
Contributions of Machine Learning Models towards Student Academic Performance Prediction: A Systematic Review




Abstract
:1. Introduction
2. Review Methodology
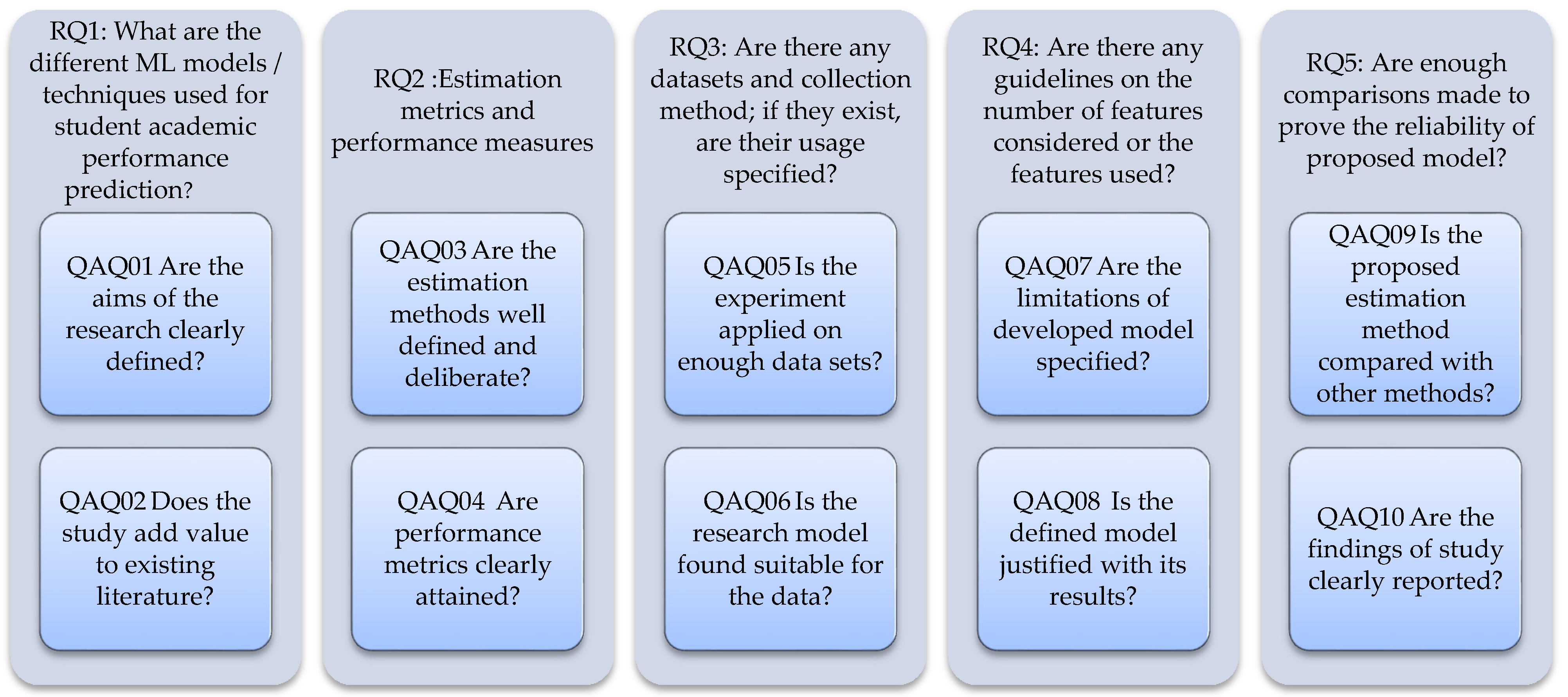
2.1. Research Question (RQ) Identification
2.2. Search Strategy
2.2.1. Search Strategy Design
2.2.2. Selection Criteria
- Using ML to analyze the academic performance;
- Using ML to preprocess the modeling data;
- Comparative assessment of various ML methods and their results obtained;
- Journal versions—for duplicate articles, the recently published article is considered;
- Articles including online education assessment;
- Academic performance and recommendation systems.
- Review articles;
- Book chapters;
- Factor analysis;
