
A Novel Load Forecasting Approach Based on Smart Meter Data Using Advance Preprocessing and Hybrid Deep Learning


Abstract
:1. Introduction
2. Literature Survey
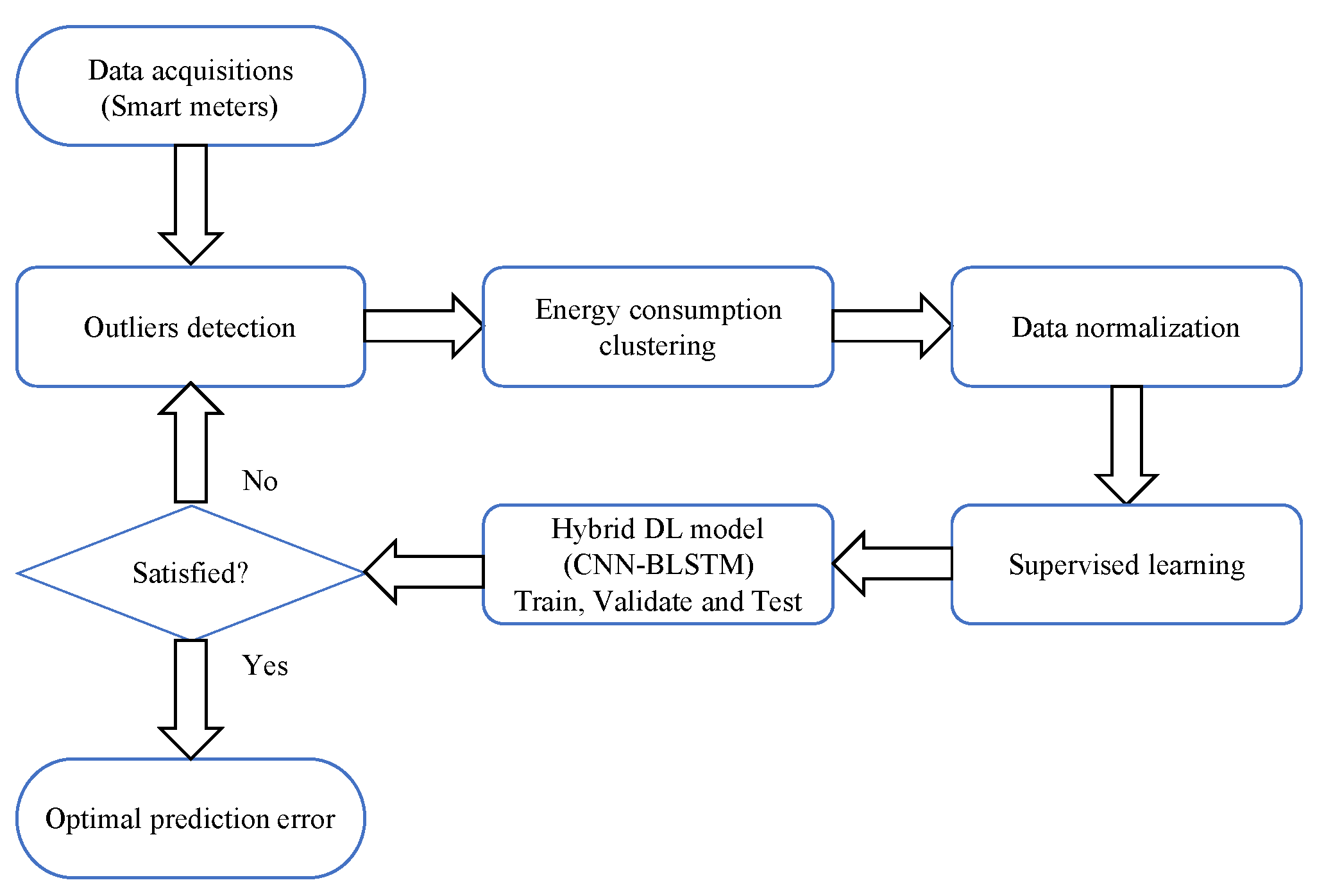
3. Preprocessing Methods
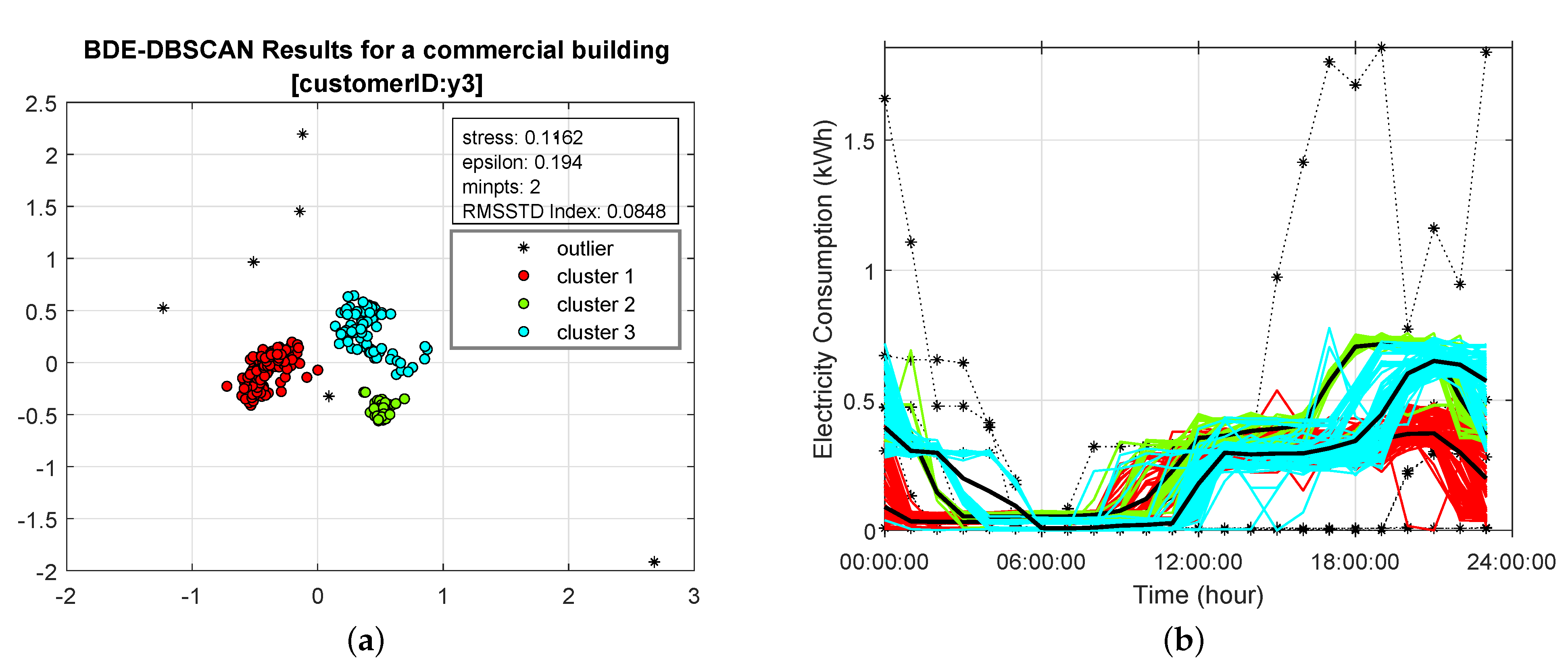
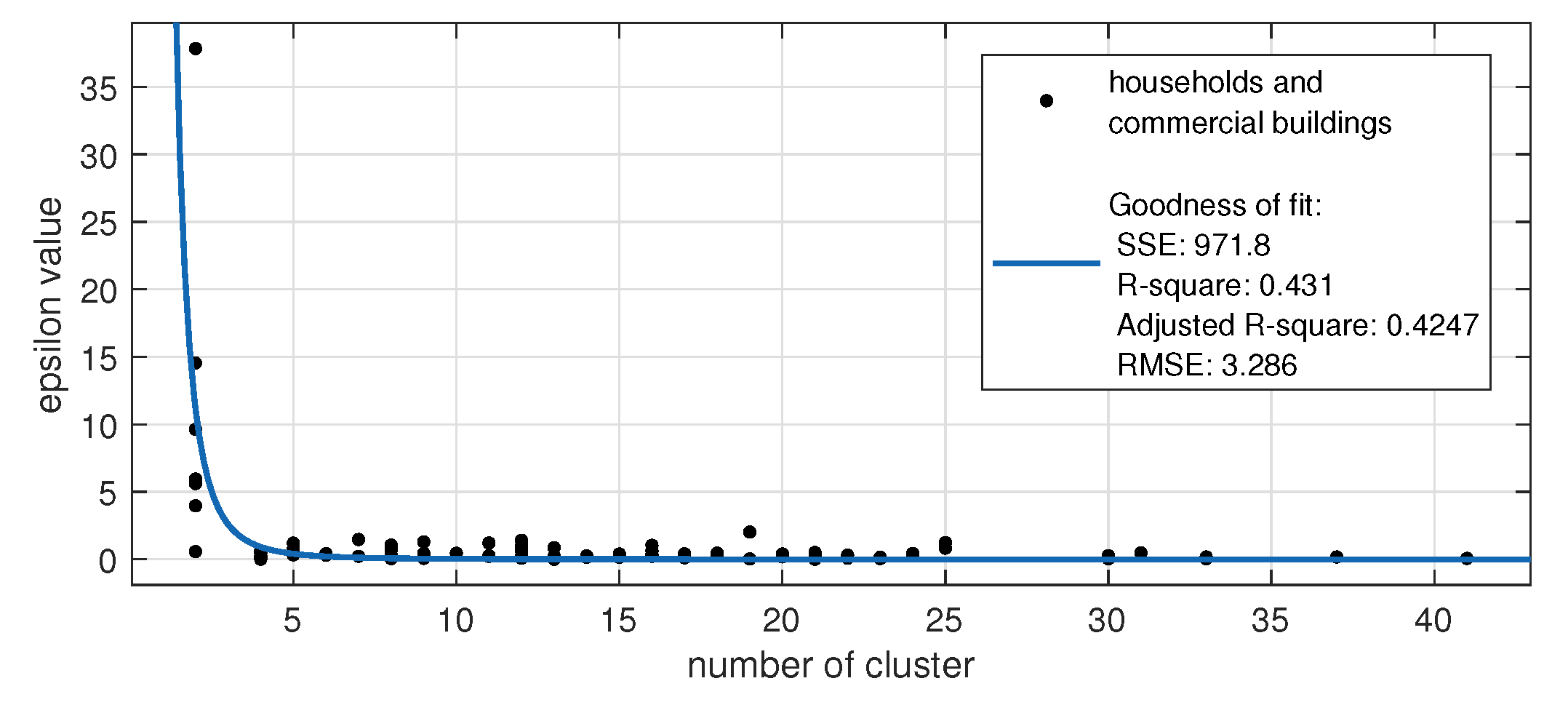
3.1. Non-Metric Multidimensional Scaling-Based Load Profile Representation
| Algorithm 1 Pseudo-code of the proposed outlier detection process based on the binary differential evolution (BDE)–density-based spatial clustering applications with noise (DBSCAN) algorithm [22] |
Input: Output: Initialisation : Use the initial parameters described in [22] Modification : Change purity metric with RMSSTD index for clustering validation and performance evaluation
|
3.2. Density-Based Outlier Analysis of Daily Load Profiles
4. Forecasting Methods
4.1. Convolutional Neural Networks
4.2. Long Short-Term Memory
4.3. Bidirectional Long Short-Term Memory
5. Modeling Details
5.1. Data Descriptions
5.2. Advanced Preprocessing and Hybrid Dl Approach
6. Forecasting Results and Discussion
6.1. Comparison with Conventional Methods
6.2. Aggregated Forecasting with Clean Data
6.3. Individual Customer Forecasting with Outliers Cancellation
6.4. Time Resolution Forecasting
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Nomenclature
| dataset of customer (i) | |
| Euclidean distance between two daily load profile | |
| distance (dissimilarity) matrix | |
| two-dimensional (2-D) subspace projection | |
| proximity between different daily load profiles | |
| f | mapping function of proximities |
| ith daily load profile | |
| the ith cluster | |
| the center of the ith cluster | |
| N | time resolution of the dataset [24,48,96] |
| best solution of the BDE–DBSCAN algorithm for different parameters | |
| generated population at the ith epoch and th iteration | |
| k-dimensional input vector at the th time step | |
| input node of the LSTM model | |
| internal state of the LSTM model | |
| hidden state of the LSTM model | |
| input sample at the tth time step | |
