1. Introduction
Most recent deep learning breakthroughs are related to convolutional neural networks (CNNs), which are also the main developing area for deep neural networks (DNNs). Modern CNN approaches can be more accurate than humans for image recognition. The ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) [
1] is a highly representative academic competition for machine vision solutions based on image data provided by ImageNet. The main dataset comprises more than 14 million marked images, with a smaller subset sampled for the yearly ILSVRC. The best ILSVRC result prior to 2012 achieved a 26% error rate. However, a CNN model based on AlexNet [
2] reduced the error rate to 16.4% in 2012, winning the championship. Subsequent studies have used various CNN approaches, some going on to become major and well-known CNN architectures.
Many current products use deep learning technologies, most of which relate to image recognition. Recent hardware breakthroughs and significant improvements have brought a strong focus onto deep learning, with CNN models becoming the most popular approaches for image recognition, image segmentation [
3,
4,
5] and object recognition. Image recognition refers to the process where a machine is trained using CNNs to extract important features from large image datasets, combine them into a feature map and perform recognition by connecting neurons. The approach has been successfully applied to various areas, such as handwriting recognition [
6,
7,
8], face recognition [
9,
10,
11], automatic driving vehicles [
12], video surveillance [
13] and medical image recognition [
14,
15,
16,
17].
With the development of computer technology applied to the medical field, whether through basic medical applications, disease treatments, clinical trials or new drug therapies, all such applications involve data acquisition, management and analysis. Therefore, determining how modern medical information can be used to provide the required data is an important key to modern medical research. Medical services mainly include telemedicine, information provided through internet applications and digitization of medical information. In this way, we more accurately and quickly confirm a patient’s physical condition and determine how best to treat a patient, thereby improving the quality of medical care. Smart healthcare can help us to establish an effective clinical decision support system to improve work efficiency and the quality of diagnosis and treatment. This is of particular importance in the aging population in society, which has many medical problems. In addition, the COVID-19 [
18,
19,
20,
21,
22] outbreak in 2020 greatly increased the demand for medical information processing. Therefore, medical information is combined with quantitative medical research; in addition, assistance in diagnosis from an objective perspective is a trend at present. The development of big data systems has also enabled the systematic acquisition and integration of medical images [
23,
24,
25,
26,
27]. Furthermore, traditional image processing algorithms have gradually been replaced by deep learning algorithms.
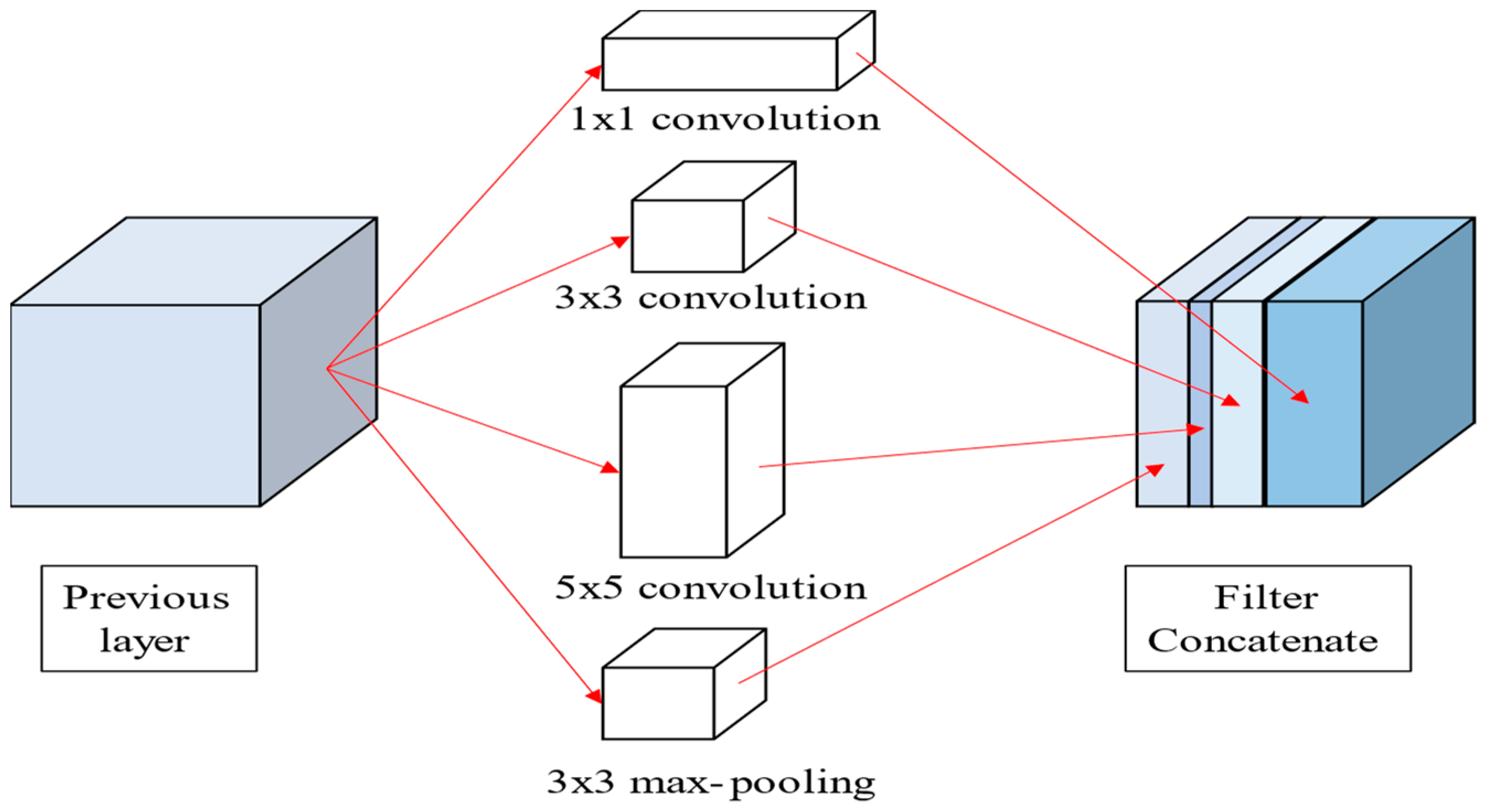
Recent deep learning and machine learning developments mean that traditional image processing method performance for image recognition is no longer comparable to that of neural network (NN)-based approaches. Consequently, many studies have proposed optimized deep learning algorithms to improve image recognition accuracy for various recognition scenarios. CNN is the most prominent approach for image recognition, improving recognition accuracy by increasing hidden layer depths and effectively acquiring more characteristic parameters. Successful image recognition applications include face, object, and license plate recognition, but medical image recognition is less common due to difficulties acquiring medical images and poor understanding regarding how diseases appear in the various images. Therefore, physician assistance is usually essential for medical image recognition to diagnose and label focal areas or lesions before proceeding to model training. This study used open-source thoracic X-ray images from the Kaggle data science community, which were already categorized and labeled by professional physicians. Recognition systems were pre-trained using LeNet [
28], AlexNet [
2], GoogLeNet [
29] and VGG16 [
30] images, but trained VGG16 model classification exhibited poor image classification accuracy in the test results. Therefore, this paper proposes IVGG13 to solve the problem of applying VGG16 to medical image recognition. Several other well-known CNNs were also trained on the same datasets, and the outcomes were compared with the proposed IVGG13 approach. The proposed IVGG13 model outperformed all other CNN models considered. We also applied data augmentation to increase the raw dataset and improve the data balance, hence improving the model recognition rate. It is essential to consider hardware requirements for CNN training and deployment. The number of network control parameters increases rapidly with increasing network layer depth, which imposes higher requirements on hardware and increases overhead and computing costs. Therefore, this paper investigated methods to reduce network depth and parameter count without affecting recognition accuracy. The proposed IVGG13 incorporates these learnings, and it has strong potential for practical medical image recognition systems.
