
Analysis of the Learning Process through Eye Tracking Technology and Feature Selection Techniques

 ,
,  , ,
, ,  ,
, 
Abstract
:1. Introduction
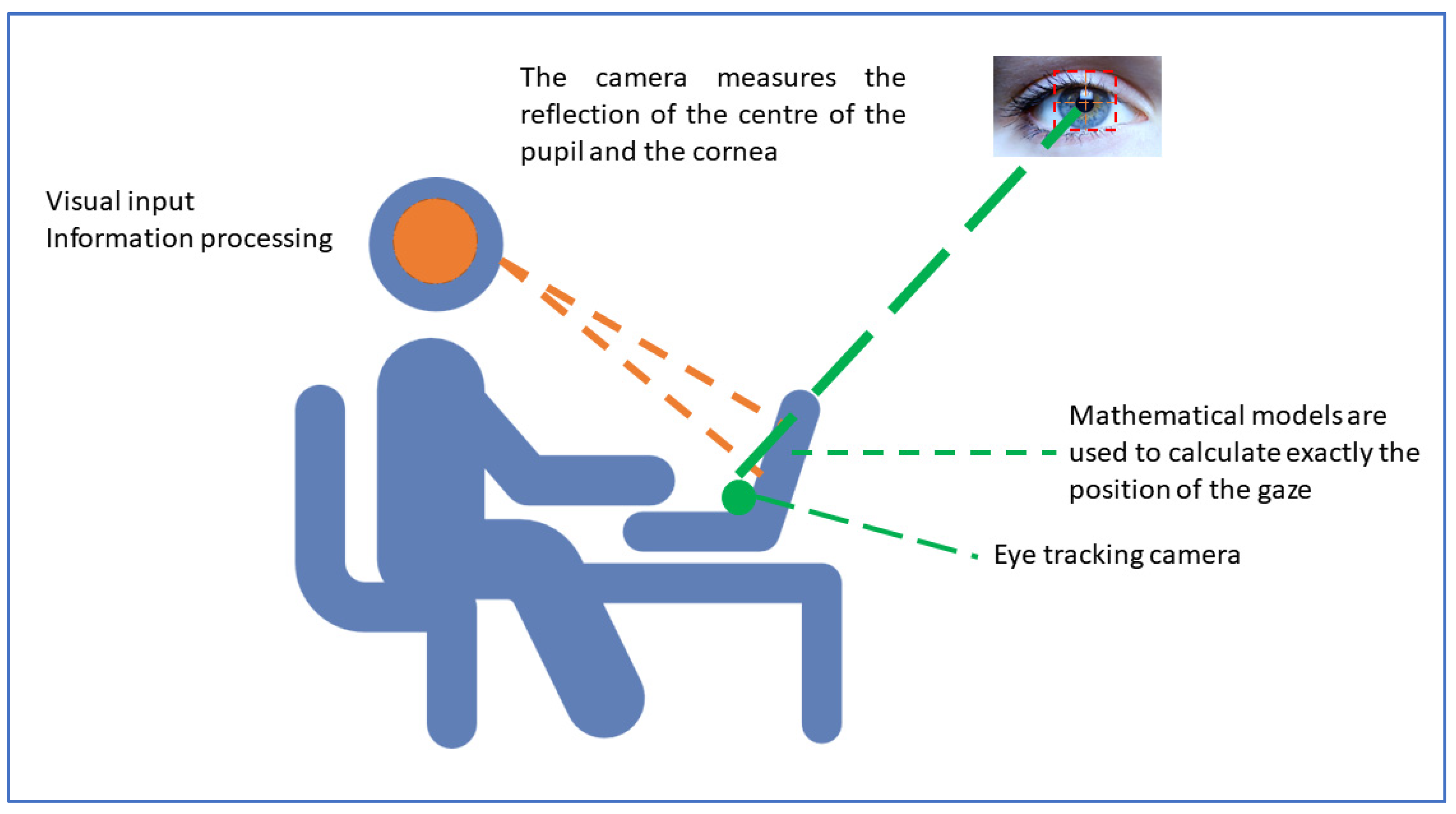
1.1. Measurement Parameters in Eye Tracking Technology
1.2. Use of Data Mining and Pattern Mining Techniques in the Interpretation of the Results Obtained with the Eye Tracking Methodology
1.3. Application of the Use of Eye Tracking Technology
2. Materials and Methods
2.1. Participants
2.2. Instruments
- (a)
- Age;
- (b)
- Gender;
- (c)
- Level of education;
- (d)
- Field of knowledge;
- (e)
- Employment status (active, retired, student);
- (f)
- Knowledge about the origin of monasteries in Europe.
- (a)
- Monks belonging to the order of St. Benedict;
- (b)
- Powerful Benedictine monastic centre founded in the 10th century, whose influence spread throughout Europe;
- (c)
- Space around which the organisation of the monastery revolves;
- (d)
- Set of rules that govern monastic life;
- (e)
- Each of the bays or sides of a cloister.
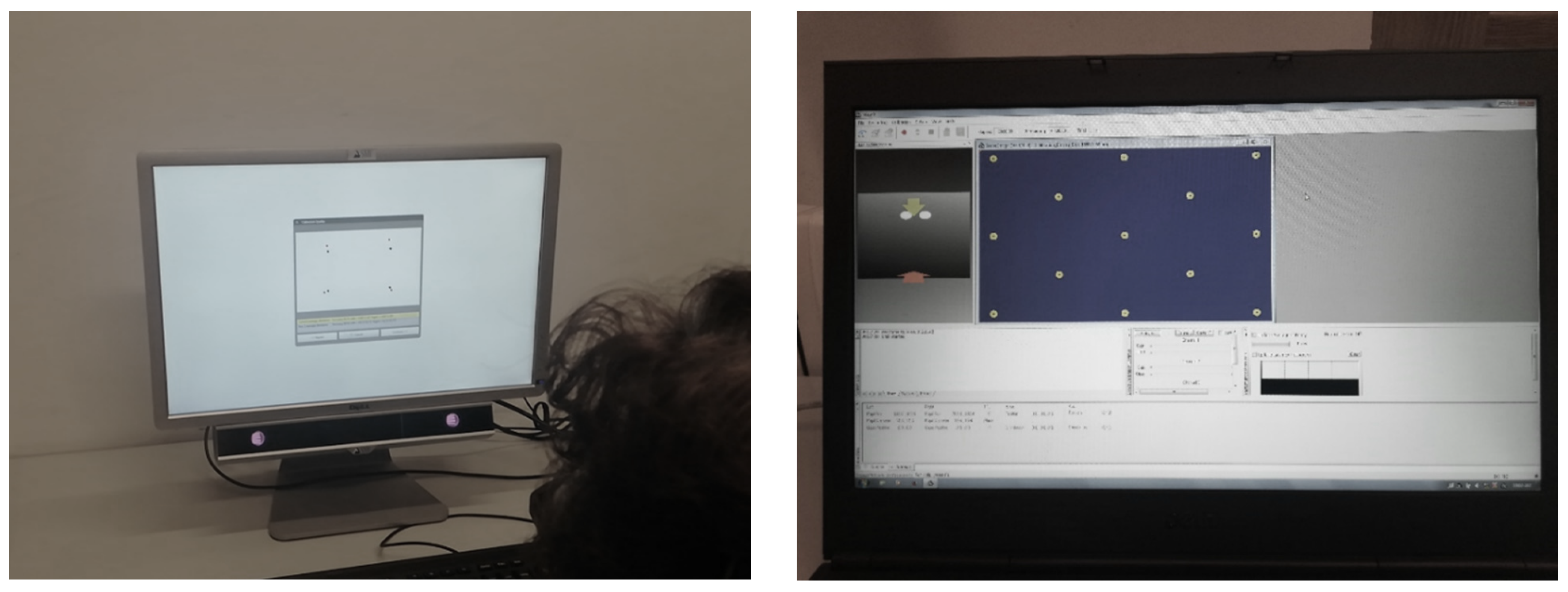
2.3. Procedure
2.4. Data Analysis
2.4.1. Statistical Study
- Solving crossword puzzle results;
- Fixations (fixation count, fixation frequency count, fixation duration total, fixation duration average, fixation duration maximum, fixation duration minimum, fixation dispersion total, fixation dispersion average, fixation dispersion maximum, fixation dispersion minimum);
- Saccades (saccade count, saccade frequency count, saccade duration total, saccade duration average, saccade duration maximum, saccade duration minimum, saccade amplitude total, saccade amplitude average, saccade amplitude maximum, saccade amplitude minimum, saccade velocity total, saccade velocity average, saccade velocity maximum, saccade velocity minimum, saccade latency average);
- Blinks (blink count, blink frequency count, blink duration total, blink duration average, blink duration maximum, blink duration minimum) and scan path length.
