
Physical Side-Channel Attacks on Embedded Neural Networks: A Survey


Abstract
:1. Introduction
2. Background
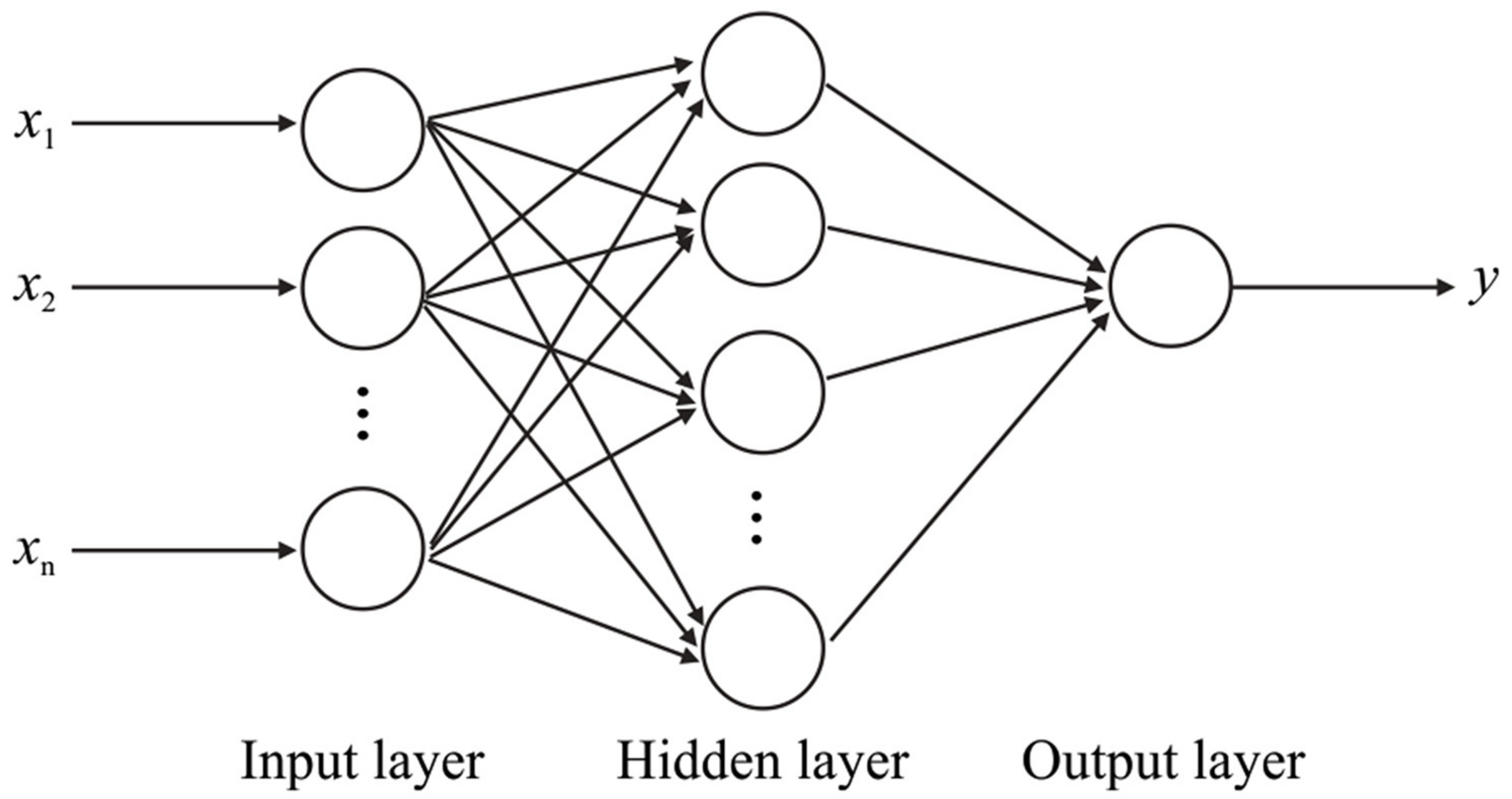
2.1. Some Background on Neural Networks (NN)
2.2. SCA Generalities
- Attacker capability: Two main attack families can be distinguished: passive and active. In the former one, the attacker is passive in the sense that he/she can only observe the information leaked and investigate changes in these leakages in order to correlate them to possible causes. For instance, a difference in the execution time (or power consumption) is a consequence of different computations or different processed data. By modeling the observed effects of possible specific causes, the adversary is able to learn useful information related to the actual computation on the target device. In the second family of attacks, the adversary is able to influence the target device via a side-channel, for instance, by modifying its environmental conditions [15]. Note that feeding the target with arbitrary inputs, for instance, by triggering the encryption of a specific text or in our case querying a DNN with any input image is, even for a potential attacker, a normal and authorised action and is not considered an active attack. In this study we focus on passive SCA attacks on DNN implementations.
- Information leaks: Following the work from Spreitzer et al. [15], information leaks can be categorised into two types. On the one hand, traditional leaks are the most studied and define the unintended information leakage inherent to hardware implementations on every system. These include execution and delay time, power consumption, EM emanation, heat, sound, etc. These leaks are considered unintentional as they naturally result from the computation on a hardware device without any intention of designers or developers on creating these side-channel sources. On the other hand, in addition to unintended information leakage, devices provide more features such as the ability of providing run-time and intended information of the system. For instance, information on embedded sensors (e.g., power consumption) is provided for the optimisation of the resources management. This results in publishing data on purpose, which can leak information and can be exploited in the same manner as unintended information leaks. The surveyed attacks exploit information leaked from unintended side-channel sources.
