1. Introduction
One of the most important issues for autonomous robots is to localize their positions in the environment. A mobile robot lacking localization information will have a restricted capability for navigation and exploration. Some general tasks, such as home-care services or industrial applications, become more difficult to accomplish. This led the robotics research community paying more attention to coping with the mobile robot localization problem [
1]. The commonly used techniques for environmental perception utilize the sensing data obtained from visual, auditory and tactile sensors. This provides the essential information for mobile robots to detect obstacles, complete missions and build a map of the environment. In addition, there also exist indoor localization techniques based on radio technology. The current 5G network and personal mobile radar can be used for accurate environmental mapping [
2,
3].
Self-localization is a key technology for autonomous robots, and many researchers have attempted to improve its efficiency [
4,
5]. In general, various sensors are adopted to acquire the information from the environment and derive the 2D/3D position of the mobile robot for motion planning [
6,
7]. The position computation can be divided into two different approaches. The first approach is based on the probability estimation methods to calculate the robot’s position. The Kalman filter is frequently used to find the largest probability and update the location state based on the sensor data [
8,
9,
10]. In the previous work, Negenborn illustrated a method using the distributed Kalman filter algorithm with a distributed model predictive control (MPC) scheme for large-scale, multi-rate systems [
11]. Ledergerber et al. [
12] presented a self-localization technique using the extended Kalman filter and random-walk model with the data collected from ultra-wideband signals.
The other self-localization approach is based on the data registration of the 3D models reconstructed from the real scene environment at different locations. Zhang proposed a technique using the iterative closest point (ICP) algorithm to compute the robot’s movement [
13]. The 3D registration is carried out on two sets of sensor data obtained from sonar, a laser rangefinder or an RGB-D camera. Due to its high computational cost and insufficient accuracy, a number of works have been proposed for further improvements [
14,
15]. In addition, Salvi et al. compared the performance of various registration techniques, including the 3D data obtained from multiple viewpoints [
16].
In the past few decades, omnidirectional cameras have been widely adopted to the mobile robot applications due to their capability with observing the panoramic viewpoints of the surroundings [
17]. Traditional studies attempted to identify the features of the environment (edges, points or lines) by direct extraction from the images captured by the camera. For mobile robot localization, Tasaki et al. presented a beacon-based technique using an omnidirectional camera [
18]. The image features are extracted using SURF with the scale and orientation invariant. Kawanishi et al. proposed a localization method based on the parallel lines appearing in omnidirectional images [
19]. The line features in the structured environment are detected using structure-from-motion. There also exist various stereo vision-based approaches using multiple cameras [
20]. Nevertheless, the direct use of image information brings disadvantages for robot self-localization, for example, the problems associated with illumination change, motion blur, etc.
In this paper, we present a novel self-localization approach using the generated virtual environment to simulate the robot navigation in the real world. The basic idea is to calculate the localization position through the computer generated virtual environment. In the simulated virtual space, a mobile robot equipped with an omnidirectional vision sensor represents a mirror of its real world counterpart. Since computing the 3D position without the illumination change and noise in the simulated environment is much easier, it is used to process the image features extracted from the real world scenes. In the existing literature, the omnidirectional images are used to directly deal with the objects without the virtual information. This work suggests creating a parallel virtual space which simulates the environment in the real world. A mobile robot navigating along a trajectory is used to evaluate the proposed localization technique.
This paper is organized as follows. In the next section, we introduce the omnidirectional vision system adopted in this work and the catadioptric image projection model. The construction of the virtual space and how to generate vertical and horizontal lines within the structured space are described in the Virtual Environment section. In the section Robot Self-Localization, we formulate the pose of the mobile robot as the efficient perspective-n-point (EPnP) problem and our proposed solution. The implementation and experimental results are presented in the Experiments section, followed by the conclusions in the last section.
2. Omnidirectional Vision System
In this work, we utilized an omnidirectional camera for vision based mobile robot self-localization. Since the relationship between the 3D scene points and 2D image pixels is required, it is necessary to perform the camera calibration. To calibrate a conventional perspective camera, a planar checkerboard is commonly adopted for its simplicity and high accuracy on camera matrix computation [
21]. For omnidirectional cameras, Scaramuzza et al. proposed a method to calibrate the non-classic cameras (e.g., catadioptric cameras) based on the polynomial approximation [
22]. They estimated the camera parameters by transferring the manually selected 3D feature points on the checkerboard pattern to the image plane.
