
Evaluation of English–Slovak Neural and Statistical Machine Translation




Abstract
:1. Introduction
Research Objectives
2. Related Work
- Masked self-attention mechanism summarizing the partial prediction history;
- Encoder–decoder attention sublayer determining the dynamic source-side contexts for current prediction;
- Feedforward sublayer.
3. Materials and Methods
- Obtaining the unstructured text data (source text) of a journalistic style in English.
- Text preparation—removing the document formatting.
- Machine translation using various systems:
- Google Translate—statistical machine translation,
- Google Translate—neural machine translation,
- mt@ec—statistical machine translation,
- eTranslation—neural machine translation.
- Human translation of the documents using the online system OSTPERE.
- Text alignment—the segments of source texts were aligned with the generated MT system output, where each source text segment had its corresponding MT outputs and human translation output; this was done using the HunAlign tool [36].
- Evaluation of the texts using automatic metrics of accuracy from the Python Natural Language Toolkit library, or NLTK, which provides an implementation of the BLEU score using the sentence_bleu function.In our research, we applied automatic metrics of accuracy [14]. The metrics of accuracy (e.g., precision, recall, BLEU) are based on the closeness of the MT output () with the reference () in terms of n-grams; their lexical overlap is calculated in (A) the number of common words (), (B) the length (number of words) of the MT output, and (C) the length (number of words) of the reference. The higher the values of these metrics, the better the translation quality.BLEU (Bilingual Evaluation Understudy) [14], which is used in our research, is a geometric mean of n-gram precisions (), and the second part is a brevity penalty (BP), i.e., a length-based penalty to prevent very short sentences as compensation for inappropriate translation. BLEU represents two features of MT quality—adequacy and fluency [7].where S indicates hypothesis (h) and reference (r) in the complete corpus C.
