1. Introduction
In recent years, driven by industry 4.0, data-driven enterprises have become a global trend. The pandemic has changed the way companies work, and contents on the internet and paper documents are growing exponentially. The demand for document digitization by commercial and non-commercial institutions (such as banks, enterprises, educational institutions, or libraries) is gradually increasing, which can greatly improve the availability of data. However, extracting text data manually is a complicated, time-consuming, and impractical process to obtain reliable information from paper documents [
1,
2,
3]. Office Automation is essential to the contemporary pursuit of a paperless work environment, and in most cases, it is completed by scanning and mail transmission. As the number of documents to be processed increases, the demand for automatic text information extraction will also grow rapidly [
4], and using Optical Character Recognition (OCR) to automate the process of text information acquisition can reduce human work and greatly improve the overall speed [
5]. Although OCR performs automatic retrieval of information in the text area of a document, the current technology is suitable only for simple text data, thus, it will easily result in recognition errors for complex information [
6,
7]. Data formats are mainly structured, semi-structured, and unstructured. Structured data are data processed for easy analysis; unstructured data are unprocessed data, such as common emails, images, and PDFs; semi-structured data refers to data between structured data and unstructured data. In addition, due to the improvement and development of the Internet of Things technology, a large amount of text data can be received and exchanged in a variety of ways in the future. In this case, it is important to protect personal privacy and protect shared data [
8]. Lin et al. [
9] proposed an ant colony optimization (ACO) method that uses multiple goals and uses transaction deletion to protect confidential and hide sensitive information. Wu et al. [
10] proposed a genetic algorithm (GA)-based framework for privacy in the field of data mining through sensitive patterns of different lengths, in order to hide sensitive information for data sanitization. When dealing with documents, privacy and sensitivity towards information in the text will be considered. Therefore, the realization of automatic text information acquisition faces various challenges.
Robotic Process Automation (RPA) is a concept that automates repetitive and tedious tasks [
11], and the concept of rules-based or knowledge-based RPA has existed for a long time, and with the development of artificial intelligence, its concepts, methods, and technology have more flexible availability [
12]. Over the past decade, advances in artificial intelligence have changed the operation mode of most businesses in dealing with business processes, thus, companies are beginning to apply artificial intelligence to many business processes, which can significantly reduce costs, improve efficiency, and increase profits. IT, finance, insurance, medical care, education, government, and other industries spend a lot of manpower on document processing [
13]; however, the difficulty of processing unstructured images, texts, documents, voices, and films is greatly increased [
14]. Therefore, automated document management systems (ADMS) and intelligent document processing (IDP) are receiving great attention. As the demand for digital documents to replace paper documents is growing rapidly [
15], the development of automatic document analysis focuses on Natural Language Processing (NLP) [
16]. Although words are the basic means of conveying information, tables are used in many documents to help convey information faster; therefore, effective automatic document processing methods to obtain text information from tables and charts are essential [
17], as most documents combine text and charts. When converting paper documents, converting charts into digital documents is particularly labor-intensive. As an important element in a document, tables can express more information in fewer words; however, due to the different arrangement of tables and words, detection of tables is still a major challenge, although a number of methods have been proposed [
18].
In recent years, Deep Convolution Neural Networks have been proved to be applicable to highly complex visual recognition. Object detection, which is widely used in natural scenes and forms the basis of many other visual detection models [
19], has been widely applied in various fields, such as automatic driving [
20] and object tracking [
21]. In the field of document analysis, the combination of Support Vector Machine and Deep Neural Network initially replaced traditional machine learning to promote RPA to help solve unstructured document data [
22], thus, the convolution model has been gradually used for document analysis [
23,
24]. Hao et al. [
25] applied Deep Convolution Neural Networks to detect forms in PDF files. Saha et al. [
26] used graphical object detection and transfer learning to locate graphic objects in documents. As object detection is scalable and flexible, it has been used in unnatural scenes, and its detection effect is remarkable. With the popularity of object detection algorithms based on deep learning in recent years, the object detection method can be used to detect images, tables, and formulas in document images. Documents are composed of text areas and charts, which are complex text data. The tables in a document are rows and columns that represent relevant information content, which is convenient for readers to understand and analyze the text. However, the appearance, typesetting, and layout of tables vary greatly, and the size and style depend on the habits of the writer, thus, during document analysis, the wide variety of sizes, colors, and fonts can produce very different results. Therefore, this study used the object detection method Single Shot Detector (SSD) [
27] to identify complex table areas, and integrated U-Net [
28], which is an image segmentation model that merges and retains marginal information through its autoencoder features. In addition, dilated convolution was added to compensate for the slight loss of feature information and maximize the retention of table features. Accurate edge information can minimize errors of table detection, facilitate subsequent OCR operation, and improve the overall process efficiency.
