
A Data Loss Recovery Technique Using EMD-BiGRU Algorithm for Structural Health Monitoring

Abstract
:1. Introduction
2. Proposed EMD-BiGRU Architecture
2.1. Empirical Mode Decomposition
2.2. Bidirectional Gated Recurrent Unit
2.3. The Proposed Method
| Algorithm 1 EMD-BiGRU Algorithm |
|---|
| 1: Definition: is the length of the missing data; 2: is decompose by EMD algorithm and the initial feature set is obtained; 3: A features set including original sequence and initial feature is defined as inputs data. 4: is split into training and testing dataset and the training is inputted into the EMD-BiGRU to form predicted model; 5: Testing datasets are inputted into the predicted model to get the final predicted output : 6. END |
2.4. Evaluation Metric
3. Experimental Setting
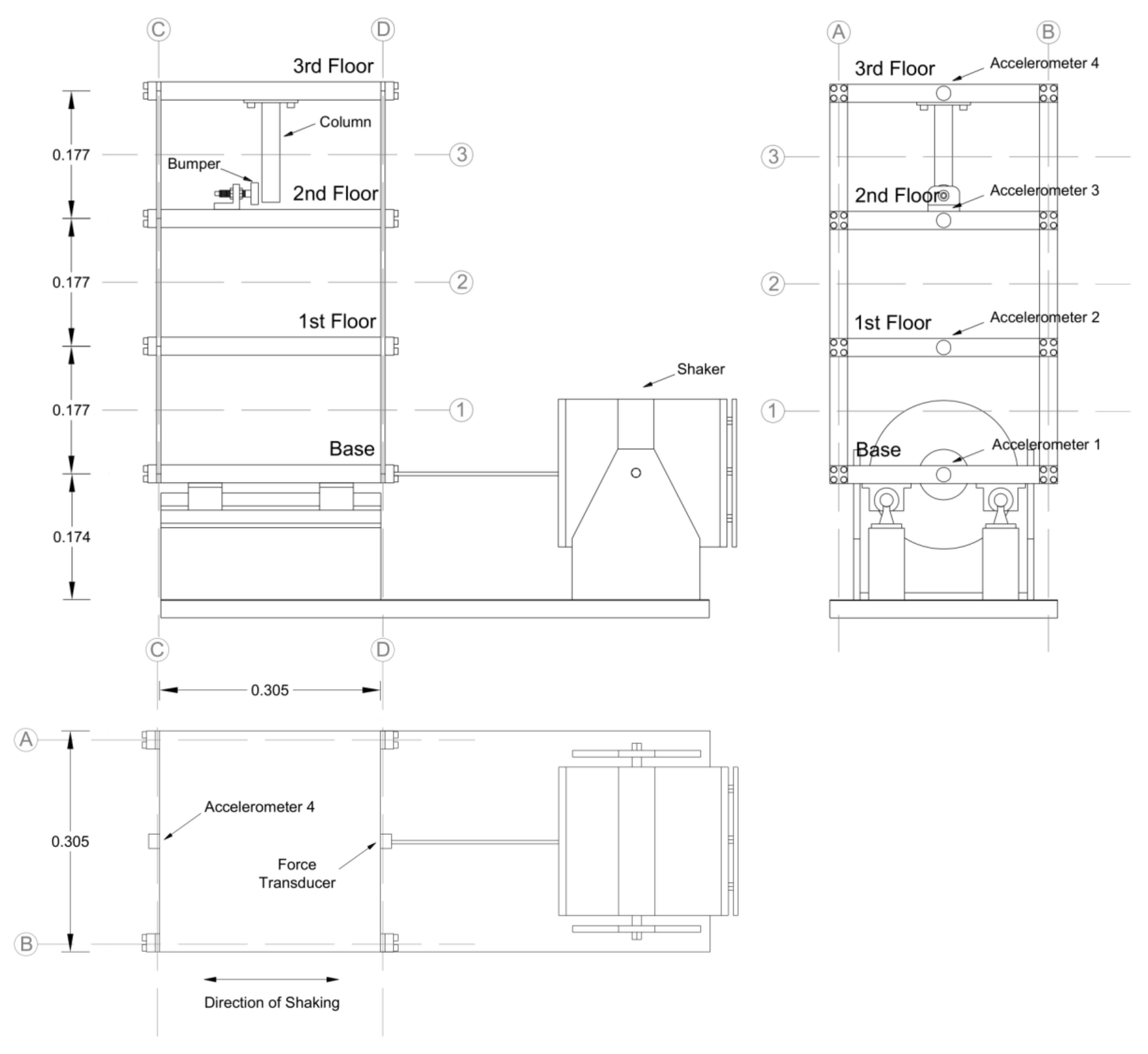
3.1. Description of Data Sets
3.2. Acceleration Decomposition Based on EMD
3.3. Parameters Setting of Different Algorithms
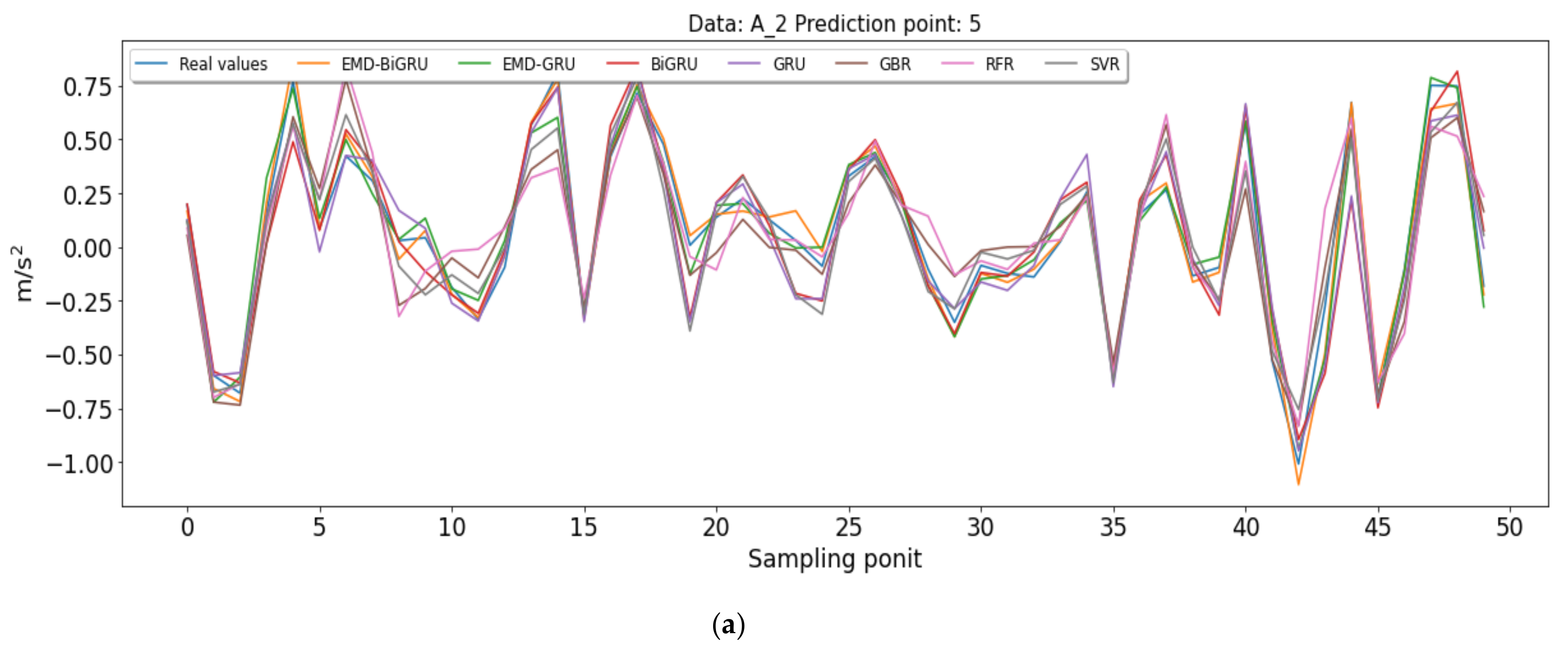
4. Analysis of Predicted Results
5. Effectiveness of the EMD-BiGRU for Data Loss Recovery under Different Structural Conditions
5.1. Data Description
5.2. Experimental Analysis
6. Conclusions and Future Work
- (1)
- In recognition of the influence of EMD, the EMD-BiGRU and single models such as BiGRU, GRU, GBR, RFR, and SVR are investigated. The results show that the proposed EMD-BiGRU method achieves better performance for data imputation and demonstrates that the proposed method effectively captures the dynamic temporal characteristics of acceleration data.
