
An Improved Attention-Based Integrated Deep Neural Network for PM2.5 Concentration Prediction



Abstract
:1. Introduction
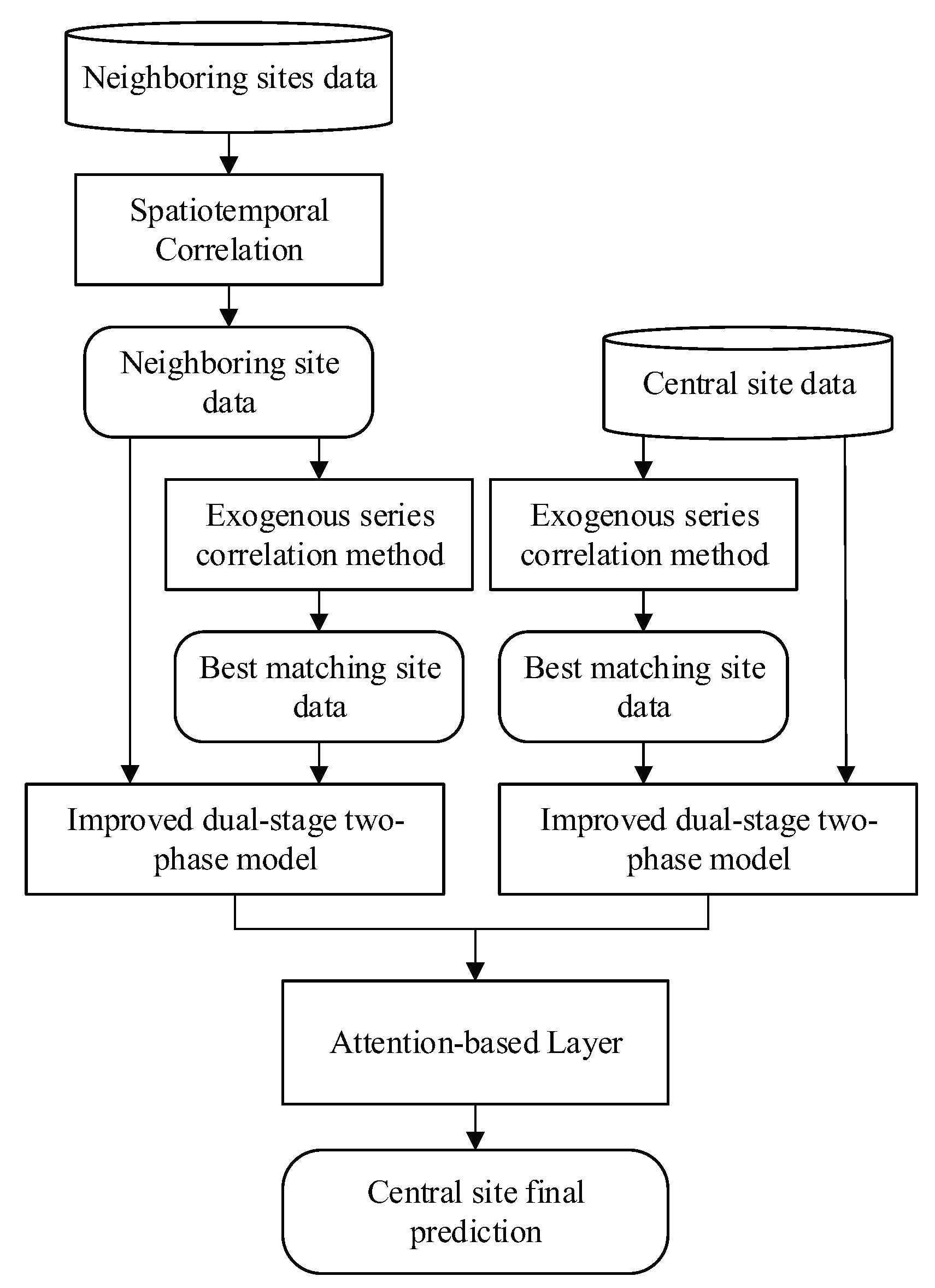
2. Proposed Method
| Algorithm 1 The data flow of the proposed method |
| Input: All sites’ data for current batch, denoted as ; |
| Output: The prediction result of the central site , denoted as S; |
|
| returnS; |
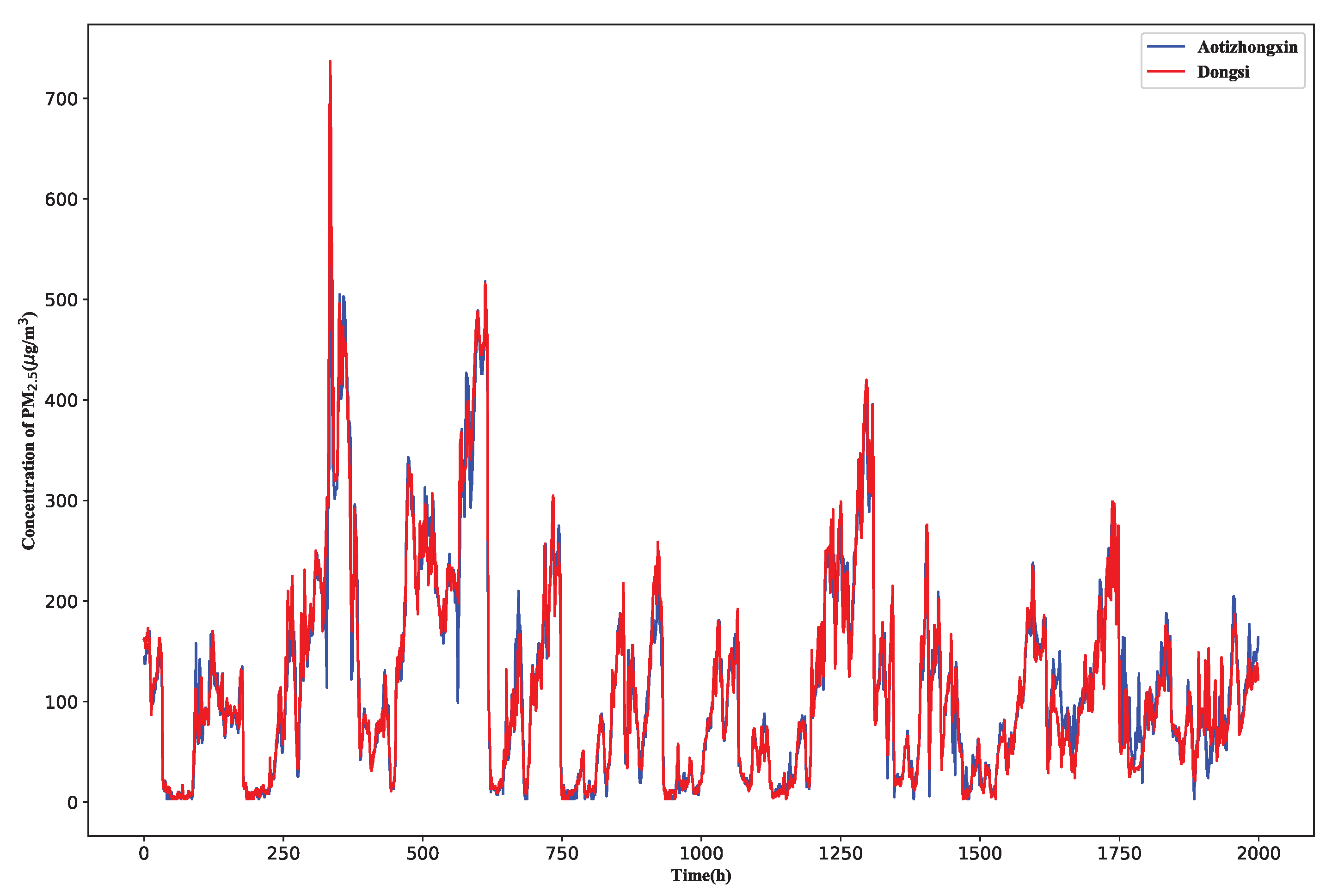
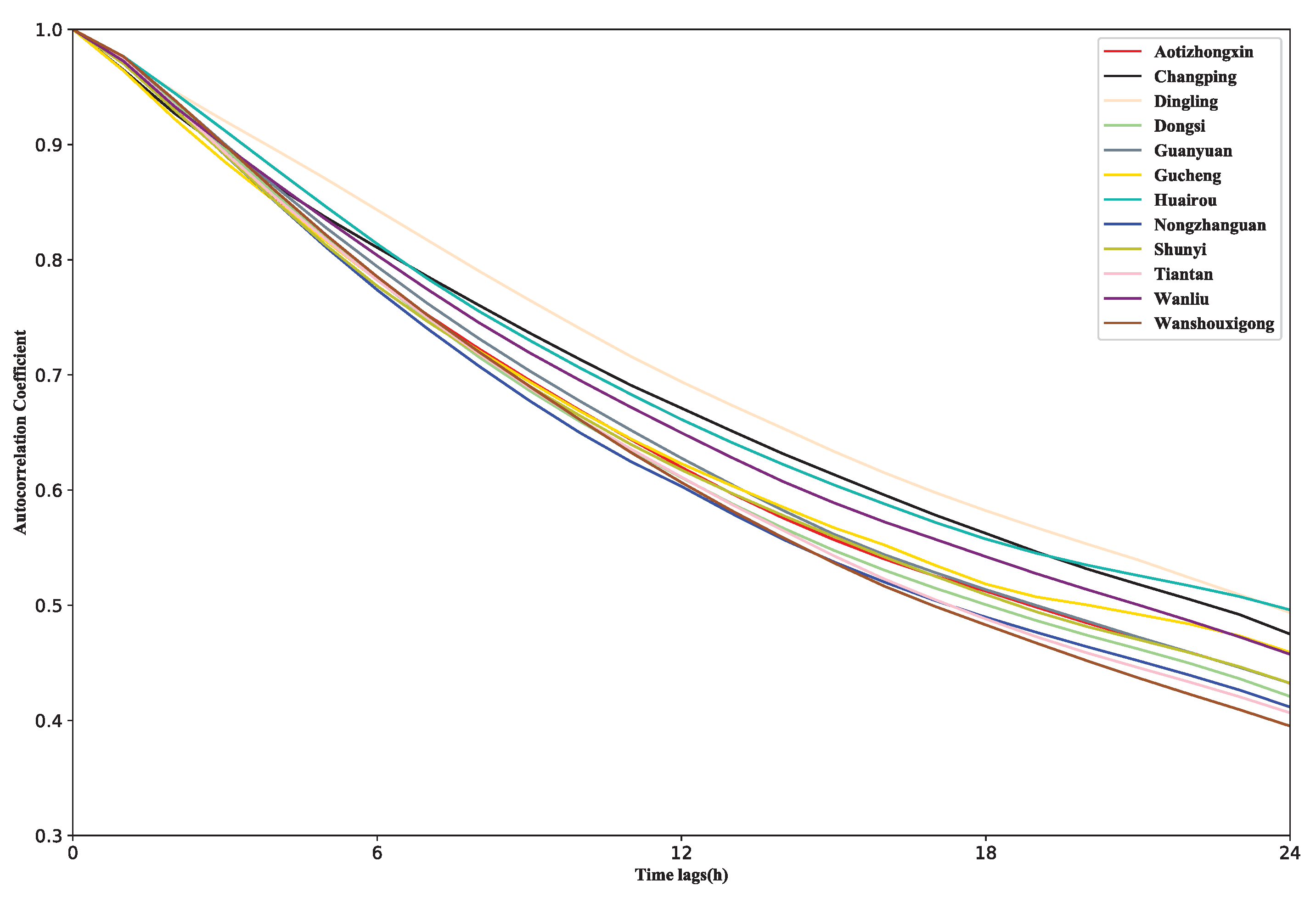
2.1. Spatiotemporal Correlation Analysis
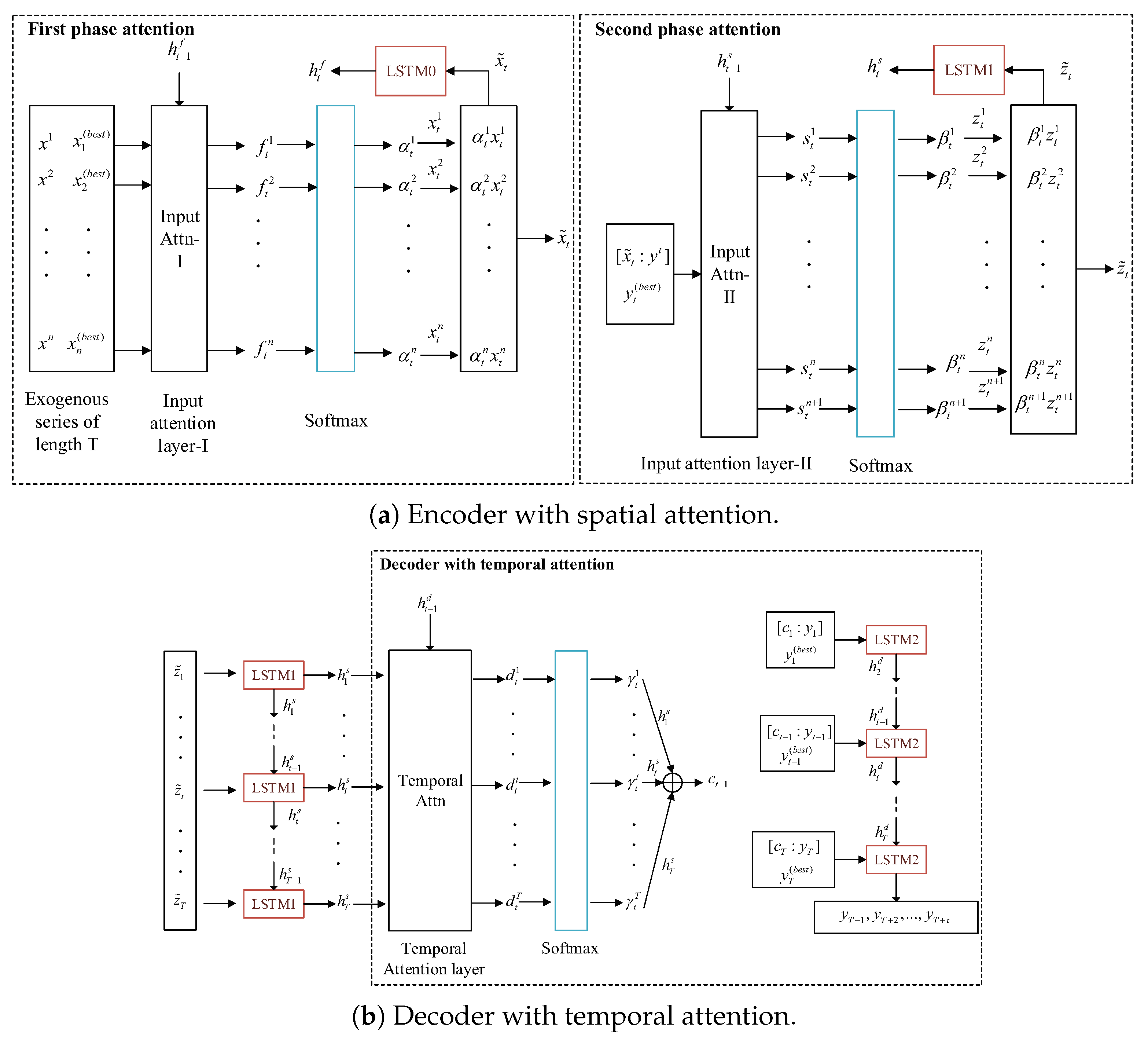
2.2. Improved Dual-Stage Two-Phase Model Based on Attention Mechanism
2.2.1. Notation and Problem Statement
2.2.2. Models
2.3. Attention-Based Layer
3. Experimental Results
3.1. Settings
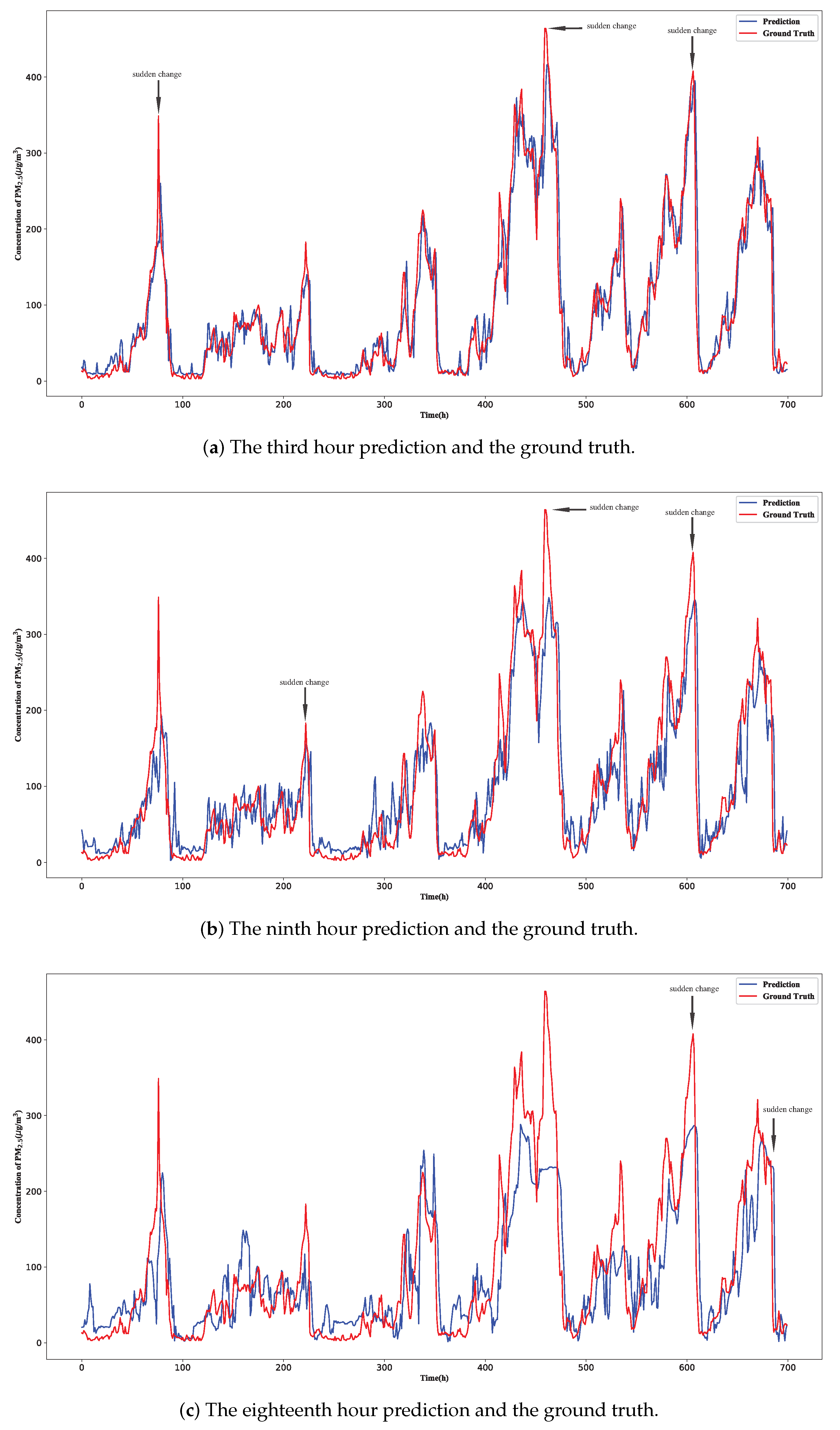
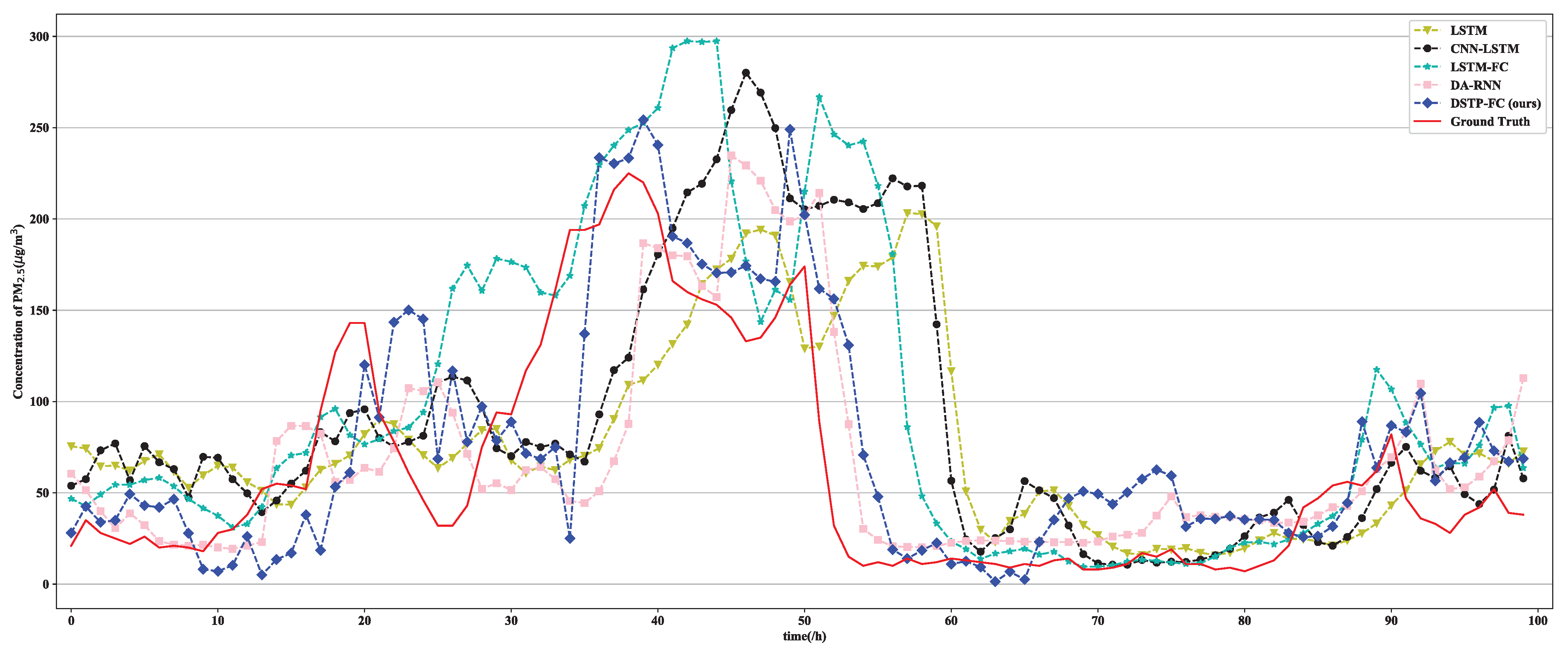
3.2. Models Comparison
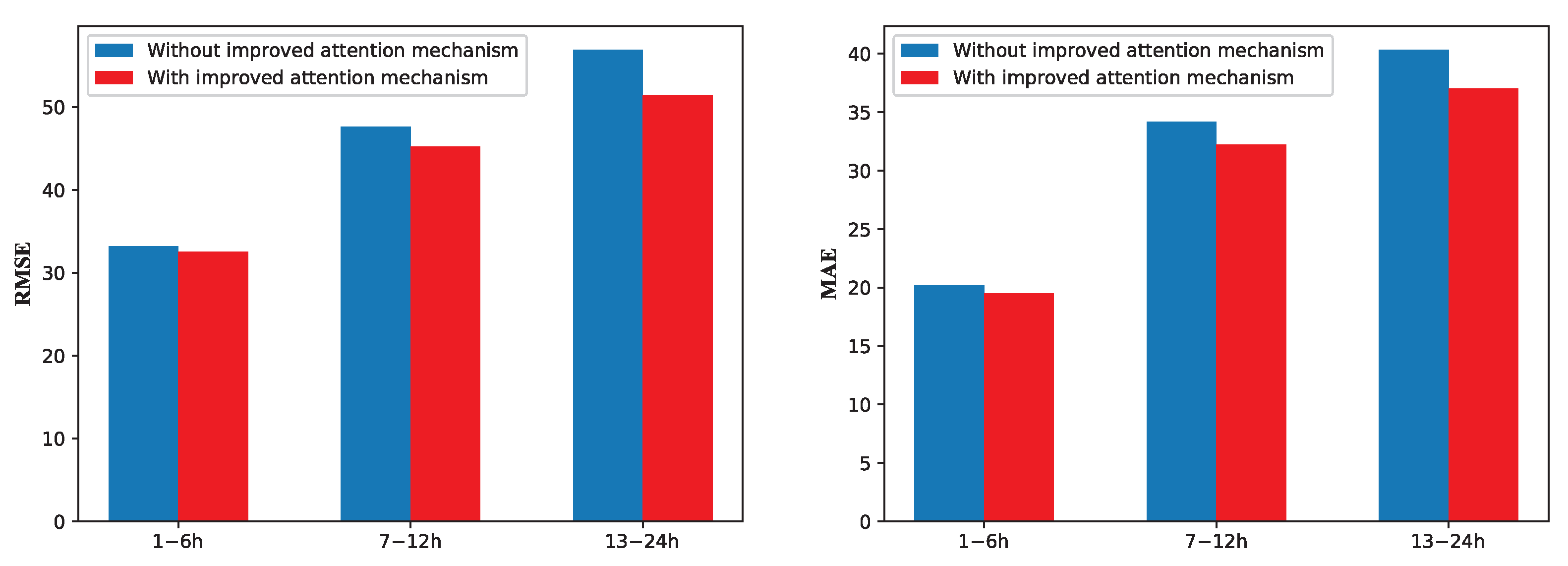
3.3. Ablation Experiment
4. Discussions
4.1. About the Spatio-Temporal Correlation
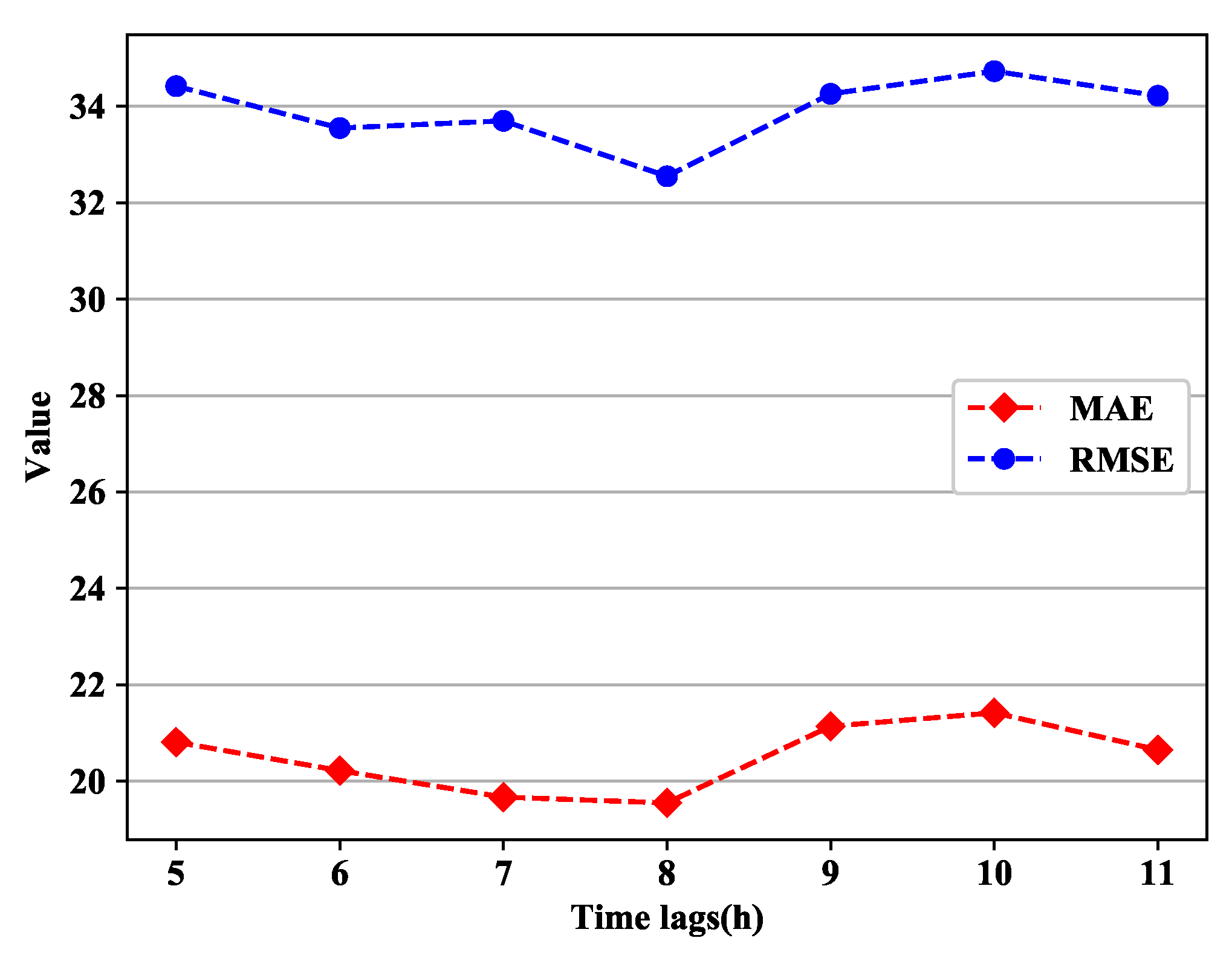
4.2. About the Time Steps
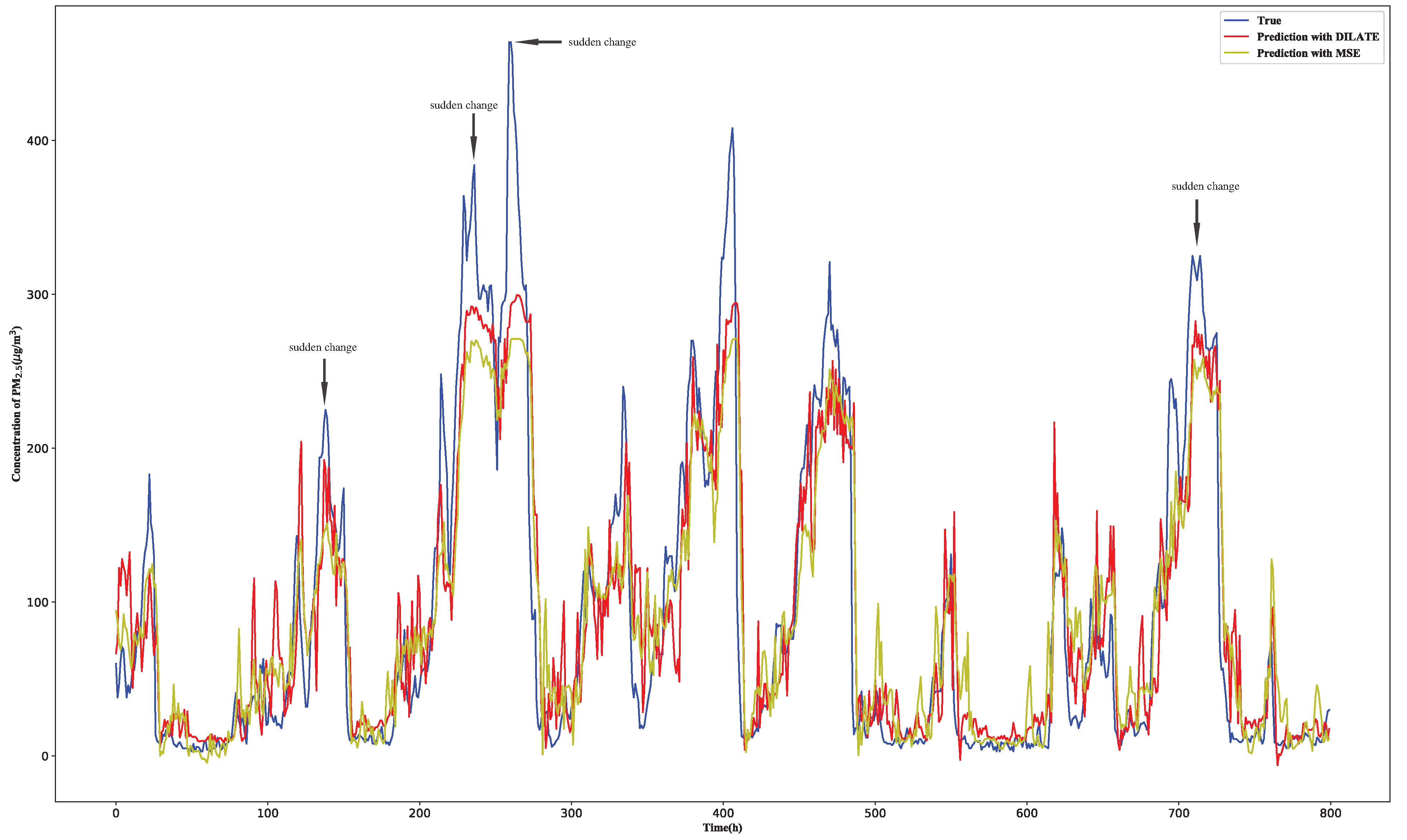
4.3. About the Loss Functions
4.4. About the Cross Validation
