
Data-Driven Convolutional Model for Digital Color Image Demosaicing


Abstract
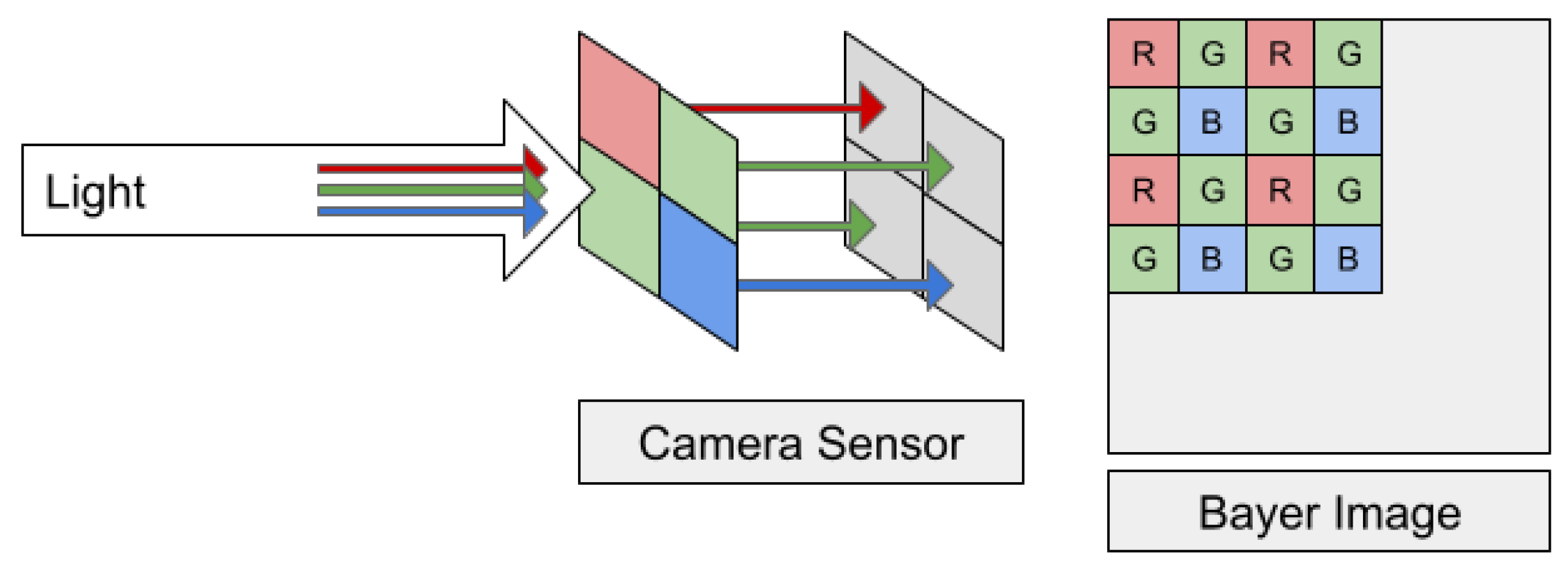
:1. Introduction
2. Previous Works
3. Methods