- (2)
- With the increasing missing data, the data recovery ability of most algorithms could decrease. EMD-BiGRU has lower errors in MSE, RMSE, and MAE than single algorithms such as GRU, GBR, and BiGRU. It indicates that the proposed method has strong robustness and can be promoted on a large scale in practical applications
- (3)
- For different structural conditions of a three-story building, the EMD-BiGRU exhibits better data imputation performance. It shows that EMD-BiGRU, as a flexible and data-driven method, is effective for mining measured acceleration data.
- (4)
- One of the limitations of this study is that EMD-BiGRU is tested using original acceleration data without considering the effect of noise. In future work, raw acceleration data with the noises are considered to solve the imputation of the missing data. Another future research direction is that the extension of EMD to tackle missing data should be studied in the future.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| data set | Point | Metrics | EMD-BiGRU | EMD-GRU | BiGRU | GRU | GBR | RFR | SVR |
|---|---|---|---|---|---|---|---|---|---|
| A_2 | 5 | MSE | 0.0065 | 0.0097 | 0.0249 | 0.0249 | 0.0573 | 0.0669 | 0.0429 |
| 5 | RMSE | 0.0808 | 0.0987 | 0.1579 | 0.1579 | 0.2394 | 0.2587 | 0.2070 | |
| 5 | MAE | 0.0609 | 0.0739 | 0.1175 | 0.1182 | 0.1859 | 0.2010 | 0.1595 | |
| 5 | R2 | 96.85% | 95.30% | 87.97% | 87.96% | 72.35% | 67.72% | 79.32% | |
| A_2 | 10 | MSE | 0.0054 | 0.0083 | 0.0156 | 0.0203 | 0.0841 | 0.0935 | 0.0679 |
| 10 | RMSE | 0.0731 | 0.0910 | 0.1250 | 0.1424 | 0.2900 | 0.3058 | 0.2606 | |
| 10 | MAE | 0.0567 | 0.0711 | 0.0957 | 0.1090 | 0.2259 | 0.2386 | 0.2009 | |
| 10 | R2 | 97.44% | 96.03% | 92.51% | 90.29% | 59.68% | 55.17% | 67.45% | |
| A_2 | 15 | MSE | 0.0073 | 0.0129 | 0.0200 | 0.0181 | 0.0919 | 0.0992 | 0.0777 |
| 15 | RMSE | 0.0856 | 0.1136 | 0.1415 | 0.1345 | 0.3031 | 0.3149 | 0.2787 | |
| 15 | MAE | 0.0674 | 0.0887 | 0.1096 | 0.1049 | 0.2375 | 0.2476 | 0.2170 | |
| 15 | R2 | 96.48% | 93.78% | 90.36% | 91.29% | 55.77% | 52.25% | 62.60% | |
| A_2 | 20 | MSE | 0.0047 | 0.0086 | 0.0829 | 0.0192 | 0.1026 | 0.1091 | 0.0904 |
| 20 | RMSE | 0.0684 | 0.0929 | 0.2880 | 0.1384 | 0.3203 | 0.3302 | 0.3007 | |
| 20 | MAE | 0.0534 | 0.0727 | 0.2233 | 0.1079 | 0.2524 | 0.2609 | 0.2351 | |
| 20 | R2 | 97.76% | 95.87% | 60.33% | 90.84% | 50.92% | 47.84% | 56.76% |


| data set | Point | Metrics | EMD-BiGRU | EMD-GRU | BiGRU | GRU | GBR | RFR | SVR |
|---|---|---|---|---|---|---|---|---|---|
| A_3 | 5 | MSE | 0.004 | 0.0055 | 0.0124 | 0.0114 | 0.0299 | 0.0321 | 0.0244 |
| 5 | RMSE | 0.0634 | 0.0741 | 0.1115 | 0.1066 | 0.173 | 0.179 | 0.1563 | |
| 5 | MAE | 0.0458 | 0.0537 | 0.0798 | 0.0763 | 0.1329 | 0.1365 | 0.12 | |
| 5 | R2 | 98.15% | 97.48% | 94.29% | 94.78% | 86.26% | 85.27% | 88.78% | |
| A_3 | 10 | MSE | 0.0028 | 0.0056 | 0.0381 | 0.0376 | 0.0575 | 0.0612 | 0.0494 |
| 10 | RMSE | 0.0526 | 0.0751 | 0.1953 | 0.1939 | 0.2399 | 0.2473 | 0.2223 | |
