1. Introduction
In most domains, it is a common problem where labeled data are precious and scarce due to costly human resources, but unlabeled data are easily sampled. Particularly, in professional fields such as LaTeX or biomedicine, accurate labels are limited, costly and easily misclassified since they need people with field knowledge. By leveraging massive unlabeled data and fewer resources, an effective classifier can be proposed and optimized for better labelling. Mining information from unlabeled data to improve the performance of classification models is needed. A large amount of unlabeled data are utilized to improve the model’s robustness by self-training without much extra complexity, which has been successfully applied to image recognition [
1,
2] and speech recognition [
3,
4,
5]. The self-training method labels unlabeled data with a teacher model and uses the labeled data and unlabeled data to jointly train a student model. Reference [
2] proposed that the strategy of Noisy Student Training was helpful for improving the generalization capabilities and robustness. Reference [
4] proposed the normalized filtering scores that filter out low-confident utterance-transcript pairs generated by the teacher to mitigate the noise introduced by the teacher model.
On the other hand, in the text classification task of specific domains, such as biology, information security, and mathematics, where Proper Nouns are widely used, pretraining from unlabeled data is more critical, which can make the representation of terms more accurate in NLP tasks. The representation learning of a specific domain can be enhanced by the pretraining [
6] of EMLO [
7] or BERT [
8]. BioBERT [
9] was pretrained in the biomedical field, which can have a greater performance in the corresponding biomedical text mining task. MathBERT [
10] was proposed for mathematical formulas, and a new pretraining task was designed to improve the model’s ability. Reference [
11] also showed the effectiveness of the pretraining of a specific domain in computer vision, where a deep learning model was trained on a large unlabeled medical image dataset. Better results can be obtained on a small number of labeled medical images.
Recently, semi-supervised learning [
12] has become a new research direction that has attracted much attention in deep learning. In SimCLRv2 [
13], unsupervised pretraining of a ResNet architecture and self-training via unlabeled examples for refining and transferring the task-specific knowledge are proposed for image recognition. Self-training and pretraining are complementary and effective approaches to improve speech recognition using unlabeled data [
14].
The widely used semi-supervised methods are mainly based on pseudo-labels [
15,
16], which are predicted by models (such as decision tree, generative model, BERT) on unlabeled data. The unlabeled data with pseudo-labels and the original data form a new dataset, which is used to retrain the original model. Self-training is a specific type of pseudo-label-based method, which includes a teacher model for pseudo-labeling, and a student model on the new dataset. In the self-training process, the teacher model is updated by the student model in each training round to further improve the model’s performance. It is necessary to explore more values of unlabeled data in specific text domains on classification tasks by means of pretraining and self-training.
This paper proposes a text classification model (UL-BERT) in the LaTeX formula domain that takes advantage of unlabeled data and requires fewer labeled data. The word vector space is transferred from the general space of BERT to a particular space pretrained by domain pretrained stage and task pretrained stage on unlabeled data. A new dataset on unlabeled data with pseudo-labels is produced, and fed to a multi-round model training process to improve the performance of the text classification model. In this paper, the LaTex formula’s data are chosen as the study case to investigate the role of unlabeled data in the text classification task.
In summary, the contribution of this work is as follows:
We propose a two-stage pretraining model based on BERT(TP-BERT) for the domain specific unlabeled data. It ensures the word vector’s space is more effective for the representation of the data in the LaTeX formula domain;
We introduce the double-prediction pseudo-labeling (DPP) method to obtain more accurate pseudo-labels. The pseudo-labels are selected, which are predicted by the same labels from the origin and its augmented unlabeled text and have high predicting probabilities. It improves the confidence of the pseudo-label and reduces the effects from the label noise;
We propose a multi-rounds teacher–student training approach to train the classification model, where pseudo-labels are iteratively predicted by the new student model. It shows that our training approach can achieve a superior performance and low resources are needed.
