The Selection of Strategic Alliance in IC Packaging and Testing Industry with DEA Resampling Comparative Evaluation




Abstract
:1. Introduction
2. Literature Review
2.1. Data Envelopment Analysis
2.2. Strategic Alliance
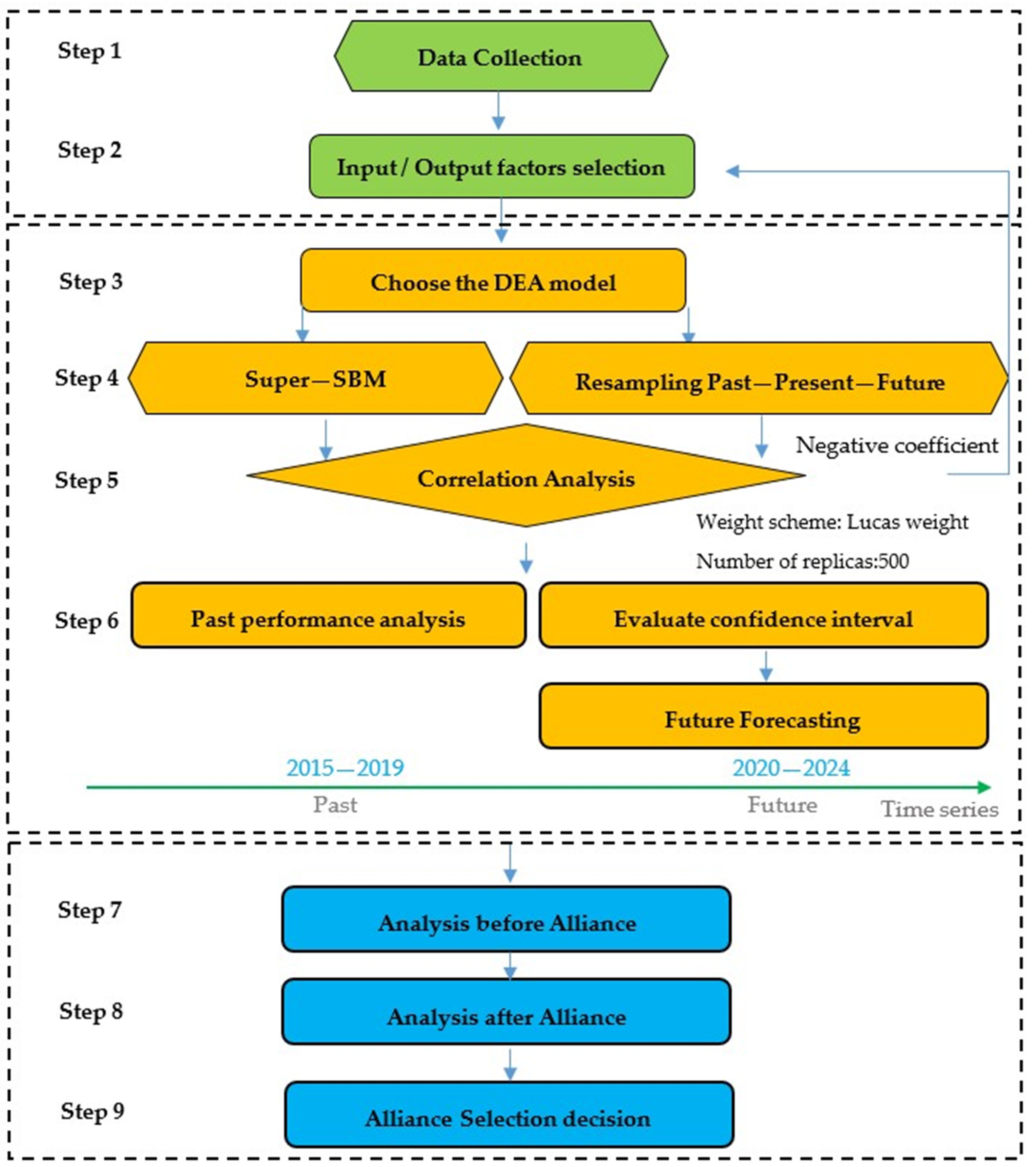
3. Materials and Methodologies
3.1. Research Development
3.2. Data Collection
3.3. Nonradial Super Efficiency Model (Super-SBM)
3.4. Resampling Model
3.4.1. Historical (Past–Present)
3.4.2. Forecasting (Past–Present–Future Model)
- ▪
- Trend analysis: a simple linear least squares regression.
- ▪
- Weight average: weight by Lucas number.
- ▪
- Average trend and Lucas weight average.
