
CF-CNN: Coarse-to-Fine Convolutional Neural Network



Abstract
:1. Introduction
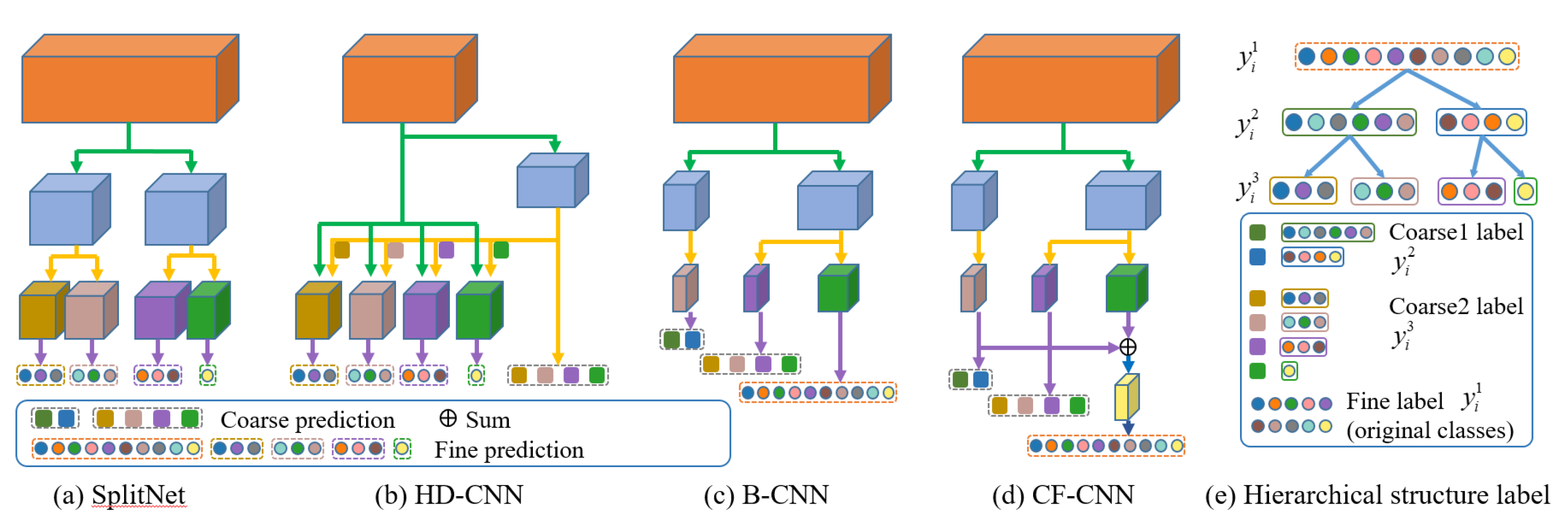
2. Coarse-to-Fine Convolutional Neural Network
2.1. Loss Function for CF-CNN
2.2. Disjoint Grouping Regularization
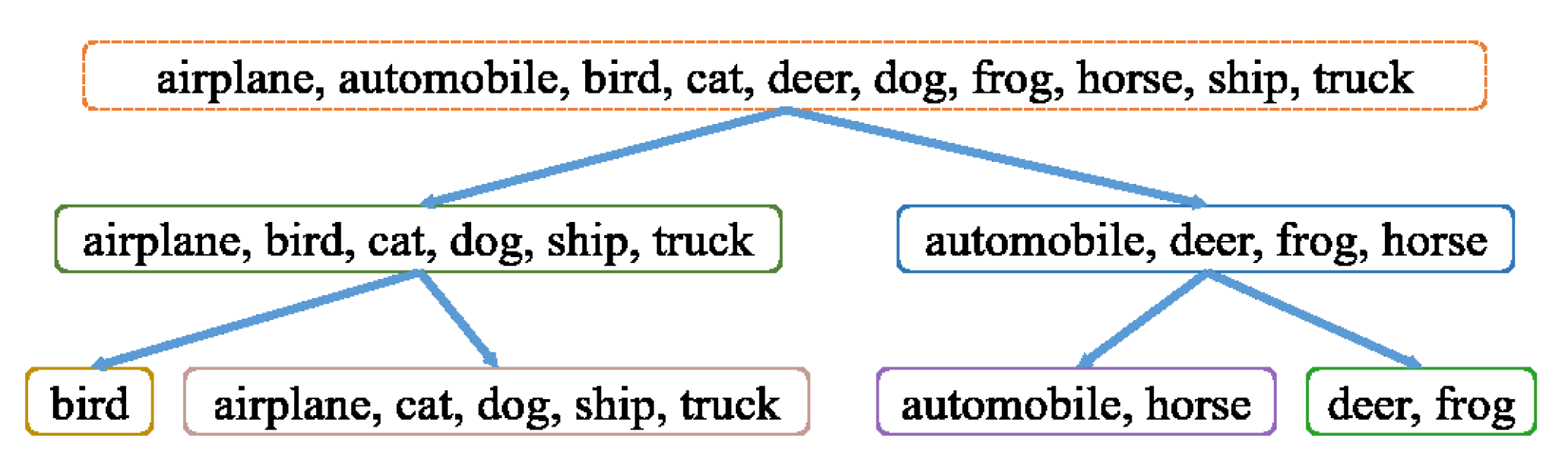
2.2.1. Disjoint Group Assignment
2.2.2. Orthogonal Property
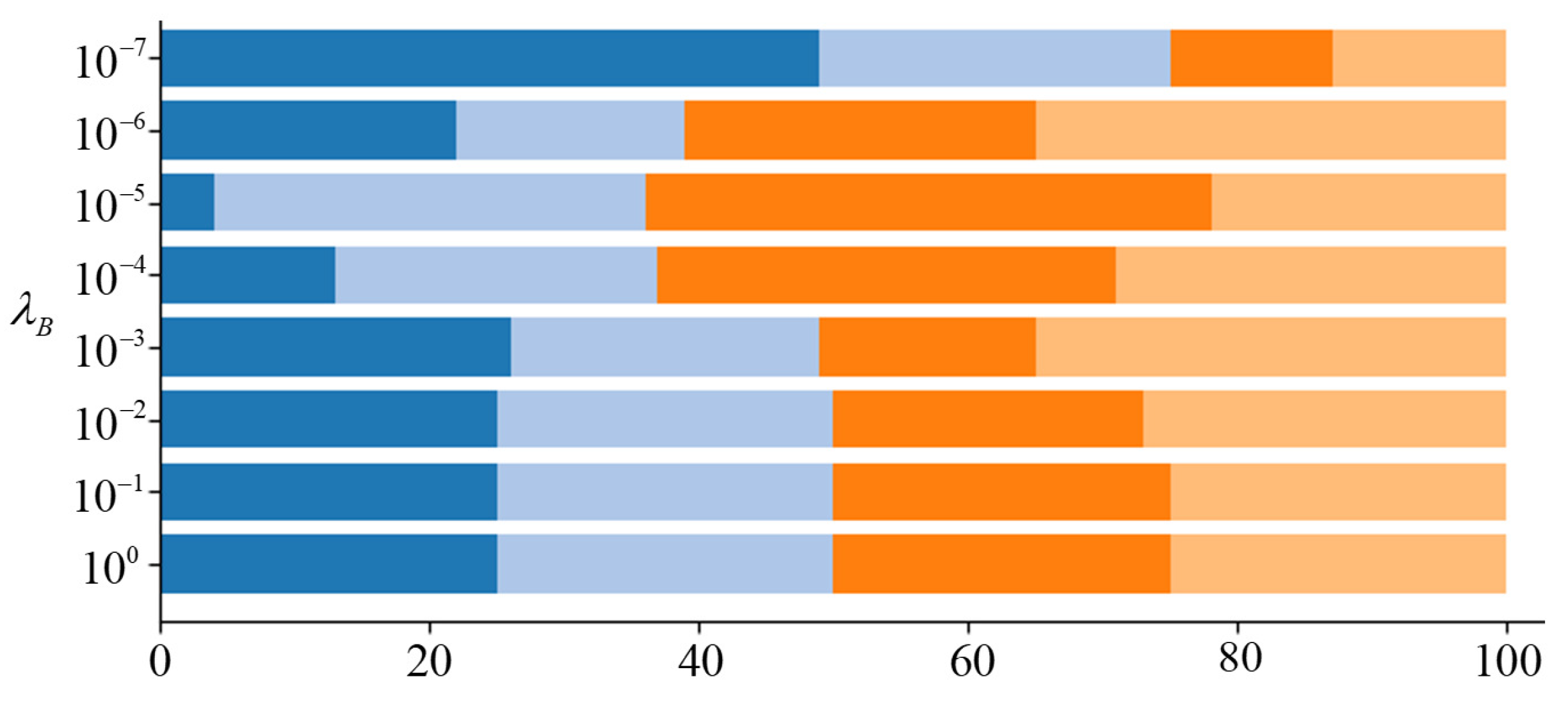
2.2.3. Group Balance
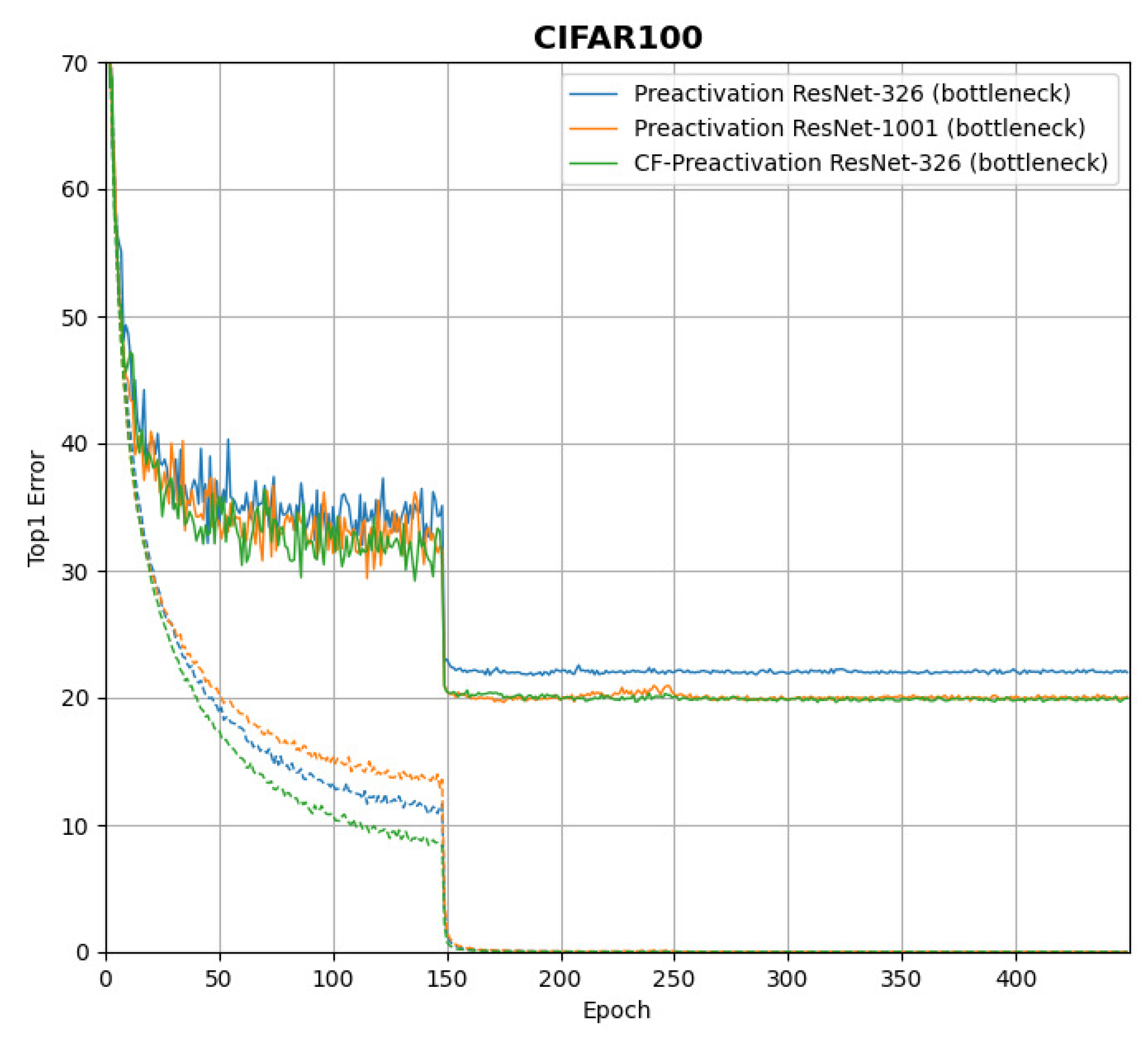
3. Experimental Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. Decaf: A deep convolutional activation feature for generic visual recognition. In Proceedings of the 31st International Conference on Machine Learning (ICML), Beijing, China, 21–26 June 2014; pp. 647–655. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 3431–3440. