
A Query Expansion Method Using Multinomial Naive Bayes

 , , and
, , and
Abstract
:1. Introduction
Related Works
2. Materials and Methods
2.1. Text Preprocessing and Matching
- represents the word count in the document D;
- represents the word count in the document collection;
- default.
2.2. Corpus
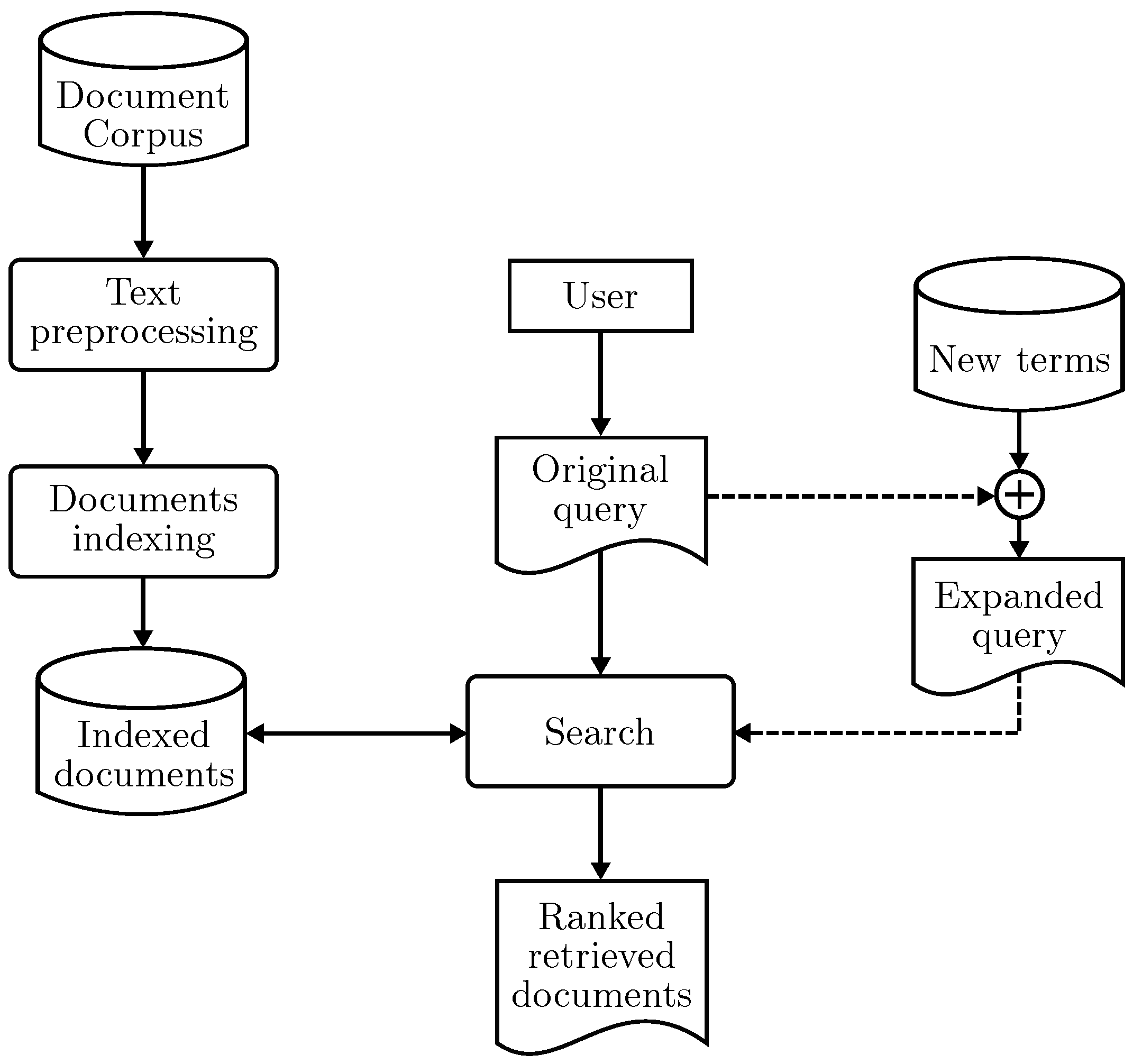
2.3. System Architecture
2.3.1. Combined Query (CQ)
- #band(w1 w2 … wn) returns documents containing all the terms w1, w2, …, wn;
- #combine (w1 w2 … wn) returns a scored list of documents that contains at least one of the terms;
- #syn(w1 w2 … wn) returns the score of documents containing one of the terms w1, w2,…, wn, but considering these as synonyms.