The remainder of this paper is organized as follows. The related works are described in
Section 2. The research methodology is stated in
Section 3. The performance evaluation is outlined in
Section 4. Finally, conclusions and suggestions for future research are provided in
Section 5.
3. Research Methods
This section discusses various study approaches.
Section 3.1 introduces the source and classification for image datasets used in this study;
Section 3.2 describes data augmentation pre-processing to solve unbalanced or small dataset problems; and
Section 3.3 presents the proposed IVGG13 model.
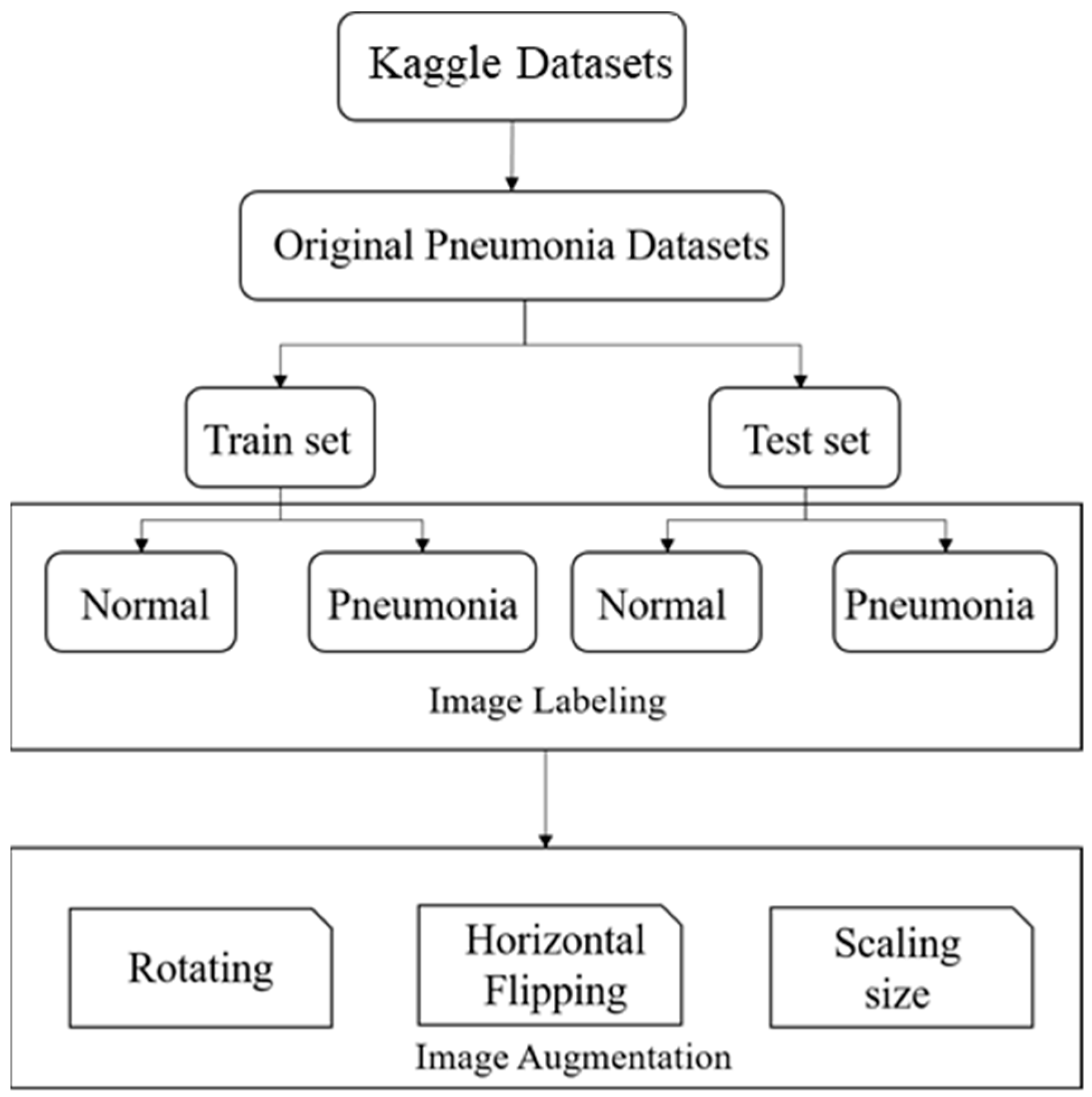
Figure 6 shows the flow chart of data pre-processing and
Figure 7 exhibits the proposed CNN training process. LeNet, AlexNet, GoogLeNet, VGG16 and IVGG13 models were trained with the original datasets without data augmentation and then evaluated and compared. The models were subsequently trained with augmented datasets and again evaluated and compared.
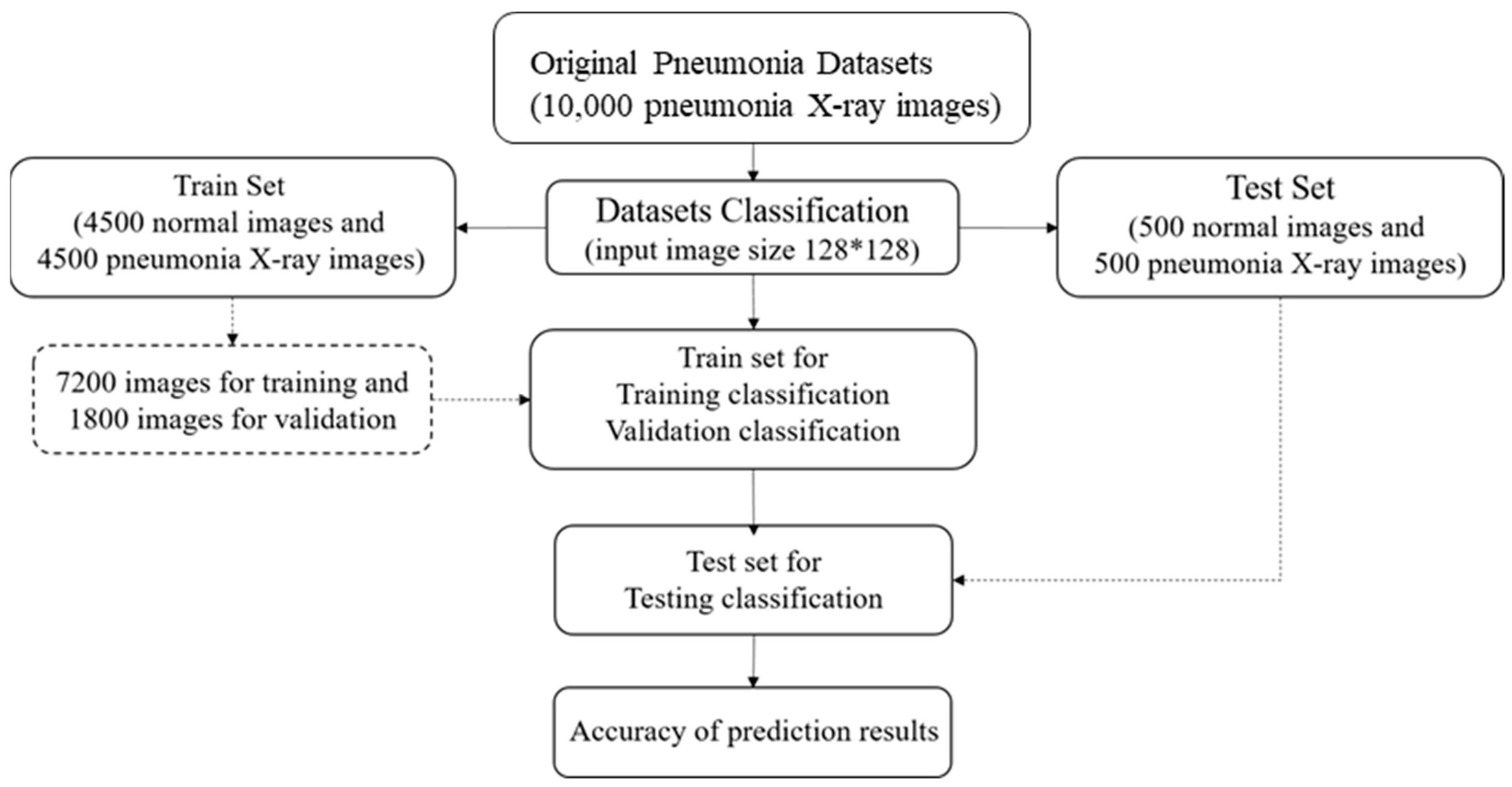
3.1. Training Datasets
We used an open-source dataset provided by the Kaggle data science competition platform for training (
https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia accessed on 25 March 2018) [
31]. The dataset comprised thoracic cavity images from child patients (1 to 5 years old) from the Guangzhou Women and Children’s Medical Center, China. These images were classified by two expert physicians and separated into training, test and validation sets.