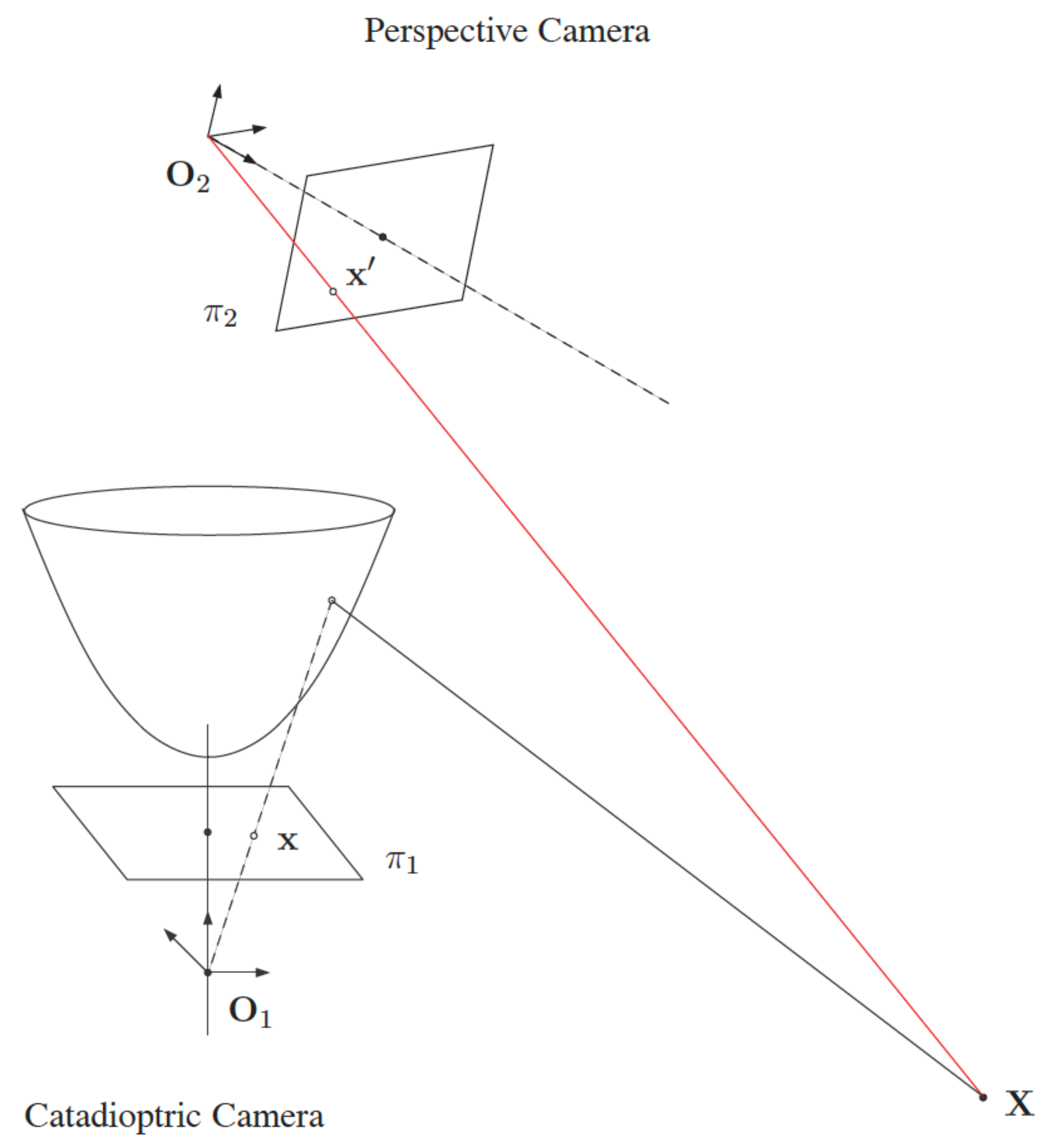
Figure 1 illustrates the projection models of a perspective camera and an omnidirectional camera. The images captured by the omnidirectional cameras are distorted by reflection from the hyperbolic mirror and refraction from the lens. Thus, the feature extraction on the calibration checkerboard is not so straightforward compared to the perspective projection of conventional cameras. Since large errors will be introduced by the line detection in omnidirectional images, it is necessary to select the point features manually. Consequently, the parameter initialization of the image projection function is a complicated and tedious process. To simplify the parameter initialization problem, Mei and Rives [
23] proposed a projection model for catadioptric cameras. Specific imaging reflection functions are formulated for different types of curved mirrors to reduce the projection error via an initialization process. It only requires one to take four points on each image of the calibration board, and all corner features can be extracted automatically based on the estimates from the project model.