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, Z.; Cui, L.; Cui, X.; Li, X.; Yu, K.; Yue, K.; Dai, Z.; Zhou, J.; Jia, G.; Zhang, J. The association between high ambient air pollution exposure and respiratory health of young children: A cross sectional study in Jinan, China. Sci. Total Environ. 2019, 656, 740–749. [Google Scholar] [CrossRef]
- Zhang, C.; Di, L.; Sun, Z.; Lin, L.; Yu, E.; Gaigalas, J. Exploring cloud-based Web Processing Service: A case study on the implementation of CMAQ as a Service. Environ. Model. Softw. 2019, 113, 29–41. [Google Scholar] [CrossRef]
- Mathur, R.; Xing, J.; Gilliam, R.; Sarwar, G.; Hogrefe, C.; Pleim, J.; Pouliot, G.; Roselle, S.; Spero, T.L.; Wong, D.C.; et al. Extending the Community Multiscale Air Quality (CMAQ) Modeling System to Hemispheric Scales: Overview of Process Considerations and Initial Applications. Atmos. Chem. Phys. 2017, 17, 12449–12474. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hsu, C.H.; Cheng, F.Y.; Chang, H.Y.; Lin, N.H. Implementation of a dynamical NH3 emissions parameterization in CMAQ for improving PM2.5 simulation in Taiwan. Atmos. Environ. 2019, 218, 116923. [Google Scholar] [CrossRef]
