
A Reinforcement Learning-Based Approach to Automate the Electrochromic Glass and to Enhance the Visual Comfort


Abstract
:1. Introduction
2. Methodology
2.1. Model Description
2.2. Simulating Electrochromic Glass in Radiance
2.3. Annual Simulations
2.3.1. Glare Simulations
- (cd/m), the luminance of the glare source i. Usually, the luminance of the sky seen through the window is considered here.
- , solid angle of the glare source i. Here the apparent size of the visible area of the sky w.r.t to observer’s eye through the window is considered.
- , Guth’s position index of the glare source i. It is calculated relative to the position of the observer’s line of sight which includes azimuth and elevation of the source.
- A sky file is created based on the solar direct and diffuse components along with the time, latitude, and longitude. This can be achieved with the tool gendaylit.
- The tool oconv uses the created sky file and other geometric files of the test room and creates a binary file in octree format to be further processed by other radiance tools. An octree file is created for each of the viewpoints of the occupant, each time step, and for every combination of EC glass.
- The tool rpict is the one that creates the photorealistic simulation of the entity based on given parameters. It can output several different image formats, but the one suitable is an HDR image in fisheye format.
- Evalglare uses the rpict generated fisheye HDR images to evaluate glare. It outputs DGP value along with several other glare indices.
2.3.2. Daylight Simulations
- The View (V) matrix contains the flux transfer from the points on the workspace where illuminance is to be calculated to the Electrochromic glass.
- The Transmission (T) matrix contains the flux transfer through the Electrochromic glass.
- The Daylight (D) matrix contains the flux transfer from exterior of Electrochromic glass to the sky.
- The Sky (S) represents the descritized sky vector with 145 patches based on Tregenza sky model(ref)
2.4. DQN Agent
2.5. Formal Definition
2.5.1. Observations
2.5.2. States
2.5.3. Actions
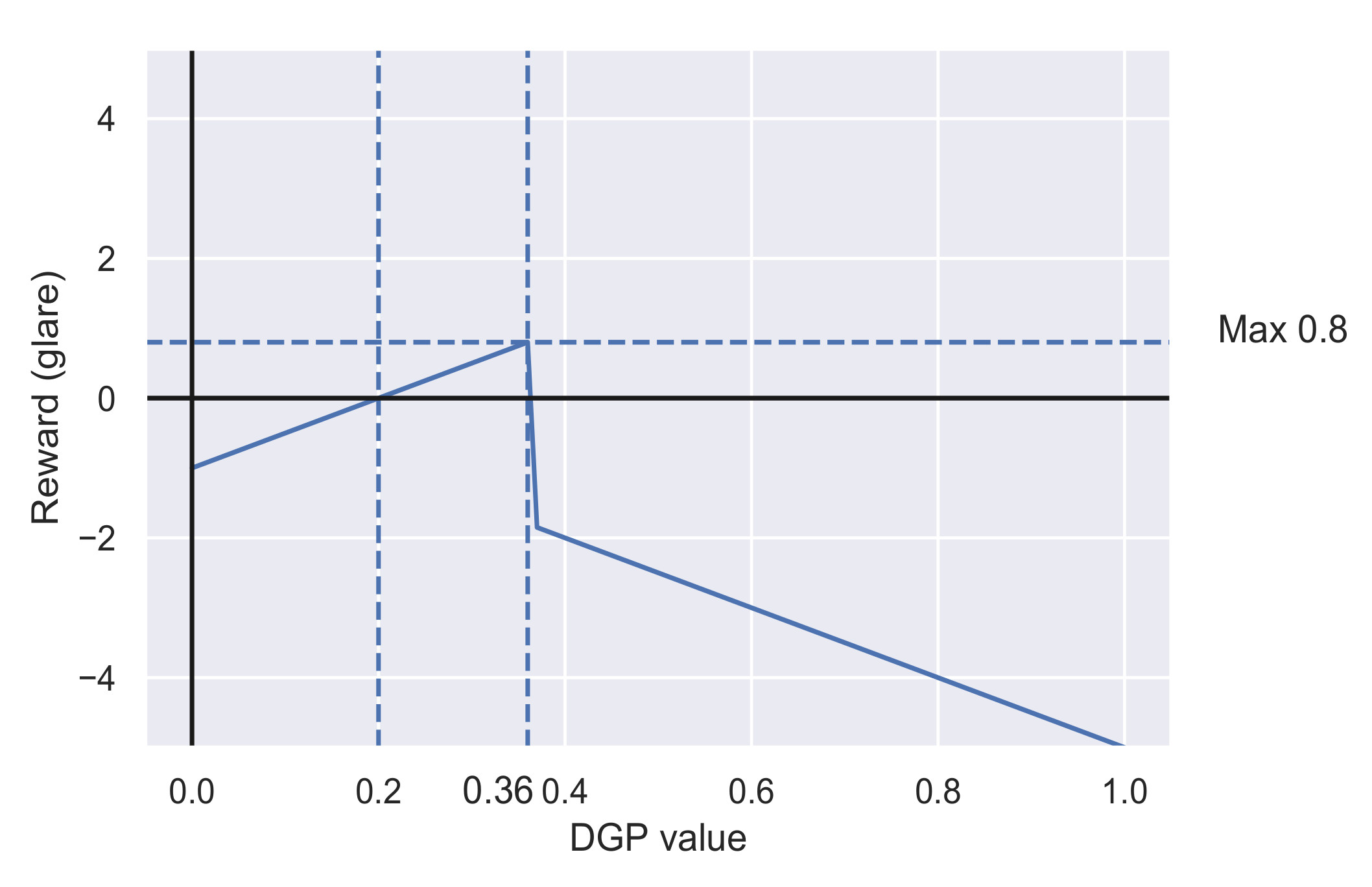
2.5.4. Reward Function
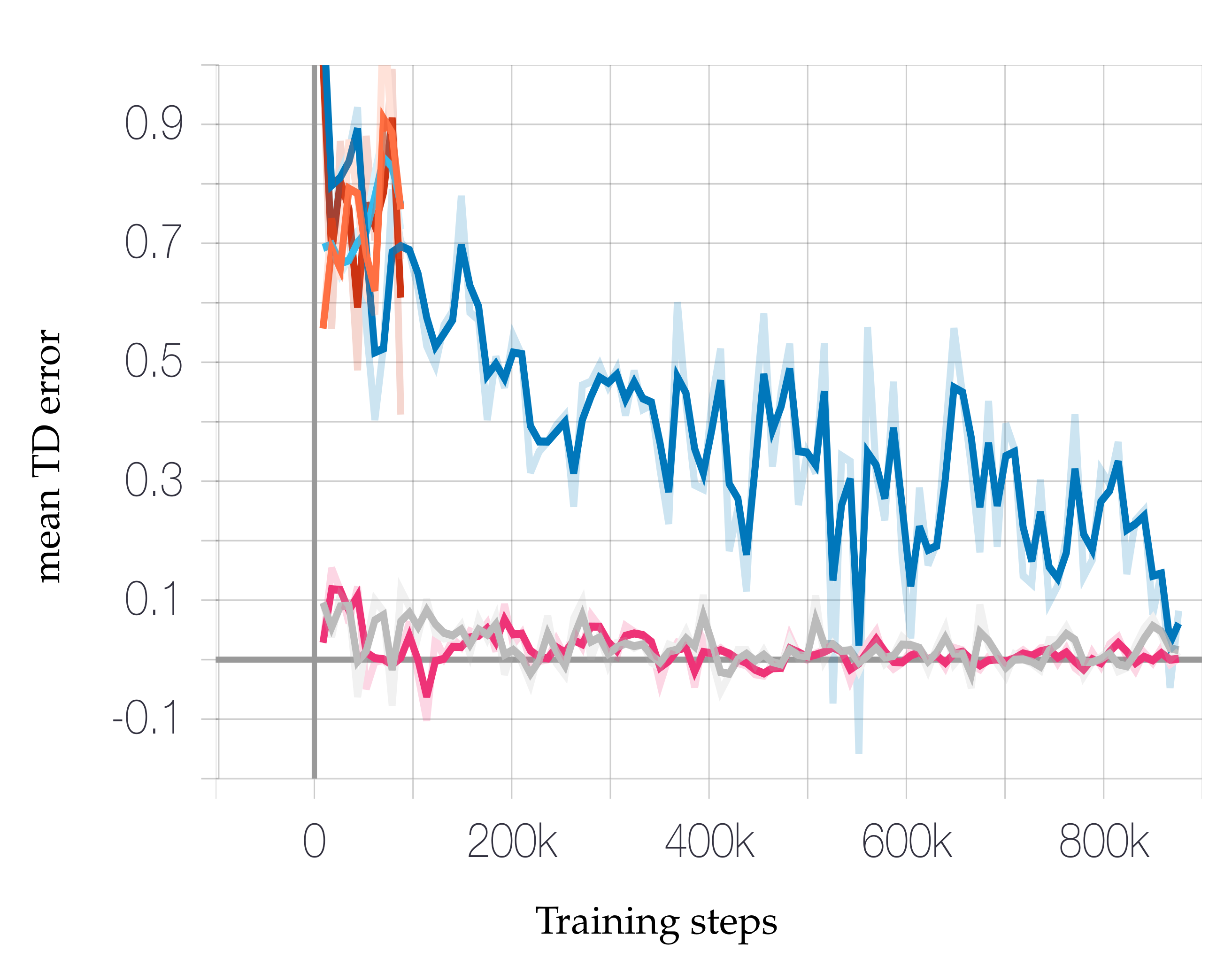
2.5.5. Training the DQN Agent
3. Results & Discussion
- Maximizing the daylight availability;
- Minimizing the glare.