| tanh | activation function of LSTM nodes |
| weight matrices of the LSTM cell | |
| bias matrices of the LSTM cell | |
| ⊙ | element-wise multiplication |
| sigmoid activation function of LSTM nodes | |
| hidden state of BRNN | |
| the normalized value scaled to the range | |
| the maximum value of the features in | |
| the minimum value of the features in | |
| the normalized predicted energy time series | |
| the function of prediction model based on supervised learning | |
| the mapped predicted load at time | |
| n | the number of future time prediction elements in the set |
| m | the total number of data points in the time series |
| the actual measured time series in the original scale of the dataset | |
| the predicted output of the time series | |
| the average of the actual values of energy consumption |
References
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-Term Residential Load Forecasting Based on LSTM Recurrent Neural Network. IEEE Trans. Smart Grid 2019, 10, 841–851. [Google Scholar] [CrossRef]
- Tascikaraoglu, A.; Sanandaji, B.M. Short-term residential electric load forecasting: A compressive spatio-temporal approach. Energy Build. 2016, 111, 380–392. [Google Scholar] [CrossRef]
- Grolinger, K.; L’Heureux, A.; Capretz, M.A.; Seewald, L. Energy Forecasting for Event Venues: Big Data and Prediction Accuracy. Energy Build. 2016, 112, 222–233. [Google Scholar] [CrossRef] [Green Version]
- Almalaq, A.; Edwards, G. A Review of Deep Learning Methods Applied on Load Forecasting. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 511–516. [Google Scholar]
- Villalba, S.; Bel, C. Hybrid demand model for load estimation and short term load forecasting in distribution electric systems. IEEE Trans. Power Deliv. 2000, 15, 764–769. [Google Scholar] [CrossRef]
- Sun, X.; Luh, P.B.; Cheung, K.W.; Guan, W.; Michel, L.D.; Venkata, S.S.; Miller, M.T. An Efficient Approach to Short-Term Load Forecasting at the Distribution Level. IEEE Trans. Power Syst. 2016, 31, 2526–2537. [Google Scholar] [CrossRef]