3.4.3. Fisher’s z Transformation
4. Empirical Results
4.1. Testing Replicas and Correlation
4.2. Past–Present–Future Framework
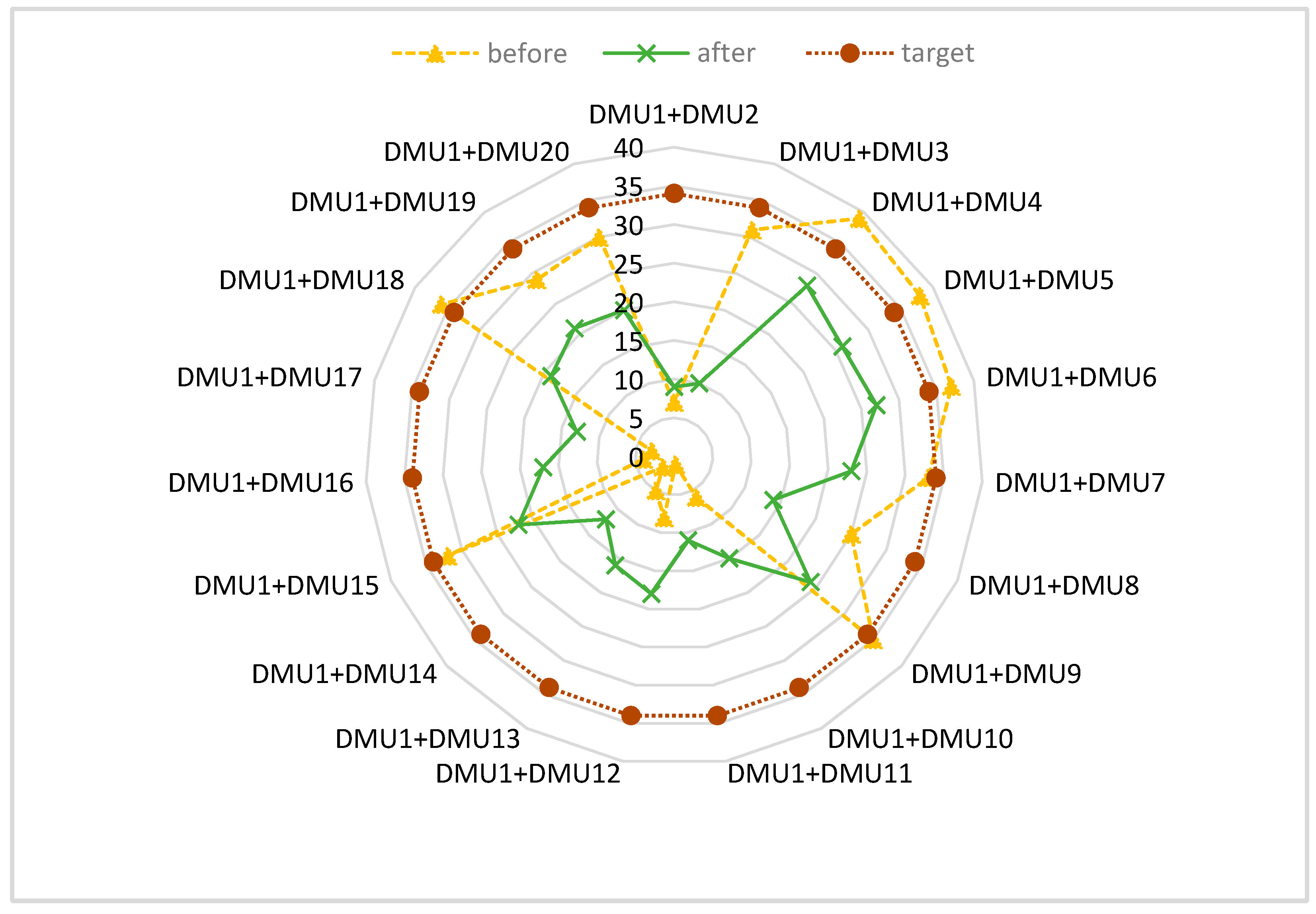
4.3. Analysis before Alliance
4.4. Analysis after Alliance
4.5. Alliance Selection Decision
5. Conclusions
- The study conducted a new comparative evaluation of the IC packaging and testing industry. In the past, previous studies were scarce regarding the IC packaging and testing industry.
- The study conducted an evaluation of the IC packaging and testing industry that considered the past, current, and future performance comprehensively, not only to comprehend the past performance of these companies, but also to predict future performance.
- The study applied the resampling model in DEA to establish the strategic alliance instead of grey prediction, which was more commonly used. The resampling model can evaluate the past and present, as well as predict future performance. Compared with grey prediction, the resampling method reduces the influence of outliers and considers the characteristics of the data between various industries.
- The previous studies on strategic alliances focus on the alliance performance of the target company, ignoring the cooperative company. This research provides a comparative evaluation model that can compare the performance between target and partners. It not only looks for progressive alliances, but also separates unilateral and dual progressive alliances.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| IC | integrated circuit |
| DEA | data envelopment analysis |
| FMS | flexible manufacturing system |
| AMT | advanced manufacturing technologies |
| R&D | research and development |
| OSAT | outsourced semiconductor assembly and test |
Appendix A

{kind=link}
{kind=link}
{kind=link}
| 2021 | 2022 | 2023 | 2024 | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DMU | 97.50% | DEA | Avg | 2.50% | Rank | 97.50% | DEA | Avg | 2.50% | Rank | 97.50% | DEA | Avg | 2.50% | Rank | 97.50% | DEA | Avg | 2.50% | Rank |
| DMU1 | 1.104 | 0.621 | 0.621 | 0.489 | 15 | 1.1 | 0.613 | 0.625 | 0.512 | 15 | 0.838 | 0.61 | 0.622 | 0.544 | 15 | 0.817 | 0.614 | 0.621 | 0.552 | 15 |
| DMU2 | 1.1 | 1.054 | 1.018 | 0.598 | 7 | 1.086 | 1.057 | 1.054 | 1.034 | 7 | 1.076 | 1.058 | 1.058 | 1.042 | 7 | 1.064 | 1.056 | 1.056 | 1.049 | 7 |
| DMU3 | 1.176 | 0.723 | 0.765 | 0.587 | 10 | 1.157 | 0.722 | 0.74 | 0.627 | 11 | 1.162 | 0.725 | 0.744 | 0.669 | 11 | 0.759 | 0.727 | 0.734 | 0.692 | 11 |
| DMU4 | 0.425 | 0.361 | 0.362 | 0.29 | 20 | 0.395 | 0.36 | 0.36 | 0.324 | 20 | 0.386 | 0.358 | 0.359 | 0.334 | 20 | 0.376 | 0.359 | 0.358 | 0.341 | 20 |
| DMU5 | 0.552 | 0.384 | 0.408 | 0.316 | 19 | 0.483 | 0.38 | 0.387 | 0.34 | 19 | 0.44 | 0.372 | 0.376 | 0.338 | 19 | 0.396 | 0.372 | 0.374 | 0.35 | 19 |