One of the important objectives of our omnidirectional camera calibration is to simplify the feature extraction. The approximated focal length and image center obtained during the initialization process are combined with manually selected four corner points to estimate all other feature points on the calibration images. This greatly reduces the cost for the detection and selection of all features. In addition to the initialization step, we also incorporate the simulation of distortion parameters. It is used to minimize the error through the simulated environment, and provides more accurate calibration results. In this work, the catadioptric projection model proposed by Geyer and Barreto was used to calibrate the omnidirectional camera [
24,
25].
2.1. Camera Model
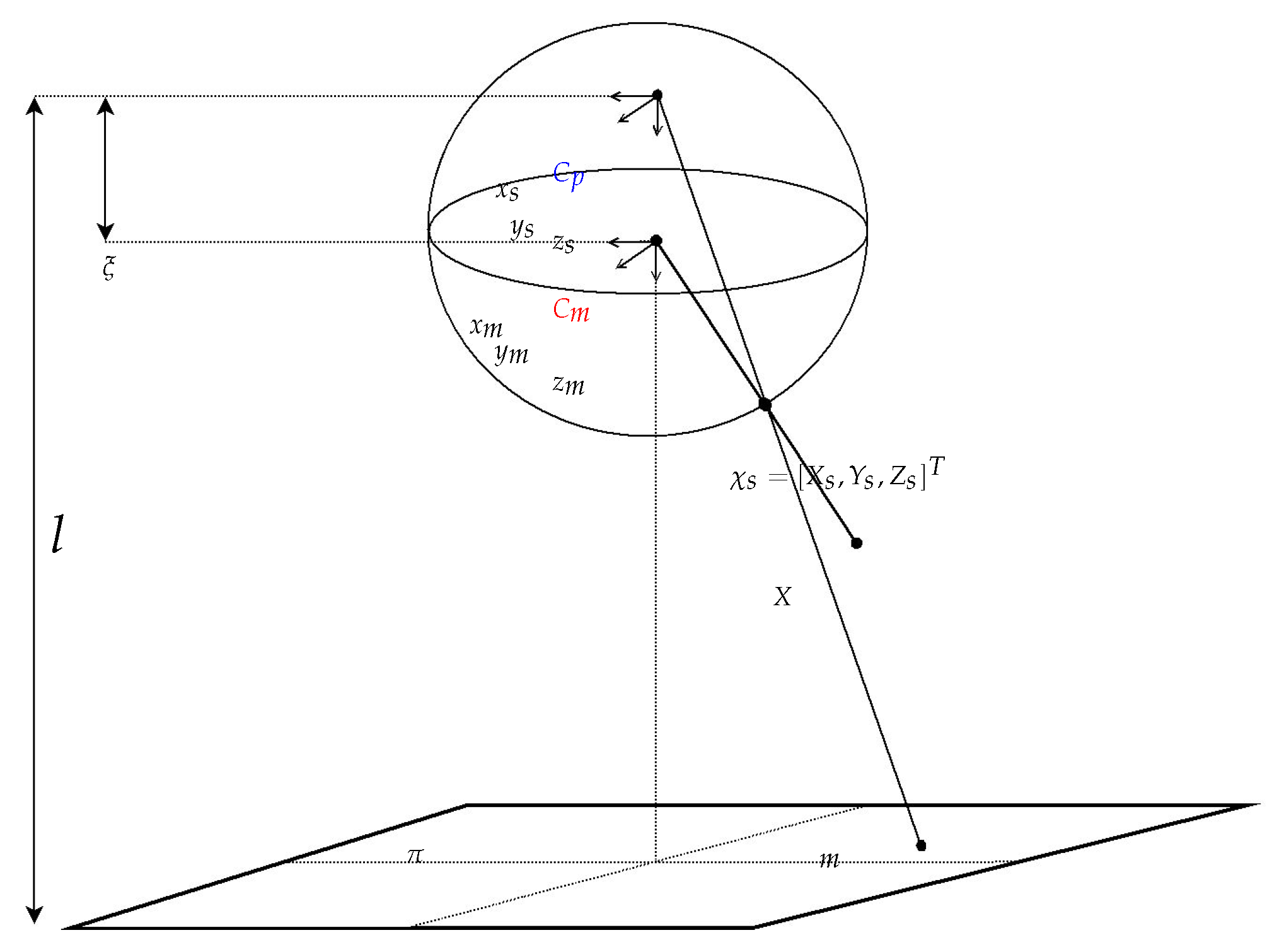
The omnidirectional camera realized through the catadioptric imaging system construction can be formulated using a unified sphere model, as shown in
Figure 2. Given a point
X in the 3D space, it can be projected onto a unified sphere at the point
as illustrated in the figure. The point
is then transferred to a new reference frame centered at
, and projected onto an image plane at the point
where
is the distance between the center of the sphere
and the image projection center
. The projected point
p is given by
This projection model involves a generalized camera matrix
K with the focal length
, the principal point
, the skew factor
s and the pixel aspect ratio
r. An image pixel
in the omnidirectional image is then calculated by the ratios
Figure 2.