2.3.2. Extraction of New Terms
2.3.3. Attribute Selection
2.3.4. Multinomial Naive Bayes
2.4. Expanded Query
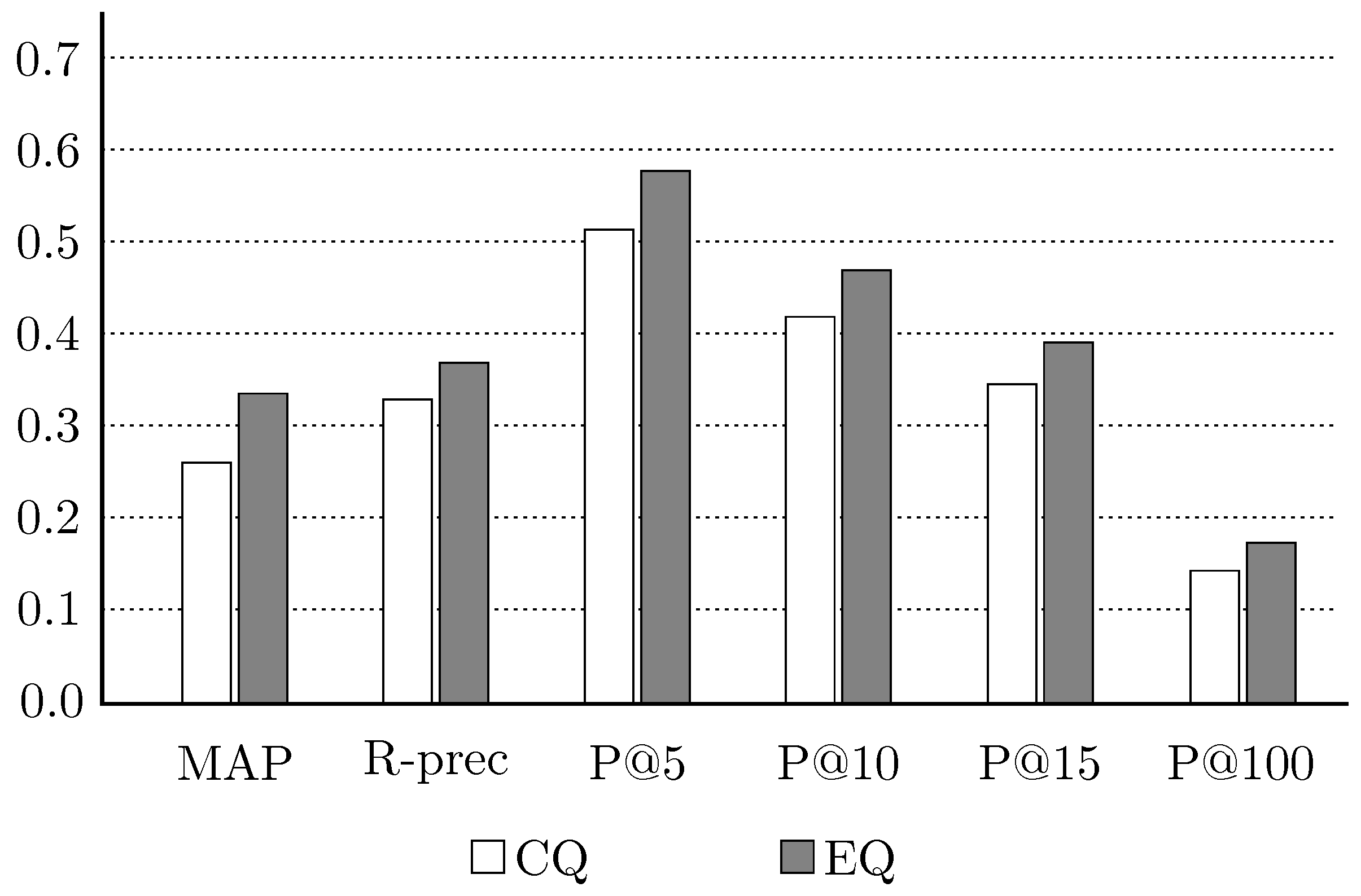
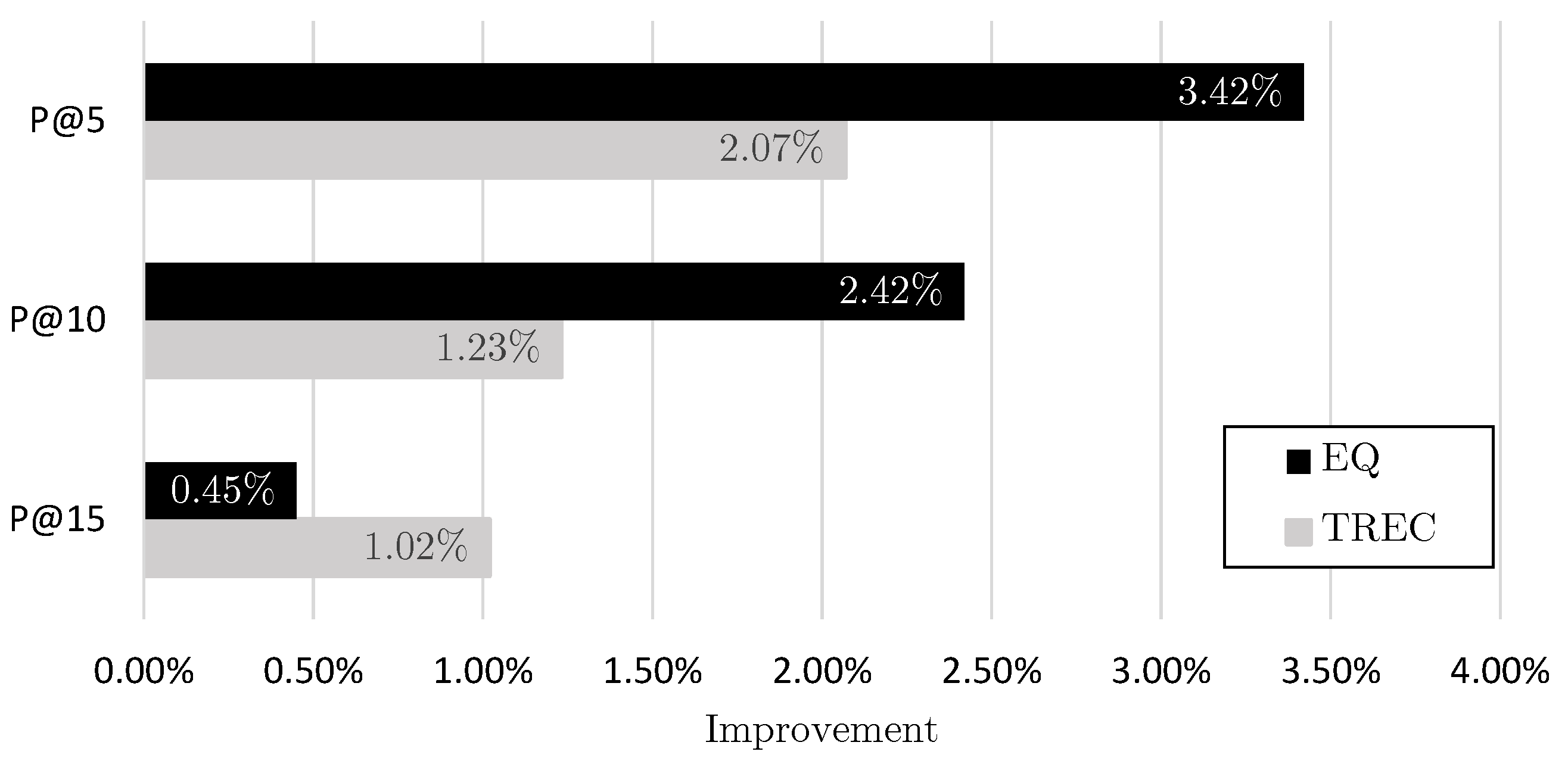
3. Results and Discussion
- k is the rank in the sequence of retrieved documents;
- n is the number of retrieved documents;
- is a binary function that assumes the value of 1 if the item at rank k is a relevant document, and zero if otherwise;
- is the precision at cut-off k on the list.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Azad, H.K.; Deepak, A. Query expansion techniques for information retrieval: A survey. Inf. Process. Manag. 2019, 56, 1698–1735. [Google Scholar] [CrossRef] [Green Version]
- Zhu, D.; Wu, S.; Carterette, B.; Liu, H. Using large clinical corpora for query expansion in text-based cohort identification. J. Biomed. Inform. 2014, 49, 275–281. [Google Scholar] [CrossRef] [PubMed]
- McDonald, R.; Brokos, G.I.; Androutsopoulos, I. Deep relevance ranking using enhanced document-query interactions. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, EMNLP 2018, Brussels, Belgium, 31 October–4 November 2018; pp. 1849–1860. [Google Scholar]
- Rehman, A.; Javed, K.; Babri, H.A. Feature selection based on a normalized difference measure for text classification. Inf. Process. Manag. 2017, 53, 473–489. [Google Scholar] [CrossRef]
- Araújo, G.; Mourão, A.; Magalhães, J. NOVASearch at Precision Medicine 2017. In Proceedings of the Twenty-Sixth Text REtrieval Conference (TREC 2017) Proceedings, Gaithersburg, MD, USA, 15–17 November 2017. [Google Scholar]
- Afuan, L.; Ashari, A.; Suyanto, Y. A Study: Query Expansion Methods in Information Retrieval. J. Phys. Conf. Ser. 2019, 1367, 012001. [Google Scholar]
