1. Introduction
In the past few years, as deep-learning technology has advanced dramatically, state-of-the-art deep neural network (DNN) models find applications in several fields, ranging from computer vision to natural language processing [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10]. Modern DNNs are based on the convolutional neural network (CNN) structure [
11], such as AlexNet [
12], GoogleNet [
13], VGGNet [
14], the residual network (ResNet) [
15,
16], a densely connected convolutional network (DenseNet) [
17], and EfficientNet [
18], that has achieved increased accuracy by expanding more layers. Therefore, generally, top-performing DNNs have deep and wide neural network architectures with enormous parameters, significantly increasing the training time at high computational costs. Moreover, it is challenging to achieve global or local optimization for a complex DNN with an extended dataset, such as ImageNet data [
19], used for training from scratch. Transfer learning [
20] can be a reasonable candidate to address this limitation. This is because it leverages the knowledge gained from solving a task when applied to other similar tasks. When the wide and deep DNNs are successfully trained, they usually contain a wealth of knowledge within the learning parameters. Therefore, well-known transfer learning based on CNN structures [
21,
22] directly reuses most pre-trained convolutional layers that automatically learn hierarchical feature representations for knowledge formation. Notably, CNN-based transfer learning allows us to quickly and easily build some of the accurate network models by taking advantage of the previous learning without beginning from scratch. In addition, although transfer learning provides a generalized network model with high performance, the training data are insufficient for a new domain. However, notably, the DNN trained from the existing CNN-based transfer learning becomes a complex neural network structure with numerous parameters because it reuses the entire pre-trained convolution-based structure. This complex structure can lead to high memory demands and increased inference time, which is not well suited for applications with limited computing resources, such as the “Internet of Things” (IoT) environment [
23,
24,
25]. Therefore, more efficient knowledge distillation (KD) and knowledge transfer techniques in transfer learning are essentially extended to the application of DNNs for improved accuracy, fast inference time, including training time, and lightweight network structures suitable for restricted computing environments.
To achieve these requirements, in this study, we consider a knowledge transfer framework (KTF)-based training approach using a pre-trained DNN (as the source network model) and target DNN need to be trained using pre-trained knowledge. The concept of the KTF was first introduced in [
26] by minimizing the Kullback–Leibler (KL) divergence of the output distribution between the pre-trained and target network models. Based on [
26], Hinton et al. [
27] proposed KD terminology from the KTF by considering the relaxed output distribution of the pre-trained DNN as distilled knowledge. According to [
27], softening the output layer’s neural response in the pre-trained DNN provided more information to the target DNN during training. Therefore, the main feature of KD can define the best knowledge that represents the useful information of the pre-trained DNN. Research on KD has been further extended by introducing an intermediate representation of the pre-trained DNN [
28] and the flow of the solution procedure (FSP) [
29] for knowledge expression. While Ref. [
28] used the intermediate hidden information in the middle layer of the pre-trained DNN, the flow across two different layers in [
29] was devised to represent the direction between the features of the two layers. Compared with [
28], FSP-based distilled knowledge [
29] provided better performance in classification accuracy over several benchmark datasets. Notably, the aforementioned methods are adopted by the Euclidean distance-based similarity measure to calculate the cost function of transferring distilled knowledge. There have been other studies in terms of knowledge transfer [
30,
31], attempting to transfer knowledge extracted by the pre-trained DNN to other target DNNs using a network structure similar to the generative adversarial network (GAN) [
32,
33]. In their studies, a target DNN was modeled as a generator, and a discriminator tried to distinguish the output results created by the pre-trained DNN from the result provided by the target DNN. The aforementioned knowledge transfer methods adopting the GAN structure experimentally showed that the target DNN using the adversarial optimization-based approach would be better captured into the pre-trained knowledge distributions than the
-norm-based knowledge transfer methods, as mentioned above. Therefore, it is crucial to extract useful knowledge from the pre-trained DNN and efficiently transfer the extracted knowledge to the target DNN.