Figure 8 displays the dataset structure, with training sets including 1341 and 3875, test sets 234 and 390, validation set 8, and eight normal and pneumonia images, respectively.
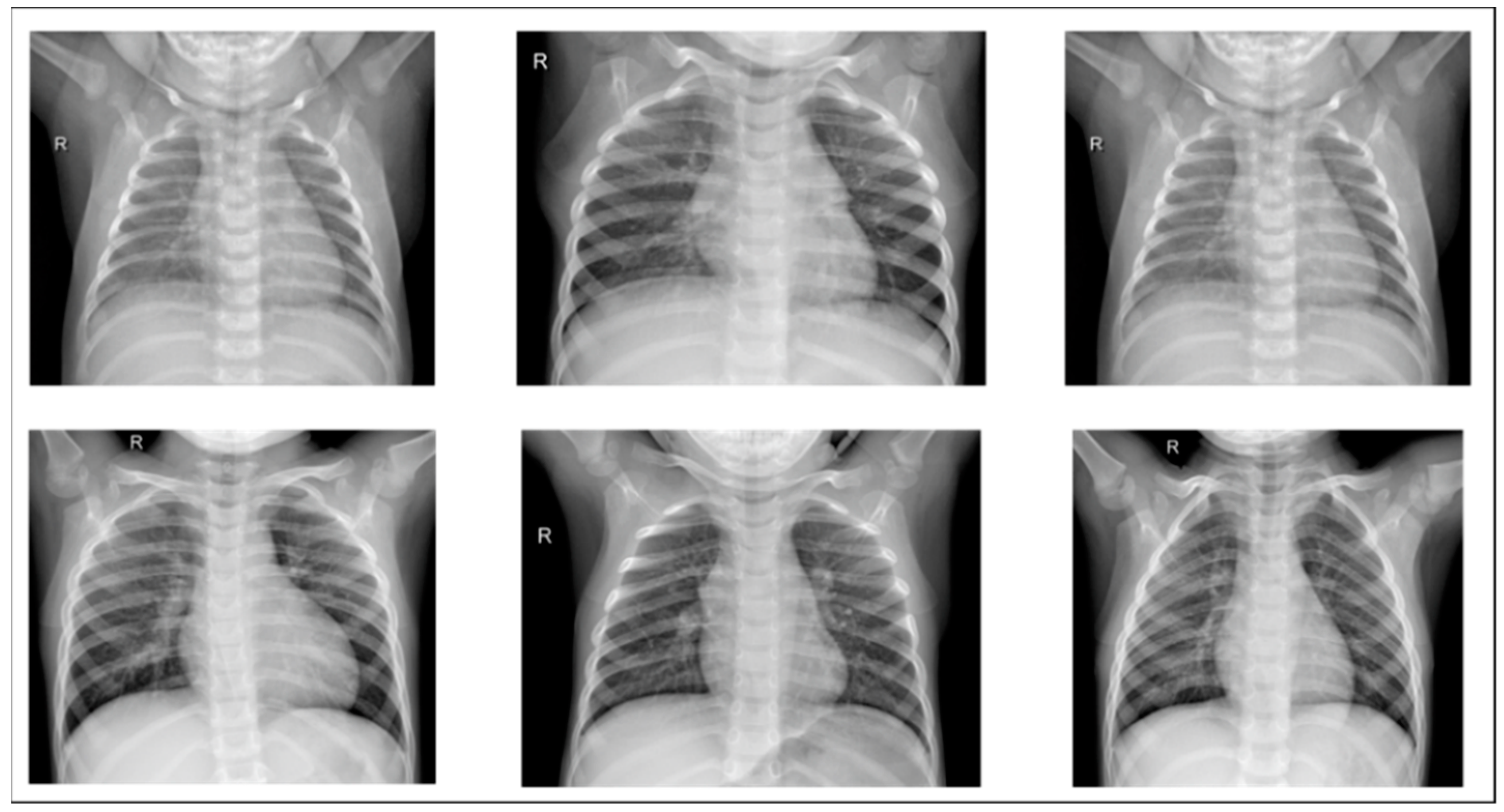
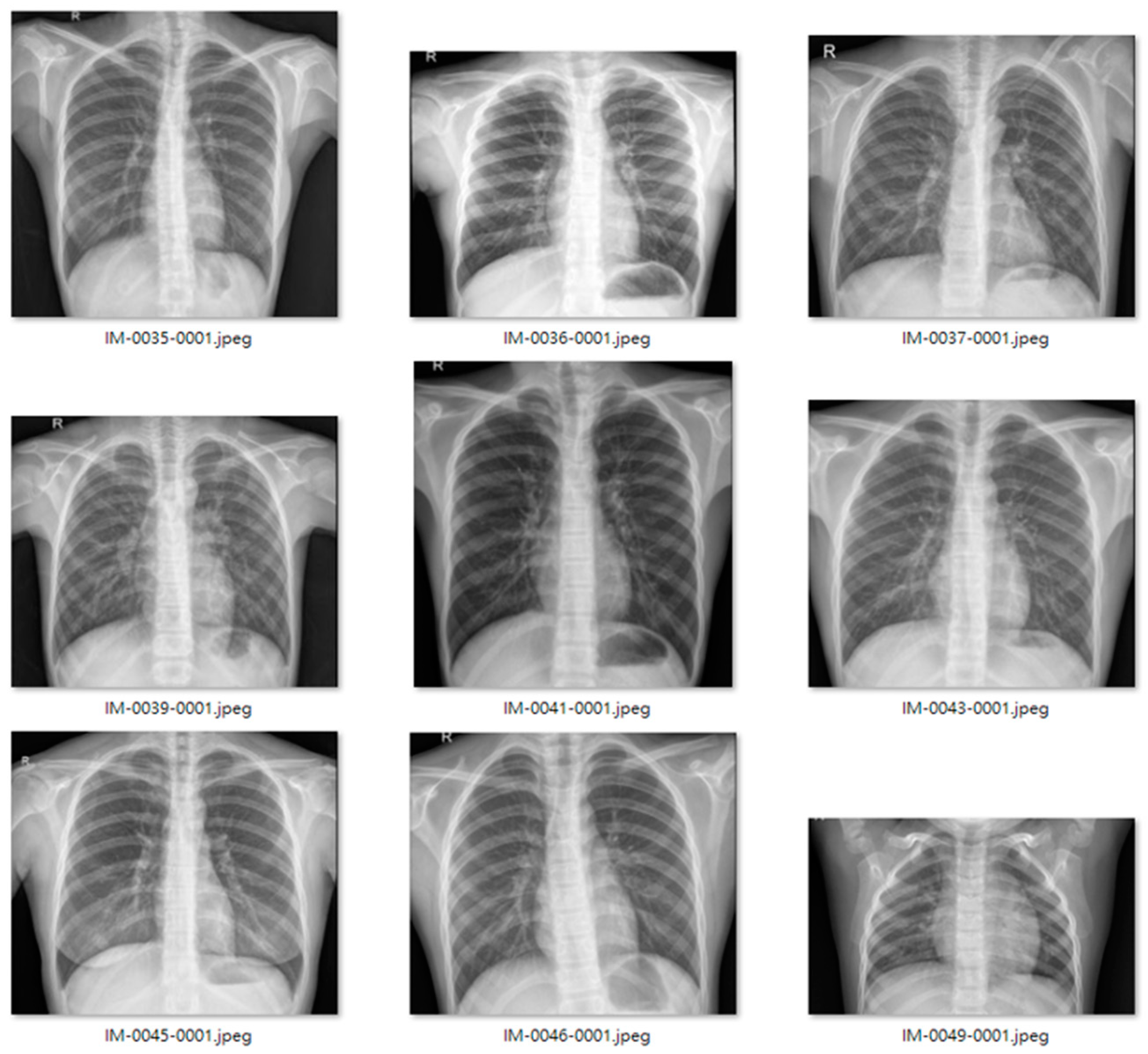
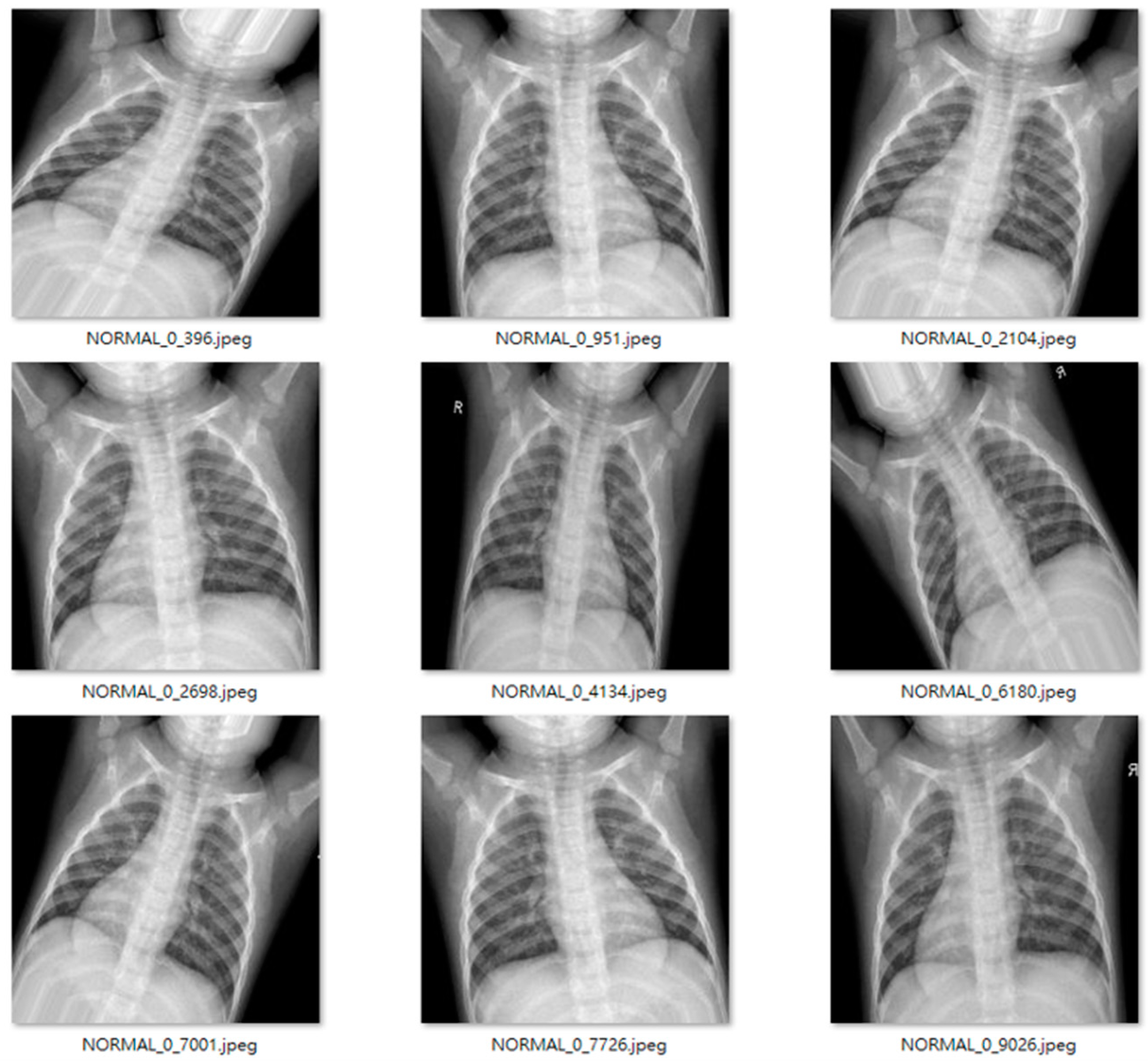
Figure 9 and
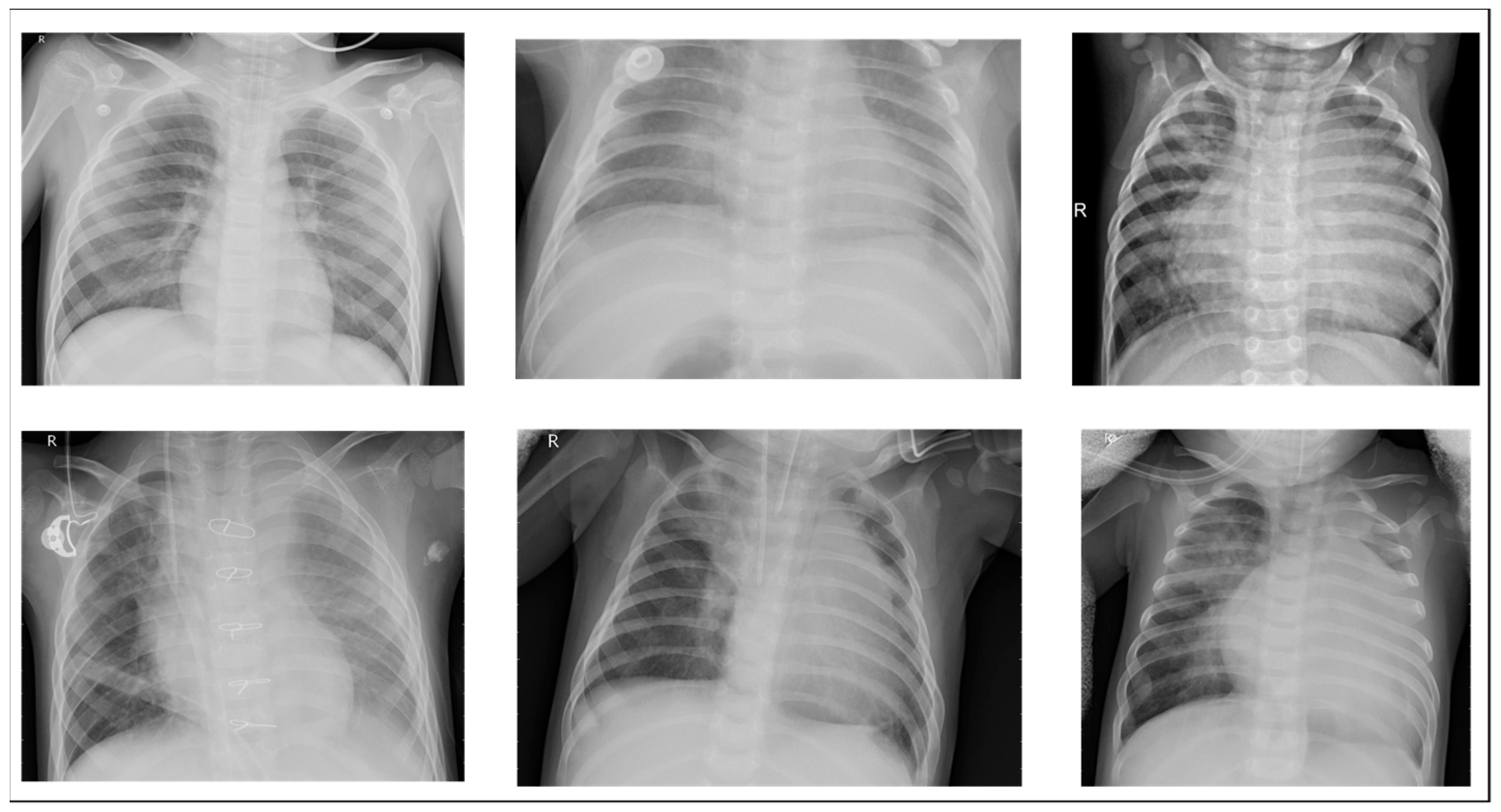
Figure 10 show examples of normal and pneumonia thoracic cavity X-ray images, respectively.
3.2. Data Augmentation
The study dataset included unbalanced positive and negative samples, with significantly fewer normal images than pneumonia images in both training and test sets and relatively low data volume. This could lead to