- Agosti, M.; Di Nunzio, G.M.; Marchesin, S. An analysis of query reformulation techniques for precision medicine. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 973–976. [Google Scholar]
- Xu, B.; Lin, H.; Yang, L.; Xu, K.; Zhang, Y.; Zhang, D.; Yang, Z.; Wang, J.; Lin, Y.; Yin, F. A supervised term ranking model for diversity enhanced biomedical information retrieval. BMC Bioinform. 2019, 20, 1–11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, J.; Pan, M.; He, T.; Huang, X.; Wang, X.; Tu, X. A Pseudo-relevance feedback framework combining relevance matching and semantic matching for information retrieval. Inf. Process. Manag. 2020, 57. [Google Scholar] [CrossRef]
- Junior, J.R.C. Desenvolvimento de uma Metodologia para Mineração de Textos; Pontificia Universidad Catolica de Rio de Janeiro: Rio de janeiro, Brasil, 2007. [Google Scholar]
- Porter, M.F. An algorithm for suffix stripping. Program 1980, 14, 130–137. [Google Scholar] [CrossRef]
- Zipf, G.K. Human Behaviour and the Principle of Least-Effort: An Introduction to Human Ecology; Martino Fine Books: Eastford, CT, USA, 1949. [Google Scholar]
- Baeza-Yates, R.A.; Ribeiro-Neto, B. Modern Information Retrieval; Addison-Wesley Longman: Reading, MA, USA, 1999. [Google Scholar]
- Gauch, S.; Wang, J.; Rachakonda, S.M. A corpus analysis approach for automatic query expansion and its extension to multiple databases. ACM Trans. Inf. Syst. (TOIS) 1999, 17, 250–269. [Google Scholar] [CrossRef]
- Crouch, C.J.; Yang, B. Experiments in automatic statistical thesaurus construction. In Proceedings of the 15th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Copenhagen, Denmark, 21–24 June 1992; pp. 77–88. [Google Scholar]
- Qiu, Y.; Frei, H.P. Concept based query expansion. In Proceedings of the 16th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Pittsburgh, PA, USA, 27 June–1 July 1993; pp. 160–169. [Google Scholar]
