1. Introduction
Anomaly detection is an essential study field in visual image understanding. It is defined as an unexpected pattern recognition that is significantly different from the rest of the data. Some of the significant challenges include imbalanced data distribution, the difficulty of a generalizable feature extractor, variance in anomaly situations, and various environmental conditions in the data. There has been a massive surge in the availability of publicly available real-world datasets following recent trends. However, in most of these datasets, the class imbalance towards normal classes and lack of abnormal classes means these datasets lack diversity and are not capable of efficiently training supervised detection models [
1]. In addition, labeling the data is a labor-intensive and costly endeavor. Deep learning models require large amounts of data for optimal performance, and the developed systems may have only a limited utility and sub-optimal generalization [
2]. Under such cases, unsupervised anomaly detection has become the standard approach to such data distribution modeling. In such scenarios, the model is trained only with normal-designated class images to capture the data distribution. Afterward, the inference is performed with both normal and abnormal images to detect the deviation from the learned distribution of the normal data.
Various approaches have been proposed [
3,
4,
5] for different domains for anomaly detection [
6,
7,
8]. It is generally assumed that abnormal cases differ in higher and lower dimensional space, making the latent space a vital part of anomaly detection. Recent studies propose generative adversarial networks (GANs) [
9] for anomaly detection due to their efficient mapping of the data distribution of both high-dimensional and low-dimensional features [
10].
Public space is defined as a place that is open and accessible to people, including roads, public squares, parks, and beaches. Creating safer public spaces requires actions such as enhancing the security level against public security threats. Unemployment and different pathologies usually cause crime and economic inequality [
11]. An increase in the population also increases this threat caused by anonymity and weaker interpersonal ties [
12]. It is crucial to reduce the rate of urban crime to make these public spaces safer, mainly focusing on the "crime triangle"—place, victim, and the perpetrator [
13]. The location can also have effects on impeding the crime or facilitating it.
Video surveillance cameras have become a prominent part of public spaces. Surveillance cameras are given an increased allocated budget all over the world. For example, three-quarters of the Home Office budget was allocated to surveillance-related projects from 1996 to 1998 in Great Britain [
