
An All-Batch Loss for Constructing Prediction Intervals


Abstract
:1. Introduction
- Some existing methods are not able to handle large-scale data because of the high computational costs, while other methods are unsatisfactory for small-batch data due to assumptions regarding data distribution. No method that can be applied to all batch sample sizes at present;
- Many of the PI generation methods suffer from a fragile training process. Due to the ubiquitous disadvantage of high computational complexity, existing methods may be more likely to suffer from problems such as over-fitting, gradient disappearance and gradient explosion when encountering complex models;
- It is difficult to get high-quality point estimates and PIs at the same time.
- Instead of using the central limit theorem as the approximator, the AB loss estimates the likelihood function directly by adopting the Taylor formula, which enables the AB loss to adapt to both small and large batches;
- To address the problem of the gradient disappearance which occasionally occurs during the training by QD loss, a penalty term for misclassification is proposed. The proposed penalty term can speed up the convergence of the model and improve the quality of the output PIs;
- By utilizing the structure of the dual FNNs similar to the MVE method, the point estimates and the bias estimates can be obtained separately without affecting each other, which is more flexible in real-world tasks.
2. Materials and Methods
2.1. Prediction Interval
2.1.1. Confidence
2.1.2. Sharpness
2.2. Quality Driven Loss
2.3. All-Batch Loss Function
2.3.1. Derivation
2.3.2. Comparison with QD Loss
2.4. Prediction Interval Generation Framework
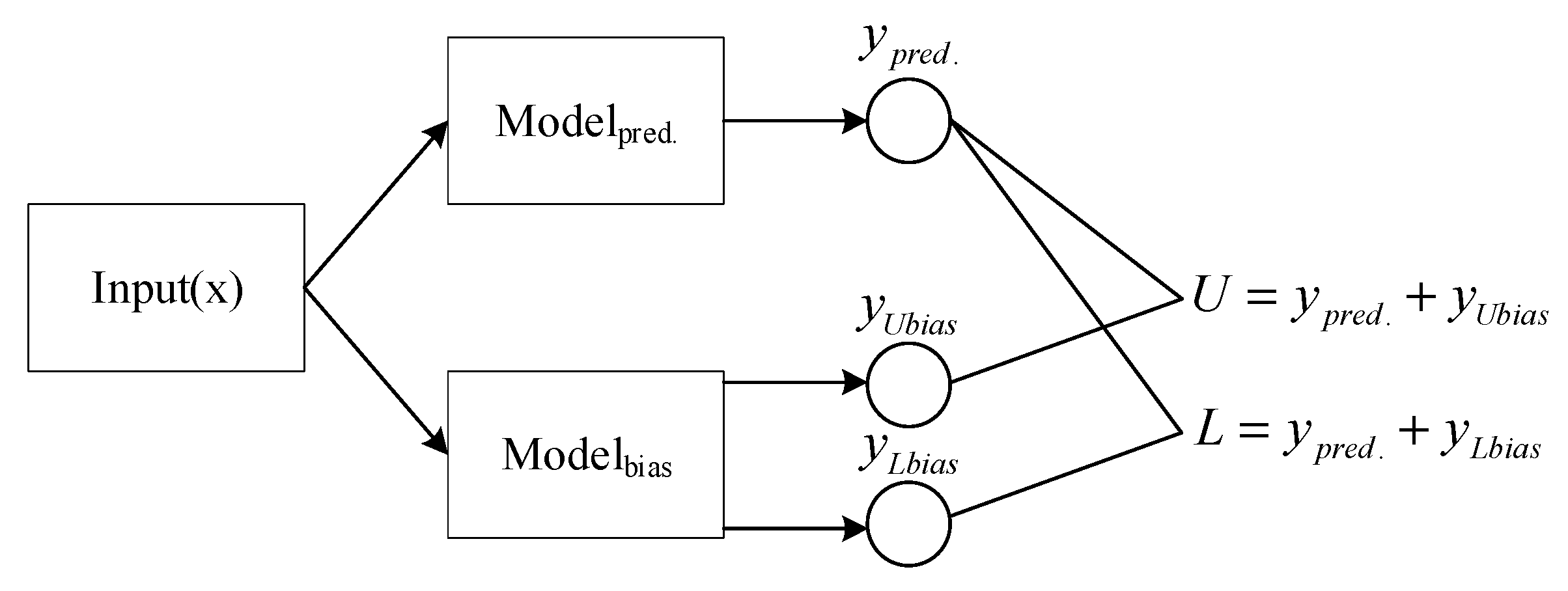
