
Position Control of a Mobile Robot through Deep Reinforcement Learning

 , , ,
, , ,  and
and
Abstract
:1. Introduction
2. Reinforcement Learning
2.1. Deep Q-Network (DQN)
| Algorithm 1 Deep Q-Learning algorithm with Experience Replay [44] |
do do end for end for |
2.2. Deep Deterministic Policy Gradient (DDPG)
| Algorithm 2 Deep Deterministic Policy Gradient algorithm [33] |
| with weights , respectively do for action exploration do according to the current policy and exploration noise and observe reward and observe new state Update the actor policy using the sampled policy gradient: Update the target networks: end for end for |
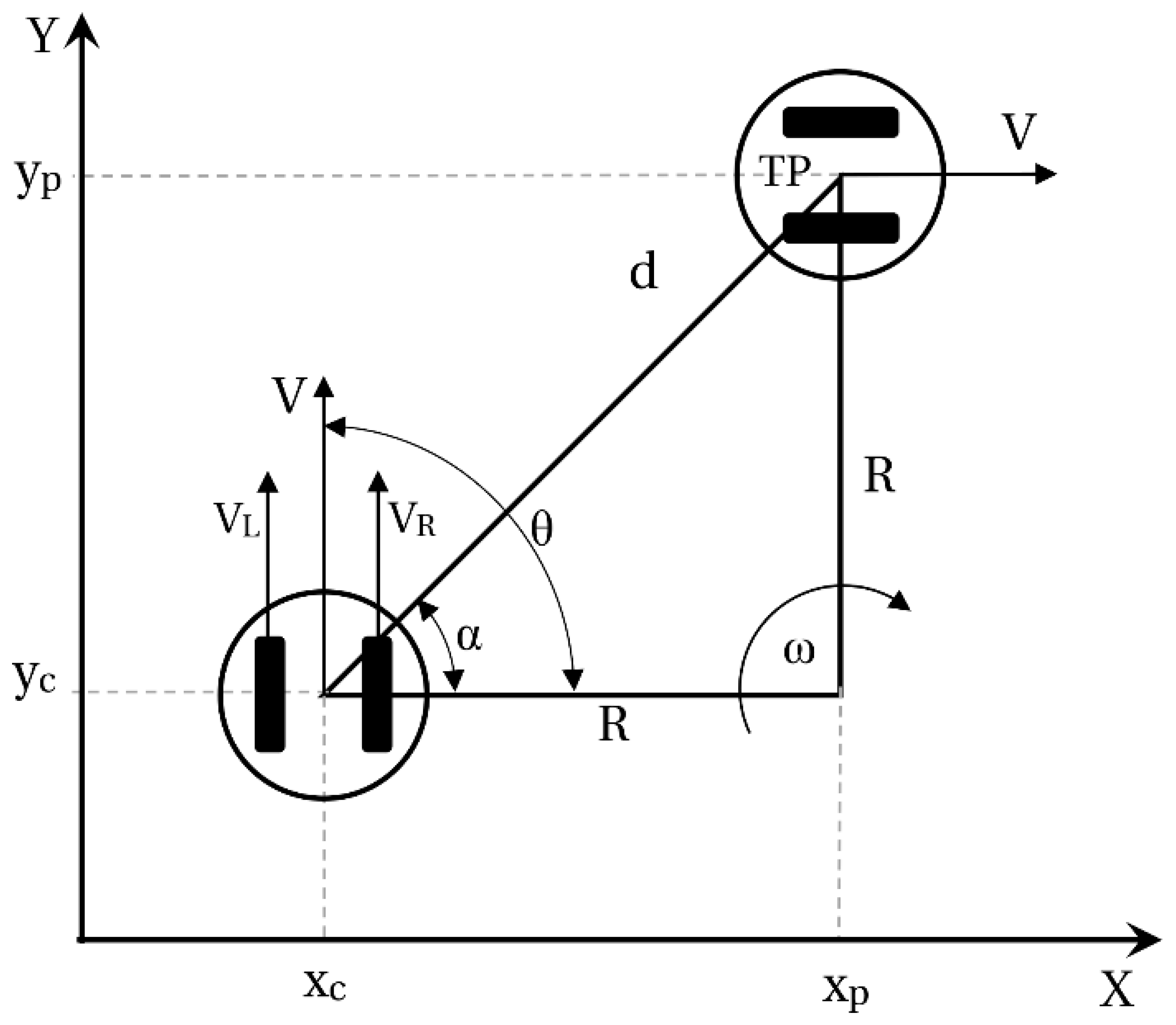
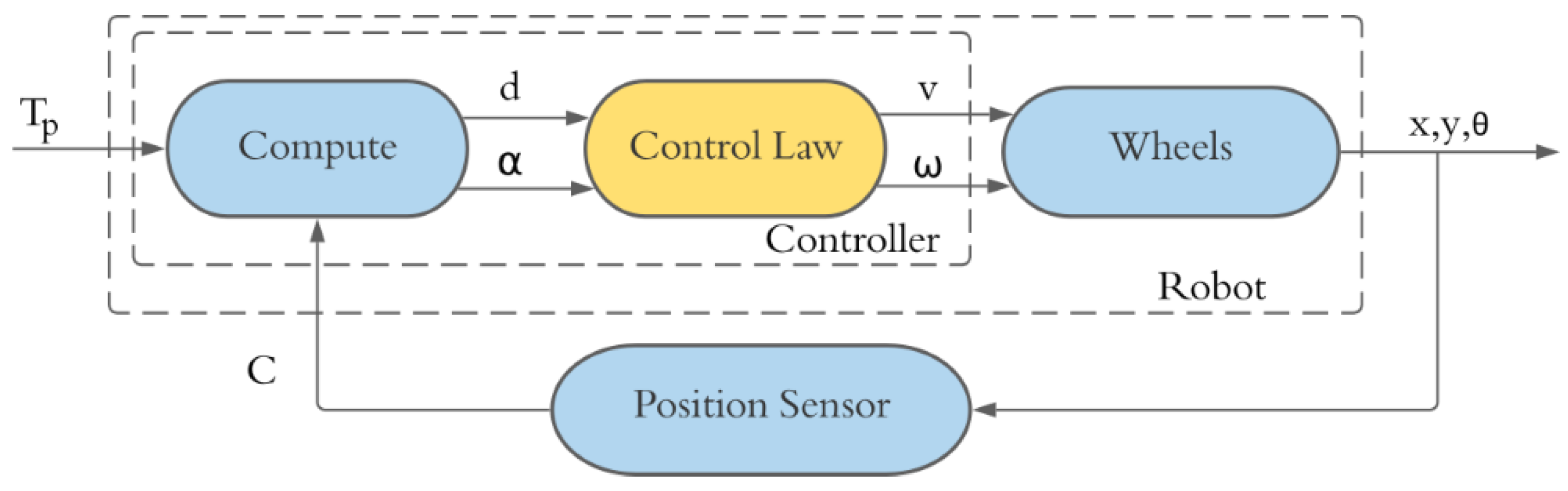
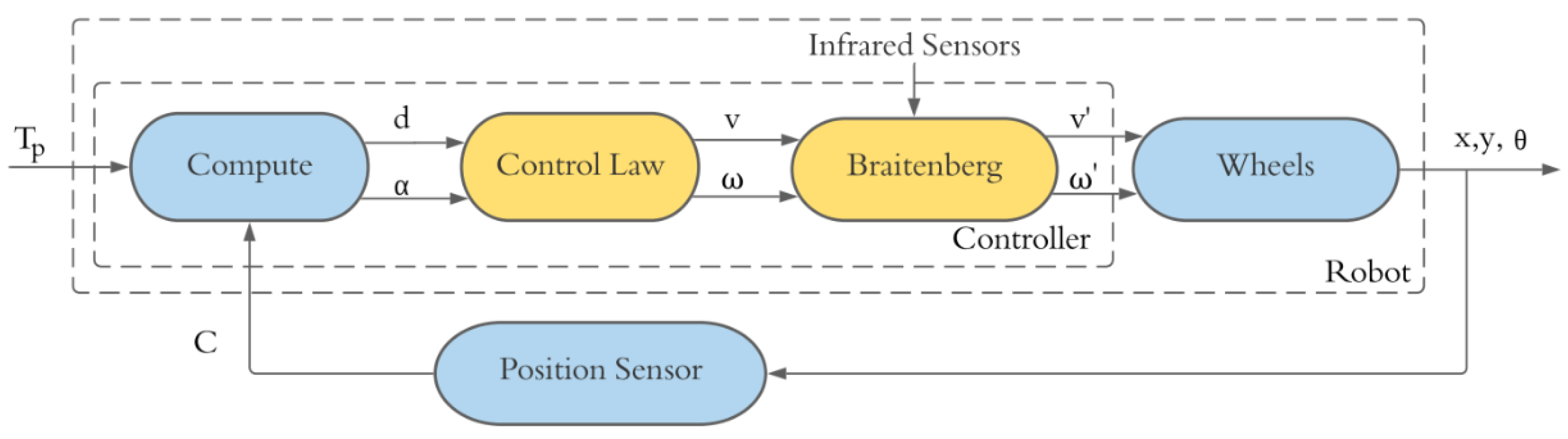
3. Position Control
4. Simulated Environment and Mobile Robot