- Articles not written in the English language.
2.3. Study Quality Assessment
3. Results and Discussions
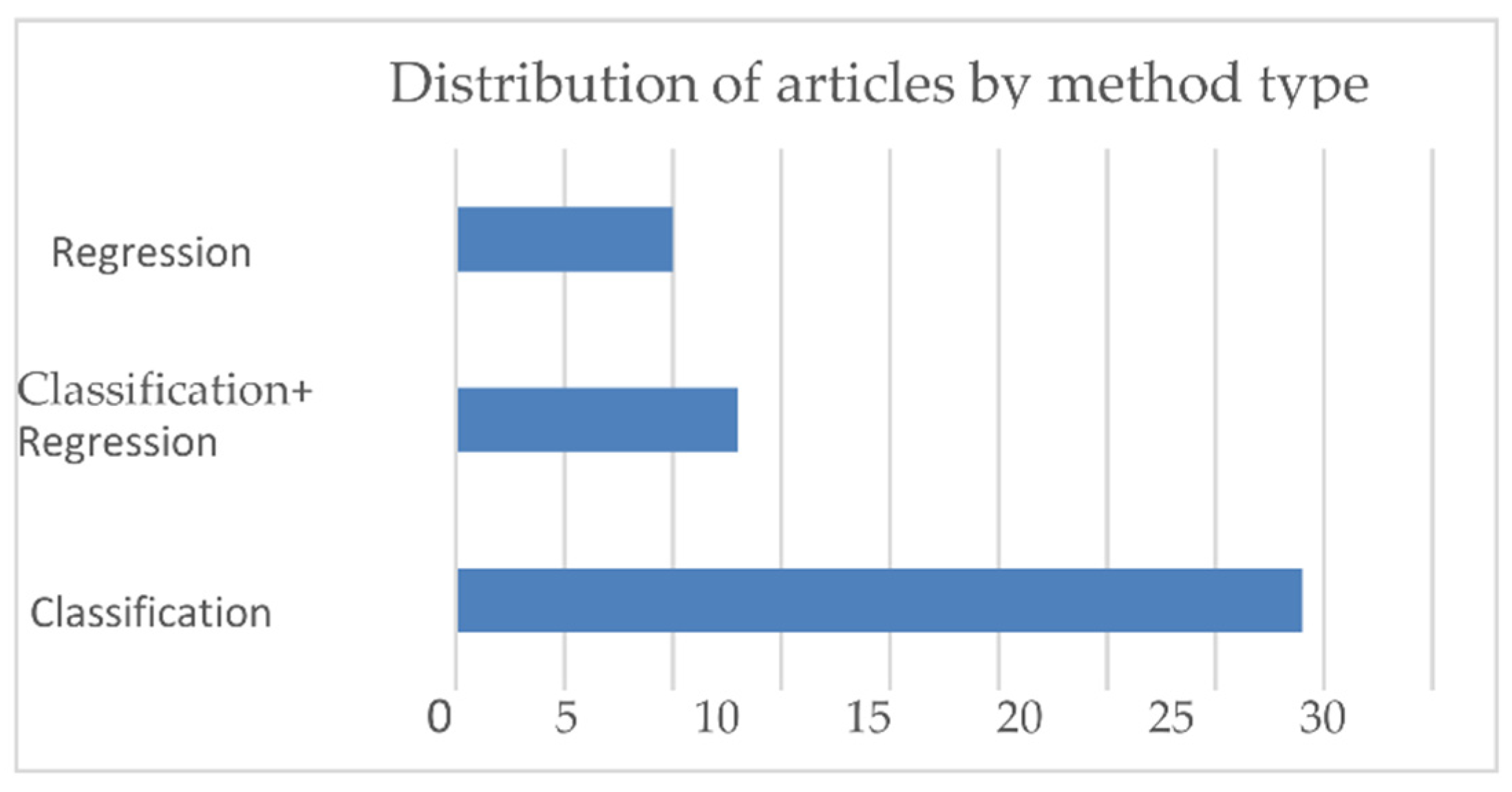
3.1. Overview of the Selected Studies
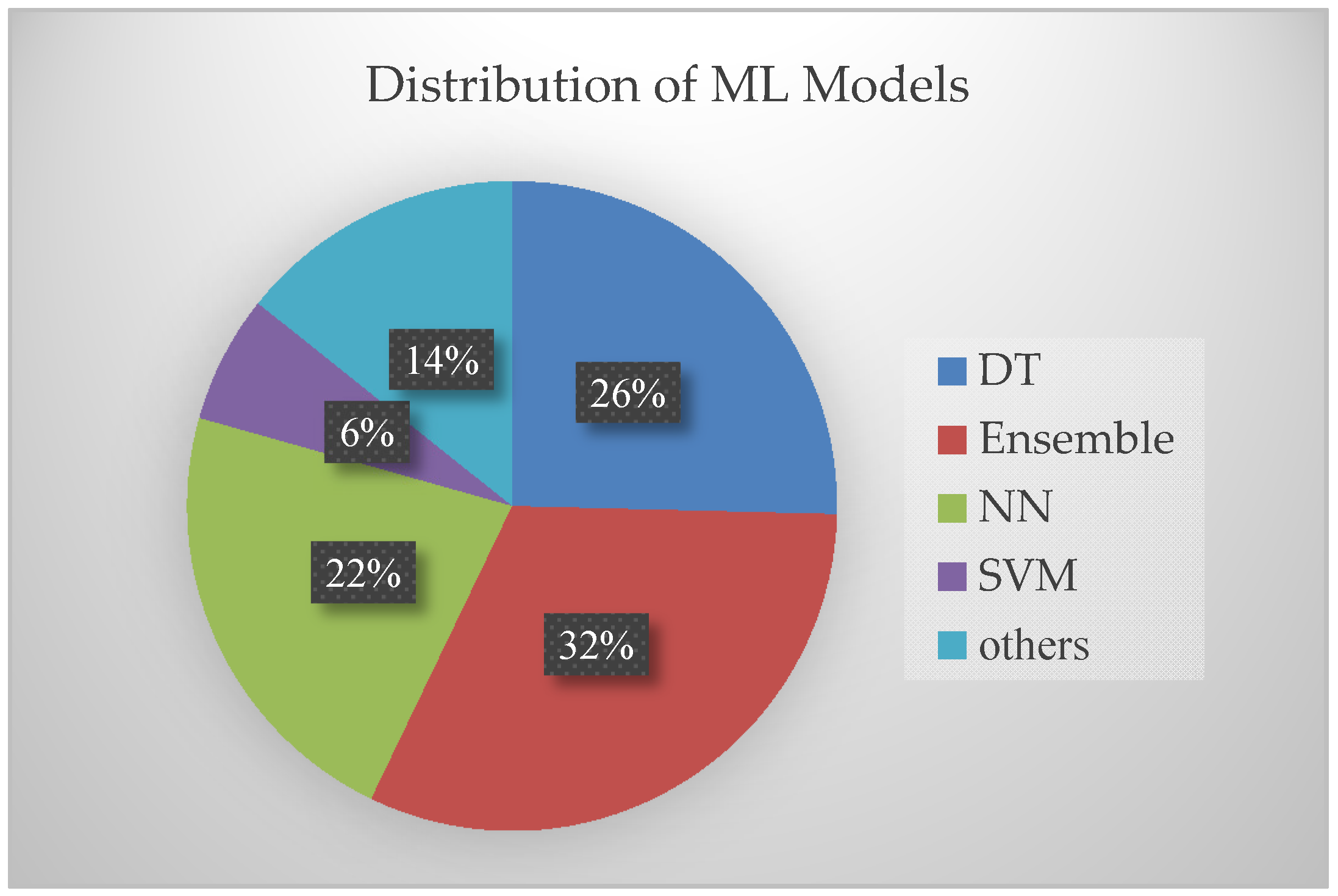
3.2. Models and Metrics Used
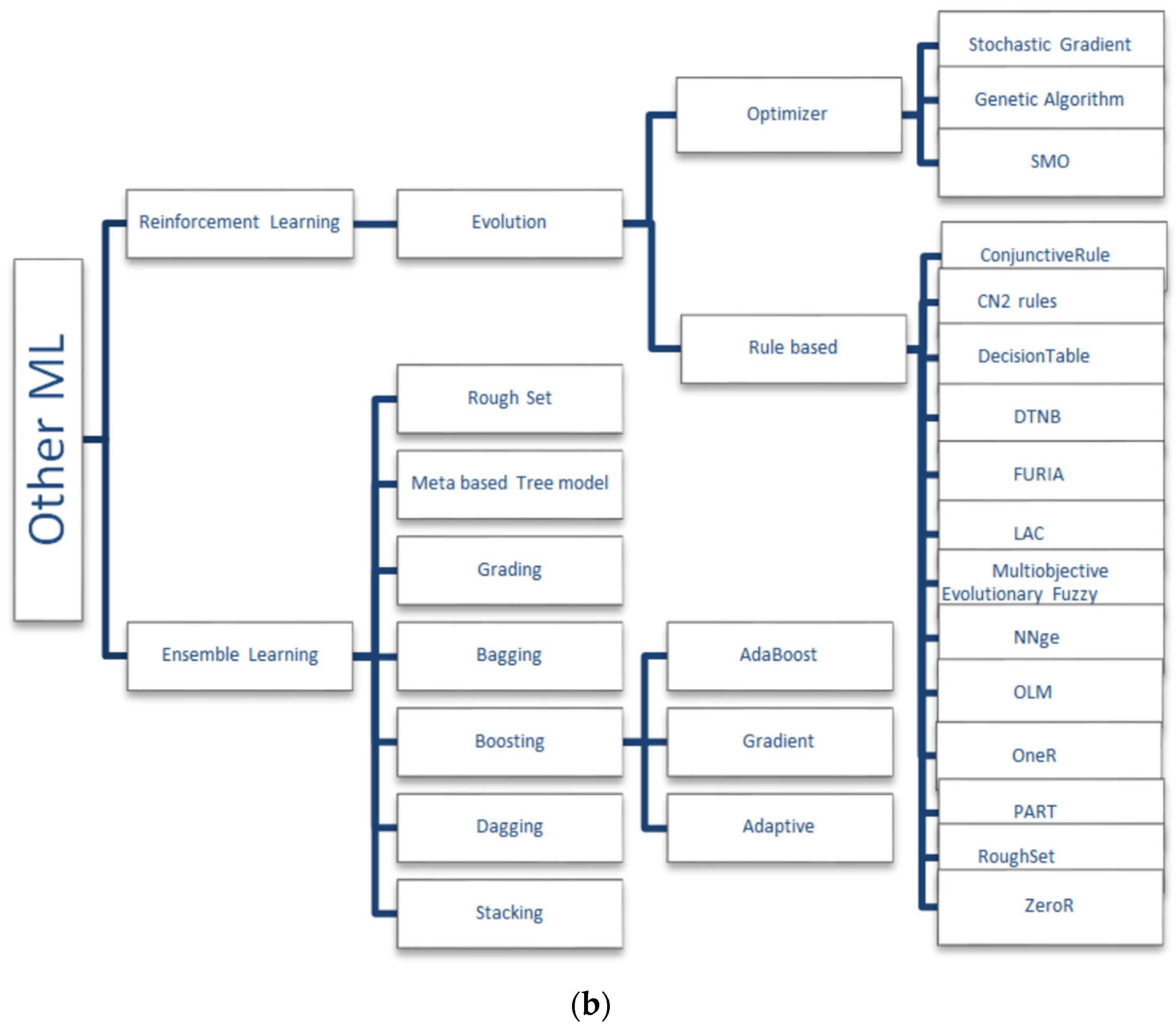
3.2.1. Supervised Learning Algorithms
3.2.2. Unsupervised Learning Algorithms
3.3. Dataset Preparation and Utilization
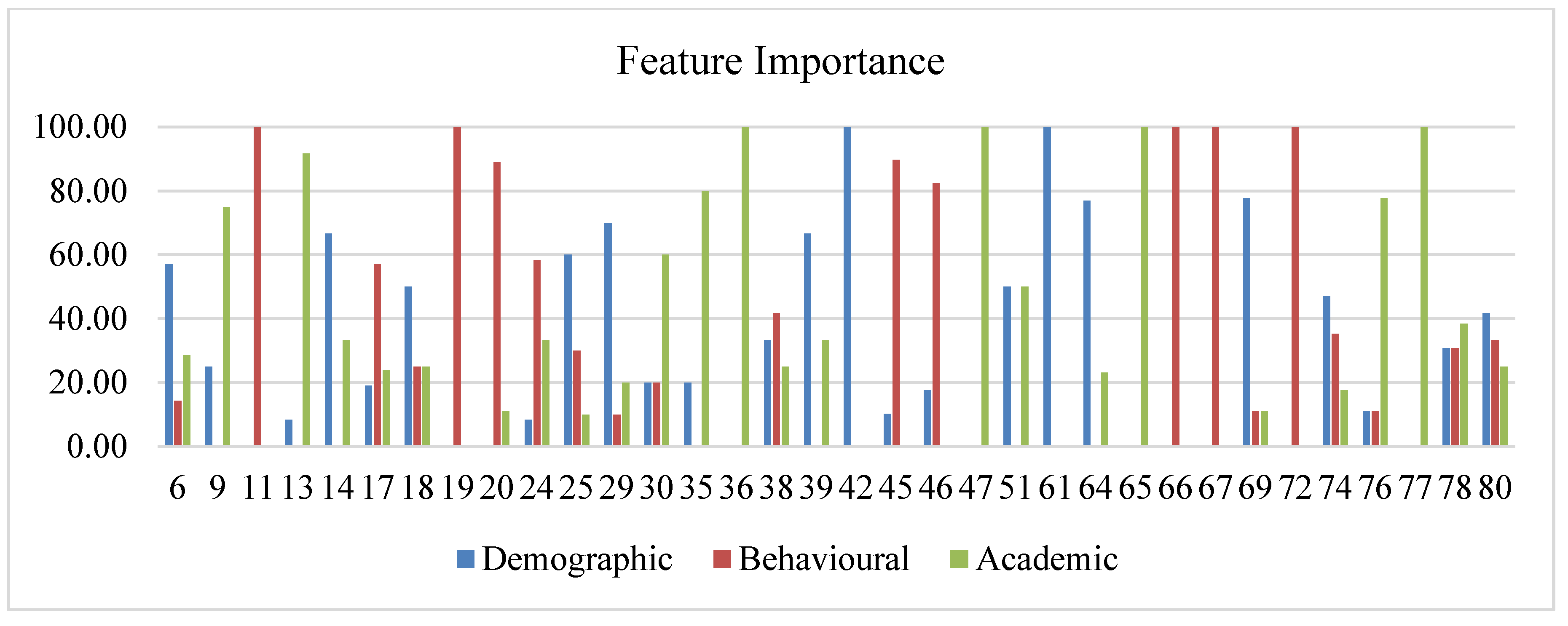
3.4. Feature Description and Usage
4. Conclusions
- DT and ensemble learning models have been employed in several selected articles, wherein NNs or transfer learning with appropriate layers can be adopted to make an unbiased decision on the model suitable for the collected data.
