
Enhance Text-to-Text Transfer Transformer with Generated Questions for Thai Question Answering


Abstract
:1. Introduction
- We present a data preprocessing method for the Thai Language.
- We demonstrate fine-tuning of two Transformer based models, WangchanBERTa and mT5, for the QA task, with synthesized data and real human-labeled corpus, and achieve higher EM and F1 scores than those when using only the real human-labeled data.
- We compare the quality of the generated question-answer pairs used in the QA models as well as training strategies.
- We propose new metrics: Syllable-level F1 to evaluate the models along with the original Word-level F1.
2. Literature Review
2.1. Recent Research in Question Answering
2.2. Researches in Thai Question Answering
2.3. Data Augmentation Methods
2.4. The Text-to-Text Transfer Transformer Model
2.5. The WangchanBERTa Model
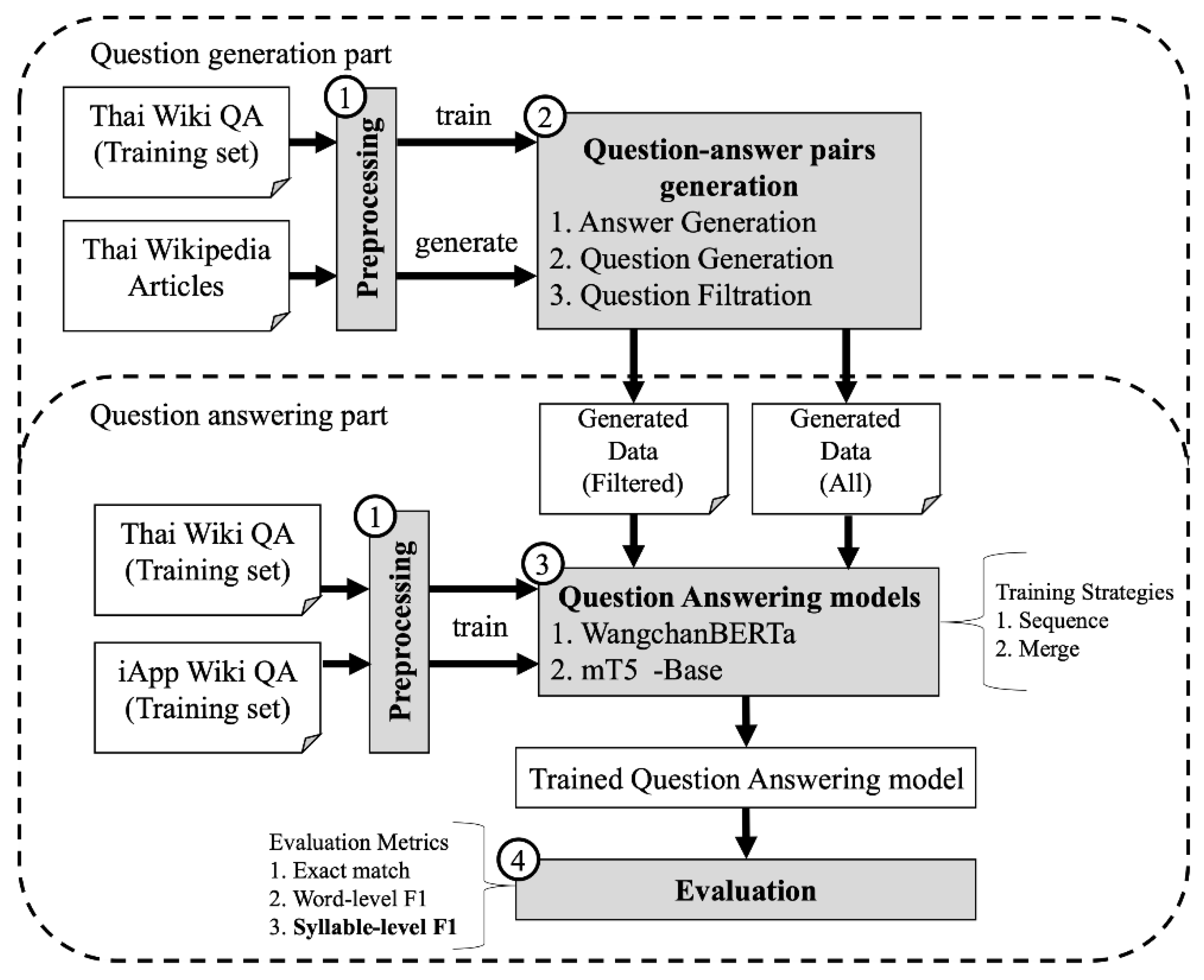
3. Proposed Method
3.1. Preprocessing Methods for Thai Texts
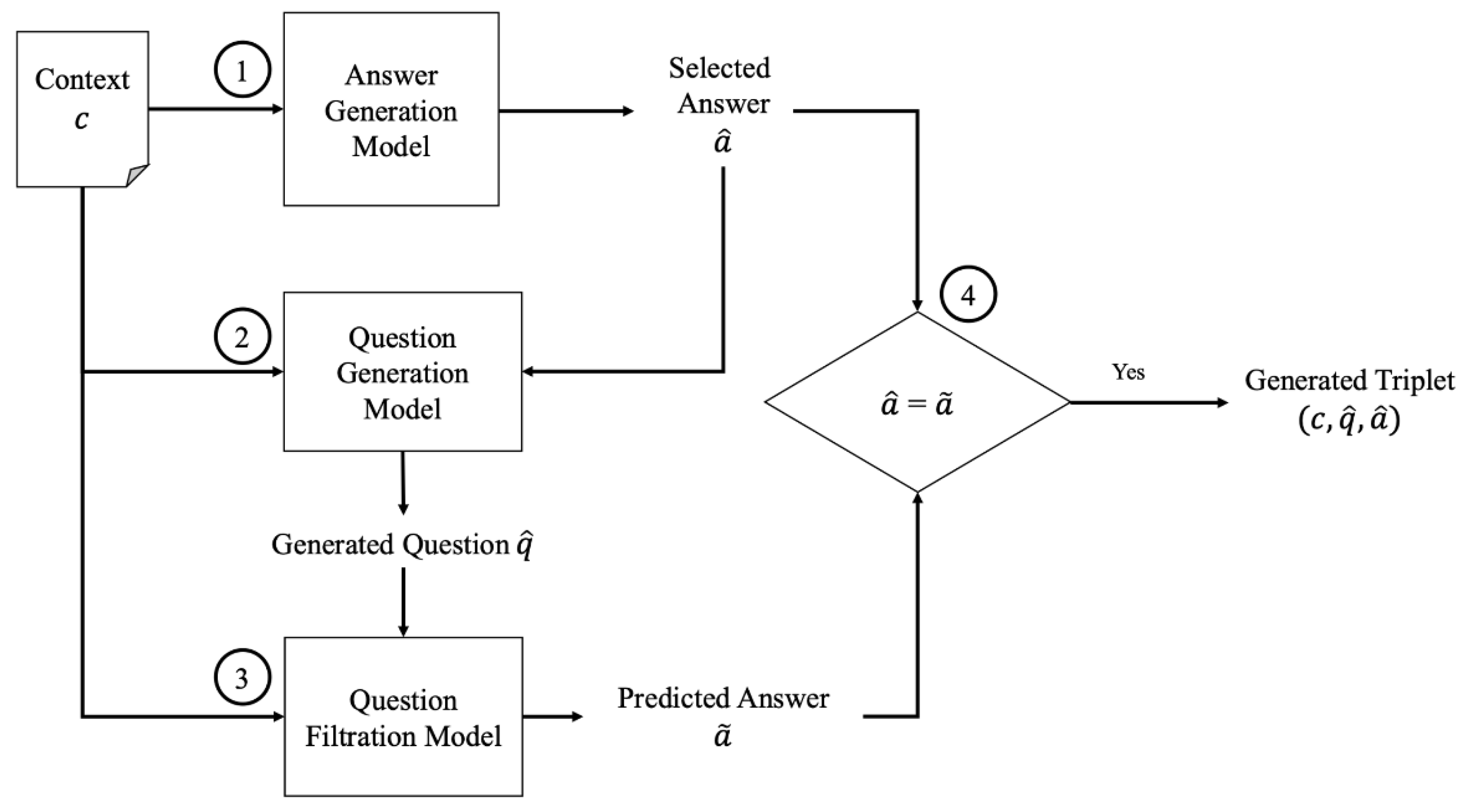
3.2. Question-Answer Pairs Generation
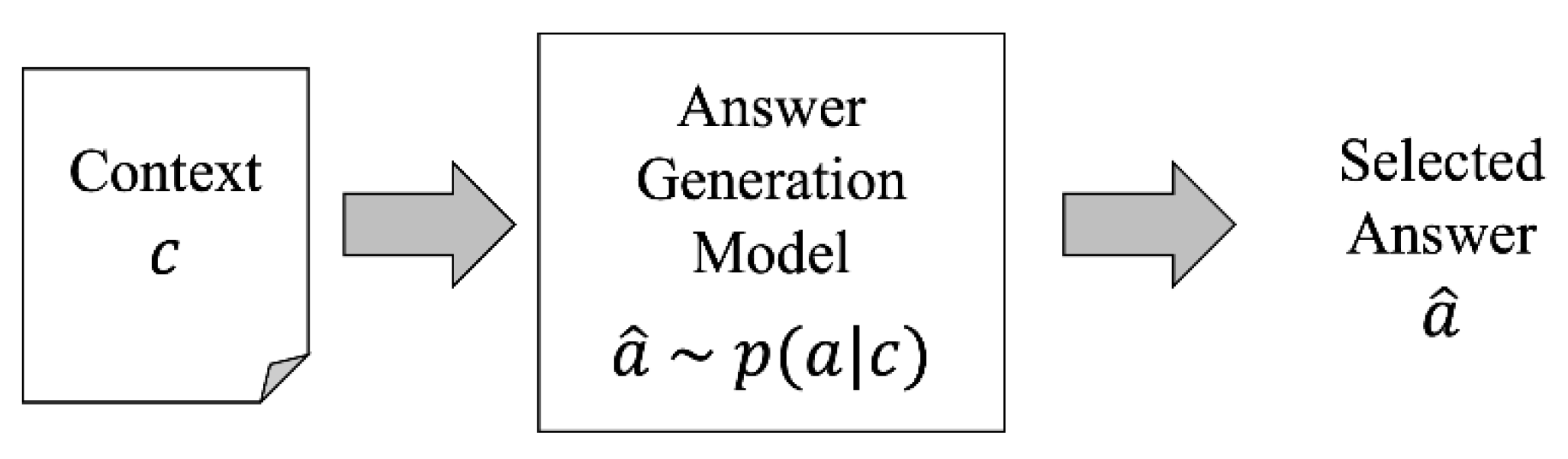
3.2.1. Step 1: Answer Generation
3.2.2. Step 2: Question Generation
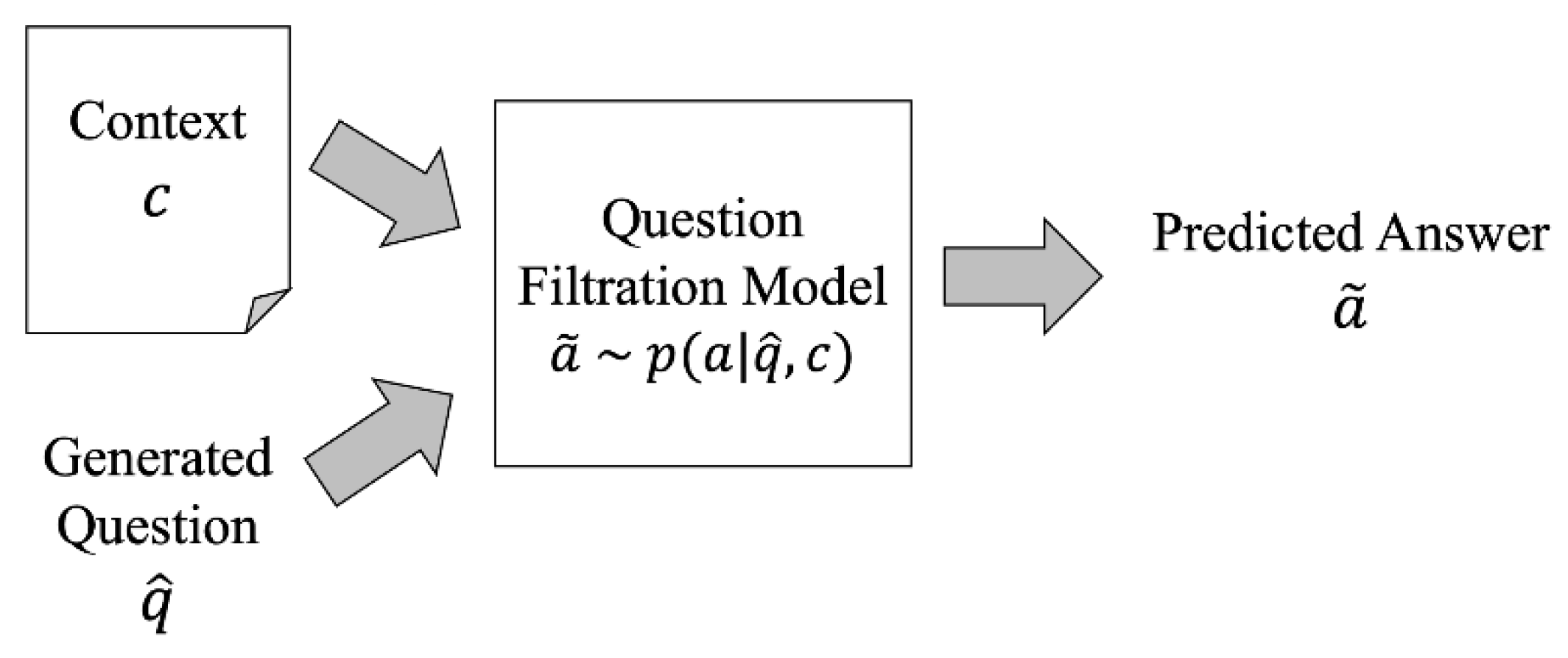
3.2.3. Step 3: Question Filtration
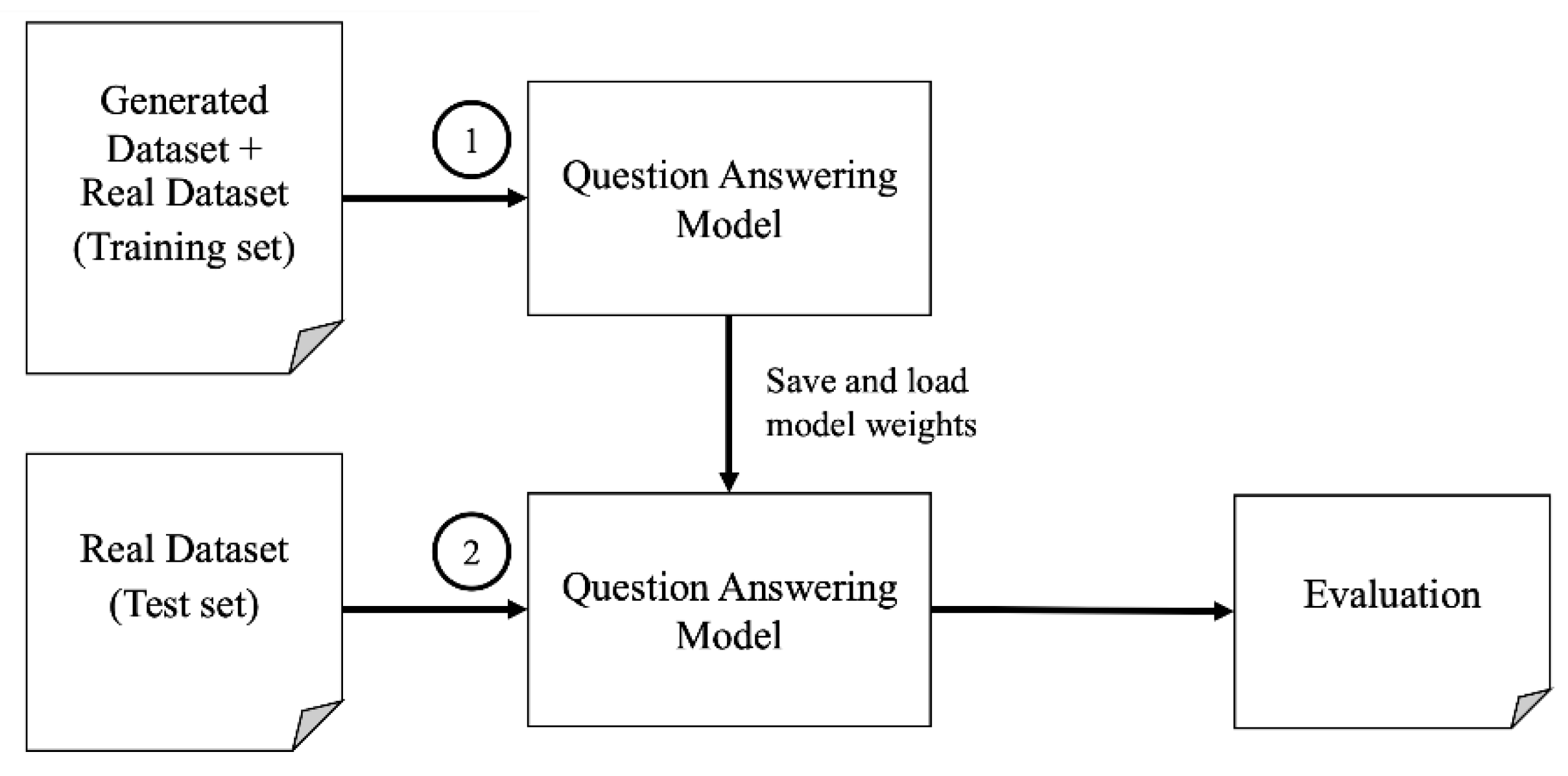
3.3. Question Answering Models Training
3.4. Model Evaluation
4. Experiment Setup
4.1. Datasets
4.2. Tools and Parameter Setup
5. Results
5.1. Overall Results
5.2. Comparison of the Training Strategies
5.3. Comparison of Using Different Qualities of the Generated Question-Answer Pairs
5.4. Comparison of the Baseline Models
5.5. Comparison of the Syllable-Level F1
6. Discussion
6.1. Analysis of Model Improvement
6.2. Model Performance Analysis by Question Types
- Who: a group of questions that requires an answer as a person name
- What: a group of questions that requires an answer as a thing or a name of things
- Where: a group of questions that requires an answer as a name of places, for instance, countries, provinces, or states
- Year: a group of questions that requires an answer as a year, either Common Era (C.E.) or Buddhist Era (B.E.)