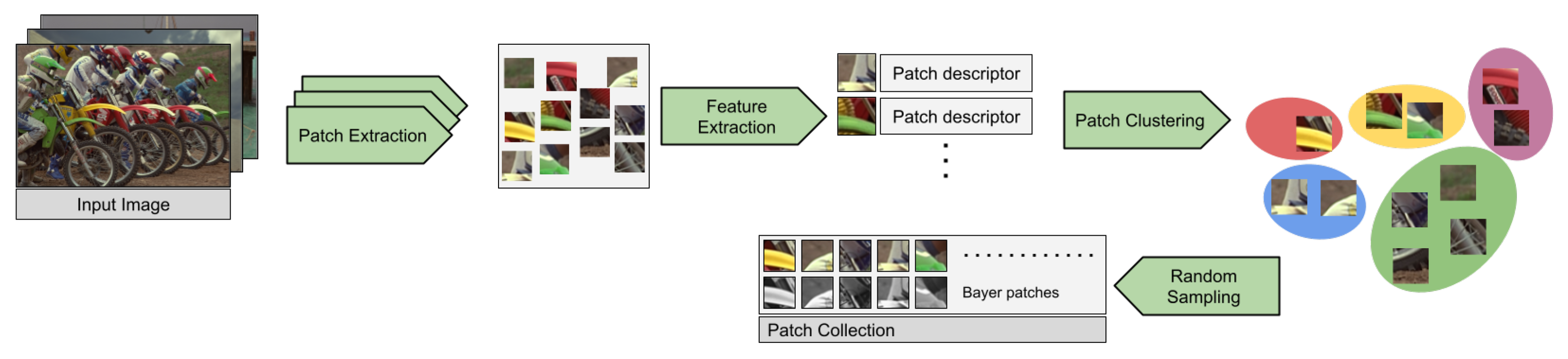
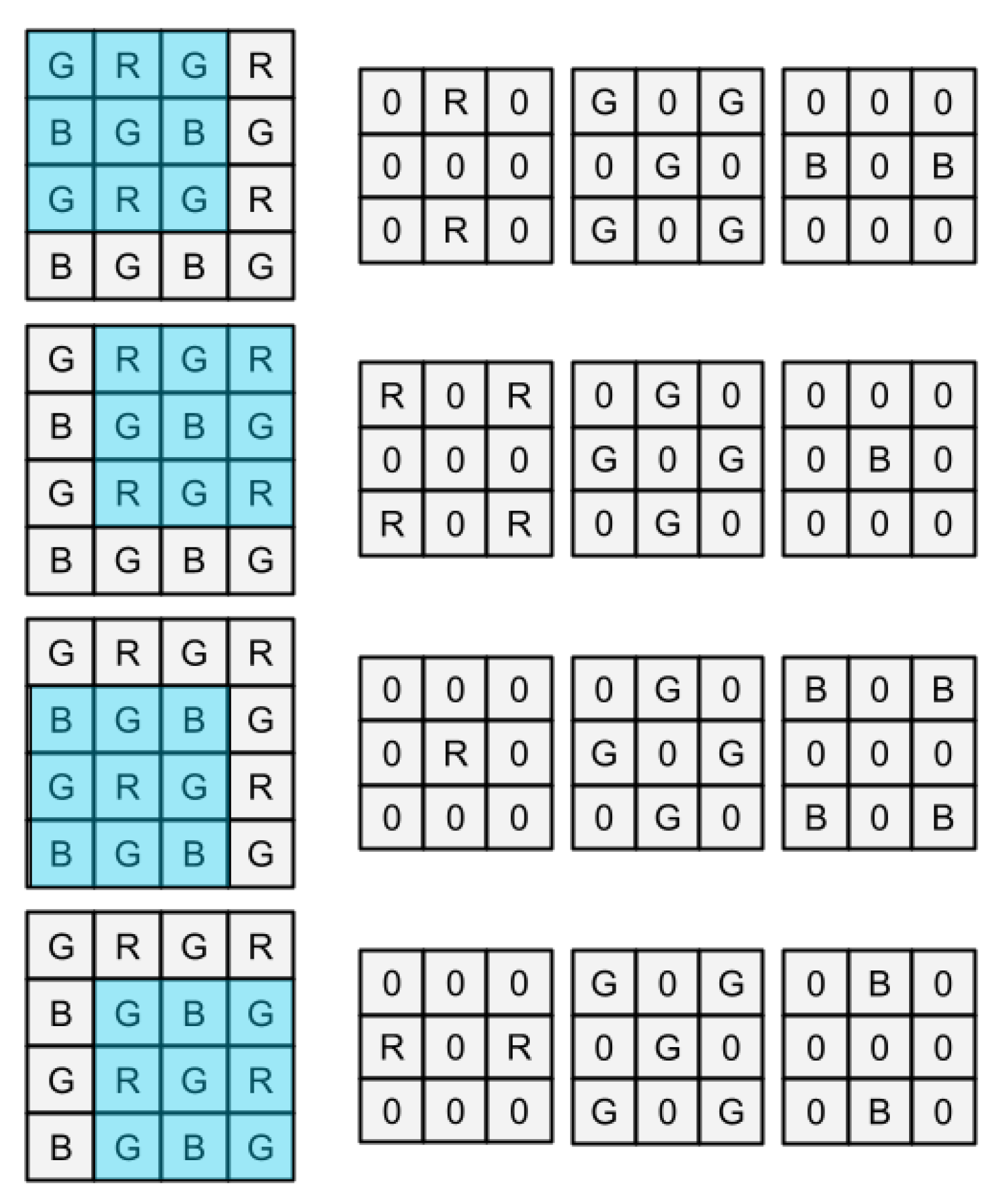
3.1. Dataset Creation
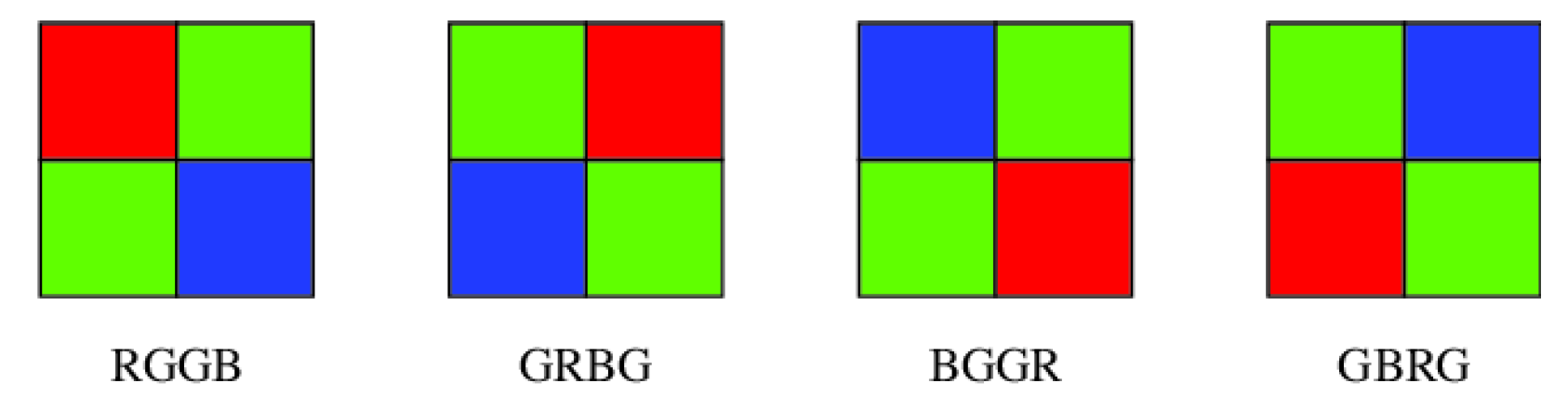
3.2. Image Model