2.4.2. Study Using Machine Learning Techniques
3. Results
3.1. Statistical Study
3.1.1. Previous Analyses
3.1.2. Hypothesis Testing Analysis
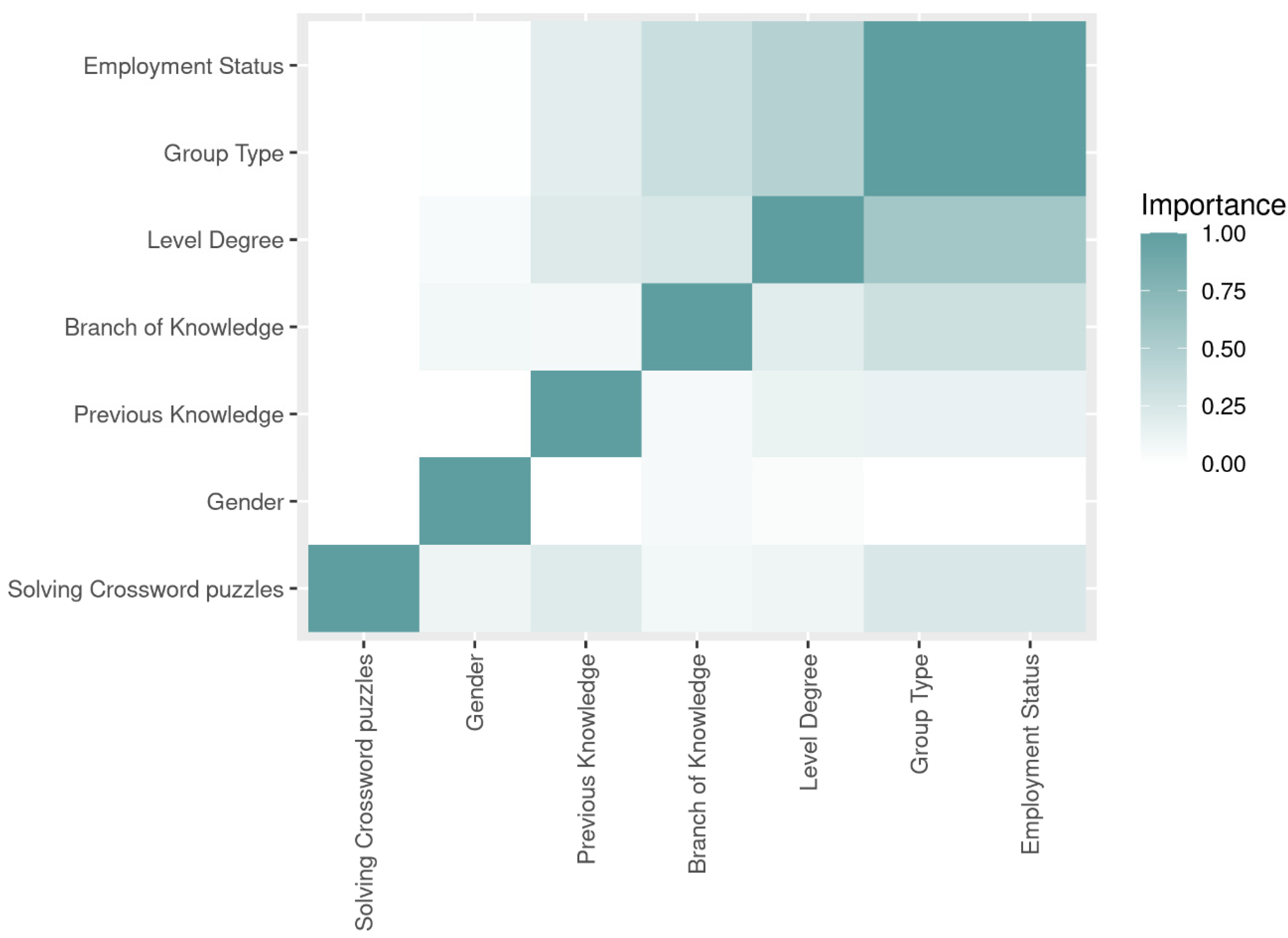
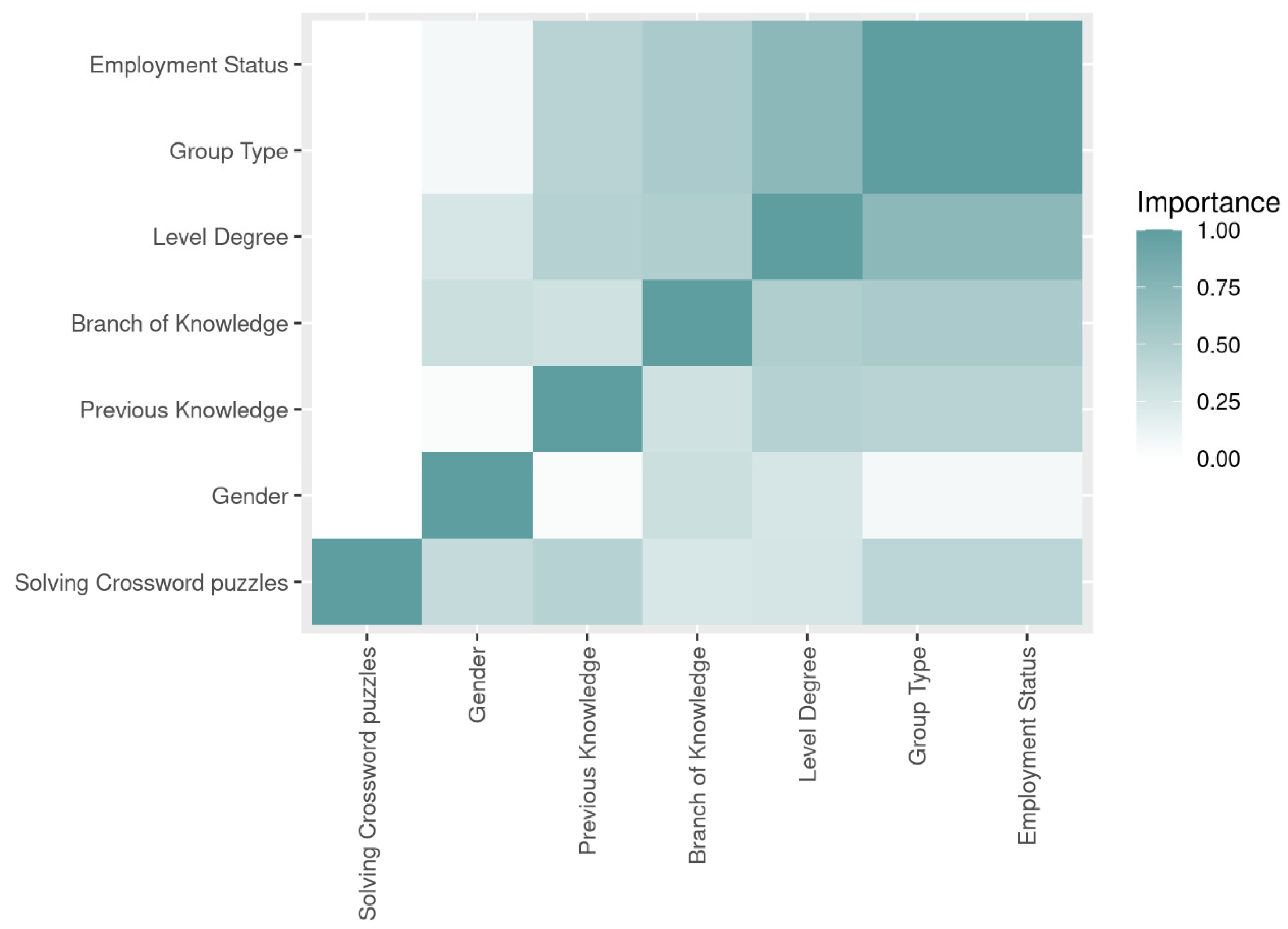
3.2. Study with Supervised Learning Machine Learning Techniques: Feature Selection
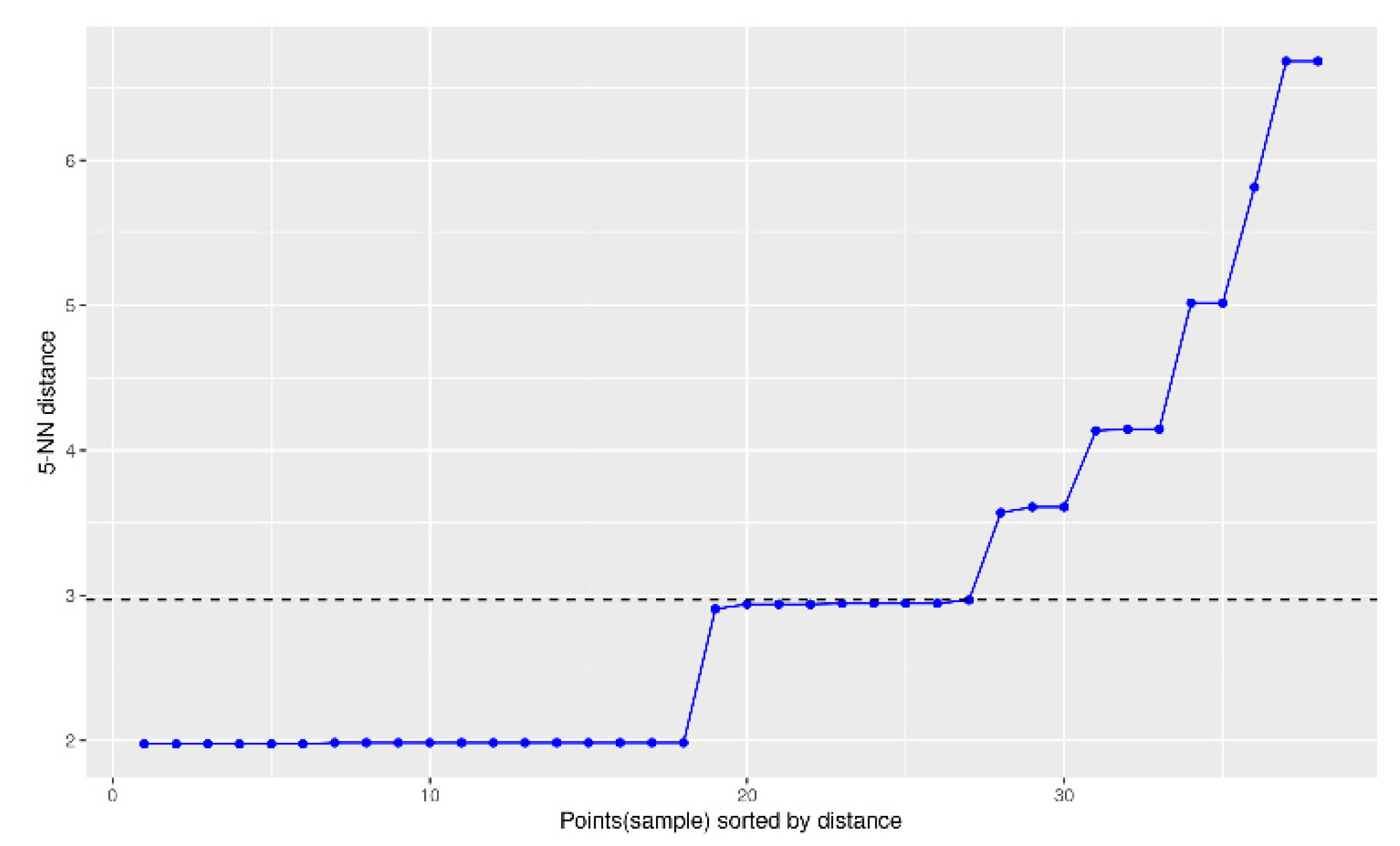
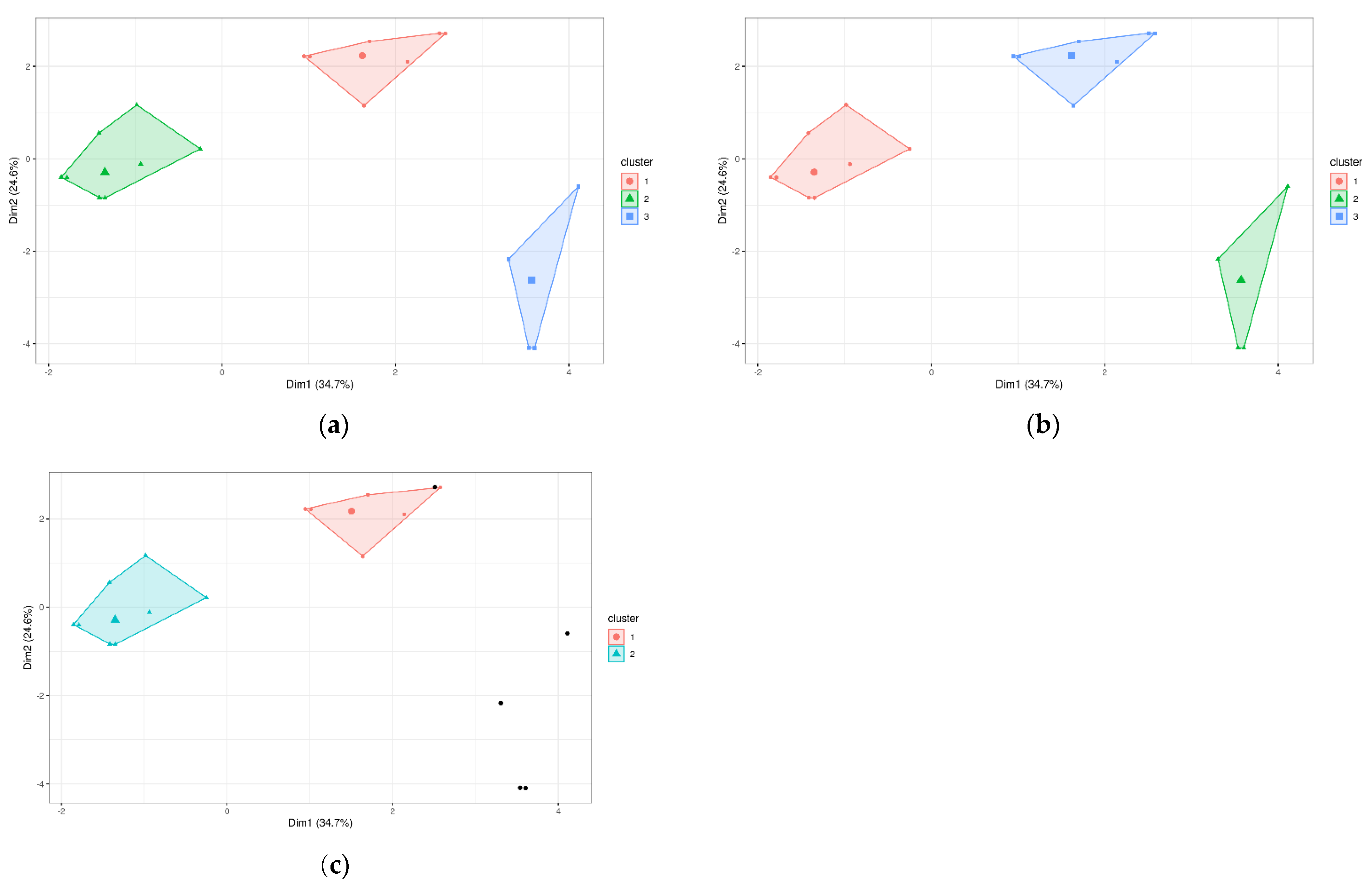
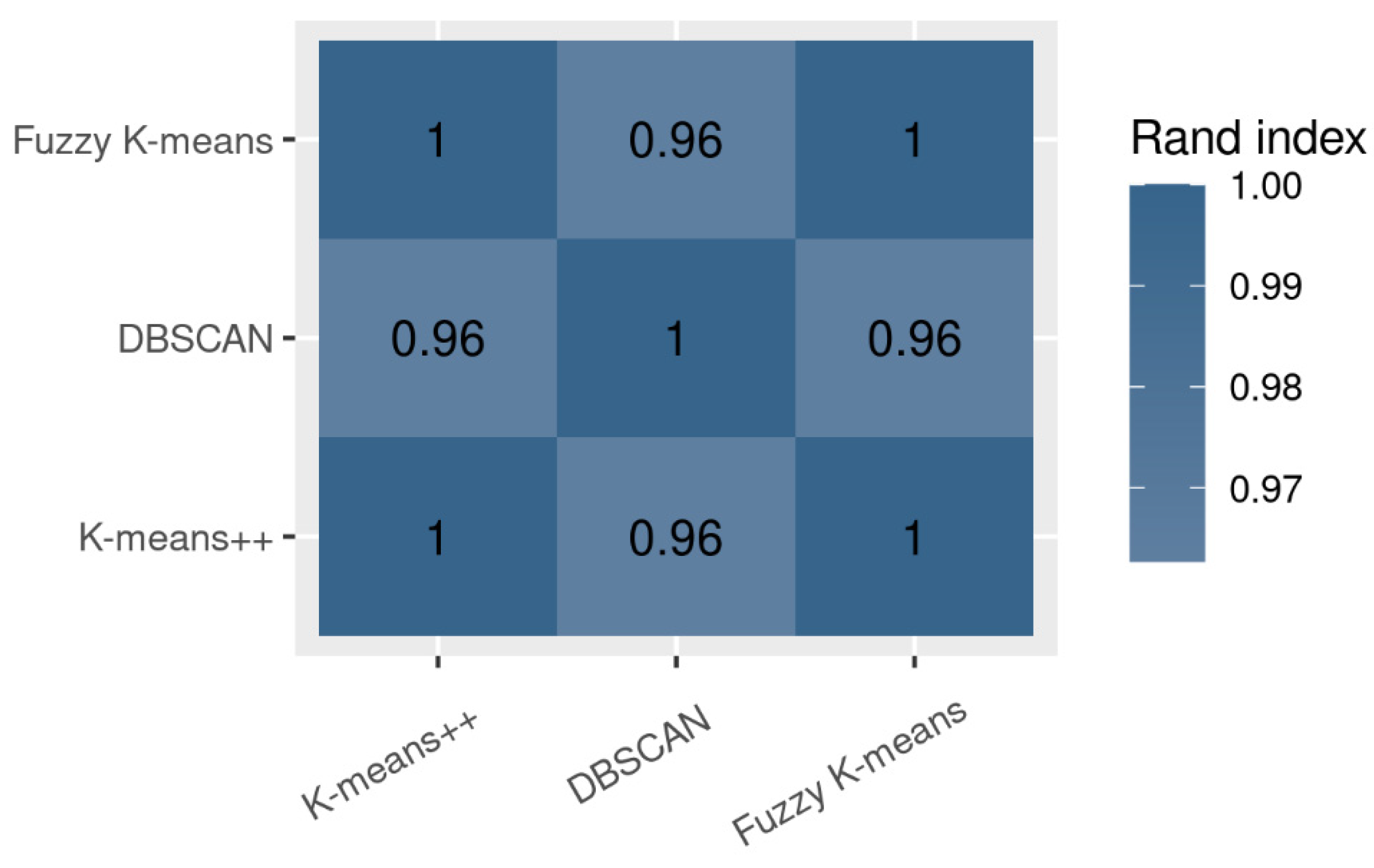
3.3. Study with Unsupervised Learning Machine Learning Techniques: Clustering
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Access | N | n | G1 | n | G2 | df | F | p | η2 |
|---|---|---|---|---|---|---|---|---|---|
| M (SD) | M (SD) | ||||||||
| Independent Variable (novel vs. expert) | |||||||||
| Fixation Count | 38 | 17 | 654.18 (138.56) | 21 | 625.19 (189.87) | 1,35 | 0.09 | 0.76 | 0.003 |
| Fixation Frequency Count | 38 | 17 | 3.01 (0.67) | 21 | 2.96 (0.91) | 1,35 | 0.09 | 0.76 | 0.003 |
| Fixation Duration Total | 38 | 17 | 166,132.18 (44,244.00) | 21 | 152,531.78 (48,472.19) | 1,35 | 0.49 | 0.49 | 0.01 |
| Fixation Duration Average | 38 | 17 | 255.93 (72.55) | 21 | 254.36 (88.36) | 1,35 | 0.004 | 0.95 | 0.000 |
| Fixation Duration Maximum | 38 | 17 | 1189.10 (484.92) | 21 | 1286.40 (623.33) | 1,35 | 0.42 | 0.52 | 0.01 |
| Fixation Duration Minimum | 38 | 17 | 83.21 (0.05) | 21 | 83.21 (0.04) | 1,35 | 0.03 | 0.86 | 0.001 |
| Fixation Dispersion Total | 38 | 17 | 47,498.23 (11,528.53) | 21 | 46,202.81 (15,068.91) | 1,35 | 0.01 | 0.93 | 0.000 |
| Fixation Dispersion Average | 38 | 17 | 72.50 (5.00) | 21 | 73.58 (5.00) | 1,35 | 0.42 | 0.52 | 0.01 |
| Fixation Dispersion Maximum | 38 | 17 | 99.98 (0.04) | 21 | 98.89 (0.39) | 1,35 | 0.79 | 0.38 | 0.02 |
| Fixation Dispersion Minimum | 38 | 17 | 11.54 (4.65) | 21 | 9.94 (5.01) | 1,35 | 0.85 | 0.36 | 0.02 |
| Saccade Count | 38 | 17 | 664.29 (136.78) | 21 | 632.24 (195.64) | 1,35 | 0.12 | 0.73 | 0.003 |
| Saccade Frequency Count | 38 | 17 | 3.15 (0.65) | 21 | 3.00 (0.93) | 1,35 | 0.12 | 0.73 | 0.003 |
| Saccade Duration Total | 38 | 17 | 32,282.09 (27,891.81) | 21 | 31,241.80 (21,906.09) | 1,35 | 0.03 | 0.86 | 0.001 |
| Saccade Duration Average | 38 | 17 | 59.47 (89.43) | 21 | 52.58 (44.21) | 1,35 | 0.23 | 0.63 | 0.02 |
| Saccade Duration Maximum | 38 | 17 | 629.38 (1332.76) | 21 | 467.00 (414.22) | 1,35 | 0.49 | 0.49 | 0.01 |
| Saccade Duration Minimum | 38 | 17 | 16.57 (0.05) | 21 | 16.49 (0.30) | 1,35 | 2.00 | 0.17 | 0.05 |
| Saccade Amplitude Total | 38 | 17 | 4825.23 (6815.38) | 21 | 4740.95 (4780.52) | 1,35 | 0.02 | 0.88 | 0.001 |
| Saccade Amplitude Average | 38 | 17 | 10.74 (25.55) | 21 | 8.69 (10.82) | 1,35 | 0.26 | 0.61 | 0.02 |
| Saccade Amplitude Maximum | 38 | 17 | 156.15 (300.65) | 21 | 119.67 (96.25) | 1,35 | 0.47 | 0.50 | 0.013 |
| Saccade Amplitude Minimum | 38 | 17 | 0.03 (0.05) | 21 | 0.05 (0.07) | 1,35 | 0.35 | 0.56 | 0.010 |
| Saccade Velocity Total | 38 | 17 | 61,828.35 (17,396.33) | 21 | 66,554.31 (26,550.69) | 1,35 | 0.50 | 0.49 | 0.014 |
| Saccade Velocity Average | 38 | 17 | 96.85 (36.43) | 21 | 113.01 (45.91) | 1,35 | 0.95 | 0.34 | 0.03 |
| Saccade Velocity Maximum | 38 | 17 | 878.00 (190.65) | 21 | 844.58 (173.95) | 1,35 | 0.25 | 0.62 | 0.01 |
| Saccade Velocity Minimum | 38 | 17 | 2.81 (1.43) | 21 | 3.62 (2.47) | 1,35 | 0.75 | 0.39 | 0.02 |
| Saccade Latency Average | 38 | 17 | 279.93 (64.36) | 21 | 295.73 (106.93) | 1,35 | 0.12 | 0.73 | 0.003 |
| Blink Count | 38 | 17 | 33.12 (25.59) | 21 | 45.00 (37.00) | 1,35 | 1.14 | 0.29 | 0.03 |
| Blink Frequency Count | 38 | 17 | 0.15 (0.12) | 21 | 0.21 (0.18) | 1,35 | 1.14 | 0.29 | 0.03 |
| Blink Duration Total | 38 | 17 | 6777.12 (9174.98) | 21 | 20,619.05 (41,403.88) | 1,35 | 1.36 | 0.25 | 0.04 |
| Blink Duration Average | 38 | 17 | 202.48 (244.52) | 21 | 545.61 (1352.20) | 1,35 | 0.77 | 0.39 | 0.02 |
| Blink Duration Maximum | 38 | 17 | 898.75 (2087.86) | 21 | 5951.36 (19,080.82) | 1,35 | 0.88 | 0.36 | 0.02 |
| Blink Duration Minimum | 38 | 17 | 85.19 (5.57) | 21 | 84.80 (5.05) | 1,35 | 0.07 | 0.79 | 0.002 |
| Scan Path Length | 38 | 17 | 122,506.94 (21157.24) | 21 | 117,620.71 (36,042.24) | 1,35 | 0.16 | 0.69 | 0.01 |
| Covariable (type of participant student vs. professor) | |||||||||
| Fixation Count | 38 | 17 | 21 | 1,35 | 1.61 | 0.21 | 0.04 | ||