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks. In Proceedings of the 2nd International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Chen, X.; Yang, Y.; Wang, S.; Wu, H.; Tang, J.; Zhao, J.; Wang, Z. Ship type recognition via a coarse-to-fine cascaded convolution neural network. J. Navig. 2020, 73, 813–832. [Google Scholar] [CrossRef]
- Khan, M.A.; Kim, J. Toward Developing Efficient Conv-AE-Based Intrusion Detection System Using Heterogeneous Dataset. Electronics 2020, 9, 1771. [Google Scholar] [CrossRef]
- Wu, Z.; Shi, G.; Chen, Y.; Shi, F.; Xinjian, C.; Coatrieux, G.; Yang, J.; Luo, L.; Li, S. Coarse-to-Fine Classification for Diabetic Retinopathy Grading using Convolutional Neural Network. Artif. Intell. Med. 2020, 108, 101936. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 630–645. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. In Proceedings of the British Machine Vision Conference (BMVC), York, UK, 19–22 September 2016. [Google Scholar]
- Han, D.; Kim, J.; Kim, J. Deep Pyramidal Residual Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6307–6315. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning Long-Term Dependencies with Gradient Descent is Difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Glorot, X.; Bengio, Y. Understanding The Difficulty of Training Deep Feedforward Neural Networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics (AISTATS), Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Yan, Z.; Zhang, H.; Piramuthu, R.; Jagadeesh, V.; DeCoste, D.; Di, W.; Yu, Y. HD-CNN: Hierarchical Deep Convolutional Neural Networks for Large Scale Visual Recognition. In Proceedings of the IEEE International Conference on Computer Vision 2015, Santiago, Chile, 7–13 December 2015; pp. 2740–2748. [Google Scholar]
- Zhu, X.; Bain, M. B-CNN: Branch Convolutional Neural Network for Hierarchical Classification. arXiv 2017, arXiv:1709.09890. [Google Scholar]
- Verma, M.; Kumawat, S.; Nakashima, Y.; Raman, S. Yoga-82: A New Dataset for Fine-Grained Classification of Human Poses. In Proceedings of the IEEE/CVF CVPR Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1038–1039. [Google Scholar]
- Kim, J.; Park, Y.; Kim, G.; Hwang, S.J. SplitNet: Learning to Semantically Split Deep Networks for Parameter Reduction and Model Parallelization. In Proceedings of the 34th International Conference on Machine Learning (ICML), Sydney, NSW, Australia, 6–11 August 2017; pp. 1866–1874. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009; Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.222.9220 (accessed on 20 April 2021).