- Most articles focused only on a specific aspect of accuracy, and it seems to be a biased one. Indeed, the performance measures can be chosen from a wide variety of available measures suitable for the problem of study as classification or regression.
- The amount of data collected for the dataset can be computed in a high quantity and of a cohort nature of a specific set of students to analyze their change in behavioral features and demographic features that influences their academic feature study.
- Behavioral features were taken in a large quantity, which could be equated to the other two categories of features as academic and demographic features. In the online mode of study, the demographic feature does not have much impact on the academic features, whereas during offline modes of study, three types of features contribute equally to the performance of the student, which, in turn, leads us to decide the dropout percentage.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Models Used | Accuracy | AUC | Recall | Precision | F1 | Dataset Used | Quality Score |
|---|---|---|---|---|---|---|---|---|
| [11] | Random forest | 77.29 | NS | 75.6 | 75.6 | 75.6 | xAPI-Edu-Data | 9 |
| [12] | Random forest | 86 | 68 | 86 | 85 | 85 | Self-data from 3 different universities | 9 |
| [24] | Decision tree | 79 | NS | 75.1 | 70.3 | 72 | Webpage | 9 |
| [29] | Decision tree | 98.94 | 99.4 | 100 | 85.7 | 92 | Self-collected | 9 |
| [31] | Decision tree | 95.82 | NS | NS | NS | NS | UCI repository | 8 |
| [34] | Decision tree | 96.5 | NS | NS | 93 | NS | Collected data | 9 |
| [44] | Decision tree | 75 | NS | NS | NS | NS | Self-data | 8 |
| [46] | Decision tree | 98.5 | 92.1 | 97.3 | 94 | 95.6 | University of Stanford | 9 |
| [54] | Genetic algorithm-based decision tree | 94.39 | NS | NS | NS | NS | Federal Board of Pakistan | 8 |
| [55] | Random forest | 79.8 | 93.8 | 79.8 | 78.8 | 79 | University of Nigeria | 7 |
| [58] | Random forest | NS | 93 | NS | NS | NS | Self-data | 9 |
| [59] | Multiple linear regression | 90 | NS | 90 | 89 | 89 | Kaggle | 7 |
| [60] | Decision tree | 87.21 | NS | 93.65 | 89.39 | NS | University of Phayao | 9 |
| [62] | Random forest | 70.1 | NS | NS | NS | NS | University of Li’ege (Belgium) | 9 |
| [64] | Decision tree | 94.63 | NS | 95.76 | 98.33 | 71.9 | Open University of China | 10 |
| [79] | Decision tree | 67.71 | NS | NS | NS | NS | NEDUET, Pakistan | 9 |
| Ref. | Models Used | Accuracy | Sensitivity | Specificity | AUC | Recall | Precision | F1 | Dataset Used | Quality Score |
|---|---|---|---|---|---|---|---|---|---|---|
| [7] | Ensemble (J48, real AdaBoost) | 95.78 | NS | NS | NS | 0.958 | 0.958 | 0.96 | UCI Student Performance | 8 |
| [15] | Ensemble (reptree bagging) | 97.5 | NS | NS | NS | 96.3 | 96.4 | 96.2 | Self-data | 8 |
| [27] | Ensemble [DT, boosting] | 96.96 | NS | NS | NS | 95.97 | 94.97 | 95.5 | Self-data | 8 |
| [32] | Ensemble [NN, RF-boosting] | NS | NS | NS | NS | NS | NS | NS | NS | 6 |
| [43] | Ensemble [NB + AdaBoost] | 98.12 | 96 | 100 | NS | NS | NS | 98 | Directorate of Higher Secondary Education | 7 |
| [44] | Ensemble [DT-XGBoost] | NS | NS | NS | NS | 92.5 | 89 | 89 | OULAD | 8 |
| [47] | Ensemble [DT, SMO] | 90.13 | NS | NS | NS | NS | NS | NS | Microsoft showcase school “Avgoulea-Linardatou” | 9 |
| [57] | SVM-boosting | 90.6 | NS | NS | NS | NS | 97 | NS | North Carolina | 5 |
| [61] | [DT, ANN, SVM] Stacking ensemble | NS | NS | NS | 77.7 | 74.52 | NS | 76.1 | Self-data | 10 |
| [63] | Ensemble learning [random forest (RF) and adaptive boosting (AdaBoost)] | 98 | NS | NS | NS | 91 | 69 | 78 | Self-data | 7 |
| [66] | RF, KNN, and adaptive boosting | 70 | NS | NS | NS | 70 | 70 | 79 | University of León | 9 |
| [74] | Ensemble [RF, boosting] | 98.22 | NS | NS | NS | NS | NS | NS | Self-data | 10 |
| [76] | Hybrid linear vector quantization (LVQ + AdaBoost) | 92.6 | NS | NS | NS | 95.6 | 91 | 92.3 | NS | 8 |
| [78] | Ensemble (DT + K means clustering) | 75.47 | NS | NS | NS | 72.2 | 47.27 | 57.1 | NS | 8 |
| [80] | Ensemble learning (SVM, RF, AdaBoost + logistic regression via stacking) | NS | NS | NS | 91.9 | 86 | 85.5 | 85 | Hankou University | 10 |
| Ref. | Models Used | Accuracy | Sensitivity | Specificity | AUC | Recall | Precision | F1 | Dataset Used | Quality Score |
|---|---|---|---|---|---|---|---|---|---|---|
| [16] | NB, MLP, SMO, C4.5, JRip, kNN | 85.43 | NS | 82.61 | NS | 97.48 | NS | 84.3 | Self-data | 10 |
| [17] | MLP-BP(ANN) | 100 | NS | NS | 100 | 100 | 100 | 100 | Self-data | 10 |
| [22] | CNN | 99.4 | NS | NS | 88.7 | 77.26 | 97 | 86 | US K12 schools | 8 |
| [26] | Improved deep belief network | 83.14 | NS | NS | NS | NS | ADS, GT4M | 10 | ||
| [35] | NN | 51.9 | NS | NS | 63.5 | 51.9 | 48.6 | 49.4 | Self-data | 10 |
| [37] | NN | 96 | NS | NS | NS | 92 | 96 | 89.2 | NS | 6 |
| [39] | MLP(ANN) | 94.8 | NS | NS | NS | 94.8 | 94.2 | NS | STIKOM Poltek Cirebon | 10 |
| [45] | ANN | 88.48 | NS | NS | NS | 69 | 93 | NS | OULA | 9 |
| [56] | BPNN | 84.8 | 94.8 | 54.6 | NS | NS | 86.3 | NS | Self-data | 6 |
| [65] | MLR, MLP, RBF, SVM | 89.9 | NS | NS | NS | NS | NS | NS | NS | 9 |
| [67] | NN | 96 | NS | NS | NS | NS | NS | NS | University of Tartu in Estonia | 10 |
| [69] | NN—Levenberg–Marquardt learning algorithm | 83.7 | 77.37 | 85.16 | NS | NS | NS | NS | Self-data | 10 |
| [72] | RBF | 76.92 | 100 | 60 | NS | NS | NS | NS | NS | 8 |
| [77] | kNN | 86 | 89 | 84 | NS | NS | NS | 81 | Self-data | 9 |
| Ref. | Models Used | Accuracy | Sensitivity | Specificity | AUC | Recall | Precision | F1 | Dataset Used | Quality Score |
|---|---|---|---|---|---|---|---|---|---|---|
| [3] | Adversarial network based deep support vector machine | 0.954 | 0.971 | 0.968 | NS | NS | NS | NS | Self-data | 8 |
| [10] | Multiple linear regression model | NS | NS | NS | NS | NS | NS | NS | Covenant University in Nigeria | 6 |
| [19] | LSTM | NS | NS | NS | 68.2 | NS | NS | NS | Canadian University | 10 |
| [20] | SVM | 70.21 | NS | NS | NS | NS | NS | NS | George Mason University | 10 |
| [25] | Decision tree, random Forest, support vector machine, logistic regression, AdaBoost, stochastic gradient descent | 96.65 | 93.75 | 93.75 | NS | NS | 99.6 | NS | UCI | 10 |
| [30] | Multiple regression algorithm | NS | NS | NS | NS | NS | NS | NS | Self-collected | 10 |
| [36] | Logistic regression | 89.15 | NS | NS | NS | NS | NS | NS | Covenant University | 9 |
| [40] | SVM | 76.67 | NS | NS | NS | NS | NS | NS | 5 | |
