1. Introduction
With the development of industrialization, environmental pollution has become a vital problem to be resolved urgently. Compared with the classical physical and chemical approaches, the novel biological methods are more efficient and transparent, causing no secondary pollution, which has become the preference for environmental pollution. The research of Environmental Microorganisms (EMs) is helpful to focus on the interrelationship among microorganisms, pollutants and the environment. It is essential to use microorganisms to degrade the increasingly severe and diverse environmental pollutants effectively.
Yeast is a kind of single-celled eukaryotic microorganism that is highly adaptable to the environment. It is widely applied to produce alcohol, glycerol and organic acids, which are closely linked to the life and production activity of humanity. Until now, yeast have also been used in the treatment of toxic industrial wastewater and solid waste, which plays an important role in treating environmental pollution [
1,
2].
In the research of yeast applied in industrial production and environmental pollution control, biomass is the basic evaluation method and can quantitatively consider the performance of yeast in various tasks [
3]. At present, there are mainly two types of counting methods. The first is manual counting methods, such as plate counting and hemocytometry; another is semi-automatic counting methods, such as flow cytometry [
4,
5].
Manual counting is straightforward and stable to use with high accuracy when the number of cells is limited. However, when the number of cells becomes larger, it will be time-consuming, and the accuracy will be lowered due to the subjective influence of the operator. Semi-automatic counting is more accurate and can obtain ideal results in the case of large biomass; however, it is not portable and requires expensive equipment [
6]. Therefore, these classical methods have non-negligible limitations in practice.
Due to the rapid developments of computer vision and deep learning technologies, computer-assisted image analysis is broadly applied in many research fields, including histopathological image analysis [
7,
8,
9,
10], cytopathological image analysis [
11,
12,
13], object detection [
14,
15,
16], microorganism classification [
17,
18,
19,
20,
21,
22], microorganism segmentation [
23,
24,
25,
26] and microorganism counting [
27,
28].
However, by reviewing the works of microorganism counting from the 1980s until now [
28], we find that, in the process of image segmentation, all existing segmentation approaches use traditional technologies, such as thresholding [
29], edge detection [
30] and watershed [
31]. Most of the deep-learning approaches are only applied for microorganism classification but not for microorganism segmentation in the task of microorganism counting [
32]. Here, we propose a novel
Pixel Interval Down-sampling Network (PID-Net) for the yeast counting task with higher accuracy.
The PID-Net is an improved Convolutional Neural Network (CNN) based on an encoder–decoder architecture, pixel interval down-sampling and concatenate operations. By comparing with the traditional SegNet [
33] and U-Net [
34]-based object counting algorithms, the accuracy of counting is improved. The workflow of the proposed PID-Net counting method is shown in
Figure 1.
In
Figure 1, (a) Original Dataset: The dataset contains images of yeast cells and their ground truth (GT). The range is from 1 to 256 yeast cells in each image. (b) Data Augmentation: Mirror and rotation operations are applied to augment the original dataset. (c) Training Process: PID-Net is trained for image segmentation and the best model is generated. (d) Segmentation Result: Test images are processed using the trained PID-Net model and output the predicted segmentation results. (e) Counting Result: The number of yeast cells is counted by using connected domain detection.
The main contributions of this paper are as follows:
We propose PID-Net for dense tiny object counting. MaxPooling and pixel interval down-sampling are concatenated as down-sampling to extract spatial local and global features.
The operation of max-pooling may lose some local features of tiny objects while segmentation, and the edge lines may not be connected after max-pooling. However, the PID-Net can cover a more detailed region.
The proposed PID-Net achieves better counting performance than other models on the EM (yeast) counting task.
The paper is organized as follows:
Section 2 is the related work of existing image analysis-based microorganism counting methods.
Section 3 describes the architecture of the proposed PID-Net in detail.
Section 4 consists of the experimental setting, evaluation metrics and results.
Section 5 is the conclusion of this paper.
3. PID-Net-Based Yeast Counting Method
Although the existing image segmentation models, such as SegNet and U-Net, have been widely applied in semantic segmentation and biomedical image segmentation, they still cannot meet the requirements of accurate segmentation in the microorganism-counting task. To this end, we propose PID-Net, a CNN-based on pixel interval down-sampling, MaxPooling and concatenate operations to obtain a better performance. The process of microorganism counting mainly contains two parts, the first is microorganism image segmentation, whose purpose is to classify the foreground and background at the pixel-level. The second part is microorganism counting, whose purpose is to count the number of segmented objects after post-processing.
