
Novel Application of Long Short-Term Memory Network for 3D to 2D Retinal Vessel Segmentation in Adaptive Optics—Optical Coherence Tomography Volumes


 , ,
, , 
Abstract
:Featured Application
Abstract
1. Introduction
2. Materials and Methods
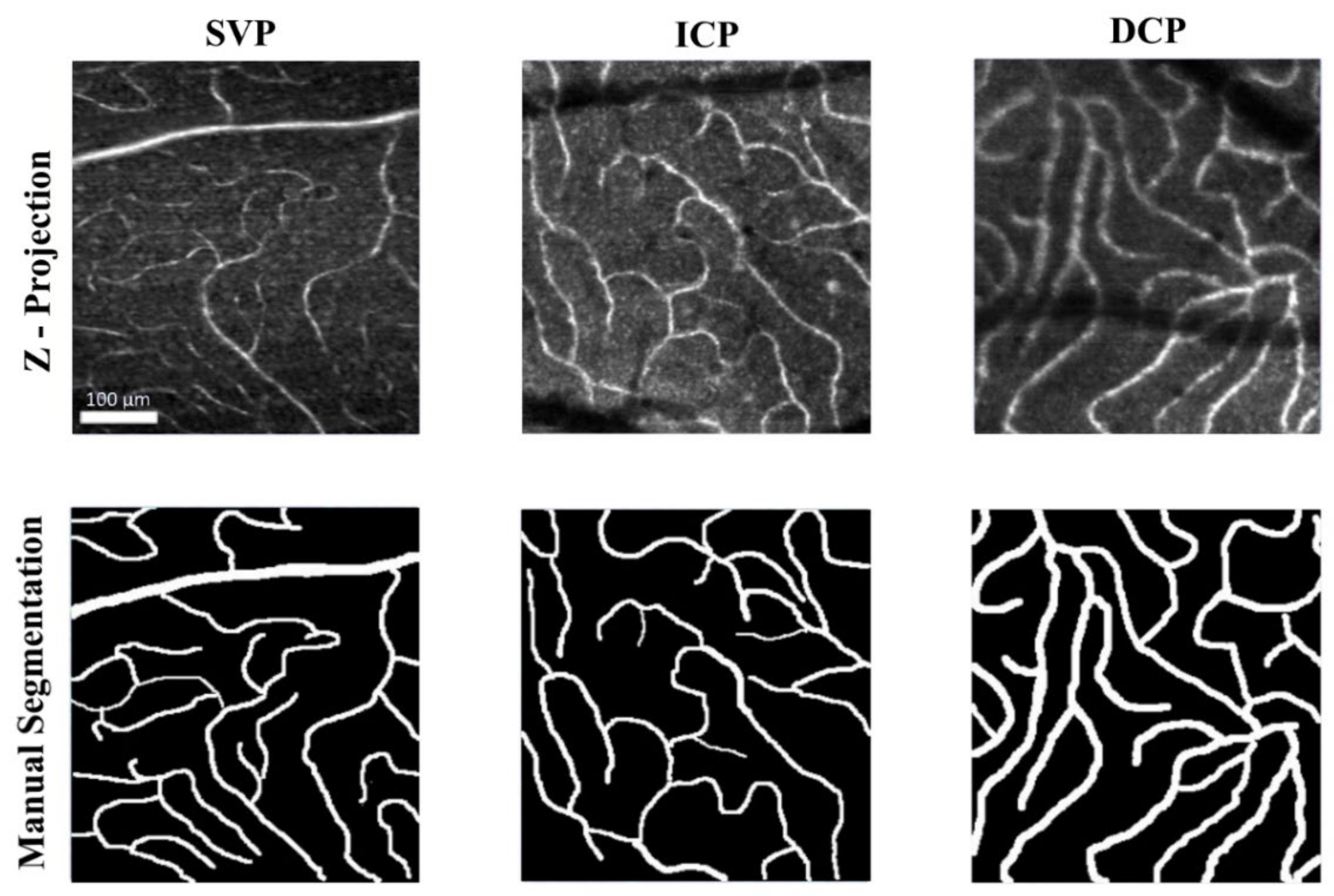
2.1. In-Vivo Adaptive Optics Imaging
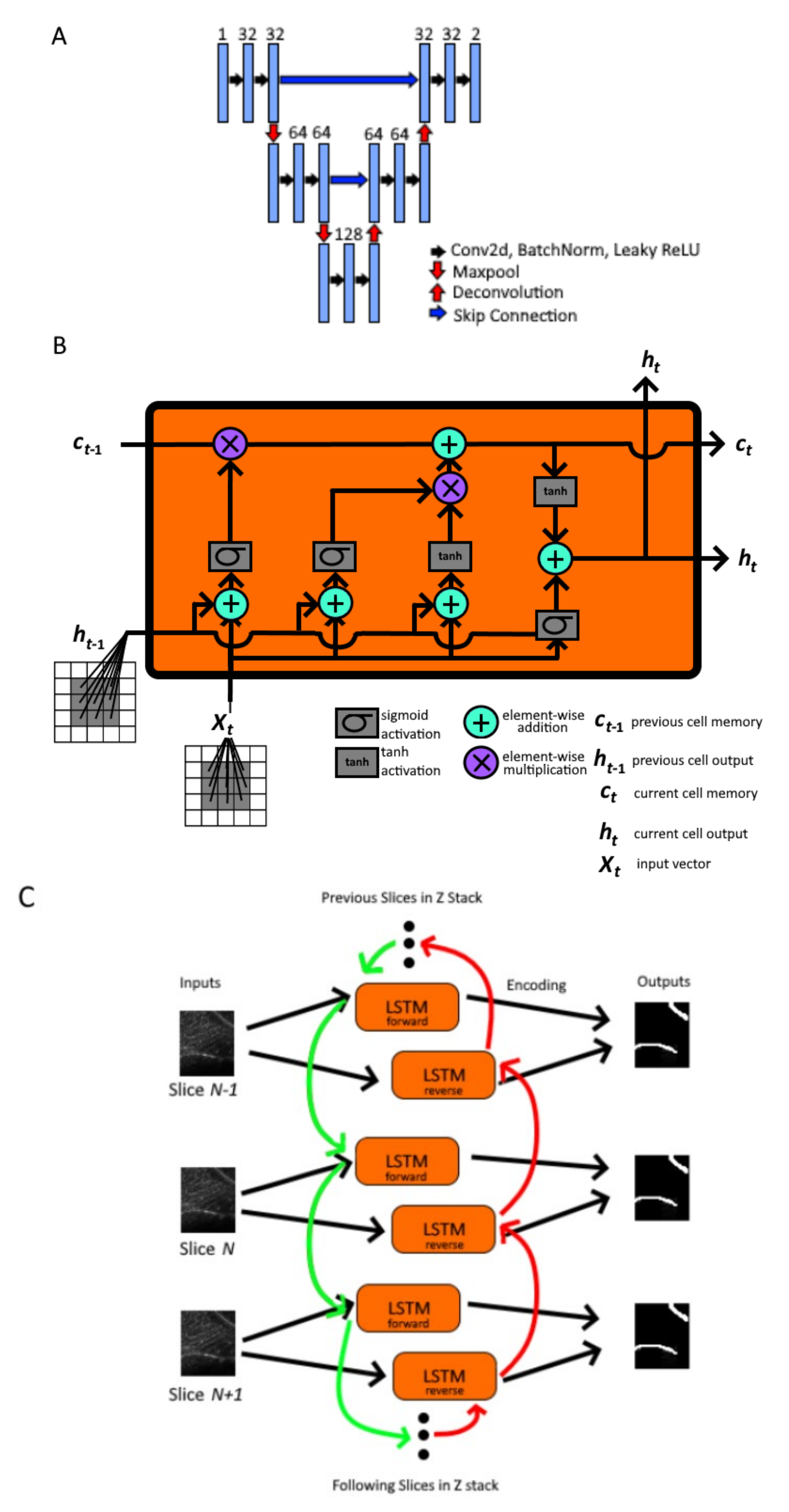
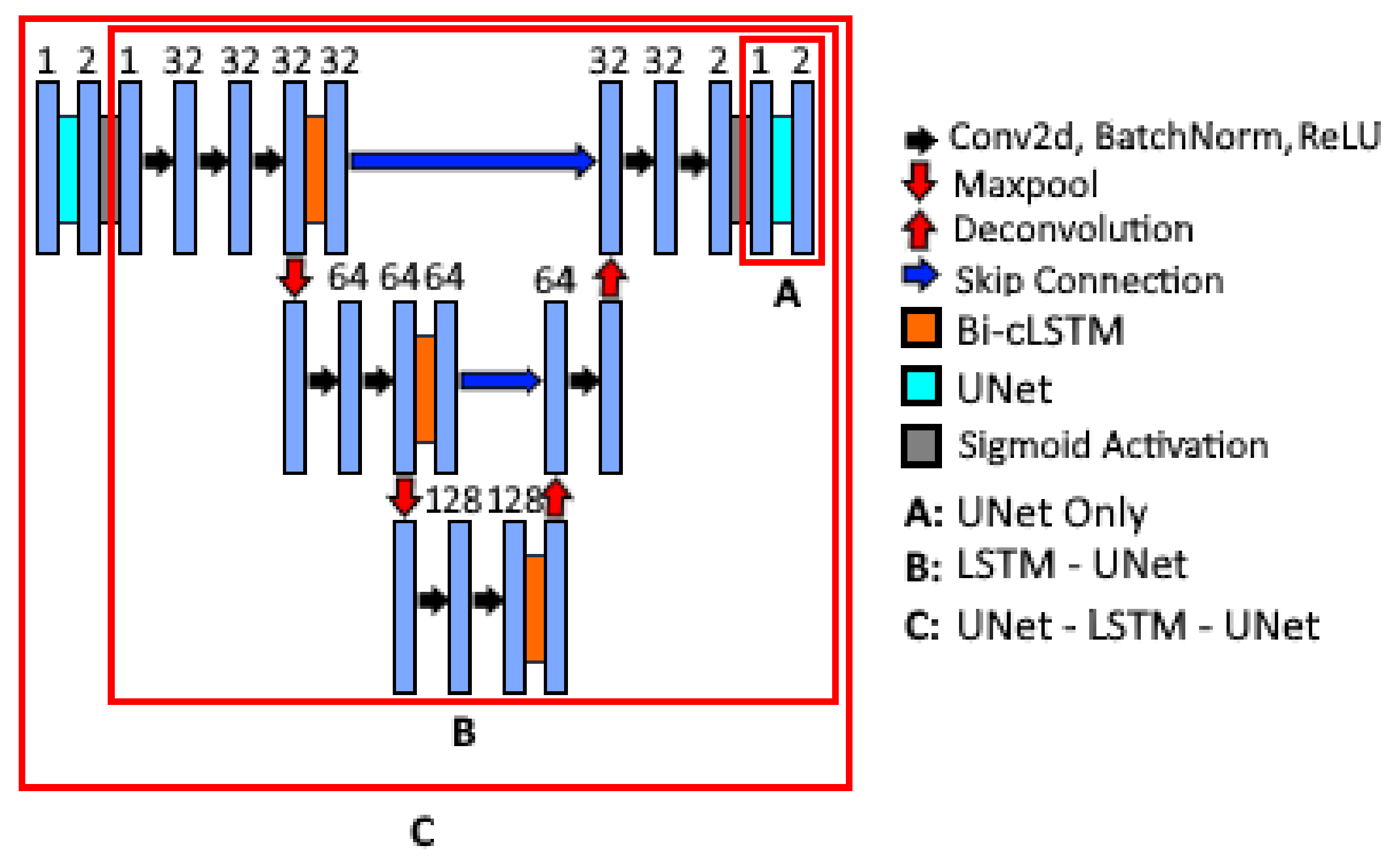
2.2. Nested Model Architectures
2.3. Model Training and Performance Evaluation
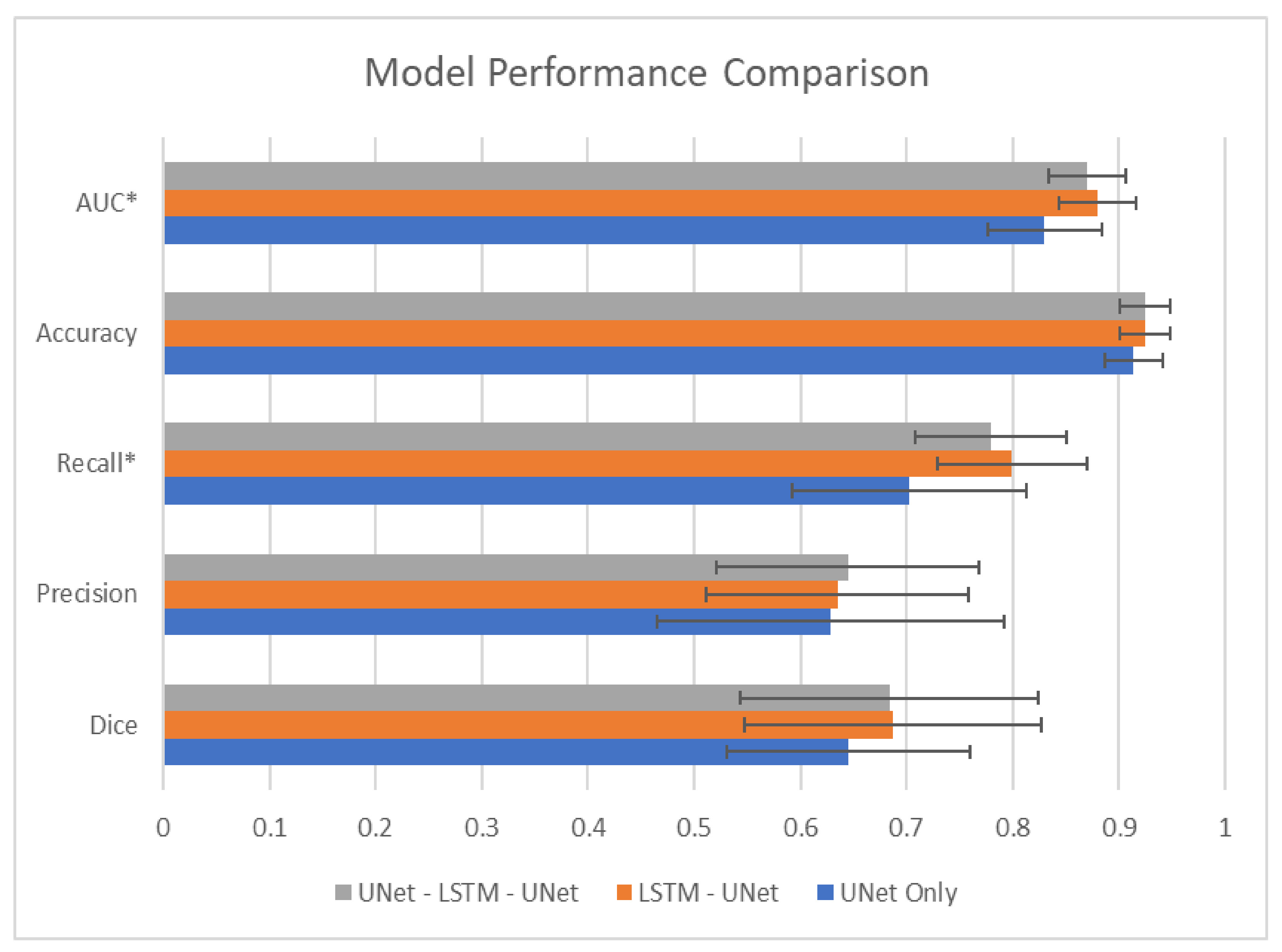
3. Results
4. Discussion
5. Conclusions
6. Disclaimer
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nadler, Z.; Wang, B.; Wollstein, G.; Nevins, J.E.; Ishikawa, H.; Bilonick, R.; Kagemann, L.; Sigal, I.A.; Ferguson, R.D.; Patel, A.; et al. Repeatability of in vivo 3D lamina cribrosa microarchitecture using adaptive optics spectral domain optical coherence tomography. Biomed. Opt. Express 2014, 5, 1114–1123. [Google Scholar] [CrossRef] [Green Version]