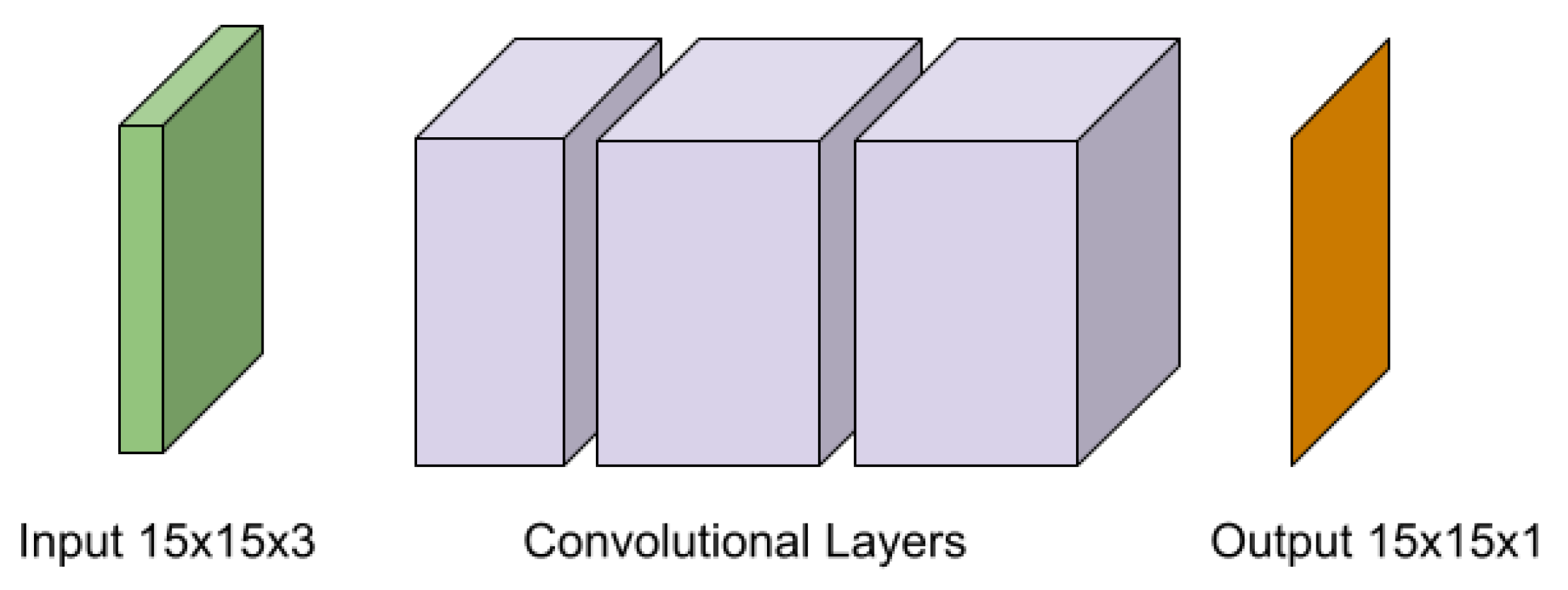
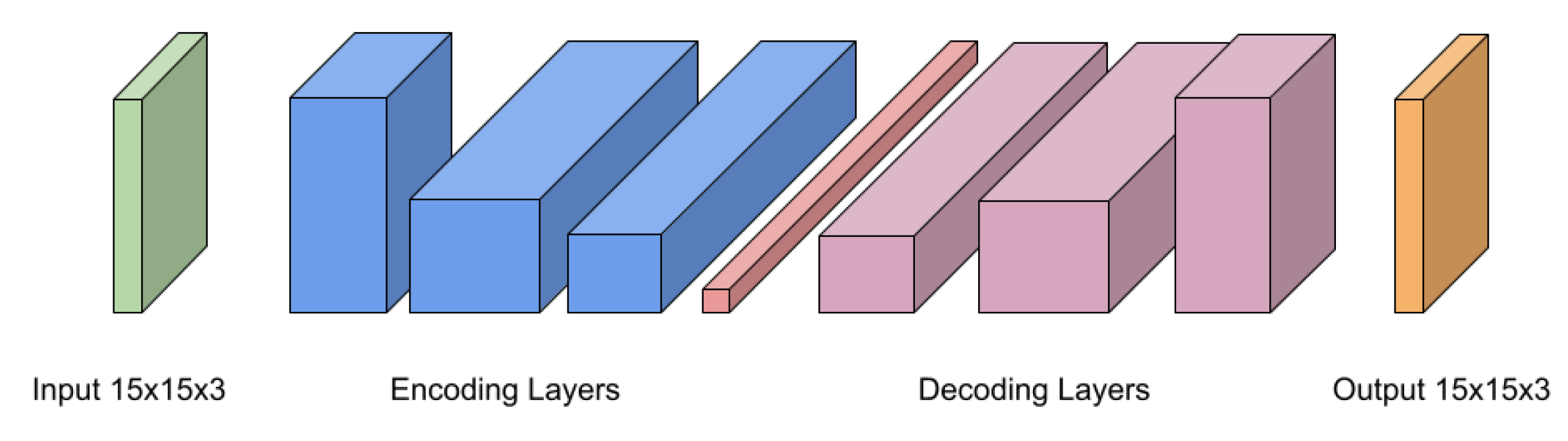
3.3. Convolutional Neural Network Model
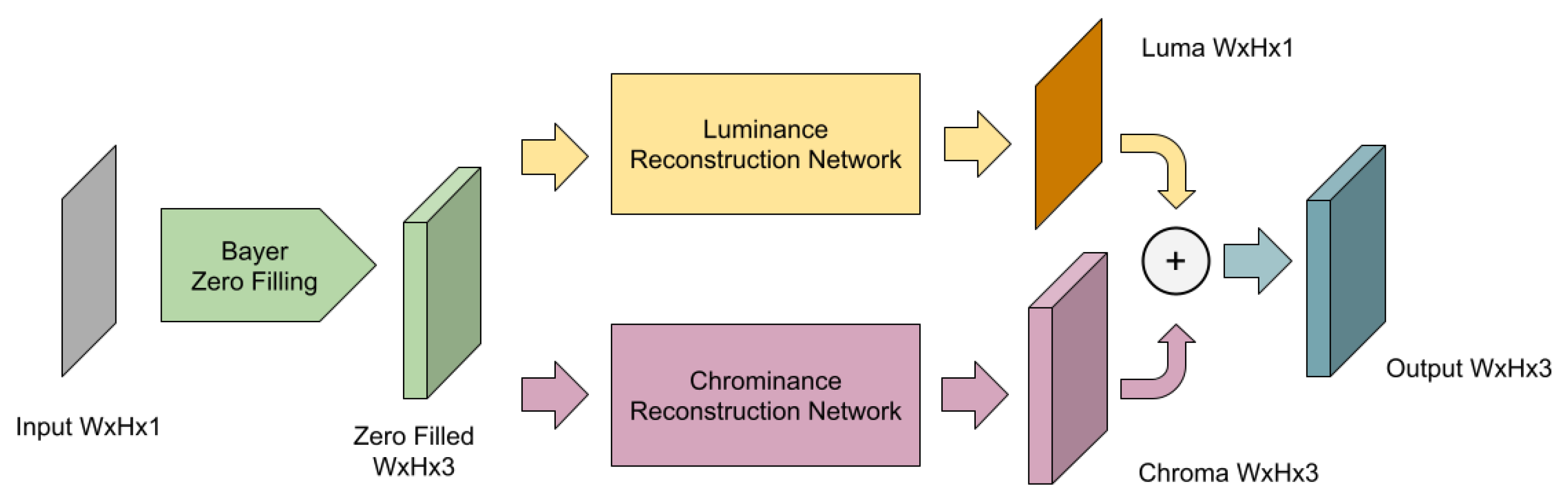
3.4. Luminance Reconstruction Network