3.1. Basic Knowledge of SegNet
SegNet is a CNN-based image segmentation network with the structure of an encoder and decoder. The innovation of SegNet is that the dense feature maps of high resolution images can be calculated by the encoder, and the up-sampling operation for low-resolution feature maps can be performed by the decoder network [
33]. The structure of SegNet can be considered as an encoder network and a corresponding decoder network. The last part is a pixel-level classification layer.
The first 13 convolutional layers of VGG16 [
69] is applied in encoder network of SegNet, which consist of convolutional layers, pooling layers and Batch Normalization layers. In the encoder network, two sequences, which consist of one 3 × 3 convolution operation, followed by a Batch Normalization and a ReLU operation, are applied in each step. After that, the feature maps are down-sampled by using a max-pooling operation with the size of 2 × 2 and stride of 2 pixels. After pooling, the size of the feature map is changed into half of the initial.
What is noteworthy is that the Pooling Indices are saved while pooling, which records the initial position of the maximum value in the input feature maps. In the decoder network, the up-sampling operation is applied for feature maps, and then the convolution operation is performed three times to fix the detail loss while pooling. The same operation is replicated five times to change the feature maps into the initial image size. The saved Pooling Indices are applied while up-sampling to set the feature points into correct positions. A Softmax layer is applied finally for feature map classification.
3.2. Basic Knowledge of U-Net
U-Net is an U-shape CNN model based on an encoder–decoder and skip connection. U-Net is first designed for the segmentation of biomedical images. The max-pooling with the size of 2 × 2 and stride of 2 pixels is applied for down-sampling. There are two 3 × 3 convolution operations (each followed by a ReLU) between two down-sampling operations. The down-sampling operation repeats four times, and the number of feature map channels is modified to 1024.
In the decoder network, the result after up-convolution operation (a 2 × 2 up-sampling and a 2 × 2 convolution operation) is concatenated with the corresponding feature maps of encoder, which can combine the high-level semantics with the low-level fine-grained information of the image. After that, two 3 × 3 convolution operations (each followed by a ReLU) are applied. The size of each feature map is changed into the size of input after four up-sampling operations. Finally, a Sigmoid function is applied for classification.
3.3. The Structure of PID-Net
Following the basic idea of SegNet and U-Net for image segmentation, the structure of the proposed PID-Net is shown in
Figure 2, which is an end-to-end CNN structure based on the encoder and decoder. There are four blocks in the encoder network.
The first parts in each block are two convolution operations with a kernel size of 3 × 3 (each followed by a ReLU operation), and then the max-pooling with the size of 2 × 2 and stride of 2 pixels is applied to reduce the size of feature maps by half, followed by a convolution and ReLU operation. The channel of feature maps is denoted as
C. Pixel interval down-sampling is applied for down-sampling, which is shown in
Figure 2. Each pixel is sampled with the pixels apart, and the size of each feature map is replaced by half.
The classical down-sampling methods, such as max-pooling (with the kernel size of 2) will drop
data of the original image. It can retain the main information but not be fit to the task of tiny object counting (the edge lines may be lost while max-pooling). Though there are several learnable pooling layers that have proposed, such as Fractional pooling [
70], Stochastic pooling [
71] and learned-norm pooling approaches [
72]; however, they still cannot meet the requirement of accurate segmentation for dense tiny yeast cells.
Thus, a new down-sampling method, pixel interval down-sampling, is proposed here, which can reduce the size of feature maps without dropping data. Afterward, four pixel interval down-sampling feature maps and the features after max-pooling are concatenated to 5C-dimensional features. Finally, a convolutional filter with C channels is applied to reduce 5C-dimensional features to C-dimensional features. Hereto, the initial feature maps with size H × W and channel C are changed to feature maps with size × and channel C. The procedure is repeated four times with output resolutions of × and channel of 8C.
In the decoder network, four blocks are applied for up-sampling. Two convolution operations with a kernel size of 3 × 3 (each followed by a ReLU operation) are applied first. Then, the transposed convolution operation with a kernel size of 3, a stride of 2 and padding of 1 is applied for up-sampling. The transposed convolution operation is widely applied in GANs to expand the size of images [
73]. The count of channels after up-sampling of the bottleneck is 512, which is calculated by using the transposed convolutional filter with 512 channels [
74].