- Ding, N.; Benoit, C.; Foggia, G.; Besanger, Y.; Wurtz, F. Neural Network-Based Model Design for Short-Term Load Forecast in Distribution Systems. IEEE Trans. Power Syst. 2016, 31, 72–81. [Google Scholar] [CrossRef]
- Cai, M.; Pipattanasomporn, M.; Rahman, S. Day-ahead building-level load forecasts using deep learning vs. traditional time-series techniques. Appl. Energy 2019, 236, 1078–1088. [Google Scholar] [CrossRef]
- Yong, Z.; Xiu, Y.; Chen, F.; Pengfei, C.; Binchao, C.; Taijie, L. Short-term building load forecasting based on similar day selection and LSTM network. In Proceedings of the 2018 2nd IEEE Conference on Energy Internet and Energy System Integration (EI2), Beijing, China, 20–22 October 2018; IEEE: Beijing, China, 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Imani, M.; Ghassemian, H. Residential load forecasting using wavelet and collaborative representation transforms. Appl. Energy 2019, 253, 1–12. [Google Scholar] [CrossRef]
- Bedi, J.; Toshniwal, D. Empirical Mode Decomposition Based Deep Learning for Electricity Demand Forecasting. IEEE Access 2018, 6, 49144–49156. [Google Scholar] [CrossRef]
- Hossen, T.; Nair, A.S.; Chinnathambi, R.A.; Ranganathan, P. Residential Load Forecasting Using Deep Neural Networks (DNN). In Proceedings of the 2018 North American Power Symposium (NAPS), Fargo, ND, USA, 9–11 September 2018; IEEE: Fargo, ND, USA, 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Enshaei, N.; Naderkhani, F. Application of Deep Learning for Fault Diagnostic in Induction Machine’s Bearings. In Proceedings of the 2019 IEEE International Conference on Prognostics and Health Management (ICPHM), San Francisco, CA, USA, 17–20 June 2019; IEEE: San Francisco, CA, USA, 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Pathak, N.; Ba, A.; Ploennigs, J.; Roy, N. Forecasting Gas Usage for Big Buildings using Generalized Additive Models and Deep Learning. In Proceedings of the 2018 IEEE International Conference on Smart Computing Forecasting, Taormina, Italy, 18–20 June 2018; IEEE: Taormina, Italy, 2018; pp. 203–210. [Google Scholar] [CrossRef]