| [41] | Non-linear SVM | NS | NS | NS | 75 | 89 | 88 | 89 | OULAD | 7 |
| [51] | LR | 94.9 | NS | NS | NS | NS | NS | NS | Imam Abdulrahman bin Faisal University | 10 |
| [53] | Vector-based SVM | 93.8 | 94 | 93.6 | NS | NS | NS | NS | OULA | 7 |
| [75] | Transfer learning (deep learning) | NS | NS | NS | NS | NS | NS | NS | NS | 8 |
References
- Rebai, S.; Ben Yahia, F.; Essid, H. A graphically based machine learning approach to predict secondary schools performance in Tunisia. Socio-Econ. Plan. Sci. 2019, 70, 100724. [Google Scholar] [CrossRef]
- Tatiana, A.C.; Cudney, E.A. Predicting Student Retention Using Support Vector Machines. Procedia Manuf. 2019, 39, 1827–1833. [Google Scholar] [CrossRef]
- Chui, K.T.; Liu, R.W.; Zhao, M.; De Pablos, P.O. Predicting Students’ Performance with School and Family Tutoring Using Generative Adversarial Network-Based Deep Support Vector Machine. IEEE Access 2020, 8, 86745–86752. [Google Scholar] [CrossRef]
- Fernandez-Garcia, A.J.; Rodriguez-Echeverria, R.; Preciado, J.C.; Manzano, J.M.C.; Sanchez-Figueroa, F. Creating a Recommender System to Support Higher Education Students in the Subject Enrollment Decision. IEEE Access 2020, 8, 189069–189088. [Google Scholar] [CrossRef]
- Xu, J.; Moon, K.H.; van der Schaar, M. A Machine Learning Approach for Tracking and Predicting Student Performance in Degree Programs. IEEE J. Sel. Top. Signal Process. 2017, 11, 742–753. [Google Scholar] [CrossRef]
- Song, X.; Li, J.; Sun, S.; Yin, H.; Dawson, P.; Doss, R.R.M. SEPN: A Sequential Engagement Based Academic Performance Prediction Model. IEEE Intell. Syst. 2020, 36, 46–53. [Google Scholar] [CrossRef]
- Imran, M.; Latif, S.; Mehmood, D.; Shah, M.S. Student Academic Performance Prediction using Supervised Learning Techniques. Int. J. Emerg. Technol. Learn. (iJET) 2019, 14, 92–104. [Google Scholar] [CrossRef] [Green Version]
- Rivera, J.E.H. A Hybrid Recommender System to Enrollment for Elective Subjects in Engineering Students using Classification Algorithms. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 400–406. [Google Scholar] [CrossRef]
- Cen, L.; Ruta, D.; Powell, L.; Hirsch, B.; Ng, J. Quantitative approach to collaborative learning: Performance prediction, individual assessment, and group composition. Int. J. Comput. -Supported Collab. Learn. 2016, 11, 187–225. [Google Scholar] [CrossRef]
- Adekitan, A.I.; Shobayo, O. Gender-based comparison of students’ academic performance using regression models. Eng. Appl. Sci. Res. 2020, 47, 241–248. [Google Scholar]
- Enaro, A.O.; Chakraborty, S. Feature Selection Algorithms for Predicting Students Academic Performance Using Data Mining Techniques. Int. J. Sci. Technol. Res. 2020, 9, 3622–3626. [Google Scholar]
- Huang, A.Y.Q.; Lu, O.H.T.; Huang, J.C.H.; Yin, C.J.; Yang, S.J.H. Predicting Students’ Academic Performance by Using Educational Big Data and Learning Analytics: Evaluation of Classification Methods and Learning Logs. Interact. Learn. Environ. 2020, 28, 206–230. [Google Scholar] [CrossRef]
- Xu, X.; Wang, J.; Peng, H.; Wu, R. Prediction of academic performance associated with internet usage behaviors using machine learning algorithms. Comput. Hum. Behav. 2019, 98, 166–173. [Google Scholar] [CrossRef]
- Livieris, I.E.; Drakopoulou, K.; Tampakas, V.T.; Mikropoulos, T.A.; Pintelas, P. Predicting Secondary School Students’ Performance Utilizing a Semi-supervised Learning Approach. J. Educ. Comput. Res. 2018, 57, 448–470. [Google Scholar] [CrossRef]
- Shanthini, A.; Vinodhini, G.; Chandrasekaran, R.M. Predicting Students’ Academic Performance in the University Using Meta Decision Tree Classifiers. J. Comput. Sci 2018, 14, 654–662. [Google Scholar] [CrossRef] [Green Version]
- Vialardi, C.; Chue, J.; Peche, J.; Alvarado, G.; Vinatea, B.; Estrella, J.; Ortigosa, Á. A data mining approach to guide students through the enrollment process based on academic performance. User Model User-Adap. Inter. 2011, 21, 217–248. [Google Scholar] [CrossRef] [Green Version]
- Musso, M.F.; Hernández, C.F.R.; Cascallar, E.C. Predicting key educational outcomes in academic trajectories: A machine-learning approach. High. Educ. 2020, 80, 875–894. [Google Scholar] [CrossRef] [Green Version]
- Lagman, A.C.; Alfonso, L.P.; Goh, M.L.I.; Lalata, J.-A.P.; Magcuyao, J.P.H.; Vicente, H.N. Classification Algorithm Accuracy Improvement for Student Graduation Prediction Using Ensemble Model. Int. J. Inf. Educ. Technol. 2020, 10, 723–727. [Google Scholar] [CrossRef]
- Chen, F.; Cui, Y. Utilizing Student Time Series Behaviour in Learning Management Systems for Early Prediction of Course Performance. J. Learn. Anal. 2020, 7, 1–17. [Google Scholar] [CrossRef]
- Damuluri, S.; Islam, K.; Ahmadi, P.; Qureshi, N.S. Analyzing Navigational Data and Predicting Student Grades Using Support Vector Machine. Emerg. Sci. J. 2020, 4, 243–252. [Google Scholar] [CrossRef]
- Kabakus, A.T.; Senturk, A. An analysis of the professional preferences and choices of computer engineering students. Comput. Appl. Eng. Educ. 2020, 28, 994–1006. [Google Scholar] [CrossRef]
- Yang, Z.; Yang, J.; Rice, K.; Hung, J.-L.; Du, X. Using Convolutional Neural Network to Recognize Learning Images for Early Warning of At-Risk Students. IEEE Trans. Learn. Technol. 2020, 13, 617–630. [Google Scholar] [CrossRef]
- Cruz-Jesus, F.; Castelli, M.; Oliveira, T.; Mendes, R.; Nunes, C.; Sa-Velho, M.; Rosa-Louro, A. Using artificial intelligence methods to assess academic achievement in public high schools of a European Union country. Heliyon 2020, 6, e04081. [Google Scholar] [CrossRef] [PubMed]
- Figueroa-Canas, J.; Sancho-Vinuesa, T. Early Prediction of Dropout and Final Exam Performance in an Online Statistics Course. IEEE Rev. Iberoam. De Tecnol. Del Aprendiz. 2020, 15, 86–94. [Google Scholar] [CrossRef]
- Razaque, A.; Alajlan, A. Supervised Machine Learning Model-Based Approach for Performance Prediction of Students. J. Comput. Sci. 2020, 16, 1150–1162. [Google Scholar] [CrossRef]
- Sokkhey, P.; Okazaki, T. Study on Dominant Factor for Academic Performance Prediction using Feature Selection Methods. Int. J. Adv. Comput. Sci. Appl. 2020, 11. [Google Scholar] [CrossRef]
- Almasri, A.; Alkhawaldeh, R.S.; Çelebi, E. Clustering-Based EMT Model for Predicting Student Performance. Arab. J. Sci. Eng. 2020, 45, 10067–10078. [Google Scholar] [CrossRef]
