
A Novel Broad Echo State Network for Time Series Prediction: Cascade of Mapping Nodes and Optimization of Enhancement Layer

 , ,
, ,  ,
,  and
and
Abstract
:1. Introduction
2. Related Works
2.1. Time Series Prediction Methods
2.2. Broad Learning System
2.3. Echo State Network
3. Novel Broad Echo State Network
3.1. Network Based on the Cascade of Mapping Nodes
| Algorithm 1: The training algorithm of CMBESN |
| Input: Input data (after abnormal data processing and normalization, custom data step length), number of nodes in the mapping layer, RMSE threshold, spectral radius of ESN, leakage factor, and reserve pool size. |
| Output: Number of nodes in the enhancement layer, RMSE, training time. |
| Algorithm: |
| Step 1: Randomly initialize ; the initialized ESN unit includes the sparsity, the reservoir size, and the connection weight matrix. |
| Step 2: Record the output of mapping layer nodes . |
| Step 3: Record enhancement layer output . |
| Step 4: Calculate the combination matrix and the pseudo-inverse matrix of the combination matrix, and calculate the output weight matrix by Formulas (11) and (12). |
| Step 5: Calculate the current RMSE and compare it with the RMSE threshold. |
| Step 6: If the current prediction is greater than the RMSE threshold, the ESN unit is increased by the incremental algorithm. |
| Step 7: Initialize the newly added ESN cell by Step 1 and loop Step 4 to Step 6 to know that the RMSE of the prediction result is less than the RMSE threshold. |
| Step 8: Record training results. |
3.2. Optimization of Enhancement Layer Based on Unit Increment and Nonstationary Metrics
3.2.1. Incremental Algorithm of Enhancement Units
| Algorithm 2: Incremental Algorithm |
| Input: Number of ESN, ESN parameter configuration, RMSE threshold. |
| Output: Output weight matrix . |
| Algorithm: |
| Step 1: Initialize mapping layer node parameters. |
| Step 2: Initialize the reinforced layer ESN cells, including reserve pool size, leakage factor, sparsity, etc. |
| Step 3: CEBESN network output before the incremental algorithm is used and is calculated. |
| Step 4: If is less than the RMSE threshold, incremental algorithm optimization is started. |
| Step 5: Calculate the current RMSE and compare it with the RMSE threshold. |
| Step 6: If the current prediction is greater than the RMSE threshold, the ESN unit is increased by the incremental algorithm. |
| Step 7: Update the combination matrix with by Formulas (14)–(18). |
| Step 8: Repeat step 5 to step 7 until is less than the RMSE threshold. Update at the same time. |
| Step 9: Record the last . |
3.2.2. Parameter Optimization Based on Nonstationary Metrics

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Number of Mapping Layer Nodes | Number of Enhancement Layer Nodes | Reservoir Size | Spectral Radius Rate | Leaking Rate | Sparseness |
|---|---|---|---|---|---|---|