- Zheng, Z.; Yang, Y.; Niu, X.; Dai, H.N.; Zhou, Y. Wide and Deep Convolutional Neural Networks for Electricity-Theft Detection to Secure Smart Grids. IEEE Trans. Ind. Inform. 2018, 14, 1606–1615. [Google Scholar] [CrossRef]
- Qiu, D.; Liu, Z.; Zhou, Y.; Shi, J. Modified Bi-Directional LSTM Neural Networks for Rolling Bearing Fault Diagnosis. In Proceedings of the ICC 2019-2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; IEEE: Shanghai, China, 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Sehovac, L.; Nesen, C.; Grolinger, K. Forecasting Building Energy Consumption with Deep Learning: A Sequence to Sequence Approach. In Proceedings of the 2019 IEEE International Congress on Internet of Things (ICIOT), Milan, Italy, 8–13 July 2019; IEEE: Milan, Italy, 2019; pp. 108–116. [Google Scholar] [CrossRef] [Green Version]
- Su, H.; Zio, E.; Zhang, J.; Xu, M.; Li, X.; Zhang, Z. A hybrid hourly natural gas demand forecasting method based on the integration of wavelet transform and enhanced Deep-RNN model. Energy 2019, 178, 585–597. [Google Scholar] [CrossRef] [Green Version]
- Gao, Y.; Ruan, Y.; Fang, C.; Yin, S. Deep learning and transfer learning models of energy consumption forecasting for a building with poor information data. Energy Build. 2020, 223, 110156. [Google Scholar] [CrossRef]
- Ma, J.; Cheng, J.C.; Jiang, F.; Chen, W.; Wang, M.; Zhai, C. A bi-directional missing data imputation scheme based on LSTM and transfer learning for building energy data. Energy Build. 2020, 216, 109941. [Google Scholar] [CrossRef]
- Kruskal, J.B. Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis. Psychometrika 1964. [Google Scholar] [CrossRef]
- Karami, A.; Johansson, R. Choosing DBSCAN Parameters Automatically using Differential Evolution. Int. J. Comput. Appl. 2014, 91, 1–11. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. KDD 1996, 96, 226–231. [Google Scholar]
- Sharma, S. Applied Multivariate Techniques; John Wiley and Sons, Inc.: Hoboken, NJ, USA, 1995. [Google Scholar]