| 10 | MAE | 0.0396 | 0.057 | 0.141 | 0.1393 | 0.1821 | 0.1873 | 0.1674 | |
| 10 | R2 | 98.71% | 97.36% | 82.15% | 82.4% | 73.06% | 71.37% | 76.86% | |
| A_3 | 15 | MSE | 0.0039 | 0.0053 | 0.0195 | 0.0609 | 0.0799 | 0.0825 | 0.0724 |
| 15 | RMSE | 0.0626 | 0.0726 | 0.1396 | 0.2468 | 0.2826 | 0.2872 | 0.2691 | |
| 15 | MAE | 0.0485 | 0.0563 | 0.1065 | 0.1803 | 0.2151 | 0.2192 | 0.2031 | |
| 15 | R2 | 98.18% | 97.55% | 90.94% | 71.67% | 62.84% | 61.62% | 66.32% | |
| A_3 | 20 | MSE | 0.0043 | 0.0059 | 0.0707 | 0.0777 | 0.0934 | 0.0954 | 0.0872 |
| 20 | RMSE | 0.0655 | 0.0766 | 0.2658 | 0.2787 | 0.3055 | 0.3089 | 0.2952 | |
| 20 | MAE | 0.0507 | 0.0596 | 0.1991 | 0.2075 | 0.2341 | 0.2371 | 0.2245 | |
| 20 | R2 | 97.99% | 97.26% | 66.98% | 63.69% | 56.37% | 55.41% | 59.26% |


| data set | Point | Metrics | EMD-BiGRU | EMD-GRU | BiGRU | GRU | GBR | RFR | SVR |
|---|---|---|---|---|---|---|---|---|---|
| A_4 | 5 | MSE | 0.0041 | 0.0164 | 0.0187 | 0.0180 | 0.0440 | 0.0495 | 0.035 |
| 5 | RMSE | 0.0644 | 0.1281 | 0.1367 | 0.1343 | 0.2097 | 0.2226 | 0.187 | |
| 5 | MAE | 0.0470 | 0.0912 | 0.0957 | 0.0938 | 0.1597 | 0.1690 | 0.1414 | |
| 5 | R2 | 97.26% | 89.14% | 87.64% | 88.07% | 70.91% | 67.21% | 76.87% | |
| A_4 | 10 | MSE | 0.0032 | 0.0039 | 0.0518 | 0.0107 | 0.0728 | 0.0770 | 0.0647 |
| 10 | RMSE | 0.0562 | 0.0622 | 0.2277 | 0.1036 | 0.2698 | 0.2774 | 0.2543 | |
| 10 | MAE | 0.0427 | 0.0471 | 0.1649 | 0.0780 | 0.2063 | 0.2130 | 0.192 | |
| 10 | R2 | 97.92% | 97.45% | 65.82% | 92.92% | 52.01% | 49.25% | 57.35% | |
| A_4 | 15 | MSE | 0.0033 | 0.0048 | 0.0739 | 0.0734 | 0.0844 | 0.088 | 0.0784 |
| 15 | RMSE | 0.0578 | 0.0691 | 0.2718 | 0.2709 | 0.2905 | 0.2966 | 0.2801 | |
| 15 | MAE | 0.0447 | 0.0539 | 0.2029 | 0.2028 | 0.2252 | 0.2305 | 0.215 | |
| 15 | R2 | 97.76% | 96.8% | 50.46% | 50.77% | 43.38% | 41.0% | 47.39% | |
| A_4 | 20 | MSE | 0.0038 | 0.0053 | 0.0841 | 0.0102 | 0.0931 | 0.0960 | 0.0883 |
| 20 | RMSE | 0.0618 | 0.0727 | 0.2901 | 0.1008 | 0.3052 | 0.3099 | 0.2971 | |
| 20 | MAE | 0.0477 | 0.0566 | 0.2198 | 0.0771 | 0.2370 | 0.2411 | 0.2286 | |
| 20 | R2 | 97.45% | 96.47% | 43.75% | 93.21% | 37.74% | 35.81% | 40.99% |


References
- Annamdas, V.G.M.; Bhalla, S.; Soh, C.K. Applications of Structural Health Monitoring Technology in Asia. Struct. Health Monit. 2017, 16, 324–346. [Google Scholar] [CrossRef]
- Li, H.; Ou, J. The State of the Art in Structural Health Monitoring of Cable-Stayed Bridges. J. Civ. Struct. Health Monit. 2016, 6, 43–67. [Google Scholar] [CrossRef]
- Nagayama, T.; Sim, S.H.; Miyamori, Y.; Spencer, B.F., Jr. Issues in Structural Health Monitoring Employing Smart Sensors. Smart Struct. Syst. 2007, 3, 299–320. [Google Scholar] [CrossRef] [Green Version]
- Bao, Y.; Yu, Y.; Li, H.; Mao, X.; Jiao, W.; Zou, Z.; Ou, J. Compressive Sensing-Based Lost Data Recovery of Fast-Moving Wireless Sensing for Structural Health Monitoring: Lost Data Recovery for Fast-Moving Wireless Sensing. Struct. Control Health Monit. 2015, 22, 433–448. [Google Scholar] [CrossRef]
