
Semantic Microservice Framework for Digital Twins


Abstract
:1. Introduction
2. Related Work
2.1. Digital Twin Service Frameworks
2.2. Requirements for a Digital Twin Service Framework
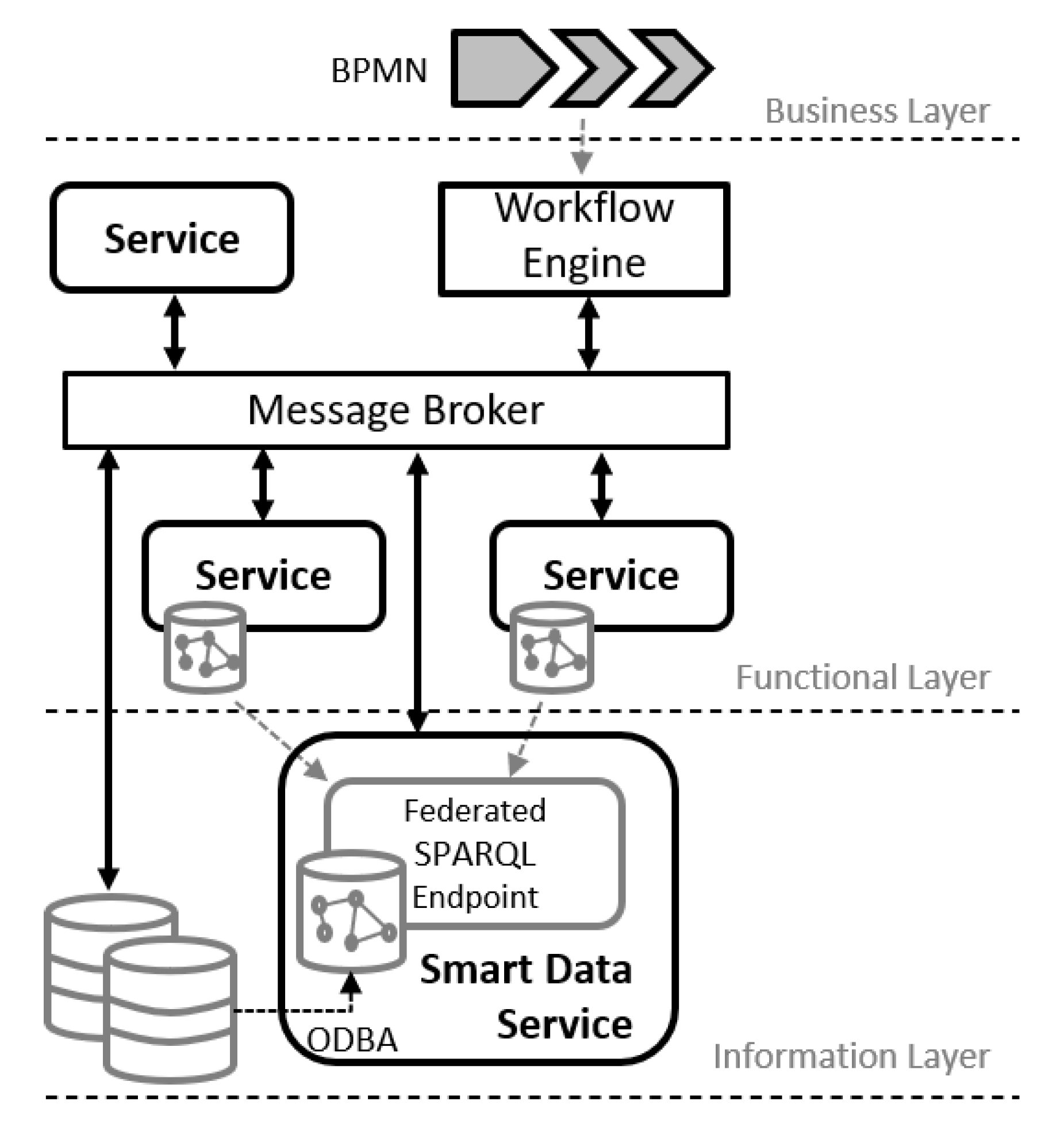
3. Microservice Framework Architecture
3.1. Identified Requirements
3.1.1. Non-Functional Requirements
3.1.2. Functional Requirements
3.2. Proposed Service Framework Architecture
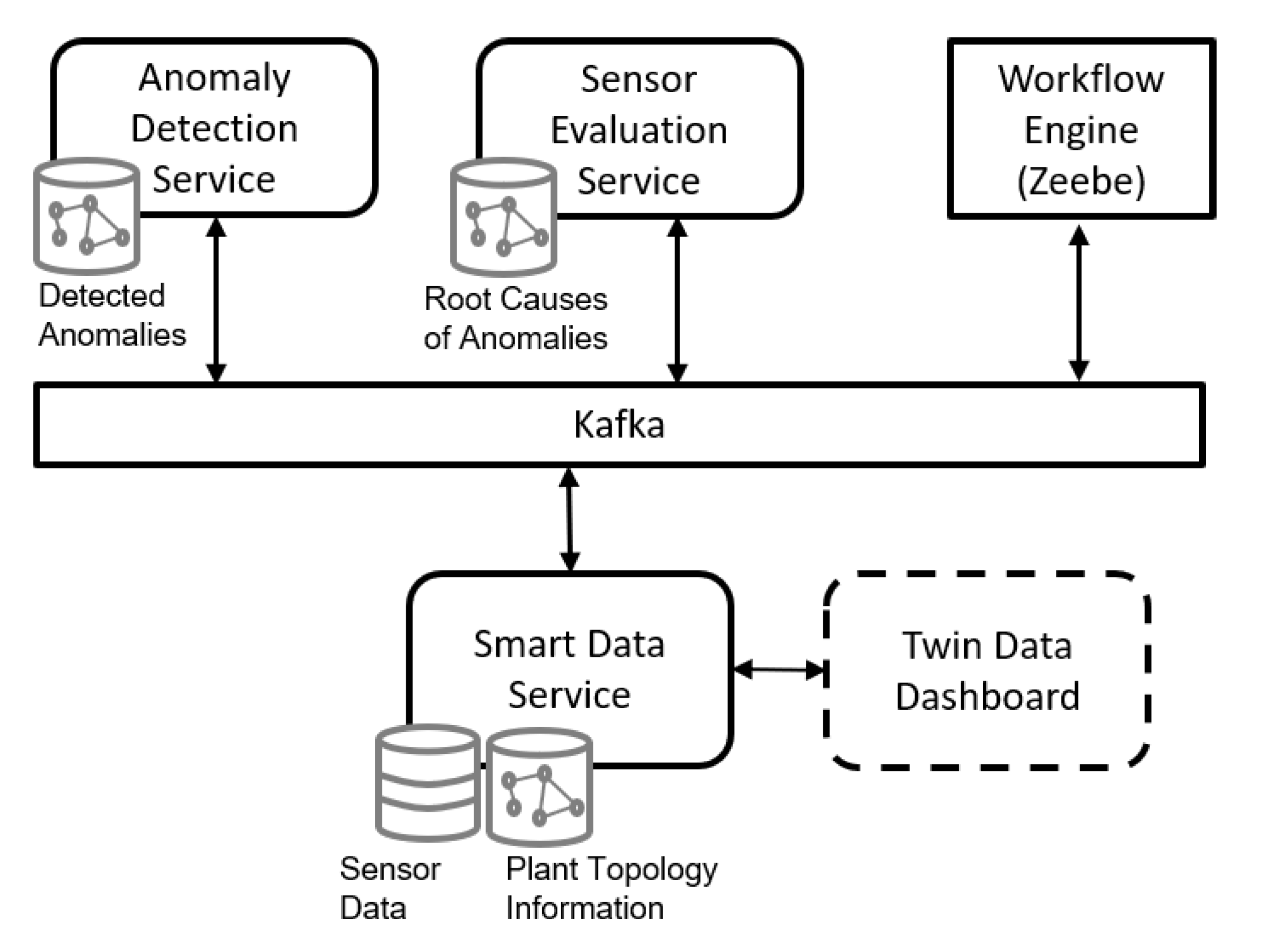
4. Proof-of-Concept: Automatic Sensor Data Evaluation
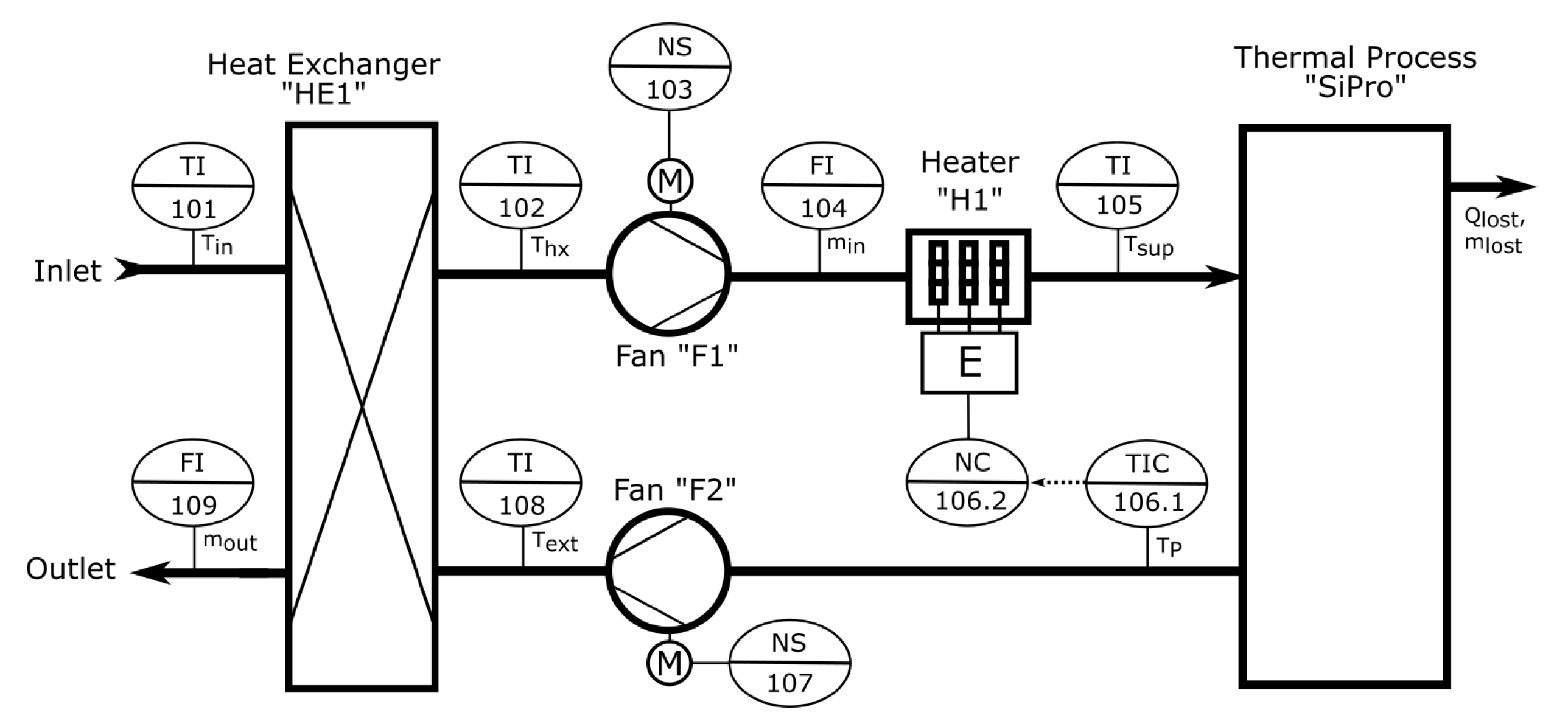
4.1. Use-Case: Thermal Heating Process
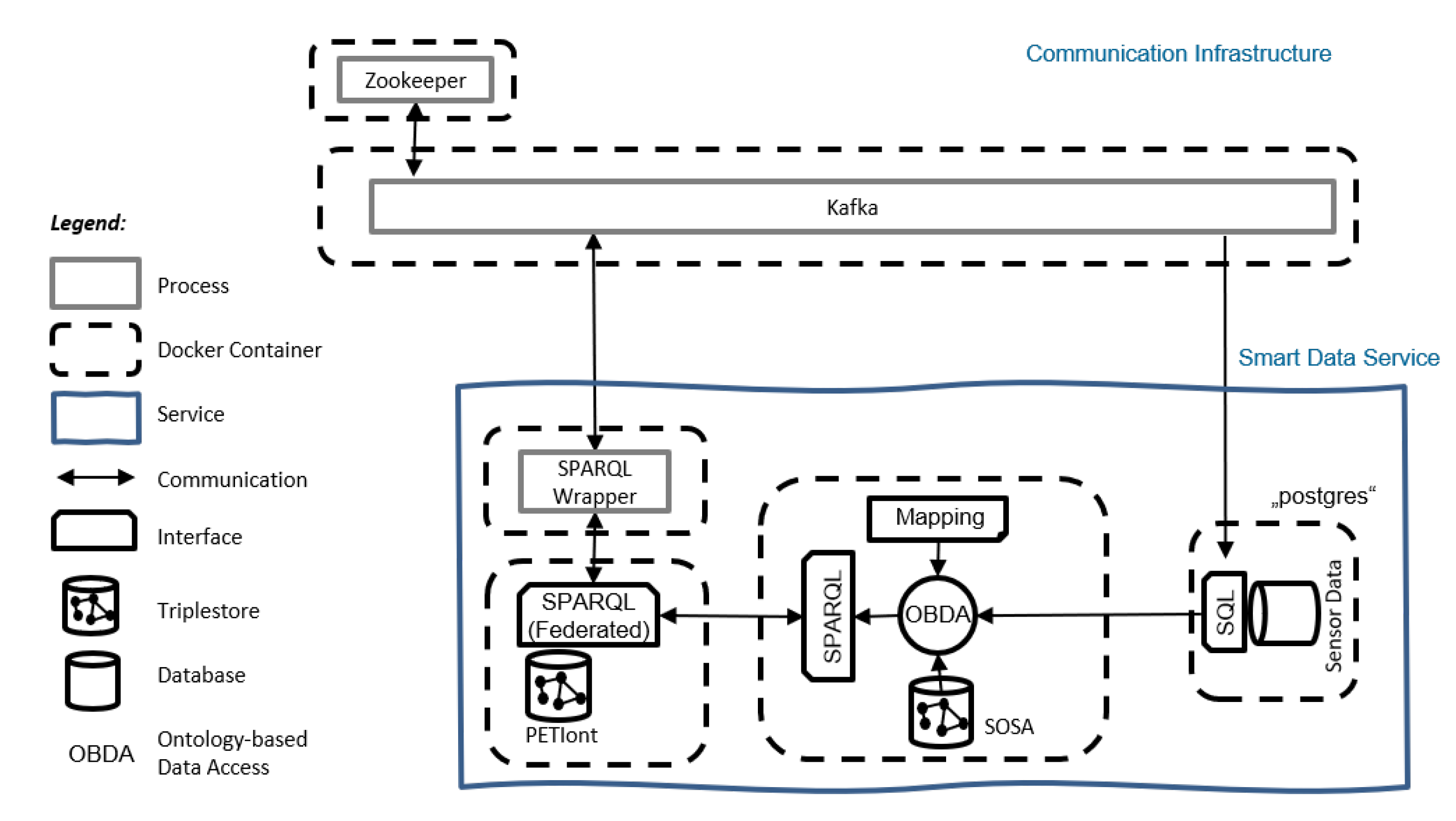
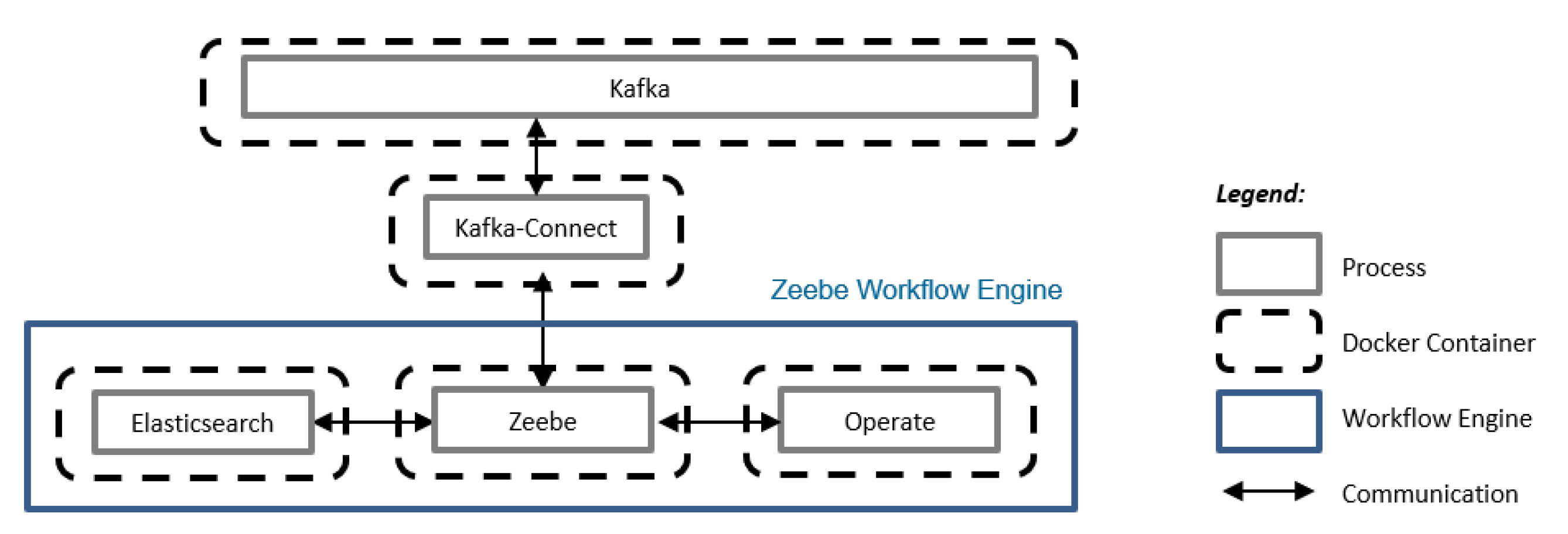
4.2. Smart Data Service and Communication Infrastructure
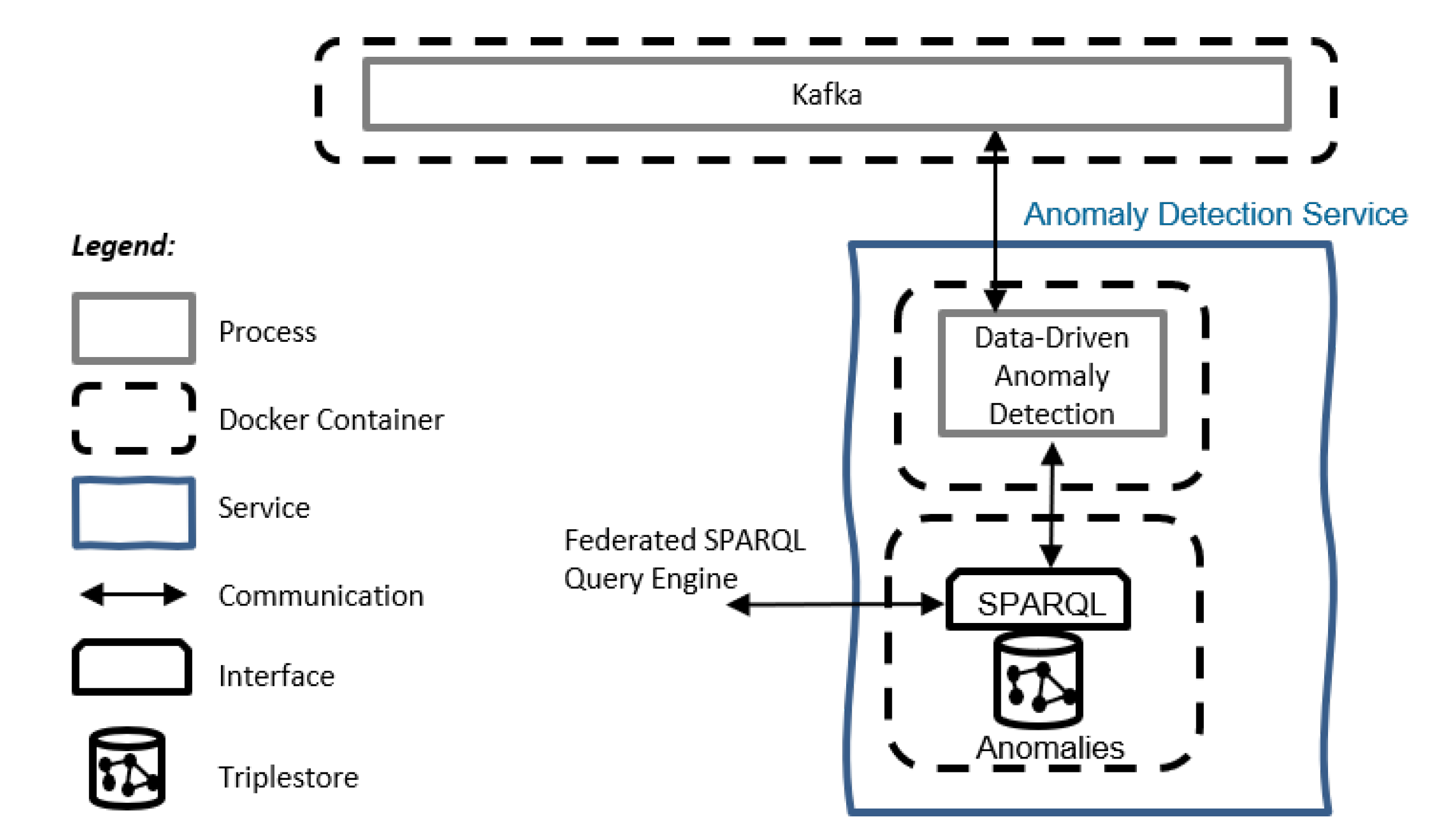
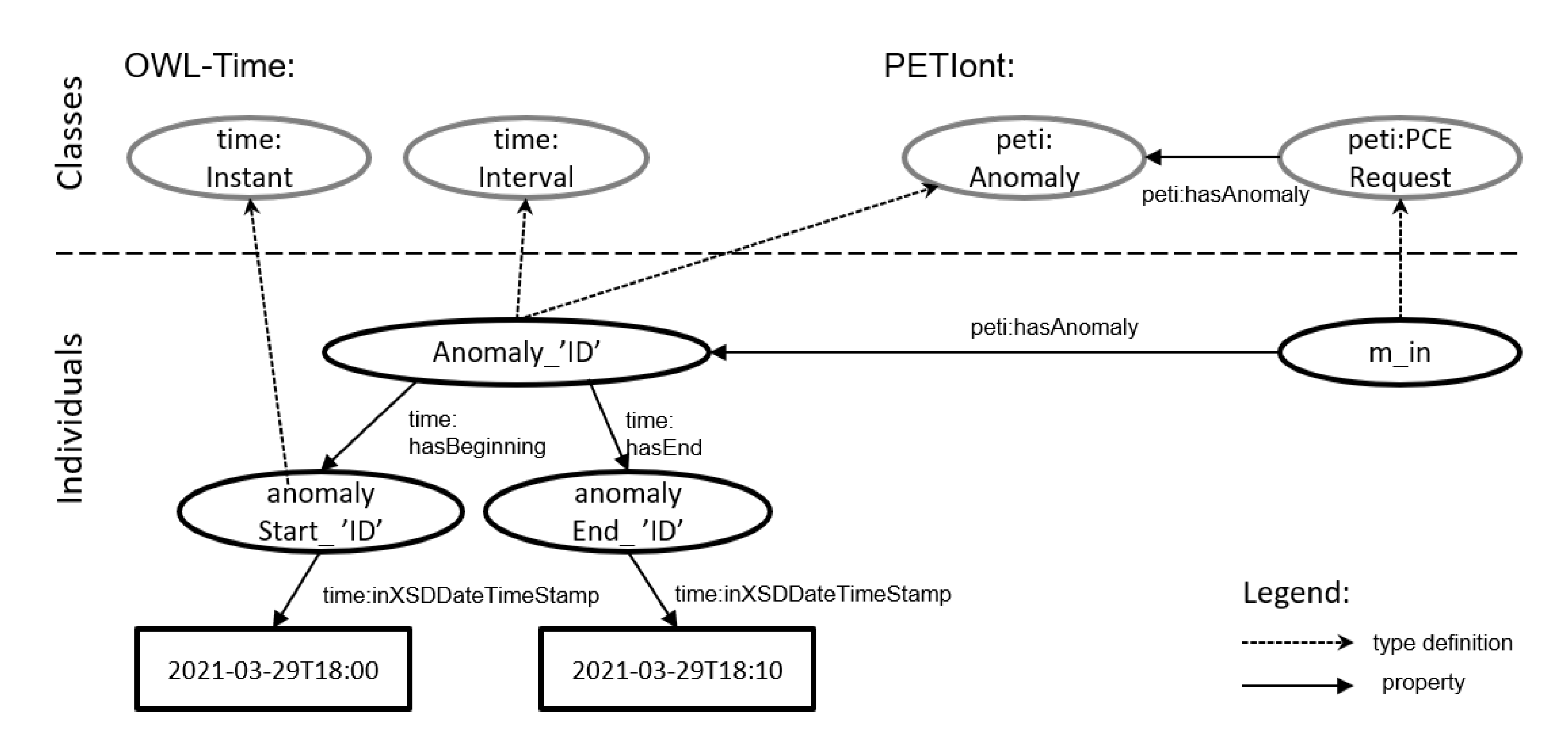
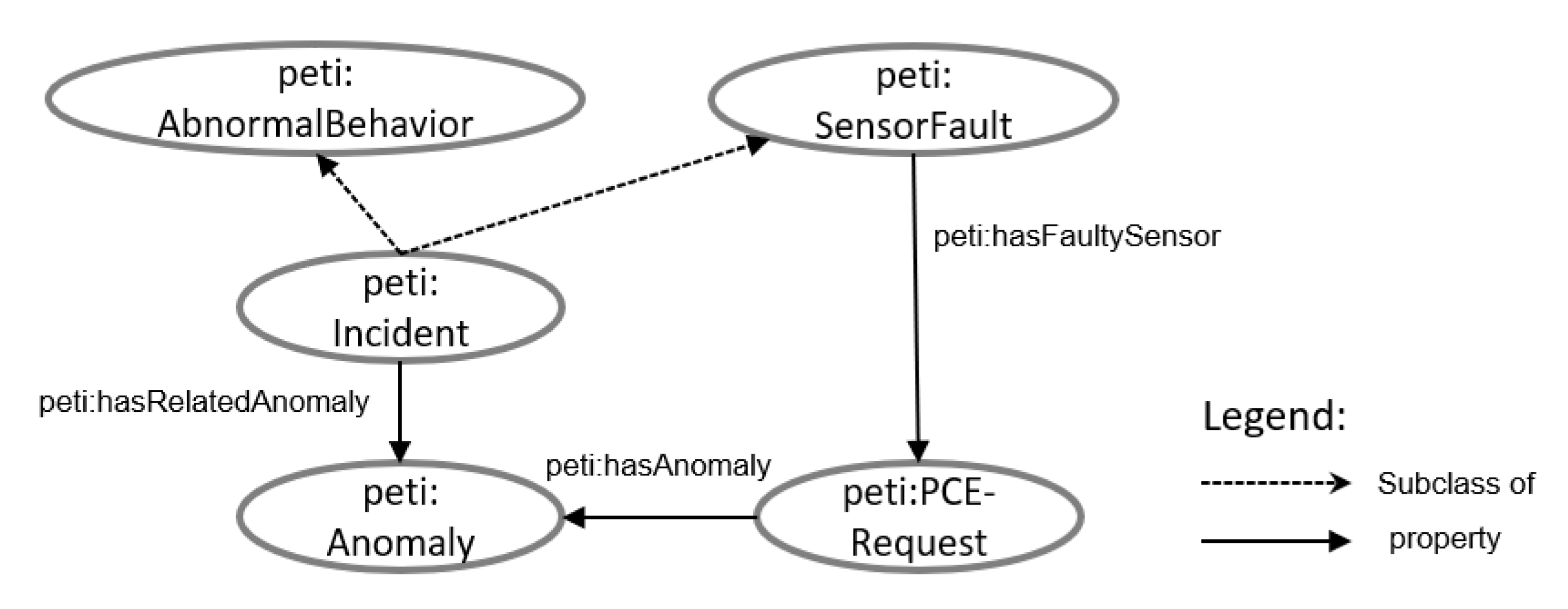
