
MFCosface: A Masked-Face Recognition Algorithm Based on Large Margin Cosine Loss



Abstract
:1. Introduction
- We designed a masked-face image generation algorithm based on the detection of key facial features, and generate masked-face images from face datasets and mask templates. The images were used construct a dataset for training, which alleviated the problem of insufficient data.
- A masked-face recognition algorithm based on large margin cosine loss is proposed. We analyzed the characteristics of the masked-face dataset, and proved the rationality of using the large margin cosine loss function.
- Experiments on our artificial masked-face dataset and a real masked-face image dataset proved that our algorithm greatly improves the accuracy of masked-face recognition, and can accurately perform facial recognition in spite of mask occlusion.
2. Related Work
2.1. Face Alignment and the Detection of Key Facial Features
2.2. Softmax Loss Function
- The size of the linear transformation matrix increases linearly with the number of identities n. Since a matrix is used to output n identity prediction probabilities, the number of identities n in the large-scale test set is usually very large, so the matrix W will show a linear increasing trend with n, which will reduce the training efficiency of the model.
- In the open-set facial recognition problem, a face cannot be fully distinguished. If a face image that has not been trained with before appears in the model recognition process, this method cannot distinguish it well, because the final output of the model does not include the probability of the identity never having appeared.
- The softmax loss function does not explicitly optimize the characteristics of images to increase the similarity of the samples within the class and the diversity of the samples between the classes, which leads to a large number of appearance changes within each class. Hence, the performance for facial recognition is poor.
2.3. Attention Model
3. Proposed Methods
3.1. Dataset Preprocessing
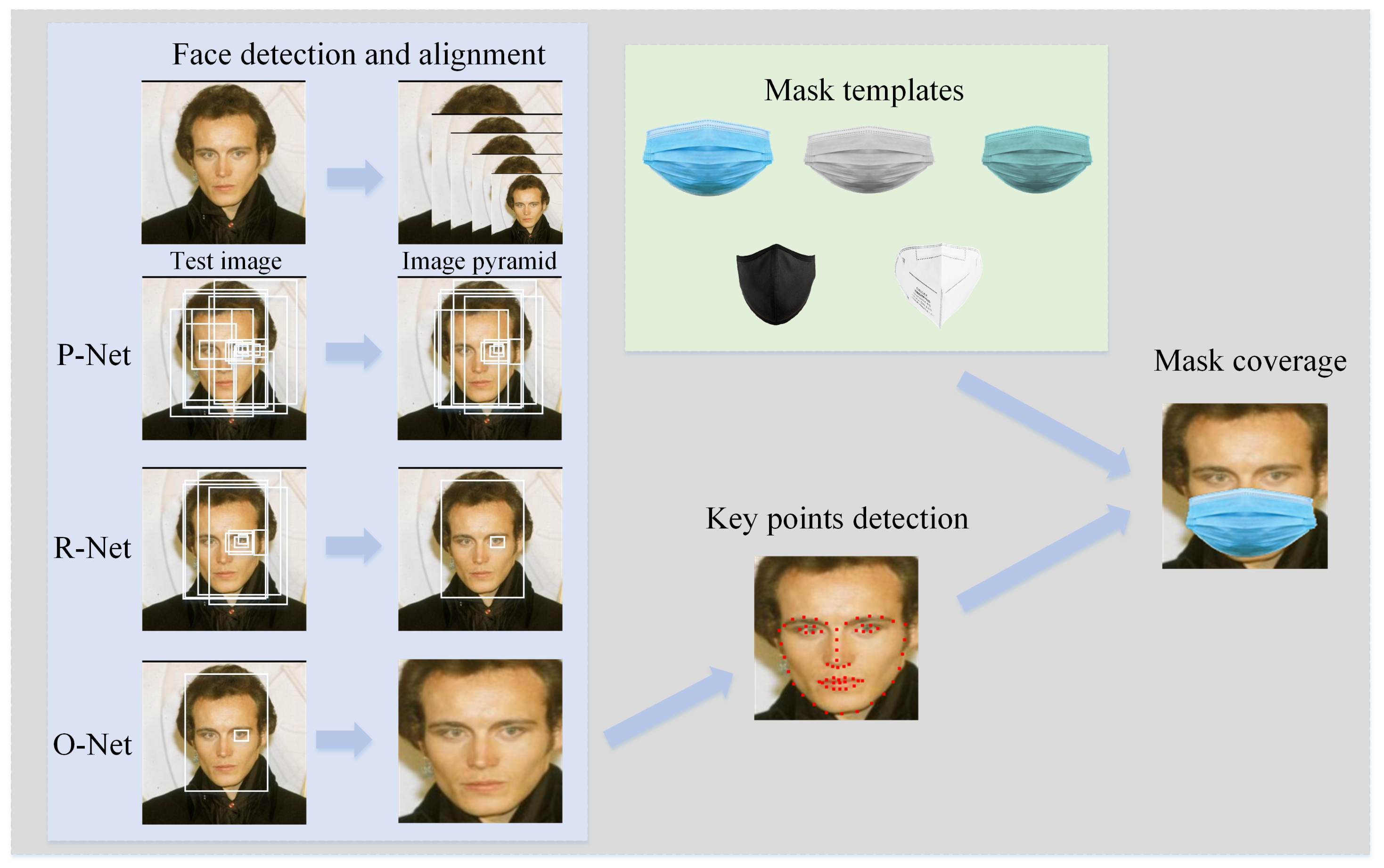
- Face detection: We used a multi-task cascaded convolutional neural network (MTCNN) [25] for preprocessing, and got an image containing only faces. The result is shown in Figure 1. MTCNN is mainly composed of three convolutional neural networks, cascaded. First our system involves resizing the image and generating image pyramids of different scales; then we send them to P-Net to generate many candidate frames containing faces or partial faces; then we filter out a large number of poor candidate frames through R-Net and perform regression on the candidate frames to optimize the prediction results; finally, we use O-Net to regress the features and output the positions of the key features.