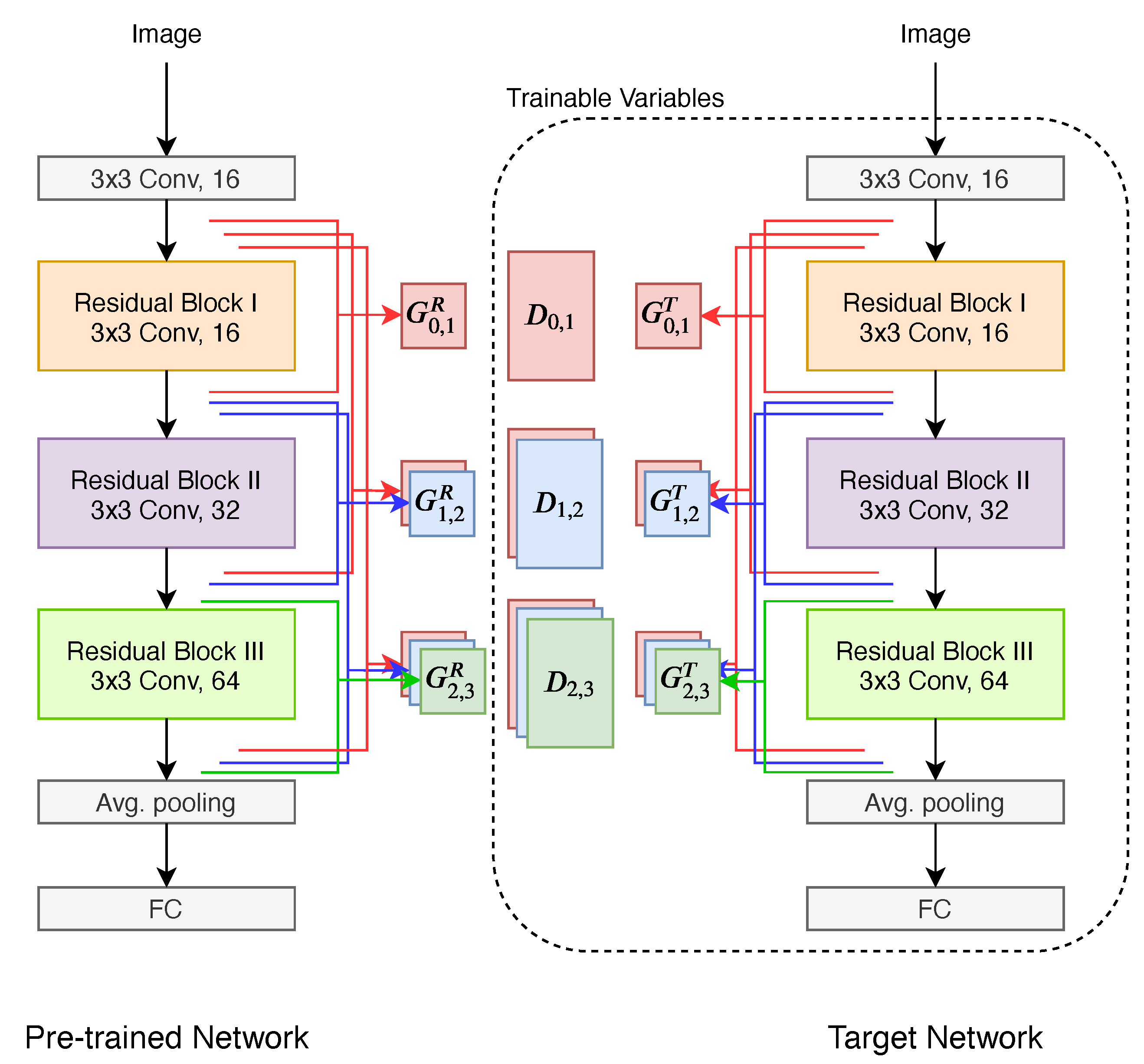
In this study, we propose a layer-wise dense flow (LDF)-based knowledge transfer technique coupled with an adversarial network to generate low complexity DNN models with high accuracy performance that can be adaptively applied to target domains with limited computing resources. First, the proposed method introduces densely overlapped flow using FSP matrices as distilled knowledge of the pre-trained DNN. To rephrase, the multiple-overlapped flow-based knowledge is densely distilled, such that each piece of flow-based knowledge extracted between two different corresponding layers is superimposed. Second, KTF using the adversarial network transfers densely extracted knowledge with layer-wise concurrent training between the pre-trained and target DNNs. In this stage, we designed multiple independent discriminators for adversarial optimization-based knowledge transfer using multiple pairs of dense flows, where each discriminator is assigned to compare a pair of flow-based features between the pre-trained and target DNNs. Owing to the proposed LDF and its concurrent transfer for the adversarial optimization process, the target DNN can efficiently and accurately learn a plethora of information from the pre-trained DNN.