- Date: a group of questions that requires an answer as a date
- Number: a group of questions that requires an answer as a number
6.3. Word Tokenizer Choices
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv 2019, arXiv:1910.10683. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Dodge, J.; Sap, M.; Marasovic, A.; Agnew, W.; Ilharco, G.; Groeneveld, D.; Gardner, M. Documenting the english colossal clean crawled corpus. arXiv 2021, arXiv:2104.08758. [Google Scholar]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. Squad: 100,000+ questions for machine comprehension of text. arXiv 2016, arXiv:1606.05250. [Google Scholar]
- Decha, H.; Patanukhom, K. Development of thai question answering system. In Proceedings of the 3rd International Conference on Communication and Information Processing, Tokyo, Japan, 24–26 November 2017; pp. 124–128. [Google Scholar]
- Seo, M.; Kembhavi, A.; Farhadi, A.; Hajishirzi, H. Bidirectional attention flow for machine comprehension. arXiv 2016, arXiv:1611.01603. [Google Scholar]
- Lapchaicharoenkit, T.; Vateekul, P. Machine Reading Comprehension on Multiclass Questions Using Bidirectional Attention Flow Models with Contextual Embeddings and Transfer Learning in Thai Corpus. In Proceedings of the 8th International Conference on Computer and Communications Management, Singapore, 17–19 July 2020; pp. 3–8. [Google Scholar]
- Trakultaweekoon, K.; Thaiprayoon, S.; Palingoon, P.; Rugchatjaroen, A. The first wikipedia questions and factoid answers corpus in the thai language. In Proceedings of the 2019 14th International Joint Symposium on Artificial Intelligence and Natural Language Processing (iSAI-NLP), Chiang Mai, Thailand, 7–9 November 2019; pp. 1–4. [Google Scholar]
- Puri, R.; Spring, R.; Patwary, M.; Shoeybi, M.; Catanzaro, B. Training question answering models from synthetic data. arXiv 2020, arXiv:2002.09599. [Google Scholar]
- Lowphansirikul, L.; Polpanumas, C.; Jantrakulchai, N.; Nutanong, S. WangchanBERTa: Pretraining transformer-based Thai Language Models. arXiv 2021, arXiv:2101.09635. [Google Scholar]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; Al-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. mt5: A massively multilingual pre-trained text-to-text transformer. arXiv 2020, arXiv:2010.11934. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Joshi, M.; Chen, D.; Liu, Y.; Weld, D.S.; Zettlemoyer, L.; Levy, O. Spanbert: Improving pre-training by representing and predicting spans. Trans. Assoc. Comput. Linguist. 2020, 8, 64–77. [Google Scholar] [CrossRef]
- Dhingra, B.; Pruthi, D.; Rajagopal, D. Simple and effective semi-supervised question answering. arXiv 2018, arXiv:1804.00720. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Phatthiyaphaibun, W.; Suriyawongkul, A.; Chormai, P.; Lowphansirikul, L.; Siwatammarat, P.; Tanruangporn, P.P.; Charoenchainetr, P.; Udomcharoenchaikit, C.; Janthong, A.; Chaovavanichet, K.; et al. PyThaiNLP/pythainlp: PyThaiNLP v2.3.2 Release! Zenodo 2021. [Google Scholar] [CrossRef]
- Zeng, C.; Li, S.; Li, Q.; Hu, J.; Hu, J. A Survey on Machine Reading Comprehension—Tasks, Evaluation Metrics and Benchmark Datasets. Appl. Sci. 2020, 10, 7640. [Google Scholar] [CrossRef]