- Kurt, A.; Oktay, A.B. Forecasting air pollutant indicator levels with geographic models 3 days in advance using neural networks. Expert Syst. Appl. 2010, 37, 7986–7992. [Google Scholar] [CrossRef]
- Wang, Q.; Zeng, Q.; Tao, J.; Sun, L.; Zhang, L.; Gu, T.; Wang, Z.; Chen, L. Estimating PM2.5 Concentrations Based on MODIS AOD and NAQPMS Data over Beijing-Tianjin-Hebei. Sensors 2019, 19, 1207. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.B.; Wang, Z.; Wang, Q.; Li, J.; Xu, J.; Chen, H.; Ge, B.; Zhou, G.; Chang, L. Development of an on-line source-tagged model for sulfate, nitrate and ammonium: A modeling study for highly polluted periods in Shanghai, China. Environ. Pollut. 2017, 221, 168–179. [Google Scholar] [CrossRef]
- Stadlober, E.; Hoermann, S.; Pfeiler, B. Quality and performance of a PM10 daily forecasting model. Atmos. Environ. 2008, 42, 1098–1109. [Google Scholar] [CrossRef]
- Martin, F.; Palomino, I.; Vivanco, M.G. Combination of measured and modelling data in air quality assessment in Spain. Int. J. Environ. Pollut. 2012, 49, 36–44. [Google Scholar] [CrossRef]