In contrast to previous work on the dense flow-based knowledge transfer [
34], there are major differences between [
34] and the proposed method. First, flow-based knowledge in [
34] is transferred based on
-norm-based training when the dense flow extracted from layers is transferred and trained to another target model. However, knowledge in our study is transferred in the GAN structure-based adversarial optimization manner. Second, the densely extracted flow-based knowledge in [
34] is sequentially transferred step-by-step to a target model, but this study deals with layer-wise concurrent training when transferring the dense flow.
4. Experiments
In this section, we analyze the proposed method using reliable benchmark datasets: CIFAR-10 and CIFAR-100 [
44]. First, for CIFAR-10, we considered adapting a ResNet structure with three residual modules with {16,32,64} filters [
29] for the pre-trained and target DNNs in a KTF. Second, for CIFAR-100, we used a wide ResNet structure with {64,128,256} four times more than those in the CIFAR-10, considering the small number of training images per class. In this experiment, there are six discriminators:
and
. Each discriminator structure is based on multilayer perceptron [
31]. Here, the number of linear units with each discriminator of CIFAR-10 and CIFAR-100 is configured, as shown in
Table 1. When each discriminator structure of
is designed with the number of MLP-based linear units, the number is determined by the spatial size of the corresponding
. For example, in CIFAR-10, sorting by the number of elements constituting the Gramian matrix is as follows:
. Notably, this is because the dimensions of the Gramian matrices are represented as
,
,
, and
. For this reason, we set the number of linear units of the discriminators in the following order:
. Therefore, based on several experiments, the final number of linear units of the discriminators is determined in
Table 1. Similar to CIFAR-10, in CIFAR-100, the number of linear units of the discriminators was set experimentally, as shown in
Table 1, according to the Gramian matrix dimension.
The experimental conditions for the proposed method were as follows: The loss function using (
15) has
and
, as shown in
Table 2.
was used in all experiments, 0.01. Both optimizers for the target ResNet and the discriminator used the same RMSProp optimization algorithm [
45]. In addition, 64,000 iterations were performed, and a batch size of 256 was used when one target ResNet was trained in the KTF. Notably,
and
have an initial learning rate for training each target ResNet and discriminator. In our experiment, both
and
were trained by applying variable learning rates, where the learning rate changed 0.1 times after 32,000 iterations and 0.01 times after 48,000 iterations.