- Wolf, T.; Chaumond, J.; Debut, L.; Sanh, V.; Delangue, C.; Moi, A.; Cistac, P.; Funtowicz, M.; Davison, J.; Shleifer, S. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Chormai, P.; Prasertsom, P.; Rutherford, A. AttaCut: A Fast and Accurate Neural Thai Word Segmenter. arXiv 2019, arXiv:1911.07056. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Implementation | Answer Generation | Question Generation | Question Filtration |
|---|---|---|---|
| Raul Puri et al. | BERT | GPT-2 | BERT |
| Our | mT5-Large | mT5-Large | WangchanBERTa |
| Original Word | Human-Tokenized | Use Word Tokenizer (newmm) | Syllable Tokenizer | |
|---|---|---|---|---|
| Ground truth | มลายู (Malay language in short term) | มลายู | มลายู | ม / ลา / ยู |
| Prediction | ภาษามลายู (Malay language) | ภาษา / มลายู | ภาษามลายู | ภา / ษา / ม / ลา / ยู |
| F1 Score | 66.6 | 0.0 | 77.49 |
| Dataset | No. of Training Set | No. of Validation Set | No. of Test Set |
|---|---|---|---|
| Thai Wiki QA | 9045 | 1005 | 4950 |
| iApp Wiki QA | 5761 | 742 | 439 |
| Thai Wiki QA | Baseline | + Filtered Generated Pairs (FLT) | + All Generated Pairs (ALL) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| EM | W-F1 | S-F1 | EM | W-F1 | S-F1 | EM | W-F1 | S-F1 | |
| WangchanBERTa (WBT) | |||||||||
| Sequence Strategy (SEQ) | 43.92 | 70.73 | 74.71 | 45.90 | 73.35 | 77.55 | 46.48 | 74.40 | 78.60 |
| Merge Strategy (MRG) | 44.63 | 71.11 | 75.15 | 43.35 | 71.09 | 75.26 | |||
| mT5-Base (mT5) | |||||||||
| Sequence Strategy (SEQ) | 64.14 | 78.24 | 80.35 | 70.42 | 83.64 | 85.29 | 69.03 | 83.02 | 84.74 |
| Merge Strategy (MRG) | 69.01 | 82.88 | 84.68 | 63.66 | 79.30 | 81.17 | |||
| iApp Wiki QA | Baseline | + Filtered Generated Pairs (FLT) | + All Generated Pairs (ALL) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| EM | W-F1 | S-F1 | EM | W-F1 | S-F1 | EM | W-F1 | S-F1 | |
| WangchanBERTa (WBT) | |||||||||
| Sequence Strategy (SEQ) | 30.58 | 69.68 | 71.81 | 32.88 | 71.81 | 74.42 | 33.15 | 72.98 | 75.14 |
| Merge Strategy (MRG) | 29.77 | 69.59 | 71.97 | 31.66 | 70.37 | 72.82 | |||
| mT5-Base (mT5) | |||||||||
| Sequence Strategy (SEQ) | 29.36 | 63.46 | 63.71 | 56.02 | 81.31 | 82.58 | 58.05 | 81.97 | 83.15 |
| Merge Strategy (MRG) | 57.10 | 81.42 | 82.57 | 53.45 | 79.53 | 80.81 | |||
| Datasets | No. Training Set | No. Training Set + Filtered Generated Pairs | No. Training Set + All Generated Pairs |
|---|---|---|---|
| Thai Wiki QA | 9045 | 62,610 (+592.2%) | 119,813 (+1224.6%) |
| iApp Wiki QA | 5761 | 59,326 (+929.8%) | 116,529 (+1922.7%) |
| Predicted Answer | Ground Truth Answer | Syllable-Level F1 |
|---|---|---|
| มหาวิทยาลัยรามคําแหง (Ramkhamhaeng University) | รามคำแหง (Ramkhamhaeng) | 66.67 |
| คณะนิติศาสตร์ (Faculty of Law) | นิติศาสตร์ (Law) | 85.71 |
| คมนาคม (Transportation) | กระทรวงคมนาคม (Ministry of Transportation) | 75.00 |
| ไม้ล้มลุกขนาดเล็ก (Small biennial plant) | ล้มลุก (Biennial) | 57.14 |
| Who | What | Where | Year | Date | Number |
|---|---|---|---|---|---|
| ใคร (Who) | อะไร (What) | ที่ไหน (Where) | ปีใด (What year) | วันที่เท่าใด (Which date) | เท่าไร (How many/much) |