- Exploited properties: Attacks exploit different kinds of properties for their observations. We distinguish logical properties, such as memory access patterns, from physical ones including timing, sound, heat, etc. Specifically, the studied attacks have exploited physical properties such as power consumption and EM emanation. The nature of the exploited property may or may not condition the access required to perform the attack.
- Required access: First, the attacker can have local access to the system in software-only attacks, where only an adversary application co-located with the victim on the same hardware resources is required (e.g., attacks observing the access patterns/times on shared resources such as cache memories). Second, the attacker can be in physical proximity to the system in order to monitor power consumption or EM emissions (i.e., this is a hardware attack). A third category called remote attacks is distinguished. This latter defines hardware attacks performed from software, for instance, attacks observing power consumption from embedded sensors information accessed by software. Note that attacker access on the target system is irrespective to the exploited property. For instance, an adversary application co-located with the victim and sharing hardware resources can exploit timing physical properties by observing timing through changes on the state of the shared cache. In this work physical and remote access-based attacks are covered.
- Profiling phase: A profiling phase prior to the actual attack might be necessary for certain attacks. During this phase, the attacker characterises the device behaviour and side-channel information leakage in an ideal environment where the adversary has full control and knowledge of the victim. This includes the access to an exact copy of the system, full knowledge of the neural network implementation on the target device and full control of the inputs and access to the output. The adversary is therefore capable of extensively characterising the device according to the observed side-channel information in order to distinguish different profiles (also called templates. In the second phase, which corresponds to the actual attack, the adversary has limited knowledge and/or control on the victim (e.g., limited knowledge on the neural network implementation details or limited control on the inputs) and compares the observed side-channel information to the prior characterisation in order to determine the most probable profile. Attacks requiring a profiling phase are also known as template attacks.
2.3. SCA Techniques Covered in This Work
3. Threat Model and Attack Motivation
- (i)
- Reverse engineering. In the context of industrial DNNs, Intellectual Property (IP) models are a secret. A use-case for SCA in this context is an attacker who has a (legal) copy of a pre-trained network but does not have any details on the model architecture, parameters and, in general, training set (black-box). As the fine tuning of parameters, for instance weights, is of great importance in optimised networks accuracy and is currently one of the main challenges, commercial network details are kept confidential. Reverse engineering the network details would allow an attacker, who might be a competitor, to replicate the commercial IP resulting in substantial consequences including counterfeiting and economic losses. Two main objectives that will serve for evaluation are the following: (i) accuracy of the extracted information when compared to the victim network and (ii) task equivalence searching to obtain similar results than the victim model. These evaluation metrics are further discussed in Section 6. It has been proven that SCA enables the recovery of the network models architecture and parameters including activation functions, number of layers, neurons, output classes and weights. The standard assumption for this type of attacks is that an attacker has no knowledge on the network but can feed it with chosen inputs and has access to the outputs. Furthermore, in the scenario of commercial models, data being used to train the model are, in general, kept confidential as well. Indeed, in some cases, these data can be extremely sensitive, for instance, for models trained on medical patients data records.
- (ii)
- Data theft. Through SCA, inference input data (data to be classified) can be recovered by directly hampering data confidentiality and user’s privacy. In privacy-preserving applications such as medical image analysis, patients’ data privacy requires the utmost attention. In general, as the network architecture becomes more and more complex, deducing the input data by observation of outputs is not considered feasible. In the literature, SCA-based works assume partial or entire knowledge on the network architecture and parameters in order to be able to retrieve inference input data [19,20]. A possible use-case is an attacker who does not know nor control the inputs/outputs but knows the network as it is publicly available or as it has been previously reverse engineered such as in [21].