| DMU6 | 0.566 | 0.445 | 0.434 | 0.336 | 18 | 0.517 | 0.451 | 0.44 | 0.356 | 18 | 0.494 | 0.455 | 0.446 | 0.379 | 18 | 0.465 | 0.455 | 0.449 | 0.411 | 18 |
| DMU7 | 0.83 | 0.654 | 0.639 | 0.498 | 14 | 0.799 | 0.648 | 0.641 | 0.529 | 14 | 0.783 | 0.651 | 0.648 | 0.56 | 14 | 0.777 | 0.656 | 0.656 | 0.603 | 14 |
| DMU8 | 1.241 | 0.939 | 0.929 | 0.592 | 8 | 1.181 | 0.943 | 0.929 | 0.602 | 9 | 1.146 | 0.965 | 0.95 | 0.799 | 9 | 1.138 | 0.971 | 0.966 | 0.83 | 9 |
| DMU9 | 0.582 | 0.525 | 0.521 | 0.456 | 16 | 0.561 | 0.525 | 0.522 | 0.472 | 16 | 0.559 | 0.528 | 0.526 | 0.495 | 16 | 0.553 | 0.528 | 0.529 | 0.508 | 16 |
| DMU10 | 1.207 | 1.122 | 1.106 | 0.685 | 6 | 1.195 | 1.125 | 1.127 | 1.069 | 6 | 1.179 | 1.126 | 1.13 | 1.083 | 6 | 1.165 | 1.126 | 1.127 | 1.099 | 6 |
| DMU11 | 2.835 | 2.303 | 2.327 | 1.827 | 1 | 2.674 | 2.289 | 2.3 | 1.946 | 1 | 2.623 | 2.3 | 2.313 | 2.049 | 1 | 2.517 | 2.292 | 2.295 | 2.176 | 1 |
| DMU12 | 1.164 | 1.04 | 0.929 | 0.615 | 9 | 1.122 | 1.038 | 0.968 | 0.652 | 8 | 1.098 | 1.038 | 0.998 | 0.699 | 8 | 1.089 | 1.038 | 1.033 | 0.86 | 8 |
| DMU13 | 1.349 | 1.197 | 1.162 | 1.024 | 5 | 1.32 | 1.191 | 1.178 | 1.074 | 5 | 1.256 | 1.181 | 1.179 | 1.101 | 5 | 1.242 | 1.181 | 1.179 | 1.104 | 5 |
| DMU14 | 2.598 | 1.695 | 1.628 | 0.37 | 2 | 2.517 | 1.69 | 1.684 | 0.4 | 2 | 2.345 | 1.681 | 1.638 | 0.405 | 2 | 1.736 | 1.677 | 1.648 | 0.418 | 2 |
| DMU15 | 1.343 | 0.693 | 0.717 | 0.477 | 12 | 0.985 | 0.695 | 0.699 | 0.533 | 13 | 0.826 | 0.699 | 0.695 | 0.62 | 13 | 0.768 | 0.699 | 0.7 | 0.659 | 13 |
| DMU16 | 2.152 | 1.385 | 1.42 | 1.157 | 4 | 2.113 | 1.386 | 1.409 | 1.226 | 4 | 1.459 | 1.389 | 1.392 | 1.275 | 4 | 1.43 | 1.384 | 1.382 | 1.291 | 4 |
| DMU17 | 1.757 | 1.484 | 1.462 | 0.693 | 3 | 1.659 | 1.484 | 1.479 | 1.326 | 3 | 1.64 | 1.496 | 1.493 | 1.378 | 3 | 1.629 | 1.487 | 1.488 | 1.39 | 3 |
| DMU18 | 0.717 | 0.474 | 0.507 | 0.376 | 17 | 0.672 | 0.475 | 0.494 | 0.399 | 17 | 0.538 | 0.473 | 0.475 | 0.41 | 17 | 0.519 | 0.474 | 0.475 | 0.422 | 17 |
| DMU19 | 1.079 | 0.774 | 0.744 | 0.488 | 11 | 1.07 | 0.777 | 0.76 | 0.597 | 10 | 1.052 | 0.775 | 0.769 | 0.663 | 10 | 0.809 | 0.772 | 0.769 | 0.686 | 10 |
| DMU20 | 1.075 | 0.733 | 0.7 | 0.547 | 13 | 0.781 | 0.73 | 0.704 | 0.564 | 12 | 0.755 | 0.73 | 0.715 | 0.585 | 12 | 0.745 | 0.731 | 0.726 | 0.677 | 12 |
References
- Development, Y. Status of the Advanced Packaging Industry. 2019. Available online: Https://Yole-I-Micronews-Com.Osu.Eu-West-2.Outscale.Com/Uploads/2019/2007/Yole_Yd19030_Status-Of-The-Advanced-Packaging-Industry-12019_Sample.Pdf (accessed on 2 May 2020).
- Technology, A. Annual Report Pursuant to Section 13 Or 15(D). 2017. Available online: https://www.sec.gov/files/form10-k.pdf (accessed on 7 June 2020).
- Advanced Semiconductor Engineering Technology Holding Co., Ltd. 2020 Q1 Earnings Conference Call/Webcast. 2020. Available online: http://ir.aseglobal.com/html/ir_events_details.php?id=15032 (accessed on 7 June 2020).