3.5. Chrominance Reconstruction Network
3.6. Full Reconstruction Network
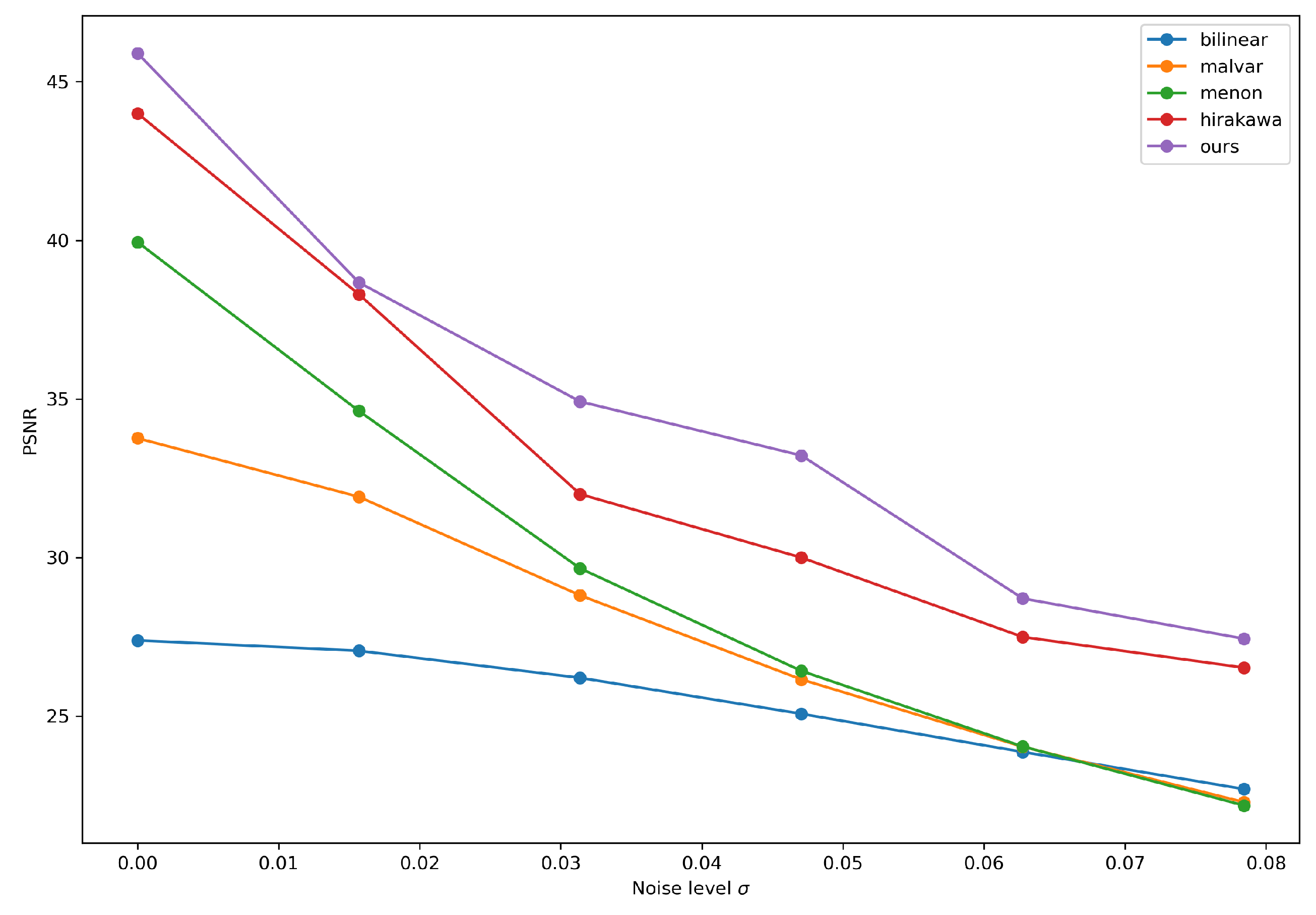
4. Results
5. Conclusions
6. Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Bayer, B.E. Color Imaging Array. 1976. Available online: http://www.google.com/patents?id=Q_o7AAAAEBAJ&dq=3,971,065 (accessed on 19 June 2021).