2. Pretraining Based on Unlabeled Data
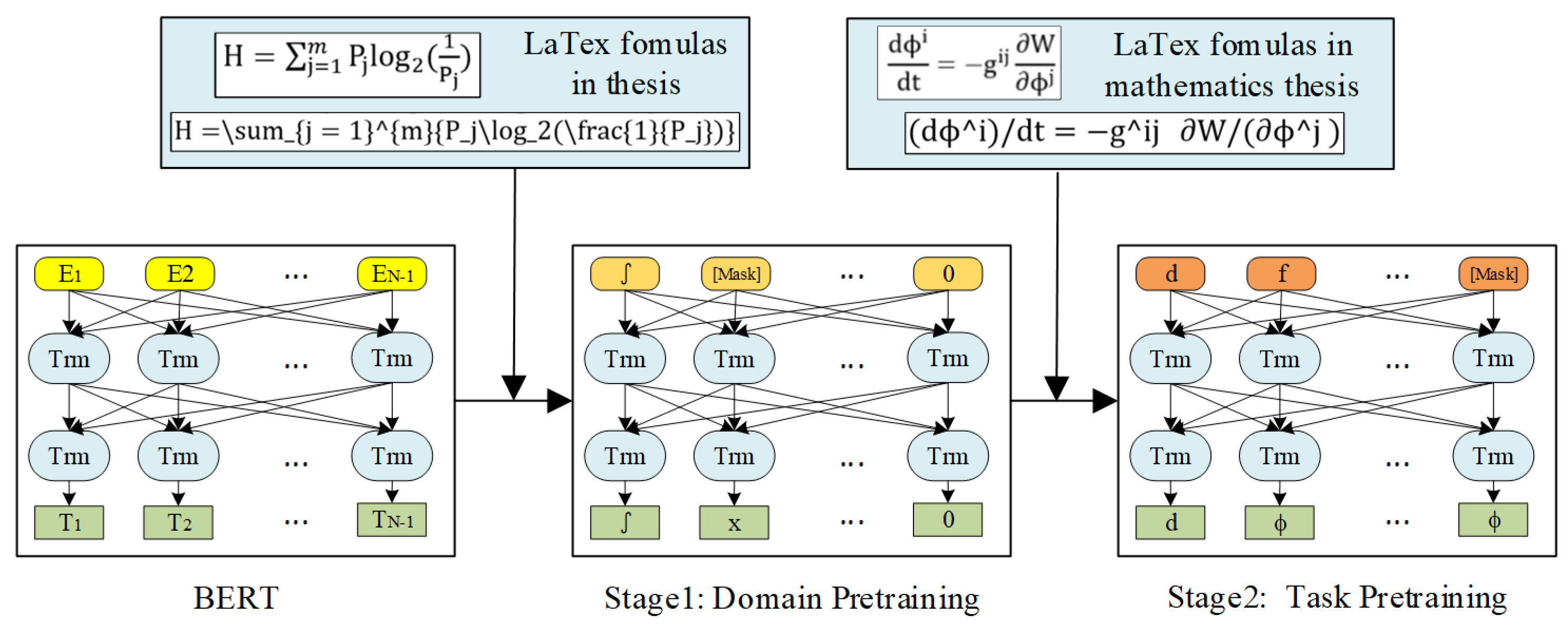
The pretrained models, such as BERT, are based on a general large-scale corpus such as BooksCorpus and English Wikipedia. We pretrained a two-stage Pretraining BERT model (TP-BERT) on unlabeled text data, including a domain pretraining stage and then a task pretraining stage. By adding the domain data to the pretraining dataset, the pretrained model can learn more targeted information from the domain data and the representation is more accurate in finetune.
The domain pretraining stage makes the pretrained model adapt more to the domain data, such as in BioBERT [
9], a linguistic representation model for biomedicine. The task pretraining stage pretrains on the task dataset, a narrowly-defined subset of the domain itself or data relevant to the task, which may be helpful for a specific task pretrained model.
Figure 1 shows the detail of the TP-BERT model of LaTeX formulas. BERT is trained with a masked language modeling objective to obtain TP-BERT based on domain data (LaTeX formulas in thesis) and task data (LaTeX formulas in mathematics thesis).