2.4.1. Structure
2.4.2. Framework Training
3. Experiments
3.1. Data Description
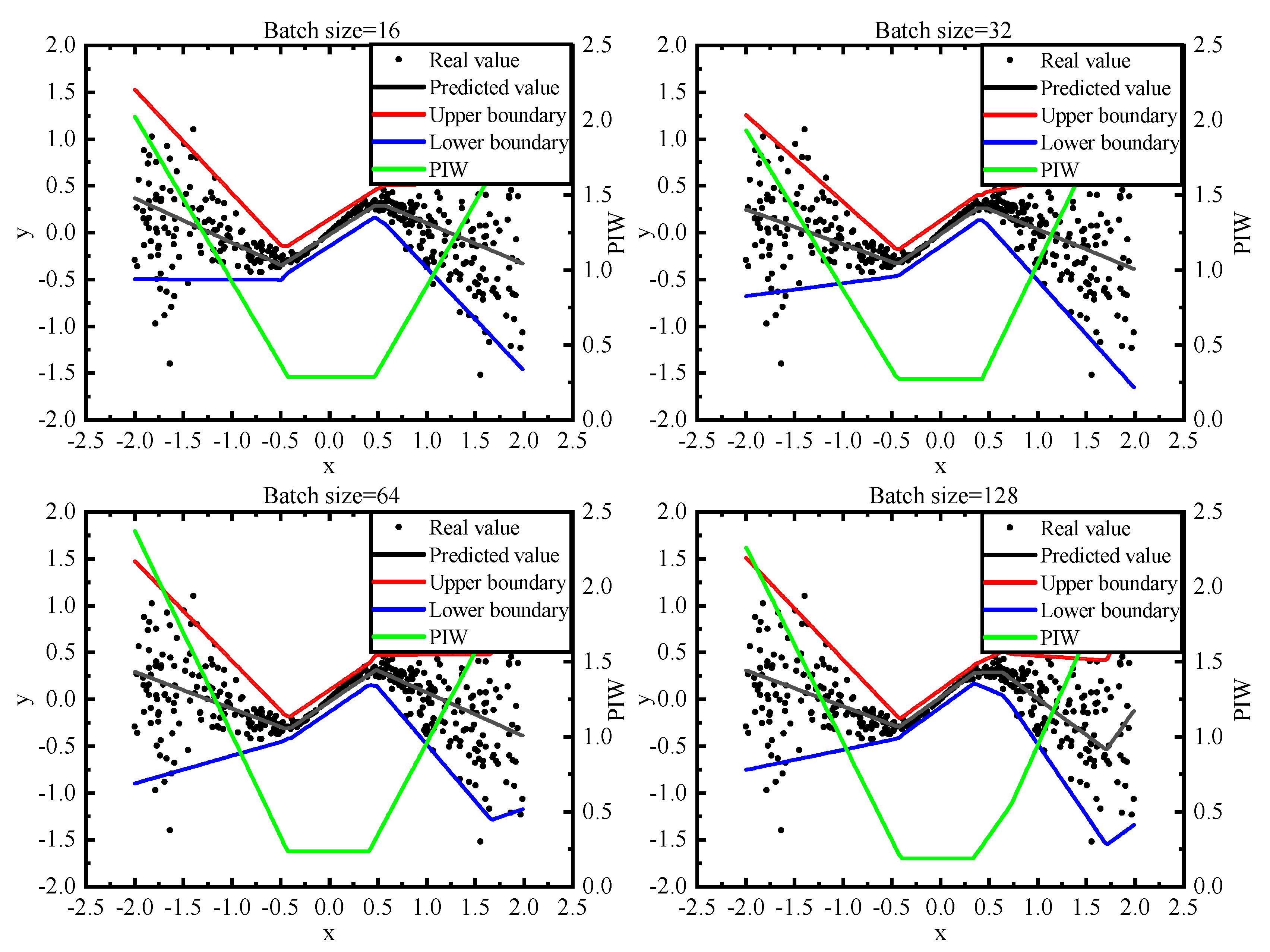
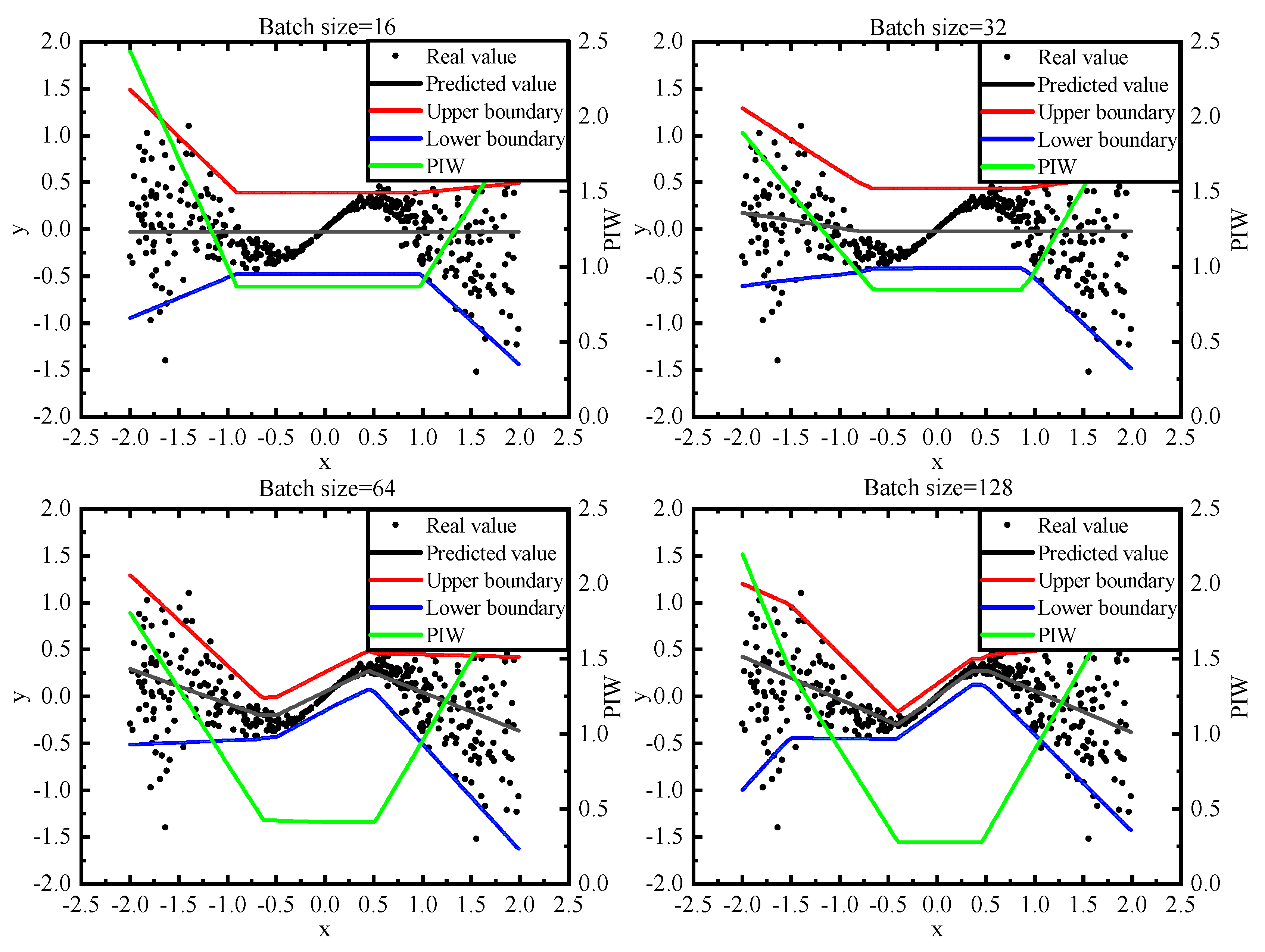
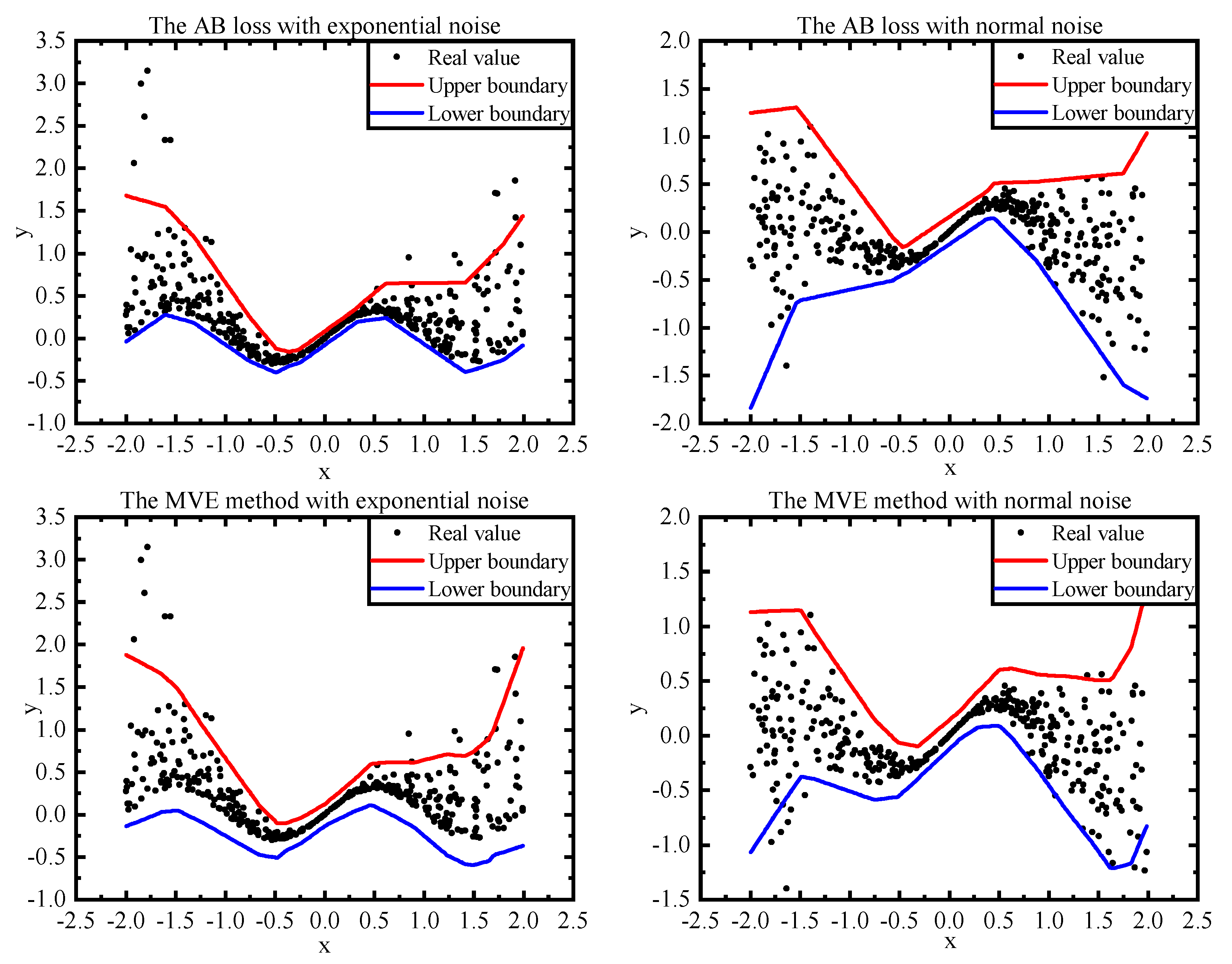
3.2. Experiment Methodology
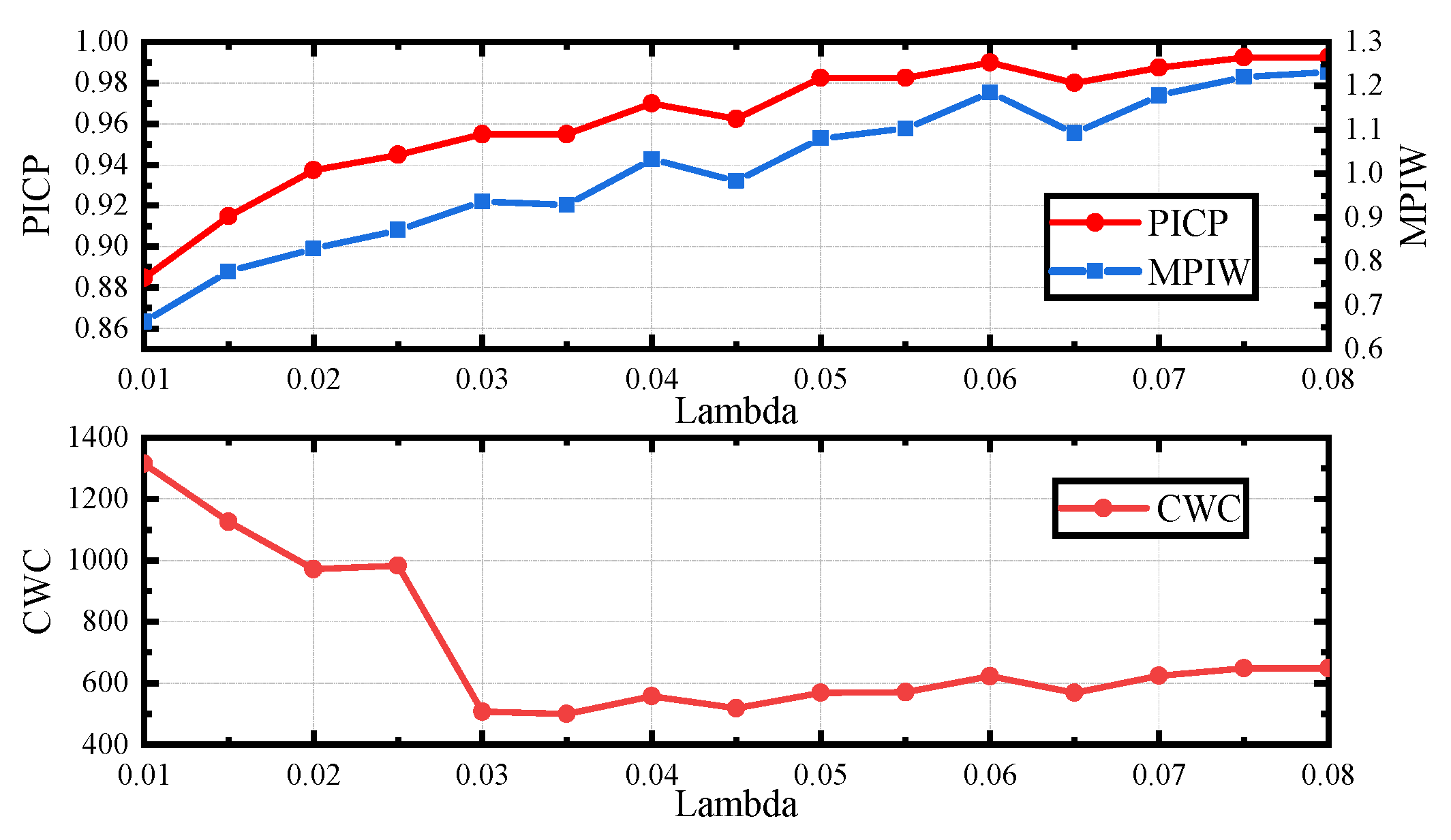
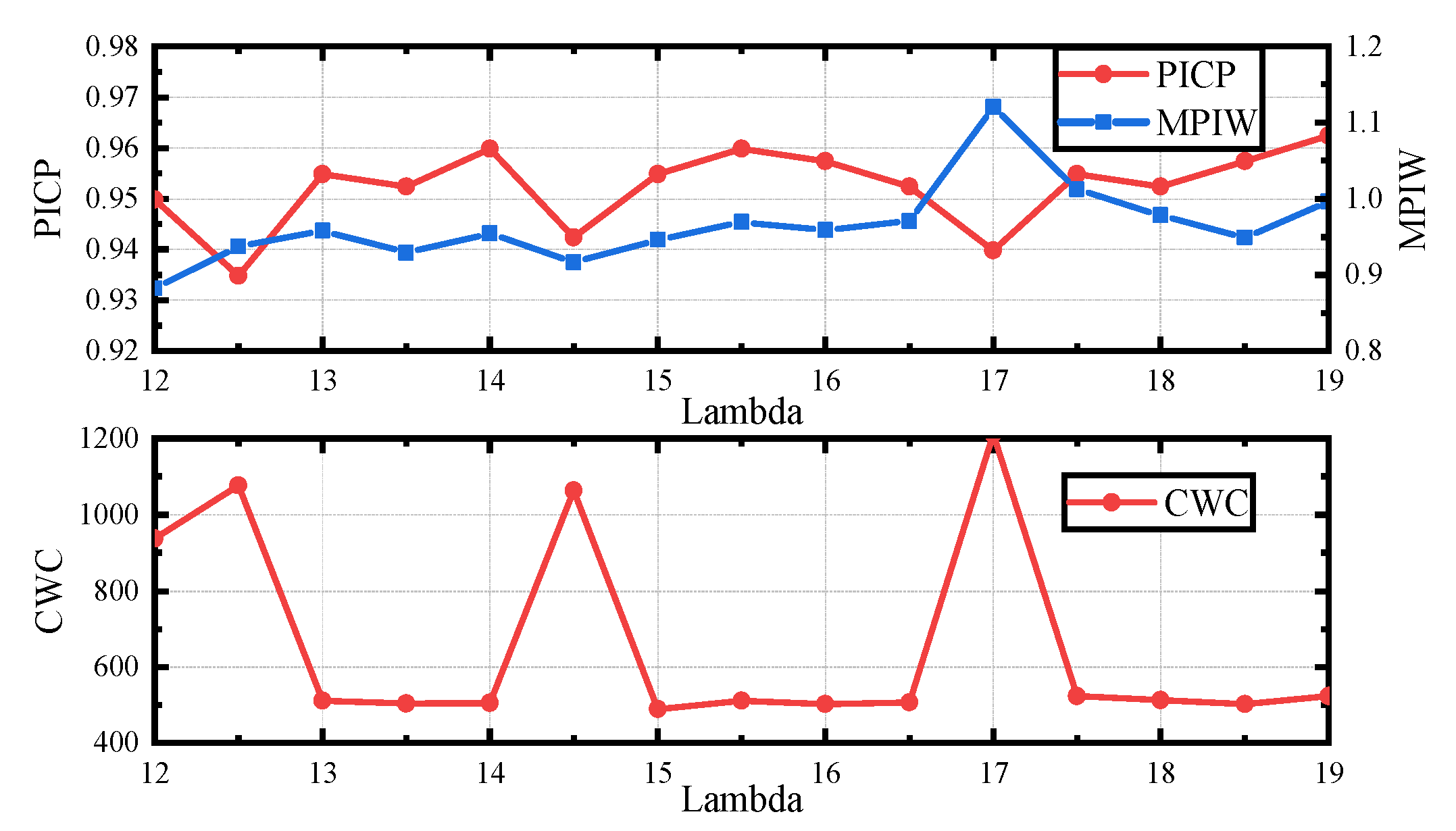
3.3. Parameters
3.4. Model Comparisions
4. Discussions
- The realization of the AB loss in this study did not consider the impact of model uncertainty. Since two networks are used to predict the prediction estimate and the bias estimate, the uncertainty of the model was not determined in the implementation. It is possible to use methods such as bootstrap to estimate model uncertainty to improve the quality of the results;
- The existence of the penalty term means it is not necessary to initialize the model before the training process, although this feature increases the computational complexity. More efforts should be made to simplify the penalty term;
- It is difficult to adjust the weight parameter of the AB loss on different datasets. A more efficient way should be explored to balance the contradiction between confidence and sharpness.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Meade, N.; Islam, T. Prediction intervals for growth curve forecasts. J. Forecast. 1995, 14, 413–430. [Google Scholar] [CrossRef]
- Shen, Y.; Wang, X.; Chen, J. Wind power forecasting using multi-objective evolutionary algorithms for wavelet neural network optimized prediction intervals. Appl. Sci. 2018, 8, 185. [Google Scholar] [CrossRef] [Green Version]
- Wan, C.; Zhao, C.; Song, Y. Chance constrained extreme learning machine for nonparametric prediction intervals of wind power generation. IEEE Trans. Power Syst. 2020, 35, 3869–3884. [Google Scholar] [CrossRef]