| Fixation Frequency Count | 38 | 17 | 21 | 1,35 | 1.53 | 0.23 | 0.04 | ||
| Fixation Duration Total | 38 | 17 | 21 | 1,35 | 1.12 | 0.30 | 0.03 | ||
| Fixation Duration Average | 38 | 17 | 21 | 1,35 | 0.001 | 0.98 | 0.000 | ||
| Fixation Duration Maximum | 38 | 17 | 21 | 1,35 | 0.60 | 0.44 | 0.02 | ||
| Fixation Duration Minimum | 38 | 17 | 21 | 1,35 | 0.04 | 0.84 | 0.001 | ||
| Fixation Dispersion Total | 38 | 17 | 21 | 1,35 | 1.36 | 0.25 | 0.04 | ||
| Fixation Dispersion Average | 38 | 17 | 21 | 1,35 | 0.002 | 0.97 | 0.000 | ||
| Fixation Dispersion Maximum | 38 | 17 | 21 | 1,35 | 0.08 | 0.78 | 0.002 | ||
| Fixation Dispersion Minimum | 38 | 17 | 21 | 1,35 | 0.12 | 0.73 | 0.004 | ||
| Saccade Count | 38 | 17 | 21 | 1,35 | 1.73 | 0.20 | 0.047 | ||
| Saccade Frequency Count | 38 | 17 | 21 | 1,35 | 1.65 | 0.21 | 0.045 | ||
| Saccade Duration Total | 38 | 17 | 21 | 1,35 | 0.11 | 0.74 | 0.003 | ||
| Saccade Duration Average | 38 | 17 | 21 | 1,35 | 1.05 | 0.31 | 0.03 | ||
| Saccade Duration Maximum | 38 | 17 | 21 | 1,35 | 1.09 | 0.30 | 0.03 | ||
| Saccade Duration Minimum | 38 | 17 | 21 | 1,35 | 2.41 | 0.13 | 0.06 | ||
| Saccade Amplitude Total | 38 | 17 | 21 | 1,35 | 0.44 | 0.51 | 0.01 | ||
| Saccade Amplitude Average | 38 | 17 | 21 | 1,35 | 1.18 | 0.28 | 0.03 | ||
| Saccade Amplitude Maximum | 38 | 17 | 21 | 1,35 | 1.01 | 0.32 | 0.03 | ||
| Saccade Amplitude Minimum | 38 | 17 | 21 | 1,35 | 5.19 | 0.03 * | 0.13 | ||
| Saccade Velocity Total | 38 | 17 | 21 | 1,35 | 0.28 | 0.60 | 0.01 | ||
| Saccade Velocity Average | 38 | 17 | 21 | 1,35 | 1.27 | 0.27 | 0.04 | ||
| Saccade Velocity Maximum | 38 | 17 | 21 | 1,35 | 0.08 | 0.77 | 0.002 | ||
| Saccade Velocity Minimum | 38 | 17 | 21 | 1,35 | 5.18 | 0.03 * | 0.13 | ||
| Saccade Latency Average | 38 | 17 | 21 | 1,35 | 1.19 | 0.28 | 0.03 | ||
| Blink Count | 38 | 17 | 21 | 1,35 | 0.02 | 0.81 | 0.001 | ||
| Blink Frequency Count | 38 | 17 | 21 | 1,35 | 0.000 | 0.98 | 0.000 | ||
| Blink Duration Total | 38 | 17 | 21 | 1,35 | 0.93 | 0.34 | 0.03 | ||
| Blink Duration Average | 38 | 17 | 21 | 1,35 | 0.58 | 0.45 | 0.02 | ||
| Blink Duration Maximum | 38 | 17 | 21 | 1,35 | 0.53 | 0.47 | 0.02 | ||
| Blink Duration Minimum | 38 | 17 | 21 | 1,35 | 0.09 | 0.77 | 0.003 | ||
| Scan Path Length | 38 | 17 | 21 | 1,35 | 0.21 | 0.65 | 0.01 |
| Type of Access | N | n | G1 | n | G2 | df | F | p | η2 |
|---|---|---|---|---|---|---|---|---|---|
| M (SD) | M (SD) | ||||||||
| Independent Variable (novel vs. expert) | |||||||||
| Fixation Count | 38 | 25 | 628.92 (183.40) | 13 | 655.92 (136.21) | 1,35 | 0.55 | 0.46 | 0.02 |
| Fixation Frequency Count | 38 | 25 | 2.98 (0.88) | 13 | 3.10 (0.65) | 1,35 | 0.51 | 0.48 | 0.01 |
| Fixation Duration Total | 38 | 25 | 152,469.04 (54,256.14) | 13 | 170,437.56 (23,520.29) | 1,35 | 1.98 | 0.17 | 0.05 |
| Fixation Duration Average | 38 | 25 | 243.64 (69.26) | 13 | 277.03 (98.19) | 1,35 | 1.49 | 0.23 | 0.04 |
| Fixation Duration Maximum | 38 | 25 | 1184.55 (512.27) | 13 | 1355.00 (650.35) | 1,35 | 1.06 | 0.31 | 0.03 |
| Fixation Duration Minimum | 38 | 25 | 83.22 (0.06) | 13 | 83.20 (0.00) | 1,35 | 1.16 | 0.29 | 0.03 |
| Fixation Dispersion Total | 38 | 25 | 46,170.27 (14,279.23) | 13 | 47,959.40 (12,120.32) | 1,35 | 0.39 | 0.54 | 0.01 |
| Fixation Dispersion Average | 38 | 25 | 73.19 (4.65) | 13 | 72.89 (5.72) | 1,35 | 0.04 | 0.84 | 0.001 |
| Fixation Dispersion Maximum | 38 | 25 | 99.90 (0.36) | 13 | 99.99 (0.03) | 1,35 | 1.03 | 0.32 | 0.03 |
| Fixation Dispersion Minimum | 38 | 25 | 11.02 (4.59) | 13 | 9.95 (5.44) | 1,35 | 0.30 | 0.59 | 0.01 |
| Saccade Count | 38 | 25 | 638.44 (186.76) | 13 | 662.23 (139.21) | 1,35 | 0.47 | 0.50 | 0.01 |
| Saccade Frequency Count | 38 | 25 | 3.03 (0.89) | 13 | 3.12 (0.67) | 1,35 | 0.36 | 0.55 | 0.01 |
| Saccade Duration Total | 38 | 25 | 35,070.90 (28,103.57) | 13 | 25,238.52 (13,761.84) | 1,35 | 1.57 | 0.22 | 0.04 |
| Saccade Duration Average | 38 | 25 | 65.17 (81.24) | 13 | 37.38 (14.49) | 1,35 | 2.06 | 0.16 | 0.06 |
| Saccade Duration Maximum | 38 | 25 | 633.59 (1130.76) | 13 | 358.96 (252.82) | 1,35 | 1.12 | 0.30 | 0.03 |
| Saccade Duration Minimum | 38 | 25 | 16.52 (0.26) | 13 | 16.52 (0.16) | 1,35 | 0.07 | 0.80 | 0.002 |
| Saccade Amplitude Total | 38 | 25 | 5679.51 (6777.34) | 13 | 3046.24 (1794.51) | 1,35 | 2.31 | 0.14 | 0.06 |