| BLS | 1–50 | 1–40 | NA | NA | NA | NA |
| ESN | NA | NA | 300–800 | 0.95 | 0.1 | 0.05 |
| CMBLS | 1–50 | 1–40 | NA | NA | NA | NA |
| CMBESN | 1–50 | 1–40 | 300–800 | 0.95 | 0.1 | 0.05 |
| Model | Number of Mapping Layer Nodes | Number of Enhancement Layer Nodes | Reservoir Size | Spectral Radius Rate | Leaking Rate | Sparseness |
|---|---|---|---|---|---|---|
| BLS | 20–60 | 10–50 | NA | NA | NA | NA |
| ESN | NA | NA | 400–1000 | 0.95 | 0.1 | 0.05 |
| CMBLS | 20–60 | 10–50 | NA | NA | NA | NA |
| CMBESN | 20–60 | 10–50 | 400–1000 | 0.95 | 0.1 | 0.05 |
4. Experiment and Result
4.1. Dataset
4.1.1. Simulation Dataset
4.1.2. Air Quality Dataset
4.2. Experimental Environment and Settings
4.3. Results
4.3.1. Results of MSO Dataset
4.3.2. Results of Air Quality Dataset
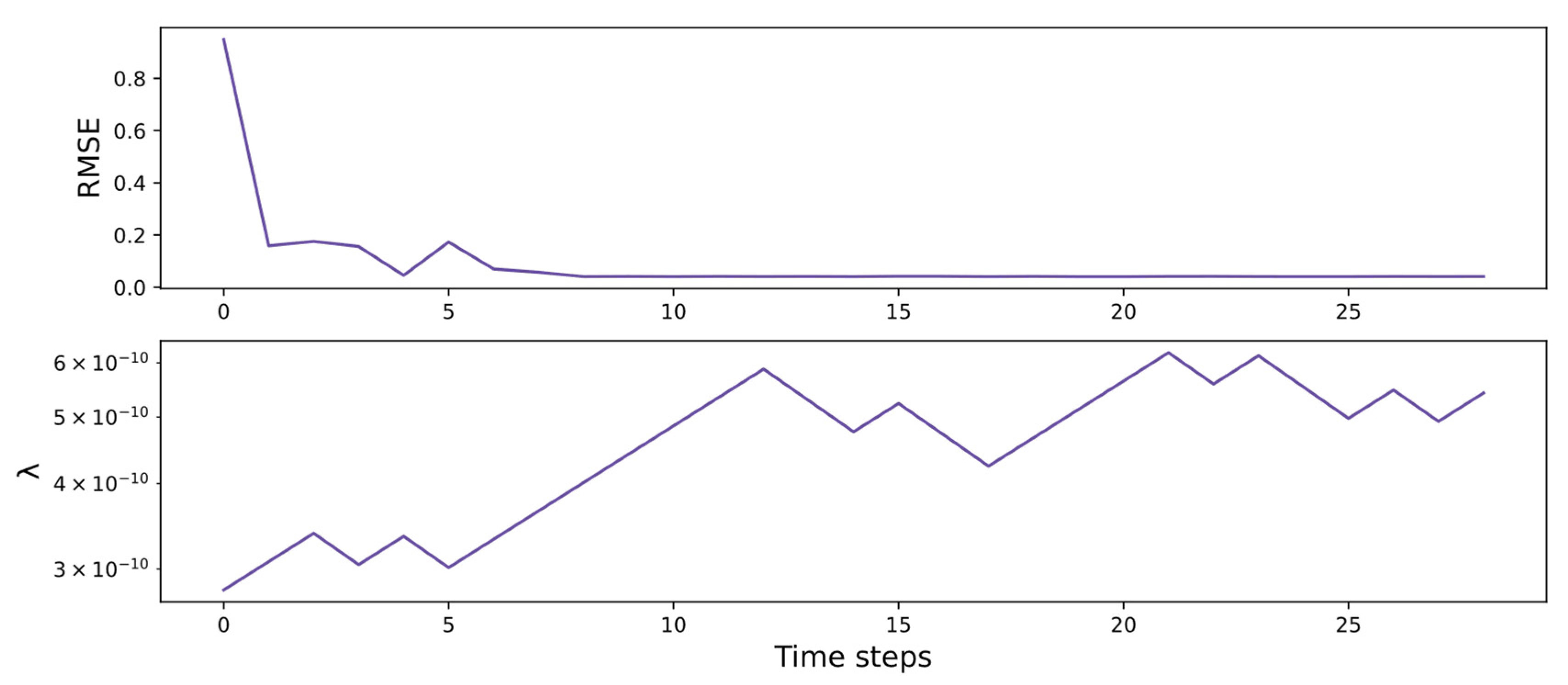
4.4. Optimization Experiments
4.4.1. Optimization Results of MSO Dataset
4.4.2. Optimization Results of Air Quality Dataset
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Harris, E.; Coleman, R. The social life of time and methods: Studying London’s temporal architectures. Time Soc. 2020, 29, 604–631. [Google Scholar] [CrossRef]
- Xu, L.; Li, Q.; Yu, J.; Wang, L.; Xie, J.; Shi, S. Spatio-temporal predictions of SST time series in China’s offshore waters using a regional convolution long short-term memory (RC-LSTM) network. Int. J. Remote Sens. 2020, 41, 3368–3389. [Google Scholar] [CrossRef]
- Shi, Z.; Bai, Y.; Jin, X.; Wang, X.; Su, T.; Kong, J. Parallel deep prediction with covariance intersection fusion on nonstationary time series. Knowl.-Based Syst. 2021, 211, 106523. [Google Scholar] [CrossRef]
- Taylor, S.J. Modelling Financial Time Series; World Scientific: Singapore, 2008. [Google Scholar]
- Kong, J.; Wang, H.; Wang, X.; Jin, X.; Fang, X.; Lin, S. Multi-stream hybrid architecture based on cross-level fusion strategy for fine-grained crop species recognition in precision agriculture. Comput. Electron. Agric. 2021, 185, 106134. [Google Scholar] [CrossRef]
- Kong, J.; Wang, H.; Yang, C.; Jin, X.; Zuo, M.; Zhang, X. Fine-grained pests & diseases recognition via Spatial Feature-enhanced attention architecture with high-order pooling representation for Precision Agriculture Practice. Agriculture 2022, 2022, 1592804. [Google Scholar]
- Jin, X.B.; Zheng, W.Z.; Kong, J.L.; Wang, X.Y.; Bai, Y.T.; Su, T.L.; Lin, S. Deep-learning forecasting method for electric power load via attention-based encoder-decoder with Bayesian optimization. Energies 2021, 14, 1596. [Google Scholar] [CrossRef]
- Jin, X.-B.; Zheng, W.-Z.; Kong, J.-L.; Wang, X.-Y.; Zuo, M.; Zhang, Q.-C.; Lin, S. Deep-learning temporal predictor via bidirectional self-attentive encoder–decoder framework for IOT-based environmental sensing in intelligent greenhouse. Agriculture 2021, 11, 802. [Google Scholar] [CrossRef]