poor post-training validation and overfitting. Therefore, we applied data augmentation on the original datasets, creating new images by horizontal flipping, rotating, scaling size and ratio, and changing brightness and color temperature for the original images to compensate for the lack of data volume. Data augmentation increased the training set from 5216 to 22,146 images, and the test set from 624 to 1000 images. Furthermore, some images were transferred from the training to test set for data balance and to ensure images in the test set were predominantly originals.
Figure 11 and
Figure 12 show examples of original and augmented images, respectively.
3.3. IVGG13
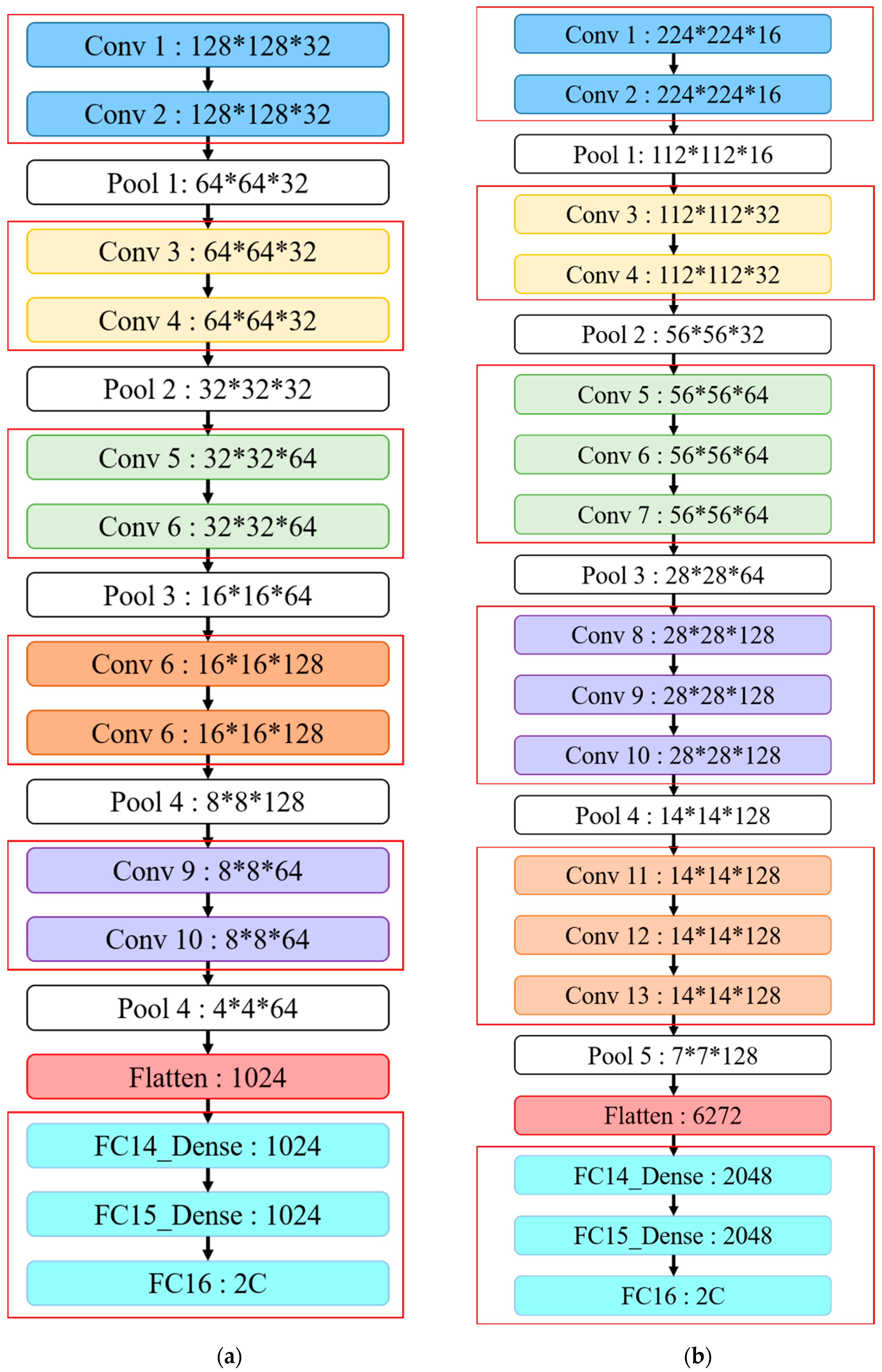
This study proposes IVGG13—an improved VGG16 that reduces the VGGNet network depth—as shown in both
Table 1 and
Figure 13. The proposed network architecture reduces the number of parameters by reducing the network depth compared to the original VGG16 to avoid both under- and overfitting problems during training. The original VGG16 convolutional architecture was retained by performing feature extraction using two consecutive small convolutional kernels rather than a single large one. This maintains VGG16 perceptual effects while reducing the number of parameters, which not only reduces the training time but also maintains the network layer depth.
