
Chinese Named Entity Recognition Based on Knowledge Based Question Answering System

Abstract
:1. Introduction
- We verify the performance of the SoftLexicon+Bi-LSTM-CRF model in NER tasks under a KBQA scenario. Moreover, we explore the applicability of this model in the non-public field, such as a power grid field, and improve the SoftLexicon method according to the application domain.
- To improve the performance of NER, we propose an efficient fuzzy matching module that can modify those entities incorrectly recognized by the NER model based on the combination of multiple methods. This module can be easily deployed in a KBQA system and has strong portability and robustness.
- We further build a dataset and lexicon related to a power grid based on the data provided by the Hebei Electric Power Company and use them to construct an NER system suitable for the power grid field.
2. Related Works
2.1. Power Grid Intelligent Customer Service System
2.2. Text Matching
- The KBQA system needs to achieve efficient query.
- For the data used in this work, the length of entities is relatively short, normally no more than 10 characters.
- The query text input by the user in a KBQA system generally does not contain contextual information.
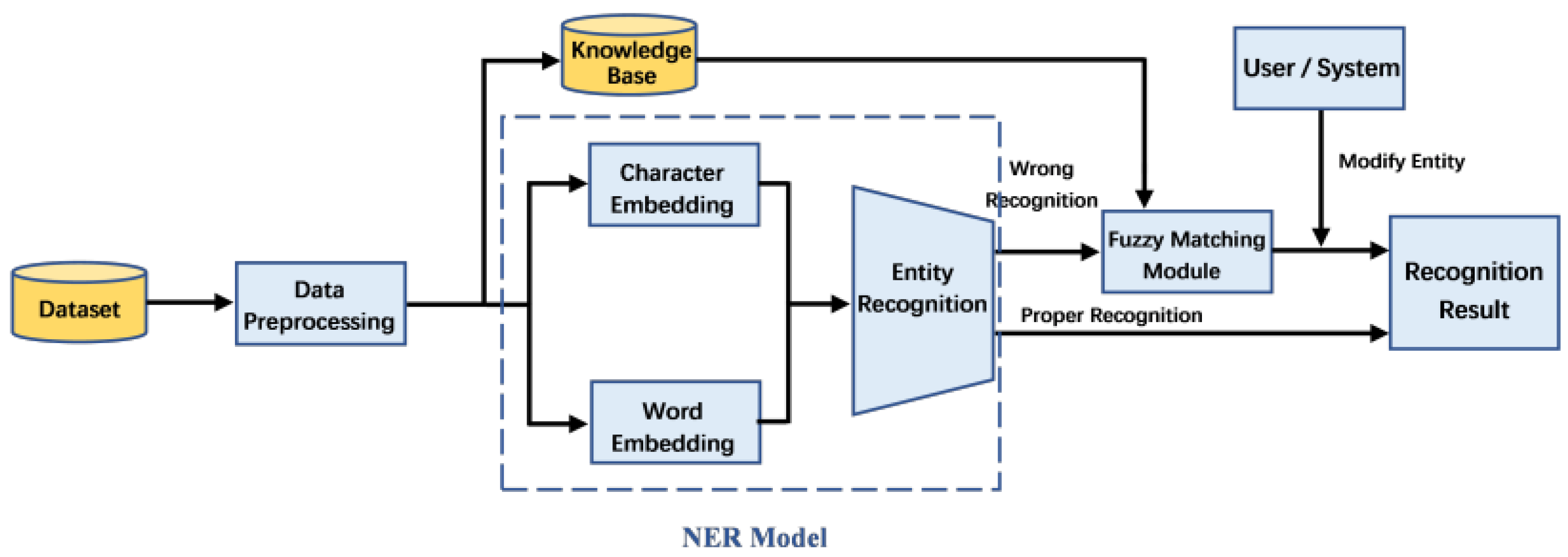
3. Model and Approach
3.1. The NER Model
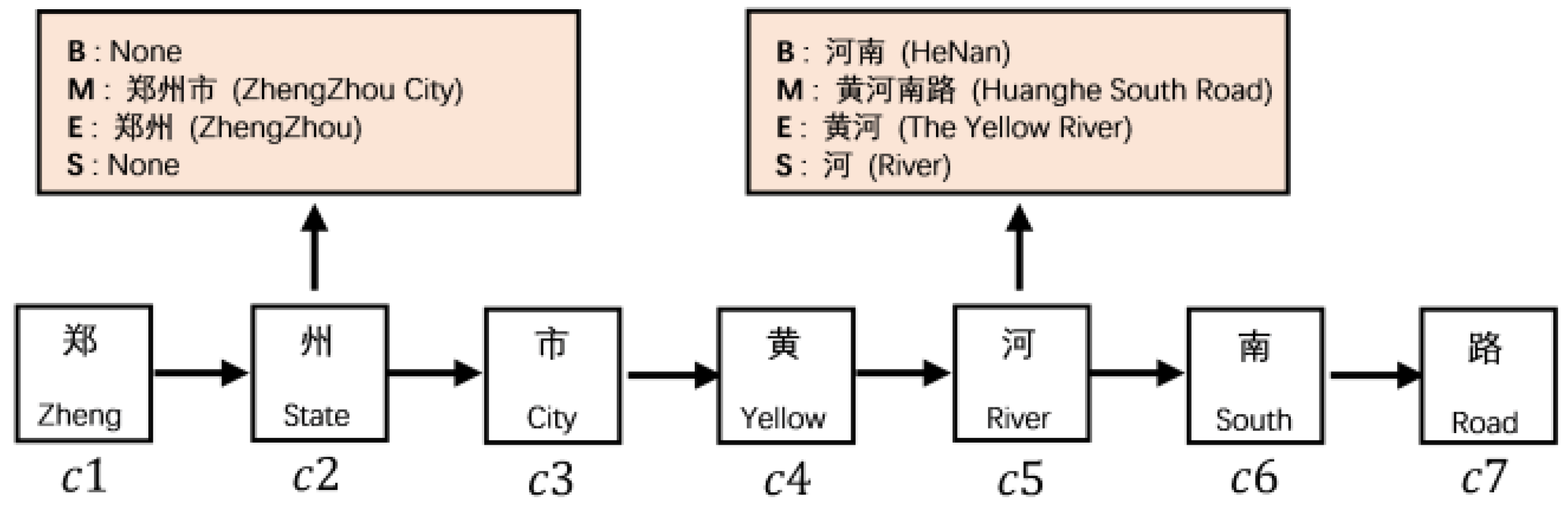
3.1.1. SoftLexicon Method
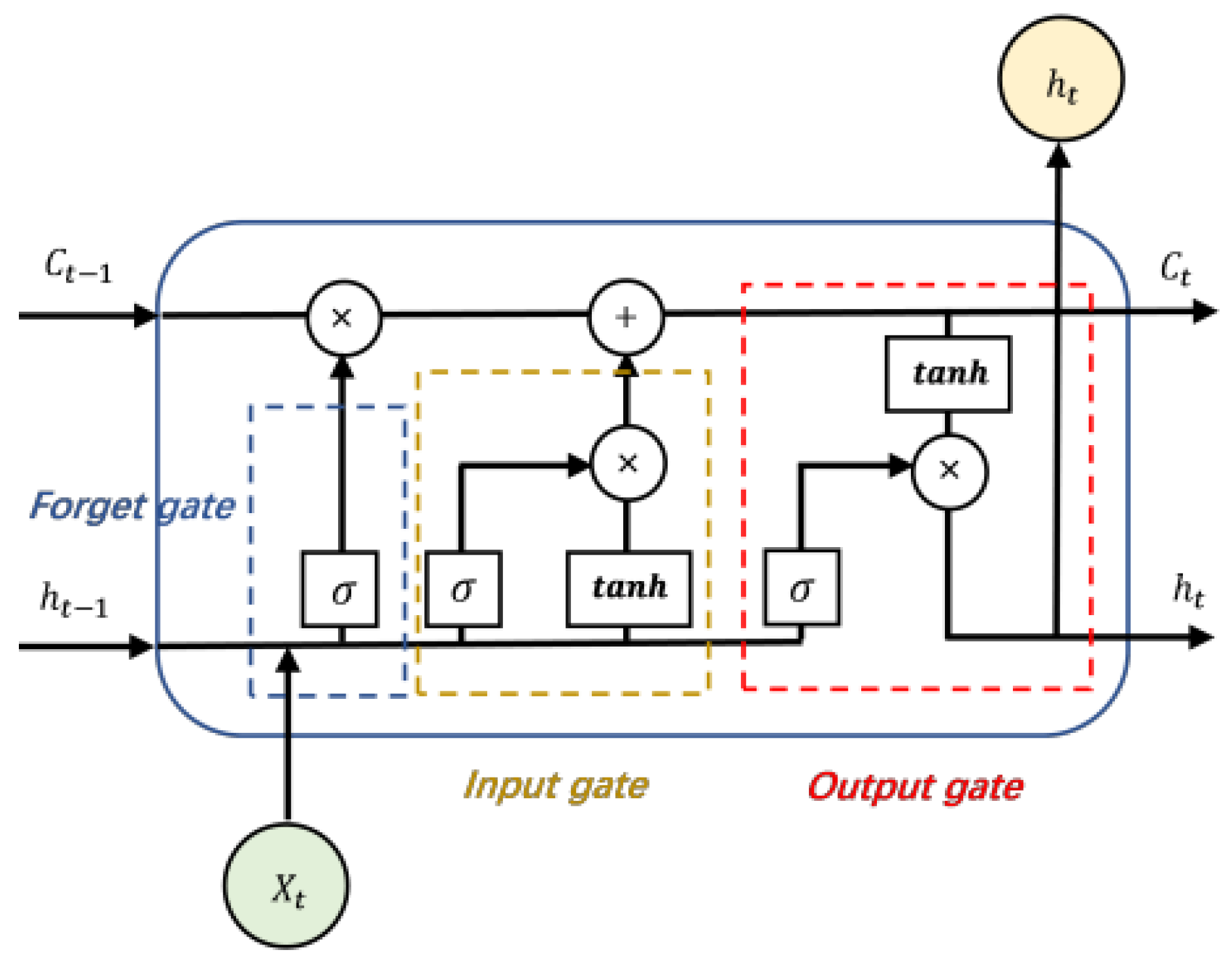
3.1.2. The Bi-LSTM-CRF Model
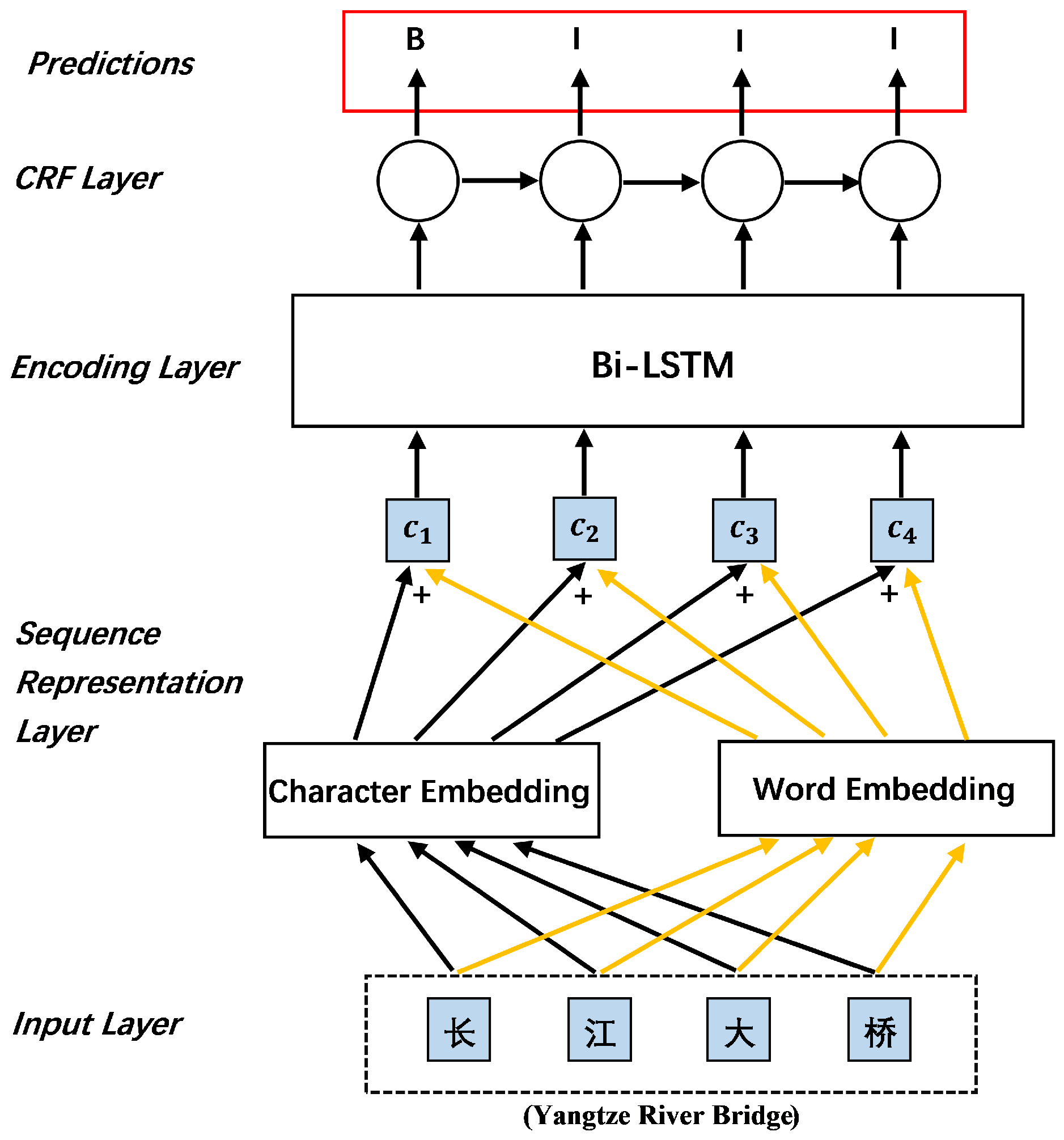
3.1.3. SoftLexicon+Bi-LSTM-CRF Model
3.2. Fuzzy Matching Module
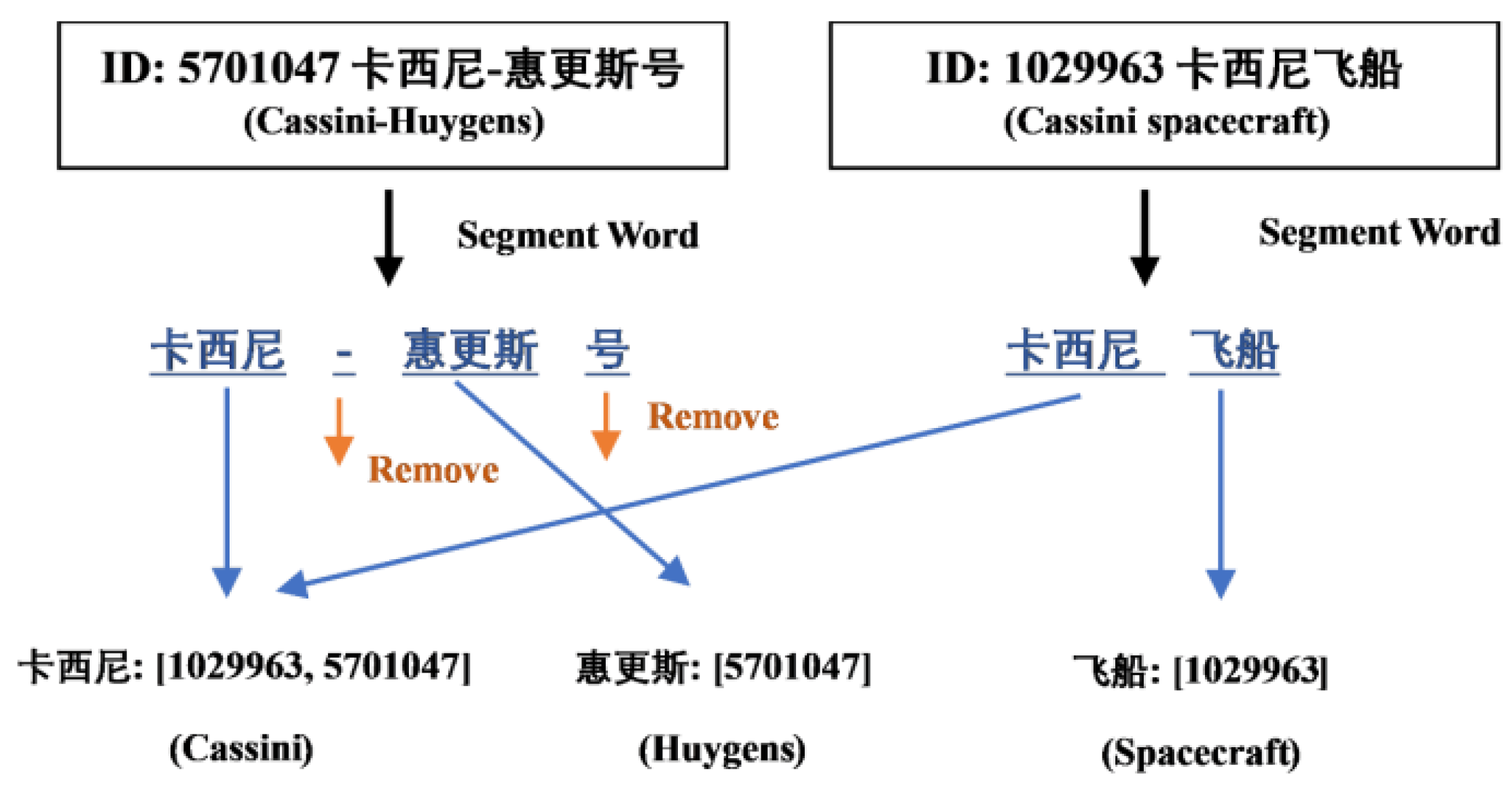
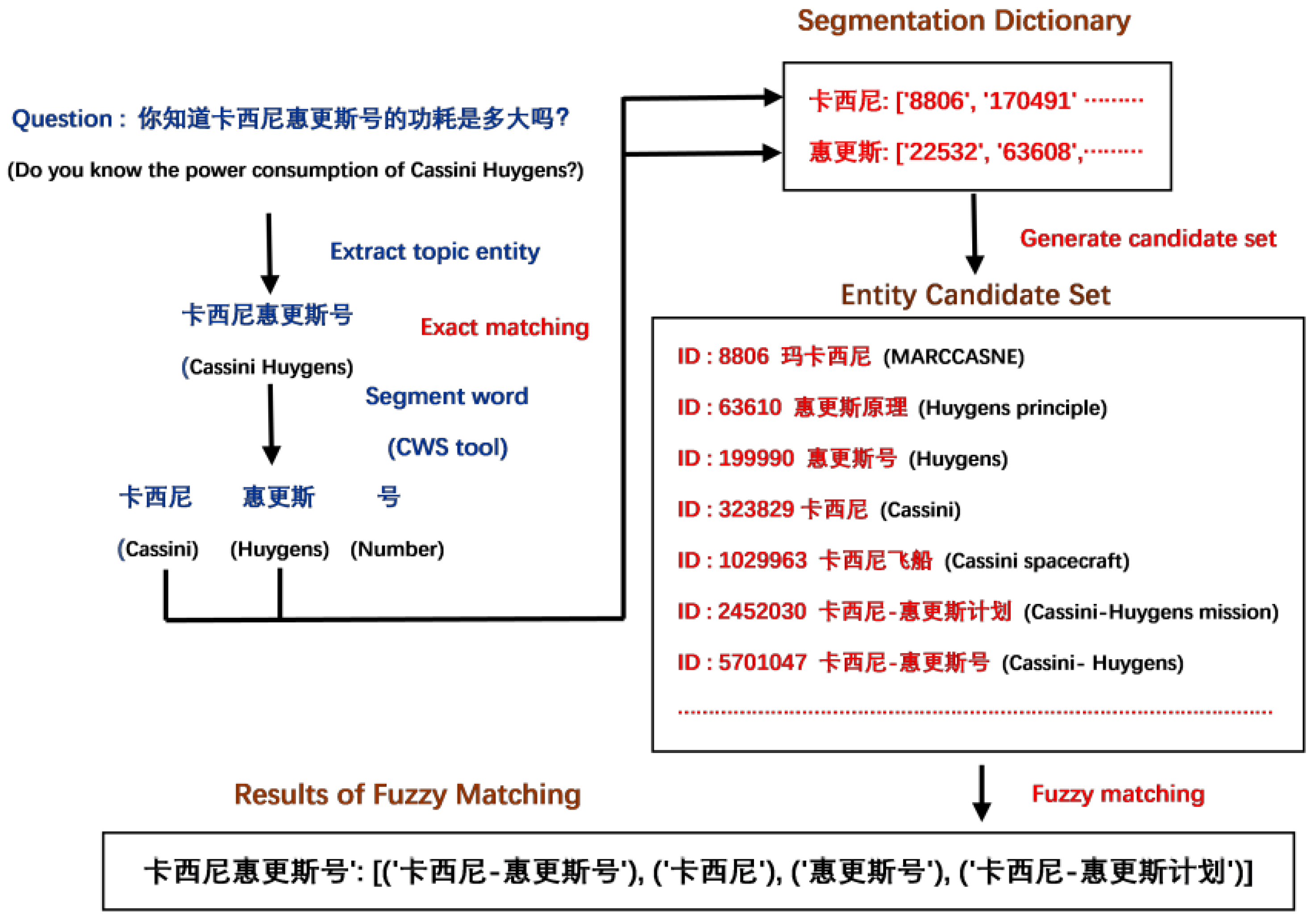