- Wu, Y.-K.; Wu, Y.-C.; Hong, J.-S.; Phan, L.-H.; Phan, Q.-D. Probabilistic forecast of wind power generation with data processing and numerical weather predictions. IEEE Trans. Ind. Appl. 2020, 57, 36–45. [Google Scholar] [CrossRef]
- Mykhailovych, T.; Fryz, M. Model and information technology for hourly water consumption interval forecasting. In Proceedings of the IEEE 15th International Conference on Advanced Trends in Radioelectronics, Telecommunications and Computer Engineering, Lviv-Slavske, Ukraine, 25–29 February 2020; pp. 341–345. [Google Scholar]
- Du, S.; Wu, M.; Chen, L.; Hu, J.; Cao, W.; Pedrycz, W. Operating mode recognition based on fluctuation interval prediction for iron ore sintering process. IEEE/ASME Trans. Mechatron. 2020, 25, 2297–2308. [Google Scholar] [CrossRef]
- Zheng, L.; Xiao, X.; Sun, B.; Mei, D.; Peng, B. Short-term parking demand prediction method based on variable prediction interval. IEEE Access. 2020, 8, 58594–58602. [Google Scholar] [CrossRef]
- Cheng, J.; Duan, D.; Cheng, X.; Yang, L.; Cui, S. Adaptive control for energy exchange with probabilistic interval predictors in isolated microgrids. Energies 2021, 14, 375. [Google Scholar] [CrossRef]
- Kurt, H.; Maxwell, S.; Halbert, W. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar]
- Chryssolouris, G.; Lee, M.; Ramsey, A. Confidence interval prediction for neural network models. IEEE Trans. Neural Netw. 1996, 7, 229–232. [Google Scholar] [CrossRef]
- Hwang, J.T.G.; Ding, A.A. Prediction intervals for artificial neural networks. J. Am. Stat. Assoc. 1997, 92, 748–757. [Google Scholar] [CrossRef]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: London, UK, 1995. [Google Scholar]