- Park, S.H.; Ungson, G.R. Interfirm Rivalry and Managerial Complexity: A Conceptual Framework of Alliance Failure. Organ. Sci. 2001, 12, 37–53. [Google Scholar] [CrossRef]
- Farrell, M.J. The Measurement of Productive Efficiency. J. R. Stat. Soc. Ser. A (Gen.) 1957, 120, 253–290. [Google Scholar] [CrossRef]
- Charnes, A.; Cooper, W.W.; Rhodes, E. Measuring the Efficiency of Decision Making Units. Eur. J. Oper. Res. 1978, 2, 429–444. [Google Scholar] [CrossRef]
- Tone, K. Slacks-Based Measure of Efficiency. In Handbook on Data Envelopment Analysis; Springer: Berlin/Heidelberg, Germany, 2011; pp. 195–209. [Google Scholar] [CrossRef]
- Tone, K. A Slacks-Based Measure of Efficiency in Data Envelopment Analysis. Eur. J. Oper. Res. 2001, 130, 498–509. [Google Scholar] [CrossRef] [Green Version]
- Tone, K.; Ouenniche, J. Dea Scores’ Confidence Intervals with Past-Present and Past-Present-Future Based Resampling. Am. J. Oper. Res. 2016, 6, 121–135. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.-N.; Le, A.L. Measuring the Macroeconomic Performance among Developed Countries and Asian Developing Countries: Past, Present, and Future. Sustainability 2018, 10, 3664. [Google Scholar] [CrossRef] [Green Version]
- Lo Storto, C. A Double-Dea Framework to Support Decision-Making in the Choice of Advanced Manufacturing Technologies. Manag. Decis. 2018, 56. [Google Scholar] [CrossRef]
- Kozmetsky, G.; Yue, P. Comparative Performance of Global Semiconductor Companies. Omega 1998, 2, 153–175. [Google Scholar]
- Bamford, J.D.; Gomes-Casseres, B.; Robinson, M.S. Mastering Alliance Strategy: A Comprehensive Guide to Design, Management, And Organization; John Wiley & Sons: Hoboken, NJ, USA, 2003. [Google Scholar] [CrossRef]
- Chan, S.H.; Kensinger, J.W.; Keown, A.J.; Martin, J.D. Do Strategic Alliances Create Value? J. Financ. Econ. 1997, 46, 199–221. [Google Scholar] [CrossRef]
- Cravens∗, D.W.; Shipp, S.H.; Cravens, K.S. Analysis of Co-Operative Interorganizational Relationships, Strategic Alliance Formation, and Strategic Alliance Effectiveness. J. Strateg. Mark. 1993, 1, 55–70. [Google Scholar] [CrossRef]
- Vanhaverbeke, W.; Duysters, G.; Noorderhaven, N. External Technology Sourcing Through Alliances or Acquisitions: An Analysis of The Application-Specific Integrated Circuits Industry. Organ. Sci. 2002, 13, 714–733. [Google Scholar] [CrossRef] [Green Version]
- Parkhe, A. Understanding Trust in International Alliances. J. World Bus. 1998, 33, 219–240. [Google Scholar] [CrossRef]
- Ahern, K.R. Bargaining Power and Industry Dependence in Mergers. J. Financ. Econ. 2012, 103, 530–550. [Google Scholar] [CrossRef]
- Hamel, G. Collaborate with Your Competitors and Win. Harv. Bus. Rev. 1989, 67, 133–139. [Google Scholar]
- Wang, C.-N.; Nguyen, X.-T.; Wang, Y.-H. Automobile Industry Strategic Alliance Partner Selection: The Application of a Hybrid Dea And Grey Theory Model. Sustainability 2016, 8, 173. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, N.; Tran, T.-T. A Two-Stage Study of Grey System Theory and dea In Strategic Alliance: An Application in Vietnamese Fertilizing Industry. Int. J. Adv. Appl. Sci. 2018, 5, 73–81. [Google Scholar] [CrossRef]
- Yi, Z. Research of Strategic Alliance Stable Decision-Making Model Based on Rough Set and dea. Telkomnika Indones. J. Electr. Eng. 2013, 11, 7295–7301. [Google Scholar] [CrossRef]