- Key feature detection: MTCNN can only detect the key points of the eyes, nose, left mouth, and right mouth, and it is difficult to generate a more realistic masked-face image using only 5 key points, so we used HOG features to detect 68 key points of the face [42]. This method is more detailed in the detection of key points. Note that we used the Dilb library to implement this process.
- Mask coverage: To generate a mask, we calculate the distance and structure information based on the relative positions of the chin and the bridge of the nose, get the coordinates of the mask, use common mask templates (surgical mask, KN95, etc.) to cover the face, and generate the masked-face image. The result is shown in Figure 1. Anwar et al. [43] also used a method for generating masked-face images for model training, but their method needs to collect mask templates from different angles, which has significant limitations. Our method uses only a front image of the mask, analyzes the relative positions of the key points of the face, and distorts the mask to generate a more realistic masked-face image.
3.2. Loss Function
3.3. Attention Model
3.4. Network Structure
4. Experimental Results
4.1. Datasets and Evaluation Criteria
4.2. Experimental Configuration
4.3. Experimental Results
4.4. Ablation Experiment
4.5. Noise Experiment
4.6. Attention Mechanism Experiment
4.7. Real-World Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, J.; Su, G.; Xiong, Y.; Chen, J.; Shang, Y.; Liu, J.; Ren, X. Sparse representation for based on constraint sampling and face alignment. Tsinghua Sci. Technol. 2013, 18, 62. [Google Scholar] [CrossRef]
- Shenvi, D.R.; Shet, K. Cnn based covid-19 prevention system. In Proceedings of the 2021 International Conference on Artificial Intelligence and Smart Systems (ICAIS), Coimbatore, India, 25–27 March 2021; pp. 873–878. [Google Scholar]
- Yin, X.; Yu, X.; Sohn, K.; Liu, X.; Chandraker, M. Feature transfer learning for face recognition with under-represented data. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5697–5706. [Google Scholar]
- Hu, G.; Yang, Y.; Yi, D.; Kittler, J.; Li, S.; Hospedales, T. When face recognition meets with deep learning: An evaluation of convolutional neural networks for face recognition. In Proceedings of the IEEE International Conference on Computer Vision Workshop, Santiago, Chile, 7–13 December 2015; pp. 384–392. [Google Scholar]
- Oloyede, M.O.; Hancke, G.P.; Myburgh, H.C. A review on face recognition systems: Recent approaches and challenges. Multimed. Tools Appl. 2020, 79, 37–38. [Google Scholar] [CrossRef]
- Sun, Y.; Liang, D.; Wang, X.; Tang, X. DeepID3: Face Recognition with Very Deep Neural Networks. arXiv 2015, arXiv:1502.00873. [Google Scholar]
- Deng, H.; Feng, Z.; Liu, Y.; Luo, D.; Yang, X.; Li, H. Face recognition algorithm based on weighted intensity pcnn. In Proceedings of the 2020 Eighth International Conference on Advanced Cloud and Big Data (CBD), Taiyuan, China, 5–6 December 2020; pp. 207–212. [Google Scholar]
- Yang, M.; Zhang, L.; Yang, J.; Zhang, D. Robust sparse coding for face recognition. In Proceedings of the Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 625–632. [Google Scholar]
- Wen, Y.; Liu, W.; Yang, M.; Fu, Y.; Xiang, Y.; Hu, R. Structured occlusion coding for robust face recognition. Neurocomputing 2016, 178, 11–24. [Google Scholar] [CrossRef] [Green Version]
- Wu, C.; Ding, J. Occluded face recognition using low-rank regression with generalized gradient direction. arXiv 2019, arXiv:1906.02429. [Google Scholar] [CrossRef] [Green Version]
- Dong, J.; Zheng, H.; Lian, L. Low-rank laplacian-uniform mixed model for robust face recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 11889–11898. [Google Scholar]
- Shi, Y.; Yu, X.; Sohn, K.; Chandraker, M.; Jain, A. Towards universal representation learning for deep face recognition. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6816–6825. [Google Scholar]
