
CloudRCNN: A Framework Based on Deep Neural Networks for Semantic Segmentation of Satellite Cloud Images

Abstract
:1. Introduction
- We propose two designs to improve MaskRCNN according to the characteristics in the satellite cloud images (the clouds and the background can be easily distinguished while different types of clouds have little difference);
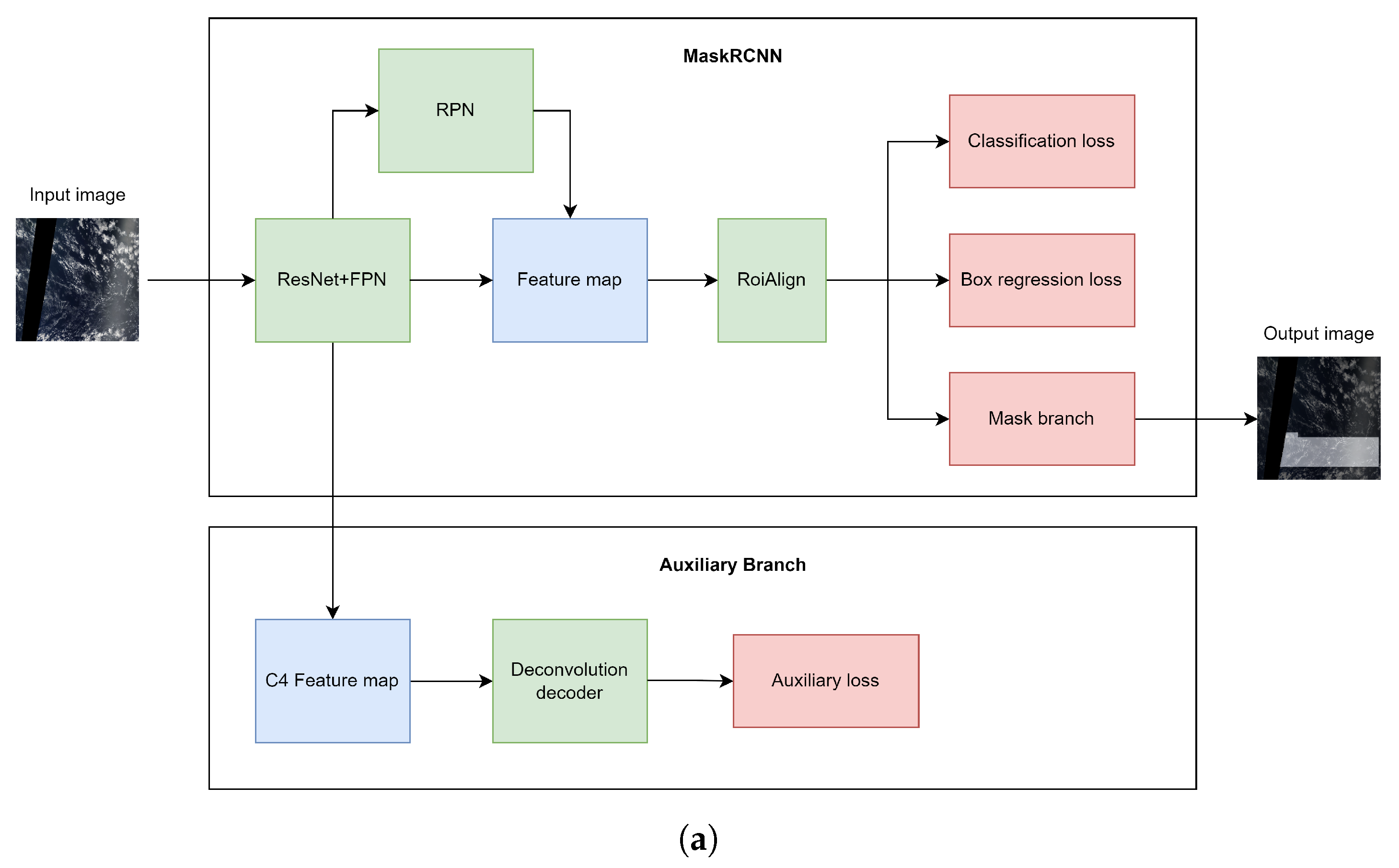
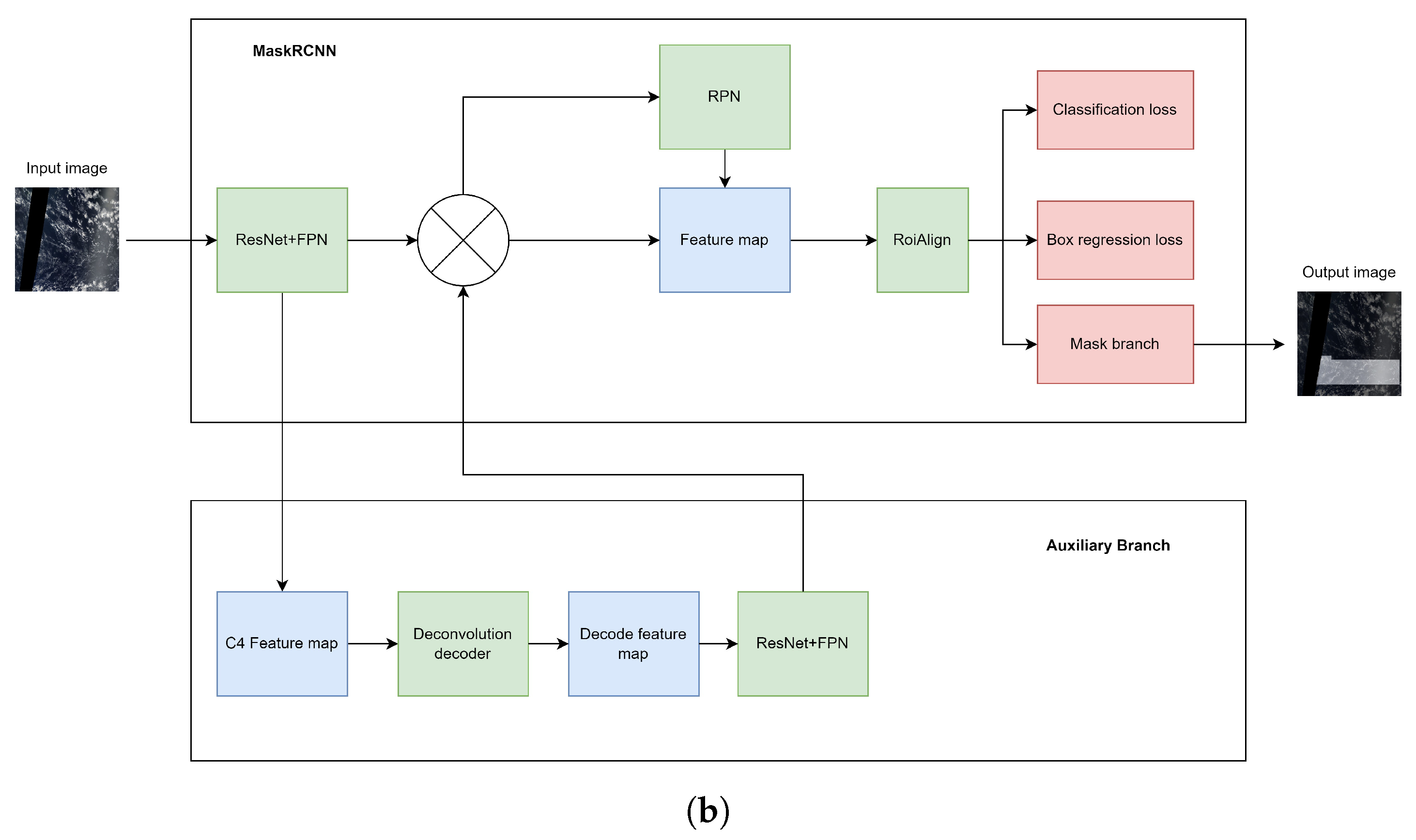
- We explore two branch designs of MaskRCNN, including using auxiliary loss to supervise the foreground and designing a feature fusion module to restore the feature map, so as to judge the feature extraction of the first-stage convolution;
- We design comprehensive experiments on the Kaggle competition dataset called “Understanding Clouds from Satellite Images” to evaluate the performance of our model, which achieves substantial improvements over MaskRCNN.
2. Related Work
2.1. Deep Learning-Based Methods
2.2. Multi-Task and Auxiliary Loss Supervised Semantic Segmentation Models