The unified sphere model for omnidirectional cameras. It consists of two linear projection steps.
Figure 2.
The unified sphere model for omnidirectional cameras. It consists of two linear projection steps.
To calibrate the omnidirectional camera, a checkerboard pattern was adopted as the calibration plate. The parameters were initialized according to the type of reflection mirrors. After the focal length and principal point were estimated, the parameters were used to simplify the feature extraction process and further optimize the parameters. The procedure is given as follows.
Provide the center and border of the reflection mirror as shown in
Figure 3a, and then estimate the principal point
.
Select at least three points on the same line (distorted by catadioptric imaging) from the calibration pattern as shown in
Figure 3b, and estimate the focal length
.
Select the four corners on the calibration pattern as illustrated in
Figure 3c, and estimate the extrinsic parameters.
The rest feature points on the calibration can be detected at the sub-pixel resolution via the inverse projection, as illustrated in
Figure 3d.
Finally, the overall optimization should be carried out based on Equation (
3) to derive more accurate intrinsic and extrinsic camera parameters.
2.2. Vision Recognition
The surrounding visual information obtained from a mobile robot contains important features for image analysis. The proposed vision system simplified the object detection and recognition procedures using the acquired omnidirectional images with the resolution of
. First, the object locations are detected via the color segmentation technique in the omnidirectional image. The position representation is converted to the polar coordinates
,
where
is in pixel coordinates,
is the center of the omnidirectional image,
is the height of the image plane, and
is the detected or estimated location of the object in the image coordinates.
3. Virtual Environment
In the existing literature, the vision-based approaches for localization usually analyze the images taken by the cameras, and use the extracted features to derive the robot position. In this work, we first created a virtual space as the counterpart of the real environment. The synthetic image acquired in the virtual space was compared with the real image to deduce the relationship between the virtual and real cameras. It was then used to compute the location of the mobile robot in the real environment.
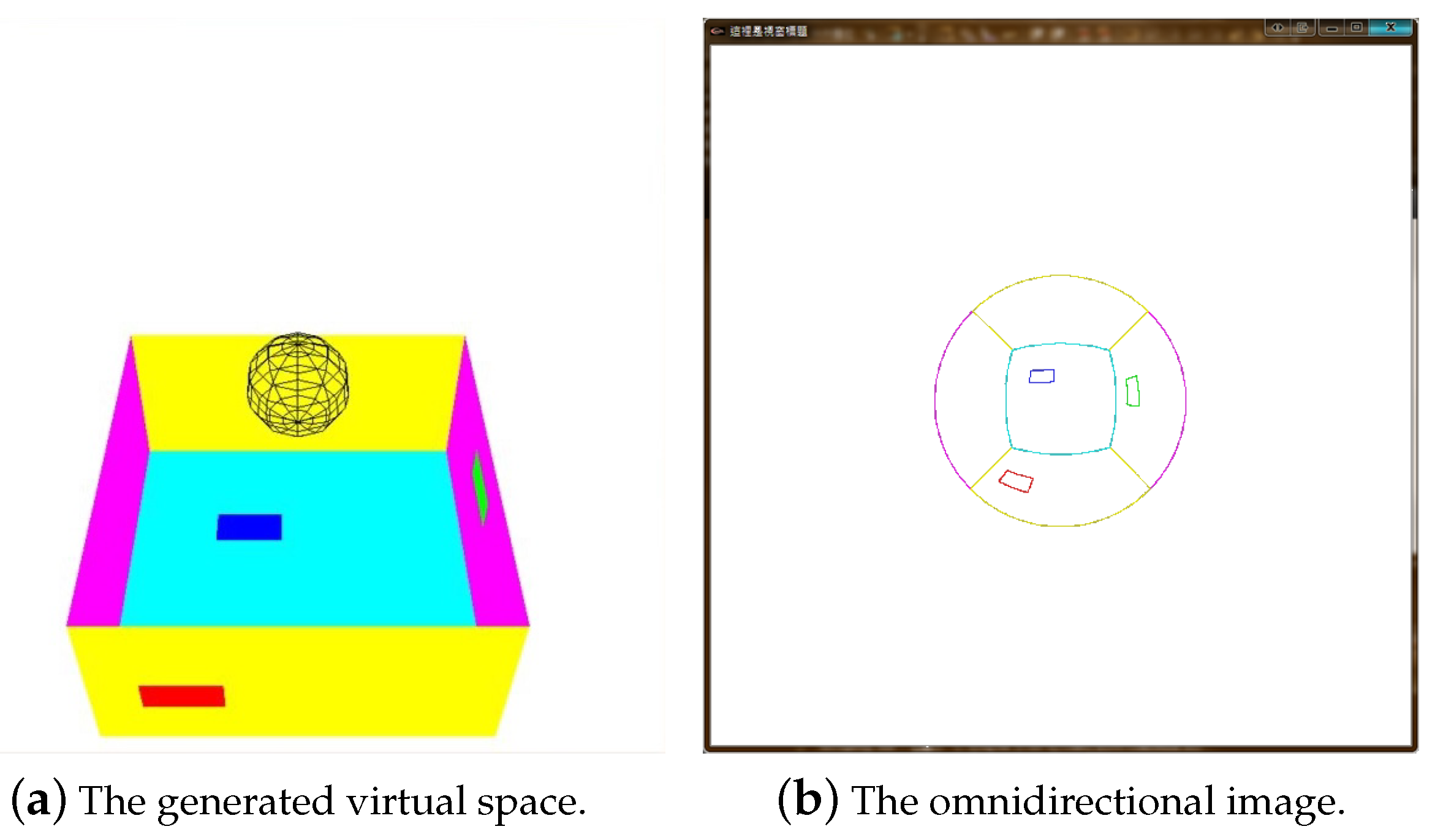
We first constructed a virtual space for the robot’s movement with several simulated objects, and created an omnidirectional camera in the space at an initial position. As illustrated in
Figure 4a, the white sphere indicates the position of the virtual omnidirectional camera, and the space below represents the maximum range for image acquisition.
Figure 4b shows an image of several objects and lines in the space captured by the virtual omnidirectional camera. The images of the virtual space and real environment were then compared using the same camera projection model, as described in the previous section for correspondence matching. Once the similar features were identified in both the virtual and real omnidirectional images, the positions of the objects and the camera were estimated in the virtual environment. The relative motion with respect to the starting position was then converted to the real world environment to calculate the mobile robot location.