The contributions of this study include improved SSD and the end-to-end table detection model. VGG in the original SSD architecture was replaced with U-Net to increase edge features, and 8 additional convolution layers were added to increase feature extraction. In addition, the concept of dilated convolution was introduced to reduce information loss during feature transmission. Finally, six feature maps of different scales were selected to detect targets of different sizes. The edge prediction errors of the table are greatly reduced by the proposed method and the detection effect is remarkable. This experiment used the dataset of accident claim documents, as provided by a Taiwanese law firm, and the performance of proposed method was also evaluated on TableBank, Github, and ICDAR13 datasets. The results show that the network architecture based on SSD can achieve good performance.
3. Proposed Method
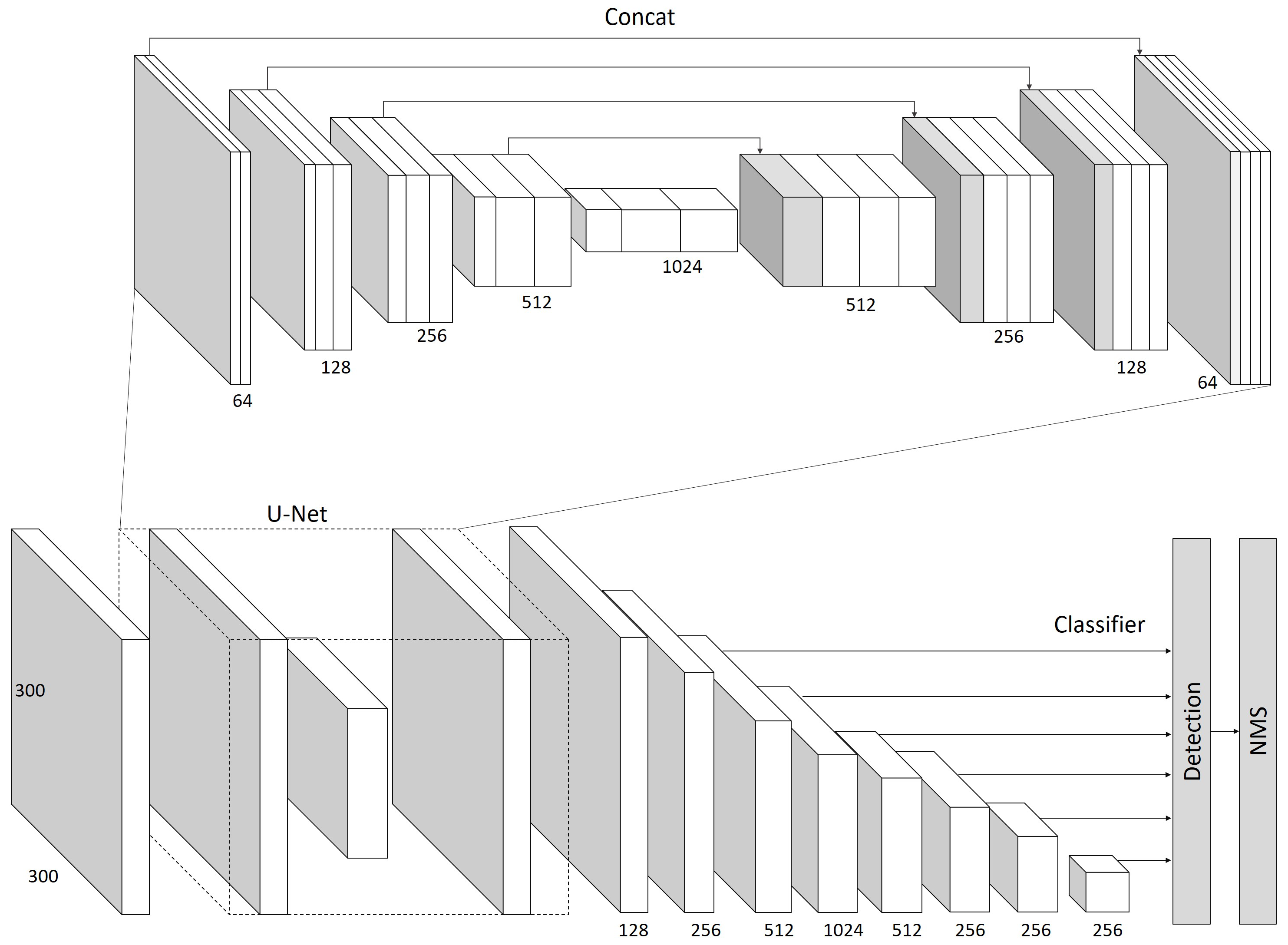
The model architecture proposed in this paper is based on SSD, and the original VGG model was improved by U-Net, which is called U-SSD, as shown in
Figure 1. In the data input layer, the size of 300 × 300 was maintained, and VGG16 was replaced by U-Net in the basic network layer. As the model architecture of VGG is highly similar to the feature extraction part of the contracting path (Encoder Part) of U-Net, feature extraction was carried out by the convolution layer. In the process of downsampling, some image edge information will be lost during the convolution operation. The other part of the U-Net network architecture is the expansive path (Decoder Part). In the decoder stage, the overlap-tile strategy was used to mirror the feature map, and the feature map, as generated by upsampling, was combined with the feature map of the same size, as generated in the encoder stage. In addition, in order to greatly reduce feature loss during feature transmission and complete the lost image edge information, multi-scale feature fusion was used to splice feature dimensions. Therefore, replacing VGG16 with U-Net improved the effect of feature map extraction. In the feature layer of the latter half of the original SSD, Conv4_3 and the output of the last layer in VGG16 are used as the starting point of the multi-scale feature map. In the latter part of the feature layer of U-SSD, as part of image information would be lost in the process of feature map scaling down and amplification in the U-Net encoder stage, this study added two additional convolutional layers, for a total of 8 convolutional layers (originally 6 in SSD), as shown in
Figure 2. In addition, similar to the original SSD, this study maintained the last six layers of feature maps with different scales (38 × 38, 19 × 19, 10 × 10, 5 × 5, 3 × 3, 1 × 1) for detection of different scale targets and field of vision, and there was a L2 normalization layer after Conv13. The loss function and ground-truth matching optimization are based SSD. The loss function
L is a weighted sum of the localization loss (loc) and the confidence loss (conf), seen in Equation (
1).
is an indicator for matching the
i-th default box to the
j-th ground truth box of category
p. N is the number of matched default boxes. The localization loss is a smooth L1 loss