4. Physical SCA Attacks on DNNs
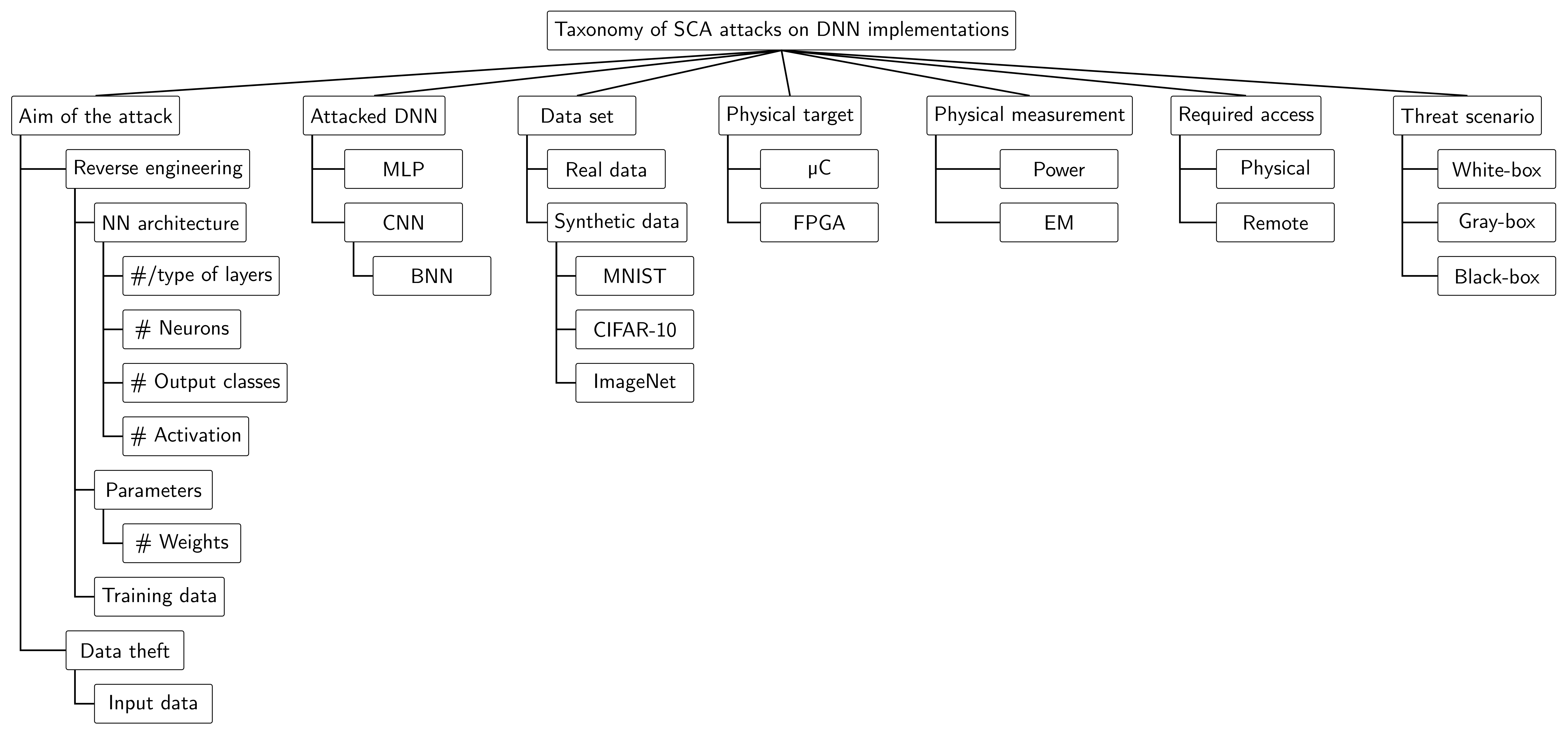
4.1. Taxonomy of SCA Attacks against DNN Implementations
4.2. Recovering Network Architecture and Parameters
4.2.1. Micro-Controller Targets
4.2.2. FPGA Targets
4.3. Recovering Input Data
4.3.1. Micro-Controller Targets
4.3.2. FPGA Targets
5. Current Countermeasures
6. Discussion and Future Research Leads
6.1. Challenges of Studied Attacks
6.2. Future Research Leads
6.3. Out of the Scope Attacks
7. Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mittal, S. A Survey of FPGA-Based Accelerators for Convolutional Neural Networks. Neural Comput. Appl. 2020, 32, 1109–1139. [Google Scholar] [CrossRef]
- Abdelouahab, K.; Pelcat, M.; Serot, J.; Berry, F. Accelerating CNN inference on FPGAs: A survey. arXiv 2018, arXiv:1806.01683. [Google Scholar]
- Chen, Y.H.; Emer, J.; Sze, V. Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks. ACM SIGARCH Comput. Archit. News 2016, 44, 367–379. [Google Scholar] [CrossRef]
- Abdelouahab, K.; Pelcat, M.; Serot, J.; Bourrasset, C.; Berry, F. Tactics to Directly Map CNN Graphs on Embedded FPGAs. IEEE Embed. Syst. Lett. 2017, 9, 113–116. [Google Scholar] [CrossRef] [Green Version]
- QaisarAhmadAlBadawi, A.; Chao, J.; Lin, J.; Mun, C.F.; Jie, S.J.; Tan, B.H.M.; Nan, X.; Khin, A.M.M.; Chandrasekhar, V. Towards the AlexNet Moment for Homomorphic Encryption: HCNN, the First Homomorphic CNN on Encrypted Data with GPUs. IEEE Trans. Emerg. Top. Comput. 2020. [Google Scholar] [CrossRef]
- Bourse, F.; Minelli, M.; Minihold, M.; Paillier, P. Fast Homomorphic Evaluation of Deep Discretized Neural Networks. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 19–23 August 2018; pp. 483–512. [Google Scholar]
- Hesamifard, E.; Takabi, H.; Ghasemi, M. CryptoDL: Deep Neural Networks over Encrypted Data. arXiv 2017, arXiv:1711.05189. [Google Scholar]
- Chillotti, I.; Joye, M.; Paillier, P. New Challenges for Fully Homomorphic Encryption. Privacy-Preserving Machine Learning (PPML-PriML 2020) NeurIPS 2020 Workshop. 2020. Available online: https://ppml-workshop.github.io/ppml20/pdfs/Chillotti_et_al.pdf (accessed on 22 July 2021).
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 22 July 2021).