3.1. Lines in The Virtual Space
In this work, the robot was expected to move in a man-made environment, such as a room or a corridor. Such an environment usually contains horizontal and vertical lines. Thus, we created a virtual space with 3D lines to associate with the real world environment. To match the generated virtual lines with the lines in the omnidirectional image captured in the real world, we used the polar coordinate system to produce the lines in the virtual space. In general, the Cartesian coordinate system was used to create the parallel and orthogonal lines in the space. However, this will make the distribution of the 2D lines very uneven in the captured image.
Figure 5 shows the parallel lines generated in the virtual space and captured by a virtual omnidirectional camera. To deal with this problem, we use the polar coordinate system to generate the 3D lines in the virtual space. These lines are expected to locate in the virtual environment with the dense appearance as illustrated in
Figure 6a. The appearance in the omnidirectional image is shown in
Figure 6b. With this process the polar coordinate system is able to avoid the computational cost.
3.2. Matching of Virtual Images to Real Images
The synthetic image generated in the virtual space is compared with the real image captured by the omnidirectional camera. The line features in the synthetic image is matched with the edges in the real image. Once the correspondences are identified, the matched 3D lines are preserved in the simulated environment. These virtual lines are then used to compute the position of the virtual camera in the 3D space. Consequently, the relationship between the virtual lines and the virtual camera is proportional to the relationship between the edges and the omnidirectional camera in the real world environment. The location of the mobile robot is then calculated via the transformation.
In the implementation, the robot’s motion was also taken into account to calculate the camera pose. We adjusted the angles of virtual lines to approximately match the edges in the omnidirectional images. The matching steps are as follows:
4. Robot Self-Localization
The image projection of the simulated lines are matched to the lines in the real world, and applied to derive the robot motion in the virtual environment. It is assumed that the surrounding environment is fixed, and the robot captures the images in a moving trajectory. In this work, we use the perspective-n-point (PnP) algorithm to compute the robot motion. The algorithm estimates the camera position in 3D with respect to a series of 3D known feature such as points and lines. It is efficient to use linear equations to solve the PnP problem, but this has to result in a larger position estimation error [
26]. A better solving strategy is to adopt nonlinear iterative equations to achieve high accuracy [
27]. Our method is based on the efficient perspective-n-point (EPnP) algorithm proposed by Lepetit et al. [
28] to estimate the virtual camera position during the robot motion.