| Saccade Amplitude Average | 38 | 25 | 12.20 (22.60) | 13 | 4.62 (2.49) | 1,35 | 2.05 | 0.16 | 0.06 |
| Saccade Amplitude Maximum | 38 | 25 | 161.21 (254.94) | 13 | 87.50 (56.00) | 1,35 | 1.49 | 0.23 | 0.04 |
| Saccade Amplitude Minimum | 38 | 25 | 0.04 (0.07) | 13 | 0.03 (0.05) | 1,35 | 1.39 | 0.25 | 0.04 |
| Saccade Velocity Total | 38 | 25 | 66,146.90 (24,164.73) | 13 | 61,157.70 (20,255.49) | 1,35 | 0.31 | 0.58 | 0.01 |
| Saccade Velocity Average | 38 | 25 | 112.39 (47.64) | 13 | 93.07 (26.12) | 1,35 | 2.78 | 0.10 | 0.074 |
| Saccade Velocity Maximum | 38 | 25 | 882.20 (193.02) | 13 | 815.95 (148.76) | 1,35 | 1.02 | 0.32 | 0.03 |
| Saccade Velocity Minimum | 38 | 25 | 3.50 (2.41) | 13 | 2.79 (1.20) | 1,35 | 2.49 | 0.12 | 0.07 |
| Saccade Latency Average | 38 | 25 | 282.75 (76.56) | 13 | 300.02 (113.31) | 1,35 | 0.12 | 0.73 | 0.003 |
| Blink Count | 38 | 25 | 39.24 (29.03) | 13 | 40.54 (39.73) | 1,35 | 0.003 | 0.96 | 0.000 |
| Blink Frequency Count | 38 | 25 | 0.18 (0.14) | 13 | 0.18 (0.20) | 1,35 | 0.000 | 0.98 | 0.000 |
| Blink Duration Total | 38 | 25 | 15,683.28 (38,413.22) | 13 | 12,009.94 (12,594.05) | 1,35 | 0.32 | 0.58 | 0.01 |
| Blink Duration Average | 38 | 25 | 418.80 (1251.58) | 13 | 340.78 (286.44) | 1,35 | 0.16 | 0.69 | 0.01 |
| Blink Duration Maximum | 38 | 25 | 4263.06 (17603.20) | 13 | 2590.82 (3294.93) | 1,35 | 0.27 | 0.61 | 0.01 |
| Blink Duration Minimum | 38 | 25 | 85.22 (5.57) | 13 | 84.51 (4.66) | 1,35 | 0.20 | 0.66 | 0.01 |
| Scan Path Length | 38 | 25 | 122,693.40 (31,212.68) | 13 | 114,255.23 (27,953.39) | 1,35 | 0.52 | 0.48 | 0.02 |
| Covariable (type of participant student vs. professor) | |||||||||
| Fixation Count | 38 | 25 | 13 | 1,35 | 2.14 | 0.15 | 0.06 | ||
| Fixation Frequency Count | 38 | 25 | 13 | 1,35 | 2.03 | 0.16 | 0.06 | ||
| Fixation Duration Total | 38 | 25 | 13 | 1,35 | 2.13 | 0.15 | 0.06 | ||
| Fixation Duration Average | 38 | 25 | 13 | 1,35 | 0.04 | 0.84 | 0.001 | ||
| Fixation Duration Maximum | 38 | 25 | 13 | 1,35 | 0.74 | 0.40 | 0.02 | ||
| Fixation Duration Minimum | 38 | 25 | 13 | 1,35 | 0.14 | 0.71 | 0.004 | ||
| Fixation Dispersion Total | 38 | 25 | 13 | 1,35 | 1.69 | 0.20 | 0.05 | ||
| Fixation Dispersion Average | 38 | 25 | 13 | 1,35 | 0.04 | 0.85 | 0.001 | ||
| Fixation Dispersion Maximum | 38 | 25 | 13 | 1,35 | 0.39 | 0.54 | 0.01 | ||
| Fixation Dispersion Minimum | 38 | 25 | 13 | 1,35 | 0.16 | 0.69 | 0.01 | ||
| Saccade Count | 38 | 25 | 13 | 1,35 | 2.27 | 0.14 | 0.06 | ||
| Saccade Frequency Count | 38 | 25 | 13 | 1,35 | 2.12 | 0.15 | 0.06 | ||
| Saccade Duration Total | 38 | 25 | 13 | 1,35 | 0.29 | 0.59 | 0.01 | ||
| Saccade Duration Average | 38 | 25 | 13 | 1,35 | 1.53 | 0.23 | 0.04 | ||
| Saccade Duration Maximum | 38 | 25 | 13 | 1,35 | 1.28 | 0.27 | 0.04 | ||
| Saccade Duration Minimum | 38 | 25 | 13 | 1,35 | 1.75 | 0.20 | 0.05 | ||
| Saccade Amplitude Total | 38 | 25 | 13 | 1,35 | 0.89 | 0.35 | 0.03 | ||
| Saccade Amplitude Average | 38 | 25 | 13 | 1,35 | 1.67 | 0.21 | 0.05 | ||
| Saccade Amplitude Maximum | 38 | 25 | 13 | 1,35 | 1.27 | 0.27 | 0.04 | ||
| Saccade Amplitude Minimum | 38 | 25 | 13 | 1,35 | 6.90 | 0.01 * | 0.16 | ||
| Saccade Velocity Total | 38 | 25 | 13 | 1,35 | 0.09 | 0.77 | 0.003 | ||
| Saccade Velocity Average | 38 | 25 | 13 | 1,35 | 2.67 | 0.11 | 0.07 | ||
| Saccade Velocity Maximum | 38 | 25 | 13 | 1,35 | 0.04 | 0.85 | 0.001 | ||
| Saccade Velocity Minimum | 38 | 25 | 13 | 1,35 | 7.67 | 0.01 * | 0.18 | ||
| Saccade Latency Average | 38 | 25 | 13 | 1,35 | 1.17 | 0.29 | 0.032 | ||
| Blink Count | 38 | 25 | 13 | 1,35 | 0.10 | 0.75 | 0.003 | ||
| Blink Frequency Count | 38 | 25 | 13 | 1,35 | 0.03 | 0.87 | 0.001 | ||
| Blink Duration Total | 38 | 25 | 13 | 1,35 | 1.55 | 0.22 | 0.04 | ||
| Blink Duration Average | 38 | 25 | 13 | 1,35 | 0.95 | 0.34 | 0.03 | ||
| Blink Duration Maximum | 38 | 25 | 13 | 1,35 | 0.95 | 0.34 | 0.03 | ||
| Blink Duration Minimum | 38 | 25 | 13 | 1,35 | 0.12 | 0.74 | 0.003 | ||
| Scan Path Length | 38 | 25 | 13 | 1,35 | 0.15 | 0.70 | 0.004 |
References
- van Marlen, T.; van Wermeskerken, M.; Jarodzka, H.; van Gog, T. Effectiveness of eye movement modeling examples in problem solving: The role of verbal ambiguity and prior knowledge. Learn. Instr. 2018, 58, 274–283. [Google Scholar] [CrossRef]