4.1. Robot Khepera IV
4.2. CoppeliaSim
4.3. Environments
5. Experiments and Results
5.1. Experiments
5.1.1. Khepera Robot Position Control
5.1.2. Position Control with Obstacles
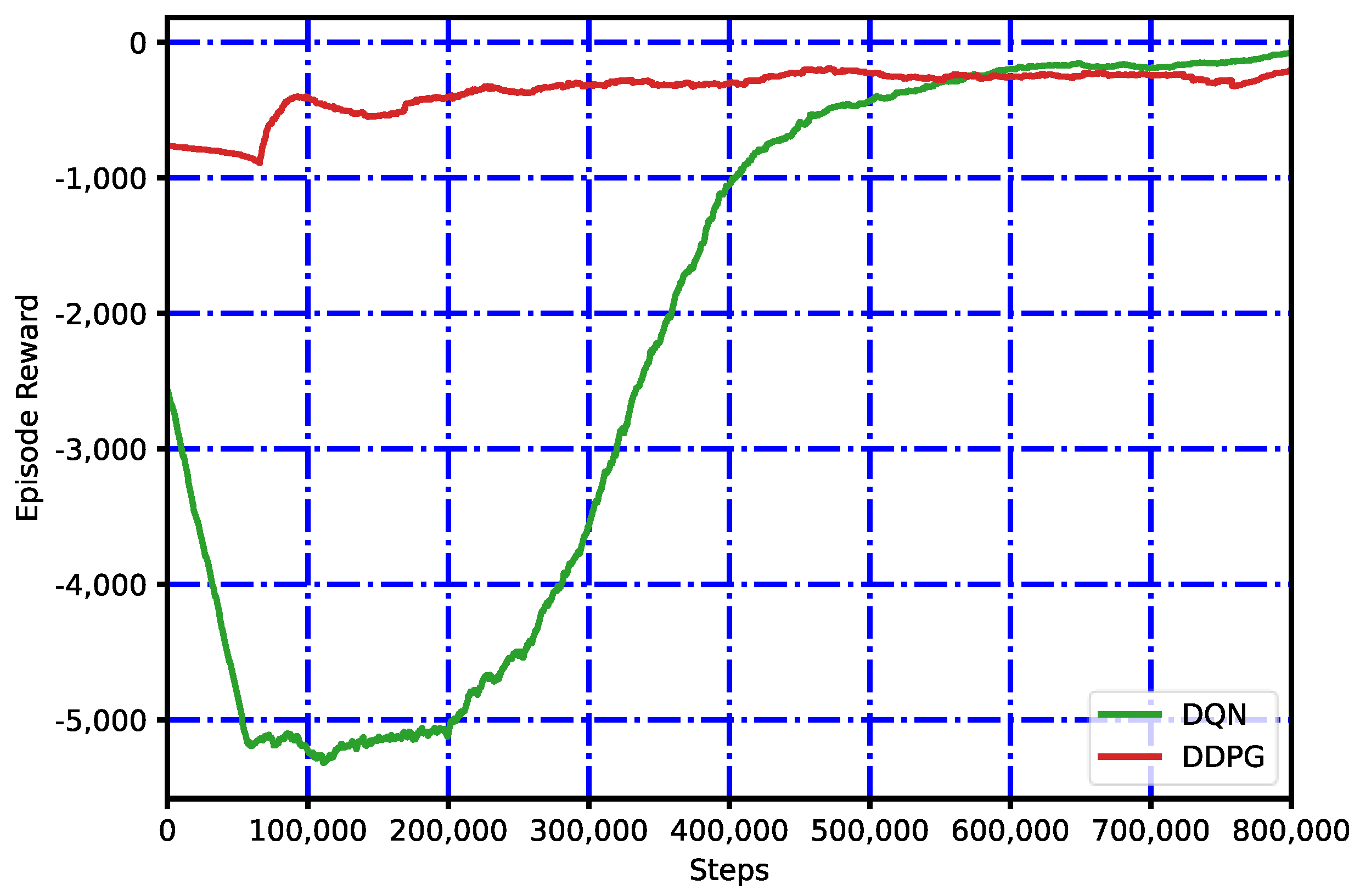
5.2. Training of RL Agents
5.3. Results
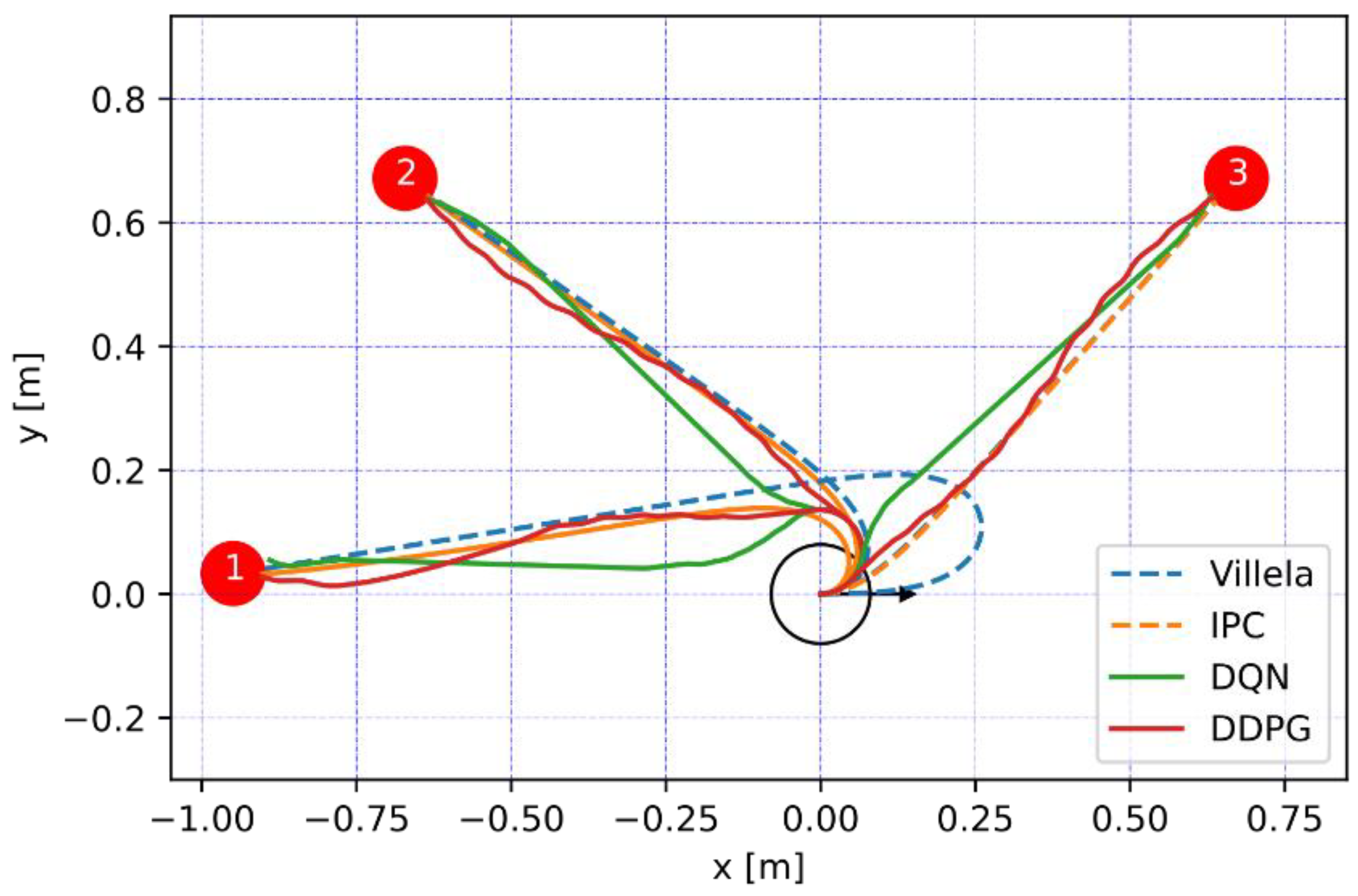
5.3.1. One Target Point
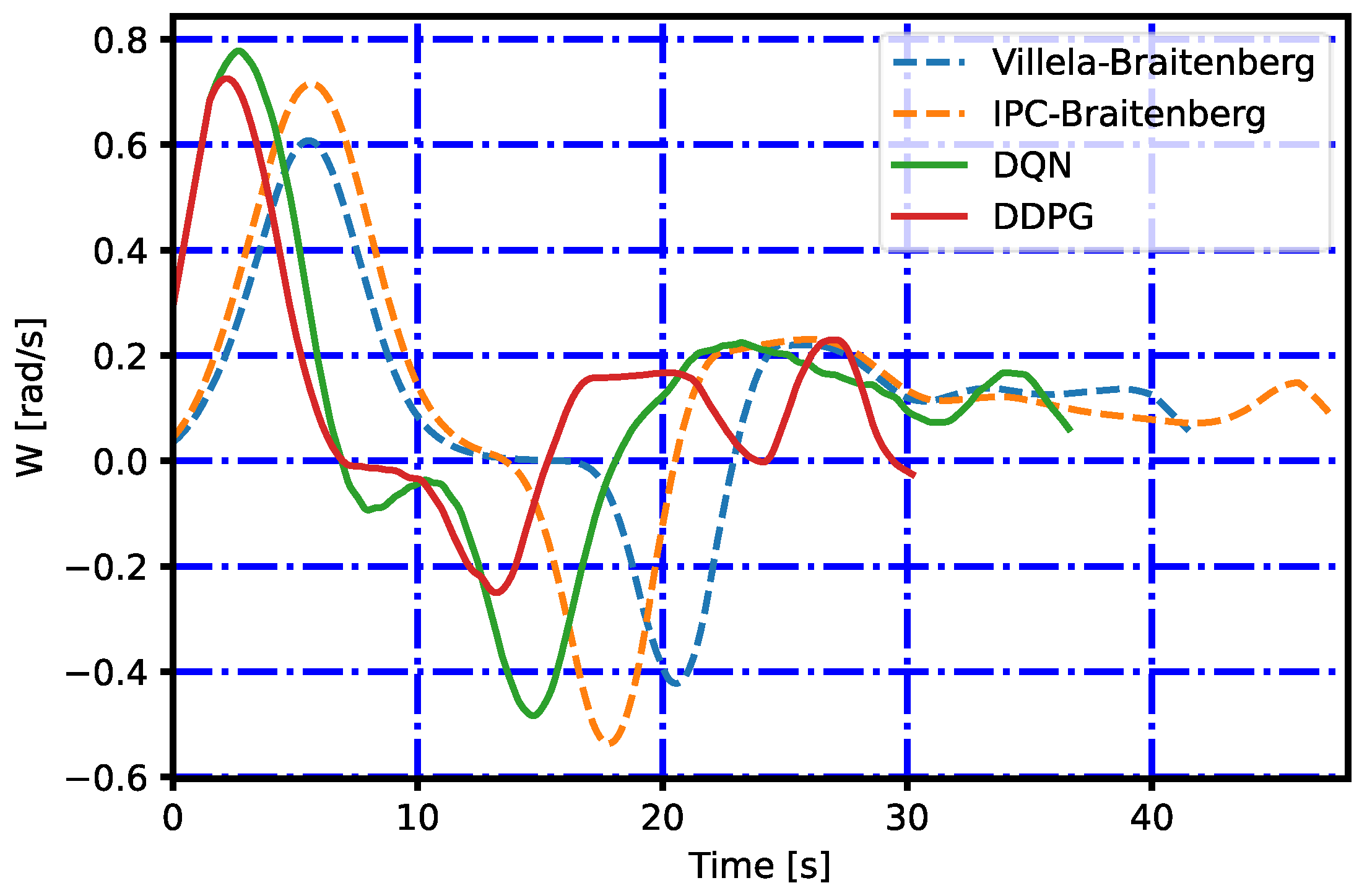
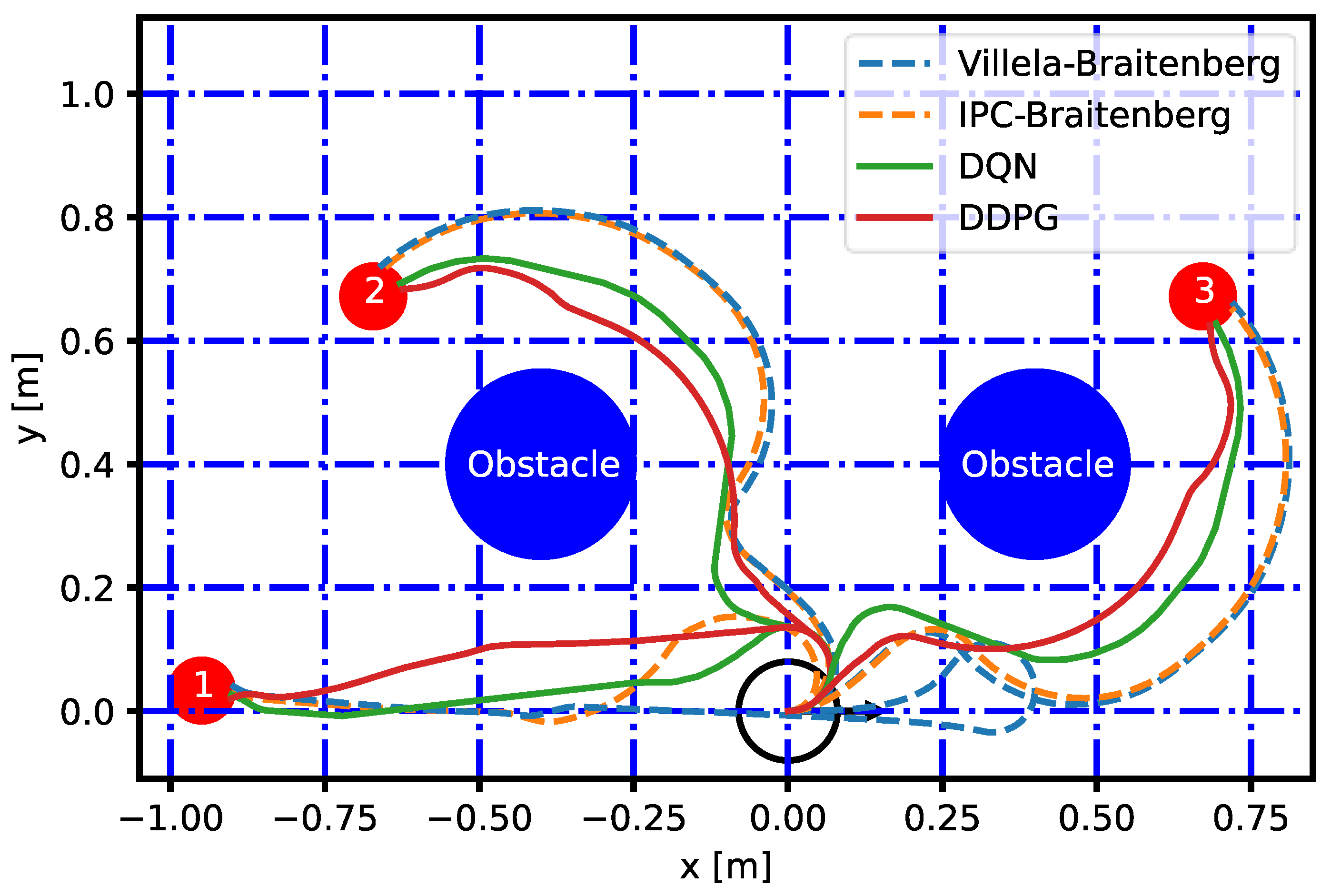
5.3.2. Multiple Target Points
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Klancar, G.; Zdesar, A.; Blazic, S.; Skrjanc, I. Introduction to Mobile Robotics, in Wheeled Mobile Robotics: From Funda-Mentals towards Autonomous Systems; Butterworth-Heinemann: Oxford, UK, 2017; pp. 1–11. [Google Scholar]