- Jin, X.B.; Gong, W.T.; Kong, J.L.; Bai, Y.T.; Su, T.L. A variational Bayesian deep network with data self-screening layer for massive time-series data forecasting. Entropy 2022, 24, 355. [Google Scholar] [CrossRef]
- Kong, J.; Yang, C.; Wang, J.; Wang, X.; Zuo, M.; Jin, X.; Lin, S. Deep-stacking network approach by multisource data mining for hazardous risk identification in iot-based intelligent food management systems. Comput. Intell. Neurosci. 2021, 2021, 1194565. [Google Scholar] [CrossRef]
- Jin, Z.C.; Zhou, X.H.; He, J. Statistical methods for dealing with publication bias in meta-analysis. Stat. Med. 2015, 34, 343–360. [Google Scholar] [CrossRef]
- Austin, P.C. Comparing paired vs. non-paired statistical methods of analyses when making inferences about absolute risk reductions in propensity-score matched samples. Stat. Med. 2011, 30, 1292–1301. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yariyan, P.; Janizadeh, S.; Van Phong, T.; Nguyen, H.D.; Costache, R.; Van Le, H.; Pham, B.T.; Pradhan, B.; Tiefenbacher, J.P. Improvement of best first decision trees using bagging and dagging ensembles for flood probability mapping. Water Resour. Manag. 2020, 34, 3037–3053. [Google Scholar] [CrossRef]
- Daneshfaraz, R.; Bagherzadeh, M.; Esmaeeli, R.; Norouzi, R.; Abraham, J. Study of the performance of support vector machine for predicting vertical drop hydraulic parameters in the presence of dual horizontal screens. Water Supply 2021, 21, 217–231. [Google Scholar] [CrossRef]
- Tang, W.H.; Röllin, A. Model identification for ARMA time series through convolutional neural networks. Decis. Support Syst. 2021, 146, 113544. [Google Scholar] [CrossRef]
- Abueidda, D.W.; Koric, S.; Sobh, N.A.; Sehitoglu, H. Deep learning for plasticity and thermo-viscoplasticity. Int. J. Plast. 2021, 136, 102852. [Google Scholar] [CrossRef]
- Jin, X.-B.; Gong, W.-T.; Kong, J.-L.; Bai, Y.-T.; Su, T.-L. PFVAE: A planar flow-based variational auto-encoder prediction model for time series data. Mathematics 2022, 10, 610. [Google Scholar] [CrossRef]
- Cho, K.; Kim, Y. Improving streamflow prediction in the WRF-Hydro model with LSTM networks. J. Hydrol. 2022, 605, 127297. [Google Scholar] [CrossRef]
- Chen CL, P.; Liu, Z.; Feng, S. Universal approximation capability of broad learning system and its structural variations. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 1191–1204. [Google Scholar] [CrossRef]
- Shi, Z.; Bai, Y.; Jin, X.; Wang, X.; Su, T.; Kong, J. Deep Prediction Model Based on Dual Decomposition with Entropy and Frequency Statistics for Nonstationary Time Series. Entropy 2022, 24, 360. [Google Scholar] [CrossRef]
- Mohammadpour, M.; Soltani, A.R. Forward Moving Average Representation in Multivariate MA (1) Processes. Commun. Stat. Theory Methods 2010, 39, 729–737. [Google Scholar] [CrossRef]
- Singh, S.N.; Mohapatra, A. Repeated wavelet transform based ARIMA model for very short-term wind speed prediction. Renew. Energy 2019, 136, 758–768. [Google Scholar]