- Wang, X.; Han, C.; Hu, X. Densely connected convolutional networks face recognition algorithm based on weighted feature fusion. J. Front. Comput. Sci. Technol. 2019, 13, 1195–1205. [Google Scholar]
- Song, L.; Gong, D.; Li, Z.; Liu, C.; Liu, W. Occlusion robust face recognition based on mask learning with pairwise differential siamese network. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 773–782. [Google Scholar]
- Cen, F.; Wang, G. Dictionary representation of deep features for occlusion-robust face recognition. IEEE Access 2019, 7, 26595–26605. [Google Scholar] [CrossRef]
- Du, H.; Shi, H.; Liu, Y.; Zeng, D.; Mei, T. Towards nir-vis masked face recognition. IEEE Signal Process. Lett. 2021, 28, 768–772. [Google Scholar] [CrossRef]
- Wang, Z.; Kim, T.S. Learning to recognize masked faces by data synthesis. In Proceedings of the 2021 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Korea, 13–16 April 2021; pp. 36–41. [Google Scholar]
- Amin, M.I.; Hafeez, M.A.; Touseef, R.; Awais, Q. Person identification with masked face and thumb images under pandemic of covid-19. In Proceedings of the 2021 7th International Conference on Control, Instrumentation and Automation (ICCIA), Tabriz, Iran, 23–24 February 2021; pp. 1–4. [Google Scholar]
- Xie, J.; Yang, J.; Qian, J.; Tai, Y.; Zhang, H. Robust nuclear norm-based matrix regression with applications to robust face recognition. IEEE Trans. Image Process. 2017, 26, 2286–2295. [Google Scholar] [CrossRef] [PubMed]
- Ejaz, M.; Islam, M.; Sifatullah, M.; Sarker, A. Implementation of principal component analysis on masked and non-masked face recognition. In Proceedings of the 2019 1st International Conference on Advances in Science, Engineering and Robotics Technology (ICASERT), Dhaka, Bangladesh, 3–5 May 2019; pp. 1–5. [Google Scholar]
- Xu, X.-F.; Zhang, L.; Duan, C.-d.; Lu, Y. Research on inception module incorporated siamese convolutional neural networks to realize face recognition. IEEE Access 2019, 8, 12168–12178. [Google Scholar] [CrossRef]
- Xin, J.; Tan, X. Face alignment in-the-wild: A Survey. Comput. Vis. Image Underst. 2017, 162, 1–22. [Google Scholar]
- Georgios, T.; Maja, P. Optimization Problems for Fast AAM Fitting in-the-Wild. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 593–600. [Google Scholar]
- Epameinondas, A.; Joan, A.; Stefanos, Z. Active Pictorial Structures. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5435–5444. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 4. [Google Scholar] [CrossRef] [Green Version]
- Wu, W.; Qian, C.; Yang, S.; Wang, Q.; Cai, Y.; Zhou, Q. Look at Boundary: A Boundary-Aware Face Alignment Algorithm. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2129–2138. [Google Scholar]
- Kowalski, M.; Naruniec, J.; Trzcinski, T. Deep alignment network: A convolutional neural network for robust face alignment. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 2034–2043. [Google Scholar]
- Huang, Z.; Zhang, J.; Shan, H. When age-invariant face recognition meets face age synthesis: A multi-task learning framework. arXiv 2021, arXiv:2103.01520. [Google Scholar]
- Zhong, Y.; Deng, W.; Wang, M.; Hu, J.; Peng, J.; Tao, X.; Huang, Y. Unequal-training for deep face recognition with long-tailed noisy data. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7804–7813. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A discriminative feature learning approach for deep face recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–12 October 2016; pp. 499–515. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Yang, M. Large-margin softmax loss for convolutional neural networks. arXiv 2016, arXiv:1612.02295. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. Sphereface: Deep hypersphere embedding for face recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J.; Li, Z.; Liu, W. Cosface: Large margin cosine loss for deep face recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5265–5274. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4685–4694. [Google Scholar]