- Gan, G.; Ma, C.; Wu, J. Data Clustering: Theory, Algorithms, and Applications (ASA-SIAM Series on Statistics and Applied Probability); Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2007. [Google Scholar]
- Kim, J.; Moon, J.; Hwang, E.; Kang, P. Recurrent inception convolution neural network for multi short-term load forecasting. Energy Build. 2019, 194, 328–341. [Google Scholar] [CrossRef]
- Liao, G.; Gao, W.; Yang, G.; Guo, M. Hydroelectric Generating Unit Fault Diagnosis Using 1-D Convolutional Neural Network and Gated Recurrent Unit in Small Hydro. IEEE Sensors J. 2019, 19, 9352–9363. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to Forget: Continual Prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A critical review of recurrent neural networks for sequence learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional Recurrent Neural Networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef] [PubMed]
- Borg, I.; Groenen, P.J.F. Modern Multidimensional Scaling Theory and Applications; Springer: New York, NY, USA, 2005. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Z.; Xiong, H.; Gao, X.; Wu, J. Understanding of Internal Clustering Validation Measures. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, NSW, Australia, 3–17 December 2010; pp. 911–916. [Google Scholar]
- Jin, L.; Lee, D.; Sim, A.; Borgeson, S.; Wu, K.; Spurlock, C.A.; Todd, A. Comparison of Clustering Techniques for Residential Energy Behavior Using Smart Meter Data. In AAAI Workshop—Technical Report; Association for the Advancement of Artificial Intelligence (AAAI): San Francisco, CA, USA, 2017. [Google Scholar]
- Hawkins, D.M. Identification of Outliers; Springer: Berlin/Heidelberg, Germany, 1980; Volume 11. [Google Scholar]
- Yildiz, B.; Bilbao, J.; Dore, J.; Sproul, A. Recent advances in the analysis of residential electricity consumption and applications of smart meter data. Appl. Energy 2017, 208, 402–427. [Google Scholar] [CrossRef]
- sklearn.svm.SVR—scikit-learn 0.24.1 Documentation. scikit-Learn. 2018. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVR.html/sklearn.svm.SVR (accessed on 13 March 2021).