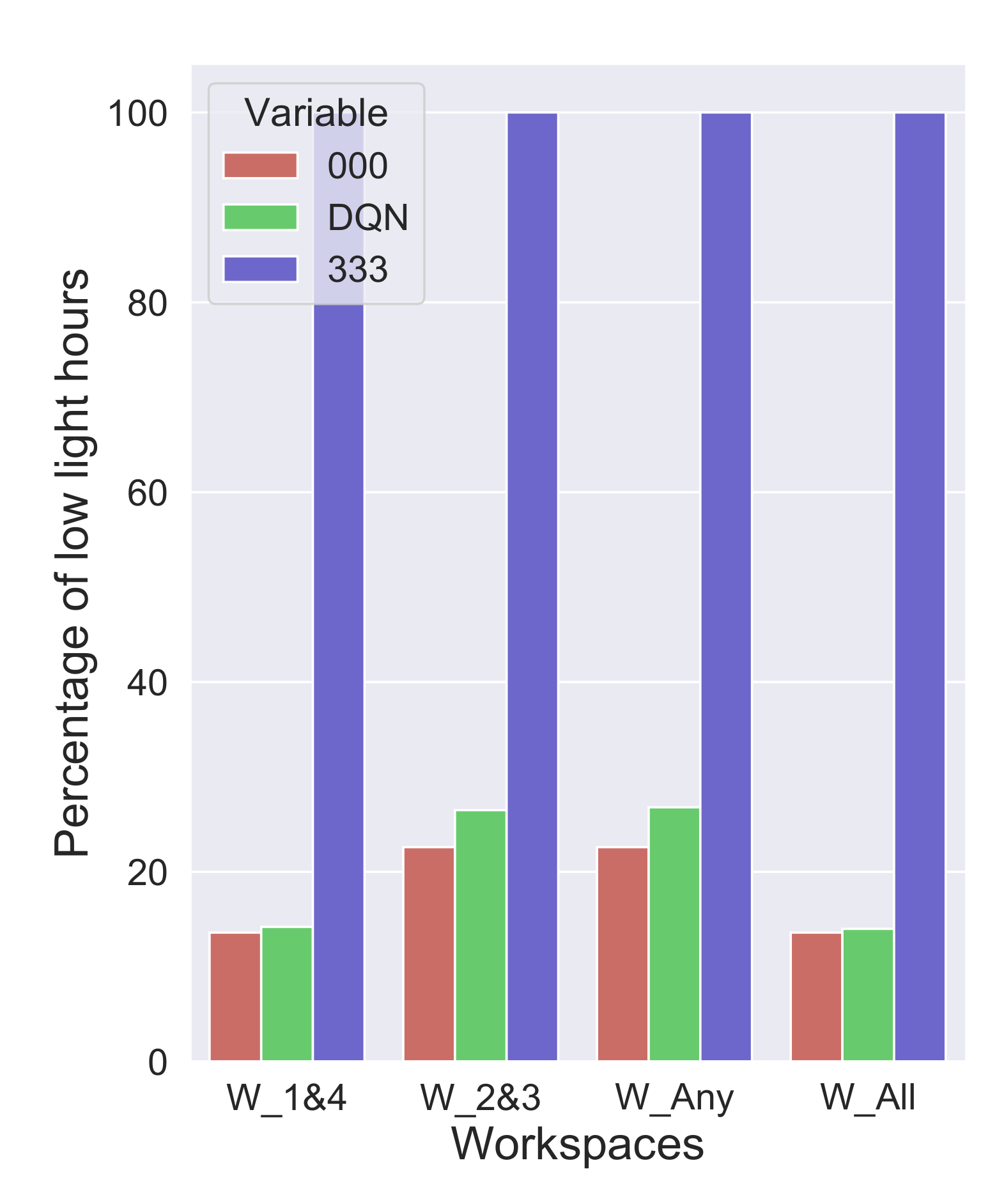
3.1. Daylight at Workspaces
3.1.1. Lowlight Scenario
3.1.2. Brightlight Scenario
3.1.3. Perfect Daylight Scenario
3.2. Glare Reduction
3.3. Analysis of DQN Agent’s Annual Results
3.3.1. Annual Glare with DQN Agent
3.3.2. Annual Daylight Availability with DQN Agent
3.3.3. Rewards
4. Conclusions
- In the case of bright daylight hours, it performs as well as its benchmark combination 330, whereas in the useful daylight scenario it does better than its benchmark combination 000 allowing up to 90% daylight.