14]. In the last decade, cities in the United States have also done substantial development projects using surveillance data, 87% for areas with 250,000 or more [
15].
Violence against children is defined as all forms of violence against people under 18. This act may come from parents, caregivers, peers, or strangers. It includes physical, sexual, and emotional violence as well as witnessing the violence. An estimated 1 billion children have experienced any form of violence aged 2–17 years [
16]. This indicates that population-based surveillance of violence against the most vulnerable of the society, the children, and ordinary people is essential to target prevention and is endorsed in the United Nations 2030 Sustainable Development Agenda.
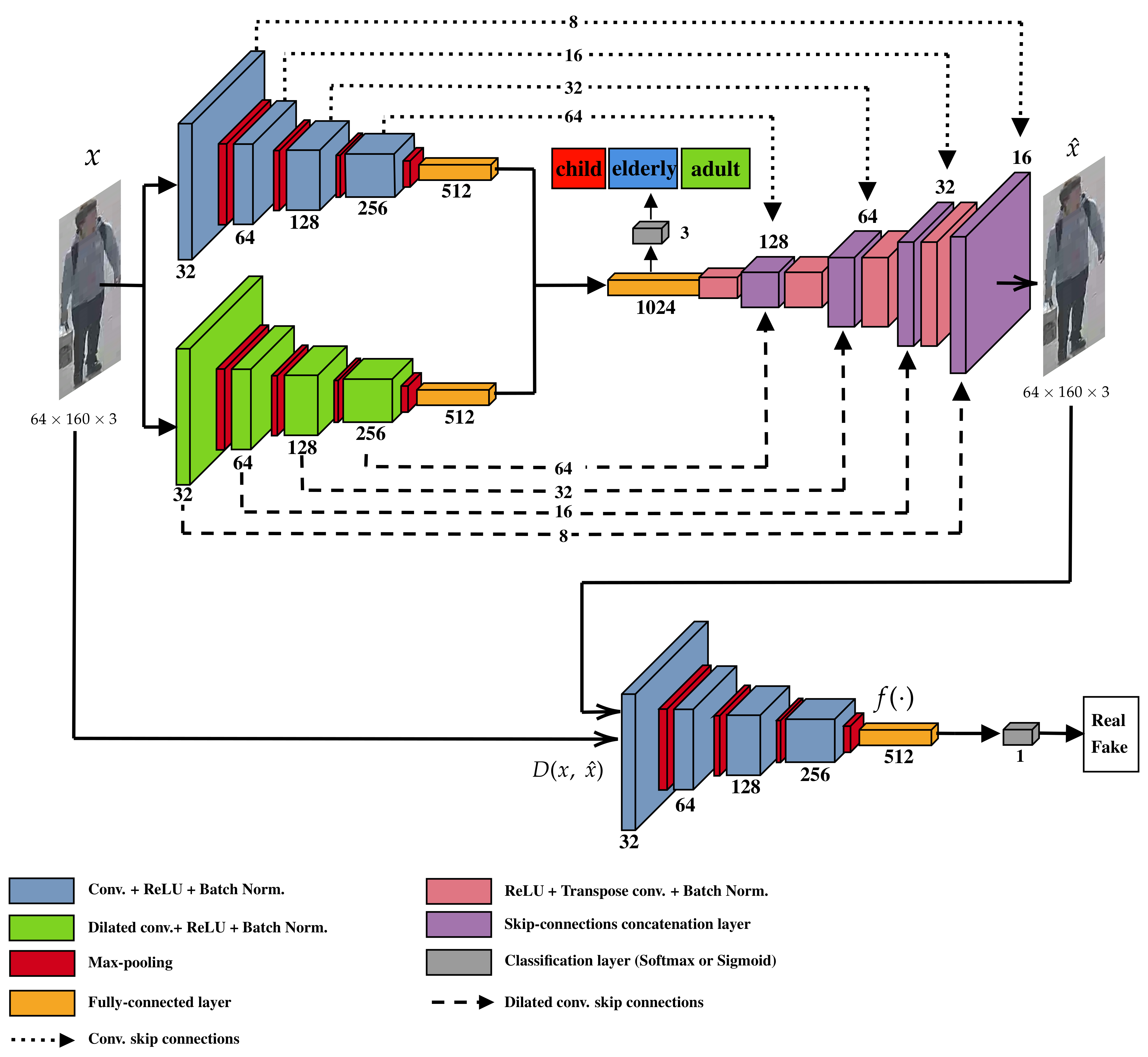
In this paper, an unsupervised anomaly detection model for different age groups of people, namely child, adults, and elderly, is proposed to achieve this goal. The proposed model has a parallel pipeline feature extractor, a conventional cascading convolutional neural network (CNN), and a cascading dilated convolutional neural network (DCN) with a dilation rate of two. At the end of both pipelines, the extracted features in the shape of fully connected layers are concatenated and then become the input for the generator, where it is used to reconstruct the original input image. The generator has partial-skip connections in a UNet-fashion [
17] from both the CNN and the DCN pipeline, which allows the information from the shallow layers to propagate more efficiently to deeper layers [
18] to alleviate the vanishing gradient problem, and the mode collapse [
19]. Afterward, both the input image and the reconstructed output image are sent to a discriminator to be distinguished as real or fake. The discriminator’s latent vector also learns the reconstructed normal input’s latent space in the proposed scheme. The motivation to combine two sub-networks comes from the dilated convolution’s capability to extract global features without increasing the computational cost [
20,
21], and the combination of both the local and the global features improves the performance of the model as it was previously applied in the field of machine learning by concatenating the extracted local and global features which are then subsequently trained with traditional machine learning classifiers such as SVM [
22,
23]. In other words, the proposed scheme applies the same philosophy into a deep learning model by having both sub-networks extract these features automatically and then concatenate them as a result of the training. Moreover, as a part of the ablation study of the parallel encoder, supervised training is performed with a Softmax layer with three nodes added to the end of the concatenated feature vector to perform supervised classification.