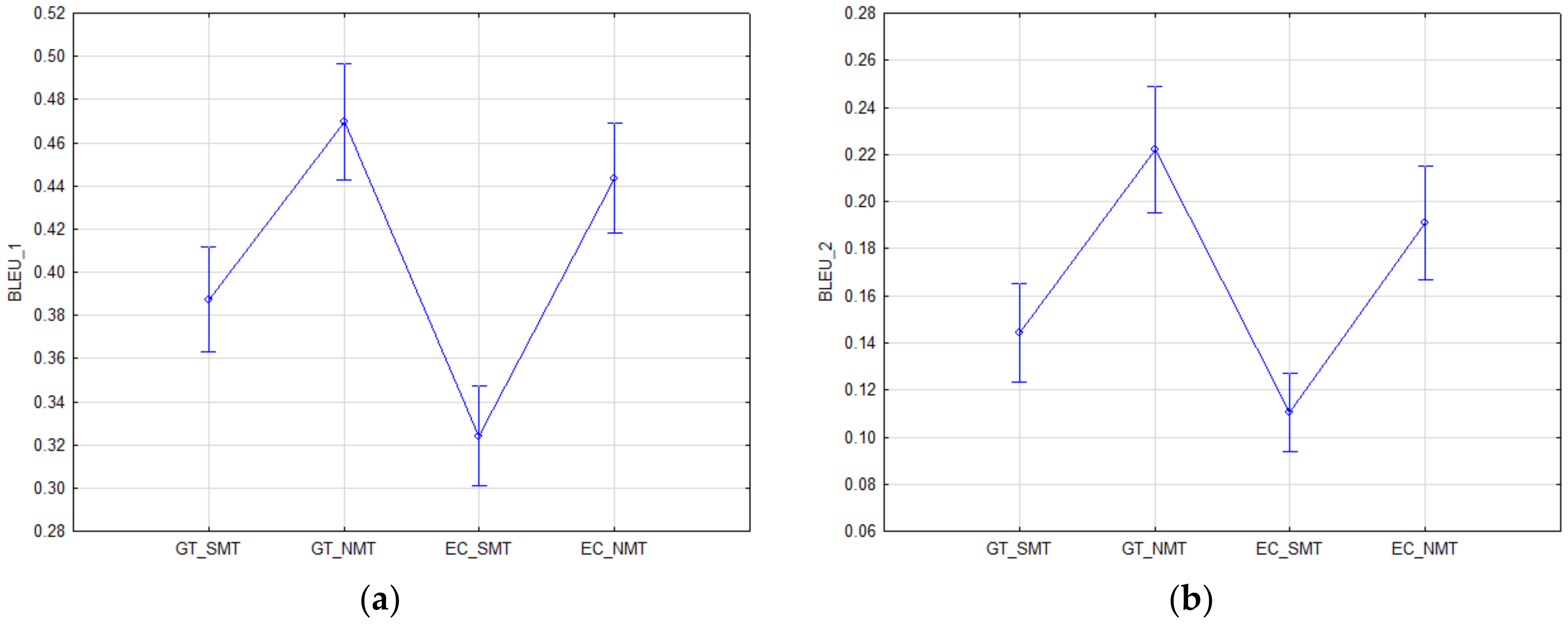
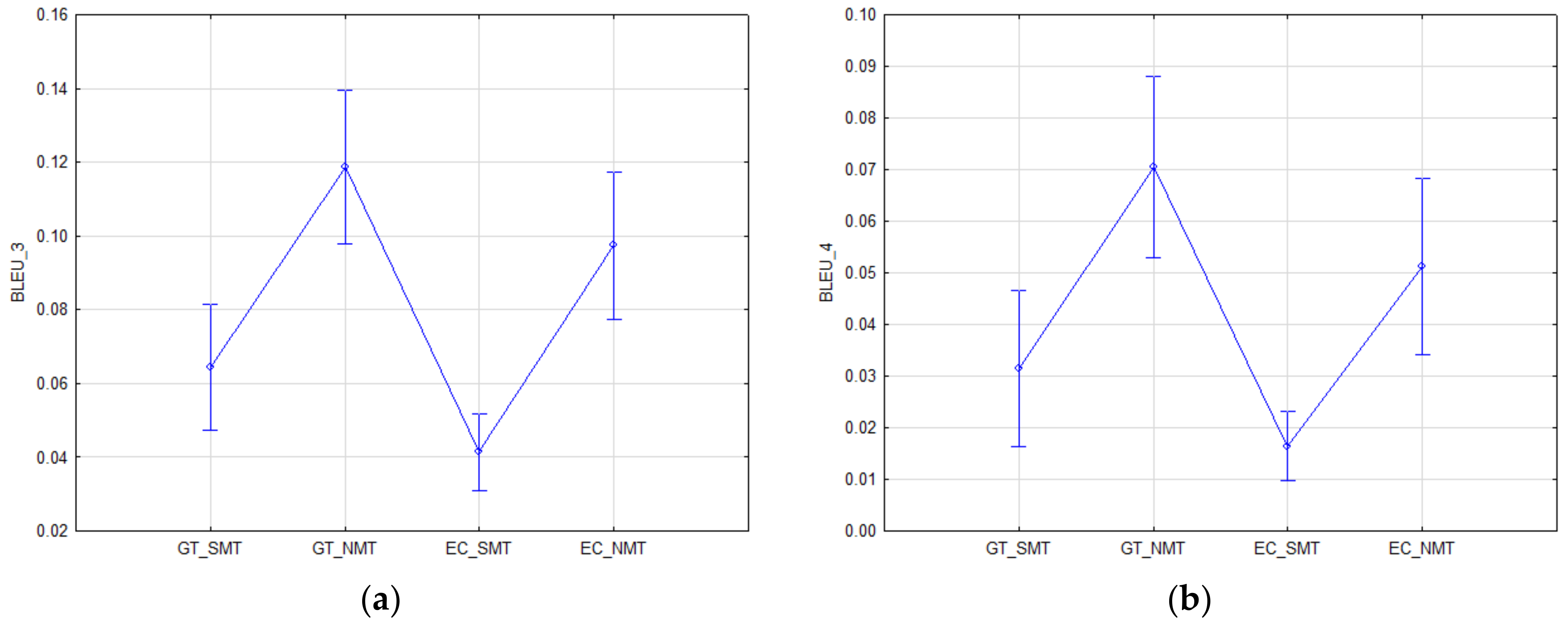
- Comparison of the translation quality based on the system (GT, EC) and translation technology (SMT, NMT).We verified the quality of the machine translations using the BLEU_n (n = 1, 2, 3, and 4) automatic evaluation metrics. We tested the differences in MT quality—represented by the score of the BLEU_n automatic metrics—between the translations generated from Google Translate (GT_SMT and GT_NMT) and the European Commission’s MT tool (EC_mt@ec and EC_e-translation).This resulted in the following global null hypotheses:The quality of machine translation (BLEU_n, n = 1, 2, 3, and 4) does not depend on the MT system (GT or EC) or the translation technology (SMT or NMT).To test for differences between dependent samples (BLEU_n: EC_SMT, GT_SMT, EC_NMT, and GT_NMT), we used adjusted univariate tests for repeated measures due to the failure of the sphericity assumption (Mauchley sphericity test—BLEU_1: W = 0.831, Chi-Square = 29.149, df = 5, p < 0.001; BLEU_2: W = 0.725, Chi-Square = 50.651, df = 5, p < 0.001; BLEU_3: W = 0.804, Chi-Square = 34.495, df = 5, p < 0.001; BLEU_4: W = 0.618, Chi-Square = 76.023, df = 5, p < 0.001). For all BLEU_n automatic metrics, the test is significant (p < 0.001), i.e., the assumption is violated. If the assumption of covariance matrix sphericity is not met, the type I error rate increases. We adjusted the degrees of freedom using the Greenhouse–Geisser adjustment (, for the F-test that was used, thus achieving the declared level of significance.where T is the number of dependent samples (BLEU_n scores of the examined translations) and D is the number of cases (documents).