- MacKay, D.D.J.C. The evidence framework applied to classification networks. Neural Comput. 1992, 4, 720–736. [Google Scholar] [CrossRef]
- Heskes, T. Practical confidence and prediction intervals. In Proceedings of the 1997 Conference on Advance in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1997; pp. 176–182. [Google Scholar]
- Carney, J.G.; Cunningham, P.; Bhagwan, U. Confidence and prediction intervals for neural network ensembles. In Proceedings of the International Joint Conference on Neural Networks, Washington, DC, USA, 10–16 July 1999; pp. 1215–1218. [Google Scholar]
- Errouissi, R.; Cárdenas-Barrera, J.L.; Meng, J.; Guerra, E.C. Bootstrap prediction interval estimation for wind speed forecasting. In Proceedings of the IEEE Energy Conversion Congress and Exposition, Montreal, QC, Canada, 20–24 September 2015; pp. 1919–1924. [Google Scholar]
- Mancini, T.; Pardo, H.C.; Olmo, J. Prediction intervals for deep neural networks. arXiv 2020, arXiv:2010.04044. [Google Scholar]
- Dybowski, R.; Roberts, S.J. Confidence Intervals and Prediction Intervals for Feed-Forward Neural Networks; Cambridge University Press: Cambridge, UK, 2001. [Google Scholar]
- Nix, D.A.; Weigend, A.S. Estimating the mean and variance of the target probability distribution. In Proceedings of the IEEE International Conference on Neural Networks, Orlando, FL, USA, 28 June–2 July 1994; pp. 55–60. [Google Scholar]
- Khosravi, A.; Nahavandi, S.; Creighton, D.; Atiya, A.F. Lower upper bound estimation method for construction of neural network-based prediction intervals. IEEE Trans. Neural Netw. 2010, 22, 337–346. [Google Scholar] [CrossRef] [PubMed]