To sum up, in this paper, an unsupervised anomaly detection model for age classes (child, adult, elderly) using surveillance image data is introduced. There are no unsupervised anomaly detection models for age detection with only full-body images to the authors’ best knowledge. The majority of the models are supervised and are based on facial features [
24]. The deep learning model proposed in this paper is the extended and improved version of the previous work introduced in [
25]. The multi-class normality scheme is applied where a single class in the dataset is designated to be the abnormal class, and the remaining classes are designated to be the normal class. The proposed model performs better than the authors’ previous work and all the benchmark models qualitatively and quantitatively.
2. Related Work
Starting with AlexNet’s [
26] superior performance in The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) against conventional methods, deep learning models have also created a new spark of interest in anomaly detection. With broad real-world applicable areas such as video surveillance [
5], and biomedical engineering [
4], a large number of papers have been published using anomaly detection [
27]. The proposed model in this paper also follows recent reconstruction-based trends.
An influential model proposed by Schlegl et al. [
4] uses adversarial training. In the paper, it is hypothesized that the latent vector of the GAN represents the data distribution. However, the authors initially train a generator and a discriminator with only normal images to achieve this. Afterward, using the frozen weights of the pre-trained generator and discriminator, they remap to the latent vector by optimizing the model based on its latent vector. The model shows an anomaly by showing a high anomaly score during the testing, a significantly better score than previous works. The main drawback of this proposal is the computational complexity due to the two-stage approach, and latent vector remapping is computationally costly. Following this work, Zenati et al. [
28] use BiGAN [
29], applying joint training to map the data distribution from the image and the latent space. Akcay et al. [
10] propose an autoencoder (GANomaly) with an additional encoder added to the decoder’s end to train this autoencoder and the discriminator jointly. Afterward, Akcay et al. [
30] propose an additional anomaly detection model with skip-connections trained jointly with the discriminator.
Human age in the literature is generally classified into four major categories: child (0–12 years), adolescent (13–18), adult (19–59), and senior adult (60 and above) [
31]. Most of the age group classification approaches are either gait-based [
31] or focus facial features [
32]. These approaches range from using support vector machines [
33] to complex CNN architectures [
34]. However, the major issue with these approaches is that the choice of the dataset is labeled. These approaches have minimal use for real-time surveillance usage. External conditions such as lighting, image quality, positioning of the pedestrians, occlusion through other people, and other objects often cause less-than-ideal scenarios. The proposed model is trained to distinguish the abnormal and normal images and jointly minimize the distance between their latent vector representations.
As reconstruction-based approaches [
4,
10,
28,
30] show promising results in anomaly detection; a solution to this problem is the proposed unsupervised anomaly detection approach, where the input data does not have a label. Surveillance camera footage captured from regions in the Republic of Korea is used to train the proposed model. The pedestrians observed in the surveillance cameras are selectively cropped and are manually labeled with age classes, namely, the child, adult, and elderly. A total of 80% of the normal classes in a cluster to learn the data distribution of these classes is used for training. For comparison, the remaining 20% of the normal class images and an equal amount of corresponding anomalous class images are input through the model. An anomaly score is obtained for each image. The abnormal image’s deviation from the normal distribution is shown in its anomaly score compared with normal images, and this is used to detect outlier cases.