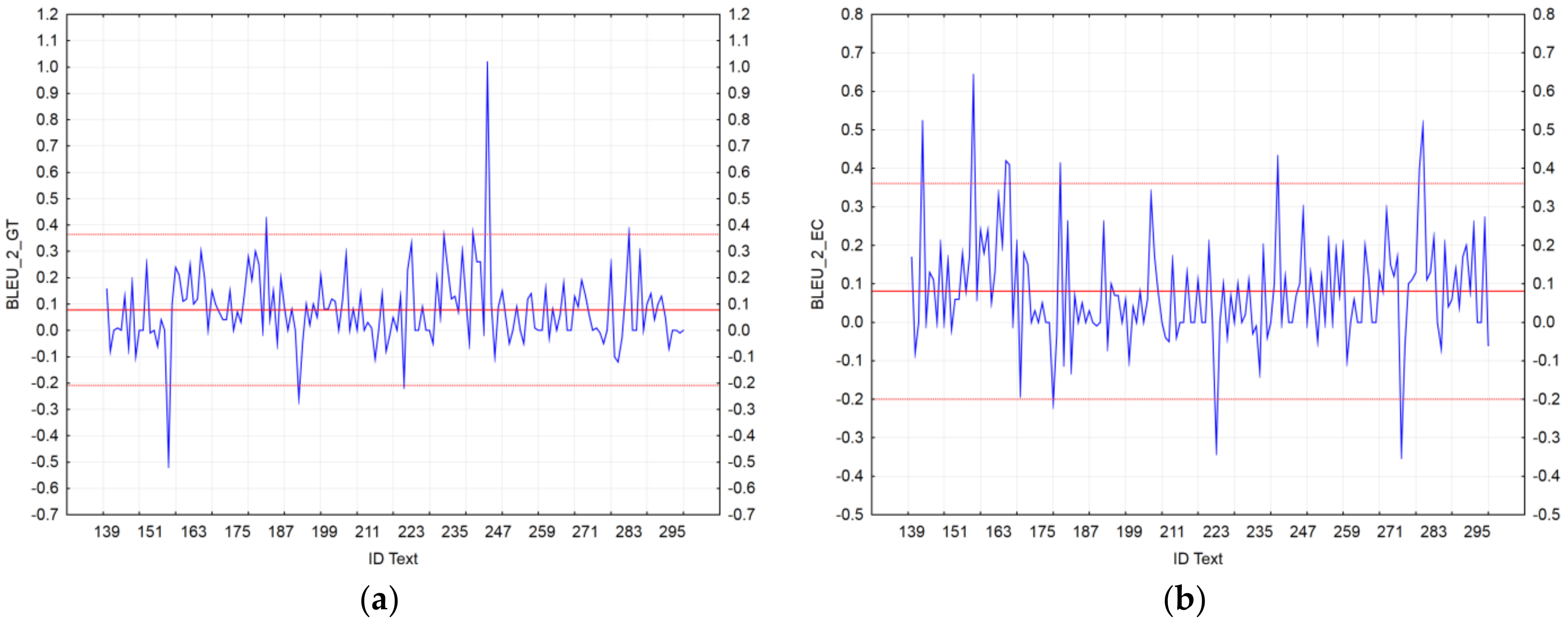
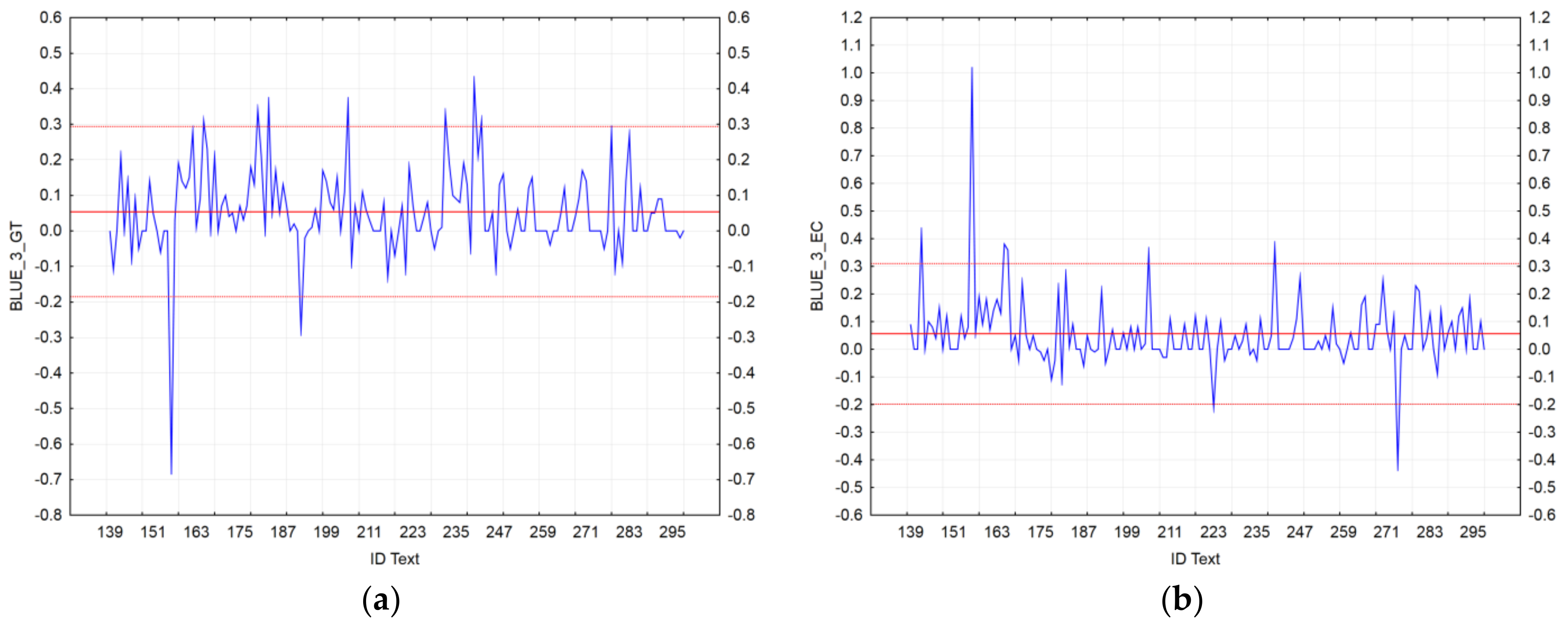
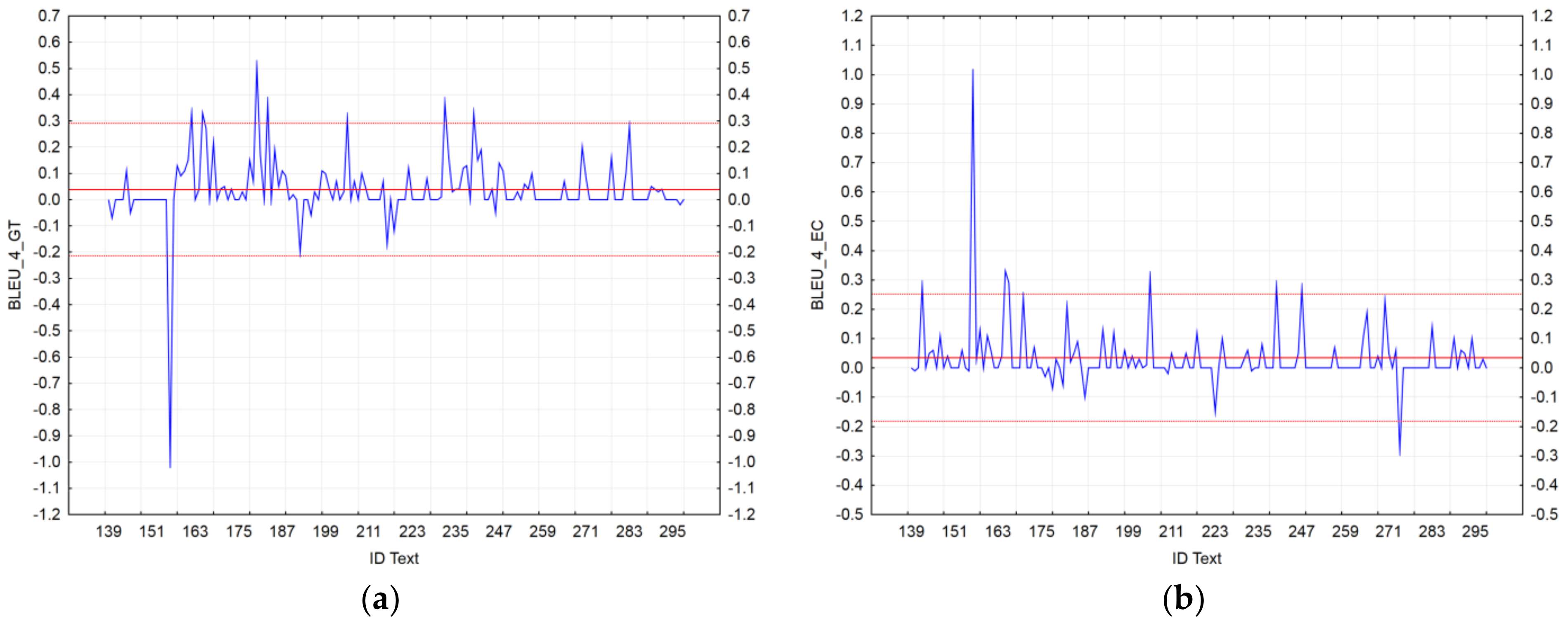
- Identification of the texts with the greatest distance between SMT and NMT [39]. We used residuals to compare scores of the BLEU_n automatic metrics of MT_SMT with MT_NMT at the document level. In our case, the residual analysis was defined as follows: ,where D is the number of examined texts in the dataset, NMT is a neural machine translation, and SMT is a statistical machine translation.