- Sharma, S.; Sharma, S. Activation functions in neural networks. Towards Data Sci. 2017, 6, 310–316. [Google Scholar] [CrossRef]
- Sze, V.; Chen, Y.H.; Yang, T.J.; Emer, J.S. Efficient Processing of Deep Neural Networks: A Tutorial and Survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef] [Green Version]
- Hubara, I.; Courbariaux, M.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized Neural networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 4114–4122. [Google Scholar]
- Qin, H.; Gong, R.; Liu, X.; Bai, X.; Song, J.; Sebe, N. Binary neural networks: A survey. Pattern Recognit. 2020, 105, 107281. [Google Scholar] [CrossRef] [Green Version]
- Jap, D.; Yli-Mäyry, V.; Ito, A.; Ueno, R.; Bhasin, S.; Homma, N. Practical Side-Channel Based Model Extraction Attack on Tree-Based Machine Learning Algorithm. In Proceedings of the International Conference on Applied Cryptography and Network Security, Rome, Italy, 19–22 October 2020; pp. 93–105. [Google Scholar]
- Spreitzer, R.; Moonsamy, V.; Korak, T.; Mangard, S. Systematic Classification of Side-Channel Attacks: A Case Study for Mobile Devices. IEEE Commun. Surv. Tutor. 2017, 20, 465–488. [Google Scholar] [CrossRef] [Green Version]
- Kocher, P.; Jaffe, J.; Jun, B. Differential Power Analysis. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 15–19 August 1999; pp. 388–397. [Google Scholar]
- Brier, E.; Clavier, C.; Olivier, F. Correlation Power Analysis with a Leakage Model. In Proceedings of the International Workshop on Cryptographic Hardware and Embedded Systems, Cambridge, MA, USA, 11–13 August 2004; pp. 16–29. [Google Scholar]
- Gilad-Bachrach, R.; Dowlin, N.; Laine, K.; Lauter, K.; Naehrig, M.; Wernsing, J. CryptoNets: Applying Neural Networks to Encrypted Data with High Throughput and Accuracy. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 201–210. [Google Scholar]
- Wei, L.; Luo, B.; Li, Y.; Liu, Y.; Xu, Q. I Know What You See: Power Side-Channel Attack on Convolutional Neural Network Accelerators. In Proceedings of the 34th Annual Computer Security Applications Conference, San Juan, PR, USA, 3–7 December 2018; pp. 393–406. [Google Scholar]
- Batina, L.; Bhasin, S.; Jap, D.; Picek, S. CSI NN: Reverse Engineering of Neural Network Architectures Through Electromagnetic Side Channel. In Proceedings of the 28th USENIX Security Symposium (USENIX Security 19), Santa Clara, CA, USA, 14–16 August 2019; pp. 515–532. [Google Scholar]
- Batina, L.; Bhasin, S.; Jap, D.; Picek, S. CSI Neural Network: Using Side-channels to Recover Your Artificial Neural Network Information. arXiv 2018, arXiv:1810.09076. [Google Scholar]
- Chabanne, H.; Danger, J.L.; Guiga, L.; Kühne, U. Side channel attacks for architecture extraction of neural networks. CAAI Trans. Intell. Technol. 2021, 6, 3–16. [Google Scholar] [CrossRef]
- Xu, Q.; Arafin, M.T.; Qu, G. Security of Neural Networks from Hardware Perspective: A Survey and Beyond. In Proceedings of the 2021 26th Asia and South Pacific Design Automation Conference (ASP-DAC), Tokyo, Japan, 18–21 January 2021; pp. 449–454. [Google Scholar]
- Joud, R.; Moellic, P.A.; Bernhard, R.; Rigaud, J.B. A Review of Confidentiality Threats Against Embedded Neural Network Models. arXiv 2021, arXiv:2105.01401. [Google Scholar]
- Mittal, S.; Gupta, H.; Srivastava, S. A Survey on hardware security of DNN models and accelerators. J. Syst. Archit. 2021, 117, 102163. [Google Scholar] [CrossRef]
- Lai, L.; Suda, N.; Chandra, V. CMSIS-NN: Efficient Neural Network Kernels for Arm Cortex-M CPUs. arXiv 2018, arXiv:1801.06601. [Google Scholar]
- Deng, L. The MNIST Database of Handwritten Digit Images for Machine Learning Research [Best of the Web]. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Alex, K.; Vinod, N.; Geoffrey, H. CIFAR-10 (Canadian Institute for Advanced Research). Available online: http://www.cs.toronto.edu/~kriz/cifar.html (accessed on 22 July 2021).