3. Proposed Model
The proposed model is built with two primary components: the generator (
G) and the discriminator (
D) as shown in
Figure 1. The generator includes an encoder with two cascading parallel sub-networks, a conventional convolutional pipeline (CNN), and a dilated convolutional pipeline (DCN) with a dilation factor of two. Both pipelines are four layers deep. Each layer uses
convolutional filters, followed by a rectified linear unit (ReLU) activation function, a batch normalization operation [
35], and a max-pooling operation for spatial dimension reduction. This also means that the computational cost is identical between both the CNN and DCN (dilation rate has no effect on the computational complexity). The reasoning behind the parallel DCN is that the dilated convolutions increase the receptive field of the network while keeping the number of coefficients the same as its conventional counterpart, causing it to capture more global features [
36]. The latent space vector created by the concatenation of the features obtained from CNN and DCN becomes the input of the decoder part of the generator. The four layer-deep up-sampling layers also concatenate the skip-connections from CNN and DCN to enable multi-scale capturing of the image space with high capability [
37]. In the scenario of replacing the DCN with a CNN with
convolutions, the computational cost would increase 2.78 times due to the massive increase in the number of trainable parameters (from 387,840 trainable parameters to 1,077,334 trainable parameters). Moreover,
convolutions are highly optimized for modern computing libraries on GPU and CPU. Winograd algorithm [
38] which is designed specifically for
convolutions with stride 1, is well supported by libraries like cuDNN [
39].
The generator reconstructs a corresponding image from the input image x such that where and . The input image is sent through both CNN and DCN, and at the end of each network, the feature vectors are concatenated into the latent space vector z.
The discriminator (D) is comprised of a four-layer cascading CNN that is responsible for predicting the correct class (i.e., real or fake) based on the features of the input image. Its structure is identical to the CNN sub-network in the generator, with convolutional filters, ReLU activation, and a batch normalization operation. At the end of the fully connected