4. Results
4.1. Comparison of MT Quality
4.2. MT Text Identification
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Farhan, W.; Talafha, B.; Abuammar, A.; Jaikat, R.; Al-Ayyoub, M.; Tarakji, A.B.; Toma, A. Unsupervised dialectal neural machine translation. Inf. Process. Manag. 2020, 57, 102181. [Google Scholar] [CrossRef]
- Chomsky, N. Three Factors in Language Design. Linguist. Inq. 2005, 36, 1–22. [Google Scholar] [CrossRef]
- Christensen, C.H. Arguments for and against the Idea of Universal Grammar. Leviathan Interdiscip. J. Engl. 2019, 4, 12–28. [Google Scholar] [CrossRef] [Green Version]
- Castilho, S.; Doherty, S.; Gaspari, F.; Moorkens, J. Approaches to Human and Machine Translation Quality Assessment. In Translation Quality Assessment. Machine Translation: Technologies and Applications; Springer: Cham, Switzerland, 2018; Volume 1. [Google Scholar]
- Popović, M. Error Classification and Analysis for Machine Translation Quality Assessment. In Machine Translation: Technologies and Applications; Moorkens, J., Castilho, S., Gaspari, F., Doherty, S., Eds.; Springer: Cham, Switzerland, 2018; Volume 1. [Google Scholar]
- Dowling, M.; Moorkens, J.; Way, A.; Castilho, S.; Lynn, T. A human evaluation of English-Irish statistical and neural machine translation. In Proceedings of the 22nd Annual Conference of the European Association for Machine Translation, Lisboa, Portugal, 3–5 November 2020; European Association for Machine Translation: Lisboa, Portugal, 2020; pp. 431–440. [Google Scholar]
- Munk, M.; Munkova, D.; Benko, L. Towards the use of entropy as a measure for the reliability of automatic MT evaluation metrics. J. Intell. Fuzzy Syst. 2018, 34, 3225–3233. [Google Scholar] [CrossRef] [Green Version]
- Bahdanau, D.; Cho, K.H.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015-Conference Track Proceedings, International Conference on Learning Representations, ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, Australia, 6–11 August 2017; Volume 3. [Google Scholar]
- Zhang, J.J.; Zong, C.Q. Neural machine translation: Challenges, progress and future. Sci. China Technol. Sci. 2020, 63, 2028–2050. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 3104–3112. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Curran Associates: Long Beach, CA, USA, 2017; Volume 2017-Decem. [Google Scholar]
- Biesialska, M.; Guardia, L.; Costa-jussa, M.R. The TALP-UPC System for the WMT Similar Language Task: Statistical vs Neural Machine Translation; Association for Computational Linguistics: Florence, Italy, 2019; pp. 185–191. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Webster, R.; Fonteyne, M.; Tezcan, A.; Macken, L.; Daems, J. Gutenberg goes neural: Comparing features of dutch human translations with raw neural machine translation outputs in a corpus of english literary classics. Informatics 2020, 7, 21. [Google Scholar] [CrossRef]
- Van Brussel, L.; Tezcan, A.; Macken, L. A fine-grained error analysis of NMT, PBMT and RBMT output for English-to-Dutch. In Proceedings of the LREC 2018-11th International Conference on Language Resources and Evaluation, Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Tezcan, A.; Daems, J.; Macken, L. When a ‘sport’ is a person and other issues for NMT of novels. In Qualities of Literary Machine Translation; European Association for Machine Translation: Dublin, Ireland, 2019; pp. 40–49. [Google Scholar]
- Yu, H.; Luo, H.; Yi, Y.; Cheng, F. A2R2: Robust Unsupervised Neural Machine Translation With Adversarial Attack and Regularization on Representations. IEEE Access 2021, 9, 19990–19998. [Google Scholar] [CrossRef]