- Huang, Y.; Beck, J.L.; Wu, S.; Li, H. Bayesian Compressive Sensing for Approximately Sparse Signals and Application to Structural Health Monitoring Signals for Data Loss Recovery. Probabilistic Eng. Mech. 2016, 46, 62–79. [Google Scholar] [CrossRef] [Green Version]
- Hong, Y.H.; Kim, H.-K.; Lee, H.S. Reconstruction of Dynamic Displacement and Velocity from Measured Accelerations Using the Variational Statement of an Inverse Problem. J. Sound Vib. 2010, 329, 4980–5003. [Google Scholar] [CrossRef]
- Bao, Y.; Li, H.; Sun, X.; Yu, Y.; Ou, J. Compressive Sampling–Based Data Loss Recovery for Wireless Sensor Networks Used in Civil Structural Health Monitoring. Struct. Health Monit. 2013, 12, 78–95. [Google Scholar] [CrossRef]
- Zou, Z.; Bao, Y.; Li, H.; Spencer, B.F.; Ou, J. Embedding Compressive Sensing-Based Data Loss Recovery Algorithm into Wireless Smart Sensors for Structural Health Monitoring. IEEE Sens. J. 2015, 15, 797–808. [Google Scholar] [CrossRef]
- Liu, G.; Mao, Z.; Todd, M.; Huang, Z. Damage Assessment with State-Space Embedding Strategy and Singular Value Decomposition under Stochastic Excitation. Struct. Health Monit. 2014, 13, 131–142. [Google Scholar] [CrossRef]
- Wan, H.-P.; Ni, Y.-Q. Bayesian Multi-Task Learning Methodology for Reconstruction of Structural Health Monitoring Data. Struct. Health Monit. 2019, 18, 1282–1309. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Nagarajaiah, S. Harnessing Data Structure for Recovery of Randomly Missing Structural Vibration Responses Time History: Sparse Representation versus Low-Rank Structure. Mech. Syst. Signal Process. 2016, 74, 165–182. [Google Scholar] [CrossRef]
- Choi, S.; Kwon, E.; Kim, Y.; Hong, K.; Park, H. A Practical Data Recovery Technique for Long-Term Strain Monitoring of Mega Columns during Construction. Sensors 2013, 13, 10931–10943. [Google Scholar] [CrossRef]
- He, J.; Guan, X.; Liu, Y. Structural Response Reconstruction Based on Empirical Mode Decomposition in Time Domain. Mech. Syst. Signal Process. 2012, 28, 348–366. [Google Scholar] [CrossRef]
- Luo, Y.F.; Ye, Z.W.; Guo, X.N.; Qiang, X.H.; Chen, X.M. Data Missing Mechanism and Missing Data Real-Time Processing Methods in the Construction Monitoring of Steel Structures. Adv. Struct. Eng. 2015, 18, 585–601. [Google Scholar] [CrossRef]
- Zhang, Z.; Luo, Y. Restoring Method for Missing Data of Spatial Structural Stress Monitoring Based on Correlation. Mech. Syst. Signal Process. 2017, 91, 266–277. [Google Scholar] [CrossRef]
- Hua, Y.; Zhao, Z.; Li, R.; Chen, X.; Liu, Z.; Zhang, H. Deep Learning with Long Short-Term Memory for Time Series Prediction. IEEE Commun. Mag. 2019, 57, 114–119. [Google Scholar] [CrossRef] [Green Version]
- Deng, Y.; Jia, H.; Li, P.; Tong, X.; Qiu, X.; Li, F. A Deep Learning Methodology Based on Bidirectional Gated Recurrent Unit for Wind Power Prediction. In Proceedings of the 2019 14th IEEE Conference on Industrial Electronics and Applications (ICIEA), Xi’an, China, 19–21 June 2019; pp. 591–595. [Google Scholar]