- Ak, R.; Li, Y.-F.; Vitelli, V.; Zio, E. Multi-Objective Genetic Algorithm Optimization of a Neural Network for Estimating Wind Speed Prediction Intervals; hal-00864850; HAL: Paris, France, 2013; Unpublished work. [Google Scholar]
- Wang, J.; Fang, K.; Pang, W.; Sun, J. Wind power interval prediction based on improved PSO and BP neural network. J. Electr. Eng. Technol. 2017, 12, 989–995. [Google Scholar] [CrossRef] [Green Version]
- Long, H.; Zhang, C.; Geng, R.; Wu, Z.; Gu, W. A combination interval prediction model based on biased convex cost function and auto rncoder in solar power prediction. IEEE Trans. Sustain. Energy 2021. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Pearce, T.; Zaki, M.; Brintrup, A.M.; Neely, A. High-quality prediction intervals for deep learning: A distribution-free, ensembled approach. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4075–4084. [Google Scholar]
- Hoffer, E.; Hubara, I.; Soudry, D. Train longer, generalize better: Closing the generalization gap in large batch training of neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1731–1741. [Google Scholar]
- Liu, D.; He, Z.; Chen, D.; Lv, J. A network framework for small-sample learning. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4049–4062. [Google Scholar] [CrossRef]
- Salem, T.S.; Langseth, H.; Ramampiaro, H. Prediction intervals: Split normal mixture from quality-driven deep ensemble. arXiv 2020, arXiv:2007.09670v1. [Google Scholar]
- Khosravi, A.; Nahavandi, S.; Creighton, D.; Atiya, A.F. Comprehensive review of neural network-based prediction intervals and new advances. IEEE Trans. Neural Netw. 2011, 22, 1341–1356. [Google Scholar] [CrossRef] [PubMed]
- Khosravi, A.; Nahavandi, S.; Creighton, D. A prediction interval based approach to determine optimal structures of neural network metamodels. Expert Syst. Appl. 2010, 37, 2377–2387. [Google Scholar] [CrossRef]