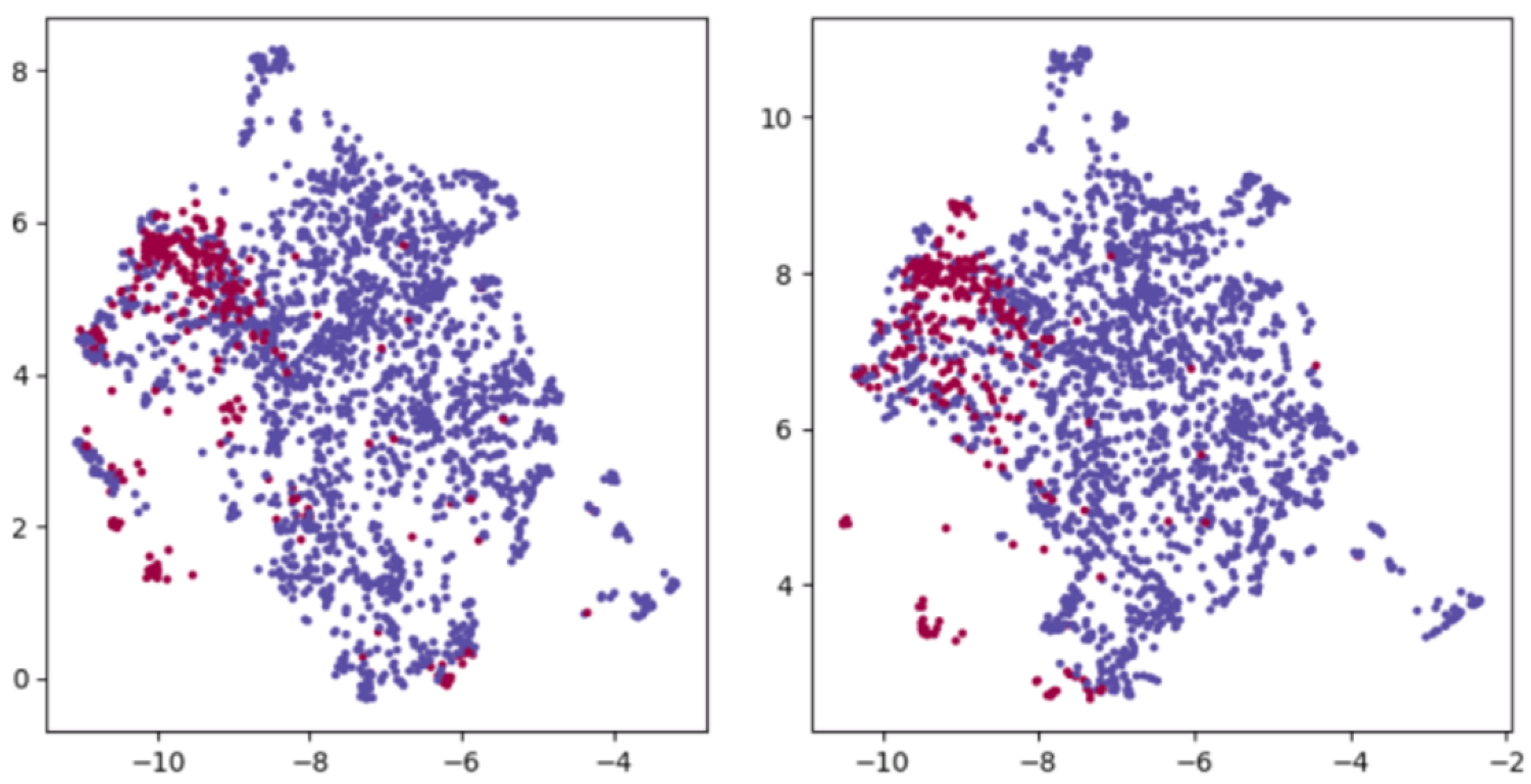
Figure 2 is the corresponding word vector spaces of BERT and TP-BERT on LaTeX mathematical formulas shown by UMAP [
17]. It demonstrates that the word vector of TP-BERT has changed after domain pretraining and task pretraining, where the red dots move down and left from the purple ones.