Figure 13 highlights the similarities and differences between the IVGG13 and VGG16 network architectures.
First, the input image size was changed to 128 × 128, and the hidden layer was divided into five blocks, with each block containing two convolutional layers and a pooling layer. Thirty-two 3 × 3 convolutional kernels were randomly generated in each convolutional layer for feature extraction, and the image size was reduced by the pooling layer. Convolutional kernels in blocks 3–5 were the same size (3 × 3), but 64, 128 and 64 kernels in each block, respectively. Reducing convolutional kernels reduced the number of parameters required compared with VGG16. The image size was then reduced by the pooling layer, feature maps were converted to one dimension by the flattened layer and finally, three of the fully connected layers concatenated output features into two classifications.
4. Results
This section provides a concise and precise description of the experimental results, their interpretation, as well as the experimental conclusions that can be drawn.
Section 4.1 introduces the experimental environment of this article.
Section 4.2 introduces and compares various CNNs;
Section 4.3 and
Section 4.4 discuss model outcomes without and with data pre-processing, respectively; and
Section 4.5 discusses VGG16 problems highlighted by the experimental results.
4.1. Experimental Environment
This study used a workstation with Windows 10, Intel Core i5-8500 @ 3.00 GHz CPU, Nvidia GeForce RTX2070 8 G GPU, and 32.0 GB RAM. TensorFlow-GPU was employed to train the CNN in Python 3.5.6 by Anaconda3, with Python Keras to build the network architecture and training.
4.2. CNN Comparison
4.2.1. LeNet
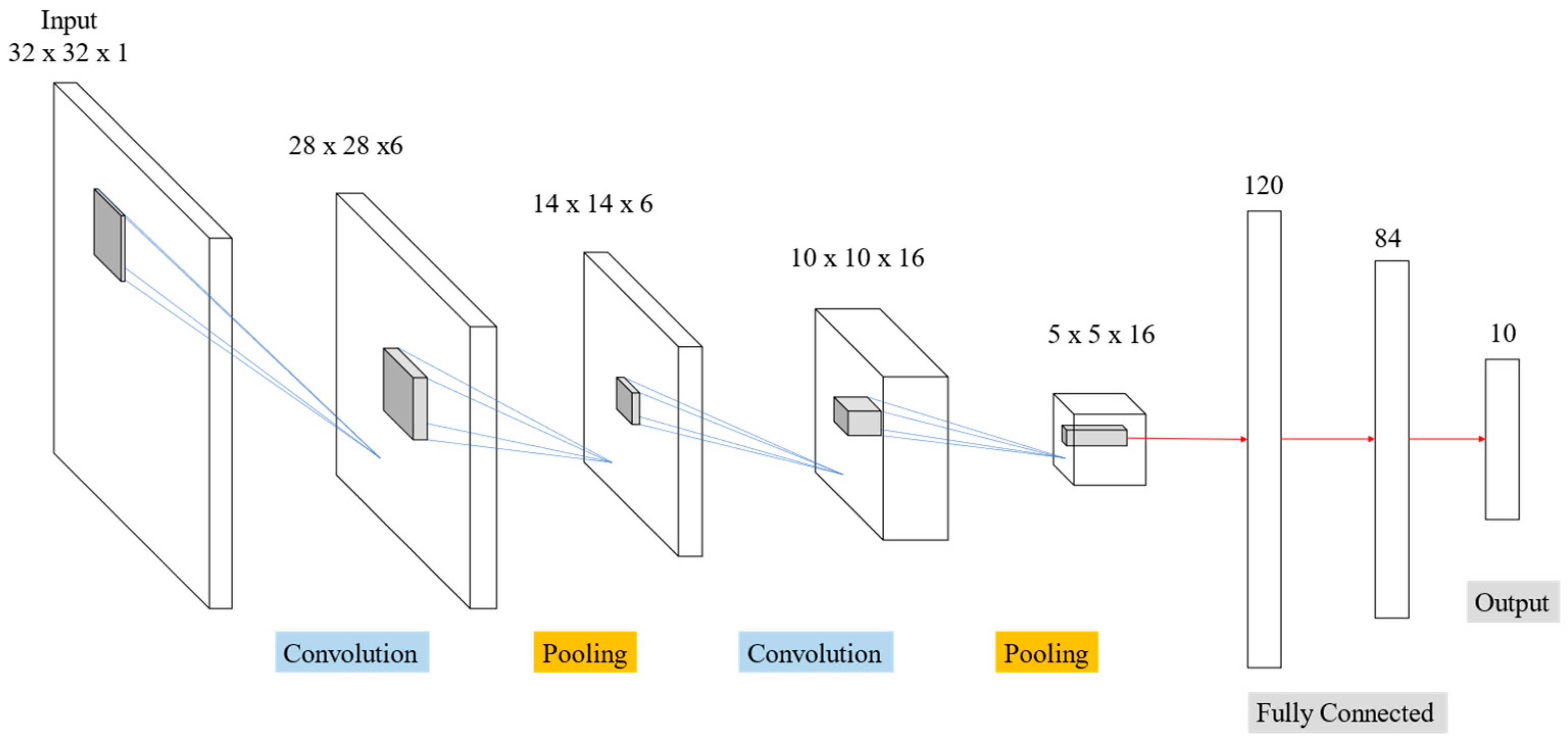
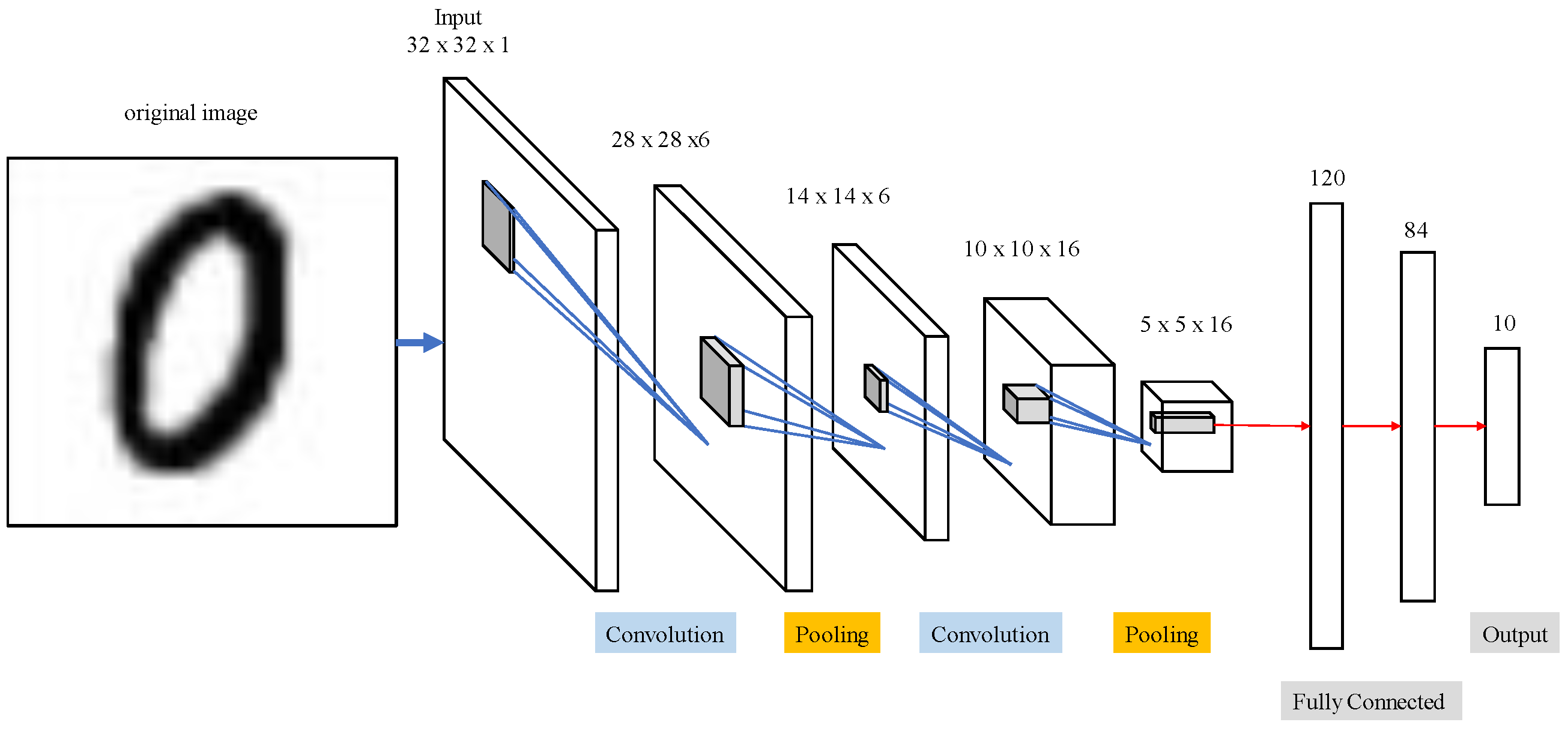
Table 2 and
Figure 14 display outcomes from LeNet network for MNIST handwriting character recognition applied to train thoracic X-ray images. Sixteen 5 × 5 convolution kernels were randomly generated from each 28 × 28 input image, and the first convolution generated 16 (28 × 28) images. Images then reduced to 14 × 14 using reduction sampling in the pooling layer. The second convolution converted the 16 images into 36 14 × 14 images using 5 × 5 convolutional kernels. The image size was then further reduced to 7 × 7 by reduction sampling in the pooling layer. Finally, the features were converted into one dimension in the flattening layer, fully connected, and output as two categories.