- Tay, C.-P.; Roy, S.; Yap, K.-H. Aanet: Attribute attention network for person re-identifications. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7127–7136. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar]
- Gao, Z.; Xie, J.; Wang, Q.; Li, P. Global second-order pooling convolutional networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3019–3028. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, X.; Girshick, R.; Mulam, H.; He, K. Non-local neural networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. Eca-net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Anwar, A.; Raychowdhury, A. Masked face recognition for secure authentication. arXiv 2020, arXiv:2008.11104. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Damer, N.; Grebe, J.H.; Chen, C.; Boutros, F.; Kirchbuchner, F.; Kuijper, A. The effect of wearing a mask on face recognition performance: An exploratory study. arXiv 2020, arXiv:2007.13521. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 4278–4284. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Training Set | LFW_m | CF_m |
|---|---|---|---|
| Facenet | VGGFace2_mini | 83.40 | 66.07 |
| Softmax | VGGFace2_mini | 90.92 | 71.72 |
| Cosface | VGGFace2_mini | 96.82 | 87.75 |
| Arcface | VGGFace2_mini | 97.30 | 89.62 |
| MFCosface | VGGFace2_m | 99.33 | 97.03 |
| Method | Training Set | MFR2 | RMFD |
|---|---|---|---|
| Facenet | VGGFace2_mini | 84.25 | 73.77 |
| Softmax | VGGFace2_mini | 92.50 | 90.30 |
| Cosface | VGGFace2_mini | 92.75 | 92.03 |
| Arcface | VGGFace2_mini | 93.11 | 92.28 |
| MFCosface | VGGFace2_m | 98.50 | 92.15 |
| Method | LFW_m | MFR2 |
|---|---|---|
| Facenet | 83.40 | 84.25 |
| Masked | 93.58 | 89.75 |
| Cosface | 96.82 | 96.75 |
| Cosface + CBAM | 96.70 | 96.25 |
| Masked + Cosface | 99.23 | 97.00 |
| MFCosface | 99.33 | 98.50 |
| Location | Dataset | Noise Type | Example | Method | Accuracy |
|---|---|---|---|---|---|
| UP | LFW | salt and pepper noise (probability = 5%) |  | FaceNet | 84.55 |
| MFCosface | 97.00 | ||||
| Down | LFW | salt and pepper noise (probability = 5%) |  | FaceNet | 82.05 |
| MFCosface | 97.92 | ||||
| All | LFW | salt and pepper noise (probability = 5%) |  | FaceNet | 77.45 |
| MFCosface | 95.12 | ||||
| UP | CASIA-FaceV5 | Gaussian noise (Mean = 0, variance = 1) |  | FaceNet | 75.71 |
| MFCosface | 93.62 | ||||
| Down | CASIA-FaceV5 | Gaussian noise (Mean = 0, variance = 1) |  | FaceNet | 75.58 |
| MFCosface | 96.47 | ||||
| All | CASIA-FaceV5 | Gaussian noise (Mean = 0, variance = 1) |  | FaceNet | 74.21 |
| MFCosface | 92.10 | ||||
| UP | MFR2 | random noise (num = 1000) |  | FaceNet | 76.75 |
| MFCosface | 94.50 | ||||
| Down | MFR2 | random noise (num = 1000) |  | FaceNet | 84.50 |
| MFCosface | 97.50 | ||||
| All | MFR2 | random noise (num = 1000) |  | FaceNet | 79.25 |
| MFCosface | 94.50 |
| Method | LFW_m | CF_m | MFR2 |
|---|---|---|---|
| CBAM_Reduction | 99.08 | 96.78 | 98.00 |
| CBAM_All | 99.18 | 97.17 | 98.00 |
| Att-Inception | 99.33 | 97.03 | 98.50 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, H.; Feng, Z.; Qian, G.; Lv, X.; Li, H.; Li, G. MFCosface: A Masked-Face Recognition Algorithm Based on Large Margin Cosine Loss. Appl. Sci. 2021, 11, 7310. https://doi.org/10.3390/app11167310
Deng H, Feng Z, Qian G, Lv X, Li H, Li G. MFCosface: A Masked-Face Recognition Algorithm Based on Large Margin Cosine Loss. Applied Sciences. 2021; 11(16):7310. https://doi.org/10.3390/app11167310
Chicago/Turabian StyleDeng, Hongxia, Zijian Feng, Guanyu Qian, Xindong Lv, Haifang Li, and Gang Li. 2021. "MFCosface: A Masked-Face Recognition Algorithm Based on Large Margin Cosine Loss" Applied Sciences 11, no. 16: 7310. https://doi.org/10.3390/app11167310
APA StyleDeng, H., Feng, Z., Qian, G., Lv, X., Li, H., & Li, G. (2021). MFCosface: A Masked-Face Recognition Algorithm Based on Large Margin Cosine Loss. Applied Sciences, 11(16), 7310. https://doi.org/10.3390/app11167310