- Akagi, T.; Hangai, M.; Takayama, K.; Nonaka, A.; Ooto, S.; Yoshimura, N. In Vivo Imaging of Lamina Cribrosa Pores by Adaptive Optics Scanning Laser Ophthalmoscopy. Investig. Opthalmol. Vis. Sci. 2012, 53, 4111–4119. [Google Scholar] [CrossRef] [PubMed]
- Hood, N.C.; Lee, N.; Jarukasetphon, R.; Nunez, J.; Mavrommatis, M.A.; Rosen, R.B.; Ritch, R.; Dubra, A.; Chui, T.Y.P. Progression of Local Glaucomatous Damage Near Fixation as Seen with Adaptive Optics Imaging. Transl. Vis. Sci. Technol. 2017, 6, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Takayama, K.; Ooto, S.; Hangai, M.; Ueda-Arakawa, N.; Yoshida, S.; Akagi, T.; Ikeda, H.; Nonaka, A.; Hanebuchi, M.; Inoue, T.; et al. High-Resolution Imaging of Retinal Nerve Fiber Bundles in Glaucoma Using Adaptive Optics Scanning Laser Ophthalmoscopy. Am. J. Ophthalmol. 2013, 155, 870–881.e3. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, M.F.; Chui, T.Y.P.; Alhadeff, P.; Rosen, R.B.; Ritch, R.; Dubra, A.; Hood, D.C. Adaptive Optics Imaging of Healthy and Abnormal Regions of Retinal Nerve Fiber Bundles of Patients with Glaucoma. Investig. Opthalmol. Vis. Sci. 2015, 56, 674–681. [Google Scholar] [CrossRef]
- Huang, G.; Luo, T.; Gast, T.J.; Burns, S.A.; Malinovsky, V.E.; Swanson, W.H. Imaging Glaucomatous Damage Across the Temporal Raphe. Investig. Opthalmol. Vis. Sci. 2015, 56, 3496–3504. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Kurokawa, K.; Zhang, F.; Lee, J.J.; Miller, D.T. Imaging and quantifying ganglion cells and other transparent neurons in the living human retina. Proc. Natl. Acad. Sci. USA 2017, 114, 12803–12808. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, Z.; Saeedi, O.; Zhang, F.; Villanueva, R.; Asanad, S.; Agrawal, A.; Hammer, D.X. Quantification