- Sethi, K.; Jaiswal, V.; Ansari, M. Machine Learning Based Support System for Students to Select Stream (Subject). Recent Adv. Comput. Sci. Commun. 2020, 13, 336–344. [Google Scholar] [CrossRef]
- Gil, J.S.; Delima, A.J.P.; Vilchez, R.N. Predicting Students’ Dropout Indicators in Public School using Data Mining Approaches. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9, 774–778. [Google Scholar] [CrossRef]
- Qazdar, A.; Er-Raha, B.; Cherkaoui, C.; Mammass, D. A machine learning algorithm framework for predicting students performance: A case study of baccalaureate students in Morocco. Educ. Inf. Technol. 2019, 24, 3577–3589. [Google Scholar] [CrossRef]
- Gamao, A.O.; Gerardo, B.D.; Medina, R.P. Prediction-Based Model for Student Dropouts using Modified Mutated Firefly Algorithm. Int. J. Adv. Trends Comput. Sci. Eng. 2019, 8, 3461–3469. [Google Scholar] [CrossRef]
- Susheelamma, H.K.; Ravikumar, K.M. Student risk identification learning model using machine learning approach. Int. J. Electr. Comput. Eng. 2019, 9, 3872–3879. [Google Scholar] [CrossRef]
- Kostopoulos, G.; Kotsiantis, S.; Fazakis, N.; Koutsonikos, G.; Pierrakeas, C. A Semi-Supervised Regression Algorithm for Grade Prediction of Students in Distance Learning Courses. Int. J. Artif. Intell. Tools 2019, 28. [Google Scholar] [CrossRef]
- Buenaño-Fernández, D.; Gil, D.; Luján-Mora, S. Application of Machine Learning in Predicting Performance for Computer Engineering Students: A Case Study. Sustainability 2019, 11, 2833. [Google Scholar] [CrossRef] [Green Version]
- Adekitan, A.I.; Noma-Osaghae, E. Data mining approach to predicting the performance of first year student in a university using the admission requirements. Educ. Inf. Technol. 2019, 24, 1527–1543. [Google Scholar] [CrossRef]
- Adekitan, A.I.; Salau, O. The impact of engineering students’ performance in the first three years on their graduation result using educational data mining. Heliyon 2019, 5, e01250. [Google Scholar] [CrossRef] [Green Version]
- Maitra, S.; Eshrak, S.; Bari, M.A.; Al-Sakin, A.; Munia, R.H.; Akter, N.; Haque, Z. Prediction of Academic Performance Applying NNs: A Focus on Statistical Feature-Shedding and Lifestyle. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 561–570. [Google Scholar] [CrossRef]
- Almasri, A.; Celebi, E.; Alkhawaldeh, R. EMT: Ensemble Meta-Based Tree Model for Predicting Student Performance. Sci. Program. 2019, 2019, 3610248. [Google Scholar] [CrossRef] [Green Version]
- Nurhayati, O.D.; Bachri, O.S.; Supriyanto, A.; Hasbullah, M. Graduation Prediction System Using Artificial Neural Network. Int. J. Mech. Eng. Technol. 2018, 9, 1051–1057. [Google Scholar]
- Aluko, R.O.; Daniel, E.I.; Oshodi, O.S.; Aigbavboa, C.O.; Abisuga, A.O. Towards reliable prediction of academic performance of architecture students using data mining techniques. J. Eng. Des. Technol. 2018, 16, 385–397. [Google Scholar] [CrossRef] [Green Version]
- Nadar, N.; Kamatchi, R. A Novel Student Risk Identification Model using Machine Learning Approach. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 305–309. [Google Scholar] [CrossRef]
- Kostopoulos, G.; Kotsiantis, S.; Pierrakeas, C.; Koutsonikos, G.; Gravvanis, G.A. Forecasting students’ success in an open university. Int. J. Learn. Technol. 2018, 13, 26–43. [Google Scholar] [CrossRef]
- Navamani, J.M.A.; Kannammal, A. Predicting performance of schools by applying data mining techniques on public examination results. Res. J. Appl. Sci. Eng. Technol. 2015, 9, 262–271. [Google Scholar] [CrossRef]
- Wakelam, E.; Jefferies, A.; Davey, N.; Sun, Y. The potential for student performance prediction in small cohorts with minimal available attributes. Br. J. Educ. Technol. 2019, 51, 347–370. [Google Scholar] [CrossRef] [Green Version]
- Waheed, H.; Hassan, S.U.; Aljohani, N.R.; Hardman, J.; Alelyani, S.; Nawaz, R. Predicting academic performance of students from VLE big data using deep learning models. Comput. Hum. Behav. 2020, 104, 106189. [Google Scholar] [CrossRef] [Green Version]
- Mourdi, Y.; Sadgal, M.; El Kabtane, H.; Fathi, W.B.; El Kabtane, H.; Youssef, M.; Mohamed, S.; Wafaa, B.F. A machine learning-based methodology to predict learners’ dropout, success or failure in MOOCs. Int. J. Web Inf. Syst. 2019, 15, 489–509. [Google Scholar] [CrossRef]
- Livieris, I.E.; Kotsilieris, T.; Tampakas, V.; Pintelas, P. Improving the evaluation process of students’ performance utilizing a decision support software. Neural Comput. Appl. 2018, 31, 1683–1694. [Google Scholar] [CrossRef]
- Son, L.H.; Fujita, H. Neural-fuzzy with representative sets for prediction of student performance. Appl. Intell. 2019, 49, 172–187. [Google Scholar] [CrossRef]
- Coussement, K.; Phan, M.; De Caigny, A.; Benoit, D.F.; Raes, A. Predicting student dropout in subscription-based online learning environments: The beneficial impact of the logit leaf model. Decis. Support Syst. 2020, 135, 113325. [Google Scholar] [CrossRef]
- Injadat, M.; Moubayed, A.; Nassif, A.B.; Shami, A. Systematic ensemble model selection approach for educational data mining. Knowl.-Based Syst. 2020, 200, 105992. [Google Scholar] [CrossRef]
- Tatar, A.E.; Düştegör, D. Prediction of Academic Performance at Undergraduate Graduation: Course Grades or Grade Point Average? Appl. Sci. 2020, 10, 4967. [Google Scholar] [CrossRef]
- Karthikeyan, V.G.; Thangaraj, P.; Karthik, S. Towards developing hybrid educational data mining model (HEDM) for efficient and accurate student performance evaluation. Soft Comput. 2020, 24, 18477–18487. [Google Scholar] [CrossRef]
- Chui, K.T.; Fung, D.C.L.; Lytras, M.D.; Lam, T.M. Predicting at-risk university students in a virtual learning environment via a machine learning algorithm. Comput. Hum. Behav. 2020, 107, 105584. [Google Scholar] [CrossRef]
- Yousafzai, B.K.; Hayat, M.; Afzal, S. Application of machine learning and data mining in predicting the performance of intermediate and secondary education level student. Educ. Inf. Technol. 2020, 25, 4677–4697. [Google Scholar] [CrossRef]
- Adekitan, A.I.; Salau, O. Toward an improved learning process: The relevance of ethnicity to data mining prediction of students’ performance. SN Appl. Sci. 2020, 2, 8. [Google Scholar] [CrossRef] [Green Version]
- Lau, E.T.; Sun, L.; Yang, Q. Modelling, prediction and classification of student academic performance using artificial neural networks. SN Appl. Sci. 2019, 1, 982. [Google Scholar] [CrossRef] [Green Version]