layer, there is a prediction layer that classifies normal images x and corresponding reconstructed images . When adversarially trained, the discriminator improves its capability to predict until the convergence is reached. A Softmax layer is also added at the end of the concatenated feature vector as an individual classification layer as an ablation study of the model. In this ablation study, the parallel feature extracting encoder is trained in a supervised method with the labeled dataset.
The dataset is split into the training set containing N normal images where , and a test set of A normal and abnormal images combined where denoting normal and abnormal classes, respectively. The main task is to train the model f on and perform inference on . In an ideal scenario, the size of the training set should be much larger than the testing set. Training helps the model map the dataset distribution in all vector spaces, causing it to learn both higher and lower-level features distinctly different from abnormal samples.
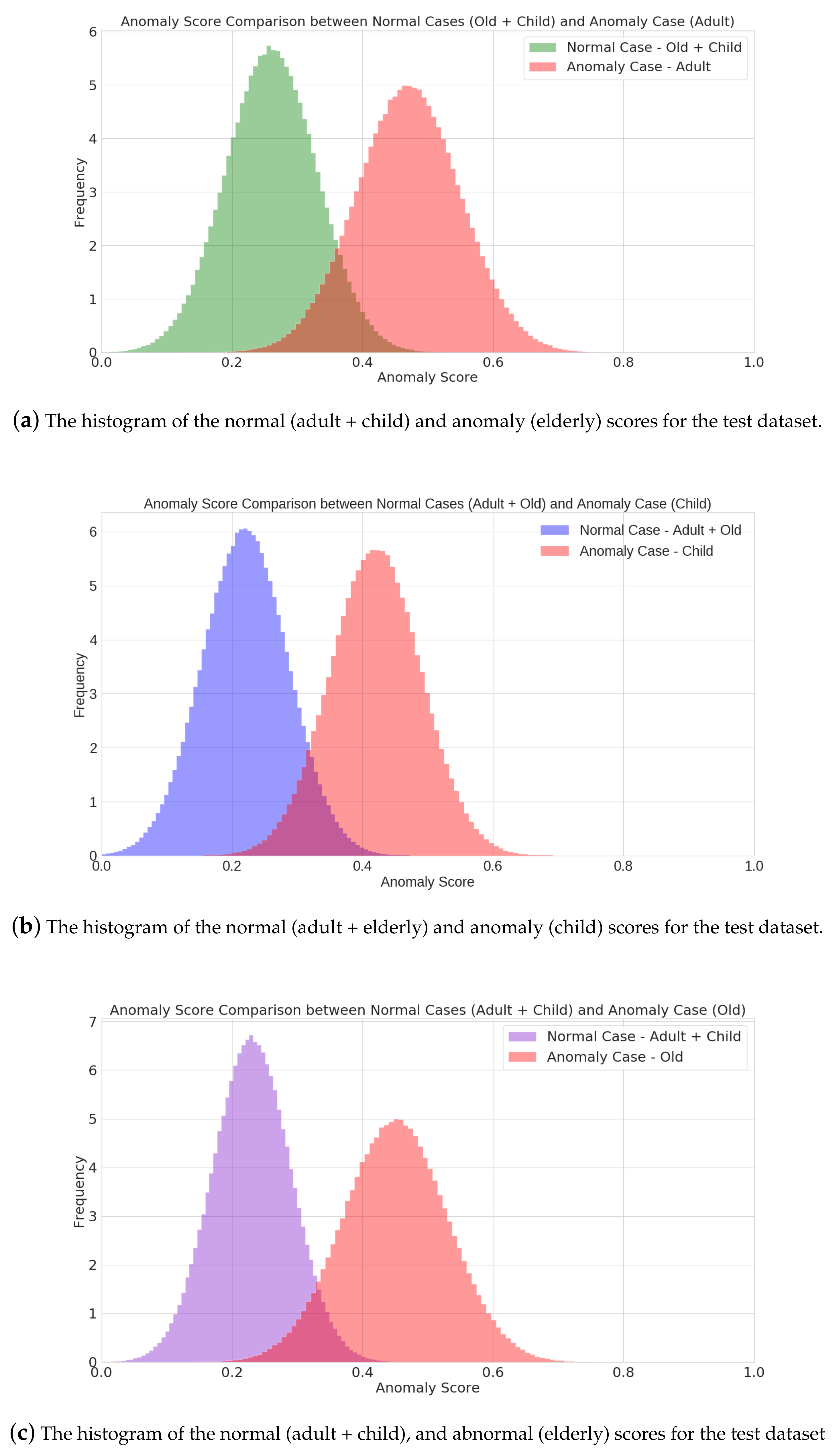
The task of the training is to capture and map the distribution of the training set in both the image space and the latent vector space. It is hypothesized that defining an anomaly score should yield minimal scores for normal samples used in training but higher scores for abnormal samples that the model is not trained with. A higher anomaly score would indicate the sample x is from an abnormal class with respect to the data distribution learned by f from .
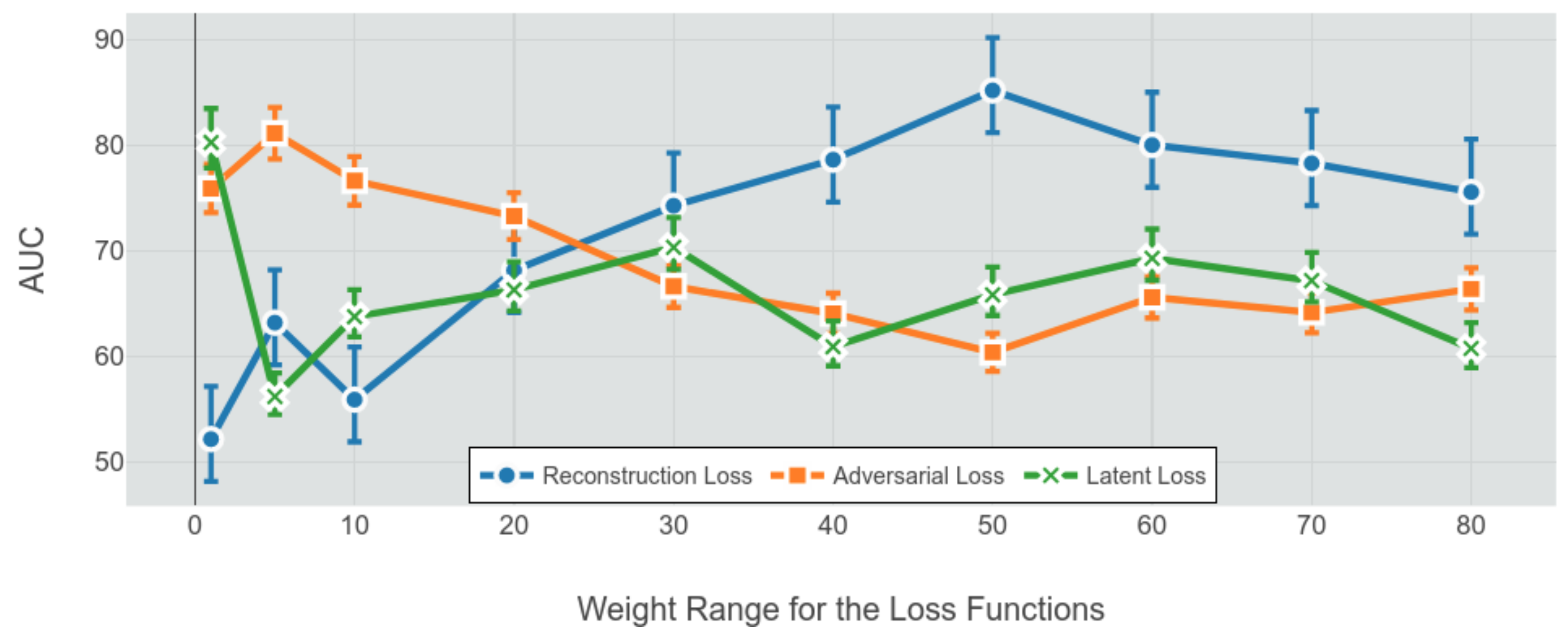
Three loss functions have been implemented to train the proposed model. Each of the loss functions has its weighting in the training objective.
Contextual Loss:
normalization between the input image
x and the corresponding reconstructed image
is applied to learn the image distribution. This causes the model to generate contextually similar images from normal samples. The loss is defined as:
Adversarial Loss: Wasserstein loss proposed in [
40] is applied to improve the reconstruction performance for normal image
x during training. This loss is helpful for the generator to reconstruct an image
from the input image
x as realistic as possible while helping the discriminator to classify real or fake (generated) samples. It is defined as:
where
D is the set of 1-Lipshitz functions and
is the model distribution defined by