The params in the transposed convolution filter can be learned while training. After that, the high resolution feature maps of encoder network are transformed to low-resolution feature maps using 2×, 4× and 8× max-pooling, which is shown in
Figure 2. Then, the feature maps after up-sampling and max-pooling are concatenated with the feature maps generated by the corresponding layer from the encoder.
For instance, the 8× max-pooling features of the first block, 4× max-pooling of the second block and 2× max-pooling of the third block in the encoder are concatenated with the copied features of the fourth encoder block and the features after up-sampling (five parts of feature maps are concatenated in the first decoder block). In the same way, there are 4, 3 and 2 parts of features are concatenated in the second, third and fourth level of the decoder, respectively. After the concatenated operation, two convolutions and ReLU operations are applied to change the number of channels. The up-sampling operation is repeated four times with output resolutions of H × W and channel of C, which has the same size as the encoder’s input features. Finally, a Softmax layer with two output channels is applied for feature map classification.
3.4. Counting Approach
A post-processing method is applied to eliminate the effect of noises after segmentation. First, a morphological filter is applied to remove useless debris, which can improve the performance of counting prominently. Then, the eight neighborhood search algorithm is applied to count the connected regions of segmented images after denoising [
75]. The process of counting is shown in
Figure 3. A binary matrix is traversed in line and a mark matrix is applied to mark the connected domain [
76]. Finally, the number of connected domain in mark matrix is the number of yeast cells.
4. Experiments
4.1. Experimental Setting
4.1.1. Image Dataset
In our work, we use a yeast image dataset proposed in [
77], containing 306 different images of yeast cells and their corresponding ground truth (GT) images. All images are resized to the resolution of 256 × 256 pixels, which are shown in
Figure 4. Then, the original 306 images are rotated (0, 90, 180 and 270 degrees) and flipped (mirror), and thus the number of images in this dataset is augmented to eight times (2448 images).
4.1.2. Training, Validation and Test Data Setting
The original yeast image dataset was randomly divided into training, validation and test dataset with the ratio of 3:1:1, and then, each dataset was augmented eight times. Therefore, there 1470 images with their GT were applied as the training dataset, 489 images with their corresponding GT were applied for validation, and 489 original images were applied for testing.
4.1.3. Experimental Environment
The experiment was conducted by Python 3.8.10 in Windows 10 operating system. The experimental environment was based on Torch 1.9.0. The workstation was equipped with Intel(R) Core(TM) i7-8700 CPU with 3.20 GHz, 16 GB RAM and NVIDIA GEFORCE RTX 2080 8 GB.
4.1.4. Hyper Parameters
In the experiment of yeast cell counting, the purpose of image segmentation is to determine whether a pixel is a foreground (yeast cell) or background. The last part in the proposed PID-Net before the output is Softmax, which is applied to calculate the classification result of feature maps. The definition of Softmax is shown as Equation (
1).
In Equation (
1),
is the output in the
ith node, and
C is the number of output nodes, representing the number of classified categories. The classification prediction can be converted into the probabilities by using the Softmax function, which distributes in the range of [0, 1], and the sum of probability is 1. As the image segmentation for yeast counting is to distinguish the foreground and the background. Hence, it is a binary classification, Equation (
1) can be rewritten as Equation (
2).
In Equation (
2),
is
, which means the Softmax function and the Sigmoid function are the same for binary classification (a little difference between them is, the number of the fully connected (FC) layer of Softmax is two to distinguish two different categories; however, the number of FC layer of Sigmoid is one, only to judge whether the single pixel is the object to be segmented).
The probability of the pixel to be classified as 1 is:
Apparently, the probability of the pixel to be classified as 0 is:
According to the maximum likelihood formula, the joint probability can be expressed as:
After that,
function is applied to remain the monotonicity invariance of the function:
Hereto, the loss can be expressed as
, and the loss function for multiple samples can be defined as the cross-entropy loss (
N is the number of categories):
In order to guarantee the stable and fast convergence of the proposed network, we deploy preliminary experiments to determine the choices of hyper parameters. Adaptive moment estimation (Adam) is compared with stochastic gradient descent (SGD) and natural gradient descent (NGD). Adam optimizer has the smoothest loss curves and stablest convergence, which performs best in microorganism-counting task. Adam optimizer is applied to minimize the loss function, which can adjust the learning rate automatically by considering the gradient momentum of the previous time steps [
78].
The initial learning rate is set from 0.0001 to 0.01 in preliminary experiments. By observing the loss curves while training, the learning rate of 0.001 can balance the speed and stability of convergence. The batch size is set as 8 due to the limited memory size (8 GB). The selection of the hyper parameters above are optimal in preliminary experiments, and thus they are applied in our formal microorganism counting experiment. The epoch is set as 100 by considering the converge speed of experimental models, the example of loss and intersection over union (IoU) curves of models is shown in
Figure 5.