In the EPnP algorithm, we first select four non-coplanar points as reference points. Their coordinates in the camera reference system are derived according to the 2D image points and the relationships between 3D points and the reference points. Let
be
n points in the 3D space, and
and
for
be the four reference points in the world and camera coordinate systems, respectively. Then the transformation between
and
is given by
where
are the coordinates of
taking the reference points as basis. Similarly, we have
Thus,
where
represents the projection of
and
A is the intrinsic camera parameter matrix.
Let
and for given
N points. The right-hand side of Equation (
8) can be written as
M with
where
Thus, the above equation can be solved by singular value decomposition. Given the world coordinates
and the camera coordinates
, the relationship between
and
is written as
by Equations (
6) and (
7). The extrinsic camera parameter matrices
R and
T can then be derived with the closed-form solution [
29].
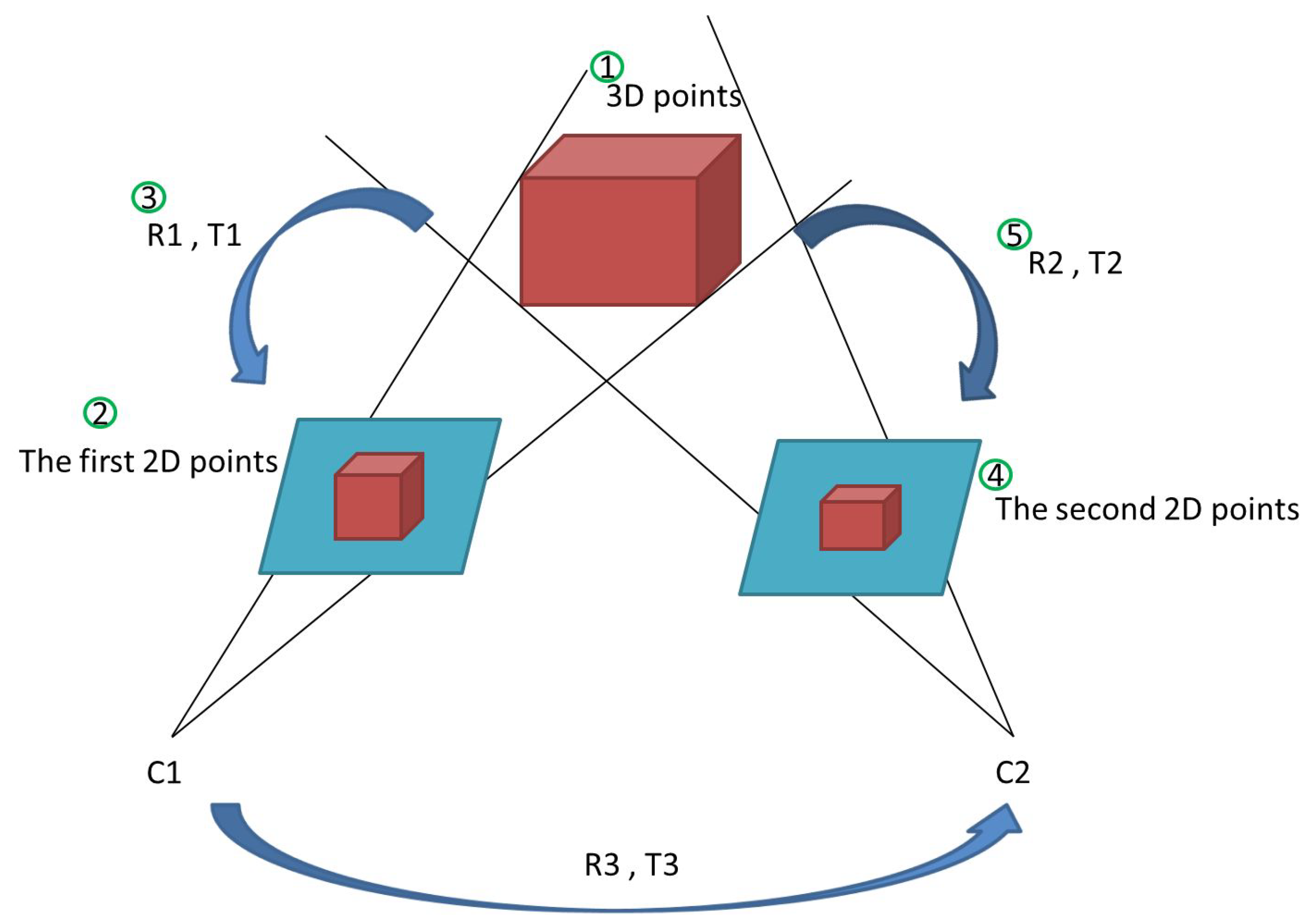
To apply the EPnP algorithm to estimate the camera’s position in the virtual environment, we define a set of 3D points and the corresponding 2D points detected in the acquired omnidirectional images. The second set of 3D and 2D point correspondences is then obtained in the omnidirectional image captured after the robot’s motion. As illustrated in
Figure 8, the EPnP algorithm is used to compute the transformation between the two sets of 3D and 2D point correspondence. This provides the rotation matrix and translation vector of the robot movement.