- Fabregas, E.; Farias, G.; Peralta, E.; Vargas, H.; Dormido, S. Teaching control in mobile robotics with V-REP and a Khepera IV library. In Proceedings of the 2016 IEEE Conference on Control Applications, Buenos Aires, Argentina, 19–22 September 2016; pp. 821–826. [Google Scholar] [CrossRef]
- Villela, V.J.; Parkin, R.; Parra, M.; Dorador, J.M.; Dorador, J.M.; Guadarrama, M.J. A wheeled mobile robot with obstacle avoidance capability. Ing. Mecánica Tecnología Desarro. 2004, 1, 159–166. [Google Scholar]
- Fabregas, E.; Farias, G.; Aranda-Escolastico, E.; Garcia, G.; Chaos, D.; Dormido-Canto, S.; Bencomo, S.D. Simulation and Experimental Results of a New Control Strategy For Point Stabilization of Nonholonomic Mobile Robots. IEEE Trans. Ind. Electron. 2019, 67, 6679–6687. [Google Scholar] [CrossRef]
- Alajlan, A.M.; Almasri, M.M.; Elleithy, K.M. Multi-sensor based collision avoidance algorithm for mobile robot. In Proceedings of the 2015 Long Island Systems, Applications and Technology, Farmingdale, NY, USA, 1 May 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Almasri, M.M.; Alajlan, A.M.; Elleithy, K.M. Trajectory Planning and Collision Avoidance Algorithm for Mobile Robotics System. IEEE Sens. J. 2016, 16, 5021–5028. [Google Scholar] [CrossRef]
- Almasri, M.; Elleithy, K.; Alajlan, A. Sensor Fusion Based Model for Collision Free Mobile Robot Navigation. Sensors 2015, 16, 24. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Bai, W.; Liu, P.X. Finite-time adaptive fault-tolerant control for nonlinear systems with multiple faults. IEEE/CAA J. Autom. Sin. 2019, 6, 1417–1427. [Google Scholar] [CrossRef]
- Chen, M.; Wang, H.; Liu, X. Adaptive Fuzzy Practical Fixed-Time Tracking Control of Nonlinear Systems. IEEE Trans. Fuzzy Syst. 2019, 29, 664–673. [Google Scholar] [CrossRef]
- Peng, S.; Shi, W. Adaptive Fuzzy Output Feedback Control of a Nonholonomic Wheeled Mobile Robot. IEEE Access 2018, 6, 43414–43424. [Google Scholar] [CrossRef]
- Ludvi, E.A.; Bellemare, M.G.; Pearson, K.G. A Primer on Reinforcement Learning in the Brain: Psychological, Computational, and Neural Perspectives, Computational Neuroscience for Advancing Artificial Intelligence: Models, Methods and Applications; Medical Information Science: Hershey, NY, USA, 2011. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef]
- OpenAI Five. OpenAI Five Defeats Dota 2 World Champions. Available online: https://openai.com/blog/openai-five-defeats-dota-2-world-champions/, (accessed on 12 July 2022).