- Shrestha, D.L.; Solomatine, D.P. Machine learning approaches for estimation of prediction interval for the model output. Neural Netw. 2006, 19, 225–235. [Google Scholar] [CrossRef]
- Laarhoven, P.J.M.V.; Aarts, E.H.L. Simulated Annealing: Theory and Applications; Kluwer: Boston, UK, 1987. [Google Scholar]
- Harrison, D.; Rubinfeld, D. Hedonic housing prices and the demand for clean air. J. Environ. Econ. Manag. 1978, 5, 81–102. [Google Scholar] [CrossRef] [Green Version]
- Yeh, I.-C. Modeling of strength of high-performance concrete using artificial neural networks. Cem. Concr. Res. 1998, 28, 1797–1808. [Google Scholar] [CrossRef]
- Tsanas, A.; Xifara, A. Accurate quantitative estimation of energy performance of residential buildings using statistical machine learning tools. Energy Build. 2012, 49, 560–567. [Google Scholar] [CrossRef]
- Corke, P.I. A robotics toolbox for MATLAB. IEEE Robot. Autom. Mag. 1996, 3, 24–32. [Google Scholar] [CrossRef] [Green Version]
- Coraddu, A.; Oneto, L.; Ghio, A.; Savio, S.; Anguita, D.; Figari, M. Machine learning approaches for improving condition-based maintenance of naval propulsion plants. J. Eng. Maritime Environ. 2014, 230, 136–153. [Google Scholar] [CrossRef]
- Altosole, M.; Benvenuto, G.; Figari, M.; Campora, U. Real-time simulation of a cogag naval ship propulsion system. J. Eng. Maritime Environ. 2009, 223, 47–62. [Google Scholar] [CrossRef]
- Tüfekci, P. Prediction of full load electrical power output of a base load operated combined cycle power plant using machine learning methods. Int. J. Electr. Power Energy Syst. 2014, 60, 126–140. [Google Scholar] [CrossRef]