- Roy, D.; Panda, P.; Roy, K. Tree-CNN: A Hierarchical Deep Convolutional Neural Network for Incremental Learning. Neural Netw. 2020, 121, 148–160. [Google Scholar] [CrossRef] [PubMed]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Gan, W.; Yang, J.; Wu, W.; Yan, J. Dynamic Curriculum Learning for Imbalanced Data Classification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 5016–5025. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning Augmentation Strategies from Data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 113–123. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical Automated Data Augmentation with a reduced Search Space. In Proceedings of the IEEE/CVF CVPR Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 3008–3017. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CF-VGG-16 | ||||||
|---|---|---|---|---|---|---|
| Layer Name | Output Size | Block Structure | Block Numbers | |||
| Baseline | Main | Coarse1 | Coarse2 | |||
| Conv1 | , 64 , 64 | 1 | 1 | |||
| Maxpool | 1 | 1 | ||||
| Conv2 | , 128 , 128 | 1 | 1 | |||
| Maxpool | 1 | 1 | ||||
| Conv3 | , 256 , 256 , 256 | 1 | 1 | |||
| Maxpool | 1 | 1 | ||||
| Conv4 | , 512 , 512 , 512 | 1 | 1 | 1 | ||
| Maxpool | 1 | 1 | 1 | |||
| Conv5 | , 512 , 512 , 512 | 1 | 1 | 1 | 1 | |
| Refine layer | , 512 , 512 , 512 | 1 | ||||
| fc1 | 4096 | 1 | 1 | |||
| fc2 | 4096 | 1 | 1 | 1 | 1 | |
| fc3 | Classes number | 1 | 1 | 1 | 1 | |
| CF-ResNet | ||||||
|---|---|---|---|---|---|---|
| Layer Name | Output Size | Block Structure | Block Numbers 164-Layer (326-Layer) | |||
| Baseline | Main | Coarse1 | Coarse2 | |||
| Conv1 | , 16 | 1 (1) | 1 (1) | |||
| Conv2 | , 16 , 16 , 64 | 18 (36) | 18 (36) | |||
| Conv3 | , 32 , 32 , 128 | 18 (36) | 18 (36) | 6 (6) | ||
| Conv4 | , 64 , 64 , 256 | 18 (36) | 18 (36) | 6 (6) | 6 (6) | |
| Refine layer | , 64 , 64 , 256 | 2 (2) | ||||
| Average pooling | 1 (1) | 1 (1) | 1 (1) | 1 (1) | ||
| fc | Classes number | 1 (1) | 1 (1) | 1 (1) | 1 (1) | |
| CF-Pre-ResNet | ||||||
|---|---|---|---|---|---|---|
| Layer Name | Output Size | Block Structure | Block Numbers 326-Layer (1001-Layer) | |||
| Baseline | Main | Coarse1 | Coarse2 | |||
| Conv1 | , 16 | 1 (1) | 1 (1) | |||
| Conv2 | , 16 , 16 , 64 | 36 (111) | 36 (111) | |||
| Conv3 | , 32 , 32 , 128 | 36 (111) | 36 (111) | 6 (6) | ||
| Conv4 | , 64 , 64 , 256 | 36 (111) | 36 (111) | 6 (6) | 6 (6) | |
| Refine layer | , 64 , 64 , 256 | 2 (2) | ||||
| Average pooling | 1 (1) | 1 (1) | 1 (1) | 1 (1) | ||