- Liddy, E.D.; Myaeng, S.H. DR-LINK’s linguistic-conceptual approach to document detection. In Proceedings of the 1st Text Retrieval Conf. (TREC-1), Gaithersburg, MD, USA, 4–6 November 1992. [Google Scholar] [CrossRef] [Green Version]
- Voorhees, E.M. Query Expansion Using Lexical-Semantic Relations; SIGIR ’94; Springer: London, UK, 1994; pp. 61–69. [Google Scholar]
- Miller, G.A.; Beckwith, R.; Fellbaum, C.; Gross, D.; Miller, K.J. Introduction to WordNet: An on-line lexical database. Int. J. Lexicogr. 1990, 3, 235–244. [Google Scholar] [CrossRef] [Green Version]
- Borrajo, L.; Romero, R.; Iglesias, E.L.; Marey, C.R. Improving imbalanced scientific text classification using sampling strategies and dictionaries. J. Integr. Bioinform. 2011, 8, 90–104. [Google Scholar] [CrossRef]
- Hirschman, L.; Yeh, A.; Blaschke, C.; Valencia, A. Overview of BioCreAtIvE: critical assessment of information extraction for biology. BMC Bioinform. 2005, 6, S1. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, G. Recognizing names in biomedical texts using hidden markov model and SVM plus sigmoid. In Proceedings of the International Joint Workshop on Natural Language Processing in Biomedicine and Its Applications (NLPBA/BioNLP), Geneva, Switzerland, 28–29 August 2004; pp. 1–7. [Google Scholar]
- Apweiler, R.; Bairoch, A.; Wu, C.H.; Barker, W.C.; Boeckmann, B.; Ferro, S.; Gasteiger, E.; Huang, H.; Lopez, R.; Magrane, M.; et al. UniProt: the universal protein knowledgebase. Nucleic Acids Res. 2004, 32, D115–D119. [Google Scholar] [CrossRef]
- Strohman, T.; Metzler, D.; Turtle, H.; Croft, W.B. Indri: A language model-based search engine for complex queries. In Proceedings of the International Conference on Intelligent Analysis, Atlanta, GA, USA, 19–20 May 2005; Volume 2, pp. 2–6. [Google Scholar]