- Eberhard, K.M.; Tanenhaus, M.K.; Sciences, C.; Sedivy, J.C.; Sciences, C.; Hall, M. Eye movements as a window into real-time spoken language comprehension in natural contexts. J. Psycholinguist. Res. 1995, 24, 409–436. [Google Scholar] [CrossRef]
- Bruder, C.; Hasse, C. Differences between experts and novices in the monitoring of automated systems. Int. J. Ind. Ergon. 2019, 72, 1–11. [Google Scholar] [CrossRef]
- Takacs, Z.K.; Bus, A.G. How pictures in picture storybooks support young children’s story comprehension: An eye-tracking experiment. J. Exp. Child. Psychol. 2018, 174, 1–12. [Google Scholar] [CrossRef]
- Verhallen, M.J.A.J.; Bus, A.G. Young second language learners’ visual attention to illustrations in storybooks. J. Early Child. Lit. 2011, 11, 480–500. [Google Scholar] [CrossRef]
- Ooms, K.; de Maeyer, P.; Fack, V.; van Assche, E.; Witlox, F. Interpreting maps through the eyes of expert and novice users. Int. J. Geogr. Inf. Sci. 2012, 26, 1773–1788. [Google Scholar] [CrossRef]
- Hilton, C.; Miellet, S.; Slattery, T.J.; Wiener, J. Are age-related deficits in route learning related to control of visual attention? Psychol. Res. 2020, 84, 1473–1484. [Google Scholar] [CrossRef] [Green Version]
- Sáiz Manzanares, M.C.; Rodríguez-Díez, J.J.; Marticorena-Sánchez, R.; Zaparaín-Yáñez, M.J.; Cerezo-Menéndez, R. Lifelong learning from sustainable education: An analysis with eye tracking and data mining techniques. Sustainability 2020, 12, 1970. [Google Scholar] [CrossRef] [Green Version]
- Kitchenham, B.A.; Dybå, T.; Jørgensen, M. Evidence-based software engineering. In Proceedings of the 26th International Conference on Software Engineering, Edinburgh, UK, 28 May 2004; pp. 273–281. [Google Scholar] [CrossRef]
- Joe, L.P.I.; Sasirekha, S.; Uma Maheswari, S.; Ajith, K.A.M.; Arjun, S.M.; Athesh, K.S. Eye Gaze Tracking-Based Adaptive E-learning for Enhancing Teaching and Learning in Virtual Classrooms. In Information and Communication Technology for Competitive Strategies; Fong, S., Akashe, S., Mahalle, P.N., Eds.; Springer: Singapore, 2019; pp. 165–176. [Google Scholar] [CrossRef]
- Rayner, K. Eye Movements in Reading and Information Processing: 20 Years of Research. Psychol. Bull. 1998, 124, 372–422. [Google Scholar] [CrossRef]
- Taub, M.; Azevedo, R.; Bradbury, A.E.; Millar, G.C.; Lester, J. Using sequence mining to reveal the efficiency in scientific reasoning during STEM learning with a game-based learning environment. Learn. Instr. 2018, 54, 93–103. [Google Scholar] [CrossRef]
- Taub, M.; Azevedo, R. Using Sequence Mining to Analyze Metacognitive Monitoring and Scientific Inquiry Based on Levels of Efficiency and Emotions during Game-Based Learning. JEDM 2018, 10, 1–26. [Google Scholar] [CrossRef]
- Cloude, E.B.; Taub, M.; Lester, J.; Azevedo, R. The Role of Achievement Goal Orientation on Metacognitive Process Use in Game-Based Learning. In Artificial Intelligence in Education; Isotani, S., Millán, E., Ogan, A., Hastings, P., McLaren, B., Luckin, R., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 36–40. [Google Scholar] [CrossRef]
- Azevedo, R.; Gašević, D. Analyzing Multimodal Multichannel Data about Self-Regulated Learning with Advanced Learning Technologies: Issues and Challenges. Comput. Hum. Behav. 2019, 96, 207–210. [Google Scholar] [CrossRef]
- Liu, H.-C.; Chuang, H.-H. An examination of cognitive processing of multimedia information based on viewers’ eye movements. Interact. Learn. Environ. 2011, 19, 503–517. [Google Scholar] [CrossRef]
- Privitera, C.M.; Stark, L.W. Algorithms for defining visual regions-of-lnterest: Comparison with eye fixations. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 970–982. [Google Scholar] [CrossRef] [Green Version]
- Sharafi, Z.; Soh, Z.; Guéhéneuc, Y.G. A systematic literature review on the usage of eye-tracking in software engineering. Inf. Softw. Technol. 2015, 67, 79–107. [Google Scholar] [CrossRef]
- Sharafi, Z.; Shaffer, T.; Sharif, B.; Guéhéneuc, Y.G. Eye-tracking metrics in software engineering. In Proceedings of the 015 Asia-Pacific Software Engineering Conference (APSEC), New Delhi, India, 1–4 December 2015; pp. 96–103. [Google Scholar] [CrossRef]