- Schrittwieser, J.; Antonoglou, I.; Hubert, T.; Simonyan, K.; Sifre, L.; Schmitt, S.; Guez, A.; Lockhart, E.; Hassabis, D.; Graepel, T.; et al. Mastering Atari, Go, chess and shogi by planning with a learned model. Nature 2020, 588, 604–609. [Google Scholar] [CrossRef]
- Andrychowicz, O.M.; Baker, B.; Chociej, M.; Józefowicz, R.; McGrew, B.; Pachocki, J.; Petron, A.; Plappert, M.; Powell, G.; Ray, A.; et al. Learning dexterous in-hand manipulation. Int. J. Robot. Res. 2019, 39, 3–20. [Google Scholar] [CrossRef] [Green Version]
- Chebotar, Y.; Handa, A.; Makoviychuk, V.; Macklin, M.; Issac, J.; Ratliff, N.; Fox, D. Closing the Sim-to-Real Loop: Adapting Simulation Randomization with Real World Experience. arXiv 2019, arXiv:1810.05687v4. [Google Scholar] [CrossRef] [Green Version]
- Zhao, W.; Queralta, J.P.; Qingqing, L.; Westerlund, T. Towards Closing the Sim-to-Real Gap in Collaborative Multi-Robot Deep Reinforcement Learning. arXiv 2020, arXiv:2008.07875v1. [Google Scholar] [CrossRef]
- Hu, H.; Zhang, K.; Tan, A.H.; Ruan, M.; Agia, C.G.; Nejat, G. A Sim-to-Real Pipeline for Deep Reinforcement Learning for Autonomous Robot Navigation in Cluttered Rough Terrain. IEEE Robot. Autom. Lett. 2021, 6, 6569–6576. [Google Scholar] [CrossRef]
- Niu, H.; Ji, Z.; Arvin, F.; Lennox, B.; Yin, H.; Carrasco, J. Accelerated Sim-to-Real Deep Reinforcement Learning: Learning Collision Avoidance from Human Playerar. arXiv 2021, arXiv:2102.10711v2. [Google Scholar] [CrossRef]
- Smart, W.; Kaelbling, L.P. Effective reinforcement learning for mobile robots. In Proceedings of the 2002 IEEE International Conference on Robotics and Automation, Washington, DC, USA, 11–15 May 2002; Volume 4, pp. 3404–3410. [Google Scholar] [CrossRef]
- Surmann, H.; Jestel, C.; Marchel, R.; Musberg, F.; Elhadj, H.; Ardani, M. Deep Reinforcement learning for real autonomous mobile robot navigation in indoor environments. arXiv 2020, arXiv:2005.13857v1. [Google Scholar]
- Farias, G.; Garcia, G.; Montenegro, G.; Fabregas, E.; Dormido-Canto, S.; Dormido, S. Reinforcement Learning for Position Control Problem of a Mobile Robot. IEEE Access 2020, 8, 152941–152951. [Google Scholar] [CrossRef]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292, Thecnical Note. [Google Scholar]
- Ganapathy, V.; Soh, C.Y.; Lui, W.L.D. Utilization of Webots and Khepera II as a platform for Neural Q-Learning controllers. In Proceedings of the 2009 IEEE Symposium on Industrial Electronics & Applications, Kuala Lumpur, Malaysia, 4–6 October 2009; Volume 2, pp. 783–788. [Google Scholar] [CrossRef]
- Huang, B.-Q.; Cao, G.-Y.; Guo, M. Reinforcement Learning Neural Network to the Problem of Autonomous Mobile Robot Obstacle Avoidance. In Proceedings of the 2005 International Conference on Machine Learning and Cybernetics, Guangzhou, China, 18–21 August 2005; Volume 1, pp. 85–89. [Google Scholar] [CrossRef]
- Hagen, S.T.; Kröse, B. Neural Q-learning. Neural Comput. Appl. 2003, 12, 81–88. [Google Scholar] [CrossRef]
- Kulathunga, G. A Reinforcement Learning based Path Planning Approach in 3D Environment. arXiv 2022, arXiv:2105.10342v2. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Y.; Lou, P.; Yan, J.; Liu, N. Deep Reinforcement Learning based Path Planning for Mobile Robot in Unknown Environment. J. Phys. Conf. Ser. 2020, 1576, 012009. [Google Scholar] [CrossRef]