| fc | Classes number | 1 (1) | 1 (1) | 1 (1) | 1 (1) | |
| CF-Wide-ResNet-28layer | ||||||
|---|---|---|---|---|---|---|
| Layer Name | Output Size | Block Structure | Block Numbers () | |||
| Baseline | Main | Coarse1 | Coarse2 | |||
| Conv1 | , 16 | 1 (1) | 1 (1) | |||
| Conv2 | , 16 × k , 16 × k | 4 (4) | 4 (4) | |||
| Conv3 | , 16 × k , 16 × k | 4 (4) | 4 (4) | 1 (1) | ||
| Conv4 | , 16 × k , 16 × k | 4 (4) | 4 (4) | 1 (1) | 2 (2) | |
| Refine layer | , 16 × k , 16 × k | 1 (1) | ||||
| Average pooling | , 16 × k , 16 × k | 1 (1) | 1 (1) | 1 (1) | 1 (1) | |
| fc | Classes number | 1 (1) | 1 (1) | 1 (1) | 1 (1) | |
| CF-PyramidNet | ||||||
|---|---|---|---|---|---|---|
| Layer Name | Output Size | Block Structure | Block Numbers 110-Layer (200-Layer) | |||
| Baseline | Main | Coarse1 | Coarse2 | |||
| Conv1 | , 16 | 1 (1) | 1 (1) | |||
| Conv2 | , , , | 12 (30) | 12 (30) | |||
| Conv3 | , , , | 12 (30) | 12 (30) | 6 (6) | ||
| Conv4 | , , , | 12 (30) | 12 (30) | 6 (6) | 6 (6) | |
| Refine layer | , , , | 2 (2) | ||||
| Average pooling | 1 (1) | 1 (1) | 1 (1) | 1 (1) | ||
| fc | Classes number | 1 (1) | 1 (1) | 1 (1) | 1 (1) | |
| CF-ResNet and CF-Pre-ResNet | ||||||
|---|---|---|---|---|---|---|
| Layer Name | Output Size | Block Structure | Block Numbers 152-Layer | |||
| Baseline | Main | Coarse1 | Coarse2 | |||
| Conv1 | , 64 | 1 | 1 | |||
| Average pooling | 1 | 1 | ||||
| Conv2 | , 64 , 64 , 256 | 3 | 3 | |||
| Conv3 | , 128 , 128 , 512 | 8 | 8 | 4 | ||
| Conv4 | , 256 , 256 , 1024 | 36 | 36 | 6 | 6 | |
| Conv5 | , 512 , 512 , 2048 | 3 | 3 | 3 | 3 | |
| Refine layer | , 512 , 512 , 2048 | 2 | ||||
| Average pooling | 1 | 1 | 1 | 1 | ||
| fc | Classes number | 1 | 1 | 1 | 1 | |
| CF-PyramidNet | ||||||
|---|---|---|---|---|---|---|
| Layer Name | Output Size | Block Structure | Block Numbers 200-Layer | |||
| Baseline | Main | Coarse1 | Coarse2 | |||
| Conv1 | , 64 | 1 | 1 | |||
| Average pooling | 1 | 1 | ||||
| Conv2 | , , , | 3 | 3 | |||
| Conv3 | , , , | 24 | 24 | 4 | ||
| Conv4 | , , , | 36 | 36 | 6 | 6 | |
| Conv5 | , , , | 3 | 3 | 3 | 3 | |
| Refine layer | , , , | 2 | ||||
| Average pooling | 1 | 1 | 1 | 1 | ||
| fc | Classes number | 1 | 1 | 1 | 1 | |
| Network Model | Number of Labels | Accuracy |
|---|---|---|
| Resnet-326 (baseline) | 100 | 75.05 |
| CF-Resnet-326 (M) | 8, 20, 100 | 76.04 |
| CF-Resnet-326 (R) | 5, 25, 100 | 76.14 |
| CF-Resnet-326 (C) | 5, 25, 100 | 76.38 |
| CF-Resnet-326 (Proposed) | 5, 25, 100 | 76.85 |
| CIFAR-100 | ||
|---|---|---|