- The topic entity cannot be recognized normally due to some rarely used Chinese characters. The BERT model relies on a vocabulary when encoding tokens [45]. For those tokens that cannot be retrieved in the vocabulary (rarely used characters), they will be replaced by a special identifier “[UNK]”. The original tokens’ information will be discarded, making it impossible to exactly identify the topic entity. Although we can avoid some errors by expanding the vocabulary, it is impossible to add every rarely used Chinese character to the vocabulary in practical application.
- The recognized topic entity cannot be linked to the entity in the knowledge base due to typos in user input. For KBQA-related systems, it is a common phenomenon that the user input contains typos. This leads to the fact that even if the entity boundary in the sentence is correctly demarcated, the extracted topic entity cannot exactly link to the knowledge base.
- The NER model incorrectly recognizes the entity. No NER model can achieve 100% entity recognition accuracy. Inevitably, there will be some errors in recognition results due to the error of the model.
- (1)
- According to the analysis of the experimental results of the NER model, we find that most of the incorrect entities contain some effective information in either of the above cases. For example, consider the question “你知道中国工服是什么时候出现的吗”? (Do you know when Chinese Kung Fu came into being?). The user wants to ask the question about “Chinese Kung Fu” but enters “Chinese Uniform” when entering the query. Our model can extract the topic entity “中国工服” (chinese uniform) from the sentence, but the right word is “中国功夫” (Chinese kung fu). The recognized entity cannot be retrieved in the knowledge base because of typos, but the word “中国” (Chinese) is an important part of the right word “中国功夫” (Chinese kung fu). We can utilize this effective information to construct a fuzzy matching module.
- (2)
- In the application scenario of the KBQA system, the scope of the user’s query is limited. In other words, the user can only query the content that is already stored in the knowledge base. This means when matching, the entity to be matched is obtained from the user’s query, while the match objects can only be entities that already exist in the knowledge base. The determination of matching scope enables us to improve the efficiency of fuzzy matching by constructing artificial rules.