- Yuchi, W.; Gombojav, E.; Boldbaatar, B.; Galsuren, J.; Enkhmaa, S.; Beejin, B.; Naidan, G.; Ochir, C.; Legtseg, B.; Byambaa, T.; et al. Evaluation of random forest regression and multiple linear regression for predicting indoor fine particulate matter concentrations in a highly polluted city. Environ. Pollut. 2019, 245, 746–753. [Google Scholar] [CrossRef]
- Vanderschelden, G.; De Foy, B.; Herring, C.; Kaspari, S.; Vanreken, T.; Jobson, B. Contributions of wood smoke and vehicle emissions to ambient concentrations of volatile organic compounds and particulate matter during the Yakima wintertime nitrate study. J. Geophys. Res. Atmos. 2017, 122, 1871–1883. [Google Scholar] [CrossRef]
- Chelani, A.B. Estimating PM2.5 concentration from satellite derived aerosol optical depth and meteorological variables using a combination model. Atmos. Pollut. Res. 2019, 10, 847–857. [Google Scholar] [CrossRef]
- Wen, C.; Liu, S.; Yao, X.; Peng, L.; Li, X.; Hu, Y.; Chi, T. A novel spatiotemporal convolutional long short-term neural network for air pollution prediction. Sci. Total Environ. 2019, 654, 1091–1099. [Google Scholar] [CrossRef]
- Wang, P.; Liu, Y.; Qin, Z.; Zhang, G. A novel hybrid forecasting model for PM10 and SO2 daily concentrations. Sci. Total Environ. 2015, 505, 1202–1212. [Google Scholar] [CrossRef]