- Maji, S.; Banerjee, U.; Chandrakasan, A.P. Leaky Nets: Recovering Embedded Neural Network Models and Inputs through Simple Power and Timing Side-Channels–Attacks and Defenses. IEEE Internet Things J. 2021. [Google Scholar] [CrossRef]
- Yoshida, K.; Kubota, T.; Shiozaki, M.; Fujino, T. Model-Extraction Attack Against FPGA-DNN Accelerator Utilizing Correlation Electromagnetic Analysis. In Proceedings of the 2019 IEEE 27th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), San Diego, CA, USA, 28 April–1 May 2019; p. 318. [Google Scholar]
- Yoshida, K.; Kubota, T.; Okura, S.; Shiozaki, M.; Fujino, T. Model Reverse-Engineering Attack using Correlation Power Analysis against Systolic Array Based Neural Network Accelerator. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Seville, Spain, 12–14 October 2020; pp. 1–5. [Google Scholar]
- Yoshida, K.; Shiozaki, M.; Okura, S.; Kubota, T.; Fujino, T. Model Reverse-Engineering Attack against Systolic-Array-Based DNN Accelerator Using Correlation Power Analysis. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2021, 104, 152–161. [Google Scholar] [CrossRef]
- Dubey, A.; Cammarota, R.; Aysu, A. MaskedNet: The First Hardware Inference Engine Aiming Power Side-Channel Protection. In Proceedings of the 2020 IEEE International Symposium on Hardware Oriented Security and Trust (HOST), San Jose, CA, USA, 7–11 December 2020; pp. 197–208. [Google Scholar]
- Yu, H.; Ma, H.; Yang, K.; Zhao, Y.; Jin, Y. DeepEM: Deep Neural Networks Model Recovery through EM Side-Channel Information Leakage. In Proceedings of the 2020 IEEE International Symposium on Hardware Oriented Security and Trust (HOST), San Jose, CA, USA, 7–11 December 2020; pp. 209–218. [Google Scholar]
- Xiang, Y.; Chen, Z.; Chen, Z.; Fang, Z.; Hao, H.; Chen, J.; Liu, Y.; Wu, Z.; Xuan, Q.; Yang, X. Open DNN Box by Power Side-Channel Attack. IEEE Trans. Circuits Syst. II Express Briefs 2020, 67, 2717–2721. [Google Scholar] [CrossRef] [Green Version]
- Batina, L.; Bhasin, S.; Jap, D.; Picek, S. Poster: Recovering the Input of Neural Networks via Single Shot Side-channel Attacks. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 2657–2659. [Google Scholar]
- Moini, S.; Tian, S.; Szefer, J.; Holcomb, D.; Tessier, R. Remote Power Side-Channel Attacks on CNN Accelerators in FPGAs. arXiv 2020, arXiv:2011.07603. [Google Scholar]
- Moini, S.; Tian, S.; Holcomb, D.; Szefer, J.; Tessier, R. Power Side-Channel Attacks on BNN Accelerators in Remote FPGAs. IEEE J. Emerg. Sel. Top. Circuits Syst. 2021, 11, 357–370. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lowd, D.; Meek, C. Adversarial learning. In Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, Chicago, IL, USA, 21–24 August 2005; pp. 641–647. [Google Scholar]
- Zhao, R.; Song, W.; Zhang, W.; Xing, T.; Lin, J.H.; Srivastava, M.; Gupta, R.; Zhang, Z. Accelerating Binarized Convolutional Neural Networks with Software-Programmable FPGAs. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017; pp. 15–24. [Google Scholar]