4.3. Anomaly Detection Service
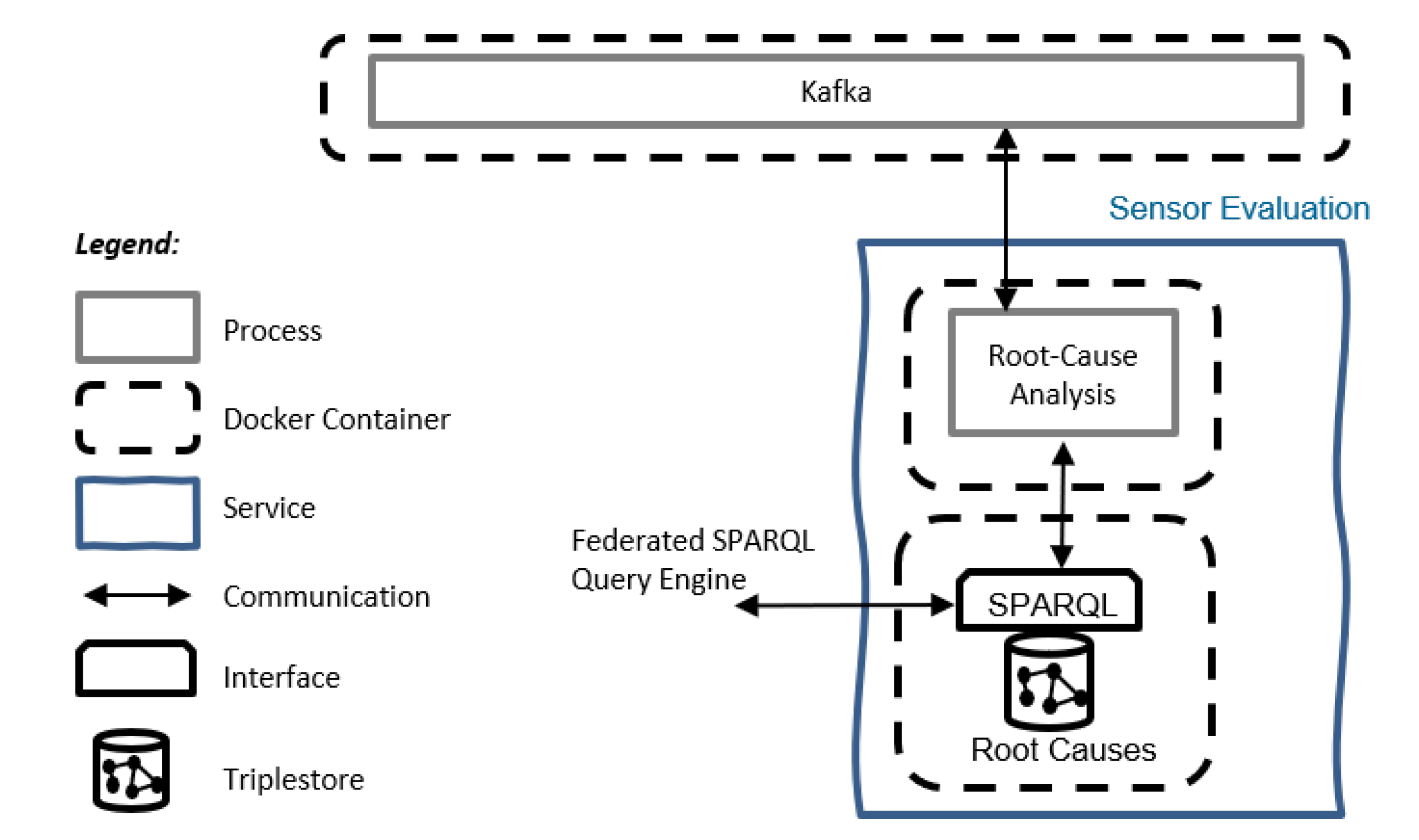
4.4. Sensor Evaluation Service
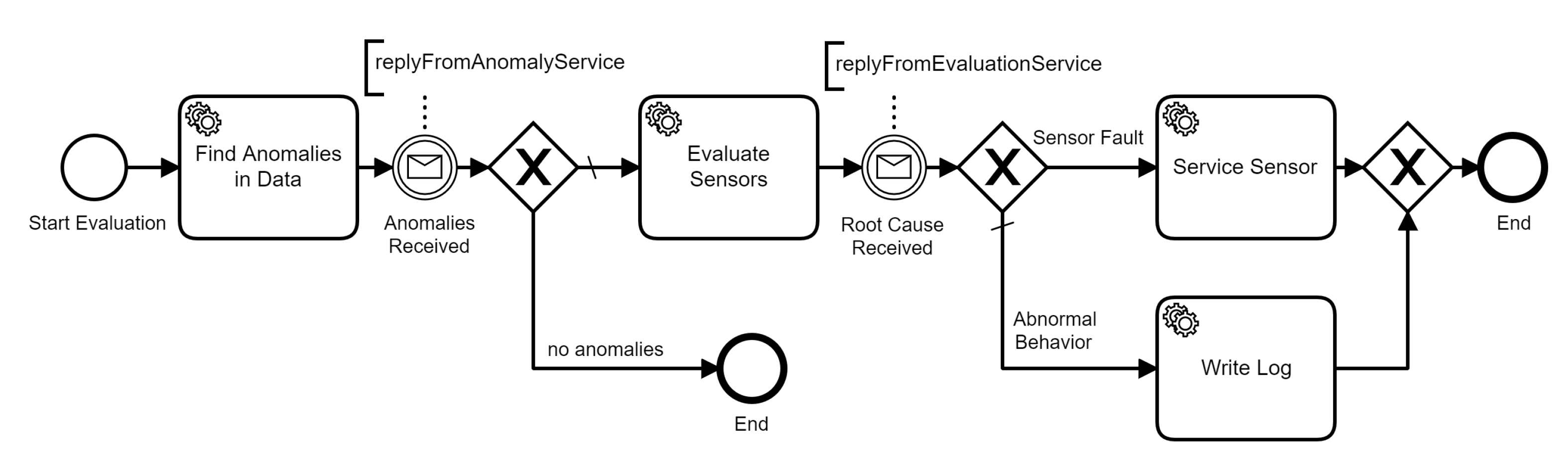
4.5. Service Orchestration
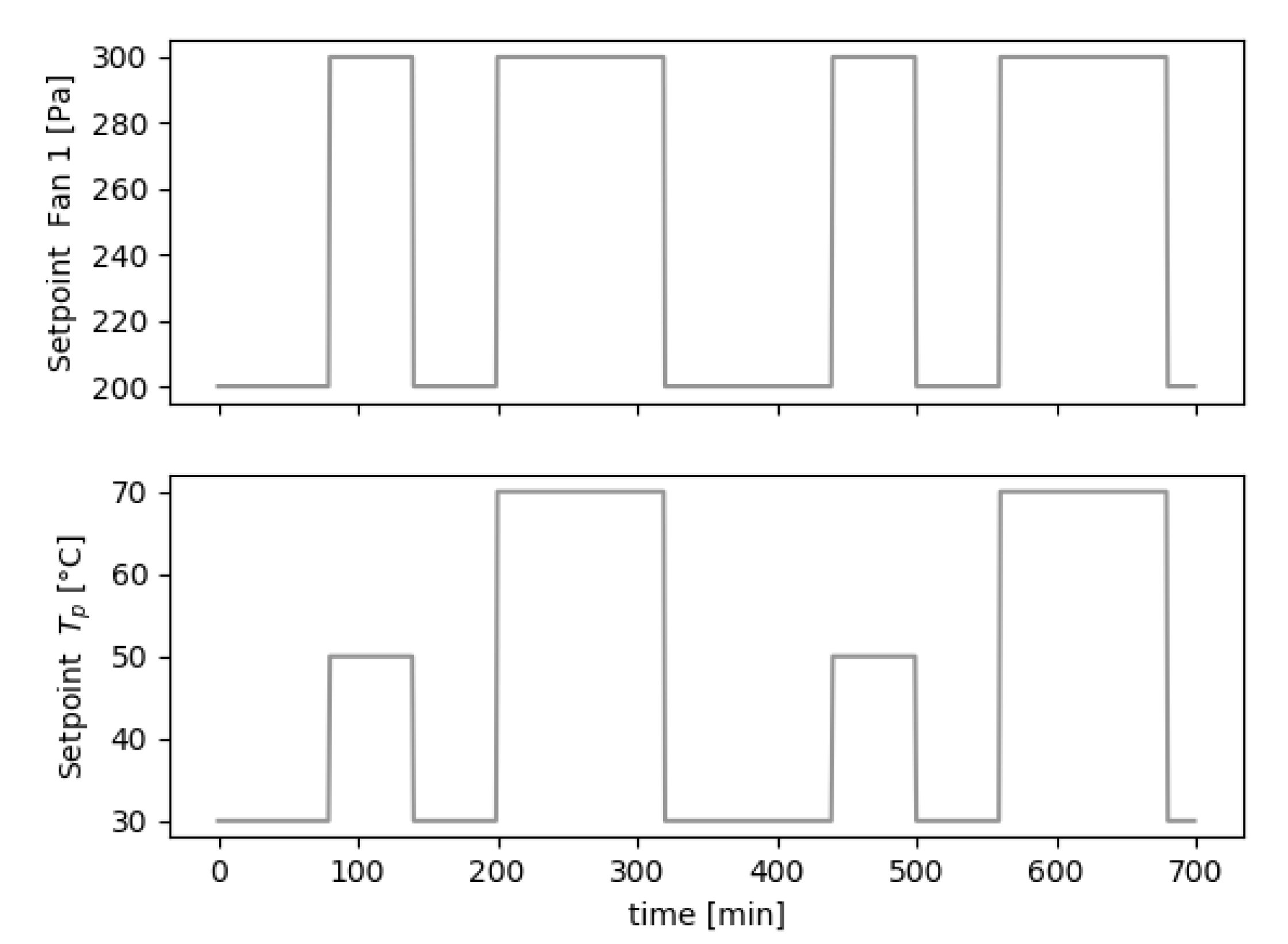
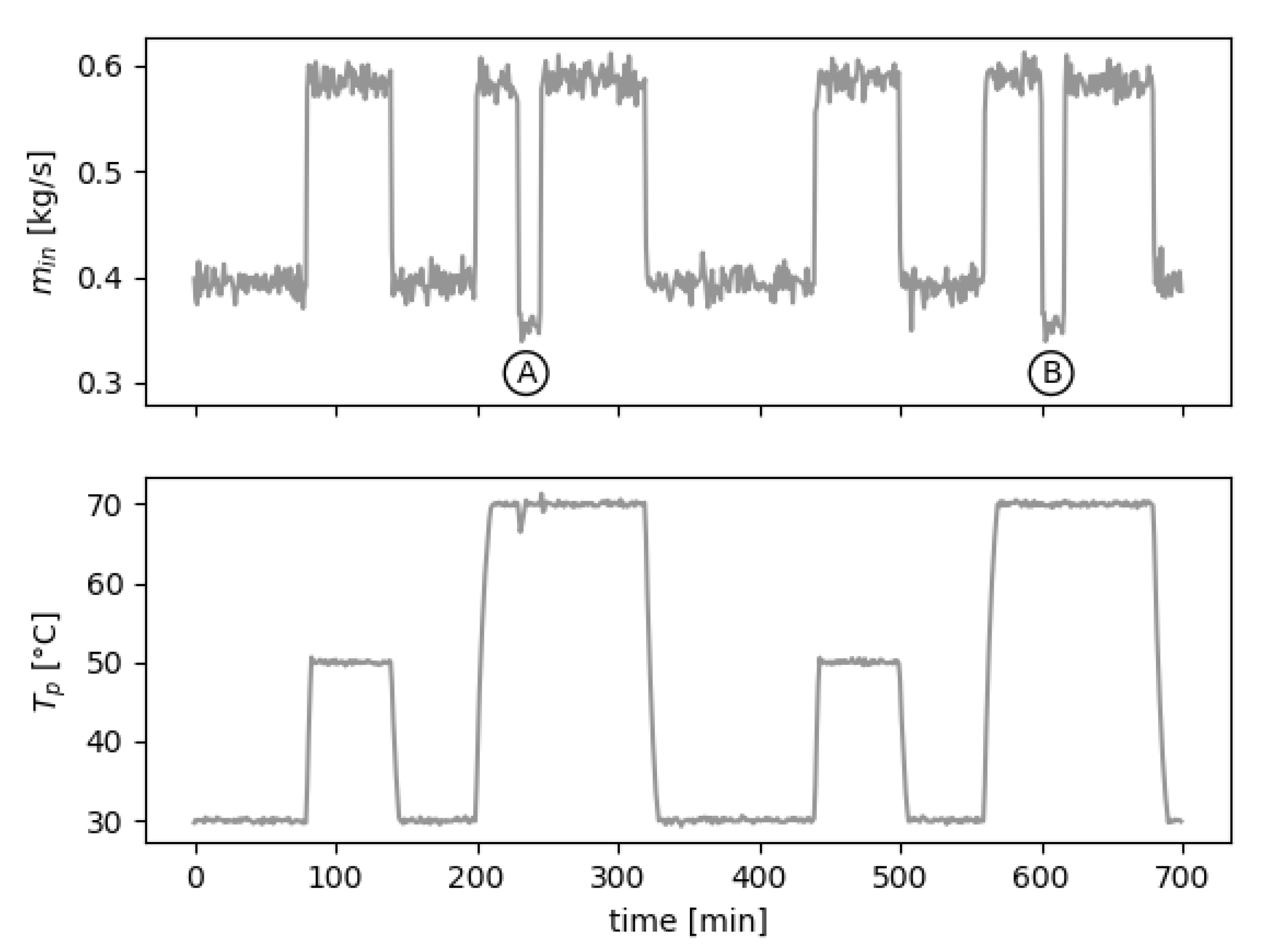
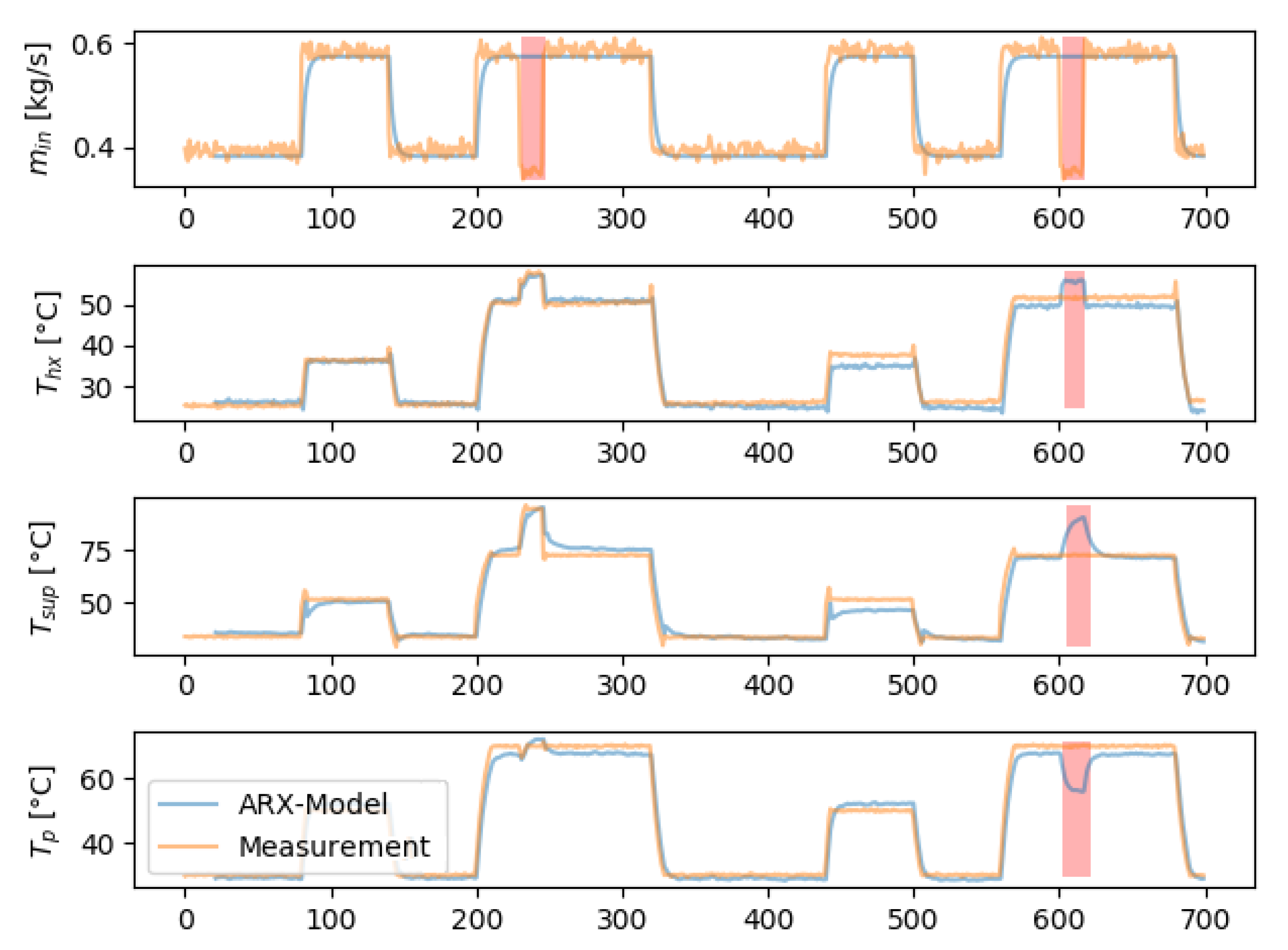
4.6. Results of the Sensor Evaluation Process
5. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| 5D-DT | Five-Dimensional Digital Twin |
| ARX | Autoregressive with exogenous input |
| BPMN | Business Process Model and Notation |
| DT | Digital Twin |
| ESB | Enterprise Service Bus |
| GDTA | Generic Digital Twin Architecture |
| HTTP | Hypertext Transfer Protocol |
| ICPS | Industrial Cyber-Physical Systems |
| ICT | Information and Communication Technology |
| IIRA | Industrial Internet Reference Architecture |