- Haque, R.; Hasanuzzaman, M.; Way, A. Analysing terminology translation errors in statistical and neural machine translation. Mach. Transl. 2020, 34, 149–195. [Google Scholar] [CrossRef]
- Junczys-Dowmunt, M.; Grundkiewicz, R.; Dwojak, T.; Heafield, H.H.K.; Neckermann, T.; Seide, F.; Germann, U.; Aji, A.F.; Bogoychev, N.; Martins, A.F.T.; et al. Marian: Fast neural machine translation in c++. In Proceedings of the ACL 2018-56th Annual Meeting of the Association for Computational Linguistics, Proceedings of System Demonstrations, Toronto, ON, Canada, 31 July 2018. [Google Scholar]
- Denkowski, M.; Lavie, A. Meteor 1.3: Automatic Metric for Reliable Optimization and Evaluation of Machine Translation Systems. In Sixth Workshop on Statistical Machine Translation; Association for Computational Linguistics: Edinburgh, Scotland, 2011; pp. 85–91. [Google Scholar]
- Snover, M.; Dorr, B.; Schwartz, R.; Micciulla, L.; Makhoul, J. A Study of Translation Edit Rate with Targeted Human Annotation; Association for Machine Translation in the Americas: East Stroudsburg, PA, USA, 2006; pp. 223–231. [Google Scholar]
- Dashtipour, K.; Gogate, M.; Li, J.; Jiang, F.; Kong, B.; Hussain, A. A hybrid Persian sentiment analysis framework: Integrating dependency grammar based rules and deep neural networks. Neurocomputing 2020, 380, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Almahasees, Z.M. Assessing the Translation of Google and Microsoft Bing in Translating Political Texts from Arabic into English. Int. J. Lang. Lit. Linguist. 2017, 3, 1–4. [Google Scholar] [CrossRef] [Green Version]
- Almahasees, Z.M. Assessment of Google and Microsoft Bing Translation of Journalistic Texts. Int. J. Lang. Lit. Linguist. 2018, 4, 231–235. [Google Scholar] [CrossRef]
- Cornet, R.; Hill, C.; De Keizer, N. Comparison of three english-to-Dutch machine translations of SNOMED CT procedures. In Studies in Health Technology and Informatics; IOS Press: Amsterdam, The Netherlands, 2017; Volume 245, pp. 848–852. [Google Scholar]
- Federico, M.; Bertoldi, N.; Cettolo, M.; Negri, M.; Turchi, M.; Trombetti, M.; Cattelan, A.; Farina, A.; Lupinetti, D.; Martines, A.; et al. The MateCat Tool. In Proceedings of the COLING 2014, 25th International Conference on Computational Linguistics: System Demonstrations, Dublin, Ireland, 23–29 August 2014; pp. 129–132. [Google Scholar]
- Ortiz-Martínez, D.; Casacuberta, F. The New Thot Toolkit for Fully-Automatic and Interactive Statistical Machine Translation. In Proceedings of the Demonstrations at the 14th Conference of the European Chapter of the Association for Computational Linguistics, Gothenburg, Sweden, 26–30 April 2014; Association for Computational Linguistics: Gothenburg, Sweden, 2014; pp. 45–48. [Google Scholar]
- Berrichi, S.; Mazroui, A. Addressing Limited Vocabulary and Long Sentences Constraints in English–Arabic Neural Machine Translation. Arab. J. Sci. Eng. 2021, 1744, 1–4. [Google Scholar] [CrossRef]
- Jassem, K.; Dwojak, T. Statistical versus neural machine translation - a case study for a medium size domain-specific bilingual corpus. Pozn. Stud. Contemp. Linguist. 2019, 55, 491–515. [Google Scholar] [CrossRef]
- Kosta, P. Targets, Theory and Methods of Slavic Generative Syntax: Minimalism, Negation and Clitics. Slavic Languages. Slavische Sprachen. An International Handbook of their Structure. In Slavic Languages. Slavische Sprachen. An International Handbook of their Structure, their History and their Investigation. Ein internationales Handbuch ihrer Struktur, ihrer Geschichte und ihrer Erforschung; Kempgen, S., Kosta, P., Berger, T., Gutschmidt, K., Eds.; Mouton. de Gruyter: Berlin, Germany; New York, NY, USA, 2009; pp. 282–316. ISBN 978-3-11-021447-5. [Google Scholar]