of Retinal Ganglion Cell Morphology in Human Glaucomatous Eyes. Investig. Opthalmol. Vis. Sci. 2021, 62, 34. [Google Scholar] [CrossRef] [PubMed]
- Soltanian-Zadeh, S.; Kurokawa, K.; Liu, Z.; Zhang, F.; Saeedi, O.; Hammer, D.X.; Miller, D.T.; Farsiu, S. Weakly supervised individual ganglion cell segmentation from adaptive optics OCT images for glaucomatous damage assessment. Optica 2021, 8, 642. [Google Scholar] [CrossRef]
- Miller, D.T.; Kurokawa, K. Cellular-Scale Imaging of Transparent Retinal Structures and Processes Using Adaptive Optics Optical Coherence Tomography. Annu. Rev. Vis. Sci. 2020, 6, 115–148. [Google Scholar] [CrossRef]
- Kurokawa, K.; Crowell, J.A.; Zhang, F.; Miller, D.T. Suite of methods for assessing inner retinal temporal dynamics across spatial and temporal scales in the living human eye. Neurophotonics 2020, 7, 015013. [Google Scholar] [CrossRef] [Green Version]
- Karst, S.G.; Salas, M.; Hafner, J.; Scholda, C.; Vogl, W.-D.; Drexler, W.; Pircher, M.; Schmidt-Erfurth, U. Three-dimensional analysis of retinal microaneurysms with adaptive optics optical coherence tomography. Retina 2019, 39, 465–472. [Google Scholar] [CrossRef]
- Iwasaki, M.; Inomata, H. Relation between superficial capillaries and foveal structures in the human retina. Investig. Ophthalmol. Vis. Sci. 1986, 27, 1698–1705. [Google Scholar]
- Felberer, F.; Rechenmacher, M.; Haindl, R.; Baumann, B.; Hitzenberger, C.; Pircher, M. Imaging of retinal vasculature using adaptive optics SLO/OCT. Biomed. Opt. Express 2015, 6, 1407–1418. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Detailed Vascular Anatomy of the Human Retina by Projection-Resolved Optical Coherence Tomography Angiography Scientific Reports. Available online: https://www.nature.com/articles/srep42201 (accessed on 15 June 2021).