2.3. Semantic Segmentation Models Based on Feature Fusion Module
2.4. Comparison of Our Model with Existing Models
- Strengths:
- Can generate candidate regions using object detection techniques, is capable of simultaneously performing object detection and image semantic segmentation tasks;
- The ROI (region of interest) align layer is introduced to make the alignment of the feature map and the original image more accurate by bilinear interpolation.
- Weaknesses:
- Insufficient consideration of global semantic information in the image;
- It is easy to make mistakes when detecting small target objects.
- Strengths:
- The ASPP (atrous spatial pyramid pooling) module is introduced to increase the perceptual field of the network and reduce the loss of the feature image size;
- Optimized edge segmentation by using a decoder to refine the segmentation results.
- Weaknesses:
- Large computational volume and slow segmentation speed;
- Less-accurate segmentation of small-scale objects.
- Strengths:
- The introduction of the GAM module can improve the segmentation performance of small targets while imposing boundary constraints;
- The designed compound loss function facilitates model optimization and improves the performance of integrated modules.
- Weaknesses:
- Large computational volume and slow segmentation speed;
- Shaded areas are easily misclassified on the ISPRS dataset.
- Strengths:
- The backbone of MaskRCNN is too long, which is prone to the gradient explosion problem. The auxiliary branch introduced by this model is a good correction of the problem;
- The model performs additional focused segmentation on the subject of the input image, so the model segments the subject’s edges more carefully;
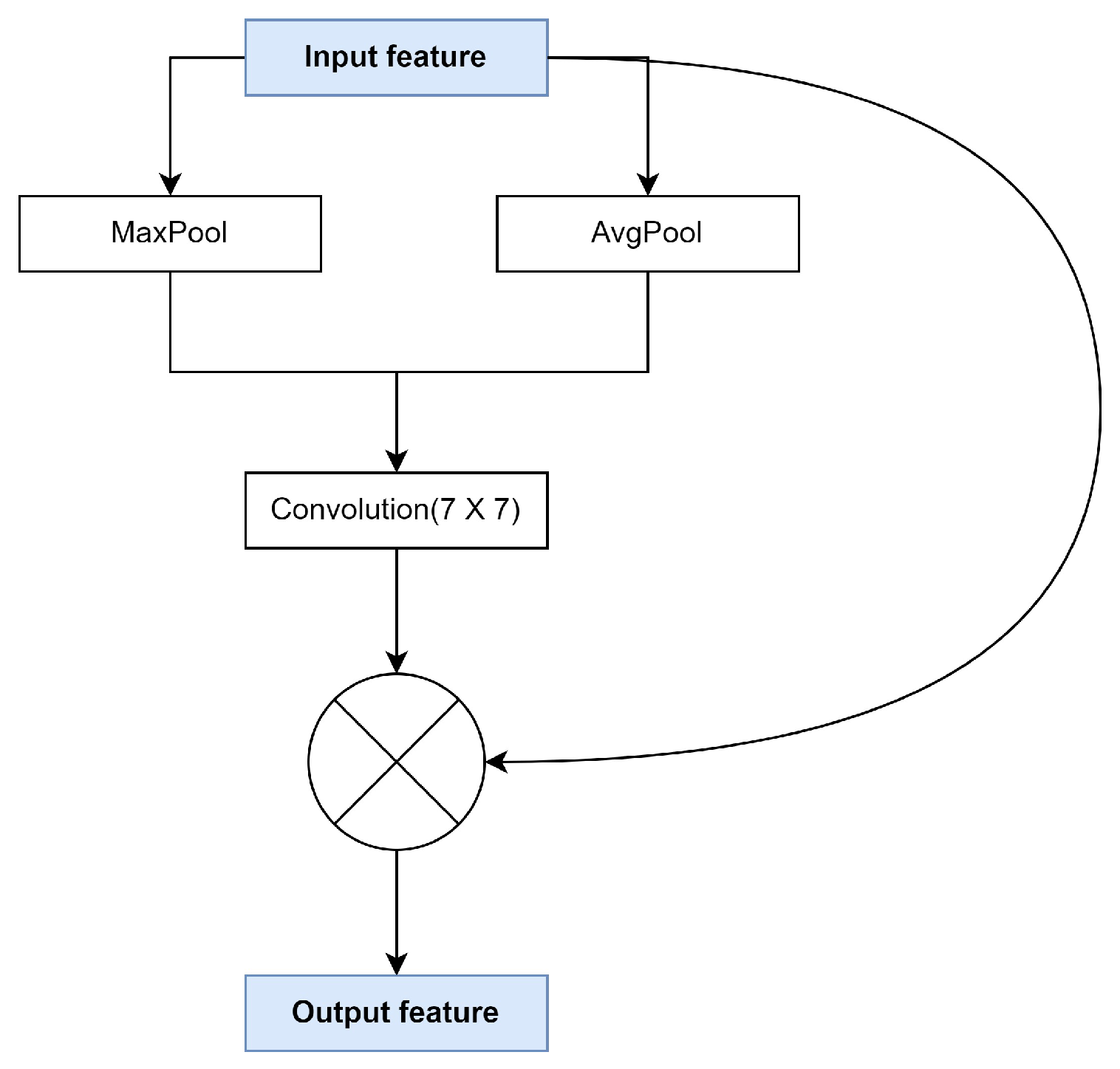
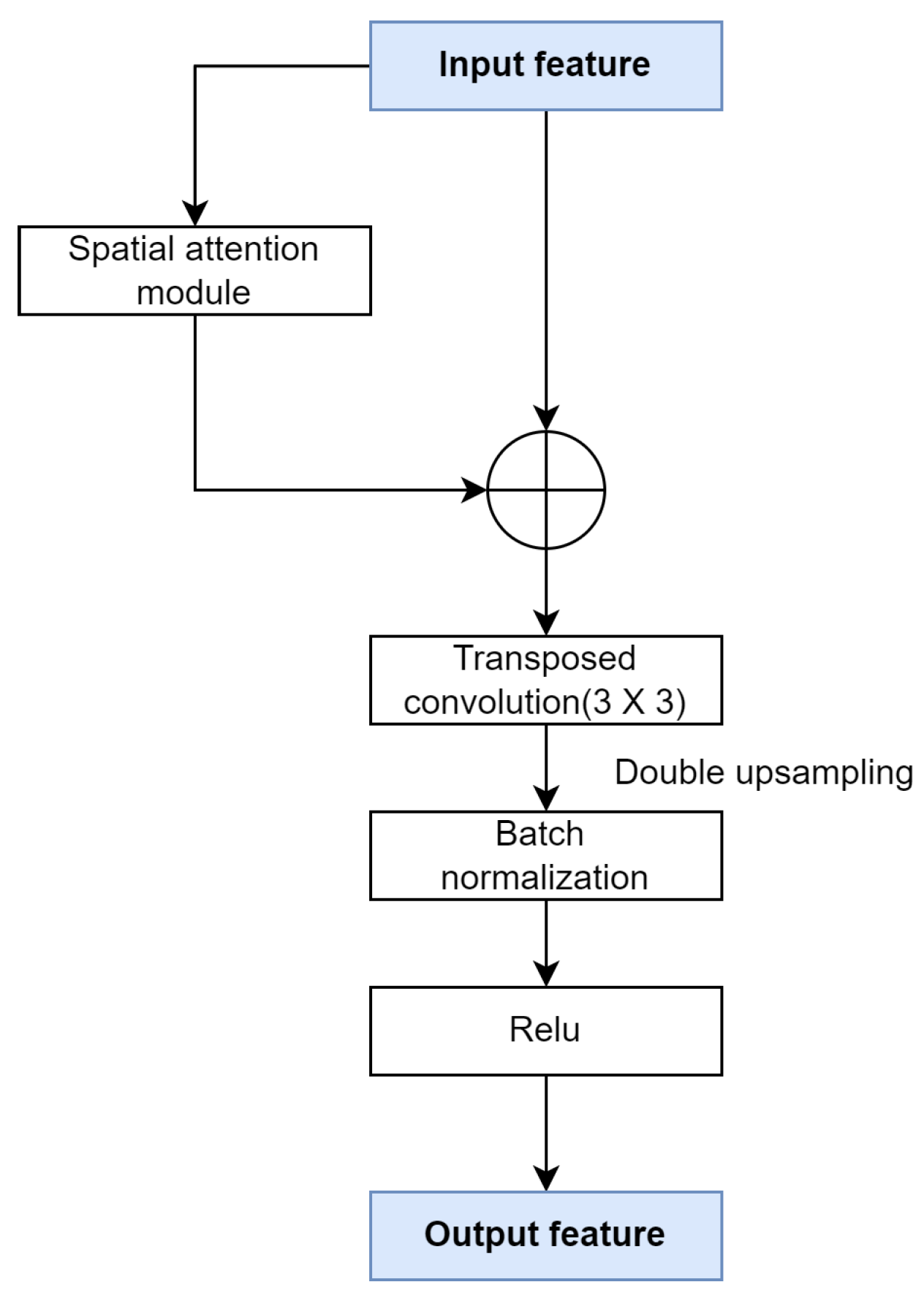
- The introduced spatial attention module refines the boundary information for semantic segmentation.
- Weaknesses:
- The number of pixels in the background is often larger than the segmented subject, and the additional supervision of foreground–background information causes the model to prefer to classify pixels as background.
