
Blind Image Separation Method Based on Cascade Generative Adversarial Networks


Abstract
:1. Introduction
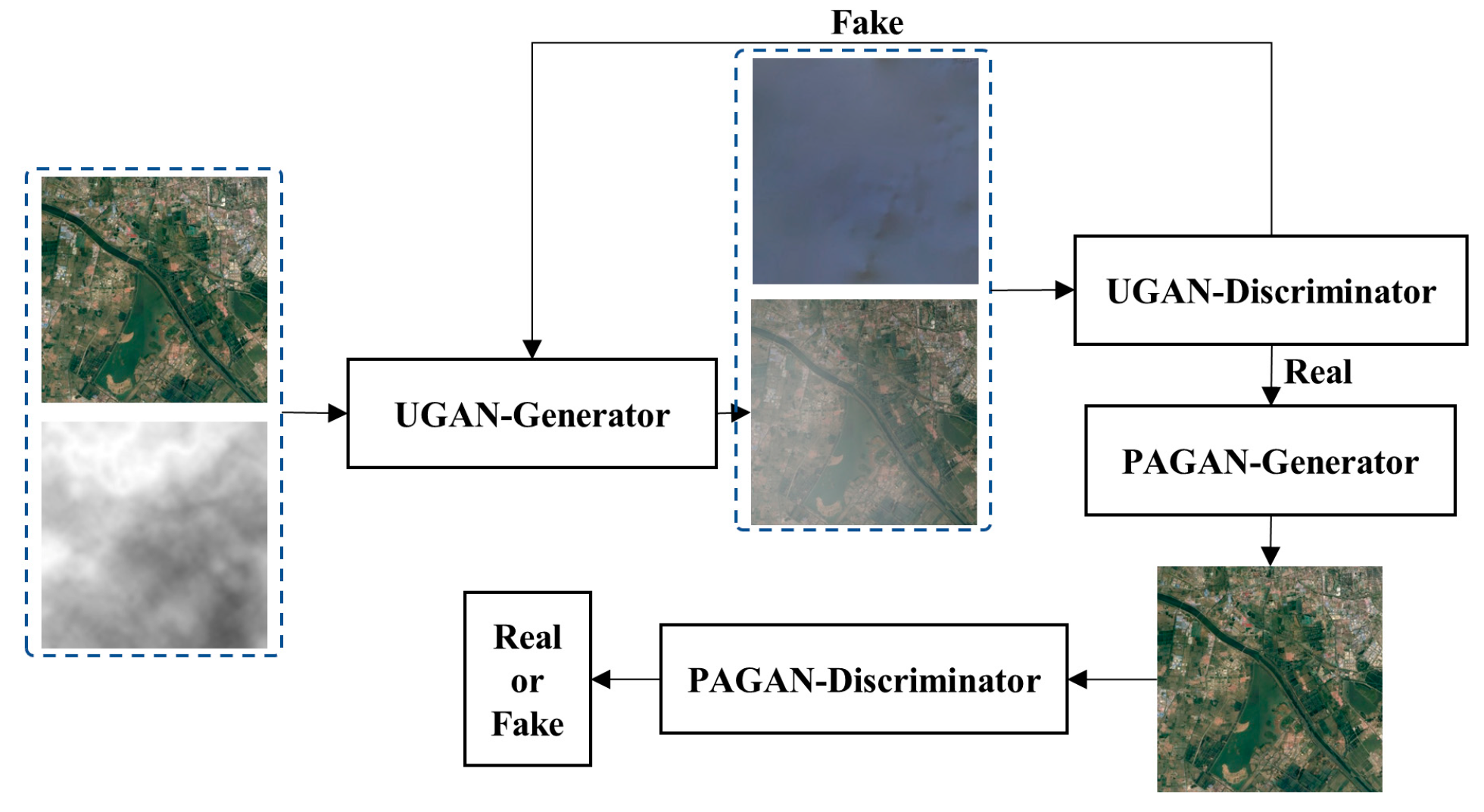
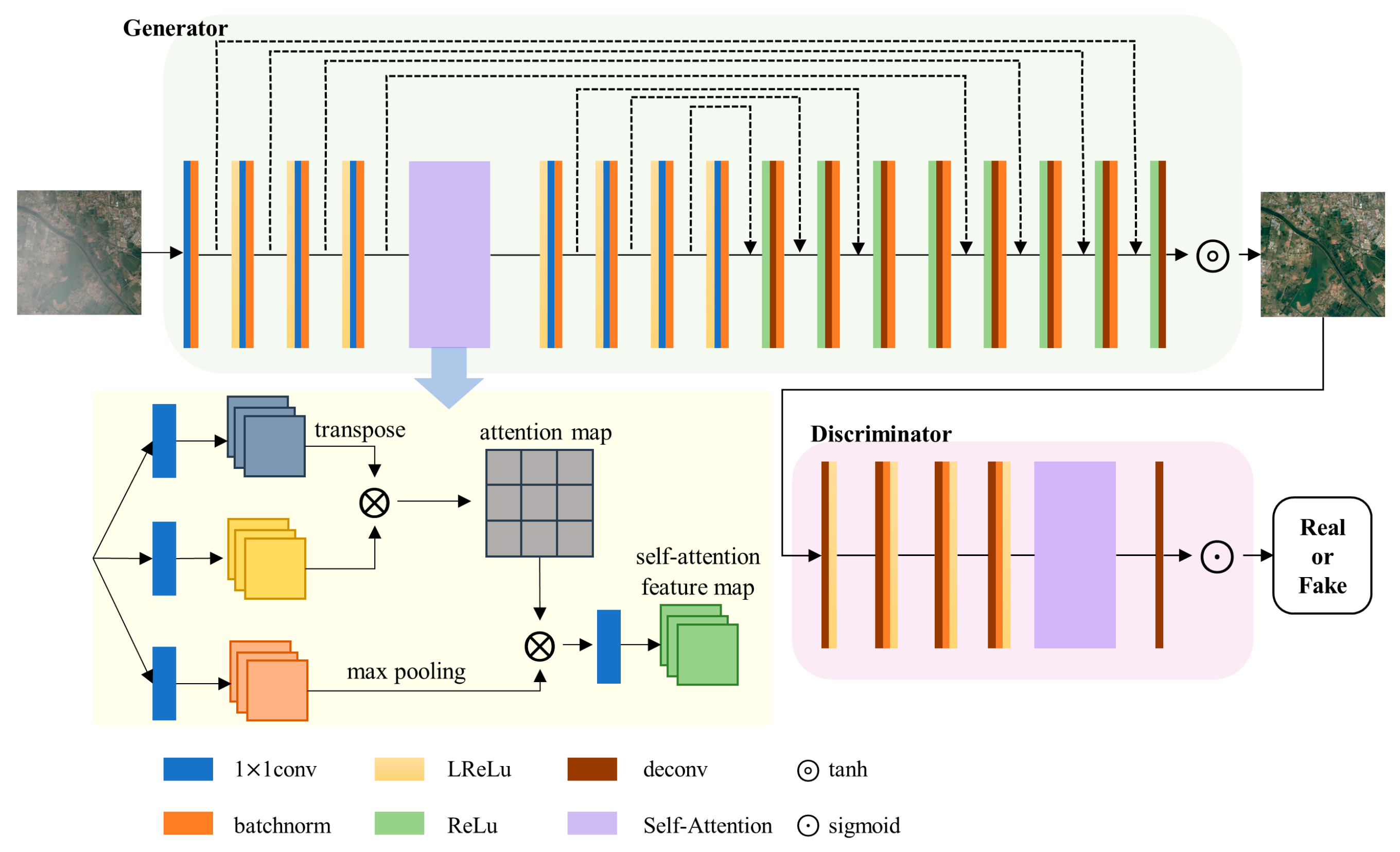
- A BIS method based on a cascade of GANs including a UGAN and a PAGAN is proposed. The goal of the UGAN is to train a generator that can synthesize new samples following examples of clear images and interference sources. In contrast to the UGAN, the goal of the PAGAN is to train a generator that can separate synthesized images. Moreover, a self-attention module is added to the PAGAN to reduce the difference between the generated image and the ground truth.
- The organic combination of a synthetic network and a separation network addresses the problem that the training of a deep learning model is difficult due to the lack of paired data.
- The proposed method is suitable for both natural image separation and remote sensing image separation, and it has an excellent generalization ability.