- Sorensen, L.C. “Big Data” in Educational Administration: An Application for Predicting School Dropout Risk. Educ. Adm. Q. 2019, 55, 404–446. [Google Scholar] [CrossRef]
- Alsuwaiket, M.; Blasi, A.H.; Al-Msie’deen, R.F. Formulating module assessment for improved academic performance predictability in higher education. arXiv 2020, arXiv:2008.13255. [Google Scholar]
- Suguna, R.; Shyamala Devi, M.; Bagate, R.A.; Joshi, A.S. Assessment of feature selection for student academic performance through machine learning classification. J. Stat. Manag. Syst. 2019, 22, 729–739. [Google Scholar] [CrossRef]
- Nuankaew, P. Dropout Situation of Business Computer Students, University of Phayao. Int. J. Emerg. Technol. Learn. 2019, 14, 115–131. [Google Scholar] [CrossRef] [Green Version]
- Adejo, O.W.; Connolly, T. Predicting student academic performance using multi-model heterogeneous ensemble approach. J. Appl. Res. High. Educ. 2018, 10, 61–75. [Google Scholar] [CrossRef]
- Hoffait, A.-S.; Schyns, M. Early detection of university students with potential difficulties. Decis. Support Syst. 2017, 101, 1–11. [Google Scholar] [CrossRef]
- Rovira, S.; Puertas, E.; Igual, L. Data-driven system to predict academic grades and dropout. PLoS ONE 2017, 12, 0171207. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tan, M.; Shao, P. Prediction of student dropout in e-Learning program through the use of machine learning method. Int. J. Emerg. Technol. Learn. 2015, 10, 11. [Google Scholar] [CrossRef]
- Huang, S.; Fang, N. Predicting student academic performance in an engineering dynamics course: A comparison of four types of predictive mathematical models. Comput. Educ. 2013, 61, 133–145. [Google Scholar] [CrossRef]
- Guerrero-Higueras, Á.M.; Fernández Llamas, C.; Sánchez González, L.; Gutierrez Fernández, A.; Esteban Costales, G.; González, M.Á.C. Academic Success Assessment through Version Control Systems. Appl. Sci. 2020, 10, 1492. [Google Scholar] [CrossRef] [Green Version]
- Hooshyar, D.; Pedaste, M.; Yang, Y. Mining Educational Data to Predict Students’ Performance through Procrastination Behavior. Entropy 2020, 22, 12. [Google Scholar] [CrossRef] [Green Version]
- Ezz, M.; Elshenawy, A. Adaptive recommendation system using machine learning algorithms for predicting student’s best academic program. Educ. Inf. Technol. 2019, 25, 2733–2746. [Google Scholar] [CrossRef]
- Al-Sudani, S.; Palaniappan, R. Predicting students’ final degree classification using an extended profile. Educ. Inf. Technol. 2019, 24, 2357–2369. [Google Scholar] [CrossRef] [Green Version]
- Gray, C.C.; Perkins, D. Utilizing early engagement and machine learning to predict student outcomes. Comput. Educ. 2019, 131, 22–32. [Google Scholar] [CrossRef]
- Garcia, J.D.; Skrita, A. Predicting Academic Performance Based on Students’ Family Environment: Evidence for Colombia Using Classification Trees. Psychol. Soc. Educ. 2019, 11, 299–311. [Google Scholar] [CrossRef] [Green Version]
- Babić, I.Đ. Machine learning methods in predicting the student academic motivation. Croat. Oper. Res. Rev. 2017, 8, 443–461. [Google Scholar] [CrossRef]
- Kotsiantis, S.B. Use of machine learning techniques for educational proposes: A decision support system for forecasting students’ grades. Artif. Intell. Rev. 2012, 37, 331–344. [Google Scholar] [CrossRef]
- Sokkhey, P.; Okazaki, T. Hybrid Machine Learning Algorithms for Predicting Academic Performance. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 32–41. [Google Scholar] [CrossRef] [Green Version]
- Hussain, S.; Gaftandzhieva, S.; Maniruzzaman, M.; Doneva, R.; Muhsin, Z.F. Regression analysis of student academic performance using deep learning. Educ. Inf. Technol. 2020, 26, 783–798. [Google Scholar] [CrossRef]
- Bhagavan, K.S.; Thangakumar, J.; Subramanian, D.V. Predictive analysis of student academic performance and employability chances using HLVQ algorithm. J. Ambient. Intell. Humaniz. Comput. 2020, 12, 3789–3797. [Google Scholar] [CrossRef]
- Akçapınar, G.; Altun, A.; Aşkar, P. Using learning analytics to develop early-warning system for at-risk students. Int. J. Educ. Technol. High. Educ. 2019, 16, 40. [Google Scholar] [CrossRef]
- Francis, B.K.; Babu, S.S. Predicting Academic Performance of Students Using a Hybrid Data Mining Approach. J. Med. Syst. 2019, 43, 162. [Google Scholar] [CrossRef]
- Asif, R.; Hina, S.; Haque, S.I. Predicting student academic performance using data mining methods. Int. J. Comput. Sci. Netw. Secur. 2017, 17, 187–191. [Google Scholar]
- Yan, L.; Liu, Y. An Ensemble Prediction Model for Potential Student Recommendation Using Machine Learning. Symmetry 2020, 12, 728. [Google Scholar] [CrossRef]
- Nicolas, P.R. Leverage Scala and Machine Learning to Construct and Study Systems that Can Learn from Data; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]











| SQ | SQ1 | SQ2 | SQ3 | Database-Wise Count |
|---|---|---|---|---|
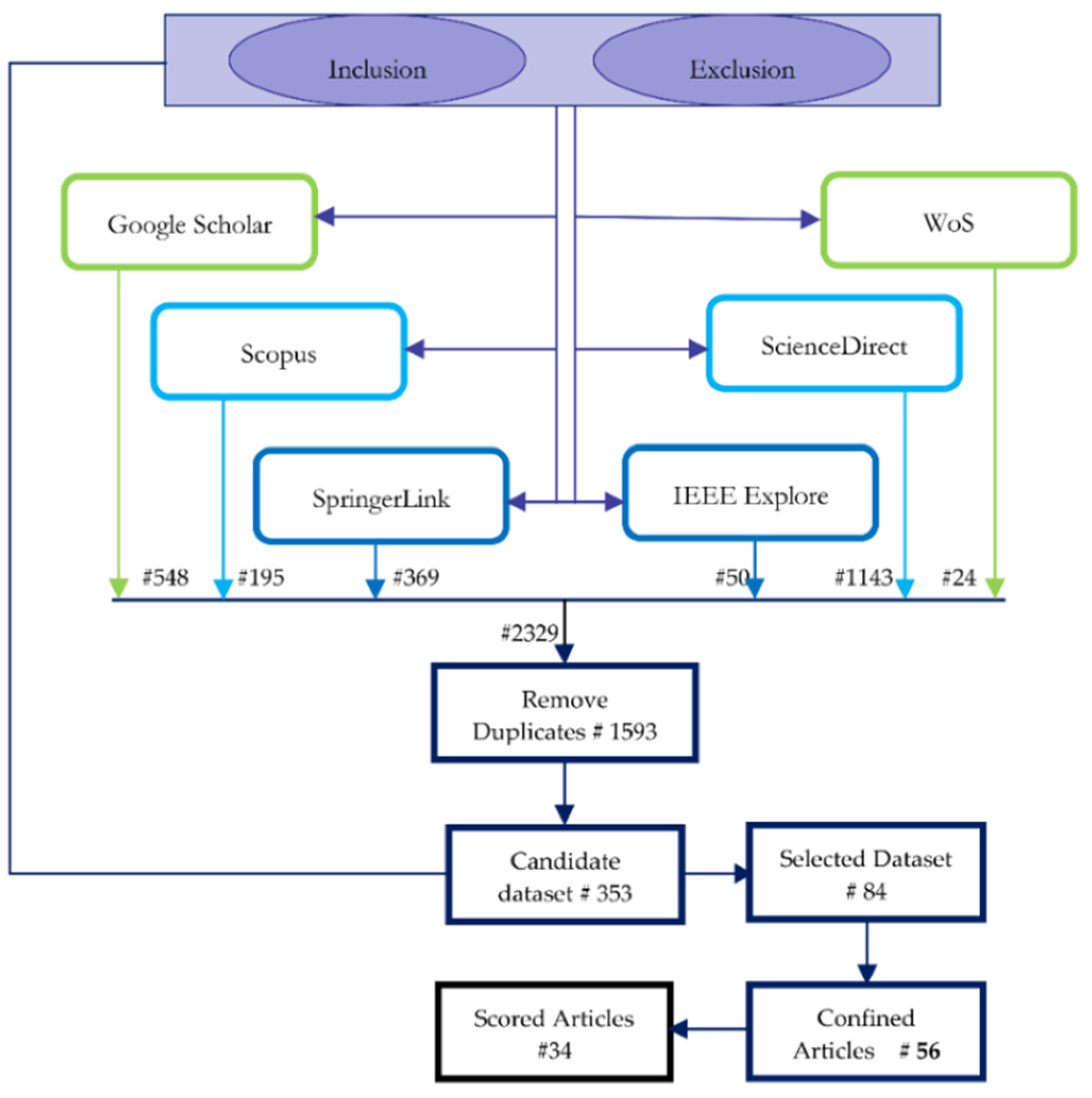
| Google Scholar | 70 | 465 | 13 | 548 |
| WoS | 171 | 24 | 0 | 195 |
| Scopus | 3 | 170 | 1 | 369 |
| ScienceDirect | 8 | 41 | 1 | 50 |
| SpringerLink | 1043 | 0 | 100 | 1143 |
| IEEE Explore | 0 | 24 | 0 | 24 |
| Query-Wise Count | 1295 | 724 | 115 | 2329 |
| Ref. | RQ1 | RQ2 | RQ3 | RQ4 | RQ5 | Ref. | RQ1 | RQ2 | RQ3 | RQ4 | RQ5 | Ref. | RQ1 | RQ2 | RQ3 | RQ4 | RQ5 | Ref. | RQ1 | RQ2 | RQ3 | RQ4 | RQ5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [1] | * | - | * | - | - | [2] | * | - | - | - | - | [3] | * | * | * | - | * | [4] | * | - | - | - | - |
| [5] | * | * | * | - | - | [6] | * | * | * | * | * | [7] | * | - | - | - | - | [8] | * | * | * | * | * |
| [9] | * | * | * | - | - | [10] | * | * | * | * | * | [11] | * | * | * | - | - | [12] | * | * | * | * | * |
| [13] | * | * | * | * | * | [14] | * | * | * | - | * | [15] | * | - | - | - | - | [16] | * | * | * | * | * |
| [17] | * | * | - | * | * | [18] | * | * | * | * | * | [19] | * | * | * | * | * | [20] | * | - | - | - | - |
| [21] | * | * | * | - | * | [22] | * | - | - | - | * | [23] | * | * | * | * | * | [24] | * | * | * | * | * |
| [25] | * | * | * | * | * | [26] | * | * | * | * | - | [27] | * | - | - | - | * | [28] | * | * | * | * | - |
| [29] | * | - | - | - | - | [30] | * | - | - | - | * | [31] | * | * | * | * | * | [32] | * | * | * | * | * |
| [33] | * | * | * | - | * | [34] | * | * | - | - | * | [35] | * | * | * | * | * | [36] | * | * | * | * | * |
| [37] | * | * | * | * | * | [38] | * | * | - | - | * | [39] | * | * | * | * | * | [40] | * | * | * | * | - |