- Wang, B.; Liu, Z.; Li, Q.; Prorok, A. Mobile Robot Path Planning in Dynamic Environments Through Globally Guided Reinforcement Learning. IEEE Robot. Autom. Lett. 2020, 5, 6932–6939. [Google Scholar] [CrossRef]
- Duguleana, M.; Mogan, G. Neural networks based reinforcement learning for mobile robots obstacle avoidance. Expert Syst. Appl. 2016, 62, 104–115. [Google Scholar] [CrossRef]
- Tai, L.; Paolo, G.; Liu, M. Virtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless navigation. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 31–36. [Google Scholar]
- Lillicrap, T.; Hunt, J.; Pritzel, A.; Hees, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous Control with Deep Reinforcement Learning; International Conference on Learning Representation: London, UK, 2016. [Google Scholar]
- Alyasin, A.; Abbas, E.I.; Hasan, S.D. An Efficient Optimal Path Finding for Mobile Robot Based on Dijkstra Method. In Proceedings of the 2019 4th Scientific International Conference Najaf (SICN), Al-Najef, Iraq, 29–30 April 2019; pp. 11–14. [Google Scholar] [CrossRef]
- Yufka, A.; Parlaktuna, O. Performance Comparison of BUG Algorithms for Mobile Robots. In Proceedings of the 5th International Advanced Technologies Symposium, Karabuk, Turkey, 7–9 October 2020. [Google Scholar] [CrossRef]
- ElHalawany, B.M.; Abdel-Kader, H.M.; TagEldeen, A.; Elsayed, A.E.; Nossair, Z.B. Modified A* algorithm for safer mobile robot navigation. In Proceedings of the 2013 5th International Conference on Modelling, Identification and Control (ICMIC), Cairo, Egypt, 31 August–2 September 2013; pp. 74–78. [Google Scholar]
- Team, K.; Tharin, J.; Lambercy, F.; Caroon, T. Khepera IV User Manual; K-Team: Vallorbe, Switzerland, 2019. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning, Deepmind. arXiv 2013, arXiv:1312.5602, 1–9. [Google Scholar]
- Rohmer, E.; Singh, S.; Freese, M. CoppeliaSim (formely V-Rep): A Verstile and Scalable Robot Simulation Framework. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013. [Google Scholar]
- Brockman, G.; Cheung, V.; Patterson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540v1. [Google Scholar]
- Puterman, M.L. Model formulation. In Markov Decision Processes: Discrete Stochastic Dynamic Programming, 1st ed.; John Wiley & Sons: Hoboken, NJ, USA, 2005; pp. 17–32. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Berger-Tal, O.; Nathan, J.; Meron, E.; Saltz, D. The Exploration-Exploitation Dilemma: A Multidisciplinary Framework. PLoS ONE 2014, 9, e95693. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Zagoraiou, M.; Antognini, A.B. Optimal designs for parameter estimation of the Ornstein-Uhlenbeck process. Appl. Stoch. Model. Bus. Ind. 2008, 25, 583–600. [Google Scholar] [CrossRef]
- Yang, X.; Patel, R.V.; Moallem, M. A Fuzzy–Braitenberg Navigation Strategy for Differential Drive Mobile Robots. J. Intell. Robot. Syst. 2006, 47, 101–124. [Google Scholar] [CrossRef]
- Farias, G.; Fabregas, E.; Peralta, E.; Torres, E.; Dormido, S. A Khepera IV library for robotic control education using V-REP. IFAC-PapersOnLine 2017, 50, 9150–9155. [Google Scholar] [CrossRef]
- Remote API. Coppelia Robotics. Available online: https://www.coppeliarobotics.com/helpFiles/en/remoteApiOverview.htm, (accessed on 12 July 2022).
- McNally, T. Keras RL2. 2019. Available online: https://github.com/wau/keras-rl2; (accessed on 12 July 2022).
