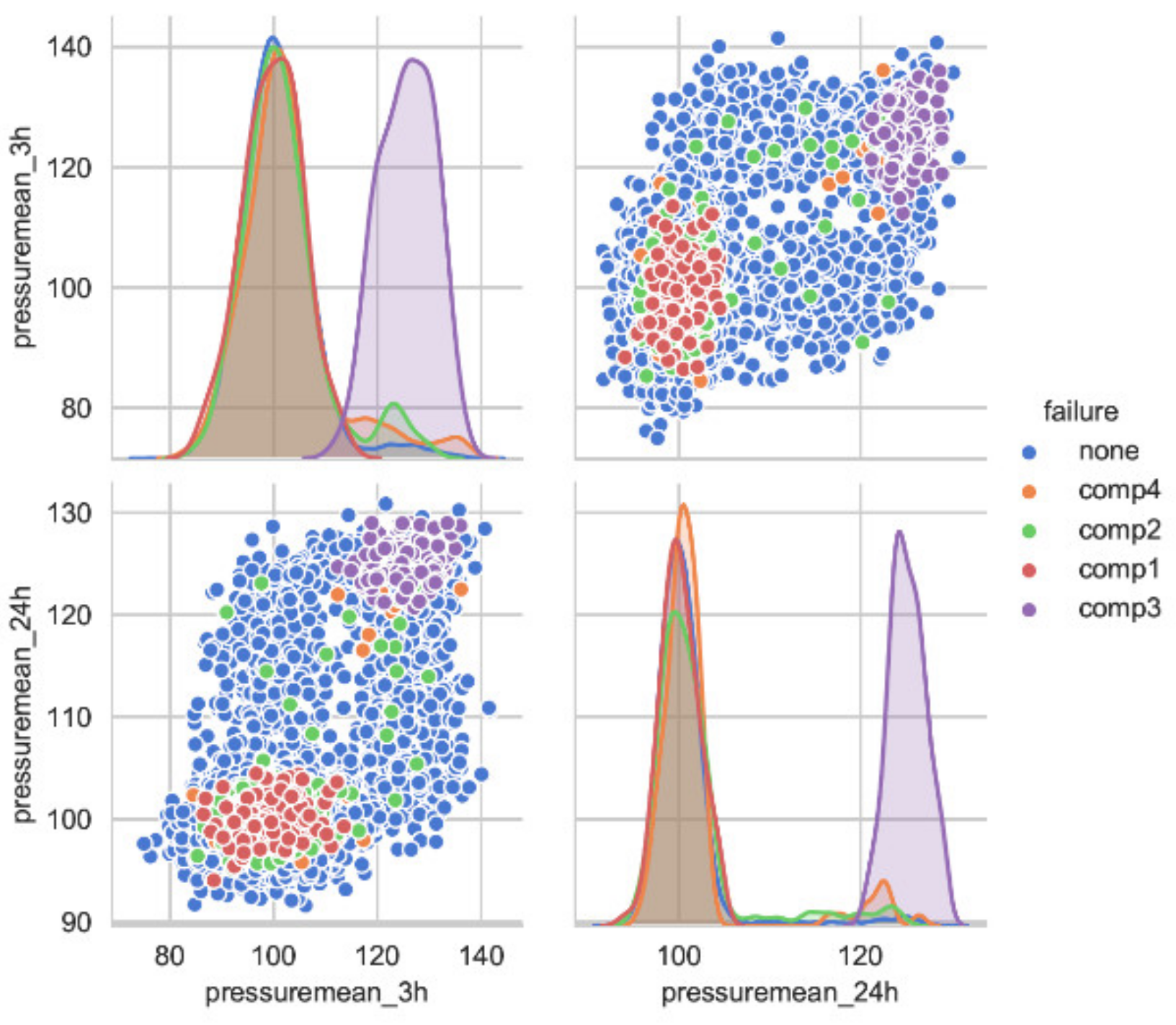
Thus,
Figure 9 shows the failures, by type of components, according to the evolution of the features pressuremean_3h and pressuremean_24h. It is possible to observe that, for components 1 and 3, there are clusters of points.
However, the same is not true for components 2 and 4. It is likewise possible to observe that most failures for component 3 occur for higher pressuremean_3h and pressuremean_24h values, when compared with the other components. Thus, it was decided to keep both features, since there is a clear relationship between these and the occurrence of failures in at least some of the components
3.6. Classification of Data and Construction of Labels
As previously mentioned, the problem of predictive maintenance under analysis is a case of Supervised Learning. In order to train a model to predict failures, it is necessary for not only examples of failure but also a time series of observations that led to that failure. Furthermore, the model needs examples of “normal” operating periods in order to be able to see the difference between the two. The classification between these two states is binary (stable or without failure/unstable or with failure). With this information available (stable/unstable), the model is only useful if it is able to promptly alert you to the imminence of a failure.