- Maltz, M.; Shina, D. Eye movements of younger and older drivers. Hum. Factors 1999, 41, 15–25. [Google Scholar] [CrossRef] [Green Version]
- Dalrymple, K.A.; Jiang, M.; Zhao, Q.; Elison, J.T. Machine learning accurately classifies age of toddlers based on eye tracking. Sci. Rep. 2019, 9, 6255. [Google Scholar] [CrossRef]
- Shen, J.; Elahipanah, A.; Reingold, E.M. Effects of context and instruction on the guidance of eye movements during a conjunctive visual search task. Eye Mov. 2007, 597–615. [Google Scholar] [CrossRef]
- Alemdag, E.; Cagiltay, K. A systematic review of eye tracking research on multimedia learning. Comput. Educ. 2018, 125, 413–428. [Google Scholar] [CrossRef]
- Scherer, R.; Siddiq, F.; Tondeur, J. The technology acceptance model (TAM): A meta-analytic structural equation modeling approach to explaining teachers’ adoption of digital technology in education. Comput. Educ. 2019, 128, 13–35. [Google Scholar] [CrossRef]
- Stull, A.T.; Fiorella, L.; Mayer, R.E. An eye-tracking analysis of instructor presence in video lectures. Comput. Hum. Behav. 2018, 88, 263–272. [Google Scholar] [CrossRef]
- Burch, M.; Kull, A.; Weiskopf, D. AOI rivers for visualizing dynamic eye gaze frequencies. Comput. Graph. Forum 2013, 32, 281–290. [Google Scholar] [CrossRef]
- Dzeng, R.-J.; Lin, C.-T.; Fang, Y.-C. Using eye-tracker to compare search patterns between experienced and novice workers for site hazard identification. Saf. Sci. 2016, 82, 56–67. [Google Scholar] [CrossRef]
- Klaib, A.F.; Alsrehin, N.O.; Melhem, W.Y.; Bashtawi, H.O.; Magableh, A.A. Eye tracking algorithms, techniques, tools, and applications with an emphasis on machine learning and Internet of Things technologies. Expert Syst. Appl. 2021, 166, 114037. [Google Scholar] [CrossRef]
- König, S.D.; Buffalo, E.A. A nonparametric method for detecting fixations and saccades using cluster analysis: Removing the need for arbitrary thresholds. J. Neurosci. Methods 2014, 227, 121–131. [Google Scholar] [CrossRef] [Green Version]
- Romero, C.; Ventura, S. Educational data mining: A survey from 1995 to 2005. Expert Syst. Appl. 2007, 33, 135–146. [Google Scholar] [CrossRef]
- Bogarín, A.; Cerezo, R.; Romero, C. A survey on educational process mining. WIREs Data Min. Knowl. Discov. 2018, 8, e1230. [Google Scholar] [CrossRef] [Green Version]
- González, Á.; Díez-Pastor, J.F.; García-Osorio, C.I.; Rodríguez-Díez, J.J. Herramienta de apoyo a la docencia de algoritmos de selección de instancias. In Proceedings of the Jornadas Enseñanza la Informática, Ciudad Real, Spain, 10–13 July 2012; pp. 33–40. [Google Scholar]
- Arnaiz-González, Á.; Díez-Pastor, J.F.; Rodríguez, J.J.; García-Osorio, C.I. Instance selection for regression by discretization. Expert Syst. Appl. 2016, 54, 340–350. [Google Scholar] [CrossRef]
- Campbell, D.F. Diseños Experimentales y Cuasiexperimentales en la Investigación Social [Experimental and Qusai-Experimental Designs for Research], 9th ed.; Amorrortu: Buenos Aires, Argentina, 2005. [Google Scholar]
- Cerezo, R.; Fernández, E.; Gómez, C.; Sánchez-Santillán, M.; Taub, M.; Azevedo, R. Multimodal Protocol for Assessing Metacognition and Self-Regulation in Adults with Learning Difficulties. JoVE 2020, 163, e60331. [Google Scholar] [CrossRef]
- Mudrick, N.V.; Azevedo, R.; Taub, M. Integrating metacognitive judgments and eye movements using sequential pattern mining to understand processes underlying multimedia learning. Comput. Hum. Behav. 2019, 96, 223–234. [Google Scholar] [CrossRef]
- Munoz, D.P.; Armstrong, I.; Coe, B. Using eye movements to probe development and dysfunction. In Eye Movements: A Window on Mind and Brain; van Gompel, R.P.G., Fischer, M.H., Murray, W.S., Hill, R.L., Eds.; Elsevier: Amsterdam, The Netherlands, 2007; pp. 99–124. [Google Scholar] [CrossRef]
- Sulikowski, P.; Zdziebko, T. Deep Learning-Enhanced Framework for Performance Evaluation of a Recommending Interface with Varied Recommendation Position and Intensity Based on Eye-Tracking Equipment Data Processing. Electronics 2020, 9, 266. [Google Scholar] [CrossRef] [Green Version]
- Moghaddasi, M.; Marín-Morales, J.; Khatri, J.; Guixeres, J.; Chicchi, G.I.A.; Alcañiz, M. Recognition of Customers’ Impulsivity from Behavioral Patterns in Virtual Reality. Appl. Sci. 2021, 11, 4399. [Google Scholar] [CrossRef]