- Kaya, H.; Tüfekci, P.; Gürgen, S.F. Local and hlobal learning methods for predicting power of a xombined gas & steam turbine. In Proceedings of the International Conference on Emerging Trends in Computer and Electronics Engineering, Dubai, United Arab Emirates, 24–25 March 2012; pp. 13–18. [Google Scholar]
- Cortez, P.; Cerdeira, A.; Almeida, F.; Matos, T. Modeling wine preferences by data mining from physicochemical properties. Decis. Support Syst. 2009, 47, 547–553. [Google Scholar] [CrossRef] [Green Version]
- Gerritsma, J.; Onnink, R.; Versluis, A. Geometry, resistance and stability of the Delft systematic yacht hull series1. Int. Shipbuild. Prog. 1981, 28, 276–286. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ye, L.; Zhou, J.; Gupta, H.V.; Zhang, H. Efficient estimation of flood forecast prediction intervals via single and multi-objective versions of the LUBE method. Hydrol. Process. 2016, 30, 2703–2716. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case Study | Target | Samples | Reference |
|---|---|---|---|
| #1 | Nonlinear function with gaussian noise | 2000 | [25] |
| #2 | Nonlinear function with exponential noise | 2000 | [25] |
| #3 | Boston housing | 506 | [33] |
| #4 | Concrete compressive strength | 1030 | [34] |
| #5 | Energy | 768 | [35] |
| #6 | Forward kinematics of an 8-link robot arm | 8192 | [36] |
| #7 | Naval | 11,934 | [37,38] |
| #8 | Power plant | 9568 | [39,40] |
| #9 | White wine quality | 4898 | [41] |
| #10 | Sailing yachts | 308 | [42] |
| Method | Parameter | Numerical Value |
|---|---|---|
| Common | 0.05 | |
| 1000 | ||
| LUBE | 50 | |
| 0.95 | ||
| QD Loss | 15 | |
| 160 | ||
| AB Loss | 0.03 | |
| 1.2 |
| Batch Size | QD Loss | AB Loss | ||||||
|---|---|---|---|---|---|---|---|---|