- Li, X.; Zhuang, W.; Zhang, H. Short-Term Power Load Forecasting Based on Gate Recurrent Unit Network and Cloud Computing Platform. In Proceedings of the 4th International Conference on Computer Science and Application Engineering, Sanya, China, 20 October 2020; pp. 1–6. [Google Scholar]
- Rosafalco, L.; Manzoni, A.; Mariani, S.; Corigliano, A. Fully Convolutional Networks for Structural Health Monitoring through Multivariate Time Series Classification. Adv. Model. Simul. Eng. Sci. 2020, 7, 38. [Google Scholar] [CrossRef]
- Liu, H.; Ding, Y.-L.; Zhao, H.-W.; Wang, M.-Y.; Geng, F.-F. Deep Learning-Based Recovery Method for Missing Structural Temperature Data Using LSTM Network. Struct. Monit. Maint. 2020, 7, 109–124. [Google Scholar] [CrossRef]
- Fan, G.; Li, J.; Hao, H. Lost Data Recovery for Structural Health Monitoring Based on Convolutional Neural Networks. Struct. Control. Health Monit. 2019, 26, e2433. [Google Scholar] [CrossRef]
- Abd Elaziz, M.; Dahou, A.; Abualigah, L.; Yu, L.; Alshinwan, M.; Khasawneh, A.M.; Lu, S. Advanced Metaheuristic Optimization Techniques in Applications of Deep Neural Networks: A Review. Neural Comput. Appl. 2021. [Google Scholar] [CrossRef]
- Abualigah, L.; Yousri, D.; Abd Elaziz, M.; Ewees, A.A.; Al-qaness, M.A.A.; Gandomi, A.H. Aquila Optimizer: A Novel Meta-Heuristic Optimization Algorithm. Comput. Ind. Eng. 2021, 157, 107250. [Google Scholar] [CrossRef]
- Wang, Z.-C.; Ren, W.-X.; Chen, G. Time–Frequency Analysis and Applications in Time-Varying/Nonlinear Structural Systems: A State-of-the-Art Review. Adv. Struct. Eng. 2018, 21, 1562–1584. [Google Scholar] [CrossRef]
- Rezaei, D.; Taheri, F. Damage Identification in Beams Using Empirical Mode Decomposition. Struct. Health Monit. 2011, 10, 261–274. [Google Scholar] [CrossRef]
- Gao, X.; Li, X.; Zhao, B.; Ji, W.; Jing, X.; He, Y. Short-Term Electricity Load Forecasting Model Based on EMD-GRU with Feature Selection. Energies 2019, 12, 1140. [Google Scholar] [CrossRef] [Green Version]
- Figueiredo, E.; Park, G.; Figueiras, J.; Farrar, C.; Worden, K. Structural Health Monitoring Algorithm Comparisons Using Standard Data Sets; Los Alamos National Lab.: Los Alamos, NM, USA, 2009; LA-14393, 961604. [Google Scholar]
- Gan, D.; Wang, Y.; Zhang, N.; Zhu, W. Enhancing Short-term Probabilistic Residential Load Forecasting with Quantile Long–Short-term Memory. J. Eng. 2017, 2017, 2622–2627. [Google Scholar] [CrossRef]
- Dong, S.; Yuan, M.; Wang, Q.; Liang, Z. A Modified Empirical Wavelet Transform for Acoustic Emission Signal Decomposition in Structural Health Monitoring. Sensors 2018, 18, 1645. [Google Scholar] [CrossRef] [Green Version]
- Li, A.; Cheng, L. Research on A Forecasting Model of Wind Power Based on Recurrent Neural Network with Long Short-Term Memory. In Proceedings of the 2019 22nd International Conference on Electrical Machines and Systems (ICEMS), Harbin, China, 11–14 August 2019; pp. 1–4. [Google Scholar]