| [41] | * | * | - | - | - | [42] | * | * | * | - | * | [43] | * | * | - | * | * | [44] | * | * | * | - | * |
| [45] | * | * | * | * | * | [46] | * | * | * | * | * | [47] | * | * | * | * | * | [48] | * | * | * | * | * |
| [49] | * | * | * | - | - | [50] | * | * | * | - | - | [51] | * | - | - | - | - | [52] | * | * | * | * | * |
| [53] | * | - | - | - | - | [54] | * | * | * | - | * | [55] | * | * | * | * | * | [56] | * | * | * | - | * |
| [57] | * | * | * | - | - | [58] | * | * | * | - | - | [59] | * | * | * | * | * | [60] | * | * | * | - | * |
| [61] | * | * | * | * | * | [62] | * | * | * | * | * | [63] | * | * | * | - | * | [64] | * | * | * | * | * |
| [65] | * | * | - | * | * | [66] | * | * | * | * | * | [67] | * | * | * | * | * | [68] | * | * | * | - | - |
| [69] | * | * | * | * | * | [70] | * | - | - | - | - | [71] | * | - | * | - | - | [72] | * | * | - | * | * |
| [73] | * | - | * | - | - | [74] | * | * | * | * | * | [75] | * | * | - | * | * | [76] | * | * | - | * | * |
| [77] | * | * | * | * | * | [78] | * | * | - | * | * | [79] | * | * | * | * | * | [80] | * | * | * | * | * |
| Indexing Source | # of Articles | % |
|---|---|---|
| Scopus | 47 | 56.6 |
| WoS | 32 | 38.5 |
| IEEE Explore | 3 | 3.6 |
| Google Scholar | 1 | 1.2 |
| Ref. | QAQ01 | QAQ02 | QAQ03 | QAQ04 | QAQ05 | QAQ06 | QAQ07 | QAQ08 | QAQ09 | QAQ10 | SCORE | Ref. | QAQ01 | QAQ02 | QAQ03 | QAQ04 | QAQ05 | QAQ06 | QAQ07 | QAQ08 | QAQ09 | QAQ10 | SCORE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [1] | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 4 | [2] | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 |
| [3] | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 8 | [4] | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 |
| [5] | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 6 | [6] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 10 |
| [7] | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 8 | [8] | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 6 |
| [9] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 9 | [10] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 10 |
| [11] | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 6 | [12] | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 9 |
| [13] | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 5 | [14] | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 9 |
| [15] | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 8 | [16] | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 8 |
| [17] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 10 | [18] | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 |
| [19] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 10 | [20] | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 9 |
| [21] | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 6 | [22] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 10 |
| [23] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 10 | [24] | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 8 |
| [25] | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | [26] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 10 |
| [27] | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 9 | [28] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 10 |
| [29] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 10 | [30] | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 |
| [31] | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 8 | [32] | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 |
| [33] | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 9 | [34] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 10 |
| [35] | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 8 | [36] | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 |
| [37] | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 9 | [38] | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 8 |
| [39] | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 8 | [40] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 9 |
| [41] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 10 | [42] | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 9 |
| [43] | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 6 | [44] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 10 |
| [45] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 10 | [46] | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 5 |
| [47] | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 7 | [48] | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 8 |
| [49] | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 7 | [50] | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 8 |
| [51] | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 9 | [52] | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 9 |
| [53] | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 5 | [54] | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 6 |
| [55] | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | [56] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 10 |
| [57] | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | [58] | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 7 |
| [59] | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 8 | [60] | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 7 |
| [61] | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 6 | [62] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 9 |
| [63] | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 7 | [64] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 9 |
| [65] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 10 | [66] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 9 |
| [67] | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 7 | [68] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 10 |
| [69] | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 9 | [70] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 10 |
| [71] | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 5 | [72] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 10 |
| [73] | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | [74] | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 3 |
| [75] | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 8 | [76] | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 4 |
| [77] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 10 | [78] | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 8 |