- Munková, D.; Munk, M.; Benko, Ľ.; Absolon, J. From Old Fashioned “One Size Fits All” to Tailor Made Online Training. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2020; Volume 916, pp. 365–376. [Google Scholar]
- Munkova, D.; Kapusta, J.; Drlik, M. System for Post-Editing and Automatic Error Classification of Machine Translation. In Proceedings of the DIVAI 2016: 11th International Scientific Conference On Distance Learning in Applied Informatics; Turcani, M., Balogh, Z., Munk, M., Benko, L., Eds.; Wolters Kluwer: Sturovo, Slovakia, 2016; pp. 571–579. [Google Scholar]
- Benko, Ľ.; Munková, D. Application of POS Tagging in Machine Translation Evaluation. In Proceedings of the DIVAI 2016: 11th International Scientific Conference on Distance Learning in Applied Informatics, Sturovo, Slovakia, 2–4 May 2016; Wolters Kluwer: Sturovo, Slovakia, 2016; pp. 471–489, ISSN 2464-7489. [Google Scholar]
- Benkova, L.; Munkova, D.; Benko, L.; Munk, M. Dataset of evaluation metrics for journalistic texts EN/SK. Mendeley Data 2021, V1. [Google Scholar] [CrossRef]
- Varga, D.; Németh, L.; Halácsy, P.; Kornai, A.; Trón, V.; Nagy, V. Parallel corpora for medium density languages. Proc. RANLP 2005, 4, 590–596. [Google Scholar]
- Lee, S.; Lee, D.K. What is the proper way to apply the multiple comparison test? Korean J. Anesthesiol. 2018, 71, 353–360. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Genç, S.; Soysal, M.İ. Parametrik Ve Parametrik Olmayan Çoklu Karşilaştirma Testleri. Black Sea J. Eng. Sci. 2018, 1, 18–27. [Google Scholar]
- Munk, M.; Munkova, D. Detecting errors in machine translation using residuals and metrics of automatic evaluation. J. Intell. Fuzzy Syst. 2018, 34, 3211–3223. [Google Scholar] [CrossRef]
- Munkova, D.; Munk, M. Automatic Evaluation of Machine Translation Through the Residual Analysis. In Advanced Intelligent Computing Theories and Applications; Huang, D.S., Han, K., Eds.; icic 2015; pt iii.; Springer: Fuzhou, China, 2015; Volume 9227, pp. 481–490. [Google Scholar]
- Welnitzova, K. Post-Editing of Publicistic Texts in The Context of Thinking and Editing Time. In Proceedings of the 7th SWS International Scientific Conference on Arts and Humanities-ISCAH 2020, Sofia, Bulgaria, 25–27 August 2020; STEF92Technology: Sofia, Bulgaria, 2020. [Google Scholar]
- Welnitzová, K. Interpretačná analýza chýb strojového prekladu publicistického štýlu z anglického jazyka do slovenského jazyka. In Mýliť sa je ľudské (ale aj strojové): Analýza chýb strojového prekladu do slovenčiny; UKF: Nitra, Slovakia, 2017; pp. 89–116. ISBN 978-80-558-1255-7. [Google Scholar]
- Welnitzova, K.; Jakubickova, B. Enhancing cultural competence in interpreting-cultural differences between the UK and Slovakia. In Proceedings of the 7th SWS International Scientific Conference on Arts And Humanities-ISCAH 2020, Sofia, Bulgaria, 25–27 August 2020; STEF92Technology: Sofia, Bulgaria, 2020. [Google Scholar]
- Welnitzová, K. Neverbálna komunikácia vo svetle konzekutívneho tlmočenia; UKF: Nitra, Slovakia, 2012; ISBN 978-80-558-0077-6. [Google Scholar]
- Neubig, G.; Hu, J. Rapid Adaptation of Neural Machine Translation to New Languages; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018. [Google Scholar]
- Aharoni, R.; Johnson, M.; Firat, O. Massively Multilingual Neural Machine Translation; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019. [Google Scholar]
- Vojtěchová, T.; Novák, M.; Klouček, M.; Bojar, O. SAO WMT19 Test Suite: Machine Translation of Audit Reports. In Proceedings of the Fourth Conference on Machine Translation-Proceedings of the Conference, Florence, Italy, 1–2 August 2019; pp. 680–692. [Google Scholar]