| IoT | Internet of Things |
| IT | Information Technology |
| JSON-LD | JSON for Linking Data |
| MOM | Message-oriented Middleware |
| OBDA | Ontology-Based Data Access |
| OPC UA | OPC Unified Architecture |
| OWL | Web Ontology Language |
| RAMI 4.0 | Reference Architecture Model Industry 4.0 |
| REST | Representational State Transfer |
| SPARQL | SPARQL Protocol and RDF Query Language |
References
- Parida, V.; Sjödin, D.; Reim, W. Reviewing literature on digitalization, business model innovation, and sustainable industry: Past achievements and future promises. Sustainability 2019, 11, 391. [Google Scholar] [CrossRef] [Green Version]
- Tao, F.; Zhang, H.; Liu, A.; Nee, A.Y. Digital Twin in Industry: State-of-the-Art. IEEE Trans. Ind. Inform. 2019, 15, 2405–2415. [Google Scholar] [CrossRef]
- Malakuti, S.; van Schalkwyk, P.; Boss, B.; Ram Sastry, C.; Runkana, V.; Lin, S.W.; Rix, S.; Green, G.; Baechle, K.; Varan Nath, C. Digital Twins for Industrial Applications. Definition, Business Values, Design Aspects, Standards and Use Cases; White Paper; Industrial Internet Consortium: Milford, MA, USA, 2020; pp. 1–19. [Google Scholar]
- Lu, Y.; Liu, C.; Wang, K.I.; Huang, H.; Xu, X. Digital Twin-driven smart manufacturing: Connotation, reference model, applications and research issues. Robot. Comput. Integr. Manuf. 2020, 61, 101837. [Google Scholar] [CrossRef]
- Grieves, M. Digital Twin: Manufacturing Excellence through Virtual Factory Replication this paper Introduces the Concept of a A Whitepaper by Dr. Michael Grieves; White Paper; Florida Institute of Technology: Melbourne, FL, USA, 2014. [Google Scholar]