5. Experiments
A mobile robot equipped with an omnidirectional camera as shown in
Figure 9 was used in our experiments. The omnidirectional vision system placed on top of the robot contained a curved mirror and a Sony X710 video camera. The software was developed with Visual Studio with OpenCV and OpenGL libraries under Windows Operation System. The virtual environment was modeled based on its real-world counterpart, with the dimensions multiplied by a scale factor. It was constructed using OpenGL with the geometric primitives, including the corridor, walls, roof, doors, and windows. The omnidirectional imaging model was used to create the virtual camera for image synthesis.
In the first experiment, an image sequence was captured and processed frame-by-frame when the mobile robot moved in a straight line.
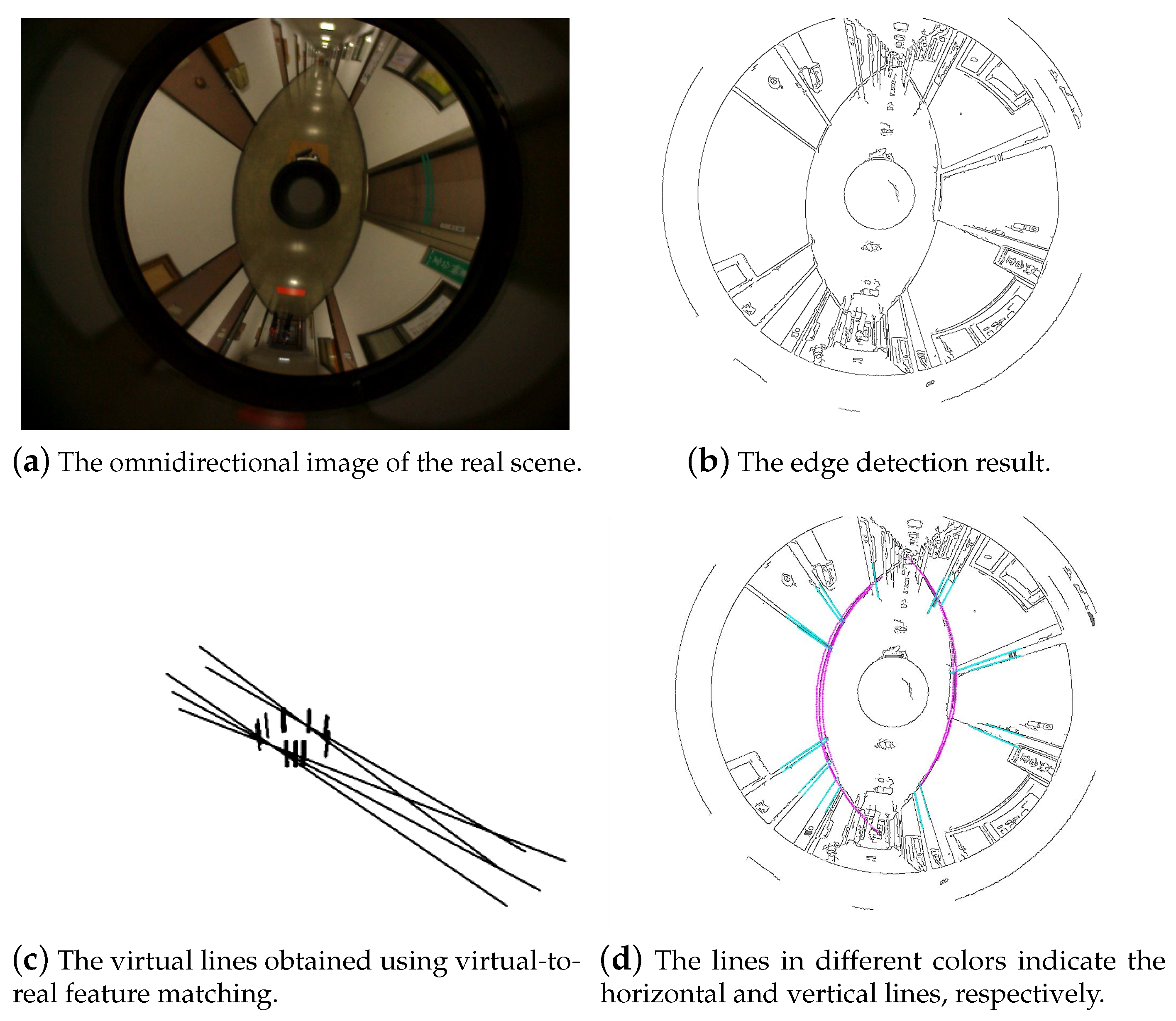
Figure 10 showed the acquired images for the self-localization computation. For the input image, as shown in
Figure 11a, the edge detection was first carried out to obtain an edge image (see
Figure 11b). The parallel horizontal and vertical lines constructed in the vertical space are illustrated in
Figure 11c.