- In the case of glare reduction, it performs as well as the darkest combination but allowing more light at the same time.
- The strategy of the DQN agent, i.e., changing different combinations continuously is efficient and reduced glare about 97% of the time and increased daylight availability in 90% of the work hours.
Author Contributions
Funding
Conflicts of Interest
References
- Climate Change Performance Index. Available online: https://ccpi.org/ (accessed on 6 April 2021).
- Global Status Report 2017. Available online: https://www.worldgbc.org/sites/default/files/UNEP%20188_GABC_en%20%28web%29.pdf (accessed on 6 April 2021).
- Frequently Asked Questions (FAQs)-U.S. Energy Information Administration (EIA). Available online: https://www.eia.gov/tools/faqs/faq.php?id=99 (accessed on 6 April 2021).
- Boyce, P.; Hunter, C.; Howlett, O. The Benefits of Daylight through Windows; Rensselaer Polytechnic Institute: Troy, NY, USA, 2003. [Google Scholar]
- Dupláková, D.; Hatala, M.; Duplák, J.; Knapčíková, L.; Radchenko, S. Illumination simulation of working environment during the testing of cutting materials durability. Ain Shams Eng. J. 2019, 10, 161–169. [Google Scholar] [CrossRef]
- Sullivan, R.; Rubin, M.; Selkowitz, S. Energy Performance Analysis of Prototype Electrochromic Windows; Technical report; Lawrence Berkeley National Lab.: Alameda County, CA, USA, 1996. [Google Scholar]
- Dupláková, D.; Flimel, M.; Duplák, J.; Hatala, M.; Radchenko, S.; Botko, F. Ergonomic rationalization of lighting in the working environment. Part I.: Proposal of rationalization algorithm for lighting redesign. Int. J. Ind. Ergon. 2019, 71, 92–102. [Google Scholar] [CrossRef]
- Kheybari, A.G.; Hoffmann, S. A Simulation-Based Framework Exploring the Controls for a Dynamic Facade with Electrochromic Glazing (EC). In Proceedings of the PowerSkin2019, Munich, Germany, 17 January 2019. [Google Scholar]
- Kalyanam, R.; Hoffmann, S. Reinforcement learning based approach to automate the external shading system and enhance the occupant comfort. In Proceedings of the AI in AEC Conference, Helsinki, Finland, 24–25 March 2021. [Google Scholar]
- Ward, G.J. The RADIANCE lighting simulation and rendering system. In Proceedings of the 21st Annual Conference on Computer Graphics and Interactive Techniques, New York, NY, USA, 24–29 July 1994. [Google Scholar]
- IGDB|Windows and Daylighting. Available online: https://windows.lbl.gov/software/igdb (accessed on 30 May 2021).
- Glass in Radiance|Model|Simulate|Visualize. Available online: https://modsimvis.blogspot.com/2014/12/glass-in-radiance.html (accessed on 29 May 2021).