- Qin, L.; Cao, Q.-L.; Leon, A.S.; Weng, Y.-N.; Shi, X.-H. Use of Pupil Area and Fixation Maps to Evaluate Visual Behavior of Drivers inside Tunnels at Different Luminance Levels—A Pilot Study. Appl. Sci. 2021, 11, 5014. [Google Scholar] [CrossRef]
- Giraldo-Romero, Y.-I.; Pérez-de-los-Cobos-Agüero, C.; Muñoz-Leiva, F.; Higueras-Castillo, E.; Liébana-Cabanillas, F. Influence of Regulatory Fit Theory on Persuasion from Google Ads: An Eye Tracking Study. J. Theor. Appl. Electron. Commer. Res. 2021, 16, 1165–1185. [Google Scholar] [CrossRef]
- Sulikowski, P. Evaluation of Varying Visual Intensity and Position of a Recommendation in a Recommending Interface Towards Reducing Habituation and Improving Sales. In Advances in E-Business Engineering for Ubiquitous Computing, ICEBE 2019, Proceedings of the International Conference on e-Business Engineering Advances in E-Business Engineering for Ubiquitous Computing, Shanghai, China, 12–13 October 2019; Chao, K.M., Jiang, L., Hussain, O., Ma, S.P., Fei, X., Eds.; Springer: Cham, Switzerland, 2019; pp. 208–218. [Google Scholar] [CrossRef]
- Sulikowski, P.; Zdziebko, T.; Coussement, K.; Dyczkowski, K.; Kluza, K.; Sachpazidu-Wójcicka, K. Gaze and Event Tracking for Evaluation of Recommendation-Driven Purchase. Sensors 2021, 21, 1381. [Google Scholar] [CrossRef]
- Bortko, K.; Piotr, B.; Jarosław, J.; Damian, K.; Piotr, S. Multi-Criteria Evaluation of Recommending Interfaces towards Habituation Reduction and Limited Negative Impact on User Experience. Procedia Comput. Sci. 2019, 159, 2240–2248. [Google Scholar] [CrossRef]
- Lee, T.L.; Yeung, M.K. Computerized Eye-Tracking Training Improves the Saccadic Eye Movements of Children with Attention-Deficit/Hyperactivity Disorder. Brain Sci. 2020, 10, 1016. [Google Scholar] [CrossRef]
- Peysakhovich, V.; Lefrançois, O.; Dehais, F.; Causse, M. The Neuroergonomics of Aircraft Cockpits: The Four Stages of Eye-Tracking Integration to Enhance Flight Safety. Safety 2018, 4, 8. [Google Scholar] [CrossRef] [Green Version]
- Bissoli, A.; Lavino-Junior, D.; Sime, M.; Encarnação, L.; Bastos-Filho, T. A Human–Machine Interface Based on Eye Tracking for Controlling and Monitoring a Smart Home Using the Internet of Things. Sensors 2019, 19, 859. [Google Scholar] [CrossRef] [Green Version]
- Brousseau, B.; Rose, J.; Eizenman, M. Hybrid Eye-Tracking on a Smartphone with CNN Feature Extraction and an Infrared 3D Model. Sensors 2020, 20, 543. [Google Scholar] [CrossRef] [Green Version]
- Vortman, L.; Schwenke, L.; Putze, F. Using Brain Activity Patterns to Differentiate Real and Virtual Attended Targets during Augmented Reality Scenarios. Information 2021, 12, 226. [Google Scholar] [CrossRef]
- Kapp, S.; Barz, M.; Mukhametov, S.; Sonntag, D.; Kuhn, J. ARETT: Augmented Reality Eye Tracking Toolkit for Head Mounted Displays. Sensors 2021, 21, 2234. [Google Scholar] [CrossRef]
- Wirth, M.; Kohl, S.; Gradl, S.; Farlock, R.; Roth, D.; Eskofier, B.M. Assessing Visual Exploratory Activity of Athletes in Virtual Reality Using Head Motion Characteristics. Sensors 2021, 21, 3728. [Google Scholar] [CrossRef] [PubMed]
- Scalera, L.; Seriani, S.; Gallina, P.; Lentini, M.; Gasparetto, A. Human–Robot Interaction through Eye Tracking for Artistic Drawing. Robotics 2021, 10, 54. [Google Scholar] [CrossRef]
- Maimon-Dror, R.O.; Fernandez-Quesada, J.; Zito, G.A.; Konnaris, C.; Dziemian, S.; Faisal, A.A. Towards free 3D end-point control for robotic-assisted human reaching using binocular eye tracking. In Proceedings of the IEEE International Conference on Rehabilitation Robotics, London, UK, 17–20 July 2017; pp. 1049–1054. [Google Scholar] [CrossRef]
- Antoniou, E.; Bozios, P.; Christou, V.; Tzimourta, K.D.; Kalafatakis, K.; Tsipouras, M.G.; Giannakeas, N.; Tzallas, A.T. EEG-Based Eye Movement Recognition Using Brain–Computer Interface and Random Forests. Sensors 2021, 21, 2339. [Google Scholar] [CrossRef] [PubMed]
- IBM Corp. SPSS Statistical Package for the Social Sciences (SPSS); Version 24; IBM: Madrid, Spain, 2016. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical; Version 4.1.0; R Foundation for Statistical Computing: Vienna, Austria, 2021; Available online: http://www.R-project.org/ (accessed on 6 June 2021).