| คนใด (Which one) | …ใด (What/Which …) | ที่ใด (Where) | ปีไหน (What year) | วันใด (Which date) | เท่าใด (How many/much) |
| คนไหน (Which one) | …ไหน (What/Which …) | ประเทศใด (Which country) | พ.ศ. ใด (What B.E. year) | เมื่อใด (When) | กี่… (How many/much of) |
| จังหวัดใด (Which province) | ค.ศ. ใด (What C.E. year) |
| Question Type | mT5 Baseline | mT5-SEQ-FLT | % of Improvement | ||||||
|---|---|---|---|---|---|---|---|---|---|
| EM | W-F1 | S-F1 | EM | W-F1 | S-F1 | EM | W-F1 | S-F1 | |
| Overall Performance | 64.14 | 78.24 | 80.35 | 70.42 | 83.64 | 85.29 | 9.79 | 6.90 | 6.15 |
| Who | 69.16 | 82.03 | 81.40 | 73.05 | 85.87 | 85.30 | 5.62 | 4.68 | 4.79 |
| What | 62.90 | 77.45 | 80.48 | 68.82 | 82.89 | 85.24 | 9.41 | 7.02 | 5.91 |
| Where | 67.54 | 83.23 | 83.02 | 76.61 | 88.82 | 88.93 | 13.42 | 6.72 | 7.12 |
| Year | 76.04 | 83.06 | 85.03 | 83.83 | 88.75 | 89.53 | 10.24 | 6.85 | 5.29 |
| Date | 58.88 | 79.53 | 79.21 | 72.08 | 90.13 | 89.43 | 22.42 | 13.33 | 12.90 |
| Number | 61.99 | 74.14 | 76.67 | 68.19 | 78.94 | 81.32 | 10.00 | 6.47 | 6.07 |
| Question Type | mT5 Baseline | mT5-SEQ-ALL | % of Improvement | ||||||
|---|---|---|---|---|---|---|---|---|---|
| EM | W-F1 | S-F1 | EM | W-F1 | S-F1 | EM | W-F1 | S-F1 | |
| Overall Performance | 29.36 | 63.46 | 63.71 | 58.05 | 81.97 | 83.15 | 97.72 | 29.17 | 30.51 |
| Who | 48.57 | 67.03 | 66.30 | 65.71 | 86.10 | 87.77 | 35.29 | 28.45 | 32.38 |
| What | 32.18 | 65.00 | 66.56 | 56.02 | 81.03 | 82.64 | 74.08 | 24.66 | 24.16 |
| Where | 33.33 | 68.22 | 71.85 | 55.56 | 79.72 | 85.17 | 66.69 | 16.85 | 18.54 |
| Year | 62.50 | 84.17 | 79.17 | 62.50 | 82.08 | 81.25 | 0.00 | −2.48 | 2.63 |
| Date | 9.68 | 63.91 | 58.22 | 62.90 | 87.97 | 86.43 | 549.79 | 37.64 | 48.45 |
| Number | 13.83 | 55.49 | 53.70 | 60.64 | 80.90 | 80.76 | 338.47 | 45.79 | 50.39 |
| Model | ‘Newmm’ (Word-Level F1) | AttaCut (Word-Level F1) | Syllable Tokenizer (Syllable-Level F1) |
|---|---|---|---|
| WangchanBERTa Baseline | 70.73 | 64.46 | 74.71 |
| mT5 Baseline | 78.24 | 73.58 | 80.35 |
| mT5-SEQ-FLT | 83.64 | 78.98 | 85.29 |
| Model | ‘Newmm’ (Word-Level F1) | AttaCut (Word-Level F1) | Syllable Tokenizer (Syllable-Level F1) |
|---|---|---|---|
| WangchanBERTa Baseline | 69.68 | 65.42 | 71.81 |
| mT5 Baseline | 63.46 | 59.75 | 63.71 |
| mT5-SEQ-ALL | 81.97 | 78.87 | 83.15 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Phakmongkol, P.; Vateekul, P. Enhance Text-to-Text Transfer Transformer with Generated Questions for Thai Question Answering. Appl. Sci. 2021, 11, 10267. https://doi.org/10.3390/app112110267
Phakmongkol P, Vateekul P. Enhance Text-to-Text Transfer Transformer with Generated Questions for Thai Question Answering. Applied Sciences. 2021; 11(21):10267. https://doi.org/10.3390/app112110267
Chicago/Turabian StylePhakmongkol, Puri, and Peerapon Vateekul. 2021. "Enhance Text-to-Text Transfer Transformer with Generated Questions for Thai Question Answering" Applied Sciences 11, no. 21: 10267. https://doi.org/10.3390/app112110267
APA StylePhakmongkol, P., & Vateekul, P. (2021). Enhance Text-to-Text Transfer Transformer with Generated Questions for Thai Question Answering. Applied Sciences, 11(21), 10267. https://doi.org/10.3390/app112110267