- Alimissis, A.; Philippopoulos, K.; Tzanis, C.; Deligiorgi, D. Spatial estimation of urban air pollution with the use of artificial neural network models. Atmos. Environ. 2018, 191, 205–213. [Google Scholar] [CrossRef]
- Zhu, S.; Lian, X.; Liu, H.; Hu, J.; Wang, Y.; Che, J. Daily air quality index forecasting with hybrid models: A case in China. Environ. Pollut. 2017, 231, 1232–1244. [Google Scholar] [CrossRef] [PubMed]
- Yan, R.; Liao, J.; Yang, J.; Sun, W.; Nong, M.; Li, F. Multi-hour and multi-site air quality index forecasting in Beijing using CNN, LSTM, CNN-LSTM, and spatiotemporal clustering. Expert Syst. Appl. 2021, 169, 114513. [Google Scholar] [CrossRef]
- Mao, W.; Wang, W.; Jiao, L.; Zhao, S.; Liu, A. Modeling air quality prediction using a deep learning approach: Method optimization and evaluation. Sustain. Cities Soc. 2021, 65, 102567. [Google Scholar] [CrossRef]
- Kim, M.H.; Kim, Y.S.; Lim, J.J.; Kim, J.T.; Sung, S.W.; Yoo, C.K. Data-driven prediction model of indoor air quality in an underground space. Korean J. Chem. Eng. 2010, 27, 1675–1680. [Google Scholar] [CrossRef]
- Zhao, J.; Deng, F.; Cai, Y.; Chen, J. Long short-term memory—Fully connected (LSTM-FC) neural network for PM2.5 concentration prediction. Chemosphere 2019, 220, 486–492. [Google Scholar] [CrossRef] [PubMed]