3. Materials and Methods
3.1. Dataset
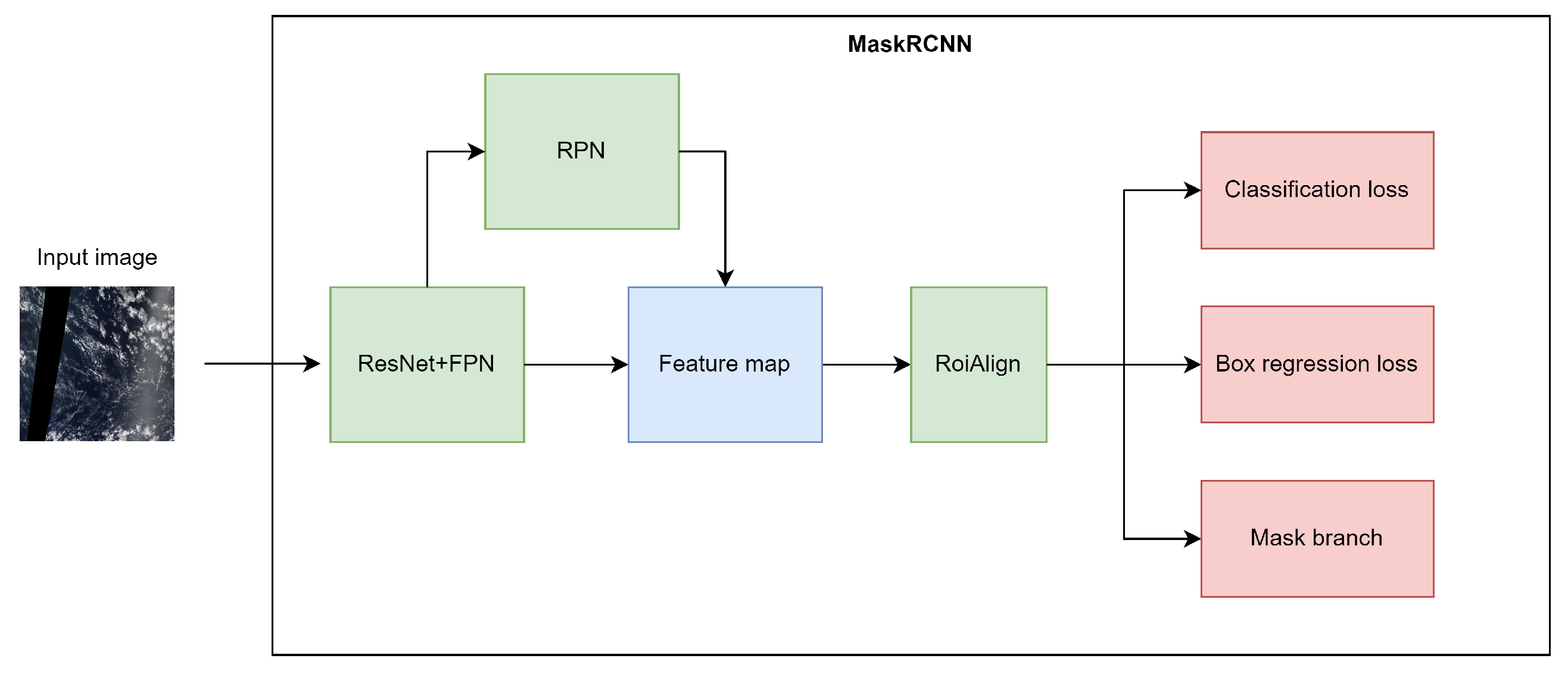
3.2. System Architecture
3.3. Methods
3.3.1. Spatial Attention Module

3.3.2. Spatial Attention Deconvolution Block
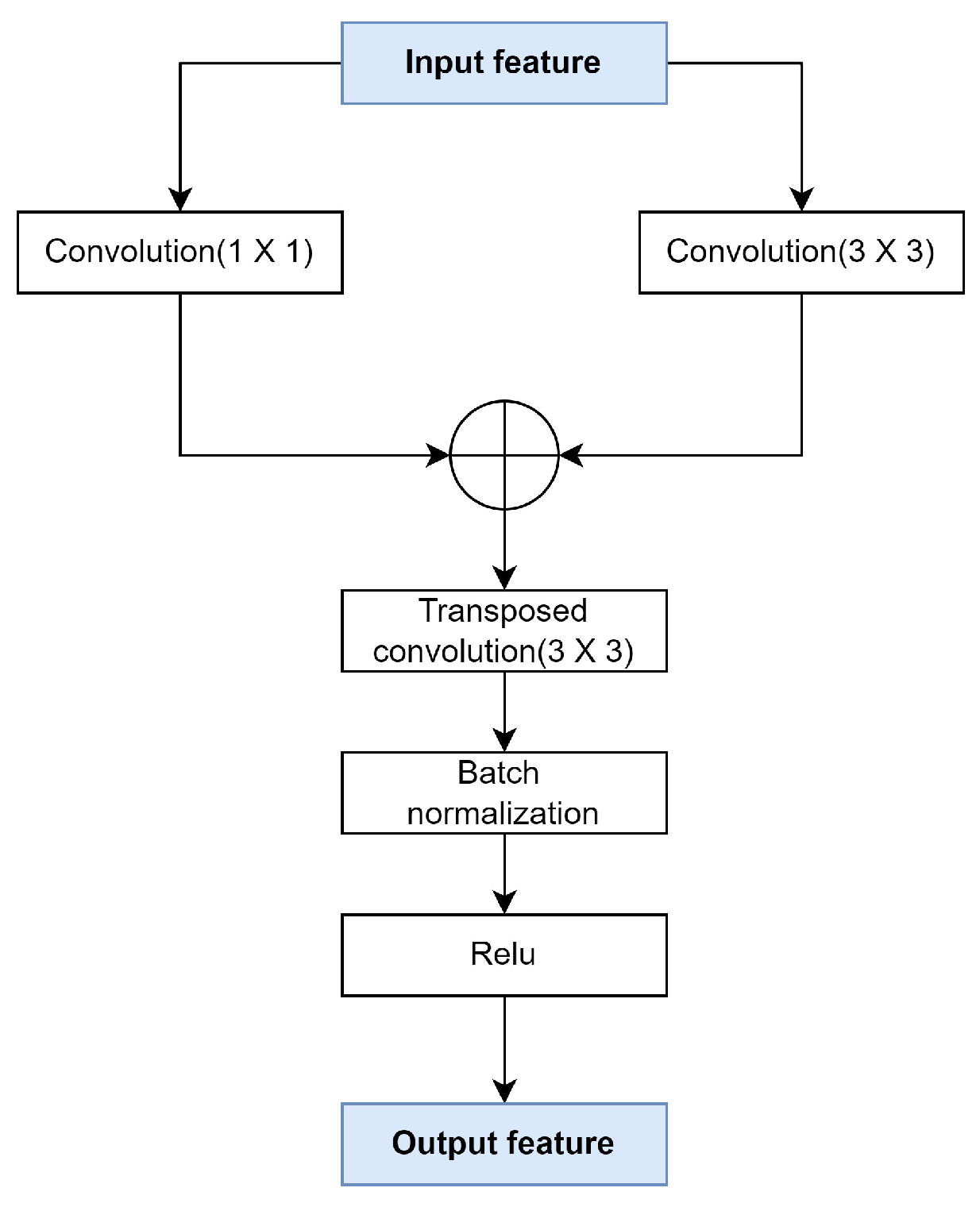
3.3.3. Parallel Convolution Block
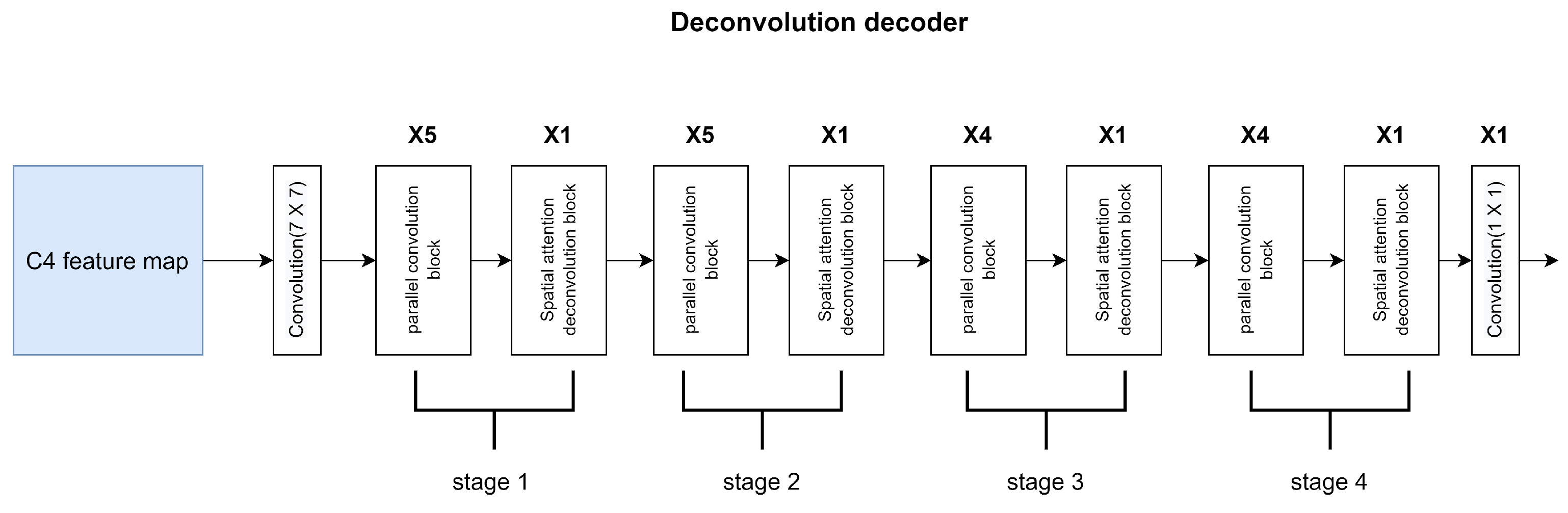
3.3.4. Deconvolution Decoder
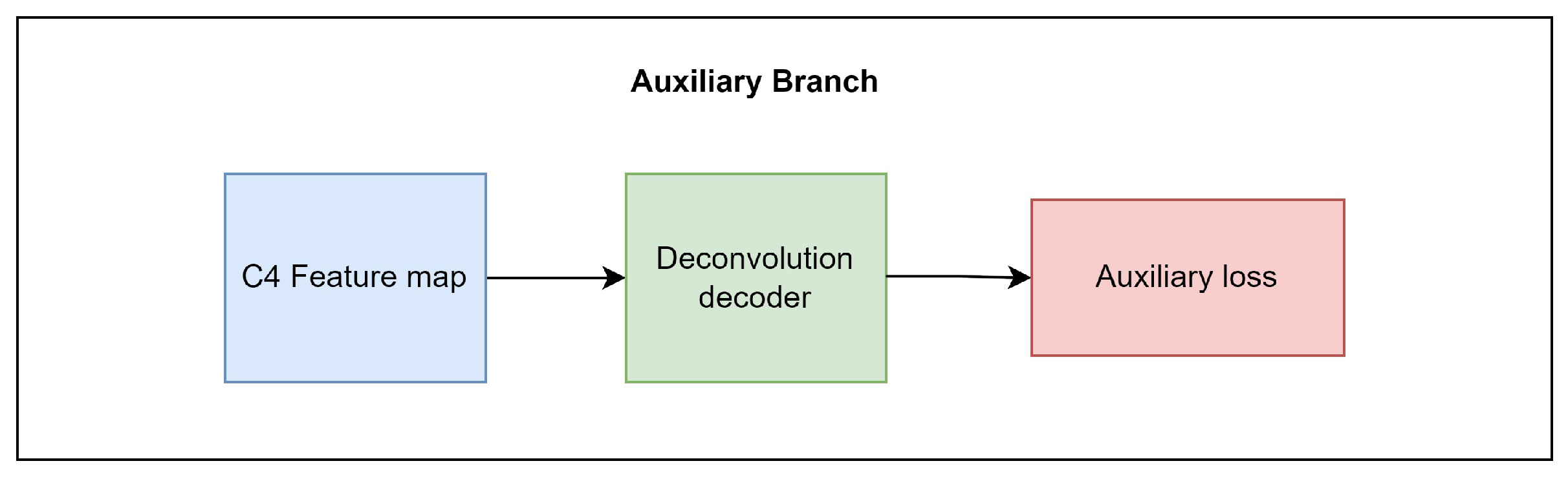
3.3.5. The Auxiliary Branch in CloudRCNN (Auxiliary Loss)
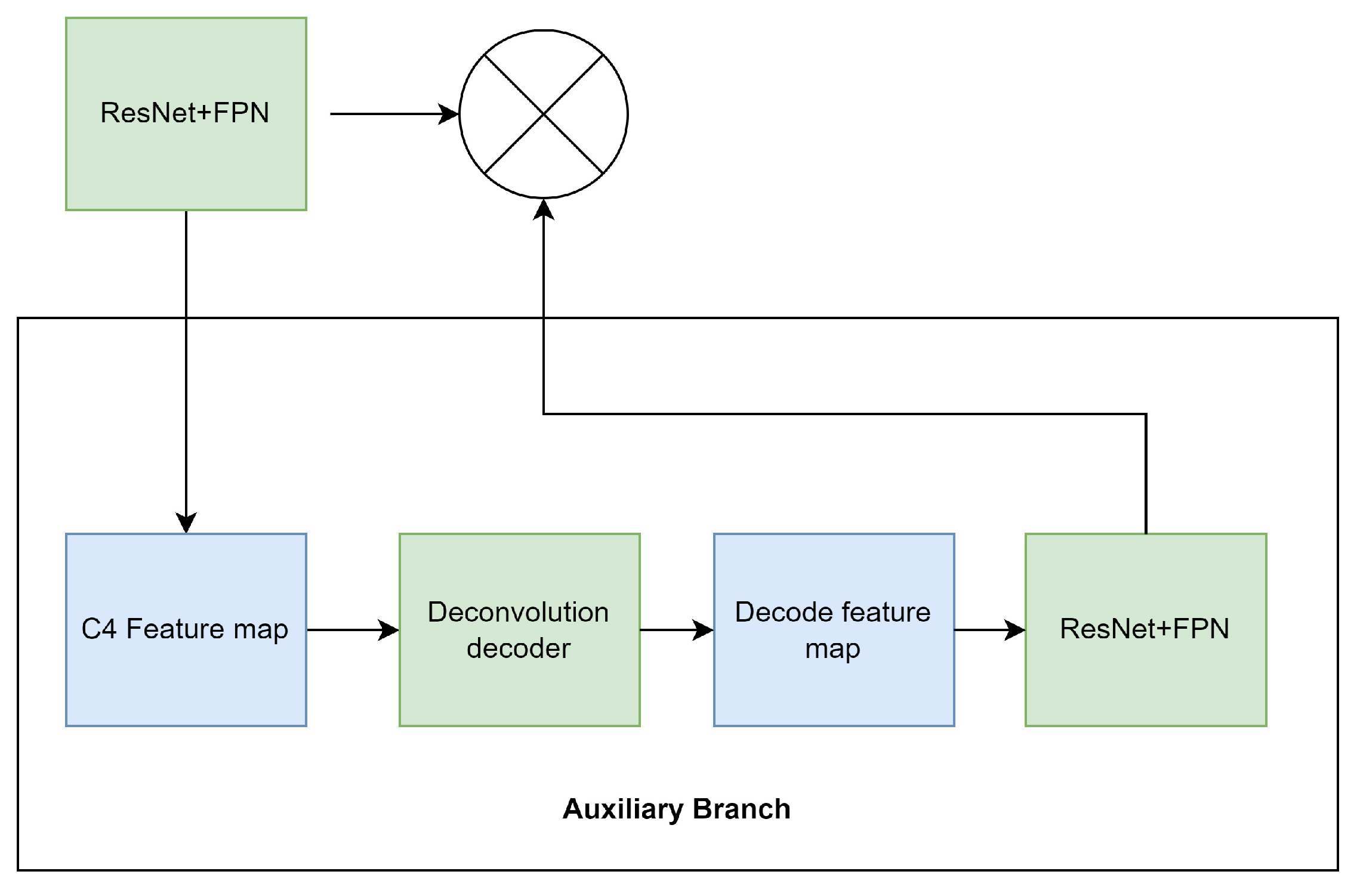
3.3.6. The Feature Fusion of CloudRCNN (Feature Fusion)
4. Experiments and Results
4.1. Evaluation Metric
4.2. Baseline Model
4.3. Model Training
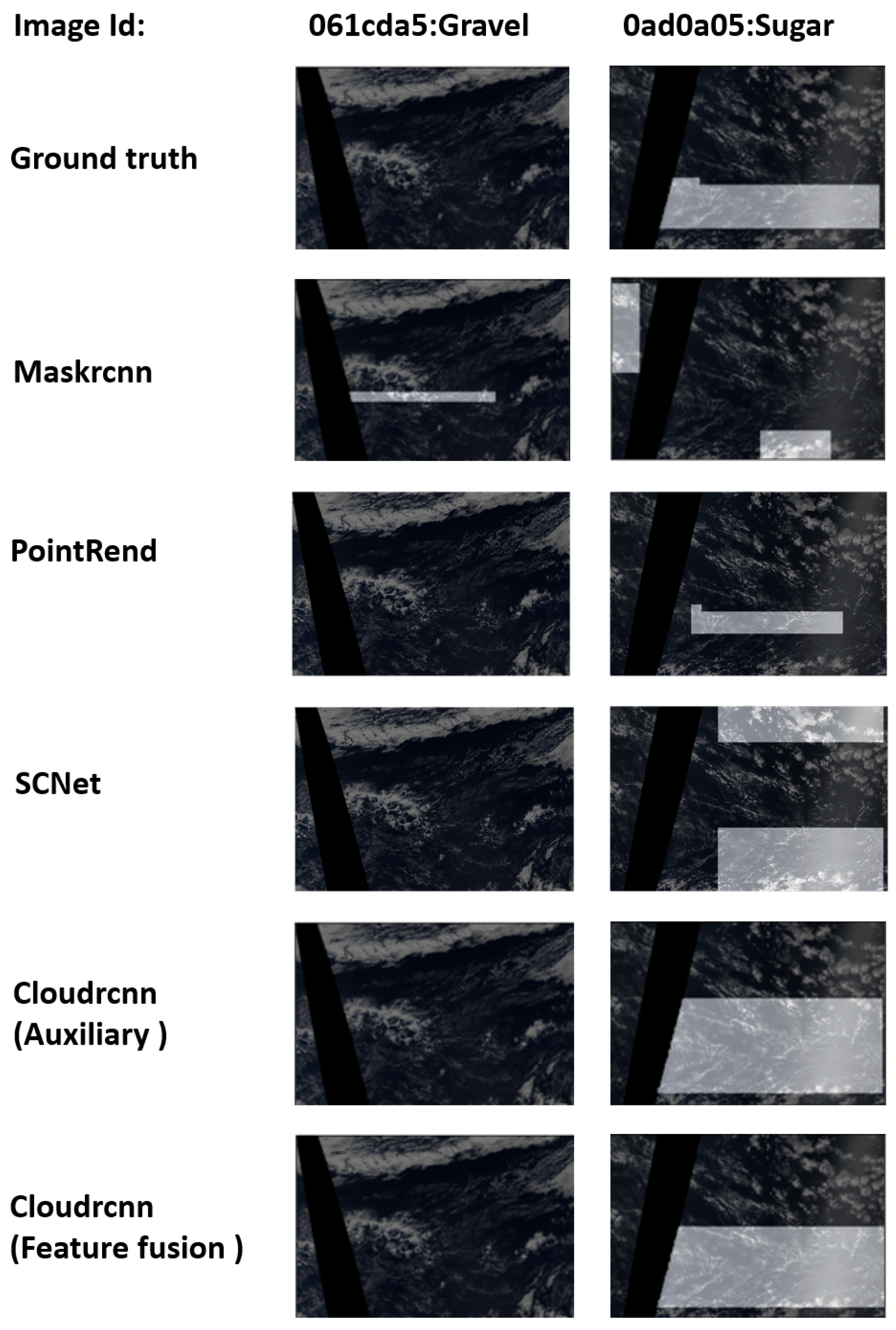
4.4. Comparative Results
4.5. Error Discussion
4.5.1. Misdetection Error
4.5.2. Label Errors