| PICP (%) | MPIW | CWC | MSE | PICP (%) | MPIW | CWC | MSE | |
| 16 | 96.24 | 1.21 | 625.40 | 0.29 | 95.20 | 0.94 | 503.70 | 0.14 |
| 32 | 96.24 | 1.17 | 584.94 | 0.32 | 96.74 | 1.01 | 515.22 | 0.13 |
| 64 | 95.49 | 0.95 | 488.79 | 0.20 | 96.99 | 1.03 | 557.50 | 0.08 |
| 128 | 95.49 | 0.95 | 506.38 | 0.13 | 97.24 | 1.02 | 536.68 | 0.07 |
| Case Study | LUBE Method | QD Loss | AB Loss | |||||
|---|---|---|---|---|---|---|---|---|
| PICP (%) | MPIW | PICP (%) | MPIW | CWC | PICP (%) | MPIW | CWC | |
| #3 | 94.07 | 5.89 | 95.00 | 1.15 | 344.00 | 96.00 | 1.16 | 355.90 |
| #4 | 94.17 | 4.98 | 95.60 | 1.34 | 141.20 | 95.60 | 1.41 | 150.00 |
| #5 | 96.09 | 4.19 | 96.10 | 1.16 | 86.57 | 100.00 | 0.73 | 72.71 |
| #6 | 94.90 | 5.33 | 95.10 | 1.72 | 786.90 | 96.80 | 1.68 | 760.66 |
| #7 | 92.37 | 3.42 | 96.70 | 3.23 | 300.90 | 100.00 | 3.38 | 314.70 |
| #8 | 95.13 | 3.72 | 95.80 | 0.99 | 339.40 | 95.40 | 0.94 | 321.30 |
| #9 | 94.00 | 6.90 | 95.70 | 4.42 | 562.60 | 97.80 | 3.85 | 500.30 |
| #10 | 96.10 | 5.31 | 100.00 | 0.37 | 26.10 | 98.39 | 0.28 | 18.96 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhong, H.; Xu, L. An All-Batch Loss for Constructing Prediction Intervals. Appl. Sci. 2021, 11, 1728. https://doi.org/10.3390/app11041728
Zhong H, Xu L. An All-Batch Loss for Constructing Prediction Intervals. Applied Sciences. 2021; 11(4):1728. https://doi.org/10.3390/app11041728
Chicago/Turabian StyleZhong, Hua, and Li Xu. 2021. "An All-Batch Loss for Constructing Prediction Intervals" Applied Sciences 11, no. 4: 1728. https://doi.org/10.3390/app11041728
APA StyleZhong, H., & Xu, L. (2021). An All-Batch Loss for Constructing Prediction Intervals. Applied Sciences, 11(4), 1728. https://doi.org/10.3390/app11041728