- Qin, D.; Yu, J.; Zou, G.; Yong, R.; Zhao, Q.; Zhang, B. A Novel Combined Prediction Scheme Based on CNN and LSTM for Urban PM2.5 Concentration. IEEE Access 2019, 7, 20050–20059. [Google Scholar] [CrossRef]
- Qin, Y.; Song, D.; Chen, H.; Cheng, W.; Cottrell, G.W. A Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Liu, Y.; Gong, C.; Yang, L.; Chen, Y. DSTP-RNN: A dual-stage two-phase attention-based recurrent neural network for long-term and multivariate time series prediction. Expert Syst. Appl. 2020, 143, 113082. [Google Scholar] [CrossRef]
- Guo, H.; Wang, Y.; Zhang, H. Characterization of criteria air pollutants in Beijing during 2014–2015. Environ. Res. 2017, 154, 334–344. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Cheng, J.C.; Lin, C.; Tan, Y.; Zhang, J. Improving air quality prediction accuracy at larger temporal resolutions using deep learning and transfer learning techniques. Atmos. Environ. 2019, 214, 116885. [Google Scholar] [CrossRef]
- Hubner, R.; Steinhauser, M.; Lehle, C. A Dual-Stage Two-Phase Model of Selective Attention. Psychol. Rev. 2010, 117, 759–784. [Google Scholar] [CrossRef] [Green Version]