- Farias, G.; Fabregas, E.; Torres, E.; Bricas, G.; Dormido-Canto, S.; Dormido, S. A Distributed Vision-Based Navigation System for Khepera IV Mobile Robots. Sensors 2020, 20, 5409. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Patel, R.V.; Moallem, M. A Fuzzy-Braitenberg Navigation Strategy for Differential Drive Mobile Robots. IFAC Proc. Vol. 2004, 37, 97–102. [Google Scholar] [CrossRef]
- Farias, G.; Fabregas, E.; Peralta, E.; Vargas, H.; Dormido-Canto, S.; Dormido, S. Development of an Easy-to-Use Multi-Agent Platform for Teaching Mobile Robotics. IEEE Access 2019, 7, 55885–55897. [Google Scholar] [CrossRef]
- Li, S.; Ding, L.; Gao, H.; Chen, C.; Liu, Z.; Deng, Z. Adaptive neural network tracking control-based reinforcement learning for wheeled mobile robots with skidding and slipping. Neurocomputing 2018, 283, 20–30. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347v2. [Google Scholar]
- Hessel, M.; Danihelka, I.; Viola, F.; Guez, A.; Schmitt, S.; Sifre, L.; Weber, T.; Silver, D.; Hasselt, H. Muesli: Combining Improvements in Policy Optimization. arXiv 2021, arXiv:2104.06159v1. [Google Scholar]
- Petroski, F.; Madhavan, V.; Conti, E.; Lehman, J.; Stanley, K.O.; Clune, J. Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning. arXiv 2018, arXiv:1712.06567. [Google Scholar]
- Niu, B.; Li, H.; Qin, T.; Karimi, H.R. Adaptive NN Dynamic Surface Controller Design for Nonlinear Pure-Feedback Switched Systems With Time-Delays and Quantized Input. IEEE Trans. Syst. Man Cybern. Syst. 2017, 48, 1676–1688. [Google Scholar] [CrossRef]
- Niu, B.; Li, H.; Zhang, Z.; Li, J.; Hayat, T.; Alsaadi, F.E. Adaptive Neural-Network-Based Dynamic Surface Control for Stochastic Interconnected Nonlinear Nonstrict-Feedback Systems With Dead Zone. IEEE Trans. Syst. Man Cybern. Syst. 2018, 49, 1386–1398. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Observation | Minimum | Maximum |
|---|---|---|---|
| 0 | 0 | 2.82 | |
| 1 | |||
| 2 | Linear velocity in previous step | 0 | 0.05 |
| 3 | Angular velocity in previous step | ||
| 4 to 12 | Distance measurements from eight infrared sensors | 0 | 1 |
| Algorithm | Times (s) |
|---|---|
| Villela | 33.95 |
| IPC | 30.40 |
| DQN | 28.75 |
| DDPG | 27.40 |
| Algorithm | Times (s) |
|---|---|
| Villela–Braitenberg | 41.50 |
| IPC–Braitenberg | 47.55 |
| DQN | 36.45 |
| DDPG | 30.20 |
| Index | Villela | IPC | DQN | DDPG |
|---|---|---|---|---|
| ISE | 30.94 | 22.62 | 19.53 | 18.04 |
| IAE | 28.92 | 23.42 | 21.08 | 19.66 |
| ITSE | 301.92 | 195.92 | 158.02 | 131.99 |
| ITAE | 351.39 | 254.32 | 213.51 | 187.5 |
| Index | Villela–Braitenberg | IPC–Braitenberg | DQN | DDPG |
|---|---|---|---|---|
| ISE | 33.64 | 27.96 | 22.79 | 19.07 |
| IAE | 33.45 | 32.20 | 26.05 | 21.32 |
| ITSE | 386.75 | 343.27 | 233.22 | 154.48 |
| ITAE | 498.41 | 533.28 | 346.31 | 226.06 |
| Algorithm | TP 1 s | TP 2 s | TP 3 s | Mean Time (s) |
|---|---|---|---|---|
| Villela | 30.45 | 20.80 | 18.25 | 23.17 |
| IPC | 25.85 | 20.70 | 18.25 | 21.60 |
| DQN | 22.50 | 20.65 | 18.35 | 20.50 |
| DDPG | 22.60 | 20.55 | 18.30 | 20.48 |
| Algorithm | TP 1 s | TP 2 s | TP 3 s | Mean Time (s) |
|---|---|---|---|---|
| Villela–Braitenberg | 36.45 | 28.85 | 27.95 | 31.08 |
| IPC–Braitenberg | 27.90 | 50.65 | 50.05 | 42.87 |
| DQN | 23.00 | 25.65 | 24.75 | 24.47 |
| DDPG | 22.50 | 23.40 | 22.15 | 22.68 |
| Index | Villela | IPC | DQN | DDPG |
|---|---|---|---|---|
| ISE | 14.52 | 14.44 | 11.43 | 11.30 |
| IAE | 11.68 | 90.5 | 8.08 | 7.95 |
| ITSE | 132.47 | 99.72 | 83.67 | 82.27 |
| ITAE | 89.16 | 58.29 | 45.86 | 44.61 |
| Index | Villela–Braitenberg | IPC–Braitenberg | DQN | DDPG |
|---|---|---|---|---|
| ISE | 20.72 | 19.82 | 13.82 | 12.60 |
| IAE | 17.42 | 13.01 | 9.61 | 8.77 |
| ITSE | 251.91 | 276.84 | 123.23 | 102.00 |
| ITAE | 182.20 | 131.94 | 67.21 | 54.95 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Quiroga, F.; Hermosilla, G.; Farias, G.; Fabregas, E.; Montenegro, G. Position Control of a Mobile Robot through Deep Reinforcement Learning. Appl. Sci. 2022, 12, 7194. https://doi.org/10.3390/app12147194
Quiroga F, Hermosilla G, Farias G, Fabregas E, Montenegro G. Position Control of a Mobile Robot through Deep Reinforcement Learning. Applied Sciences. 2022; 12(14):7194. https://doi.org/10.3390/app12147194
Chicago/Turabian StyleQuiroga, Francisco, Gabriel Hermosilla, Gonzalo Farias, Ernesto Fabregas, and Guelis Montenegro. 2022. "Position Control of a Mobile Robot through Deep Reinforcement Learning" Applied Sciences 12, no. 14: 7194. https://doi.org/10.3390/app12147194
APA StyleQuiroga, F., Hermosilla, G., Farias, G., Fabregas, E., & Montenegro, G. (2022). Position Control of a Mobile Robot through Deep Reinforcement Learning. Applied Sciences, 12(14), 7194. https://doi.org/10.3390/app12147194