- Wang, C.-N.; Hsu, H.-P.; Wang, J.-W.; Kao, Y.-C.; Nguyen, T.-P. Strategic Alliance for Vietnam Domestic Real Estate Companies Using A Hybrid Approach Combining Gm (1, 1) With Super Sbm Dea. Sustainability 2020, 12, 1891. [Google Scholar] [CrossRef] [Green Version]
- Hsu, L.-C. Using a Decision-Making Process to Evaluate Efficiency and Operating Performance for Listed Semiconductor Companies. Technol. Econ. Dev. Econ. 2014, 21, 1–31. [Google Scholar] [CrossRef] [Green Version]
- Chiu, C.-R.; Fang, C.-L.; Tsang, S.-S.; Chen, Y.-F. Performance Evaluation of The Semiconductor Industry Based on A Metafrontier Approach. Technol. Econ. Dev. Econ. 2018, 24, 825–843. [Google Scholar] [CrossRef] [Green Version]
- Wu, W.Y.; Tsai, H.J.; Cheng, K.Y.; Lai, M. Assessment of Intellectual Capital Management in Taiwanese Ic Design Companies: Using Dea and the Malmquist Productivity Index. RD Manag. 2006, 36, 531–545. [Google Scholar] [CrossRef]
- Lu, W.-M.; Hung, S.-W. Assessing the Performance of a Vertically Disintegrated Chain by The Dea Approach–A Case Study of Taiwanese Semiconductor Firms. Int. J. Prod. Res. 2010, 48, 1155–1170. [Google Scholar] [CrossRef]
- Wang, C.; Ho, H.T. The Selection Strategic Alliance Partner in Semiconductor Manufacturing Industry Based on Grey System and Dea. In Proceedings of the 2016 International Conference on Computational Intelligence and Applications (Iccia), Jeju, Korea, 27–29 August 2016; pp. 83–87. [Google Scholar]
- Simar, L.; Wilson, P.W. Sensitivity Analysis of Efficiency Scores: How to Bootstrap in Nonparametric Frontier Models. Manag. Sci. 1998, 44, 49–61. [Google Scholar] [CrossRef] [Green Version]
- Efron, B. Bootstrap Methods: Another Look at the Jackknife. In Breakthroughs in Statistics; Springer: Berlin/Heidelberg, Germany, 1992; pp. 569–593. [Google Scholar] [CrossRef]
- Fisher, R.A. On the Interpretation of Χ 2 from Contingency Tables, and the Calculation of P. J. R. Stat. Soc. 1922, 85, 87–94. [Google Scholar] [CrossRef]



| DMUS | Name of Companies |
|---|---|
| DMU1 | ASE |
| DMU2 | Amkor |
| DMU3 | Powertech Technology |
| DMU4 | Tongfu Microelectronics |
| DMU5 | Tianshuihuatian Microelectronics |
| DMU6 | UTAC |
| DMU7 | King Yuan Electronics |
| DMU8 | Chipbond Technology |
| DMU9 | Chipmos Technologies |
| DMU10 | Orient IC Electronics |
| DMU11 | SFA Semicon |
| DMU12 | AOI Electronics |
| DMU13 | Greatek Elec |
| DMU14 | Unisem Berhad |
| DMU15 | Sigurd Microelectronics |
| DMU16 | Formosa Advanced Technologies |
| DMU17 | Hana Micron |
| DMU18 | Walton Advanced Engineering |
| DMU19 | Ardentec |
| DMU20 | Tong Hsing |
| Author(s) | Input | Output |
|---|---|---|
| Hsu [24] | total assets; operating expense; administrative expenses; inventory | total revenue; net sales |
| Chiu et al. [25] | fixed assets; employees; R&D expense; cost of sales | net sales; market value |
| Wu et al. [26] | employees; R&D expense; patents; R&D employees; operating cost | net sales; intellectual capital stocks; changes in intellectual capital stocks |
| Lu and Hung [27] | assets; employees; equity | revenue; profit; EPS |
| Wang and Ho [28] | fixed assets; cost of goods sold; R&D expense; operating expense | net income; revenue; retained earnings |
| DMU | 5000 Replica | 500 Replica | Difference | |||||
|---|---|---|---|---|---|---|---|---|
| 97.50% | DEA | 2.50% | 97.50% | DEA | 2.50% | 97.50% | 2.50% | |