Though there are 92,319,298 params to be trained in PID-Net; however, it can converge rapidly and smoothly without over fitting. There is a jump in loss and IoU plots for all three tested networks from 20 to 80 epochs, which is caused by the small batch size. Small batch size may lead to huge difference between each batch, and the loss and IoU curves may jump with convergence.
4.2. Evaluation Metrics
In the task of dense tiny object counting, the evaluation of image segmentation is the most significant part. Hence, the widely applied segmentation evaluation metrics Accuracy, Dice, Jaccard and Precision are employed here to evaluate the performance of microorganism segmentation. Furthermore, the Hausdorff distance is applied to evaluate the shape similarity between the predicted image and GT. Finally, the counting accuracy is calculated to quantify the counting performance of the models.
Accuracy is applied to calculate the proportion of pixels that are correctly classified. The Dice coefficient [
79] is applied to measure the similarity of the predicted image and GT. The similarity can be quantified range from 0 to 1 (1 means the predicted result coincides exactly with the GT). Jaccard [
80], also named the intersection over union (IoU), is applied to compare the similarity and differences between the predicted image and GT image, focusing on whether the samples’ common characteristics are consistent. Precision is defined as the proportion of positive pixels in the pixels, which are classified as positive.
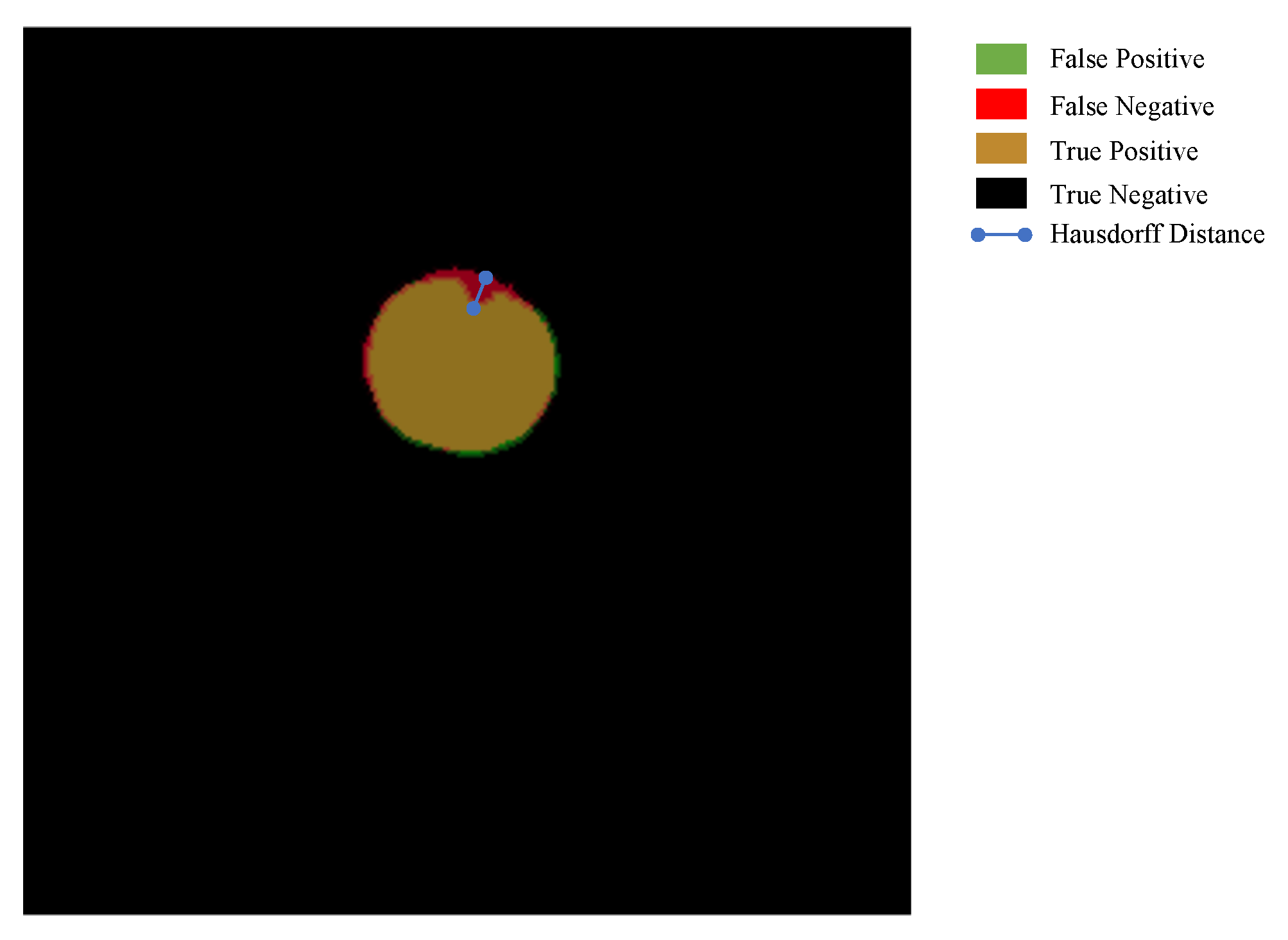
The Hausdorff distance [
81] is applied to measure the Euclidean distance between the predicted and GT images with the unit of pixels in per image. In contrast with Dice, the Hausdorff distance focuses on the boundary distance of two objects to measure the shape similarity; however, the Dice majors in the inner similarity. An example of the Hausdorff distance between GT and predicted image is shown in
Figure 6. The Hausdorff is the maximum of the shortest distance between a pixel in a image and another image [
82].
In the task of microorganism counting, the Hausdorff distance can be applied to measure the shape similarity between the GT and segmentation result, showing the performance of segmentation models. Finally, the performance of counting is measured using counting accuracy, which is defined as the proportion of the predicted number and GT number of yeast cell images.
The definitions of the proposed evaluation metrics are summarized in
Table 2. The TP (True Positive), TN (True Negative), FP (False Positive) and FN (False Negative) are basic evaluation metrics, which can be applied to measure the performance of segmentation in general. An example of a yeast cell image with its TP, TN, FP and FN is illustrated in
Figure 7 for intuitive understanding.
is the foreground after segmentation by using the model,