. The discriminator in WGAN is sometimes called a critic since it is not explicitly trained to classify; it minimizes the value function with respect to the generator parameters,
.
Latent Loss: The
loss is used to reconstruct the latent representations for the input
x and the corresponding reconstruction
. This ensures the network is sufficiently trained to produce contextually meaningful latent representations for normal samples. The final feature vector layer of the discriminator is used to obtain the features of the input image
and for the reconstructed image,
. The loss becomes:
The total loss for the model becomes the weighted sum of all the losses:
where
is the weighting parameter to assign the importance of individual losses. The optimal weighting in this study is done via a grid search operation. The optimal values for the weights can be seen in
Figure 2.
5. Conclusions
In this study, an unsupervised, encoder-decoder model that is adversarially trained with skip-connections for age classification from CCTV data is proposed. The CNN sub-network of the proposed model extracts local features, and the DCN sub-network extracts global features of the input image. The potency of the parallel model is explained through the ablation study of the entropy images of sub-networks. The Latent vectors of these sub-networks are concatenated and become the input of the decoder, where the input image is reconstructed through transpose convolution. Both CNN and DCN networks have skip connections with the decoder-counterpart, assisting in the vanishing gradient problem. Afterward, the reconstructed image and the input image are input into the discriminator, where they are classified as real or fake. In the unsupervised training scheme, the model is trained with only normal-designated classes without labels. During the inference, the normal-designated classes and the anomaly-designated class is sent through the model, and the AUC and anomaly scores are calculated. The proposed model achieves up to 5% higher AUC score, 2% higher classification accuracy when fine-tuned, and an average of 1.568 lower FID score for three classes (child, adult, and elderly) than the next-best benchmark model. For future works, various methods for improving the proposed deep learning model will be investigated.








{kind=link}
{kind=link}
{kind=link}
{kind=link}