4. Experimental Results and Discussion
4.1. Dataset
4.1.1. NLPCC2016
4.1.2. Power Grid Dataset
4.2. Experimental Setting
4.3. Evaluation Metrics
4.4. Experimental Results and Analyses
4.4.1. The Performance of the NER Model
4.4.2. The Performance of the Fuzzy Matching Module
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Turing, A.M. Computing machinery and intelligence. In Parsing the Turing Test; Springer: Berlin/Heidelberg, Germany, 2009; pp. 23–65. [Google Scholar]
- Siri. Available online: https://www.apple.com.cn/siri/ (accessed on 20 April 2022).
- ALIME. Available online: https://www.alixiaomi.com/ (accessed on 20 April 2022).
- NetEase Qiyu. Available online: https://qiyukf.com/ (accessed on 20 April 2022).
- Yadav, V.; Bethard, S. A Survey on Recent Advances in Named Entity Recognition from Deep Learning models. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 2145–2158. [Google Scholar]
- Li, J.; Sun, A.; Han, J.; Li, C. A survey on deep learning for named entity recognition. IEEE Trans. Knowl. Data Eng. 2020, 34, 50–70. [Google Scholar] [CrossRef] [Green Version]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 160–167. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Zhang, Y.; Yang, J. Chinese NER Using Lattice LSTM. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 1554–1564. [Google Scholar]
- Li, X. FLAT: Chinese NER Using Flat-Lattice Transformer. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 6836–6842. [Google Scholar]
- Ma, R.; Peng, M.; Zhang, Q.; Wei, Z.; Huang, X.J. Simplify the Usage of Lexicon in Chinese NER. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 5951–5960. [Google Scholar]
- Levow, G.A. The third international Chinese language processing bakeoff: Word segmentation and named entity recognition. In Proceedings of the Fifth SIGHAN Workshop on Chinese Language Processing, Sydney, Australia, 22–23 July 2006; pp. 108–117. [Google Scholar]
- He, H.; Sun, X. F-Score Driven Max Margin Neural Network for Named Entity Recognition in Chinese Social Media. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, Valencia, Spain, 3–7 April 2017; pp. 713–718. [Google Scholar]
- Weischedel, R.; Pradhan, S.; Ramshaw, L.; Palmer, M.; Xue, N.; Marcus, M.; Taylor, A.; Greenberg, C.; Hovy, E.; Belvin, R.; et al. Ontonotes Release 4.0; LDC2011T03; Linguistic Data Consortium: Philadelphia, PA, USA, 2011. [Google Scholar]
- NLPCC-ICCPOL 2016. Available online: Http://tcci.ccf.org.cn/conference/2016/ (accessed on 23 April 2022).
- Wang, Z.; Hamza, W.; Florian, R. Bilateral multi-perspective matching for natural language sentences. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 4144–4150. [Google Scholar]
- Lyu, B.; Chen, L.; Zhu, S.; Yu, K. LET: Linguistic Knowledge Enhanced Graph Transformer for Chinese Short Text Matching. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 13498–13506. [Google Scholar]
- Francis-Landau, M.; Durrett, G.; Klein, D. Capturing Semantic Similarity for Entity Linking with Convolutional Neural Networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1256–1261. [Google Scholar]
- Tencent Qidian. Available online: https://qidian.qq.com/ (accessed on 22 April 2022).
- Sobot. Available online: https://www.sobot.com/ (accessed on 22 April 2022).
- Analysis Report on Market Operation Pattern and Investment Prospect of Intelligent Customer Service Industry in China (2021–2027). Available online: https://www.chyxx.com/ (accessed on 22 April 2022).