In order to fulfill this early warning criterion, it is necessary to modify the definition of the failure event label, which occurs at a specific time, to a time interval where the failure event may occur. The time until the failure occurs, which delimits the boundary between the two categories, must be chosen according to operational criteria. Is the knowledge that a failure will occur within 12 h sufficient to prevent it? And what about 24 h? And two weeks? The model’s ability to predict a failure will also depend on the duration of this time window.
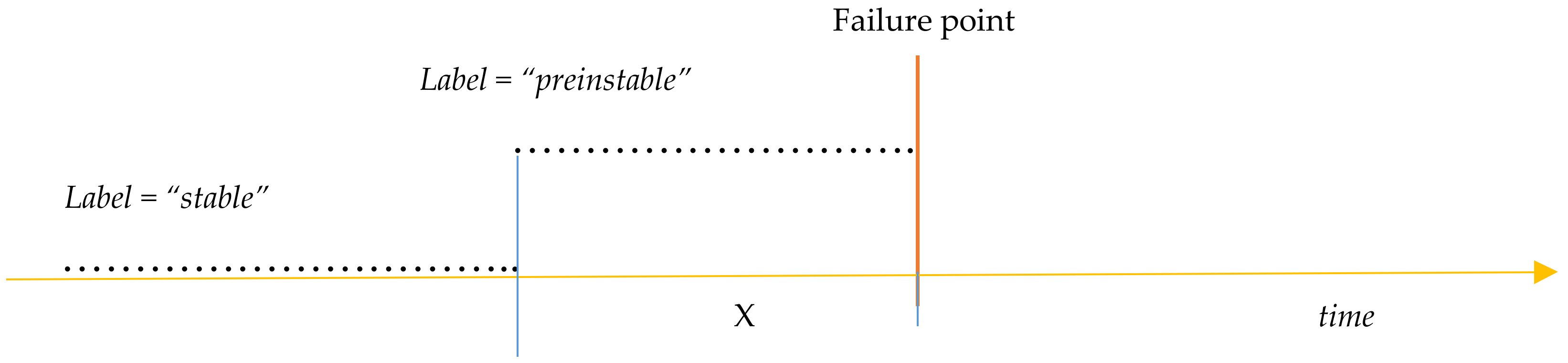
This process is illustrated in
Figure 10. In order to achieve the reset from unstable to pre-unstable, observations within the time window (represented by “X” in
Figure 9) before the occurrence of a failure have been labeled as
pre-instable, while records outside this time interval X have been labeled as stable.
The main objective of the Machine Learning models used will be to predict the probability of a failure occurring within this time window. In this case, more specifically, the probability of a machine failure occurring in the next 24 h (duration of the time window chosen for this application) related to one of the components (components 1,2,3 or 4). Thus, a new categorical feature “failure” was created, where all records in the 24 h prior to the occurrence of a failure in component 1 have the value failure = comp1 and so on for components 2,3 and 4. Records that do not check these conditions have the value of failure = none. This leads to the problem turning from a binary problem (stable/pre-unstable) to a multi-class classification problem (stable/n pre-unstable component). It should also be noted that, henceforth, due to this redefinition of failure event, when it is mentioned that a certain algorithm predicts a failure, in fact, what is being mentioned is that the algorithm predicts the occurrence of a failure within this time window.
Table 11 shows examples of failure in component 2. Note that the first 8 records occur in the 24 h prior to the occurrence of the first failure of component 2. The next 8 records in the 24 h prior to another failure of component 2.
3.7. Data Splitting
When working with associated day and time data, as is the case here, the division between the training, validation and test sets must be carried out carefully, in order to ensure that the evaluations obtained correspond to the actual performance that should be expected of the models, since there is an inherent temporal correlation between observations (high similarity between temporally close data). This validation technique is called Holdout.
In problems of predictive maintenance, in most situations, the best option is to perform a division based on time, that is, choose a point in time, train the model with all records prior to that point, using the later records to validate the model. This methodology also allows to simulate how the model will actually behave in practice.
Thus, in the present application, the registrations until 08/31/2015 1:00:00 were assigned to the test set, the registrations between 01/09/2015 1:00:00 and 31/10/2015 1:00:00 to the validation set and registration from 01-11-2015 1:00:00 to the test set. In order to guarantee that the data in different sets do not share time windows, the records at the borders, that is, the records of the 24 h preceding the date of division, have been removed. Thus,
Table 12 shows the amount of data that was attributed to each of the sets and the percentage that corresponds to failures.
3.8. Class Imbalance in Maintenance Problem Applications
Something to take into account in predictive maintenance is the fact that the occurrence of failures is rare during the life cycle of a given machine, when compared to normal operation. This leads to an imbalance between classes (
Table 13), which usually leads to an illusory performance on the part of the algorithms, which tend to classify the most common example more often at the expense of the less common, since the total number of incorrect classifications are thus less. Therefore, the Recall and Precision values can be low, although the Accuracy value is high. A clear example of this phenomenon is, in the validation set (where most of the evaluation metrics will be calculated), where 98.11% (
Table 12) of the data correspond to the Stable category (failure = none), that is, a model (without any use) that provides functioning stable values at all times would have an Accuracy of 98.11%. It is therefore essential to look at other evaluation metrics.