- Akbar, S.B.; Govindarajan, V.; Thanupillai, K. Prediction Bitcoin price using time opinion mining and bi-directional GRU. J. Intell. Fuzzy Syst. 2022, 42, 1–9. [Google Scholar]
- Ma, M.; Liu, C.; Wei, R.; Liang, B.; Dai, J. Predicting machine’s performance record using the stacked long short-term memory (LSTM) neural networks. J. Appl. Clin. Med. Phys. 2022, 23, e13558. [Google Scholar] [CrossRef] [PubMed]
- Gallicchio, C.; Micheli, A.; Silvestri, L. Local lyapunov exponents of deep echo state networks. Neurocomputing 2018, 298, 34–45. [Google Scholar] [CrossRef]
- Kong, J.; Yang, C.; Xiao, Y.; Lin, S.; Ma, K.; Zhu, Q. A Graph-Related High-Order Neural Network Architecture via Feature Aggregation Enhancement for Identification Application of Diseases and Pests. Comput. Intell. Neuro-Sci. 2022, 2022, 4391491. [Google Scholar] [CrossRef]
- Jin, X.-B.; Yu, X.-H.; Su, T.-L.; Yang, D.-N.; Bai, Y.-T.; Kong, J.-L.; Wang, L. Distributed deep fusion predictor for a multi-sensor system based on causality entropy. Entropy 2021, 23, 219. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef] [Green Version]
- Bai, Y.; Zhao, Z.; Wang, X.; Jin, X.; Zhou, B. Continuous Positioning with Recurrent Auto-Regressive Neural Network for Unmanned Surface Vehicles in GPS Outages. Neural Process. Lett. 2022, 54, 1413–1434. [Google Scholar] [CrossRef]
- Chen, C.L.P.; Liu, Z. Broad learning system: An effective and efficient incremental learning system without the need for deep architecture. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 10–24. [Google Scholar] [CrossRef]
- Jin, X.; Zhang, J.; Kong, J.; Su, T.; Bai, Y. A reversible automatic selection normalization (RASN) deep network for predicting in the smart agriculture system. Agronomy 2022, 12, 591. [Google Scholar] [CrossRef]
- Li, H.; Sun, W.; Zhou, Z.; Li, C.; Zhang, S. Human Sitting-Posture Recognition Based on the Cascade of Feature Mapping Nodes Broad Learning System. J. Nantong Univ. (Nat. Sci. Ed.) 2020, 19, 28–33. [Google Scholar]
- Feng, S.; Chen, C.L.P.; Xu, L.; Liu, Z. On the Accuracy–Complexity Tradeoff of Fuzzy Broad Learning System. IEEE Trans. Fuzzy Syst. 2020, 29, 2963–2974. [Google Scholar] [CrossRef]
- Liu, W.; Bai, Y.; Jin, X.; Wang, X.; Su, T.; Kong, J. Broad Echo State Network with Reservoir Pruning for Nonstationary Time Series Prediction. Comput. Intell. Neurosci. 2022, 2022, 3672905. [Google Scholar] [CrossRef] [PubMed]
- Li, D.; Han, M.; Wang, J. Chaotic time series prediction based on a novel robust echo state network. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 787–799. [Google Scholar] [CrossRef] [PubMed]
- Hoerl, A.E.; Kennard, R.W. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Jaeger, H. Adaptive nonlinear system identification with echo state networks. Adv. Neural Inf. Proces. Syst. 2002, 15, 609–616. [Google Scholar]