4.2.2. AlexNet
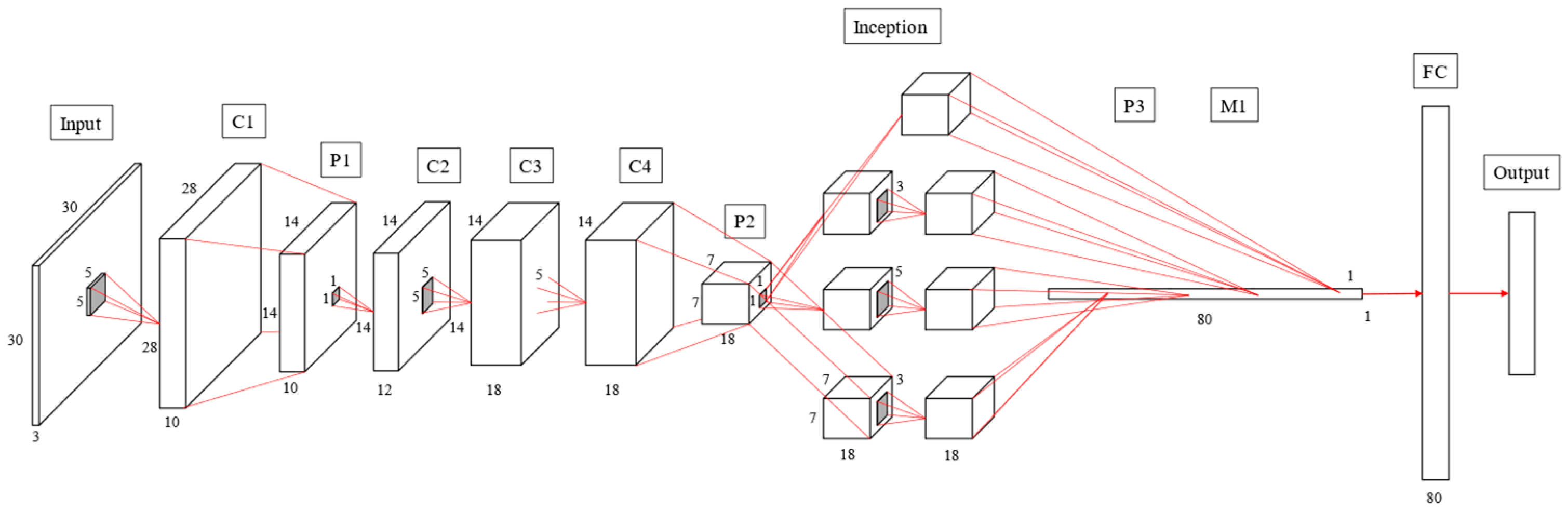
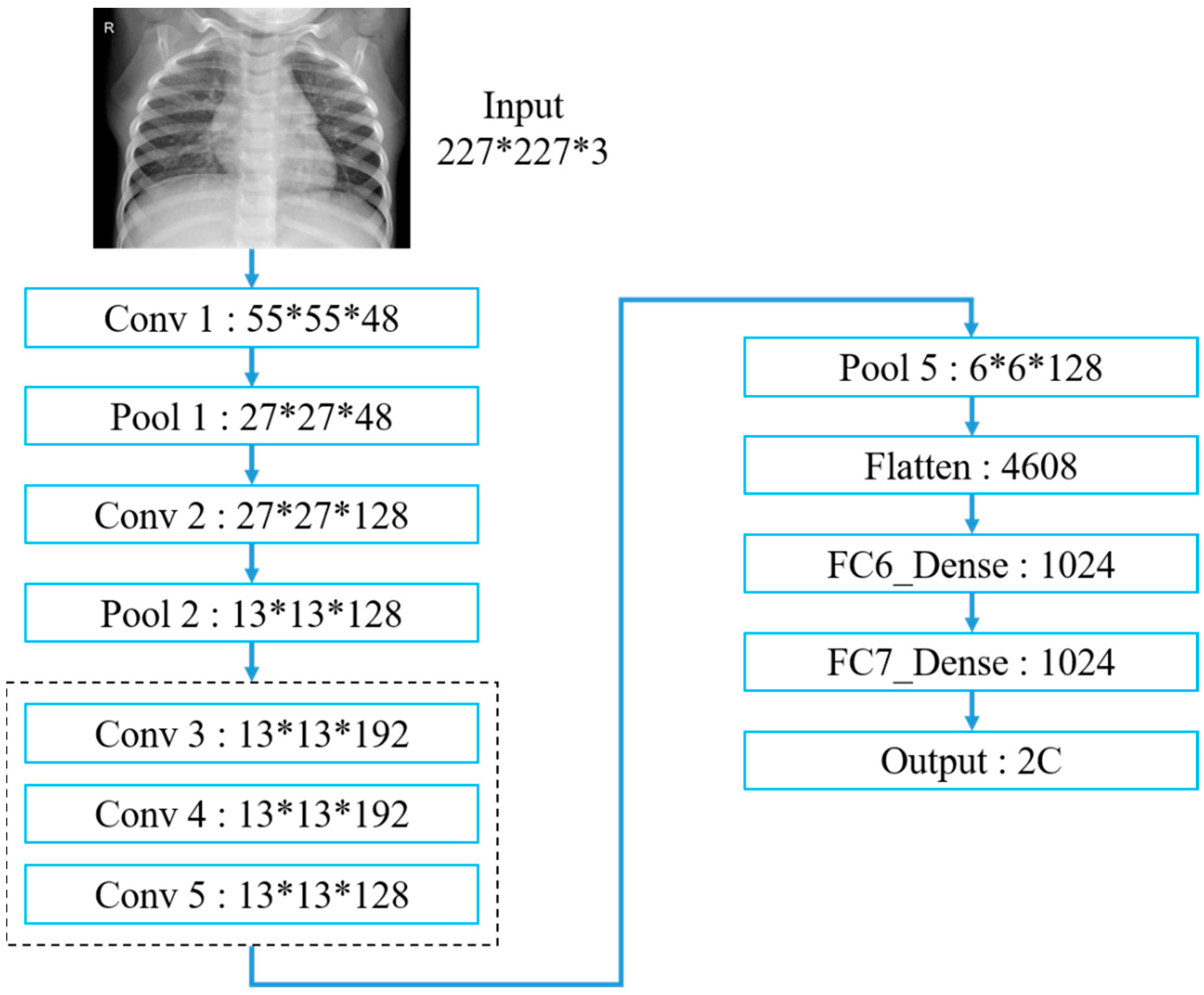
Table 3 and
Figure 15 exhibit the AlexNet architecture used to train thoracic X-ray images, which comprise five convolutional and three fully connected layers, with 227 × 227 input images. The first convolutional layer included 48 (11 × 11) convolutional kernels to produce 227 × 227 images, followed by local response normalization in the LRN layer to reduce images to 55 × 55 using 3 × 3 max pooling. The second convolutional layer was similar to the first, but included 128 (5 × 5) convolution kernels. Subsequent LRN and max pooling layers reduced image size to 13 × 13, with convolution layers 3–5 employing 192, 192 and 128 (3 × 3) kernels, respectively, producing 13 × 13 images. Images were reduced to 6 × 6 using a max pooling layer, and features were converted to one dimension in the flattening layer, fully connected, and output as two categories.