- Turtle, H.; Flood, J. Query evaluation: strategies and optimizations. Inf. Process. Manag. 1995, 31, 831–850. [Google Scholar] [CrossRef]
- Hiemstra, D.; van Leeuwen, D. Creating a Dutch information retrieval test corpus. In Computational Linguistics in the Netherlands 2001; Brill Rodopi: Leiden, The Netherlands, 2002; pp. 133–147. [Google Scholar]
- Roberts, K.; Demner-Fushman, D.; Voorhees, E.M.; Hersh, W.R.; Bedrick, S.; Lazar, A.J.; Pant, S. Overview of the TREC 2017 precision medicine track. In Proceedings of the Text Retrieval Conference (TREC) NIH Public Access, Gaithersburg, MD, USA, 15–17 November 2017; Volume 26. [Google Scholar]
- Mitra, M.; Singhal, A.; Buckley, C. Improving automatic query expansion. In Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Melbourne, Australia, 24–28 August 1998; pp. 206–214. [Google Scholar]
- Raschka, S. Naive Bayes and Text Classification I-Introduction and Theory. arXiv 2014, arXiv:1410.5329. [Google Scholar]
- Mahmood, A.A.; Li, G.; Rao, S.; McGarvey, P.B.; Wu, C.H.; Madhavan, S.; Vijay-Shanker, K. UD_GU_BioTM at TREC 2017: Precision Medicine Track; TREC: Gaithersburg, MD, USA, 2017. [Google Scholar]










{kind=link}
{kind=link}
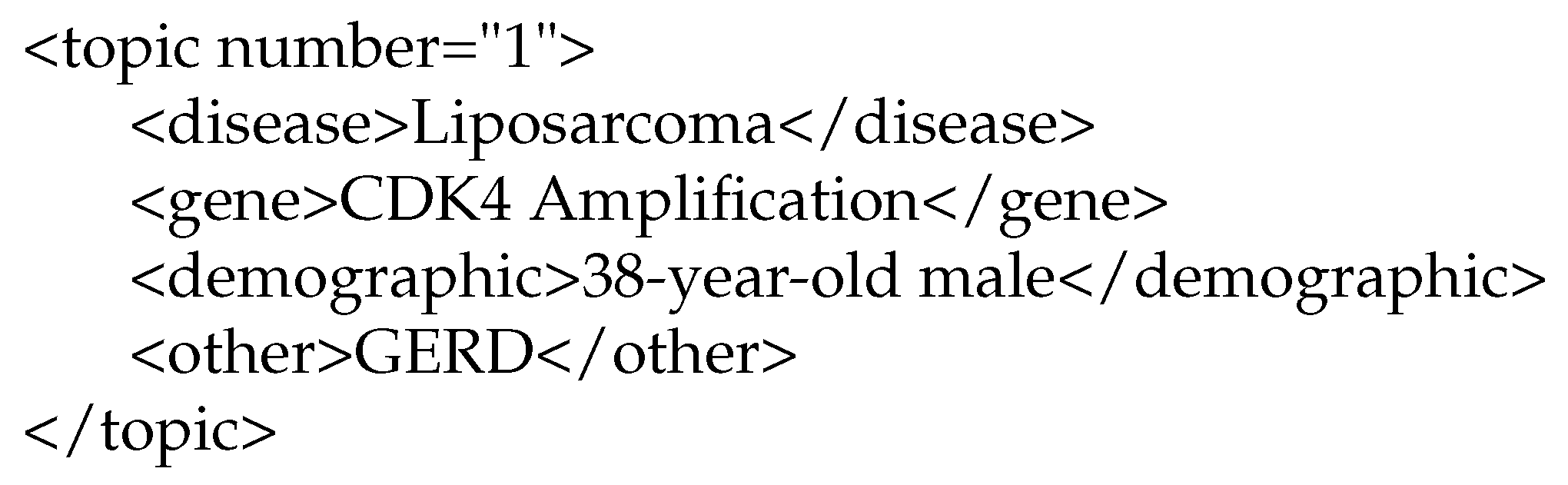{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MAP | R-prec | P@5 | P@10 | P@15 | P@100 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Query | CQ | EQ | CQ | EQ | CQ | EQ | CQ | EQ | CQ | EQ | CQ | EQ |
| 1 | 0.293 | 0.408 | 0.353 | 0.353 | 1.000 | 1.000 | 0.500 | 0.600 | 0.333 | 0.400 | 0.050 | 0.080 |
| 2 | 0.243 | 0.345 | 0.394 | 0.402 | 0.800 | 0.600 | 0.700 | 0.700 | 0.733 | 0.733 | 0.440 | 0.450 |
| 3 | 0.405 | 0.615 | 0.417 | 0.625 | 1.000 | 1.000 | 0.900 | 0.800 | 0.667 | 0.733 | 0.100 | 0.200 |