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- King, M.D.; Platnick, S.; Menzel, W.P.; Ackerman, S.A.; Hubanks, P.A. Spatial and temporal distribution of clouds observed by modis onboard the terra and aqua satellites. IEEE Trans. Geosci. Remote Sens. 2013, 51, 3826–3852. [Google Scholar] [CrossRef]
- Sun, L.; Yang, X.; Jia, S.; Jia, C.; Wang, Q.; Liu, X.; Wei, J.; Zhou, X. Satellite data cloud detection using deep learning supported by hyperspectral data. Int. J. Remote Sens. 2020, 41, 1349–1371. [Google Scholar] [CrossRef] [Green Version]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Chen, X.; Chen, J.; Jia, P.; Cao, X.; Liu, C. An iterative haze optimized transformation for automatic cloud/haze detection of landsat imagery. IEEE Trans. Geosci. Remote Sens. 2015, 54, 2682–2694. [Google Scholar] [CrossRef]
- Sun, L.; Mi, X.; Wei, J.; Wang, J.; Tian, X.; Yu, H.; Gan, P. A cloud detection algorithm-generating method for remote sensing data at visible to short-wave infrared wavelengths. ISPRS J. Photogramm. Remote Sens. 2017, 124, 70–88. [Google Scholar] [CrossRef]