2. Materials and Methods
2.1. Overall Architecture
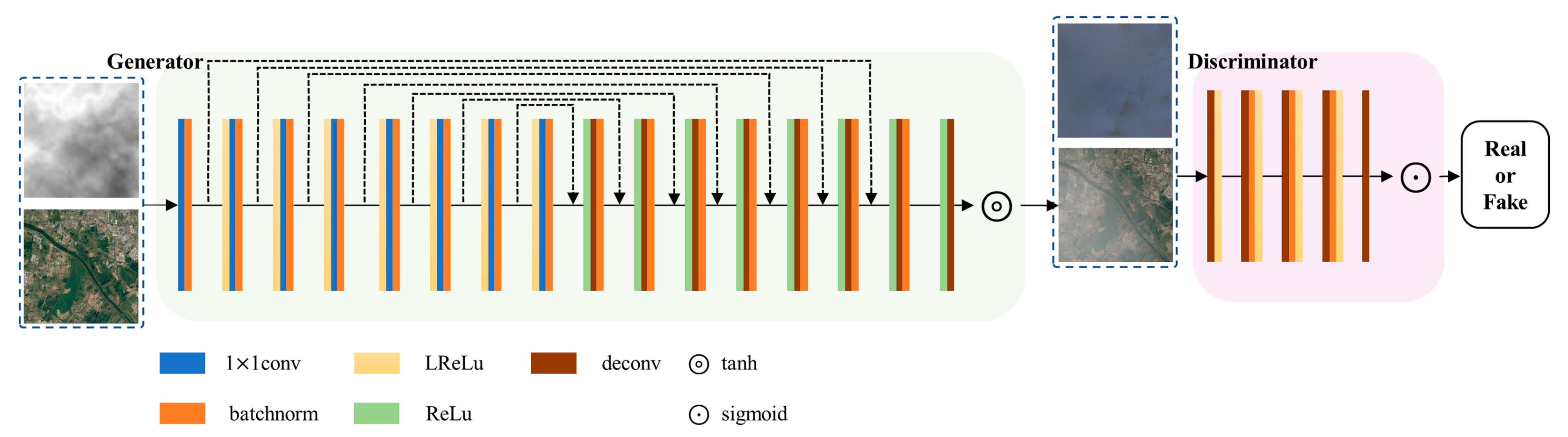
2.2. UGAN
2.3. PAGAN
2.4. Loss Function
3. Experiments
3.1. Evaluation Indices
3.2. Datasets
3.3. Experimental Results of the Natural Image Dataset
3.4. Experimental Results of the Remote Sensing Image Dataset
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, Z.Z.; Fan, L.; Yang, Y.P.; Yang, Z.; Gui, G. Generalized nuclear norm and Laplacian scale mixture based low-rank and sparse decomposition for video foreground-background separation. Signal Process. 2020, 172, 107527. [Google Scholar] [CrossRef]
- Liu, Y.; Lu, F. Separate in latent space: Unsupervised single image layer separation. In AAAI-20 Technical Tracks 7, Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Siadat, M.; Aghazadeh, N.; Akbarifard, F.; Brismar, H.; Öktem, O. Joint image deconvolution and separation using mixed dictionaries. IEEE Trans. Image Process. 2019, 28, 3936–3945. [Google Scholar] [CrossRef] [PubMed]
- Hyvärinen, A.; Oja, E. Independent component analysis: Algorithms and applications. Neural Netw. 2000, 13, 411–430. [Google Scholar] [CrossRef] [Green Version]
- Cichocki, A.; Mørup, M.; Smaragdis, P.; Wang, W.; Zdunek, R. Advances in nonnegative matrix and tensor factorization. Comput Intel Neurosc. 2008, 2008, 852187. [Google Scholar] [CrossRef] [PubMed]
- Pham, D.T.; Garat, P. Blind separation of mixture of independent sources through a quasi-maximum likelihood approach. IEEE Trans. Signal Process. 1997, 45, 1712–1725. [Google Scholar] [CrossRef]
- Yu, X.C.; Xu, J.D.; Hu, D.; Xing, H.H. A new blind image source separation algorithm based on feedback sparse component analysis. Signal Process. 2013, 93, 288–296. [Google Scholar]
- Xu, J.D.; Yu, X.C.; Hu, D.; Zhang, L.B. A fast mixing matrix estimation method in the wavelet domain. Signal Process. 2014, 95, 58–66. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Mehdi, M.; Simon, O. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Isola, P.; Zhu, Y.F.; Zhou, T.H.; Efros, A.A. Image-to-Image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, Y.; Liu, J.; Wang, S. Effective Distributed Learning with Random Features: Improved Bounds and Algorithms. In Proceedings of the 9th International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Li, T.; Lun, D.P.K. Single-image reflection removal via a two-stage background recovery process. IEEE Signal Process. Lett. 2019, 26, 1237–1241. [Google Scholar] [CrossRef]
- Halperin, T.; Ephrat, A.; Hoshen, Y. Neural separation of observed and unobserved distributions. In Proceedings of the Machine Learning Research, Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Zhao, D.; Xu, L.; Yan, Y.; Chen, J.; Duan, L.Y. Multi-scale optimal fusion model for single image dehazing. Signal Process. Image Commun. 2019, 74, 253–265. [Google Scholar] [CrossRef]
- Sun, X.; Xu, J.D.; Ma, Y.L.; Zhao, T.; Ou, S.; Peng, L. Blind image separation based on attentional generative adversarial network. J. Ambient Intell. Hum. Comput. 2020, 3, 1–8. [Google Scholar] [CrossRef]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shen, H.; Li, X.; Cheng, Q.; Zeng, C.; Yang, G.; Li, H.; Zhang, L. Missing information reconstruction of remote sensing data: A technical review. IEEE Geosci. Remote Sens. Mag. 2015, 3, 61–85. [Google Scholar] [CrossRef]
- Wu, C.; Zou, Y.; Zhi, Y. U-GAN: Generative Adversarial Networks with U-Net for Retinal Vessel Segmentation. In Proceedings of the 2019 14th International Conference on Computer Science Education, Toronto, ON, Canada, 19–21 August 2019. [Google Scholar]