- Lukac, R.; Plataniotis, K.N.; Hatzinakos, D.; Aleksic, M. A new CFA interpolation framework. Signal Process. 2006, 86, 1559–1579. [Google Scholar] [CrossRef] [Green Version]
- Condat, L. A new random color filter array with good spectral properties. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 1613–1616. [Google Scholar]
- Zapryanov, G.; Nikolova, I. Demosaicing methods for pseudo-random Bayer color filter array. In Proc. ProRisc; ProRisc: Veldhoven, The Netherlands, 2005; pp. 687–692. [Google Scholar]
- Kröger, R.H. Anti-aliasing in image recording and display hardware: Lessons from nature. J. Opt. A Pure Appl. Opt. 2004, 6, 743. [Google Scholar] [CrossRef]
- Kodak PhotoCD. Available online: https://www.math.purdue.edu/~lucier/PHOTO_CD/ (accessed on 5 September 2021).
- Gharbi, M.; Chaurasia, G.; Paris, S.; Durand, F. Deep joint demosaicking and denoising. ACM Trans. Graph. (ToG) 2016, 35, 1–12. [Google Scholar] [CrossRef]
- Losson, O.; Macaire, L.; Yang, Y. Chapter 5—Comparison of Color Demosaicing Methods. In Advances in Imaging and Electron Physics; Hawkes, P.W., Ed.; Elsevier: Amsterdam, The Netherlands, 2010; Volume 162, pp. 173–265. [Google Scholar] [CrossRef] [Green Version]
- Gunturk, B.K.; Glotzbach, J.; Altunbasak, Y.; Schafer, R.W.; Mersereau, R.M. Demosaicking: Color filter array interpolation. IEEE Signal Process. Mag. 2005, 22, 44–54. [Google Scholar] [CrossRef]
- Cok, D.R. Reconstruction of CCD images using template matching. In Proc IS&T Annual Conf./ICPS; St. Petersburg, Russia, 1994; pp. 380–385. [Google Scholar]
- Hibbard, R.H. Apparatus and Method for Adaptively Interpolating a Full Color Image Utilizing Luminance Gradients. U.S. Patent No. 5,382,976, 17 January 1995. [Google Scholar]
- Li, J.S.J.; Randhawa, S. High Order Extrapolation Using Taylor Series for Color Filter Array Demosaicing. In Image Analysis and Recognition; Kamel, M., Campilho, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 703–711. [Google Scholar]
- Hamilton, J.F.; Adams, J.E. Adaptive Color Plan Interpolation in Single Sensor Color Electronic Camera. U.S. Patent No. 5,629,734, 13 May 1997. [Google Scholar]
- Hirakawa, K.; Parks, T. Adaptive homogeneity-directed demosaicing algorithm. IEEE Trans. Image Process. 2005, 14, 360–369. [Google Scholar] [CrossRef] [PubMed]
- Chang, L.; Tan, Y.P. Hybrid color filter array demosaicking for effective artifact suppression. J. Electron. Imaging 2006, 15, 013003. [Google Scholar] [CrossRef]
- Kimmel, R. Demosaicing: Image reconstruction from color CCD samples. IEEE Trans. Image Process. 1999, 8, 1221–1228. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, L.; Wu, X.; Buades, A.; Li, X. Color demosaicking by local directional interpolation and nonlocal adaptive thresholding. J. Electron. Imaging 2011, 20, 023016. [Google Scholar]
- Wang, C. Bayer patterned image compression based on wavelet transform and all phase interpolation. In Proceedings of the 2012 IEEE 11th International Conference on Signal Processing, Beijing, China, 21 October 2012; Volume 1, pp. 708–711. [Google Scholar]
- Alleysson, D.; Susstrunk, S.; Hérault, J. Linear demosaicing inspired by the human visual system. IEEE Trans. Image Process. 2005, 14, 439–449. [Google Scholar] [PubMed] [Green Version]