- Ashtari Talkhestani, B.; Jung, T.; Lindemann, B.; Sahlab, N.; Jazdi, N.; Schloegl, W.; Weyrich, M. An architecture of an Intelligent Digital Twin in a Cyber-Physical Production System. Automatisierungstechnik 2019, 67, 762–782. [Google Scholar] [CrossRef] [Green Version]
- Josifovska, K.; Yigitbas, E.; Engels, G. Reference Framework for Digital Twins within Cyber-Physical Systems. In Proceedings of the 2019 IEEE/ACM 5th International Workshop on Software Engineering for Smart Cyber-Physical Systems, SEsCPS 2019, Montreal, QC, Canada, 28 May 2019; pp. 25–31. [Google Scholar] [CrossRef]
- Tao, F.; Zhang, M.; Nee, A. Five-Dimension Digital Twin Modeling and Its Key Technologies. Digit. Twin Driven Smart Manuf. 2019, 63–81. [Google Scholar] [CrossRef]
- Abburu, S.; Berre, A.J.; Jacoby, M.; Roman, D.; Stojanovic, L.; Stojanovic, N. COGNITWIN—Hybrid and Cognitive Digital Twins for the Process Industry. In Proceedings of the 2020 IEEE International Conference on Engineering, Technology and Innovation (ICE/ITMC), Cardiff, UK, 15–17 June 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Steindl, G.; Stagl, M.; Kasper, L.; Kastner, W.; Hofmann, R. Generic digital twin architecture for industrial energy systems. Appl. Sci. 2020, 10, 8903. [Google Scholar] [CrossRef]
- Adolphs, P.; Bedenbender, H.; Dirzus, D.; Martin, E. Reference Architecture Model Industrie 4.0 (RAMI4.0); Technical Report; VDI/VDE-Gesellschaft Mess- und Automatisierungstechnik/ZVEI: Düsseldorf, Germany, July 2015; Available online: https://www.vdi.de/ueber-uns/presse/publikationen/details/reference-architecture-model-industrie-40-rami40-english-version (accessed on 17 June 2021).