- Yu, H.; Yang, K.; Zhang, T.; Tsai, Y.Y.; Ho, T.Y.; Jin, Y. CloudLeak: Large-Scale Deep Learning Models Stealing Through Adversarial Examples. In Proceedings of the Network and Distributed Systems Security Symposium (NDSS), San Diego, CA, USA, 23–26 February 2020. [Google Scholar]
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A.; et al. In-Datacenter Performance Analysis of a Tensor Processing Unit. In Proceedings of the 44th Annual International Symposium on Computer Architecture, Toronto, ON, Canada, 24–28 June 2017; pp. 1–12. [Google Scholar]
- Kung, H.T. Why systolic architectures? IEEE Comput. 1982, 15, 37–46. [Google Scholar] [CrossRef]
- Clavier, C.; Feix, B.; Gagnerot, G.; Roussellet, M.; Verneuil, V. Horizontal Correlation Analysis on Exponentiation. In Proceedings of the International Conference on Information and Communications Security, Copenhagen, Denmark, 24–26 August 2010; pp. 46–61. [Google Scholar]
- Schellenberg, F.; Gnad, D.R.; Moradi, A.; Tahoori, M.B. An inside job: Remote power analysis attacks on FPGAs. In Proceedings of the 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 1111–1116. [Google Scholar]
- Yan, M.; Fletcher, C.W.; Torrellas, J. Cache Telepathy: Leveraging Shared Resource Attacks to Learn DNN Architectures. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), San Diego, CA, USA, 20–22 August 2020; pp. 2003–2020. [Google Scholar]
- Gongye, C.; Fei, Y.; Wahl, T. Reverse-Engineering Deep Neural Networks Using Floating-Point Timing Side-Channels. In Proceedings of the 2020 57th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 20–24 July 2020; pp. 1–6. [Google Scholar]
- Yarom, Y.; Falkner, K. FLUSH+RELOAD: A High Resolution, Low Noise, L3 Cache Side-Channel Attack. In Proceedings of the 23rd USENIX Security Symposium (USENIX Security 14), San Diego, CA, USA, 20–22 August 2014; pp. 719–732. [Google Scholar]
- Hong, S.; Davinroy, M.; Kaya, Y.; Locke, S.N.; Rackow, I.; Kulda, K.; Dachman-Soled, D.; Dumitraş, T. Security Analysis of Deep Neural Networks Operating in the Presence of Cache Side-Channel Attacks. arXiv 2018, arXiv:1810.03487. [Google Scholar]
- Gongye, C.; Li, H.; Zhang, X.; Sabbagh, M.; Yuan, G.; Lin, X.; Wahl, T.; Fei, Y. New Passive and Active Attacks on Deep Neural Networks in Medical Applications. In Proceedings of the 39th International Conference on Computer-Aided Design, San Jose, CA, USA, 6–10 November 2020; pp. 1–9. [Google Scholar]
- Hua, W.; Zhang, Z.; Suh, G.E. Reverse Engineering Convolutional Neural Networks Through Side-channel Information Leaks. In Proceedings of the 2018 55th ACM/ESDA/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 24–28 June 2018; pp. 1–6. [Google Scholar]
- Dong, G.; Wang, P.; Chen, P.; Gu, R.; Hu, H. Floating-Point Multiplication Timing Attack on Deep Neural Network. In Proceedings of the 2019 IEEE International Conference on Smart Internet of Things (SmartIoT), Tianjin, China, 9–11 August 2019; pp. 155–161. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attack | Aim of the Attack | Attacked Network | Data Set | Physical Target | Physical Measurement, Technique | Requirements/Limitations |