4.1. Dense Flow-Based Knowledge Distribution
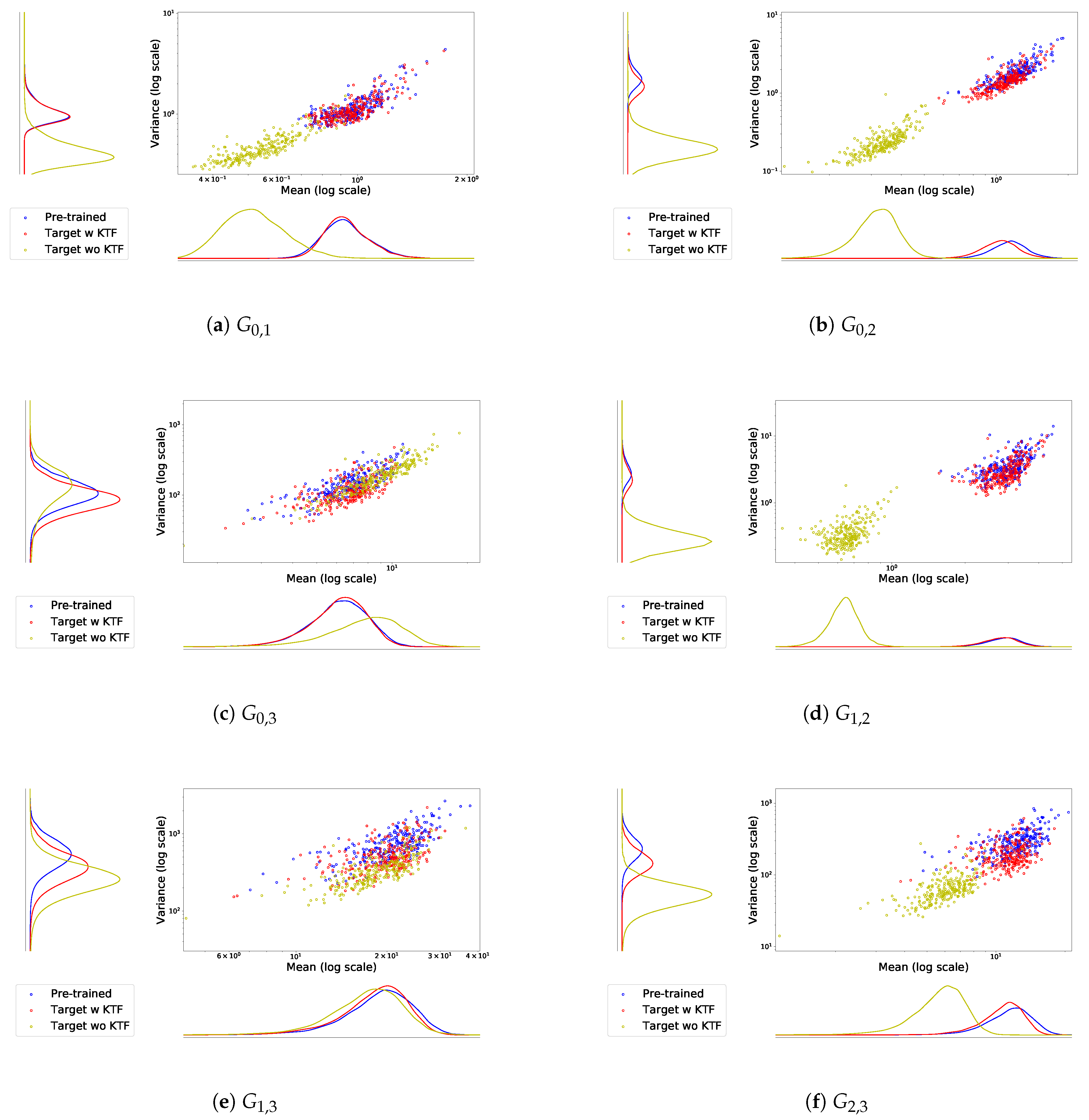
This section discusses the ability of the proposed method for delivering LDF-based distilled knowledge in the KTF. To evaluate how well the target ResNet learned pre-trained knowledge, we used the LDF-based knowledge distribution as a performance metric. In
Figure 3, the proposed method shows that the Gramian matrix distribution results in (i) the pre-trained ResNet to transmit LDF-based knowledge and (ii) the target ResNet to receive the transferred knowledge. In addition, to derive more specific results, we experimented with simple Gramian distributions of the original ResNet without pre-trained knowledge. In
Figure 3, we used CIFAR-100 as the training dataset and adopted a 32-layer ResNet and an 8-layer ResNet, respectively, as the pre-trained and target DNNs in the KTF.