- De Lauretis, L. From monolithic architecture to microservices architecture. In Proceedings of the 2019 IEEE 30th International Symposium on Software Reliability Engineering Workshops (ISSREW 2019), Berlin, German, 27–30 October 2019; pp. 93–96. [Google Scholar] [CrossRef]
- Dragoni, N.; Giallorenzo, S.; Lafuente, A.L.; Mazzara, M.; Montesi, F.; Mustafin, R.; Safina, L. Microservices: Yesterday, Today, and Tomorrow. In Present and Ulterior Software Engineering; Springer International Publishing: Cham, Switzerland, 2017; pp. 195–216. [Google Scholar] [CrossRef] [Green Version]
- Stutz, A.; Fay, A.; Barth, M.; Maurmaier, M. Orchestration vs. Choreography Functional Association for Future Automation Systems. IFAC-PapersOnLine 2020, 53, 8268–8275. [Google Scholar] [CrossRef]
- Newman, S. Building Microservices—Design Fine Grained Systems; O’Reilly Media, Inc.: Newton, MA, USA, 2021. [Google Scholar]
- Foundation, A.S. Apache Kafka. Available online: https://kafka.apache.org/ (accessed on 12 May 2021).
- Cimino, C.; Negri, E.; Fumagalli, L. Review of digital twin applications in manufacturing. Comput. Ind. 2019, 113, 103130. [Google Scholar] [CrossRef]
- Damjanovic-Behrendt, V.; Behrendt, W. An open source approach to the design and implementation of Digital Twins for Smart Manufacturing. Int. J. Comput. Integr. Manuf. 2019, 32, 366–384. [Google Scholar] [CrossRef]
- Alaasam, A.B.; Radchenko, G.; Tchernykh, A. Stateful stream processing for digital twins: Microservice-based kafka stream dsl. In Proceedings of the SIBIRCON 2019—International Multi-Conference on Engineering, Computer and Information Sciences, Novosibirsk, Russia, 21–27 October 2019; pp. 804–809. [Google Scholar] [CrossRef]
- Theorin, A.; Bengtsson, K.; Provost, J.; Lieder, M.; Johnsson, C.; Lundholm, T.; Lennartson, B. An event-driven manufacturing information system architecture for Industry 4.0. Int. J. Prod. Res. 2017, 55, 1297–1311. [Google Scholar] [CrossRef]
- Apache Software Foundation. Apache ActiveMQ—Flexible & Powerful Open Source Multi-Protocol Messaging. Available online: https://activemq.apache.org/ (accessed on 19 May 2021).
- Ali, S.; Jarwar, M.A.; Chong, I. Design methodology of microservices to support predictive analytics for IoT applications. Sensors 2018, 18, 4226. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Docker. Docker—Accelerate How You Build, Share and Run Modern Applications. Available online: https://www.docker.com/ (accessed on 19 May 2021).
- Fattah, S.; Sung, N.M.; Ahn, I.Y.; Ryu, M.; Yun, J. Building IoT services for aging in place using standard-based IoT platforms and heterogeneous iot products. Sensors 2017, 17, 2311. [Google Scholar] [CrossRef]
- Moyne, J.; Qamsane, Y.; Balta, E.C.; Kovalenko, I.; Faris, J.; Barton, K.; Tilbury, D.M. A Requirements Driven Digital Twin Framework: Specification and Opportunities. IEEE Access 2020, 8, 107781–107801. [Google Scholar] [CrossRef]
- Tao, F.; Cheng, J.; Qi, Q.; Zhang, M.; Zhang, H.; Sui, F. Digital twin-driven product design, manufacturing and service with big data. Int. J. Adv. Manuf. Technol. 2018, 94, 3563–3576. [Google Scholar] [CrossRef]
- Alam, K.M.; El Saddik, A. C2PS: A digital twin architecture reference model for the cloud-based cyber-physical systems. IEEE Access 2017, 5, 2050–2062. [Google Scholar] [CrossRef]
- Engelsberger, M.; Greiner, T. Software architecture for cyber-physical control systems with flexible application of the software-as-a-service and on-premises model. In Proceedings of the IEEE International Conference on Industrial Technology, Seville, Spain, 17–19 March 2015; pp. 1544–1549. [Google Scholar] [CrossRef]
- Ding, K.; Chan, F.T.; Zhang, X.; Zhou, G.; Zhang, F. Defining a Digital Twin-based Cyber-Physical Production System for autonomous manufacturing in smart shop floors. Int. J. Prod. Res. 2019, 57, 6315–6334. [Google Scholar] [CrossRef] [Green Version]
- Saad, A.; Faddel, S.; Mohammed, O. IoT-based digital twin for energy cyber-physical systems: Design and implementation. Energies 2020, 13, 4762. [Google Scholar] [CrossRef]
- Borodulin, K.; Sokolinsky, L.; Radchenko, G.; Tchernykh, A.; Shestakov, A.; Prodan, R. Towards digital twins cloud platform: Microservices and computational workflows to rule a smart factory. In Proceedings of the 10th International Conference on Utility and Cloud Computing—UCC 2017, Austin, TX, USA, 5–8 December 2017; pp. 205–206. [Google Scholar] [CrossRef]
- Gorecky, D.; Schmitt, M.; Loskyll, M.; Zühlke, D. Human–machine-interaction in the industry 4.0 era. In Proceedings of the 2014 12th IEEE International Conference on Industrial Informatics (INDIN 2014), Porto Alegre, Brazil, 27–30 July 2014; pp. 289–294. [Google Scholar] [CrossRef]
- Panfilenko, D.; Poller, P.; Sonntag, D.; Zillner, S.; Schneider, M. BPMN for knowledge acquisition and anomaly handling in CPS for smart factories. In Proceedings of the IEEE International Conference on Emerging Technologies and Factory Automation, ETFA, Berlin, Germany, 6–9 September 2016; pp. 2–5. [Google Scholar] [CrossRef]
- Kleppmann, M. Designing Data-Intensive Applications; O’Reilly Media, Inc.: Newton, MA, USA, 2017. [Google Scholar]
- Ehrlinger, L.; Wöß, W. Towards a definition of knowledge graphs. In Proceedings of the CEUR Workshop, Leipzig, Germany, 13–14 September 2016; Volume 1695. [Google Scholar]
- Studer, R.; Benjamins, V.R.; Fensel, D. Knowledge Engineering: Principles and methods. Data Knowl. Eng. 1998, 25, 161–197. [Google Scholar] [CrossRef] [Green Version]
- Schwarte, A.; Haase, P.; Hose, K.; Schenkel, R.; Schmidt, M. FedX: Optimization techniques for federated query processing on linked data. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar] [CrossRef] [Green Version]
- Steindl, G.; Kastner, W. Query Performance Evaluation of Sensor Data Integration Methods for Knowledge Graphs. In Proceedings of the 6th IEEE International Conference on Big Data, Knowledge and Control Systems Engineering, Sofia, Bulgaria, 21–22 November 2019. [Google Scholar]
- Schachinger, D.; Kastner, W.; Gaida, S. Ontology-based abstraction layer for smart grid interaction in building energy management systems. In Proceedings of the 2016 IEEE International Energy Conference (ENERGYCON 2016), Leuven, Belgium, 4–8 April 2016. [Google Scholar] [CrossRef]
- Richardson, C. Microservices Patterns; Manning Publications: Shelter Island, NY, USA, 2018; p. 520. [Google Scholar]
- Kozma, D.; Varga, P.; Larrinaga, F. Dynamic Multilevel Workflow Management Concept for Industrial IoT Systems. IEEE Trans. Autom. Sci. Eng. 2020, 1–13. [Google Scholar] [CrossRef]
- Gutiérrez–Fernández, A.M.; Resinas, M.; Ruiz–Cortés, A. Redefining a process engine as a microservice platform. Lect. Notes Bus. Inf. Process. 2017, 281, 252–263. [Google Scholar] [CrossRef]
- Camunda. Zeebe Workflow Engine for Microservices Orchestration. Available online: https://github.com/camunda-cloud/zeebe (accessed on 12 May 2021).