- Yan, H.; Huang, B.; Liu, L. Application prospect analysis of artificial intelligence in new generation power system. Electron. Power Inf. Commun. Technol. 2018, 11, 7–11. [Google Scholar]
- Zhang, Q.; Huang, X.; Cao, L.; Wang, H.; Xu, J. Research on the technology of power intelligent customer service. Digit. Commun. World 2019, 5, 121–122. [Google Scholar]
- Zheng, R.; Yan, J.; Li, L.; Zhao, W.; Yuan, Z.; Han, X.; Li, F.; Li, X. Research and practice of intelligent customer service innovation based on power ICT business scenarios. Power Syst. Big Data 2019, 1, 71–76. [Google Scholar]
- Pang, Y.; Tian, R.; Zhu, X.; Wang, X.; Chen, X. Research on power grid Intelligent customer service Technology based on Multi-layer Perceptron generative adversarial Network. Electron. Des. Eng. 2021, 4, 190–193. [Google Scholar]
- Zhu, Y.; Dai, C.; Chen, Y.; Zhuo, L.; Liao, Y.; Zhao, M. Design of online power intelligent customer service system based on artificial intelligence. Mach. Tool Hydraul. 2019, 46, 9–14. [Google Scholar]
- Ramos, J. Using tf-idf to determine word relevance in document queries. In Proceedings of the First Instructional Conference on Machine Learning, Washington, DC, USA, 21–24 August 2003; Citeseer: Princeton, NJ, USA, 2003; Volume 242, pp. 29–48. [Google Scholar]
- Robertson, S.E.; Walker, S.; Jones, S.; Hancock-Beaulieu, M.M.; Gatford, M. Okapi at TREC-3. Nist Spec. Publ. 1995, 109, 109. [Google Scholar]
- Ristad, E.S.; Yianilos, P.N. Learning string-edit distance. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 522–532. [Google Scholar] [CrossRef] [Green Version]
- Manber, U. Finding Similar Files in a Large File System. In Proceedings of the Usenix Winter, San Francisco, CA, USA, 17–21 January 1994; Volume 94, pp. 1–10. [Google Scholar]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and Policy Considerations for Deep Learning in NLP. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 3645–3650. [Google Scholar]
- Arora, S.; Liang, Y.; Ma, T. A simple but tough-to-beat baseline for sentence embeddings. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Peinelt, N.; Nguyen, D.; Liakata, M. tBERT: Topic models and BERT joining forces for semantic similarity detection. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7047–7055. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the 18th International Conference on Machine Learning 2001 (ICML 2001), San Francisco, CA, USA, 28 June–1 July 2001. [Google Scholar]
- Sutton, C.; McCallum, A.; Rohanimanesh, K. An introduction to conditional random fields. Found. Trends Mach. Learn. 2012, 4, 267–373. [Google Scholar] [CrossRef]
- Lu, Y.; Zhang, Y.; Ji, D. Multi-prototype Chinese character embedding. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portoroz, Slovenia, 23–28 May 2016; pp. 855–859. [Google Scholar]
- ctb.50d.vec. Available online: https://drive.google.com/file/d/1K_lG3FlXTgOOf8aQ4brR9g3R40qi1Chv/view (accessed on 23 April 2022).
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Wallach, H.M. Conditional random fields: An introduction. Tech. Rep. (CIS) 2004, 53, 267–272. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1 (Long and Short Papers), pp. 4171–4186. [Google Scholar]
- Chinese Gigaword Fifth Edition. Available online: https://catalog.ldc.upenn.edu/LDC2011T13 (accessed on 23 April 2022).
- Google-Research/Bert. Available online: https://github.com/google-research/bert (accessed on 27 April 2022).
- “Jieba” Chinese Text Segmentation Tool. Available online: https://github.com/fxsjy/jieba (accessed on 23 April 2022).
- Fuzzywuzzy. Available online: https://github.com/seatgeek/fuzzywuzzy (accessed on 23 April 2022).
- Cui, W.; Xiao, Y.; Wang, H.; Song, Y.; Hwang, S.w.; Wang, W. KBQA: Learning Question Answering over QA Corpora and Knowledge Bases. Proc. Vldb Endow. 2017, 10, 565–576. [Google Scholar] [CrossRef] [Green Version]
- Gui, T.; Zou, Y.; Zhang, Q.; Peng, M.; Fu, J.; Wei, Z.; Huang, X.J. A lexicon-based graph neural network for Chinese NER. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 1040–1050. [Google Scholar]
- Ma, X.; Hovy, E. End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1: Long Papers, pp. 1064–1074. [Google Scholar]
- The Website of the Original Code of the Paper “Chinese NER Using Lattice LSTM”. Available online: https://github.com/jiesutd/LatticeLSTM (accessed on 21 May 2022).