- Hall, M.; Smith, L.A. Practical feature subset selection for machine learning. Comput. Sci. 1998, 98, 181–191. [Google Scholar]
- Harris, E. Information Gain versus Gain Ratio: A Study of Split Method Biases. 2001, pp. 1–20. Available online: https://www.mitre.org/sites/default/files/pdf/harris_biases.pdf (accessed on 15 May 2021).
- Cramér, H. Mathematical Methods of Statistics (PMS-9); Princeton University Press: Princeton, NJ, USA, 2016. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. K-means++: The advantages of careful seeding. In Proceedings of the SODA ‘07: Actas del Decimoctavo Simposio Anual ACM-SIAM Sobre Algoritmos Discretos, Philadelphia, PA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Bezdek, J.C.; Dunn, J.C. Optimal Fuzzy Partitions: A Heuristic for Estimating the Parameters in a Mixture of Normal Distributions. IEEE Trans. Comput. 1975, 24, 835–838. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy Sets and Information Granularity. Fuzzy Sets Fuzzy Logic. Fuzzy 1996, 433–448. [Google Scholar] [CrossRef] [Green Version]
- Daszykowski, M.; Walczak, B. Density-Based Clustering Methods. In Comprehensive Chemometrics, 2nd ed.; Brown, S., Tauler, R., Walczak, B., Eds.; Elsevier: Amsterdam, The Netherlands, 2020; Volume 2, pp. 635–654. [Google Scholar]
- Hahsler, M.; Piekenbrock, M.; Doran, D. dbscan: Fast Density-Based Clustering with R. J. Stat. Softw. 2019, 91, 1–30. [Google Scholar] [CrossRef] [Green Version]
- Hubert, L.; Arabie, P. Comparing partitions. J. Classif. 1985, 2, 193–218. [Google Scholar] [CrossRef]









| Metric | Acronym | Metric Meaning | Learning Implications |
|---|---|---|---|
| Fixation Count | FC | Counts the number of specific bindings on AOIs in all stimuli | A greater number and frequency of fixations on a stimulus may indicate that the learner has less knowledge about the task or difficulty in discriminating relevant vs. non-relevant information. These are measures of global search performance [22]. |
| Fixation Frequency Count | FFC | ||
| Fixation Duration | FD | Duration of fixation | It gives an indication of the degree of interest and reaction times of the learner. Longer duration is usually associated with deeper cognitive processing and greater effort. For more complicated texts, the user has a longer average fixation duration. Fixation duration provides information about the search process [22]. |
| Fixation Duration Average | AFD | Average duration of fixation | Longer fixations refer to the learner spending more time analysing and interpreting the information content within the different areas of interest (AOIs). The average duration is considered to be between 200 and 260 ms. |
| Fixation Duration Maximum | FDMa | Maximum duration of fixation | They refer to reaction times. |
| Fixation Duration Minimum | FDMi | Minimum duration of fixation | |
| Fixation Dispersion Total | FDT | Sum of all dispersions of fixations in X and Y | It refers to the perception of information in different components of the task. |
| Fixation Dispersion Average | FDA | Sum of all fixation dispersions in X and Y divided by the number of fixations in the test | It analyses the dispersions in each of the fixations in the different stimuli. |
| Saccades Count | SC | Total number of saccades in each of the stimuli | A greater number of saccades implies greater search strategies. The greater the breadth of the saccade, the lower the cognitive effort. It may also refer to problems in understanding information. |
| Saccade Frequency Count | SFC | Sum of all saccades | They refer to the frequency of use of saccades that are related to search strategies. |
| Saccade Duration Total | SDT | Sum of the duration of all saccades | |
| Saccades Duration Average | SDA | Average duration of saccades in each of the AOIs | It allows discriminating field-dependent vs. non-dependent trainees. |
| Saccade Duration Maximum | SDMa | Maximum saccade duration. | They refer to the perception of information in different components of the task. |
| Saccade Duration Minimum | SDMi | Minimum saccade duration. | |
| Saccade Amplitude Total | SAT | Sum of the amplitude of all saccades | Newcomers tend to have shorter saccades. |
| Saccade Amplitude Maximum | SAMa | Maximum of saccade amplitude | |
| Saccade Amplitude Minimum | SAMi | Minimum of the saccade amplitude | |
| Saccade Velocity Total | SVT | Sum of the velocity of all saccades | They are directly related to the speed of information processing in moving from one element to another within a stimulus. |
| Saccade Velocity Maximum | SVMa | Maximum value of the saccade velocity | |
| Saccade Velocity Minimum | SVMi | Minimum value of saccade speed | |
| Saccade Latency Average | SLA | It is equal to the time between the end of one saccade and the start of the next saccade | It is directly related to reaction times in information processing. The initial saccade latency provides detailed temporal information about the search process [22]. |
| Blink Count | BC | Number of flashes in the test | It is related to the speed of information processing. Novice learners report a higher frequency. |
| Blink Frequency Count | BFC | Number of blinks of all selected trials per second divided by number of selected trials | Blinks are related to information processing during exposure to a stimulus to generate the next action. Learners with faster information processing may have shorter blinks of shorter duration. However, this action may also occur when attention deficit problems are present. These results will have to be compared with those obtained in the other metrics in order to adjust the explanation of these results within the analysis of a learning pattern. |
| Blink Duration Total | BDT | Sum of the duration of all blinks of the selected trials divided by the number of trials selected | |
| Blink Duration Average | BDA | The sum of the duration of all blinks of all selected trials divided by the number of selected trials | |
| Blink Duration Maximum | BDMa | Longest duration of recorded blinks | |
| Blink Duration Minimum | BDMi | The shortest duration of recorded blinks | |
| Scan Path Length | SPL | It provides a pattern of learning behaviours for each user | The study of the behavioural patterns of learning will facilitate the teacher’s orientations in relation to the way of learning. The length of the scan path provides information about reaction times in tasks with no predetermined duration. |
| Participant Type | N | With Prior Knowledge (n = 17) | Without Prior Knowledge (n = 21) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| N | n | Men | n | Woman | N | n | Men | n | Woman | ||||||
| Mage | SDage | Mage | SDage | Mage | SDage | Mage | SDage | ||||||||
| Students | 14 | 9 | 5 | 49.00 | 23.40 | 4 | 45.25 | 23.47 | 5 | 4 | 30.25 | 7.93 | 1 | 22.00 | - |
| Teachers | 24 | 8 | 5 | 47.40 | 8.62 | 3 | 42.67 | 11.85 | 16 | 9 | 43.00 | 11.79 | 7 | 52.29 | 4.79 |
| Features | Gain Ratio | Symmetrical Uncertainty | Chi-Square |
|---|---|---|---|
| Previous Knowledge | 0.199 | 0.199 | 0.453 |
| Group Type | 0.238 | 0.171 | 0.421 |
| Employment Status | 0.238 | 0.171 | 0.421 |
| Gender | 0.108 | 0.067 | 0.372 |
| Level Degree | 0.100 | 0.082 | 0.263 |
| Knowledge Branch | 0.084 | 0.057 | 0.251 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sáiz-Manzanares, M.C.; Pérez, I.R.; Rodríguez, A.A.; Arribas, S.R.; Almeida, L.; Martin, C.F. Analysis of the Learning Process through Eye Tracking Technology and Feature Selection Techniques. Appl. Sci. 2021, 11, 6157. https://doi.org/10.3390/app11136157
Sáiz-Manzanares MC, Pérez IR, Rodríguez AA, Arribas SR, Almeida L, Martin CF. Analysis of the Learning Process through Eye Tracking Technology and Feature Selection Techniques. Applied Sciences. 2021; 11(13):6157. https://doi.org/10.3390/app11136157
Chicago/Turabian StyleSáiz-Manzanares, María Consuelo, Ismael Ramos Pérez, Adrián Arnaiz Rodríguez, Sandra Rodríguez Arribas, Leandro Almeida, and Caroline Françoise Martin. 2021. "Analysis of the Learning Process through Eye Tracking Technology and Feature Selection Techniques" Applied Sciences 11, no. 13: 6157. https://doi.org/10.3390/app11136157
APA StyleSáiz-Manzanares, M. C., Pérez, I. R., Rodríguez, A. A., Arribas, S. R., Almeida, L., & Martin, C. F. (2021). Analysis of the Learning Process through Eye Tracking Technology and Feature Selection Techniques. Applied Sciences, 11(13), 6157. https://doi.org/10.3390/app11136157