- Zhang, H.; Goodfellow, I.J.; Metaxas, D.; Odena, A. Self-Attention generative adversarial networks. In Proceedings of the Machine Learning Research, Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Zhao, H.; Gallo, O.; Frosio, L.; Kautz, J. Loss functions for image restoration with neural networks. IEEE Trans. Comput. Imaging 2017, 3, 47–57. [Google Scholar] [CrossRef]
- Hesse, C.W.; James, C.J. The fastica algorithm with spatial constraints. IEEE Signal Process. Lett. 2005, 12, 792–795. [Google Scholar] [CrossRef]
- Yang, Y.; Ma, W.; Zheng, Y.; Cai, J.F.; Xu, W. Fast single image reflection suppression via convex optimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhu, Q.; Mai, J.; Shao, L. A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar] [PubMed] [Green Version]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intel. 2011, 33, 2341–2353. [Google Scholar]
- Chen, D.; He, M.; Fan, Q.; Liao, J.; Zhang, L.; Hou, D.; Yuan, L.; Hua, G. Gated context aggregation network for image dehazing and deraining. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 7–11 January 2019. [Google Scholar]
- Horé, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010. [Google Scholar]
- Zhu, J.Y.; Krähenbühl, P.; Shechtman, E.; Efros, A.A. Generative Visual Manipulation on the Natural Image Manifold. In Proceedings of the Computer Vision-ECCV 2016, European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Yu, A.; Grauman, K. Fine-grained visual comparisons with local learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Lin, D.; Xu, G.; Wang, X.; Wang, Y.; Sun, X.; Fu, K. A remote sensing image dataset for cloud removal. arXiv 2019, arXiv:1901.00600. [Google Scholar]
- Zhang, Y.; Guindon, B.; Cihlar, J. An image transform to characterize and compensate for spatial variations in thin cloud contamination of Landsat images. Remote Sens. Environ. 2002, 82, 173–187. [Google Scholar] [CrossRef]
- Shan, S.; Wang, Y. An algorithm to remove thin clouds but to preserve ground features in visible bands. In Proceedings of the IGARSS 2020-2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PSNR (dB)/SSIM | NMF | FastICA | NES | Yang [22] | Ours |
|---|---|---|---|---|---|
| Yellow haze images | 15.02/0.42 | 12.67/0.15 | 19.75/0.63 | 15.70/0.45 | 25.92/0.89 |
| Synthesized images | 23.79/0.70 | 14.70/0.55 | 20.56/0.78 | 21.37/0.71 | 23.84/0.88 |
| PSNR (dB)/SSIM | CAP | GDCP | MOF | GCANet | Ours |
|---|---|---|---|---|---|
| RICE-I | 24.51/0.82 | 20.35/0.83 | 16.64/0.73 | 19.93/0.80 | 25.92/0.85 |
| RICE-II | 20.97/0.61 | 17.18/0.54 | 18.04/0.48 | 19.16/0.56 | 21.15/0.82 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, F.; Xu, J.; Sun, X.; Ma, Y.; Ni, M. Blind Image Separation Method Based on Cascade Generative Adversarial Networks. Appl. Sci. 2021, 11, 9416. https://doi.org/10.3390/app11209416
Jia F, Xu J, Sun X, Ma Y, Ni M. Blind Image Separation Method Based on Cascade Generative Adversarial Networks. Applied Sciences. 2021; 11(20):9416. https://doi.org/10.3390/app11209416
Chicago/Turabian StyleJia, Fei, Jindong Xu, Xiao Sun, Yongli Ma, and Mengying Ni. 2021. "Blind Image Separation Method Based on Cascade Generative Adversarial Networks" Applied Sciences 11, no. 20: 9416. https://doi.org/10.3390/app11209416
APA StyleJia, F., Xu, J., Sun, X., Ma, Y., & Ni, M. (2021). Blind Image Separation Method Based on Cascade Generative Adversarial Networks. Applied Sciences, 11(20), 9416. https://doi.org/10.3390/app11209416