- Spaide, R.F.; Klancnik, J.M.; Cooney, M.J. Retinal Vascular Layers Imaged by Fluorescein Angiography and Optical Coherence Tomography Angiography. JAMA Ophthalmol. 2015, 133, 45–50. [Google Scholar] [CrossRef] [PubMed]
- Jones, A.; Kaplowitz, K.; Saeedi, O. Autoregulation of optic nerve head blood flow and its role in open-angle glaucoma. Expert Rev. Ophthalmol. 2014, 9, 487–501. [Google Scholar] [CrossRef]
- Tham, Y.-C.; Li, X.; Wong, T.Y.; Quigley, H.A.; Aung, T.; Cheng, C.-Y. Global Prevalence of Glaucoma and Projections of Glaucoma Burden through 2040. Ophthalmology 2014, 121, 2081–2090. [Google Scholar] [CrossRef]
- Leske, M.C.; Heijl, A.; Hussein, M.; Bengtsson, B.; Hyman, L.; Komaroff, E. Factors for Glaucoma Progression and the Effect of Treatment. Arch. Ophthalmol. 2003, 121, 48–56. [Google Scholar] [CrossRef]
- Weinreb, R.N.; Aung, T.; Medeiros, F.A. The Pathophysiology and Treatment of Glaucoma. JAMA 2014, 311, 1901–1911. [Google Scholar] [CrossRef] [Green Version]
- Richter, G.M.; Madi, I.; Chu, Z.; Burkemper, B.; Chang, R.; Zaman, A.; Sylvester, B.; Reznik, A.; Kashani, A.; Wang, R.; et al. Structural and Functional Associations of Macular Microcirculation in the Ganglion Cell-Inner Plexiform Layer in Glaucoma Using Optical Coherence Tomography Angiography. J. Glaucoma 2018, 27, 281–290. [Google Scholar] [CrossRef]
- Villanueva, R.; Le, C.; Liu, Z.; Zhang, F.; Magder, L.; Hammer, D.X.; Saeedi, O. Cell-Vessel Mismatch in Glaucoma: Correlation of Ganglion Cell Layer Soma and Capillary Densities. Investig. Ophthalmol. Vis. Sci. 2021, 62, 2. [Google Scholar] [CrossRef] [PubMed]
- Guo, C.; Szemenyei, M.; Hu, Y.; Wang, W.; Zhou, W.; Yi, Y. Channel Attention Residual U-Net for Retinal Vessel Segmentation. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Cananda, 6–11 June 2021; pp. 1185–1189. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, Y.; Xu, X. Pyramid U-Net for Retinal Vessel Segmentation. arXiv 2021, arXiv:2104.02333, 1125–1129. [Google Scholar] [CrossRef]
- Içek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; Available online: http://arxiv.org/abs/1606.06650 (accessed on 25 July 2021).
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Seg-mentation. 2016 Fourth International Conference on 3d Vision (3dv), Stanford, CA, USA, 25–28 October 2016; Available online: http://arxiv.org/abs/1606.04797 (accessed on 25 July 2021).