|---|---|---|---|---|---|---|
| Batina et al.’19 [20] | Recover network architecture and parameters (activation function, number of layers and neurons and weights) | MLP, CNN | MNIST | Atmel ATmega328P, ARM Cortex-M3 | EM (SEMA, CEMA) | Minimal (black-box) |
| Maji et al.’21 [29] | Recover model weights, biases | CNN, BNN | MNIST | Atmel ATmega32P, ARM Cortex-M0+, custom-designed RISC-V | SPA (timing) | Knowing the network architecture (gray-box) and disabling all peripherals and methodology specific to µC |
| Yoshida et al.’19 [30] | Recover model weights | MLP | NS | FPGA (NS) | EM (CEMA) | Intention paper |
| Yoshida et al.’20 [31], Yoshida et al.’21 [32] | Recover model weights | Systolic array | NS | Xilinx Spartan3-A | Power (CPA, chain-CPA) | Knowing the network architecture (gray-box) and the accelerator architecture; only systolic array is implemented |
| Dubey et al.’20 [33] | Recover model weights | BNN (adder tree) | MNIST | Xilinx Kintex-7 | Power (DPA) | Knowing the network architecture (gray-box) and hardware implementation details |
| Yu et al.’20 [34] | Recover network architecture and weights | BNN | CIFAR-10 | Xilinx ZynqXC7000 | SEMA, adversarial training | Black-box, restriction of certain parameters to few values and identical hidden layers |
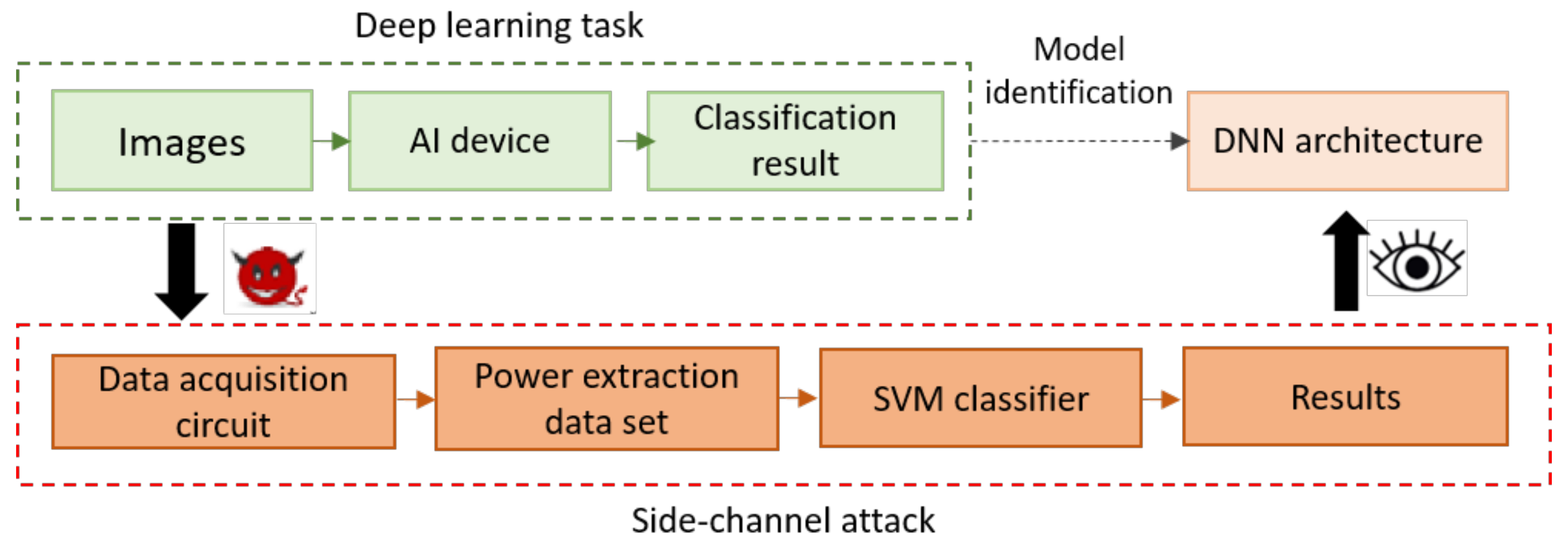
| Xiang et al.’20 [35] | Distinguish among different NN models and parameters sparsity | CNN | ImageNet | Raspberry Pi | Power, SVM classifier | Knowing the set of possible network architectures, using known pruning techniques and using non fine-tuned models once trained (gray-box) |
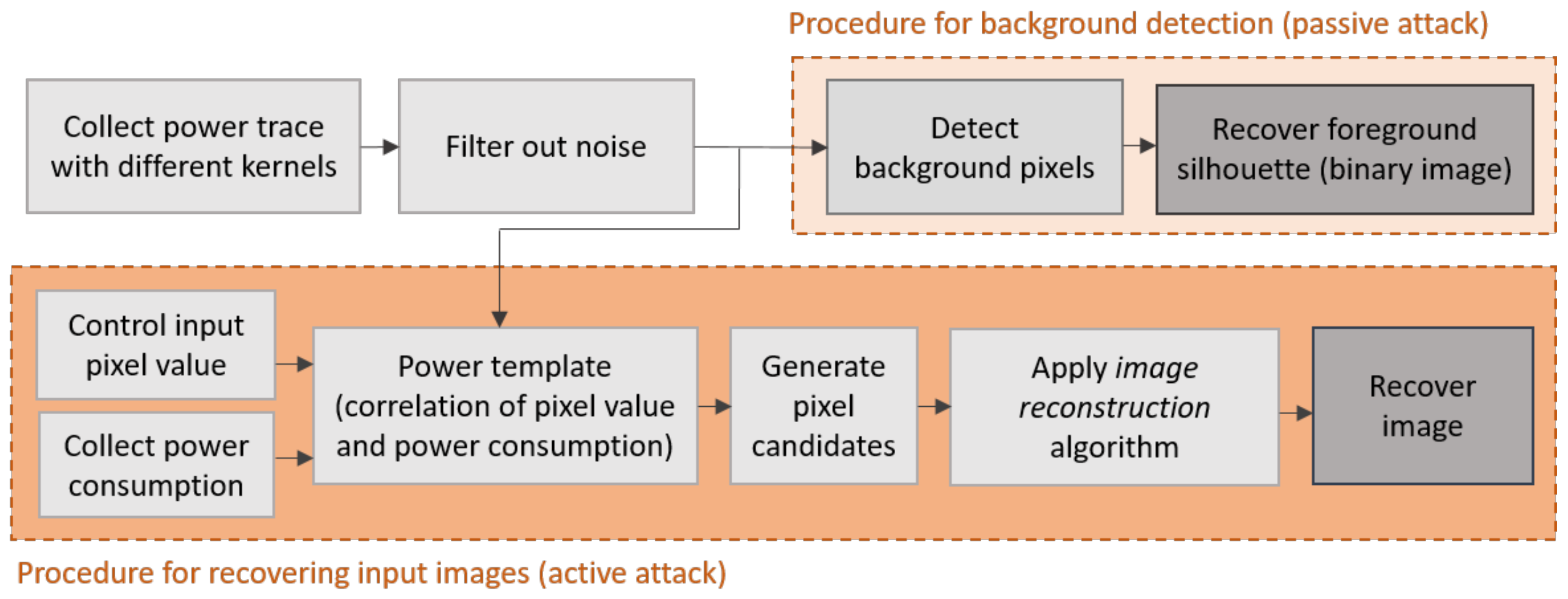
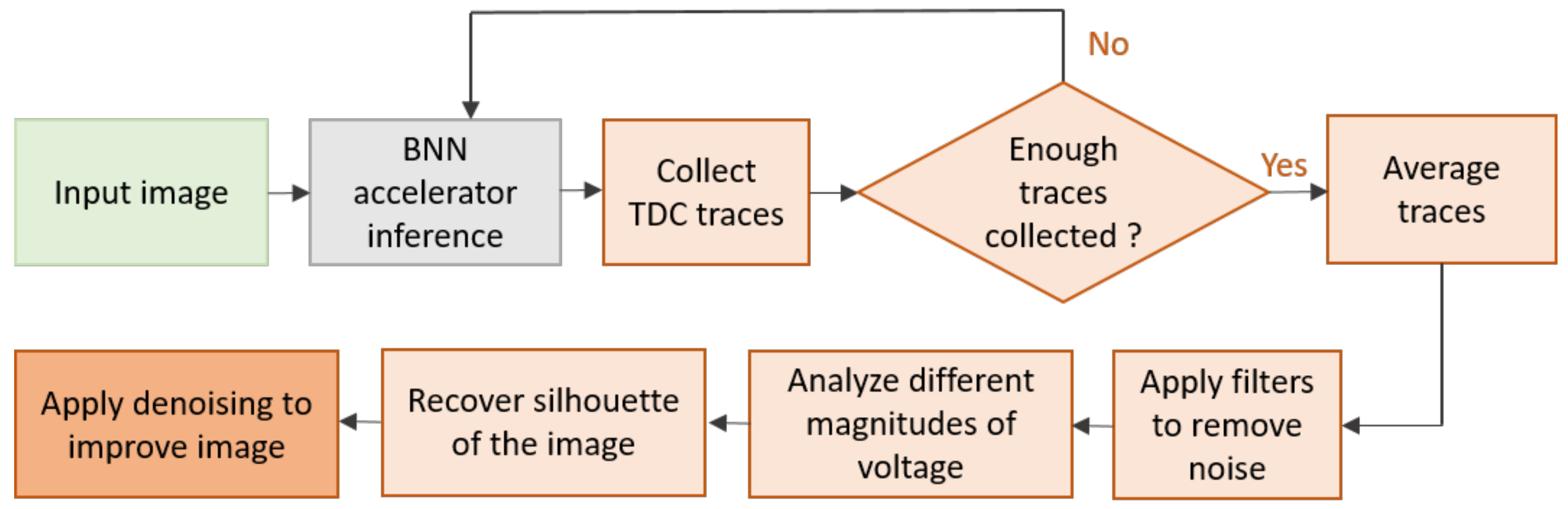
| Wei et al.’18 [19] | Recover network inputs | BNN | MNIST | Xilinx Spartan-6 LX75 | Power (template attack) | Specific to line buffer, suitable for plain background images and knowing the network architecture and parameters (white-box) |
| Batina et al.’18 [21], Batina et al.’19 [36] | Recover network inputs | MLP | MNIST | ARM Cortex-M3 | EM (HPA, DPA) | Knowing the network architecture and parameters (white-box) |
| Maji et al.’21 [29] | Recover network inputs | CNN (zero-skiping, normalised NN), BNN | MNIST | Atmel ATmega328P | Power (SPA) | Knowing the model architecture and parameters (white-box), disabling all peripherals and methodology specific to µC |
| Moini et al.’21 [37], Moini et al.’21 [38] | Recover network inputs (remote attack) | BNN | MNIST | Xilinx ZCU104, VCU118 | Power (remote) | Knowing the network architecture and parameters (white-box) and the adjacent location to victim module is required |
| Aim of the Attack | |
|---|---|
| Reverse engineering | Recovering model layout param [20,34], weights [20,29,30,31,32,33,34], biases [20,29] and distinguishing among model architectures and parameters sparsity ratios [35] |
| Data theft | Recovering inputs [19,21,29,36,37,38] |
| Attacked NN | |
| MLP | [20,21,30,36] |
| CNN | [20,29], Zero-skiping, normalised [29], Systolic array only [31,32], AlexNet, InceptionV3, ResNet50, ResNet101 [35], BNN [19,29,33,34,37,38], ConvNet, VGGNet [34] |