We have observed that all Gramian matrix distributions of the original 8-layer ResNet, which does not take knowledge transfer for the learning process, are significantly different from the distributions of the pre-trained ResNet. However, using the proposed method, the target ResNet can yield distributions with a higher learning performance, and it is largely similar to the pre-trained ResNet. Furthermore, as shown in the distribution table in
Figure 3, the obtained knowledge involved with low-level features has significant training results for the distributed information from the pre-trained ResNet. However, although the distributions between the pre-trained and target ResNets are generally in agreement, the knowledge based on high-level features, such as
, and
, yields slightly lower learning performance, compared to the distributions for
, and
.
4.2. Evaluation of the Proposed Method for Dense Flow
In these experiments, we compare the performance of the proposed adversarial-based method with that of the existing
-norm-based method from a knowledge transfer perspective for the LDF-based distilled knowledge. The related parameters in (
15) and hyper-parameters related to learning rates are given in
Table 2.
For the same pre-trained ResNet,
Table 3 shows the training results based on the CIFAR-10 dataset using a 14-layer target ResNet. In addition,
Table 4 presents the training results with the same dataset using a 20-layer target ResNet to solve a classification problem. In addition,
Table 5 shows the results of using a 32-layer pre-trained and a 14-layer target ResNets for the CIFAR-100 dataset. In
Table 3 through
Table 5, we can observe that the proposed method has better accuracy than the prior
-norm-based methods [
34] that follow both sequential and concurrent training approaches mainly based on a dense flow-based scheme. Here, the sequential training involves repetitive sequential knowledge transfer of dense flow from bottom to top between pre-trained and target DNNs, whereas the concurrent approach involves the simultaneous transmission of dense flow into a target DNN. Furthermore, we compared the relative difference between the performance of the target and pre-trained DNNs owing to the difference in performance between the pre-trained DNN model used in the experiment [
34] and the pre-trained DNN model used in our experiment. The relative difference is calculated as
where
and
denote the accuracies of the pre-trained and target DNNs, respectively. In CIFAR-10, there was no significant difference in classification accuracy performance between the 26-layer pre-trained ResNet adopted in [
34] (
=91.91%) and the pre-trained ResNet used in our experiment (
=91.79%). In contrast, we can observe that the 32-layer pre-trained ResNet in [
34] provides a lower performance for CIFAR-100 than the 32-layer pre-trained ResNet used in our experiment, although the two pre-trained ResNets have the same number of layers. Notably, this is because the pre-trained ResNet model used in [
34] did not adopt any data pre-processing, resulting in
=64.69%. To rephrase, we adopted the pre-trained ResNet with data pre-processing in our experiment [
15], resulting in
=74.70%. According to [
15], we used a random crop of size
after
padding with a pre-processing of random flip, and the same pre-processing method was used for knowledge transfer.
Table 3,
Table 4 and
Table 5 show that the relative difference using the proposed adversarial training can produce better results compared to the previous
-norm-based training experiments [
34]. In addition, it can be observed that more complex and deeper ResNet structures can yield better accuracy in terms of knowledge transfer in the proposed method.
4.3. Comparison of Knowledge Transfer Performance
In addition, as shown in
Table 6 and
Table 7, we compare the results between the existing knowledge transfer methods and the proposed method. In both existing methods, flow-based knowledge was chosen as the distilled knowledge of the pre-trained DNNs. Conversely, the difference between these two techniques is the loss function design used for knowledge transfer in a KTF. In essence, knowledge transfer using
-loss was performed in [
3] to calculate the cost function of the flow-based distilled knowledge. In the previous method [
31], the adversarial loss was used in the cost function to transfer the flow-based knowledge. In contrast to these two methods, we proposed an adversarial-based knowledge transfer method coupled with the layer-wise overlapping dense flow.