- Demirkaya, N.; Van Dijk, H.W.; Van Schuppen, S.M.; Abramoff, M.; Garvin, M.K.; Sonka, M.; Schlingemann, R.O.; Verbraak, F.D. Effect of Age on Individual Retinal Layer Thickness in Normal Eyes as Measured with Spectral-Domain Optical Coherence Tomography. Investig. Opthalmol. Vis. Sci. 2013, 54, 4934–4940. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.H.; Lee, S.H.; Han, J.Y.; Kang, H.G.; Byeon, S.H.; Kim, S.S.; Koh, H.J.; Kim, M. Comparison of Individual Retinal Layer Thicknesses between Highly Myopic Eyes and Normal Control Eyes Using Retinal Layer Segmentation Analysis. Sci. Rep. 2019, 9, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Wilson, M.; Chopra, R.; Wilson, M.Z.; Cooper, C.; MacWilliams, P.; Liu, Y.; Wulczyn, E.; Florea, D.; Hughes, C.O.; Karthikesalingam, A.; et al. Validation and Clinical Applicability of Whole-Volume Automated Segmentation of Optical Coherence Tomography in Retinal Disease Using Deep Learning. JAMA Ophthalmol. 2021, 139, 964. [Google Scholar] [CrossRef]
- Liu, Z.; Tam, J.; Saeedi, O.; Hammer, D.X. Trans-retinal cellular imaging with multimodal adaptive optics. Biomed. Opt. Express 2018, 9, 4246–4262. [Google Scholar] [CrossRef]
- NIH Image to ImageJ: 25 years of image analysis|Nature Methods. Available online: https://www.nature.com/articles/nmeth.2089 (accessed on 15 June 2021).
- Wang, D.; Haytham, A.; Pottenburgh, J.; Saeedi, O.; Tao, Y. Hard Attention Net for Automatic Retinal Vessel Segmentation. EEE J. Biomed. Health Inform. 2020, 24, 3384–3396. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.; Woo, W. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. Processing of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; Available online: https://papers.nips.cc/paper/2015/hash/07563a3fe3bbe7e3ba84431ad9d055af-Abstract.html (accessed on 15 June 2021).
- Liu, Q.; Zhou, F.; Hang, R.; Yuan, X. Bidirectional-Convolutional LSTM Based Spectral-Spatial Feature Learning for Hyperspectral Image Classification. Remote Sens. 2017, 9, 1330. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Shen, X.; Shang, F.; Ge, F.; Wang, F. CU-Net: Cascaded U-Net with Loss Weighted Sampling for Brain Tumor Segmentation; Springer: Berlin, Germany, 2019; pp. 102–111. [Google Scholar] [CrossRef] [Green Version]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1026–1034. [Google Scholar] [CrossRef] [Green Version]
- Zou, K.H.; Warfield, S.; Bharatha, A.; Tempany, C.M.; Kaus, M.R.; Haker, S.J.; Wells, W.M.; Jolesz, F.A.; Kikinis, R. Statistical validation of image segmentation quality based on a spatial overlap index1: Scientific reports. Acad. Radiol. 2004, 11, 178–189. [Google Scholar] [CrossRef] [Green Version]
- Zou, K.H.; Wells, W.M.; Kikinis, R.; Warfield, S.K. Three validation metrics for automated probabilistic image segmentation of brain tumours. Stat. Med. 2004, 23, 1259–1282. [Google Scholar] [CrossRef]
- Al-Faris, A.Q.; Ngah, U.K.; Isa, N.A.M.; Shuaib, I.L. MRI Breast Skin-line Segmentation and Removal using Integration Method of Level Set Active Contour and Morphological Thinning Algorithms. J. Med. Sci. 2012, 12, 286–291. [Google Scholar] [CrossRef] [Green Version]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Processing of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; Available online: http://arxiv.org/abs/1912.01703 (accessed on 15 June 2021).