- Yang, J.; Zhang, L.; Chen, C.; Li, Y.; Li, R.; Wang, G.; Jiang, S.; Zeng, Z. A Hierarchical Deep Convolutional Neural Network and Gated Recurrent Unit Framework for Structural Damage Detection. Inf. Sci. 2020, 540, 117–130. [Google Scholar] [CrossRef]
- Liu, C.; Qi, J. Text Sentiment Analysis Based on ResGCNN. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 1604–1608. [Google Scholar]
- Singh, P.; Dwivedi, P. Integration of New Evolutionary Approach with Artificial Neural Network for Solving Short Term Load Forecast Problem. Appl. Energy 2018, 217, 537–549. [Google Scholar] [CrossRef]
- Zhao, Y.; Ye, L.; Pinson, P.; Tang, Y.; Lu, P. Correlation-Constrained and Sparsity-Controlled Vector Autoregressive Model for Spatio-Temporal Wind Power Forecasting. IEEE Trans. Power Syst. 2018, 33, 5029–5040. [Google Scholar] [CrossRef] [Green Version]
- Mashaly, A.F.; Alazba, A.A.; Al-Awaadh, A.M.; Mattar, M.A. Predictive Model for Assessing and Optimizing Solar Still Performance Using Artificial Neural Network under Hyper Arid Environment. Sol. Energy 2015, 118, 41–58. [Google Scholar] [CrossRef]


















| data set | A_1 | A_2 | A_3 | A_4 |
|---|---|---|---|---|
| Number of samples | 8192 | 8192 | 8192 | 8192 |
| Mean | 0.000009 | 0.000073 | 0.000304 | −0.000018 |
| Standard deviation | 0.5366 | 0.4556 | 0.4593 | 0.3856 |
| Min | −2.0286 | −1.8864 | −1.7249 | −1.7085 |
| Max | 1.9513 | 2.2541 | 2.1054 | 1.4282 |
| data set | Point | Metrics | EMD-BiGRU | EMD-GRU | BiGRU | GRU | GBR | RFR | SVR |
|---|---|---|---|---|---|---|---|---|---|
| A_1 | 5 | MSE | 0.0160 | 0.0311 | 0.1088 | 0.1005 | 0.1529 | 0.1652 | 0.1292 |
| 5 | RMSE | 0.1264 | 0.1763 | 0.3298 | 0.3170 | 0.3910 | 0.4064 | 0.3595 | |
| 5 | MAE | 0.0942 | 0.1331 | 0.2525 | 0.2389 | 0.3108 | 0.3232 | 0.2825 | |
| 5 | R2 | 94.33% | 88.97% | 61.40% | 64.34% | 45.73% | 41.39% | 54.14% | |
| A_2 | 5 | MSE | 0.0065 | 0.0097 | 0.0249 | 0.0249 | 0.0573 | 0.0669 | 0.0429 |
| 5 | RMSE | 0.0808 | 0.0987 | 0.1579 | 0.1579 | 0.2394 | 0.2587 | 0.2070 | |
| 5 | MAE | 0.0609 | 0.0739 | 0.1175 | 0.1182 | 0.1859 | 0.2010 | 0.1595 | |
| 5 | R2 | 96.85% | 95.30% | 87.97% | 87.96% | 72.35% | 67.72% | 79.32% | |
| A_3 | 5 | MSE | 0.0040 | 0.0055 | 0.0124 | 0.0114 | 0.0299 | 0.0321 | 0.0244 |
| 5 | RMSE | 0.0634 | 0.0741 | 0.1115 | 0.1066 | 0.173 | 0.179 | 0.1563 | |
| 5 | MAE | 0.0458 | 0.0537 | 0.0798 | 0.0763 | 0.1329 | 0.1365 | 0.1200 | |
| 5 | R2 | 98.15% | 97.48% | 94.29% | 94.78% | 86.26% | 85.27% | 88.78% | |
| A_4 | 5 | MSE | 0.0041 | 0.0164 | 0.0187 | 0.0180 | 0.0440 | 0.0495 | 0.0350 |
| 5 | RMSE | 0.0644 | 0.1281 | 0.1367 | 0.1343 | 0.2097 | 0.2226 | 0.1870 | |
| 5 | MAE | 0.0470 | 0.0912 | 0.0957 | 0.0938 | 0.1597 | 0.1690 | 0.1414 | |
| 5 | R2 | 97.26% | 89.14% | 87.64% | 88.07% | 70.91% | 67.21% | 76.87% |
| data set | Point | Metrics | EMD-BiGRU | EMD-GRU | BiGRU | GRU | GBR | RFR | SVR |
|---|---|---|---|---|---|---|---|---|---|
| A_1 | 5 | MSE | 0.0160 | 0.0311 | 0.1088 | 0.1005 | 0.1529 | 0.1652 | 0.1292 |