- Barrault, L.; Bojar, O.; Costa-jussà, M.R.; Federmann, C.; Fishel, M.; Graham, Y.; Haddow, B.; Huck, M.; Koehn, P.; Malmasi, S.; et al. Findings of the 2019 Conference on Machine Translation (WMT19); Association for Computational Linguistics (ACL): Florence, Italy, 2019; Volume 2, pp. 1–61. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Type | GT_SMT | GT_NMT | mt@ec_SMT | E-translation_NMT | Reference |
|---|---|---|---|---|---|
| Average sentence length (words) | 21.74 | 19.54 | 18.06 | 20.15 | 18.66 |
| Average word length (characters) | 5.32 | 5.43 | 5.6 | 5.4 | 5.53 |
| Frequency of long sentences (w ≥ 10) | 84.83% | 83.97% | 73.42% | 83.44% | 81.87% |
| Frequency of short sentences (w < 10) | 15.17% | 16.03% | 26.58% | 16.56% | 18.13% |
| Frequency of nouns | 29.94% | 31.00% | 31.34% | 29.40% | 29.67% |
| Frequency of adjectives | 9.23% | 10.06% | 10.25% | 9.68% | 10.25% |
| Frequency of adverbs | 3.77% | 3.30% | 3.76% | 3.56% | 3.51% |
| Frequency of verbs | 16.16% | 15.02% | 14.67% | 16.00% | 15.91% |
| Frequency of pronominals | 7.32% | 7.64% | 6.88% | 7.67% | 8.67% |
| Frequency of participles | 2.42% | 1.81% | 2.95% | 2.40% | 1.65% |
| Frequency of morphemes | 1.65% | 2.36% | 1.61% | 2.34% | 3.07% |
| Frequency of abbreviation | 0.52% | 0.36% | 0.88% | 0.49% | 0.25% |
| Frequency of numbers | 1.74% | 1.97% | 1.97% | 1.81% | 1.33% |
| Frequency of undefinable POSs | 0.42% | 0.36% | 0.39% | 0.33% | 0.32% |
| Frequency of particules | 1.87% | 2.20% | 2.25% | 2.01% | 2.37% |
| Frequency of foreign words | 3.19% | 2.56% | 2.21% | 2.44% | 1.83% |
| Frequency of interjections | 0.00% | 0.00% | 0.04% | 0.03% | 0.00% |
| Frequency of numerals | 3.10% | 2.52% | 2.74% | 2.70% | 2.78% |
| Frequency of prepositions and conjunctions | 18.68% | 18.83% | 18.08% | 19.13% | 18.38% |
| (a) | (b) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| BLEU_1 | GT_SMT | GT_NMT | EC_SMT | EC_NMT | BLEU_2 | GT_SMT | GT_NMT | EC_SMT | EC_NMT |
| GT_SMT | 0.00000 | 0.00000 | 0.00000 | GT_SMT | 0.00000 | 0.01047 | 0.00010 | ||
| GT_NMT | 0.00000 | 0.00000 | 0.10998 | GT_NMT | 0.00000 | 0.00000 | 0.02446 | ||
| EC_SMT | 0.00000 | 0.00000 | 0.00000 | EC_SMT | 0.01047 | 0.00000 | 0.00000 | ||
| EC_NMT | 0.00000 | 0.10998 | 0.00000 | EC_NMT | 0.00010 | 0.02446 | 0.00000 | ||
| (a) | (b) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| BLEU_3 | GT_SMT | GT_NMT | EC_SMT | EC_NMT | BLEU_4 | GT_SMT | GT_NMT | EC_SMT | EC_NMT |
| GT_SMT | 0.00000 | 0.07270 | 0.00233 | GT_SMT | 0.00004 | 0.46602 | 0.12269 | ||
| GT_NMT | 0.00000 | 0.00000 | 0.12649 | GT_NMT | 0.00004 | 0.00000 | 0.14572 | ||
| EC_SMT | 0.07270 | 0.00000 | 0.00000 | EC_SMT | 0.46602 | 0.00000 | 0.00030 | ||
| EC_NMT | 0.00233 | 0.12649 | 0.00000 | EC_NMT | 0.12269 | 0.14572 | 0.00030 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benkova, L.; Munkova, D.; Benko, Ľ.; Munk, M. Evaluation of English–Slovak Neural and Statistical Machine Translation. Appl. Sci. 2021, 11, 2948. https://doi.org/10.3390/app11072948
Benkova L, Munkova D, Benko Ľ, Munk M. Evaluation of English–Slovak Neural and Statistical Machine Translation. Applied Sciences. 2021; 11(7):2948. https://doi.org/10.3390/app11072948
Chicago/Turabian StyleBenkova, Lucia, Dasa Munkova, Ľubomír Benko, and Michal Munk. 2021. "Evaluation of English–Slovak Neural and Statistical Machine Translation" Applied Sciences 11, no. 7: 2948. https://doi.org/10.3390/app11072948
APA StyleBenkova, L., Munkova, D., Benko, Ľ., & Munk, M. (2021). Evaluation of English–Slovak Neural and Statistical Machine Translation. Applied Sciences, 11(7), 2948. https://doi.org/10.3390/app11072948