- Li, T.; Hua, M.; Wu, X. A Hybrid CNN-LSTM Model for Forecasting Particulate Matter (PM2.5). IEEE Access 2020, 8, 26933–26940. [Google Scholar] [CrossRef]
- Le Guen, V.; Thome, N. Shape and Time Distortion Loss for Training Deep Time Series Forecasting Models. In Proceedings of the NeurIPS, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Wang, J.; Song, G. A Deep Spatial-Temporal Ensemble Model for Air Quality Prediction. Neurocomputing 2018, 314, 198–206. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time Methods | 1–6 h | 7–12 h | 13–24 h | |||
|---|---|---|---|---|---|---|
| RMSE | MAE | RMSE | MAE | RMSE | MAE | |
| LSTM | 37.38 | 23.45 | 57.93 | 42.63 | 66.39 | 48.15 |
| CNN-LSTM | 39.37 | 23.87 | 51.37 | 41.93 | 64.03 | 44.82 |
| LSTM-FC | 36.97 | 22.97 | 56.70 | 40.23 | 63.79 | 42.57 |
| DA-RNN | 36.29 | 21.40 | 48.07 | 35.57 | 60.81 | 43.53 |
| DSTP-FC (ours) | 32.51 | 19.50 | 45.22 | 32.22 | 51.45 | 37.04 |
| Time Methods | 1–6 h | 7–12 h | 13–24 h | |||
|---|---|---|---|---|---|---|
| RMSE | MAE | RMSE | MAE | RMSE | MAE | |
| DSTP-FC-MAE | 35.36 | 21.03 | 48.13 | 34.66 | 54.03 | 43.25 |