- Wienold, J.; Christoffersen, J. Evaluation methods and development of a new glare prediction model for daylight environments with the use of CCD cameras. Energy Build. 2006, 38, 743–757. [Google Scholar] [CrossRef]
- Saraiji, R.; Al Safadi, M.; Al Ghaithi, N.; Mistrick, R. A comparison of scale-model photometry and computer simulation in day-lit spaces using a normalized daylight performance index. Energy Build. 2015, 89, 76–86. [Google Scholar] [CrossRef]
- Ward, G.; Mistrick, R.; Lee, E.S.; McNeil, A.; Jonsson, J. Simulating the daylight performance of complex fenestration systems using bidirectional scattering distribution functions within radiance. Leukos 2011, 7, 241–261. [Google Scholar] [CrossRef] [Green Version]
- Roudsari, M.S.; Pak, M.; Smith, A. Ladybug: A parametric environmental plugin for grasshopper to help designers create an environmentally-conscious design. In Proceedings of the 13th International IBPSA Conference, Lyon, France, 26–28 August 2013. [Google Scholar]
- Subramaniam, S. Daylighting Simulations with Radiance Using Matrix-Based Methods; Lawrence Berkeley National Laboratory: Berkeley, CA, USA, 2017. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Sutton, R.S. Integrated architectures for learning, planning, and reacting based on approximating dynamic programming. In Machine Learning Proceedings 1990; Elsevier: Amsterdam, The Netherlands, 1990; pp. 216–224. [Google Scholar]
- Kalyanam, R.; Hoffmann, S. A Novel Approach to Enhance the Generalization Capability of the Hourly Solar Diffuse Horizontal Irradiance Models on Diverse Climates. Energies 2020, 13, 4868. [Google Scholar] [CrossRef]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. Openai gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Liang, E.; Liaw, R.; Nishihara, R.; Moritz, P.; Fox, R.; Gonzalez, J.; Goldberg, K.; Stoica, I. Ray rllib: A composable and scalable reinforcement learning library. arXiv 2017, arXiv:1712.09381. [Google Scholar]
- Moritz, P.; Nishihara, R.; Wang, S.; Tumanov, A.; Liaw, R.; Liang, E.; Elibol, M.; Yang, Z.; Paul, W.; Jordan, M.I.; et al. Ray: A distributed framework for emerging AI applications. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), Carlsbad, CA, USA, 8–10 October 2018; pp. 561–577. [Google Scholar]
- Liaw, R.; Liang, E.; Nishihara, R.; Moritz, P.; Gonzalez, J.E.; Stoica, I. Tune: A research platform for distributed model selection and training. arXiv 2018, arXiv:1807.05118. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Glare Perception | DGP Value |
|---|---|
| Imperceptible | <0.36 |
| Perceptible | 0.36–0.4 |
| Disturbing | 0.4–0.45 |
| Intolerable | >0.45 |
| Algorithm | Description | Policy | Action Space | State Space |
|---|---|---|---|---|
| DQN | Deep Q Network | Off-policy | Discrete | Continuous |
| DDPG | Deep Deterministic Policy Gradient | Off-policy | Continuous | Continuous |
| A3C | Asynchronous Advantage Actor-Critic Algorithm | On-policy | Continuous | Continuous |
| TRPO | Trust Region Policy Optimization | On-policy | Continuous | Continuous |
| PPO | Proximal Policy Optimization | On-policy | Continuous | Continuous |
| State | ID | IGDB ID | |
|---|---|---|---|
| Clear | 0 | 8905 | 0.448 |
| Low tint | 1 | 8906 | 0.121 |
| Medium tint | 2 | 8908 | 0.040 |
| Dark | 3 | 8909 | 0.007 |
| ID | Reward (Glare) | Reward (Illuminance) | Total Reward | Network Config | |
|---|---|---|---|---|---|
 | A | 1102 | 626 | 1728 | [2048, 2048] |
| B | 1106 | 625.6 | 1731.6 | [2048, 2048] | |
| C | 1108 | 631 | 1739 | [2048, 1024] | |
| D | 1104 | 628.5 | 1732.5 | [4096, 2048] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kalyanam, R.; Hoffmann, S. A Reinforcement Learning-Based Approach to Automate the Electrochromic Glass and to Enhance the Visual Comfort. Appl. Sci. 2021, 11, 6949. https://doi.org/10.3390/app11156949
Kalyanam R, Hoffmann S. A Reinforcement Learning-Based Approach to Automate the Electrochromic Glass and to Enhance the Visual Comfort. Applied Sciences. 2021; 11(15):6949. https://doi.org/10.3390/app11156949
Chicago/Turabian StyleKalyanam, Raghuram, and Sabine Hoffmann. 2021. "A Reinforcement Learning-Based Approach to Automate the Electrochromic Glass and to Enhance the Visual Comfort" Applied Sciences 11, no. 15: 6949. https://doi.org/10.3390/app11156949
APA StyleKalyanam, R., & Hoffmann, S. (2021). A Reinforcement Learning-Based Approach to Automate the Electrochromic Glass and to Enhance the Visual Comfort. Applied Sciences, 11(15), 6949. https://doi.org/10.3390/app11156949