| DMU1 | 1.151 | 0.645 | 0.465 | 1.154 | 0.645 | 0.458 | 0.003 | −0.007 |
| DMU2 | 1.106 | 1.051 | 0.569 | 1.107 | 1.051 | 0.554 | 0.001 | −0.015 |
| DMU3 | 1.2 | 0.737 | 0.554 | 1.219 | 0.737 | 0.542 | 0.019 | −0.012 |
| DMU4 | 0.57 | 0.374 | 0.267 | 0.585 | 0.374 | 0.269 | 0.015 | 0.002 |
| DMU5 | 1.131 | 0.409 | 0.291 | 1.152 | 0.409 | 0.271 | 0.021 | −0.020 |
| DMU6 | 0.599 | 0.445 | 0.328 | 0.578 | 0.445 | 0.322 | −0.021 | −0.006 |
| DMU7 | 1.072 | 0.657 | 0.467 | 1.042 | 0.657 | 0.456 | −0.030 | −0.012 |
| DMU8 | 1.252 | 0.931 | 0.549 | 1.284 | 0.931 | 0.526 | 0.032 | −0.023 |
| DMU9 | 0.591 | 0.539 | 0.443 | 0.595 | 0.539 | 0.434 | 0.005 | −0.008 |
| DMU10 | 1.253 | 1.121 | 0.526 | 1.235 | 1.121 | 0.512 | −0.018 | −0.014 |
| DMU11 | 3.293 | 2.104 | 1.586 | 3.169 | 2.104 | 1.569 | −0.124 | −0.017 |
| DMU12 | 1.176 | 1.043 | 0.562 | 1.171 | 1.043 | 0.568 | −0.005 | 0.006 |
| DMU13 | 1.398 | 1.196 | 0.855 | 1.387 | 1.196 | 0.812 | −0.011 | −0.044 |
| DMU14 | 2.675 | 1.705 | 0.365 | 2.664 | 1.705 | 0.365 | −0.011 | 0 |
| DMU15 | 1.441 | 0.692 | 0.392 | 1.404 | 0.692 | 0.393 | −0.037 | 0.002 |
| DMU16 | 2.31 | 1.4 | 1.144 | 2.25 | 1.4 | 1.127 | −0.060 | −0.018 |
| DMU17 | 1.875 | 1.381 | 0.541 | 1.901 | 1.381 | 0.539 | 0.026 | −0.002 |
| DMU18 | 1.252 | 0.529 | 0.351 | 1.282 | 0.529 | 0.353 | 0.03 | 0.002 |
| DMU19 | 1.14 | 0.777 | 0.47 | 1.151 | 0.777 | 0.455 | 0.011 | −0.015 |
| DMU20 | 1.095 | 0.731 | 0.51 | 1.093 | 0.731 | 0.513 | −0.002 | 0.004 |
| TA | OE | RD | EP | REV | GP | |
|---|---|---|---|---|---|---|
| TA | 1 | 0.988 | 0.989 | 0.975 | 0.996 | 0.991 |
| OE | 0.988 | 1 | 0.975 | 0.982 | 0.993 | 0.981 |
| RD | 0.989 | 0.975 | 1 | 0.957 | 0.982 | 0.973 |
| EP | 0.975 | 0.982 | 0.957 | 1 | 0.98 | 0.968 |
| Rev | 0.996 | 0.993 | 0.982 | 0.98 | 1 | 0.993 |
| GP | 0.991 | 0.981 | 0.973 | 0.968 | 0.993 | 1 |
| Lower Bounds | |||||||
|---|---|---|---|---|---|---|---|
| TA | OE | RD | EP | REV | GP | ||
| Upper bounds | TA | 0.972 | 0.972 | 0.936 | 0.99 | 0.987 | |
| OE | 0.9958 | 0.937 | 0.961 | 0.984 | 0.971 | ||
| RD | 0.9958 | 0.99 | 0.893 | 0.954 | 0.938 | ||
| EP | 0.9902 | 0.994 | 0.983 | 0.949 | 0.925 | ||
| Rev | 0.9984 | 0.998 | 0.993 | 0.992 | 0.989 | ||
| GP | 0.998 | 0.996 | 0.99 | 0.988 | 0.998 | ||
| DMU | Forecast DEA and Confidence Interval | Forecast Data by Lucas Case | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 97.50% | DEA | Average | 2.50% | Rank | (I)TA | (I)OE | (I)RD | (I)Ep | (O)Rev | (O)GP | |
| DMU1 | 1.151 | 0.645 | 0.639 | 0.466 | 15 | 16,090.44 | 974.17 | 504.15 | 85,302 | 11,887.87 | 1962.93 |
| DMU2 | 1.115 | 1.052 | 0.96 | 0.569 | 7 | 4514.61 | 414.11 | 112.83 | 32,850 | 4071.86 | 680.56 |
| DMU3 | 1.197 | 0.737 | 0.829 | 0.559 | 10 | 3301.57 | 124.07 | 58.21 | 12,938.84 | 2062.03 | 411.7 |
| DMU4 | 0.57 | 0.374 | 0.392 | 0.267 | 20 | 2028.84 | 126.24 | 76.94 | 11,015.95 | 1023.05 | 148.62 |
| DMU5 | 1.138 | 0.409 | 0.441 | 0.286 | 18 | 1712.48 | 92.28 | 47.97 | 13,182.53 | 1047.08 | 117.46 |
| DMU6 | 0.601 | 0.449 | 0.436 | 0.332 | 19 | 1485.05 | 153.39 | 15.28 | 10,519.37 | 752.67 | 138.4 |
| DMU7 | 1.072 | 0.657 | 0.645 | 0.467 | 14 | 1604.89 | 88.26 | 30.19 | 5999.16 | 735.18 | 202.36 |
| DMU8 | 1.238 | 0.931 | 0.904 | 0.545 | 8 | 1267.06 | 49.63 | 13.58 | 4803.68 | 616.51 | 179.86 |
| DMU9 | 0.592 | 0.539 | 0.516 | 0.444 | 17 | 1097.48 | 49.38 | 31 | 5996.63 | 622.33 | 120.35 |