- sklearn.tree.DecisionTreeRegressor—scikit-learn 0.24.1 Documentation. scikit-learn, 2018. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeRegressor.html/sklearn.tree.DecisionTreeRegressor (accessed on 13 March 2021).
- Smart Grid, Smart City. Australian Govern, 2014. Available online: https://webarchive.nla.gov.au/awa/20160615043539; http://www.industry.gov.au/Energy/Programmes/SmartGridSmartCity/Pages/default.aspx (accessed on 6 October 2020).
- Alhussein, M.; Aurangzeb, K.; Haider, S.I. Hybrid CNN-LSTM Model for Short-Term Individual Household Load Forecasting. IEEE Access 2020, 8, 180544–180557. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Setting |
|---|---|
| CNN-1D filter size | 64 |
| CNN-1D Kernel size | 3 |
| BLSTM 1s hidden layer | 50 hidden neurons |
| BLSTM 2nd hidden layer | 25 hidden neurons |
| Optimizer | ReLU |
| Loss function | Mean square error (mean square error (MSE)) |
| Learning rate | 0.001 |
| Batch size | 120 |
| Epoch | 100 |
| Design Parameters of the Comparison Methods * | ||||||
|---|---|---|---|---|---|---|
| Method | N. of Hidden Neuron | Activation Function | Batch Size | Filter Size | Pool Size | Optimizer |
| ANN | 500 | sigmoid | 500 | - | - | SGD ** |
| CNN | - | ReLU | 200 | 64 | - | ADAM |
| LSTM | 200 | sigmoid | 200 | - | - | SGD |
| BLSTM | 50 | - | 200 | - | - | ADAM |
| CNN-LSTM | 50/25 | ReLU | 200 | 64 | 1 | ADAM |
| Method | RMSE (kW) | NRMSE (%) | MAE (kW) | MAPE (%) |
|---|---|---|---|---|
| SVR | 0.194 | 206.107 | 0.125 | 55.826 |
| DT | 0.242 | 102.470 | 0.141 | 141.067 |
| ANN | 0.154 | 82.529 | 0.109 | 54.719 |
| CNN | 0.143 | 61.190 | 0.088 | 57.675 |
| LSTM | 0.129 | 67.580 | 0.077 | 45.084 |
| BLSTM | 0.131 | 54.825 | 0.078 | 46.452 |
| CNN-LSTM | 0.148 | 63.624 | 0.088 | 46.755 |
| Proposed | 0.108 | 55.432 | 0.058 | 36.748 |
| Reference | Public | Dataset | Forecasting | Testing | MAPE |
|---|---|---|---|---|---|
| Dataset Name | Size * | Method | Interval | (%) | |