For a considerable number of critical equipment applications, the model’s inability to predict a failure can be exorbitantly expensive. In predictive maintenance, as a general rule, the most important is the number of real failures that the model is capable of predicting, that is, the model’s Recall3. This parameter becomes even more important as the consequences of false negatives, that is, true failures that the model was unable to predict, exceed the consequences of false positives, that is, a false prediction of a failure. This phenomenon is known as “incorrect classification cost” and can be estimated by companies according to the cost of repair, parts and labor. Generally, it is preferable that the model errs as a precaution, since it will be more economical to carry out a maintenance check than a partial or total interruption of the operation. However, the wrong prediction of a failure, that is, a false positive, can also lead to a loss of time and resources. In this case, the model must be adjusted to a high Precision. However, as mentioned earlier, the Recall and Precision metrics are not independent: Increasing one implies decreasing the other.
3.9. Application of Models in the Validation Set
In this first application, the validation set is used in order to understand how a wide variety of models behave, as well as to look for the tuning of the hyper-parameters of certain models. Such an approach is due to the fact that it is not possible, at the outset, to determine which algorithm is most suitable for a given problem. When training and evaluating a wide variety of models at an early stage, it is possible to see which ones have the greatest potential, however, for this step to be successful, it is necessary that the metrics for evaluating the models have been chosen in accordance with the established objectives.
The models tested were K-Nearest Neighbors, Decision Tree, Random Forest, Naïve Bayes and Artificial Neural Networks. The best results were obtained by Random Forest and Artificial Neural Networks models [
32].
3.10. Test Set Behavior
The validation set has been used, so far, to fine-tune the models and respective hyper-parameters, in order to seek better performance. It is now important to check how the models behave in the test set. Although, in a real case, it is advisable to evaluate only the model that is intended to be implemented [
8], this section presents the results obtained for the evaluation of the two best models (in the validation set), in this case, Random Forest and Artificial Neural Networks, with min-max scaling normalization.
Table 14 and
Table 15 show the values obtained for Precision, Recall and F1 Score, for the Random Forest and Artificial Neural Network model, respectively, in the validation and test sets.
As expected, there is a generalized decrease in performance of the evaluation metrics in the test set. Still, the results remain satisfactory. As previously mentioned, in predictive maintenance, as a general rule, the most important is the number of real failures that the model is capable of predicting, that is, the value of the model’s Recall parameter [
28]. This parameter becomes even more important as the consequences of false negatives, that is, true failures that the model was unable to predict, exceed the consequences of false positives, that is, a false prediction of a failure [
33,
34].
For both models, there is a drop in the value of Recall (and, consequently, of F1Score) to values below 90% for component 1 in the test set. In the present application, the four components were considered to be of equal importance.
In a real application, where it may be possible to know more information about each one of them (such as cost, importance in the process, location in the equipment, ease of replacement), the analysis may involve trying to optimize certain metrics that are considered to be of greater relevance.
4. Conclusions
In this paper, Machine Learning models were applied to a dataset available online. The data set used was published by Microsoft, in [
9], in a Notebook for Predictive Maintenance and Machine Learning. The use of this data set was justified. In the implementation carried out in the present project, until the final phase of feature engineering, the steps presented in that Notebook were followed. However, from that moment on, as it is considered that the approach presented in [
9] is too simplistic (no validation technique is used and only a single model is applied), it was decided to deepen the analysis with the implementation of the Holdout validation, which divides the data set into three subsets (Training, Validation and Test), as well as various Machine Learning models, thus showing how to fine-tune the models and respective hyper-parameters using the validation set.
The fact that it is a multi-class classification problem added complexity to the analysis and, perhaps, starting with a binary classification problem may be advisable for a better understanding of the basic concepts of Machine Learning, fundamental to the success of any application.
It is possible to address the imbalance between classes, very common in maintenance applications, since the occurrence of failures is rare during the life cycle of a given machine, when compared to its normal operation.
At the outset, and knowing that a sensible choice of which data to use and how to handle it is crucial for the performance of Machine Learning algorithms, good results would be expected based on the result obtained. However, more important than any result was the demonstration of a methodology, starting from data of different types and sources (very common in maintenance applications), that allowed us to show how it is possible to visualize and treat them in order to apply Artificial Intelligence tools in the analysis of maintenance data, in this case, Machine Learning.
Although the results obtained compare well with those presented so far in the literature, the biggest disadvantage in using the presented methodology lies in the definition of the features. If the selection of features is not the most correct, the results obtained can lead to wrong predictions. For future work, the application of feature learning concepts will be considered instead of feature engineering, which appears to be promising to improve the results obtained [
35,
36].













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}