- Li, D.; Liu, F.; Qiao, J. Research on hierarchical modular ESN and its application. In Proceedings of the 2015 34th Chinese Control Conference (CCC), Hangzhou, China, 28–30 July 2015; pp. 2129–2133. [Google Scholar]
- Jordan, S.; Philips, A.Q. Cointegration testing and dynamic simulations of autoregressive distributed lag models. Stata J. 2018, 18, 902–923. [Google Scholar] [CrossRef] [Green Version]
- Erdem, E.; Shi, J. ARMA based approaches for prediction the tuple of wind speed and direction. Appl. Energy 2011, 88, 1405–1414. [Google Scholar] [CrossRef]
- Xie, C.; Bijral, A.; Ferres, J.L. Nonstop: A nonstationary online prediction method for time series. IEEE Signal Proces. Lett. 2018, 25, 1545–1549. [Google Scholar] [CrossRef] [Green Version]
- Osogami, T. Second order techniques for learning time series with structural breaks. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 9259–9267. [Google Scholar]
- Dolado, J.J.; Gonzalo, J.; Mayoral, L. A fractional Dickey–Fuller test for unit roots. Econometrica 2002, 70, 1963–2006. [Google Scholar] [CrossRef] [Green Version]
- Bisaglia, L.; Procidano, I. On the power of the augmented Dickey–Fuller test against fractional alternatives using bootstrap. Econ. Lett. 2002, 77, 343–347. [Google Scholar] [CrossRef]
- Xie, Y.; Liu, S.; Fang, H.; Wang, J. Global autocorrelation test based on the Monte Carlo method and impacts of eliminating nonstationary components on the global autocorrelation test. Stoch. Environ. Res. Risk Assess. 2020, 34, 1645–1658. [Google Scholar] [CrossRef]
- Thornhill, N.F.; Huang, B.; Zhang, H. Detection of multiple oscillations in control loops. J. Process Control 2003, 13, 91–100. [Google Scholar] [CrossRef] [Green Version]
- Ni, T.; Wang, L.; Zhang, P.; Wang, B.; Li, W. Daily tourist flow forecasting using SPCA and CNN-LSTM neural network. Concurr. Comput. Pract. Exp. 2021, 33, e5980. [Google Scholar] [CrossRef]
- Liao, Y.; Li, H. Deep echo state network with reservoirs of multiple activation functions for time-series forecasting. Sādhanā 2019, 44, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Twycross, J.; Garibaldi, J.M. A new accuracy measure based on bounded relative error for time series forecasting. PLoS ONE 2017, 12, e0174202. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.; Alizamir, M.; Zounemat-Kermani, M.; Kisi, O.; Singh, V.P. Assessing the biochemical oxygen demand using neural networks and ensemble tree approaches in South Korea. J. Environ. Manag. 2020, 270, 110834. [Google Scholar] [CrossRef]




















| Categories | Models | Features | Existing Problems |
|---|---|---|---|
| Statistical approaches | AR [39] | It treats the subsequent data as a linear combination of the data. | It is difficult to reduce the value of the loss function, which is not applicable in real-world data. |