The performance shown in
Table 6 and
Table 7 is the average of the three high values extracted from five experiments. The results indicate that both of the existing methods of [
3] and [
31] have better classification accuracy than all original ResNets trained without knowledge transfer approach. However, we can observe that the performance of the obtained target ResNet using the proposed approach outperforms the two methods. As mentioned in
Section 4.2, a deeper and more complex network structure can obtain better performance enhancement.
In
Table 8, the experimental results represent the total number of floating-point operations (FLOPs) required to infer pre-trained and target ResNets. FLOPs ratio (T/R) in
Table 8 represents the ratio between the total number of FLOPs in the target ResNet and that of FLOPs in the pre-trained ResNet. First, the CIFAR-10 results in
Table 6 show that the performance of the pre-trained and target DNNs in the KTF is largely similar to each other when the target DNN is a 14-layer ResNet. However, the number of FLOPs for inference is 50% or less as shown in
Table 8. In addition, the 20-layer target ResNet obtained using the proposed method is superior to the pre-trained 26-layer ResNet, which has more layers and provides improved accuracy compared to the two existing knowledge transfer methods. Subsequently, for CIFAR-100, as shown in
Table 7 and
Table 8, the 14-layer target ResNet performs 1.2% higher than the 32-layer pre-trained ResNet but only 37.6% of inference complexity. In particular, the classification accuracy of the 20-layer ResNet in
Table 7 is 77.32%, which is slightly higher or similar to 77.29% of the 1001-layer ResNet performance [
46].
5. Conclusions
In this study, we proposed an adversarial-based knowledge transfer approach using densely distilled layer-wise flow-based knowledge of a pre-trained deep neural network for image classification tasks. The proposed knowledge transfer framework was composed of a pre-trained ResNet to extract LDF-based knowledge, a given target ResNet to receive extracted knowledge, and densely placed discriminators to transfer adversarial optimization-based knowledge. In particular, to process LDF-based knowledge distilled from the pre-trained ResNet, the proposed framework was implemented by a semi-supervised learning technique using numerous discriminators for adversarial training and true labels for conventional training. In addition, we designed several adversarial-based loss functions suitable for densely distilled flow-based knowledge transfer. Regarding the loss functions, the distance-based loss function using densely generated FSP matrices was considered in the proposed framework to deliver more LDF-based feature information to a target ResNet while maintaining stability through adversarial optimization-based knowledge transfer. According to the devised loss functions and adversarial-based knowledge transfer scheme, the proposed method can concurrently update the numerous discriminators and target ResNet.
To validate the performance of the proposed method in terms of knowledge transfer accuracy, we used reliable benchmark datasets such as CIFAR-10 and CIFAR-100 and considered various ResNet architectures with different numbers of layers for a pre-trained source and target models. For all LDF distributions, the results demonstrated that the proposed approach more accurately transferred pre-trained rich information of dense flow between low-level detailed and high-level abstract knowledge compared to the existing -norm-based approach. Furthermore, the small target ResNet obtained from the proposed layer-wise concurrent training yielded higher accuracy than the existing knowledge transfer methods considered in this study or even the original complex pre-trained ResNet. In future work, we plan to use more complicated CNN-based architectures to further analyze the effect of knowledge distributions so that the parameters of the discriminators can be dynamically optimized in the adversarial learning process for a flow-based feature that has a two-dimensional image shape. We will also apply and analyze knowledge transfer proposed in this study to other DNN models that have a different form from the ResNet in future research.







{kind=link}
{kind=link}
{kind=link}