| DMU10 | 1.249 | 1.121 | 1.077 | 0.519 | 6 | 543.53 | 29.36 | 8.62 | 6307.26 | 527.58 | 40.24 |
| DMU11 | 3.293 | 2.104 | 2.367 | 1.586 | 1 | 574.45 | 21.24 | 1.71 | 677.37 | 449.96 | 40.15 |
| DMU12 | 1.176 | 1.043 | 0.9 | 0.565 | 9 | 499.19 | 34.48 | 11.71 | 2429.84 | 395.78 | 78.95 |
| DMU13 | 1.412 | 1.196 | 1.14 | 0.843 | 5 | 614.25 | 14.5 | 6.56 | 3039.74 | 388.45 | 99.38 |
| DMU14 | 2.675 | 1.705 | 1.635 | 0.363 | 2 | 431.39 | 43.92 | 3.18 | 6791.79 | 318.11 | 135.09 |
| DMU15 | 1.426 | 0.692 | 0.743 | 0.392 | 12 | 678.28 | 23.56 | 8.64 | 2933.74 | 286.45 | 82.92 |
| DMU16 | 2.306 | 1.4 | 1.459 | 1.14 | 3 | 414.63 | 6.32 | 2.65 | 2402 | 291.98 | 51.54 |
| DMU17 | 1.874 | 1.381 | 1.441 | 0.541 | 4 | 530.81 | 36.96 | 5.61 | 834.05 | 383.95 | 65.57 |
| DMU18 | 1.24 | 0.529 | 0.557 | 0.348 | 16 | 552.89 | 12.97 | 2.26 | 2825.95 | 259.27 | 18.82 |
| DMU19 | 1.14 | 0.777 | 0.76 | 0.47 | 11 | 571.64 | 28.14 | 10.51 | 2225.11 | 257.36 | 81.35 |
| DMU20 | 1.097 | 0.731 | 0.684 | 0.512 | 13 | 424.83 | 23.21 | 3.56 | 3030.37 | 247.94 | 58.44 |
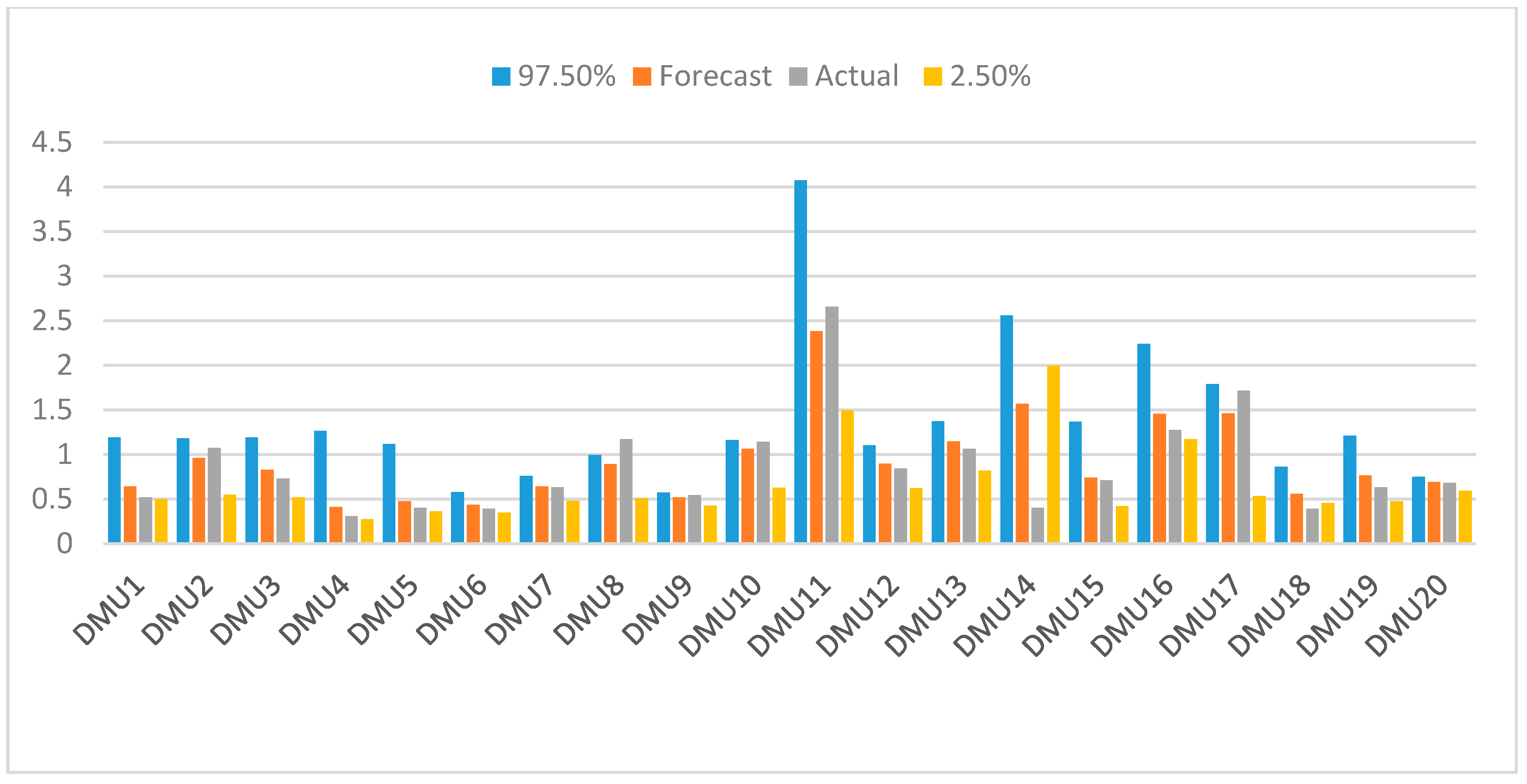
| DMU | 97.50% | Forecast 2019 | Actual 2019 | 2.50% | ||
|---|---|---|---|---|---|---|
| Average | Rank | Average | Rank | |||
| DMU1 | 1.1884 | 0.6423 | 14 | 0.76 | 12 | 0.499 |
| DMU2 | 1.1811 | 0.9603 | 7 | 1.4762 | 8 | 0.5485 |
| DMU3 | 1.192 | 0.8281 | 10 | 1.4438 | 10 | 0.5184 |
| DMU4 | 1.2634 | 0.408 | 20 | 0.4299 | 20 | 0.2746 |
| DMU5 | 1.1152 | 0.4751 | 18 | 0.5423 | 18 | 0.363 |
| DMU6 | 0.577 | 0.4346 | 19 | 0.4607 | 19 | 0.3484 |
| DMU7 | 0.7587 | 0.6386 | 15 | 0.6852 | 13 | 0.4789 |
| DMU8 | 0.9943 | 0.8928 | 9 | 1.4383 | 11 | 0.5101 |
| DMU9 | 0.572 | 0.5168 | 17 | 0.5694 | 16 | 0.4224 |
| DMU10 | 1.1579 | 1.0643 | 6 | 1.2201 | 5 | 0.6235 |
| DMU11 | 4.0707 | 2.3817 | 1 | 2.8892 | 2 | 1.4945 |
| DMU12 | 1.1029 | 0.8957 | 8 | 1.1224 | 6 | 0.6215 |
| DMU13 | 1.3712 | 1.1436 | 5 | 1.0747 | 4 | 0.8151 |
| DMU14 | 2.5575 | 1.569 | 2 | 1.3927 | 1 | 1.9958 |
| DMU15 | 1.3667 | 0.7365 | 12 | 0.75 | 17 | 0.4198 |
| DMU16 | 2.2369 | 1.4532 | 4 | 1.3927 | 3 | 1.168 |
| DMU17 | 1.7884 | 1.4572 | 3 | 1.839 | 9 | 0.5341 |
| DMU18 | 0.8622 | 0.5594 | 16 | 1.4692 | 15 | 0.4537 |
| DMU19 | 1.2115 | 0.7629 | 11 | 0.7323 | 14 | 0.4722 |
| DMU20 | 0.7499 | 0.6895 | 13 | 1.0695 | 7 | 0.5915 |
| DMU | 2015 | 2016 | 2017 | 2018 | 2019 |
|---|---|---|---|---|---|
| DMU1 | 0.8445 | 0.883 | 0.9125 | 0.783 | 0.76 |
| DMU2 | 1.1989 | 1.3894 | 1.0786 | 1.5127 | 1.4762 |
| DMU3 | 1.2413 | 1.2533 | 1.2058 | 1.1736 | 1.4438 |
| DMU4 | 0.371 | 0.4708 | 0.5571 | 0.5298 | 0.4299 |
| DMU5 | 0.5493 | 0.6153 | 0.7292 | 0.6148 | 0.5423 |
| DMU6 | 1.6521 | 0.4639 | 2.9001 | 0.6971 | 0.4607 |
| DMU7 | 0.723 | 1.0554 | 1.0761 | 0.6302 | 0.6852 |
| DMU8 | 0.7983 | 0.7973 | 1.3219 | 0.8574 | 1.4383 |
| DMU9 | 0.7217 | 0.6264 | 0.5524 | 0.5924 | 0.5694 |
| DMU10 | 1.3158 | 1.2006 | 1.0945 | 1.1961 | 1.2201 |
| DMU11 | 2.5322 | 2.7663 | 2.5189 | 2.5861 | 2.8892 |
| DMU12 | 1.1827 | 1.1246 | 1.0876 | 1.0459 | 1.1224 |
| DMU13 | 1.1437 | 1.2334 | 1.1999 | 1.2349 | 1.0747 |
| DMU14 | 3.6229 | 2.8724 | 3.2927 | 2.9655 | 1.3927 |
| DMU15 | 0.8352 | 0.8748 | 1.4045 | 0.6875 | 0.75 |
| DMU16 | 1.6204 | 1.5287 | 1.424 | 2.3044 | 1.3927 |
| DMU17 | 1.3045 | 1.4949 | 1.1628 | 1.7085 | 1.839 |
| DMU18 | 0.8022 | 0.6598 | 0.7085 | 0.7123 | 1.4692 |
| DMU19 | 1.0595 | 0.7251 | 0.7781 | 0.8735 | 0.7323 |