| Network Model | Number of Labels | Accuracy |
| HD-CNN | 9, 100 | 65.64 |
| B-CNN | 8, 20, 100 | 64.42 |
| VGG-16 | 100 | 63.04 |
| WideResnet-16 (k = 8) | 100 | 75.74 |
| SplitNet | 100 | 76.04 |
| ResNet-164 | 100 | 74.84 |
| ResNet-326 | 100 | 75.05 |
| Pre-ResNet-326 | 100 | 78.02 |
| Pre-ResNet-1001 | 100 | 80.36 |
| WideResnet-28 (k = 10) | 100 | 80.75 |
| WideResnet-28 (k = 12) | 100 | 81.48 |
| PyramidNet-110 ( = 200) | 100 | 81.98 |
| PyramidNet-272 ( = 200) | 100 | 84.36 |
| CF-VGG-16 | 5, 25, 100 | 65.11 |
| CF-ResNet-164 | 5, 25, 100 | 77.01 |
| CF-ResNet-326 | 5, 25, 100 | 76.85 |
| CF-Pre-ResNet-326 | 5, 25, 100 | 80.77 |
| CF-Pre-ResNet-1001 | 5, 25, 100 | 82.09 |
| CF-WideResnet-28 (k = 10) | 5, 25, 100 | 82.38 |
| CF-WideResnet-28 (k = 12) | 5, 25, 100 | 82.67 |
| CF-PyramidNet-110 ( = 200) | 5, 25, 100 | 82.57 |
| CF-PyramidNet-272 ( = 200) | 5, 25, 100 | 84.94 |
| CIFAR-10 | ||
|---|---|---|
| Network Model | Number of Labels | Accuracy |
| HD-CNN | − | − |
| B-CNN | 2, 7, 10 | 88.22 |
| SplitNet | − | − |
| Pre-ResNet-326 | 10 | 95.87 |
| WideResnet-28 (k = 10) | 10 | 95.83 |
| WideResnet-28 (k = 12) | 10 | 95.67 |
| PyramidNet-272 ( = 200) | 10 | 96.7 |
| CF-Pre-ResNet-326 | 2, 4, 10 | 96.09 |
| CF-WideResnet-28 (k = 10) | 2, 4, 10 | 96.48 |
| CF-WideResnet-28 (k = 12) | 2, 4, 10 | 96.49 |
| CF-PyramidNet-272 ( = 200) | 2, 4, 10 | 96.3 |
| ILSVRC 2012 | ||
|---|---|---|
| Network Model | Number of Labels | Accuracy |
| HD-CNN | 84, 1000 | 76.31 |
| B-CNN | - | - |
| SplitNet | 1000 | 75.1 |
| ResNet-18x2 | 1000 | 74.42 |
| ResNet-152 | 1000 | 77.0 |
| Pre-ResNet-152 | 1000 | 77.8 |
| PyramidNet-200 ( = 300) | 1000 | 79.5 |
| CF-ResNet-152 | 100, 487, 1000 | 78.4 |
| CF-Pre-ResNet-152 | 100, 487, 1000 | 78.7 |
| CF-PyramidNet-200 ( = 300) | 100, 487, 1000 | 80.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.; Kim, H.; Paik, J. CF-CNN: Coarse-to-Fine Convolutional Neural Network. Appl. Sci. 2021, 11, 3722. https://doi.org/10.3390/app11083722
Park J, Kim H, Paik J. CF-CNN: Coarse-to-Fine Convolutional Neural Network. Applied Sciences. 2021; 11(8):3722. https://doi.org/10.3390/app11083722
Chicago/Turabian StylePark, Jinho, Heegwang Kim, and Joonki Paik. 2021. "CF-CNN: Coarse-to-Fine Convolutional Neural Network" Applied Sciences 11, no. 8: 3722. https://doi.org/10.3390/app11083722
APA StylePark, J., Kim, H., & Paik, J. (2021). CF-CNN: Coarse-to-Fine Convolutional Neural Network. Applied Sciences, 11(8), 3722. https://doi.org/10.3390/app11083722