- Syu, N.S.; Chen, Y.S.; Chuang, Y.Y. Learning deep convolutional networks for demosaicing. arXiv 2018, arXiv:1802.03769. [Google Scholar]
- Tan, R.; Zhang, K.; Zuo, W.; Zhang, L. Color image demosaicking via deep residual learning. In Proceedings of the IEEE Int. Conf. Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; Volume 2, p. 6. [Google Scholar]
- Gunturk, B.K.; Altunbasak, Y.; Mersereau, R.M. Color plane interpolation using alternating projections. IEEE Trans. Image Process. 2002, 11, 997–1013. [Google Scholar] [CrossRef] [PubMed]
- Khashabi, D.; Nowozin, S.; Jancsary, J.; Fitzgibbon, A.W. Joint Demosaicing and Denoising via Learned Nonparametric Random Fields. IEEE Trans. Image Process. 2014, 23, 4968–4981. [Google Scholar] [CrossRef] [PubMed]
- Getreuer, P. Malvar-He-Cutler Linear Image Demosaicking. Image Process. Line 2011, 1, 83–89. [Google Scholar] [CrossRef] [Green Version]
- Menon, D.; Andriani, S.; Calvagno, G. Demosaicing with directional filtering and a posteriori decision. IEEE Trans. Image Process. 2006, 16, 132–141. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Heide, F.; Steinberger, M.; Tsai, Y.T.; Rouf, M.; Pająk, D.; Reddy, D.; Gallo, O.; Liu, J.; Heidrich, W.; Egiazarian, K.; et al. FlexISP: A Flexible Camera Image Processing Framework. ACM Trans. Graph. 2014, 33, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Jeon, G.; Dubois, E. Demosaicking of noisy Bayer-sampled color images with least-squares luma-chroma demultiplexing and noise level estimation. IEEE Trans. Image Process. 2012, 22, 146–156. [Google Scholar] [CrossRef] [PubMed]
- Condat, L. A new color filter array with optimal properties for noiseless and noisy color image acquisition. IEEE Trans. Image Process. 2011, 20, 2200–2210. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Condat, L.; Mosaddegh, S. Joint demosaicking and denoising by total variation minimization. In Proceedings of the 2012 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2013; pp. 2781–2784. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MSE | PSNR | SSIM | |
|---|---|---|---|
| bilinear | 0.14 | 29.2 | 0.93 |
| Malvar [24] | 0.07 | 35.4 | 0.98 |
| Menon [25] | 0.05 | 39.2 | 0.99 |
| Hirakawa [14] * | - | 36.5 | - |
| Zhang [17] * | - | 37.3 | - |
| Heide [27] * | - | 40.0 | - |
| Jeon [28] * | - | 36.4 | - |
| Condat [29] * | - | 35.5 | - |
| Condat [30] * | - | 36.1 | - |
| ours | 0.04 | 43.1 | 0.99 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Gioia, F.; Fanucci, L. Data-Driven Convolutional Model for Digital Color Image Demosaicing. Appl. Sci. 2021, 11, 9975. https://doi.org/10.3390/app11219975
de Gioia F, Fanucci L. Data-Driven Convolutional Model for Digital Color Image Demosaicing. Applied Sciences. 2021; 11(21):9975. https://doi.org/10.3390/app11219975
Chicago/Turabian Stylede Gioia, Francesco, and Luca Fanucci. 2021. "Data-Driven Convolutional Model for Digital Color Image Demosaicing" Applied Sciences 11, no. 21: 9975. https://doi.org/10.3390/app11219975
APA Stylede Gioia, F., & Fanucci, L. (2021). Data-Driven Convolutional Model for Digital Color Image Demosaicing. Applied Sciences, 11(21), 9975. https://doi.org/10.3390/app11219975