| 4 | 0.410 | 0.454 | 0.491 | 0.509 | 0.600 | 0.800 | 0.600 | 0.700 | 0.600 | 0.533 | 0.360 | 0.380 |
| 5 | 0.205 | 0.173 | 0.194 | 0.194 | 0.200 | 0.000 | 0.100 | 0.200 | 0.133 | 0.200 | 0.210 | 0.170 |
| 6 | 0.404 | 0.411 | 0.444 | 0.370 | 1.000 | 1.000 | 0.700 | 0.500 | 0.600 | 0.533 | 0.160 | 0.170 |
| 7 | 0.369 | 0.571 | 0.390 | 0.546 | 0.600 | 1.000 | 0.600 | 0.900 | 0.667 | 0.867 | 0.480 | 0.680 |
| 8 | 0.450 | 0.504 | 0.541 | 0.525 | 0.600 | 0.800 | 0.600 | 0.700 | 0.667 | 0.667 | 0.420 | 0.420 |
| 9 | 0.314 | 0.520 | 0.339 | 0.532 | 0.600 | 0.800 | 0.600 | 0.800 | 0.467 | 0.600 | 0.300 | 0.460 |
| 11 | 0.319 | 0.402 | 0.316 | 0.368 | 0.600 | 0.800 | 0.400 | 0.600 | 0.333 | 0.400 | 0.150 | 0.140 |
| 12 | 0.118 | 0.266 | 0.231 | 0.256 | 0.600 | 0.800 | 0.300 | 0.700 | 0.200 | 0.467 | 0.100 | 0.190 |
| 13 | 0.090 | 0.161 | 0.324 | 0.206 | 0.200 | 0.200 | 0.200 | 0.200 | 0.267 | 0.200 | 0.110 | 0.120 |
| 14 | 0.579 | 0.563 | 0.714 | 0.714 | 0.800 | 0.800 | 0.500 | 0.500 | 0.333 | 0.333 | 0.050 | 0.060 |
| 15 | 0.250 | 0.253 | 0.250 | 0.250 | 0.200 | 0.200 | 0.100 | 0.100 | 0.067 | 0.067 | 0.010 | 0.010 |
| 16 | 0.300 | 0.327 | 0.400 | 0.400 | 0.400 | 0.400 | 0.200 | 0.200 | 0.133 | 0.133 | 0.020 | 0.040 |
| 17 | 0.150 | 0.191 | 0.303 | 0.303 | 0.400 | 0.400 | 0.400 | 0.400 | 0.400 | 0.533 | 0.090 | 0.090 |
| 18 | 0.000 | 0.044 | 0.000 | 0.079 | 0.000 | 0.200 | 0.000 | 0.200 | 0.000 | 0.133 | 0.020 | 0.050 |
| 19 | 0.044 | 0.307 | 0.044 | 0.304 | 0.200 | 0.400 | 0.100 | 0.400 | 0.067 | 0.267 | 0.010 | 0.130 |
| 20 | 0.200 | 0.234 | 0.200 | 0.200 | 0.200 | 0.200 | 0.100 | 0.100 | 0.067 | 0.067 | 0.040 | 0.040 |
| 21 | 0.088 | 0.246 | 0.209 | 0.269 | 0.400 | 0.600 | 0.500 | 0.300 | 0.400 | 0.333 | 0.190 | 0.240 |
| 22 | 0.059 | 0.087 | 0.118 | 0.147 | 0.600 | 0.400 | 0.600 | 0.400 | 0.400 | 0.333 | 0.120 | 0.160 |