4.2.3. VGG16
Considering the selected workstation performance, we only used VGG16 CNN for this study. First, we used the VGG16 model and applied it to pneumonia X-ray data for training, but the prediction results failed.
Table 4 and
Figure 16 indicate that our VGG16 architecture contains 13 convolutional and 3 fully connected layers, with 3 × 3 kernels for the convolutional layers and 2 × 2 parameters for the pooling layers. VGG16 convolutional and pooling layers are divided into blocks 1–5, where each block contains multiple convolutional layers and a single pooling layer. The two convolutional layers in block 1 each use 16 kernels for feature extraction, with image size subsequently reduced in the pooling layer. Subsequent blocks have similar architecture, except that blocks 1 and 2 use two convolutional layers, whereas blocks 3–5 use three convolutional layers with different kernel numbers in each layer to deepen the network and improve accuracy. Finally, three fully connected layers concatenate and output features into two classifications.
4.3. Results without Data Pre-Processing
This section discusses the recognition rates for LeNet, AlexNet, VGG16, GoogLeNet and IVGG13 trained without data augmentation. The dataset before augmentation comprised 1349 and 3883, and 234 and 390 normal and pneumonia images in the training and test sets, respectively. The training parameters included the learning rate = 0.001, maximum epoch = 60 and batch size = 64.
Table 5 display the average confusion matrix outcomes over five repeated trainings for each network, respectively.
Figure 7 compares the overall network performance calculated using Equations (1)–(4). A good prediction model requires not only high accuracy but also generalizability. Generally, the validation is initially high, because the validation data is primarily used to select and modify the model; if the right validation data is selected at the beginning, the value of validation will exceed the accuracy value of the training set. Conversely, if the wrong data is selected, the parameters will be corrected and updated.
Evaluation metrics are usually derived from the confusion matrix (
Table 6 and
Table 7) to evaluate classification results, where true positive (TP) means both actual and predicted results are pneumonia; true negative (TN) means both actual and predicted results are normal; false positive (FP) means actual results are normal but predicted to be pneumonia; and false negative (FN) means actual results are pneumonia but predicted to be normal.
Table 8 compares the evaluation results for each model, where accuracy, precision, recall and F-measure were calculated as shown in Equations (1)–(4). Precision is the proportion of relevant instances among those retrieved, recall is the proportion of relevant instances that were retrieved and the F1-measure is a special case of the F-measure for
β = 1, i.e., precision and recall are equally important. A larger F1 means improved model effectiveness.
4.4. Results after Data Pre-Processing
We applied data augmentation to investigate the effects on model accuracy using datasets containing 4000, 5000, 6000, 7000, 8000, 9000 and 10,000 randomly selected images from the training set for each network model. Training parameters included learning rate = 0.001, maximum epoch = 60 and batch size = 64.
Table 9 exhibits performance metrics calculated using Equations (1)–(4) for comparison by using the different datasets.
Table 10 compares the best evaluations for each model. Although GoogleNet has higher accuracy and precision, the recall rate is much lower. It is therefore important to use the F1-measure as the model evaluation standard. Both precision and recall are equally important.
4.5. VGG16 Problems
The preceding analysis highlighted several VGG16 problems with extracting features from medical image datasets. VGG16 was originally applied in the ILSVRC to recognize 1000 categories from 1 million images. Therefore, applying it to small datasets with fewer training features led to significant underfitting [
32]. It has always been difficult to distinguish pneumonia presence or absence on thoracic X-ray images; image features are too homogeneous, making it difficult for models to capture relevant features. Therefore, training with deeper network layers often creates recognition errors.
Table 11 confirms the matrix for each dataset and that VGG16 also failed, even after augmentation.
5. Conclusions and Prospects
5.1. Conclusions
Since LeNet’s emergence, CNNs have continued progressing with many breakthroughs and developments, and they provide great benefits for image recognition. Computational hardware and capacity have also improved significantly, supporting DNN requirements and extending their applicability. Therefore, developing deeper NNs to extract features can effectively and continuously improve recognition accuracy and, hence, modern CNN architectures commonly include many layers. First of all, we discovered the prediction result of using the VGG16 model on failed pneumonia X-ray images. Thus, this paper proposes IVGG13 (Improved Visual Geometry Group-13), a modified VGG16 model for the classification pneumonia X-rays images. Therefore, this paper proposed IVGG13, a modified CNN for medical image recognition by using open-source thoracic X-ray images from the Kaggle platform for training. The iVGG13 recognition rate was compared with the best current practice CNNs, which confirmed IVGG13′s superior performance in medical image recognition and also highlighted VGG16 problems.
Data augmentation was employed to effectively increase data volume and balance before training. Recognition accuracy without data augmentation ranged from 74% to 77%, increasing to >85% after data augmentation, which confirmed that data augmentation can effectively improve recognition accuracy.
The proposed IVGG13 model required less training time and resources compared with the other considered CNNs. IVGG13 reduced layer depth with smaller convolutional kernels and, hence, used significantly less network parameters; this greatly reduced hardware requirements while achieving comparable or superior recognition accuracy compared with the other models considered. An accuracy of ≈89% was achieved after training with the augmented dataset, which is significantly superior to the other current best practice models.
5.2. Future Research Directions
Outcomes from this study suggest the following future directions:
We expect the proposed IVGG13 to improve its model recognition rate to above 90% after optimizing the network architecture or image processing methods, ensuring a high recognition rate and stable system with good performance for future practical application in medical clinical trials.
The proposed IVGG13 model with enhanced performance in X-ray image recognition is expected to be used for the study of kidney stones issues, such as KUB images classification.
The proposed IVGG13 model could be combined with object detection to effectively provide physicians with accurate focal area detection during diagnosis to facilitate early disease detection and prevention.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}