| 5 | RMSE | 0.1264 | 0.1763 | 0.3298 | 0.3170 | 0.3910 | 0.4064 | 0.3595 | |
| 5 | MAE | 0.0942 | 0.1331 | 0.2525 | 0.2389 | 0.3108 | 0.3232 | 0.2825 | |
| 5 | R2 | 94.33% | 88.97% | 61.40% | 64.34% | 45.73% | 41.39% | 54.14% | |
| A_1 | 10 | MSE | 0.0159 | 0.0293 | 0.0730 | 0.0740 | 0.1762 | 0.1864 | 0.1571 |
| 10 | RMSE | 0.1260 | 0.1711 | 0.2702 | 0.2720 | 0.4197 | 0.4317 | 0.3963 | |
| 10 | MAE | 0.0987 | 0.1327 | 0.2133 | 0.2138 | 0.3328 | 0.3430 | 0.3119 | |
| 10 | R2 | 94.49% | 89.84% | 74.67% | 74.32% | 38.87% | 35.32% | 45.49% | |
| A_1 | 15 | MSE | 0.0279 | 0.0404 | 0.1008 | 0.0811 | 0.1865 | 0.1968 | 0.17 |
| 15 | RMSE | 0.1670 | 0.2009 | 0.3176 | 0.2847 | 0.4319 | 0.4436 | 0.4123 | |
| 15 | MAE | 0.1293 | 0.1574 | 0.2497 | 0.2234 | 0.3435 | 0.353 | 0.3252 | |
| 15 | R2 | 90.30% | 85.96% | 64.91% | 71.79% | 35.10% | 31.54% | 40.84% | |
| A_1 | 20 | MSE | 0.0327 | 0.0458 | 0.1782 | 0.0849 | 0.2002 | 0.2087 | 0.1866 |
| 20 | RMSE | 0.1809 | 0.2141 | 0.4222 | 0.2914 | 0.4475 | 0.4568 | 0.432 | |
| 20 | MAE | 0.1427 | 0.1693 | 0.3314 | 0.2298 | 0.3557 | 0.3633 | 0.3417 | |
| 20 | R2 | 88.57% | 83.99% | 37.75% | 70.35% | 30.08% | 27.11% | 34.82% |
| Structural Conditions | Label | Description |
|---|---|---|
| Case one | State#12 | Gap = 0.20 mm |
| Case two | State#16 | Gap = 0.20 mm + 1.2 kg mass at the base |
| Case three | State#21 | Column: 3BD–50% stiffness reduction |
| Case four | State#23 | Column: 2AD + 2BD–50% stiffness reduction |
| Structural Conditions | 10 Points | 15 Points | 20 Points | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MSE | RMSE | MAE | R2 | MSE | RMSE | MAE | R2 | MSE | RMSE | MAE | R2 | |
| Case one | 0.0118 | 0.1084 | 0.0842 | 95.81% | 0.0149 | 0.1221 | 0.0954 | 94.70% | 0.0235 | 0.1532 | 0.1204 | 91.57% |
| Case two | 0.0064 | 0.0799 | 0.0623 | 96.71% | 0.0092 | 0.096 | 0.0746 | 95.27% | 0.0155 | 0.1243 | 0.0980 | 92.12% |
| Case three | 0.0119 | 0.1092 | 0.0848 | 95.54% | 0.0143 | 0.1195 | 0.0937 | 94.49% | 0.0261 | 0.1617 | 0.1282 | 90.02% |
| Case four | 0.0093 | 0.0965 | 0.0753 | 96.44% | 0.0131 | 0.1146 | 0.0894 | 94.99% | 0.0255 | 0.1610 | 0.1275 | 90.10% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, D.; Bao, Y.; He, Y.; Zhang, L. A Data Loss Recovery Technique Using EMD-BiGRU Algorithm for Structural Health Monitoring. Appl. Sci. 2021, 11, 10072. https://doi.org/10.3390/app112110072
Liu D, Bao Y, He Y, Zhang L. A Data Loss Recovery Technique Using EMD-BiGRU Algorithm for Structural Health Monitoring. Applied Sciences. 2021; 11(21):10072. https://doi.org/10.3390/app112110072
Chicago/Turabian StyleLiu, Die, Yihao Bao, Yingying He, and Likai Zhang. 2021. "A Data Loss Recovery Technique Using EMD-BiGRU Algorithm for Structural Health Monitoring" Applied Sciences 11, no. 21: 10072. https://doi.org/10.3390/app112110072
APA StyleLiu, D., Bao, Y., He, Y., & Zhang, L. (2021). A Data Loss Recovery Technique Using EMD-BiGRU Algorithm for Structural Health Monitoring. Applied Sciences, 11(21), 10072. https://doi.org/10.3390/app112110072