| [79] | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 9 | [80] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 9 |
| Criteria | # of Articles | % of Articles |
|---|---|---|
| very high (9 ≤ score ≤ 10) | 36 | 45% |
| high (7 ≤ score ≤ 8) | 20 | 25% |
| medium (5 ≤ score ≤ 6) | 11 | 13.75% |
| low (3 ≤ score ≤ 4) | 3 | 3.75% |
| very low (score ≤ 2) | 10 | 12.5% |
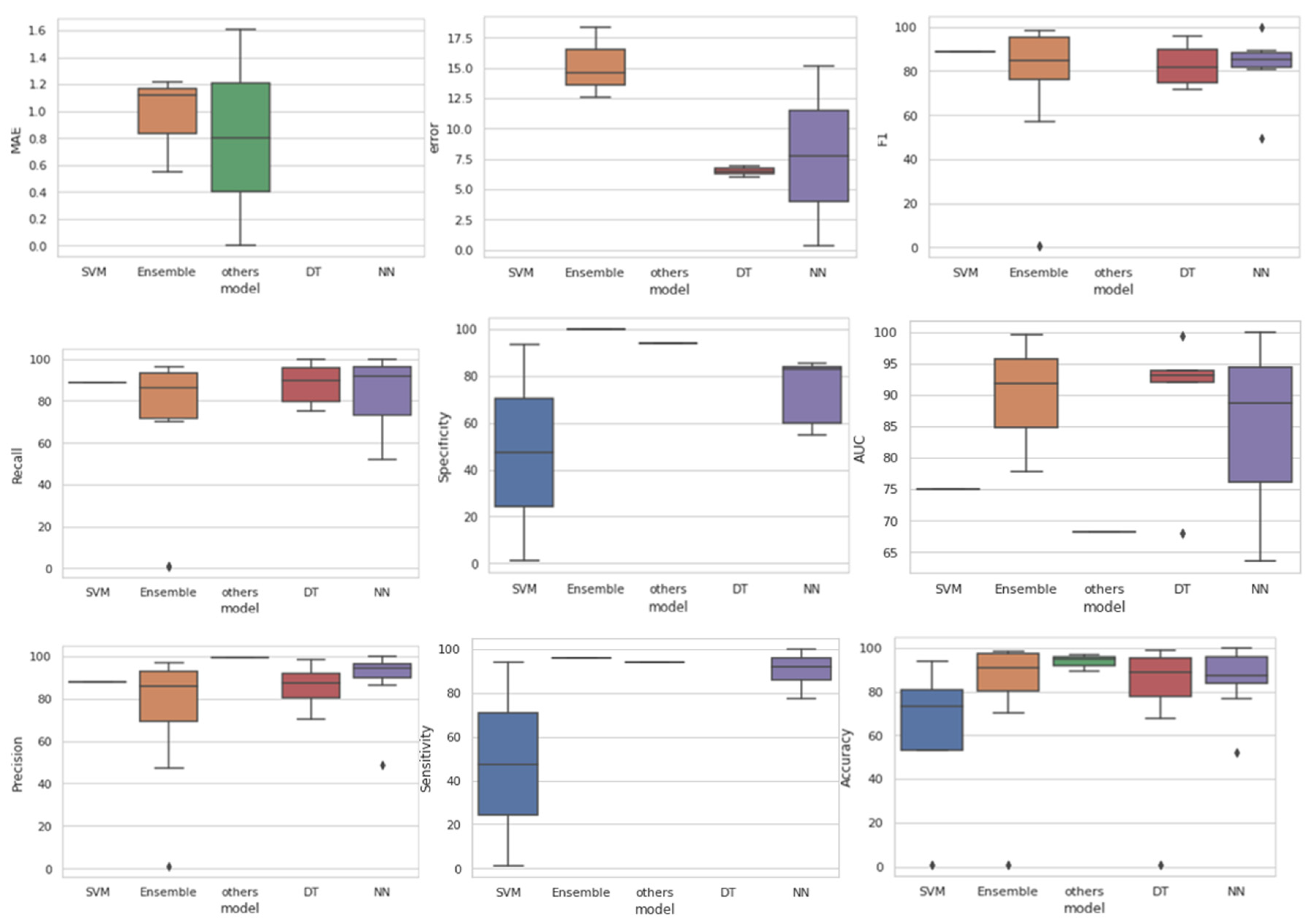
| Performance Metrics | Measures | SVM | DT | NN | Ensemble | Performance Metrics | Measures | SVM | DT | NN | Ensemble | Performance Metrics | Measures | SVM | DT | NN | Ensemble |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | Count | 4 | 15 | 14 | 16 | F1 | Count | 1 | 8 | 6 | 13 | Precision | Count | 1 | 10 | 7 | 11 |
| Mean | 60 | 80 | 86.9 | 84.7 | Mean | 89 | 82.5 | 81.65 | 72.7 | Mean | 89 | 85.9 | 87.87 | 75.1 | |||
| Min | 93.8 | 79 | 51.9 | 61 | Min | 89 | 71.9 | 49.4 | 53 | Min | 89 | 70.3 | 48.6 | 95 | |||
| Max | 95 | 98.94 | 100 | 98.5 | Max | 89 | 95.6 | 100 | 98.2 | Max | 89 | 98.3 | 100 | 97 | |||
| Std. Dev | 40.86 | 24.46 | 12.16 | 24.08 | Std. Dev | - | 9.2 | 17.08 | 33.9 | Std. Dev | - | 8.77 | 17.8 | 28.8 | |||
| Sensitivity/Recall | Count | 1 | 9 | 7 | 12 | AUC | Count | 1 | 5 | 3 | 3 | Specificity | Count | 2 | - | 5 | 1 |
| Mean | 89 | 88.13 | 83.2 | 71.8 | Mean | 75 | 89.2 | 84 | 89.7 | Mean | 47.28 | - | 73 | 100 | |||
| Min | 89 | 75 | 51.9 | 48 | Min | 75 | 68 | 63.5 | 77.7 | Min | 0.97 | - | 54.6 | 100 | |||
| Max | 89 | 100 | 100 | 96.3 | Max | 75 | 99.4 | 100 | 99.6 | Max | 94 | - | 85.16 | 100 | |||
| Std. Dev | - | 9.47 | 17.8 | 34.5 | Std. Dev | - | 12 | 18.6 | 11.1 | Std. Dev | 65 | - | 14.73 | - |
| Measures | SVM | DT | NN | ENSEMBLE | Measures | SVM | DT | NN | ENSEMBLE | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| MSE | Count | - | 1.00 | 1.00 | 2.00 | RMSE | Count | - | 2.00 | - | 4.00 |
| Mean | - | 0.05 | 75.90 | 7.60 | Mean | - | 0.35 | - | 6.14 | ||
| Min | - | 0.05 | 0.75 | 0.14 | Min | - | 0.21 | - | 56.00 | ||
| Max | - | 0.05 | 0.75 | 0.15 | Max | - | 0.50 | - | 17.90 | ||
| Std. Dev | - | - | - | 10.59 | Std. Dev | - | 0.21 | - | 0.79 | ||
| MAE | Count | - | - | - | 3.00 | Error | Count | - | 1.00 | 2.00 | 3.00 |
| Mean | - | - | - | 9.60 | Mean | - | 6.96 | 77.50 | 15.17 | ||
| Min | - | - | - | 55.00 | Min | - | 6.96 | 0.30 | 12.50 | ||
| Max | - | - | - | 12.15 | Max | - | 6.96 | 15.20 | 18.30 | ||
| Std. Dev | - | - | - | 0.35 | Std. Dev | - | - | 10.50 | 2.95 |
| Performance Metric | References | # |
|---|---|---|
| Accuracy | [3,6,8,11,12,14,15,16,17,18,20,22,24,25,26,27,29,31,34,35,36,37,38,39,40], [42,43,44,45,46,47,51,53,54,56,57,59,60,63,64,65,66,67,69,72,73,74,76,77,78,79] | 51 |
| Sensitivity | [16,25,31,43,53,56,64] | 7 |
| Specificity | [3,16,25,43,53,56,69,72,77] | 9 |
| AUC | [12,17,19,22,29,35,38,41,46,55,58,61,80] | 13 |
| Recall | [6,7,11,12,15,16,17,18,22,24,27,29,32,35,37] [39,41,45,46,55,59,60,61,63,64,66,76,78,80] | 29 |
| Precision | [7,11,12,15,17,18,22,24,25,27,29,32,34,35,37] [39,41,45,46,55,56,57,59,60,63,64,66,76,78,80] | 30 |
| F1 | [6,7,11,12,15,16,17,22,24,27,29,32,35] [37,38,39,43,46,55,59,61,63,64,66,76,78,80] | 27 |
| MSE | [6,26,43,44] | 4 |
| MAE | [30,33,42,63,75] | 5 |
| RMSE | [7,10,30,54,55,61,74] | 7 |
| Error | [18,45,55,56,58,61,80] | 7 |
| Demographic Features | Preliminary education | Behavioral features | Personal | Number of times opened |
| Gender | Self-evaluation | Number of times closed | ||
| Age | Time management | Number of times “Next” used | ||
| Location of stay | Anxiety | Number of times “Previous” used | ||
| Duration of travel | Study aids | Number of times “seek” used | ||
| Parent education | Study time duration | Number of times “jump” used | ||
| Level of income | Isolation | Number of times “search” used | ||
| Status of family | Search of emotional support | Activity and engagement | ||
| Social support group | Self-blame | Number of forum replies | ||
| Year of admission and age | Problem in focusing | Number of clarifications sought | ||
| Number of siblings | Fatalism | Number of hand-raises | ||
| Computer knowledge | Reaction time | Time spent online | ||
| Type of parent employment | Avoiding amusement | Number of assignments submitted | ||
| Type of student self-employment | Verbal communication | Number of tests submitted | ||
| Disability | Interest and motivation | Time spent on assignment | ||
| Mode of study | User navigation | Time spent on quiz | ||
| Tuition fee source | Number of clicks on the discussion forum | Number of days absent | ||
| Commuting | Number of clicks on material of study | Specificity of the days absent | ||
| Academic features | Individual semester grades | On-campus clicks versus off-campus clicks | Number of clicks on report | |
| Final exam grades | Number of clicks during weekdays | Number of clicks on mark issued | ||
| Individual subject grades | Number of clicks during weekends | Dual pane activity | ||
| Grade of previous semesters | Number of clicks on modules | E-books | ||
| Oral exam grades | Number of bookmarks created | Number of times opened | ||
| Written exam grades | Number of bookmarks deleted | Number of times closed | ||
| Number of appearance for exams | Video content | |||
| Entrance test grades | ||||
| Prerequisite course grade | ||||
| Curriculum | ||||
| Academic resource | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Balaji, P.; Alelyani, S.; Qahmash, A.; Mohana, M. Contributions of Machine Learning Models towards Student Academic Performance Prediction: A Systematic Review. Appl. Sci. 2021, 11, 10007. https://doi.org/10.3390/app112110007
Balaji P, Alelyani S, Qahmash A, Mohana M. Contributions of Machine Learning Models towards Student Academic Performance Prediction: A Systematic Review. Applied Sciences. 2021; 11(21):10007. https://doi.org/10.3390/app112110007
Chicago/Turabian StyleBalaji, Prasanalakshmi, Salem Alelyani, Ayman Qahmash, and Mohamed Mohana. 2021. "Contributions of Machine Learning Models towards Student Academic Performance Prediction: A Systematic Review" Applied Sciences 11, no. 21: 10007. https://doi.org/10.3390/app112110007
APA StyleBalaji, P., Alelyani, S., Qahmash, A., & Mohana, M. (2021). Contributions of Machine Learning Models towards Student Academic Performance Prediction: A Systematic Review. Applied Sciences, 11(21), 10007. https://doi.org/10.3390/app112110007