- Li, M.; Chen, Y.; Ji, Z.; Xie, K.; Yuan, S.; Chen, Q.; Li, S. Image Projection Network: 3D to 2D Image Segmentation in OCTA Images. IEEE Trans. Med. Imag. 2020, 39, 3343–3354. [Google Scholar] [CrossRef]
- Li, M.; Zhang, Y.; Ji, Z.; Xie, K.; Yuan, S.; Liu, Q.; Chen, Q. IPN-V2 and OCTA-500: Methodology and Dataset for Retinal Image Segmentation. arXiv Prepr. 2020, arXiv:2012.07261. [Google Scholar]
- De Carlo, T.E.; Romano, A.; Waheed, N.K.; Duker, J.S. A review of optical coherence tomography angiography (OCTA). Int. J. Retin. Vitr. 2015, 1, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Lee, K.; Sunwoo, L.; Kim, T.; Lee, K. Spider U-Net: Incorporating Inter-Slice Connectivity Using LSTM for 3D Blood Vessel Segmentation. Appl. Sci. 2021, 11, 2014. [Google Scholar] [CrossRef]
- Ma, Y.; Hao, H.; Xie, J.; Fu, H.; Zhang, J.; Yang, J.; Wang, Z.; Liu, J.; Zheng, Y.; Zhao, Y. ROSE: A Retinal OCT-Angiography Vessel Segmentation Dataset and New Model. IEEE Trans. Med. Imag. 2020, 40, 928–939. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Volumes | |||||
|---|---|---|---|---|---|
| Train | Validation | Testing | Total Volumes | Mean ± Standard Deviation # Slices per Volume (range) | |
| Superficial Vascular Plexus | 43 | 13 | 13 | 69 | 34 ± 20 (range: 5–76) |
| Intermediate Capillary Plexus | 40 | 13 | 13 | 66 | 32 ±10 (range: 14–57) |
| Deep Capillary Plexus | 26 | 8 | 8 | 42 | 33 ± 11 (range: 12–60) |
| Total Volumes | 109 | 34 | 34 | 177 | 33 ± 15 (range: 5–76) |
| Mean ± Standard Deviation # Slices per Volume (range) | 33 ± 15 (range: 5–76) | 32 ± 13 (range: 10–71) | 31 ± 15 (range: 5–60) | 33 ± 15 (range: 5–76) | |
| Model | Dice Coefficient | Precision | Recall * | Accuracy | AUC * |
|---|---|---|---|---|---|
| UNet Only | 0.645 (0.114) | 0.629 (0.161) | 0.703 (0.109) | 0.914 (0.027) | 0.830 (0.053) |
| LSTM-UNet | 0.687 (0.140) | 0.635 (0.122) | 0.799 (0.070) | 0.924 (0.023) | 0.880 (0.036) |
| UNet-LSTM-UNet | 0.684 (0.141) | 0.645 (0.127) | 0.779 (0.072) | 0.924 (0.024) | 0.870 (0.036) |
| Model | # of Parameters (Million) | Evaluation Time on 30 Slice Image (Seconds) |
|---|---|---|
| UNet Only | 0.52 | 1.56 |
| LSTM-UNet | 1.82 | 184.79 |
| UNet-LSTM-UNet | 2.34 | 241.692 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Le, C.T.; Wang, D.; Villanueva, R.; Liu, Z.; Hammer, D.X.; Tao, Y.; Saeedi, O.J. Novel Application of Long Short-Term Memory Network for 3D to 2D Retinal Vessel Segmentation in Adaptive Optics—Optical Coherence Tomography Volumes. Appl. Sci. 2021, 11, 9475. https://doi.org/10.3390/app11209475
Le CT, Wang D, Villanueva R, Liu Z, Hammer DX, Tao Y, Saeedi OJ. Novel Application of Long Short-Term Memory Network for 3D to 2D Retinal Vessel Segmentation in Adaptive Optics—Optical Coherence Tomography Volumes. Applied Sciences. 2021; 11(20):9475. https://doi.org/10.3390/app11209475
Chicago/Turabian StyleLe, Christopher T., Dongyi Wang, Ricardo Villanueva, Zhuolin Liu, Daniel X. Hammer, Yang Tao, and Osamah J. Saeedi. 2021. "Novel Application of Long Short-Term Memory Network for 3D to 2D Retinal Vessel Segmentation in Adaptive Optics—Optical Coherence Tomography Volumes" Applied Sciences 11, no. 20: 9475. https://doi.org/10.3390/app11209475
APA StyleLe, C. T., Wang, D., Villanueva, R., Liu, Z., Hammer, D. X., Tao, Y., & Saeedi, O. J. (2021). Novel Application of Long Short-Term Memory Network for 3D to 2D Retinal Vessel Segmentation in Adaptive Optics—Optical Coherence Tomography Volumes. Applied Sciences, 11(20), 9475. https://doi.org/10.3390/app11209475