Figure 11d shows the overlay of the edge image with the virtual lines projected on the omnidirectional image according to the catadioptric projection model. By matching the line features from the synthetic and real images, the true horizontal and vertical lines in the real environment could be identified, as illustrated in
Figure 11e. The corresponding lines in the virtual space (see
Figure 11f) were then used to calculate the mobile robot’s position.
In the second experiment, the mobile robot moved on non-smooth ground to evaluate the self-localization capability.
Figure 12 shows the image sequence to derive the robot motion trajectory. The self-localization results for the first and second experiments are shown in
Figure 13a,b, respectively. In the figures, the blue dot represents the localization of the mobile robot in the environment. It consists of the forward direction, horizontal and vertical displacements. The mobile robot moved smoothly in the forward direction, as illustrated in
Figure 13a. Several data points of the trajectory in
Figure 13b were due to the altitude changes in the robot’s motion. The evaluation demonstrates that the proposed self-localization method based on the matching between virtual and real spaces performed well. It can be seen in the figures that the trajectories are relatively stable for the horizontal displacements and in the forward direction. There exist slight fluctuations in the vertical direction for both cases. This could be due to the matching errors, and can be improved by better feature alignments using high resolution images.
In our method, it is required to generate the virtual environment for robot self-localization. This is different from the conventional vision-based localization approaches which use only the acquired real images. Thus, there is no easy way to compare our method with other algorithms using public image datasets. Nevertheless, we are able to run in real-time because of more restricted feature extraction and matching associated with the virtual environment. Due to the use of horizontal and vertical line features separately for the location computation, the accuracy in the horizontal direction is better than the altitude direction. This is because the feature points used for vertical lines span a fairly large range compared to the horizontal lines. Consequently, it affects the accuracy and possibly the stability of the final result. For the trade-off between our method and conventional vision based techniques, there is extra work to create the virtual environment. However, the geometric constraint enforced by the virtual space will keep the error in a certain range. It can avoid the accumulation of the drifting errors commonly seen in other localization methods.
6. Conclusions and Future Work
In this paper, we presented a vision-based self-localization technique for mobile robot navigation through a simulated virtual environment. The mobile robot’s position is calculated in the computer generated environment by the image feature matching with the real world scenes. Our proposed technique utilizes an omnidirectional camera to capture the images of the surroundings and estimate the camera motion trajectory based on the catadioptric projection model. Differently from the existing works using the omnidirectional images directly, our approach creates a parallel virtual space which simulates the environment in the real world. A mobile robot navigating along a trajectory was used to evaluate the proposed localization technique.
In the future work, a performance evaluation will be carried out in terms of the localization accuracy. The ground-truth positions of the mobile robot will be derived using a predefined path for comparison. Alternatively, other vision-based localization algorithms could be executed in parallel with the proposed technique for evaluation. Nevertheless, the input image sequence does not necessary have to be acquired from an omnidirectional camera. It could be monocular or a stereo image sequence captured from conventional perspective cameras. Another important issue for future investigation is the localization errors exclusively caused by the modeling of the virtual environment. More specifically, one should know the extent to which the localization accuracy is damaged if an incomplete or imprecise virtual model is provided.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