- Howard, J.; Ruder, S. Universal Language Model Fine-tuning for Text Classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 1: Long Papers, pp. 328–339. [Google Scholar]
- Jiao, X.; Yin, Y.; Shang, L.; Jiang, X.; Chen, X.; Li, L.; Wang, F.; Liu, Q. TinyBERT: Distilling BERT for Natural Language Understanding. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 4163–4174. [Google Scholar]
- Sun, Z.; Yu, H.; Song, X.; Liu, R.; Yang, Y.; Zhou, D. MobileBERT: A Compact Task-Agnostic BERT for Resource-Limited Devices. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 2158–2170. [Google Scholar]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef] [PubMed] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Knowledge Base | 安德烈|| 国籍|| 摩纳哥 |
| (Andre || Nationality || Monaco) | |
| Question–Answer Pairs | <question id=4> 安德烈是哪个国家的人呢? |
| (What’s Andre’s nationality) | |
| <triple id=4> 安德烈|| 国籍|| 摩纳哥 | |
| (Andre || Nationality || Monaco) | |
| <answer id=4> 摩纳哥 | |
| (Monaco) |
| Knowledge directory | 信息通信运维>>应用系统>>二级部署系统>>信息通信一体化调度运行支撑平台 (SG-I6000) |
| Information communication operation and maintenance>>Application system>>Secondary deployment system | |
| >>Information and Communication Integrated Scheduling Operation Support Platform (SG-I6000) | |
| Knowledge title | 省公司通用, 业务指导, 应用系统, I6000系统, 登录后部分模块空白 (环境支持) |
| Provincial company general, business guidance, application system, I6000 system, some modules blank after | |
| login (environment support) | |
| Knowledge content | 建议使用谷歌浏览器, 使用IE部分模块空白 |
| It is recommended to use Google browser, use IE part of the module blank |
| Datasets | Data Type | Train Set | Validation Set | Test Set |
|---|---|---|---|---|
| NLPCC2016 | Sentence | 14,480 | 1910 | 7690 |
| Entity | 14,480 | 1910 | 7690 | |
| Tokens | 225,509 | 31,501 | 126,990 | |
| Power Grid | Sentence | 3500 | None | 1023 |
| Entity | 3564 | None | 1050 | |
| Tokens | 65,769 | None | 19,332 |
| Validation Set | Test Set | |||||
|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | |
| Bi-LSTM-CRF (BERT) | 96.54% | 96.65% | 96.60% | 96.80% | 96.89% | 96.84% |
| SoftLexicon+ Bi-LSTM-CRF (BERT) | 96.81% | 96.91% | 96.86% | 97.01% | 97.10% | 97.06% |
| Models | P | R | F1 |
|---|---|---|---|
| Bi-LSTM-CRF | |||
| with random embedding | 91.42% | 91.29% | 91.35% |
| with pre-trained embedding | 92.20% | 92.12% | 92.16% |
| with SoftLexicon | 93.31% | 93.21% | 93.26% |
| LGN [49] | 92.22% | 92.13% | 92.17% |
| Bi-LSTM-CNNs-CRF [50] | 92.22% | 92.79% | 92.46% |
| Lattice-LSTM | 93.07% | 92.96% | 93.02% |
| BERT | |||
| +Bi-LSTM-Softmax | 96.51% | 96.66% | 96.58% |
| +Bi-LSTM-CRF | 96.80% | 96.89% | 96.84% |
| +Bi-LSTM-CRF (SoftLexicon) | 97.01% | 97.10% | 97.06% |
| Model | Expand Lexicon | P | R | F1 |
|---|---|---|---|---|
| SoftLexicon+Bi-LSTM-CRF | YES | 91.24% | 93.65% | 92.43% |
| (BERT) | NO | 90.48% | 92.86% | 91.65% |
| Models | P | R | F1 |
|---|---|---|---|
| Bi-LSTM-CRF | |||
| with random embedding | 80.45% | 78.15% | 79.28% |
| with pre-trained embedding | 81.34% | 78.63% | 79.96% |
| with SoftLexicon | 86.51% | 84.45% | 85.47% |
| LGN [49] | 87.72% | 87.98% | 87.85% |
| Bi-LSTM-CNNs-CRF [50] | 81.30% | 82.16% | 81.73% |
| Lattice-LSTM | 86.20% | 84.64% | 85.41% |
| BERT+SoftLexicon | |||
| +Bi-LSTM-CRF | 90.48% | 92.86% | 91.65% |
| +Bi-LSTM-CRF (Expand Lexicon) | 91.24% | 93.65% | 92.43% |
| Dataset | Incorrect Results | Successfully Modified | Response Time | ACC |
|---|---|---|---|---|
| NLPCC2016 | 225 | 135 | 0.78s | 99.0% |
| Power Grid | 77 | 68 | 0.23s | 99.1% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, D.; Cheng, S.; Pan, B.; Qiao, Y.; Zhao, W.; Wang, D. Chinese Named Entity Recognition Based on Knowledge Based Question Answering System. Appl. Sci. 2022, 12, 5373. https://doi.org/10.3390/app12115373
Yin D, Cheng S, Pan B, Qiao Y, Zhao W, Wang D. Chinese Named Entity Recognition Based on Knowledge Based Question Answering System. Applied Sciences. 2022; 12(11):5373. https://doi.org/10.3390/app12115373
Chicago/Turabian StyleYin, Didi, Siyuan Cheng, Boxu Pan, Yuanyuan Qiao, Wei Zhao, and Dongyu Wang. 2022. "Chinese Named Entity Recognition Based on Knowledge Based Question Answering System" Applied Sciences 12, no. 11: 5373. https://doi.org/10.3390/app12115373
APA StyleYin, D., Cheng, S., Pan, B., Qiao, Y., Zhao, W., & Wang, D. (2022). Chinese Named Entity Recognition Based on Knowledge Based Question Answering System. Applied Sciences, 12(11), 5373. https://doi.org/10.3390/app12115373