- RDF4J. Federation with FedX. Available online: https://rdf4j.org/documentation/programming/federation/ (accessed on 12 May 2021).
- Steindl, G. Digital Twin Service Framework. Available online: https://github.com/Smart-Industrial-Concept/DigitalTwinServiceFramework (accessed on 19 May 2021).
- Fritzson, P.; Pop, A.; Abdelhak, K.; Ashgar, A.; Bachmann, B.; Braun, W.; Bouskela, D.; Braun, R.; Buffoni, L.; Casella, F.; et al. The OpenModelica Integrated Environment for Modeling, Simulation, and Model-Based Development. Model. Identif. Control 2020, 41, 241–295. [Google Scholar] [CrossRef]
- Steindl, G. Heating Process Simulation. Available online: https://github.com/Smart-Industrial-Concept/HeatingProcessSimulation (accessed on 19 May 2021).
- Steindl, G.; Kastner, W. Ontology-Based Model Identification of Industrial Energy Systems. IEEE Int. Symp. Ind. Electron. 2020, 1217–1223. [Google Scholar] [CrossRef]
- The PostgreSQL Global Development Group. PostgreSQL: The World’s Most Advanced Open Source Relational Database. Available online: https://www.postgresql.org/ (accessed on 12 May 2021).
- Xiao, G.; Lanti, D.; Kontchakov, R.; Komla-Ebri, S.; Güzel-Kalaycı, E.; Ding, L.; Corman, J.; Cogrel, B.; Calvanese, D.; Botoeva, E. The virtual knowledge graph system ontop. CEUR Workshop Proc. 2020, 2663, 1–16. [Google Scholar]
- World Wide Web Consortium. Semantic Sensor Network Ontology. W3C Recommendation. Available online: https://www.w3.org/TR/vocab-ssn/ (accessed on 19 May 2021).
- Hobbs, J.R.; Little, C. Time Ontology in OWL. W3C Candidate Recommendation. Technical Report, World Wide Web Consortium (W3C). 2020. Available online: https://www.w3.org/TR/owl-time/ (accessed on 17 June 2021).
- Elastic. Elasticsearch—Distributed, Multitenant-Capable Full-Text Search Engine. Available online: https://www.elastic.co/elasticsearch/ (accessed on 19 May 2021).
- Ekaputra, F.J.; Sabou, M.; Serral, E.; Kiesling, E.; Biffl, S. Ontology-Based Data Integration in Multi-Disciplinary Engineering Environments: A Review. Open J. Inf. Systms 2017, 4, 1–26. [Google Scholar]
- Frühwirth, T.; Kastner, W.; Krammer, L. A methodology for creating reusable ontologies. In Proceedings of the 2018 IEEE Industrial Cyber-Physical Systems (ICPS 2018), St. Petersburg, Russia, 15–18 May 2018; pp. 65–70. [Google Scholar] [CrossRef]
- Kozma, D.; Varga, P.; Larrinaga, F. Data-driven Workflow Management by utilising BPMN and CPN in IIoT Systems with the Arrowhead Framework. In Proceedings of the IEEE International Conference on Emerging Technologies and Factory Automation, ETFA, Zaragoza, Spain, 10–13 September 2019; pp. 385–392. [Google Scholar] [CrossRef]
- Steindl, G.; Früwirth, T.; Kastner, W. Ontology-Based OPC UA Data Access via Custom Property Functions. In Proceedings of the 24th Interantional Conference on Emerging Technologies and Factory Automation, Zaragoza, Spain, 10–13 September 2019. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Requirement | Origin |
|---|---|---|
| RN1 | The DT and its services should be able to be hosted at the cloud as well as on-premises for data ownership and performance reasons. | [27,31] |
| RN2 | Services of a DT should be loosely coupled to add or remove new services without influencing each other. | [25,26] |
| RN3 | Services of a DT should be scalable to handle requests from a single machine up to a whole factory. | [25,34] |
| RN4 | Services of a DT should be maintainable by different development teams (third party integration). | [34] |
| RN5 | The service infrastructure of a DT should tolerate short down times of single services to increase the reliability. | [34] |
| ID | Requirement | Origin |
|---|---|---|
| RI1 | The DT should be able to process heterogeneous data from different sources. | [26] |
| RI2 | The DT should be able to interlink time series data with context information, to make it interpretable for other services. | [26] |
| RI3 | Services of a DT should have control about the information they provide to other services. | [25] |
| RI4 | The DT should have a service which provides access to the information provided by all services of the DT. | [10,25] |
| RI5 | Services of the DT should exchange information in a semantically meaningful way. | [25] |
| ID | Requirement | Origin |
|---|---|---|
| RF1 | Services shall be able to access a continuous stream of (sensor) data to monitor the system in real-time. | [26] |
| RF2 | Data streams should be accessible by multiple services simultaneously to process it in parallel and reduce reaction time of the system. | [26] |
| RF3 | Services of the DT should be able to receive data streams from multiple sources at the same time to fuse and process data. | [26] |
| RF4 | Services of the DT should be able to respond to a specific service request to enable a one-to-one communication for information retrieval. | [26] |
| ID | Requirement | Origin |
|---|---|---|
| RB1 | The functional services of the DT should be able to be integrated into the business processes at enterprise level to support the value-added chain. | [25] |
| RB2 | Service interaction states should be traceable to facilitate human–machine interaction and the identification of service faults. | [32] |
| Design Artifact | Supported Requirements |
|---|---|
| Microservice Architecture | RN2, RN4 |
| Containerization | RN2, RN4 |
| MOM (Apache Kafka) | RN2, RN3, RN5, RF1, RF2, RF3, RF4 |
| Shared Knowledge graph | RI1, RI5 |
| Federated Query Engine | RI4, RI3 |
| OBDA | RI2 |
| Workflow Engine | RB1, RB2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Steindl, G.; Kastner, W. Semantic Microservice Framework for Digital Twins. Appl. Sci. 2021, 11, 5633. https://doi.org/10.3390/app11125633
Steindl G, Kastner W. Semantic Microservice Framework for Digital Twins. Applied Sciences. 2021; 11(12):5633. https://doi.org/10.3390/app11125633
Chicago/Turabian StyleSteindl, Gernot, and Wolfgang Kastner. 2021. "Semantic Microservice Framework for Digital Twins" Applied Sciences 11, no. 12: 5633. https://doi.org/10.3390/app11125633
APA StyleSteindl, G., & Kastner, W. (2021). Semantic Microservice Framework for Digital Twins. Applied Sciences, 11(12), 5633. https://doi.org/10.3390/app11125633