| ARMA [40] | It combines the advantages of the AR model and MA model. | ||
| ARIMA [22] | A differential process is added to ARMA. | ||
| Typical deep learning networks | LSTM [24] | It improves the problems of gradient disappearance and explosion in RNN. | Time cost and computing resources increase. |
| GRU [23] | It reduces the number of gate units in the LSTM. | ||
| DeepESN [25] | It connects multiple echo state networks vertically with the error backpropagation training mechanism. | ||
| Broad learning system | BLS [19] | It is with horizontal scaling of the neural units. The incremental learning algorithms are designed for faster training. | The prediction accuracy is relatively low on complex time series data. |
| Model | Training Time(s) | SMAPE | MAE | RMSE | R2 |
|---|---|---|---|---|---|
| ESN | 3.7242 | 0.0525 | 0.0512 | 0.0634 | 0.9989 |
| BLS | 0.5952 | 0.0369 | 0.0326 | 0.0412 | 0.9995 |
| GRU | 71.6812 | 0.0360 | 0.0360 | 0.0409 | 0.9996 |
| CMBLS | 0.4175 | 0.0381 | 0.0335 | 0.0426 | 0.9995 |
| CMBESN | 109.6323 | 0.0349 | 0.0325 | 0.0405 | 0.9996 |
| Model | Training Time(s) | SMAPE | MAE | RMSE | R2 |
|---|---|---|---|---|---|
| ESN | 2.9911 | 0.2937 | 28.8061 | 40.8411 | 0.0881 |
| BLS | 0.1120 | 0.3507 | 57.5135 | 62.1322 | 0.4730 |
| GRU | 65.9890 | 0.0889 | 12.5609 | 26.2116 | 0.6062 |
| CMBLS | 0.0717 | 0.1249 | 13.9013 | 24.8272 | 0.4889 |
| CMBESN | 58.9831 | 0.1646 | 11.1110 | 13.5795 | 0.8959 |
| Model | SMAPE | MAE | RMSE | R2 |
|---|---|---|---|---|
| CMBESN | 0.0349 | 0.0325 | 0.0405 | 0.9996 |
| CMBESN-OE | 0.0357 | 0.0319 | 0.0401 | 0.9996 |
| Model | SMAPE | MAE | RMSE | R2 |
|---|---|---|---|---|
| CMBESN | 0.1646 | 11.1110 | 13.5795 | 0.8959 |
| CMBESN-OE | 0.0721 | 6.5313 | 8.3923 | 0.9602 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.-J.; Bai, Y.-T.; Jin, X.-B.; Kong, J.-L.; Su, T.-L. A Novel Broad Echo State Network for Time Series Prediction: Cascade of Mapping Nodes and Optimization of Enhancement Layer. Appl. Sci. 2022, 12, 6396. https://doi.org/10.3390/app12136396
Liu W-J, Bai Y-T, Jin X-B, Kong J-L, Su T-L. A Novel Broad Echo State Network for Time Series Prediction: Cascade of Mapping Nodes and Optimization of Enhancement Layer. Applied Sciences. 2022; 12(13):6396. https://doi.org/10.3390/app12136396
Chicago/Turabian StyleLiu, Wen-Jie, Yu-Ting Bai, Xue-Bo Jin, Jian-Lei Kong, and Ting-Li Su. 2022. "A Novel Broad Echo State Network for Time Series Prediction: Cascade of Mapping Nodes and Optimization of Enhancement Layer" Applied Sciences 12, no. 13: 6396. https://doi.org/10.3390/app12136396
APA StyleLiu, W. -J., Bai, Y. -T., Jin, X. -B., Kong, J. -L., & Su, T. -L. (2022). A Novel Broad Echo State Network for Time Series Prediction: Cascade of Mapping Nodes and Optimization of Enhancement Layer. Applied Sciences, 12(13), 6396. https://doi.org/10.3390/app12136396