between the predicted box (
l) and the ground truth box (
g) parameters. The weight term
is used for cross validation. The confidence loss
is the softmax loss over multiple classes confidences (
c).
Smooth L1 loss can avoid the gradient explosion caused by the wrong offset when the ground-truth and predicted box are too different. The
is defined in Equation (
2). We regress to offsets for the center (
) of the default bounding box (
d) and for its width (
w) and height (
h). The confidence loss is defined in Equation (
3).
Dilated Convolution
This paper added dilated convolution to Conv13 and Conv14, as shown in
Figure 2. Dilated convolution increases the perceived field of convolution without reducing the spatial feature resolution or increasing model and parameter complexity, meaning it compensates for the lost feature information in the first half and adds more global information to the feature map.
Figure 3 shows the difference between ordinary convolution and dilated convolution. The blue dots represent the 3 × 3 convolution kernel, and the yellow area represents the perceived field of vision after the convolution operation.
Figure 3a shows the general convolution process, which is preset to 1 and performs the sliding operation closely on the feature map.
Figure 3b shows that the dilated convolution is 2, and the perceived field of vision is 5 × 5.
Figure 3c shows that the dilated convolution is 3, and the perceived field of vision is 7 × 7.
Figure 3 shows that the benefit of dilated convolution is that without pooling loss information, the perceived field of vision is enlarged and each convolutional output contains a wide range of information. In this paper, the values of dilated convolution added to Conv13 and Conv14 were 6 and 5, respectively.
5. Conclusions
This paper proposed an end-to-end network model for table detection, U-SSD, which was improved by U-Net that is a classical image segmentation model. Edge information was added by combining feature maps, and dilated convolution was added to increase the perceived field of feature extraction to supplement the lost features. In addition, the dataset provided by a Taiwanese Law Firm was used as the training sample, thus, the object detection model and image segmentation model were initially trained with natural data. The experimental results show that the improved U-SSD can further improve the accuracy of table detection and minimize the prediction error at table edges, and the public dataset verification results show that the detection effect is good. Therefore, using an image segmentation model for object detection can also achieve good results, and adding dilated convolution can effectively improve feature information.
This paper focused on tables with large objects, and the layout was mostly tables with a few text areas; therefore, the detection of small object tables, cells, text areas, and charts in documents was limited. In the future, we will extend the optimization model to include text areas, different styles of cells, and pictures, in order to detect small object cells and further identify table structures in documents.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}