3. Unlabeled Data Enhanced Text Classification
3.1. Double-Prediction Pseudo-Labeling Method
Besides the role in pretraining, a new pseudo-label dataset can be produced based on unlabeled data by self-training, which is a helpful and effective in-model fine-tuning. The self-training method has been proposed for image recognition [
2], where it assigns pseudo-labels for unlabeled images by way of a noisy and inaccurate model which is only trained on a few labeled data. This noisy model is improved and retrained on both labeled and unlabeled images.
A revised self-training method on unlabeled text data is proposed to generate a high confidence pseudo-label from an input text and its variant. Considering the immaturity of the initial model trained with few labeled data, we improve the robustness of pseudo-label prediction, where the Double-Prediction Pseudo-labeling (DPP) method is proposed to obtain high confidence Pseudo-labels predicted by the last trained model.
The original training data are defined as with label , unlabeled data . The variants, the augmented unlabeled data , are obtained by adding auxiliary sentences to . Auxiliary sentences are meaningless texts that do not affect classification, such as ‘Without using a calculator, ⋯’ to . The DPP method in self-training is as follows:
- (1)
The UL-BERT model is fine-tuned based on TP-BERT by the original training dataset
. The cross-entropy loss function
is defined by:
where
m is the batch size and
l is the number of and classes,
y is the ground truth, and
p is the predicted label.
- (2)
Labels
and
are predicted based on an unlabeled dataset
and
by UL-BERT.
- (3)