| DMU20 | 0.6654 | 0.7164 | 0.7699 | 1.0242 | 1.0695 |
| AVG | 1.2092 | 1.1376 | 1.2887 | 1.1865 | 1.1379 |
| DMU | Average | Rank | DMU | Average | Rank |
|---|---|---|---|---|---|
| DMU11 | 2.2826 | 1 | DMU20 | 0.7305 | 11 |
| DMU14 | 1.6839 | 2 | DMU3 | 0.726 | 12 |
| DMU17 | 1.4827 | 3 | DMU15 | 0.6979 | 13 |
| DMU16 | 1.387 | 4 | DMU7 | 0.6537 | 14 |
| DMU13 | 1.1847 | 5 | DMU1 | 0.615 | 15 |
| DMU10 | 1.1252 | 6 | DMU9 | 0.528 | 16 |
| DMU2 | 1.0561 | 7 | DMU18 | 0.4767 | 17 |
| DMU12 | 1.0386 | 8 | DMU6 | 0.4522 | 18 |
| DMU8 | 0.9602 | 9 | DMU5 | 0.3769 | 19 |
| DMU19 | 0.774 | 10 | DMU4 | 0.3602 | 20 |
| Rank | DMU | Average | Rank | DMU | Average |
|---|---|---|---|---|---|
| 1 | DMU11 | 2.2826 | 21 | DMU1 + DMU19 | 0.9765 |
| 2 | DMU14 | 1.6839 | 22 | DMU1 + DMU15 | 0.9746 |
| 3 | DMU17 | 1.4827 | 23 | DMU1 + DMU7 | 0.9729 |
| 4 | DMU16 | 1.387 | 24 | DMU1 + DMU9 | 0.9698 |
| 5 | DMU13 | 1.1847 | 25 | DMU8 | 0.9602 |
| 6 | DMU10 | 1.1252 | 26 | DMU1 + DMU5 | 0.9564 |
| 7 | DMU2 | 1.0561 | 27 | DMU1 + DMU6 | 0.9484 |
| 8 | DMU12 | 1.0386 | 28 | DMU1 + DMU4 | 0.9348 |
| 9 | DMU1 + DMU2 | 1.0345 | 29 | DMU19 | 0.774 |
| 10 | DMU1 + DMU3 | 1.0253 | 30 | DMU20 | 0.7305 |
| 11 | DMU1 + DMU11 | 1.0047 | 31 | DMU3 | 0.726 |
| 12 | DMU1 + DMU14 | 1.0043 | 32 | DMU15 | 0.6979 |
| 13 | DMU1 + DMU17 | 0.9977 | 33 | DMU7 | 0.6537 |
| 14 | DMU1 + DMU8 | 0.9956 | 34 | DMU1 | 0.615 |
| 15 | DMU1 + DMU10 | 0.9941 | 35 | DMU9 | 0.528 |
| 16 | DMU1 + DMU13 | 0.9932 | 36 | DMU18 | 0.4767 |
| 17 | DMU1 + DMU16 | 0.9902 | 37 | DMU6 | 0.4522 |
| 18 | DMU1 + DMU12 | 0.9872 | 38 | DMU5 | 0.3769 |
| 19 | DMU1 + DMU18 | 0.9784 | 39 | DMU4 | 0.3602 |
| 20 | DMU1+DMU20 | 0.9784 |
| DMU | RP | RA | Comparison |
|---|---|---|---|
| Effective | |||
| DMU1 + DMU3 | 31 | 10 | 21 |
| DMU1 + DMU18 | 36 | 19 | 17 |
| DMU1 + DMU5 | 38 | 26 | 12 |
| DMU1 + DMU4 | 39 | 28 | 11 |
| DMU1 + DMU8 | 25 | 14 | 11 |
| DMU1 + DMU9 | 35 | 24 | 11 |
| DMU1 + DMU6 | 37 | 27 | 10 |
| DMU1 + DMU7 | 33 | 23 | 10 |
| DMU1 + DMU15 | 32 | 22 | 10 |
| DMU1 + DMU20 | 30 | 20 | 10 |
| DMU1 + DMU19 | 29 | 21 | 8 |
| Ineffective | |||
| DMU1 + DMU2 | 7 | 9 | −2 |
| DMU1 + DMU10 | 6 | 15 | −9 |
| DMU1 + DMU11 | 1 | 11 | −10 |
| DMU1 + DMU12 | 8 | 18 | −10 |
| DMU1 + DMU14 | 2 | 12 | −10 |
| DMU1 + DMU17 | 3 | 13 | −10 |
| DMU1 + DMU13 | 5 | 16 | −11 |
| DMU1 + DMU16 | 4 | 17 | −13 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.-N.; Peng, Y.-C.; Hsueh, M.-H.; Wang, Y.-H. The Selection of Strategic Alliance in IC Packaging and Testing Industry with DEA Resampling Comparative Evaluation. Appl. Sci. 2021, 11, 204. https://doi.org/10.3390/app11010204
Wang C-N, Peng Y-C, Hsueh M-H, Wang Y-H. The Selection of Strategic Alliance in IC Packaging and Testing Industry with DEA Resampling Comparative Evaluation. Applied Sciences. 2021; 11(1):204. https://doi.org/10.3390/app11010204
Chicago/Turabian StyleWang, Chia-Nan, Yi-Chun Peng, Ming-Hsien Hsueh, and Yen-Hui Wang. 2021. "The Selection of Strategic Alliance in IC Packaging and Testing Industry with DEA Resampling Comparative Evaluation" Applied Sciences 11, no. 1: 204. https://doi.org/10.3390/app11010204
APA StyleWang, C. -N., Peng, Y. -C., Hsueh, M. -H., & Wang, Y. -H. (2021). The Selection of Strategic Alliance in IC Packaging and Testing Industry with DEA Resampling Comparative Evaluation. Applied Sciences, 11(1), 204. https://doi.org/10.3390/app11010204