| 23 | 0.243 | 0.236 | 0.367 | 0.333 | 0.400 | 0.200 | 0.500 | 0.400 | 0.400 | 0.333 | 0.190 | 0.170 |
| 24 | 0.333 | 0.580 | 0.333 | 0.556 | 1.000 | 1.000 | 0.600 | 0.900 | 0.400 | 0.667 | 0.060 | 0.110 |
| 25 | 0.265 | 0.459 | 0.375 | 0.475 | 0.600 | 0.800 | 0.600 | 0.900 | 0.467 | 0.733 | 0.210 | 0.250 |
| 26 | 0.213 | 0.225 | 0.200 | 0.200 | 0.200 | 0.200 | 0.100 | 0.100 | 0.067 | 0.067 | 0.010 | 0.010 |
| 27 | 0.250 | 0.313 | 0.393 | 0.429 | 0.400 | 0.800 | 0.500 | 0.500 | 0.400 | 0.400 | 0.080 | 0.110 |
| 28 | 0.250 | 0.250 | 0.500 | 0.500 | 0.200 | 0.200 | 0.100 | 0.100 | 0.067 | 0.067 | 0.010 | 0.010 |
| 29 | 0.277 | 0.385 | 0.250 | 0.375 | 0.400 | 0.600 | 0.200 | 0.300 | 0.133 | 0.200 | 0.010 | 0.020 |
| 30 | 0.263 | 0.198 | 0.600 | 0.290 | 0.600 | 0.600 | 0.400 | 0.400 | 0.400 | 0.400 | 0.110 | 0.120 |
| ALL | 0.261 | 0.335 | 0.330 | 0.369 | 0.514 | 0.579 | 0.418 | 0.469 | 0.347 | 0.393 | 0.142 | 0.175 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Silva, S.; Seara Vieira, A.; Celard, P.; Iglesias, E.L.; Borrajo, L. A Query Expansion Method Using Multinomial Naive Bayes. Appl. Sci. 2021, 11, 10284. https://doi.org/10.3390/app112110284
Silva S, Seara Vieira A, Celard P, Iglesias EL, Borrajo L. A Query Expansion Method Using Multinomial Naive Bayes. Applied Sciences. 2021; 11(21):10284. https://doi.org/10.3390/app112110284
Chicago/Turabian StyleSilva, Sergio, Adrián Seara Vieira, Pedro Celard, Eva Lorenzo Iglesias, and Lourdes Borrajo. 2021. "A Query Expansion Method Using Multinomial Naive Bayes" Applied Sciences 11, no. 21: 10284. https://doi.org/10.3390/app112110284
APA StyleSilva, S., Seara Vieira, A., Celard, P., Iglesias, E. L., & Borrajo, L. (2021). A Query Expansion Method Using Multinomial Naive Bayes. Applied Sciences, 11(21), 10284. https://doi.org/10.3390/app112110284