| Dataset | |
| MNIST | [19,20,21,29,33,36,37,38] |
| CIFAR-10 | [20,29,34] |
| ImageNet | [29,35] |
| Physical Target | |
| FPGA | [30], Spartan3-A [31,32], Spartan-6 LX75 [19], ZynqXC7000 [34], Kintex7 [33], ZCU104 and VCU118 [37,38] |
| µC | Rasberri Pi [35], ARM Cortex-M0+, custom-designed RISC-V [29], ATmega328P [20,29] and ARM Cortex-M3 [20,21,36] |
| Physical Measurement | |
| Power | SPA [29], DPA [21,33], CPA/chain-CPA [31,32], template attack [19], power, SVM [35] and remotely obtained [38] [37] |
| EM | HPA [21,36], SEMA [20,29], SEMA & adversarial [34], DEMA [21,36] and CEMA [20,30,34] |
| Exploits | |
| Architecture design | Systolic array [31,32], adder tree [33] and line buffer [19,37,38] |
| Hardware target specificity | All-’0’s pre-charge of data bus [20] and timing extraction of individual operations [20,29] |
| Correlation between | Parameters sparsity and power consumption [35], latency and number of parameters/operations [34], power/EM signatures and secret data processed (summations of products) [19,21,31,32,33,34,36] and activation functions [20,34] |
| Evaluation Metric | |
| Attack accuracy | Recovered pixel-level accuracy [19,21,36,37,38], mean structural similarity index between original and recovered image (MSSIM [39]) [37,38], input precision recognition of the network (original vs recovered) [19,20,34], average accuracy of recovered NN parameters [20,29,35] and normalised cross-correlation [37,38] |
| Attack efficiency | Portion of the correct recovered values (weights) [30,31,32] |
| Attack complexity | Number of measurements required [31,32,33,37,38], image reconstruction complexity and memory complexity [19] |
| Attacker Capabilities | |
| Attacker knowledge | Network architecture [21,29,31,32,33,36], set of possible network architectures [35], network parameters [19,21,29,35,36,37,38], used pruning techniques [35] and hardware implementation details [31,32,33] |
| Control on inputs | [20,29,30,31,32,33,34,35] |
| Disabling all peripherals | [29] |
| Assumptions Made to Facilitate the Attack | Limited set of possible network models [35], limited set of possible filter-sizes [34], recovering reduced precision values [20,21,36] and input images with easily distinguishable background from foreground [19,37,38] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Méndez Real, M.; Salvador, R. Physical Side-Channel Attacks on Embedded Neural Networks: A Survey. Appl. Sci. 2021, 11, 6790. https://doi.org/10.3390/app11156790
Méndez Real M, Salvador R. Physical Side-Channel Attacks on Embedded Neural Networks: A Survey. Applied Sciences. 2021; 11(15):6790. https://doi.org/10.3390/app11156790
Chicago/Turabian StyleMéndez Real, Maria, and Rubén Salvador. 2021. "Physical Side-Channel Attacks on Embedded Neural Networks: A Survey" Applied Sciences 11, no. 15: 6790. https://doi.org/10.3390/app11156790
APA StyleMéndez Real, M., & Salvador, R. (2021). Physical Side-Channel Attacks on Embedded Neural Networks: A Survey. Applied Sciences, 11(15), 6790. https://doi.org/10.3390/app11156790