- Lang, F.; Yang, J.; Yan, S.; Qin, F. Superpixel segmentation of polarimetric synthetic aperture radar (sar) images based on generalized mean shift. Remote Sens. 2018, 10, 1592. [Google Scholar] [CrossRef] [Green Version]
- Stutz, D.; Hermans, A.; Leibe, B. Superpixels: An evaluation of the state-of-the-art. Comput. Vis. Image Underst. 2018, 166, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Ciecholewski, M. Automated coronal hole segmentation from solar euv images using the watershed transform. J. Vis. Commun. Image Represent. 2015, 33, 203–218. [Google Scholar] [CrossRef]
- Cousty, J.; Bertrand, G.; Najman, L.; Couprie, M. Watershed cuts: Thinnings, shortest path forests, and topological watersheds. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 925–939. [Google Scholar] [CrossRef] [Green Version]
- Braga, A.M.; Marques, R.C.; Rodrigues, F.A.; Medeiros, F.N. A median regularized level set for hierarchical segmentation of sar images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1171–1175. [Google Scholar] [CrossRef]
- Jin, R.; Yin, J.; Zhou, W.; Yang, J. Level set segmentation algorithm for high-resolution polarimetric sar images based on a heterogeneous clutter model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4565–4579. [Google Scholar] [CrossRef]
- Guo, Y.; Cao, X.; Liu, B.; Gao, M. Cloud detection for satellite imagery using attention-based u-net convolutional neural network. Symmetry 2020, 12, 1056. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Understanding Clouds from Satellite Images. Available online: https://www.kaggle.com/c/understanding_cloud_organization (accessed on 1 June 2021).