| Kong et al. [1] | Smart Grid | 69 | LSTM | 23-Aug-2013 to | 44.060 |
| Smart City | 31-Aug-2013 | ||||
| Alhussein et al. [41] | Smart Grid | 69 | CNN-LSTM | 23-Aug-2013 to | 40.380 |
| Smart City | 31-Aug-2013 | ||||
| Proposed | Smart Grid | 69 | CNN-BLSTM | 23-Aug-2013 to | 31.481 |
| Smart City | 31-Aug-2013 |
| Building | RMSE | NRMSE | MAE | MAPE |
|---|---|---|---|---|
| Type | (kW) | (%) | (kW) | (%) |
| Residential | 0.154 | 71.728 | 0.089 | 33.736 |
| Commercial | 0.135 | 26.672 | 0.084 | 27.374 |
| Improvement | Residential and Commercial Building * | |||
|---|---|---|---|---|
| Percentage | RMSE | NRMSE | MAE | MAPE |
| (kW) | (%) | (kW) | (%) | |
| (<0)% | 18 | 26 | 16 | 24 |
| (0–25)% | 35 | 25 | 29 | 35 |
| (25–50)% | 24 | 25 | 26 | 16 |
| (50–75)% | 6 | 7 | 12 | 12 |
| (75–100)% | 5 | 5 | 5 | 1 |
| Method | Time | RMSE | NRMSE | MAE | MAPE |
|---|---|---|---|---|---|
| Steps | (kW) | (%) | (kW) | (%) | |
| CNN-BLSTM | 1 h | 0.108 | 55.432 | 0.058 | 36.748 |
| -without(w/o) | 24 h | 0.108 | 56.478 | 0.059 | 36.911 |
| outliers | 48 h | 0.108 | 56.144 | 0.059 | 38.008 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ünal, F.; Almalaq, A.; Ekici, S. A Novel Load Forecasting Approach Based on Smart Meter Data Using Advance Preprocessing and Hybrid Deep Learning. Appl. Sci. 2021, 11, 2742. https://doi.org/10.3390/app11062742
Ünal F, Almalaq A, Ekici S. A Novel Load Forecasting Approach Based on Smart Meter Data Using Advance Preprocessing and Hybrid Deep Learning. Applied Sciences. 2021; 11(6):2742. https://doi.org/10.3390/app11062742
Chicago/Turabian StyleÜnal, Fatih, Abdulaziz Almalaq, and Sami Ekici. 2021. "A Novel Load Forecasting Approach Based on Smart Meter Data Using Advance Preprocessing and Hybrid Deep Learning" Applied Sciences 11, no. 6: 2742. https://doi.org/10.3390/app11062742
APA StyleÜnal, F., Almalaq, A., & Ekici, S. (2021). A Novel Load Forecasting Approach Based on Smart Meter Data Using Advance Preprocessing and Hybrid Deep Learning. Applied Sciences, 11(6), 2742. https://doi.org/10.3390/app11062742