| DSTP-FC-MSE | 34.55 | 20.42 | 44.17 | 31.93 | 52.79 | 39.46 |
| DSTP-FC-DILATE | 32.51 | 19.50 | 45.22 | 32.22 | 51.45 | 37.04 |
| Time | 1–6 h | 7–12 h | 13–24 h | |||
|---|---|---|---|---|---|---|
| RMSE | MAE | RMSE | MAE | RMSE | MAE | |
| Cross validation | 33.67 | 22.20 | 42.39 | 32.15 | 49.90 | 38.40 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, P.; Fang, X.; Ni, J.; Zhu, J. An Improved Attention-Based Integrated Deep Neural Network for PM2.5 Concentration Prediction. Appl. Sci. 2021, 11, 4001. https://doi.org/10.3390/app11094001
Shi P, Fang X, Ni J, Zhu J. An Improved Attention-Based Integrated Deep Neural Network for PM2.5 Concentration Prediction. Applied Sciences. 2021; 11(9):4001. https://doi.org/10.3390/app11094001
Chicago/Turabian StyleShi, Pengfei, Xiaolong Fang, Jianjun Ni, and Jinxiu Zhu. 2021. "An Improved Attention-Based Integrated Deep Neural Network for PM2.5 Concentration Prediction" Applied Sciences 11, no. 9: 4001. https://doi.org/10.3390/app11094001
APA StyleShi, P., Fang, X., Ni, J., & Zhu, J. (2021). An Improved Attention-Based Integrated Deep Neural Network for PM2.5 Concentration Prediction. Applied Sciences, 11(9), 4001. https://doi.org/10.3390/app11094001