- Ahmed, T.; Sabab, N.H.N. Classification and understanding of cloud structures via satellite images with efficientunet. SN Comput. Sci. 2022, 3, 1–11. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. Pointrend: Image segmentation as rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9799–9808. [Google Scholar]
- Vu, T.; Haeyong, K.; Yoo, C.D. Scnet: Training inference sample consistency for instance segmentation. In Proceedings of the AAAI, Virtually, 2–9 February 2021. [Google Scholar]
- Dev, S.; Nautiyal, A.; Lee, Y.H.; Winkler, S. Cloudsegnet: A deep network for nychthemeron cloud image segmentation. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1814–1818. [Google Scholar] [CrossRef] [Green Version]
- Wieland, M.; Li, Y.; Martinis, S. Multi-sensor cloud and cloud shadow segmentation with a convolutional neural network. Remote Sens. Environ. 2019, 230, 111203. [Google Scholar] [CrossRef]
- Xia, M.; Wang, T.; Zhang, Y.; Liu, J.; Xu, Y. Cloud/shadow segmentation based on global attention feature fusion residual network for remote sensing imagery. Int. J. Remote Sens. 2021, 42, 2022–2045. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Liu, Y.; Wang, W.; Li, Q.; Min, M.; Yao, Z. Dcnet: A deformable convolutional cloud detection network for remote sensing imagery. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Ruder, S. An overview of multi-task learning in deep neural networks. arXiv 2017, arXiv:1706.05098. [Google Scholar]
- Islam, M.; Atputharuban, D.A.; Ramesh, R.; Ren, H. Real-time instrument segmentation in robotic surgery using auxiliary supervised deep adversarial learning. IEEE Robot. Autom. Lett. 2019, 4, 2188–2195. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, X.; Peng, C.; Xue, X.; Sun, J. Exfuse: Enhancing feature fusion for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 269–284. [Google Scholar]
- Zheng, Z.; Zhang, X.; Xiao, P.; Li, Z. Integrating gate and attention modules for high-resolution image semantic segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4530–4546. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Aslani, S.; Murino, V.; Dayan, M.; Tam, R.; Sona, D.; Hamarneh, G. Scanner invariant multiple sclerosis lesion segmentation from mri. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 781–785. [Google Scholar]
- Deng, J.; Bei, S.; Shaojing, S.; Zhen, Z. Feature fusion methods in deep-learning generic object detection: A survey. In Proceedings of the 2020 IEEE 9th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 17–19 June 2020; Volume 9, pp. 431–437. [Google Scholar]
- Cheng, R.; Razani, R.; Taghavi, E.; Li, E.; Liu, B. 2-s3net: Attentive feature fusion with adaptive feature selection for sparse semantic segmentation network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12547–12556. [Google Scholar]
- Irfan, R.; Almazroi, A.A.; Rauf, H.T.; Damaševičius, R.; Nasr, E.A.; Abdelgawad, A.E. Dilated semantic segmentation for breast ultrasonic lesion detection using parallel feature fusion. Diagnostics 2021, 11, 1212. [Google Scholar] [CrossRef] [PubMed]
- Shang, R.; Zhang, J.; Jiao, L.; Li, Y.; Marturi, N.; Stolkin, R. Multi-scale adaptive feature fusion network for semantic segmentation in remote sensing images. Remote Sens. 2020, 12, 872. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Zhou, Y.; Wang, D.; Mu, J.; Zhou, H. Self-attention feature fusion network for semantic segmentation. Neurocomputing 2021, 453, 50–59. [Google Scholar] [CrossRef]
- Rasp, S.; Schulz, H.; Bony, S.; Stevens, B. Combining crowdsourcing and deep learning to explore the mesoscale organization of shallow convection. Bull. Am. Meteorol. Soc. 2020, 101, E1980–E1995. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Abdulla, W. Mask r-Cnn for Object Detection and Instance Segmentation on Keras and Tensorflow. 2017. Available online: https://github.com/matterport/Mask_RCNN (accessed on 2 August 2021).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Set (9477 Samples) | ||
|---|---|---|
| Category | Sample | Percentage |
| Fish pattern | 2219 | 23.41% |
| Flower pattern | 1881 | 19.94% |
| Gravel pattern | 2341 | 24.70% |
| Sugar pattern | 3036 | 32.04% |
| Testing Set (2359 Samples) | ||
| Category | Sample | Percentage |
| Fish pattern | 2219 | 23.82% |
| Flower pattern | 1881 | 20.52% |
| Gravel pattern | 2341 | 25.36% |
| Sugar pattern | 3036 | 30.31% |
| Model | Fish | Flower | Gravel | Sugar | mIoU |
|---|---|---|---|---|---|
| MaskRCNN | 0.2830 | 0.1991 | 0.2458 | 0.3171 | 0.2613 |
| PointRend | 0.3728 | 0.2816 | 0.4123 | 0.4254 | 0.3746 |
| SCNet | 0.3953 | 0.3177 | 0.4769 | 0.3984 | 0.4019 |
| CloudRCNN (auxiliary loss) | 0.3813 | 0.3288 | 0.5246 | 0.4202 | 0.4137 |
| CloudRCNN (feature fusion) | 0.3520 | 0.2769 | 0.4668 | 0.4601 | 0.3890 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, G.; Zuo, B. CloudRCNN: A Framework Based on Deep Neural Networks for Semantic Segmentation of Satellite Cloud Images. Appl. Sci. 2022, 12, 5370. https://doi.org/10.3390/app12115370
Shi G, Zuo B. CloudRCNN: A Framework Based on Deep Neural Networks for Semantic Segmentation of Satellite Cloud Images. Applied Sciences. 2022; 12(11):5370. https://doi.org/10.3390/app12115370
Chicago/Turabian StyleShi, Gonghe, and Baohe Zuo. 2022. "CloudRCNN: A Framework Based on Deep Neural Networks for Semantic Segmentation of Satellite Cloud Images" Applied Sciences 12, no. 11: 5370. https://doi.org/10.3390/app12115370
APA StyleShi, G., & Zuo, B. (2022). CloudRCNN: A Framework Based on Deep Neural Networks for Semantic Segmentation of Satellite Cloud Images. Applied Sciences, 12(11), 5370. https://doi.org/10.3390/app12115370