For data with the same predicted labels whose prediction probabilities are both above a specific threshold
t, label
is taken as its pseudo-label. The higher prediction probability has better class confidence.
where
is the predicted probability, and
t is the threshold.
- (4)
The new dataset with pseudo-labels is obtained and combined with the original label dataset to train the classification model. In general, the problem of few labeled datasets can be solved by retraining UL-BERT with the new pseudo-labeled dataset from unlabeled data self-training, which improves the robustness, generalization and accuracy of the classification model.
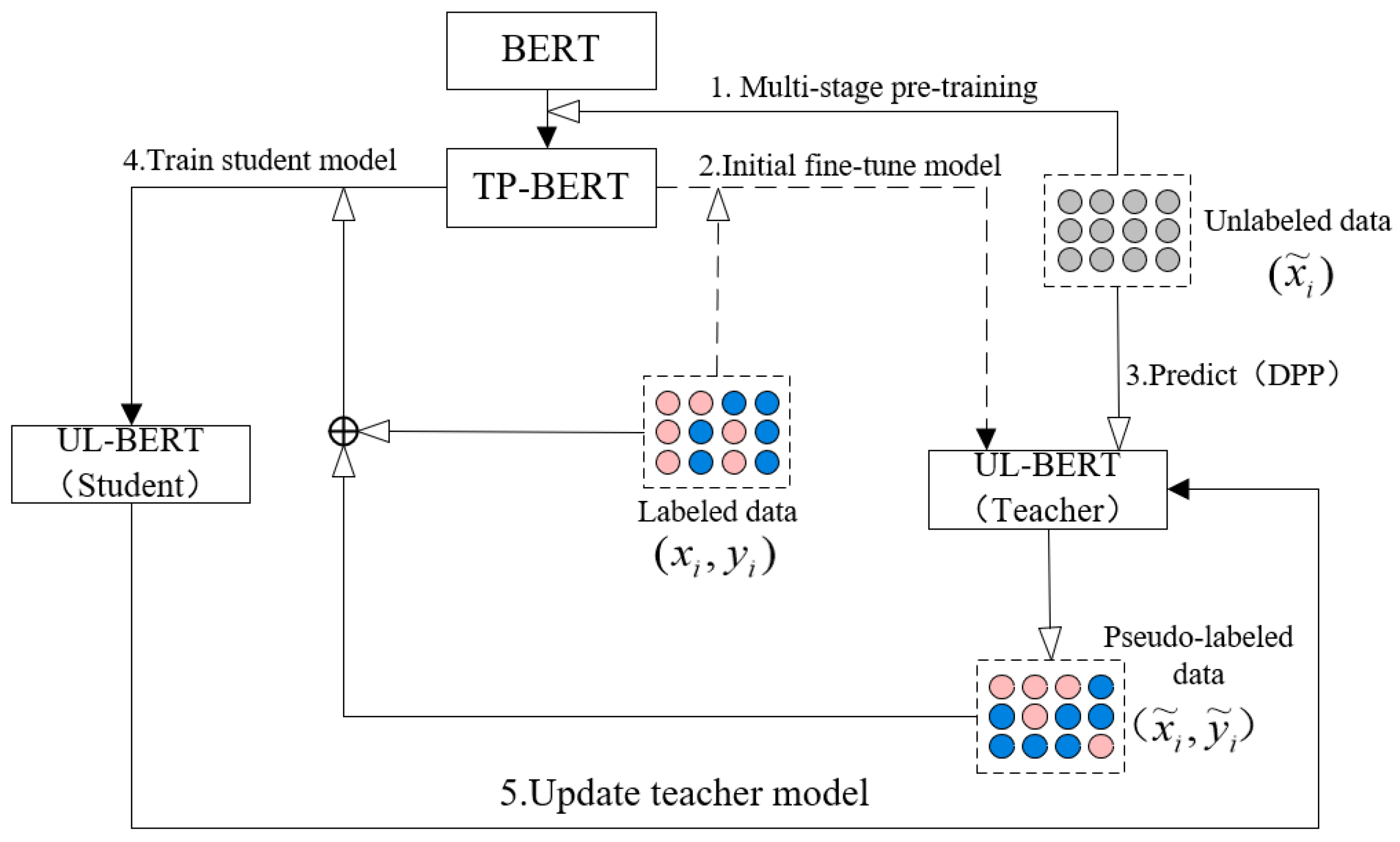
3.2. Multi-Rounds Teacher–Student Training Approach
The classification model should be trained for multi-rounds since the pseudo-labels from the single-round self-training are not accurate enough. The multi-rounds teacher–student training approach is proposed, where the Teacher model generates the pseudo-labels to retrain the Student model, and the Student model updates the Teacher model on the next training round.
The role of the Teacher model is to help and supervise the training of a better Student model. It can reduce the prediction instability caused by an immature model and improve its classification accuracy.
Figure 3 shows the training approach, and the training process is as follows:
TP-BERT is pretrained by the domain and task unlabeled data ;
For the first time, UL-BERT (Teacher) is fine-tuned based on TP-BERT by the original labeled data ;
By way of the DPP method, a high confidence label will be selected as an available pseudo-label
, which can be expressed as:
The UL-BERT model (Student) is fine-tuned on TP-BERT using the new dataset
and the original training data
. The cross-entropy loss function
from both data is given by:
where
m and
k are the batch size of the label data and pseudo-label data, which are selected from
;
is the pseudo-label and
is the pseudo-labeled data predicted label;
If the F1 score of the test dataset (by UL-BERT Student model) is better than the one (by UL-BERT Teacher model), the Teacher model will be updated by the Student model;
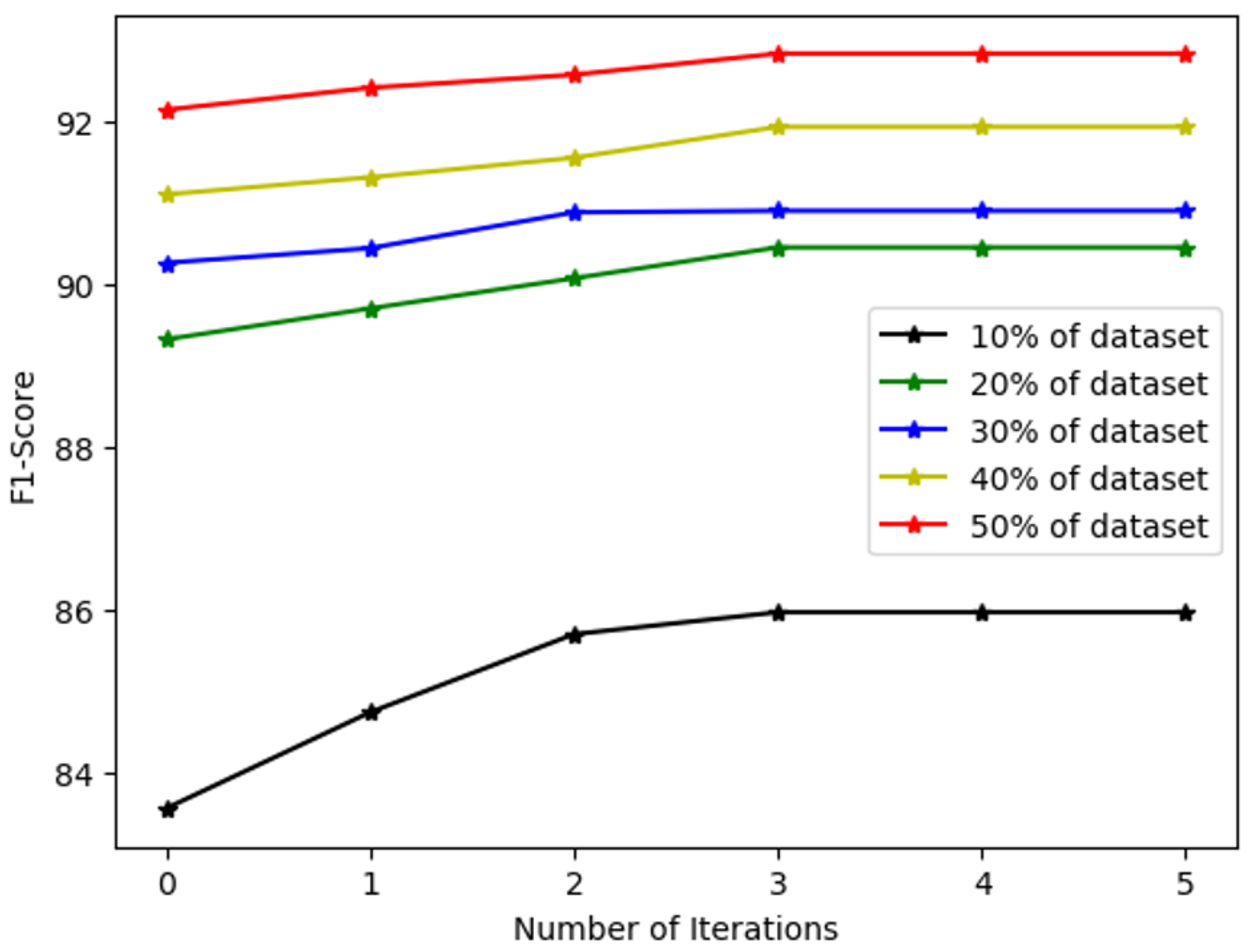
Repeat steps 3–5 until the F1 score of the test dataset of the Student model no longer increases.
5. Conclusions
Obviously, fully utilizing a large amount of unlabeled data is an important and effective way to promote the performance of the classification models of specific domains. The study of the LaTeX formulas demonstrates how to benefit from unlabeled data. The self-training method combined with pretraining is helpful for solving the problem of insufficient resources of labelled data. Experiments show that the proposed UL-BERT can improve the generalization and accuracy of the text classification model.
In our future work, we will conduct more experiments in other domains, such as biomedical and computer science publications, to prove the generalization of our method.In addition, since the cross-entropy loss function can be easily misled by incorrect pseudo-labels, we will use the loss function of contrast learning to modify the loss function of pseudo-labels to mitigate the influence of incorrect pseudo-labels and improve the model performance.








{kind=link}
{kind=link}
{kind=link}
{kind=link}