is the foreground of the GT image. Furthermore,
means the number of connected regions in the predicted image,
means the number of connected regions in the GT image, which indicates the number of yeast cells. In the definition of the Hausdorff distance,
is the supremum, and
is the infimum.
The proposed evaluation metrics, containing the Accuracy, Dice, Jaccard and Precision, are proportional to the segmentation performance of models. The Hausdorff distance has an inverse correlation with the segmentation performance. Counting accuracy can evaluate the final counting results of different models.
4.3. Evaluation of Segmentation and Counting Performance
To prove the satisfactory segmentation performance of the proposed PID-Net for dense tiny object counting, we compare different down-sampling methods to show the advancement of our proposed method. Furthermore, several state-of-the-art approaches are applied for comparative experiments. All of the experimental setting and evaluation indices are same for comparative experiment. Furthermore, the same dataset is applied for all comparative experiments, which is proposed in
Section 4.1.1. The models are trained from scratch without pre-training and fine-tuning.
4.3.1. Comparison of Different Down-Sampling Methods
In this part, we compare the effect of different down-sampling and skip connection approaches for segmentation. In our proposed PID-Net, pixel interval down-sampling and max-pooling operations are concatenated to combine the dense and sparse feature maps after convolution operations. Then, in the process of hierarchy skip connection, max-pooling is applied to combine the high-level features and low-level features directly, which is beneficial to reduce the effect of resolution loss while up-sampling and help rebuild the segmentation result.
To show the effectiveness and reasonability of the proposed method, we change the approaches of down-sampling and hierarchy skip connection as PID-Net Modified-1 (PID-Net-M1) and PID-Net Modified-2 (PID-Net-M2). In PID-Net-M1, max-pooling operations are only applied in the process of hierarchy skip connection and not in down-sampling. The down-sampling block of PID-Net-M1 is illustrated in
Figure 8. In PID-Net-M2, all down-sampling operations are realized using pixel interval down-sampling without max-pooling. The segmentation evaluations and counting performance of those approaches are shown in
Table 3.
From
Table 3, we find that the proposed PID-Net achieves the best counting performance. By comparing with the PID-Net-M1 and PID-Net-M2, the average accuracy is increased by 0.1% to 0.6%; the improvement of average Dice value is 0.1% to 1.1%; the average Jaccard is improved by around 0.3% to 1.6%. Furthermore, the mean Hausdorff distance of PID-Net is the shortest, which indicates the similarity between the predicted images and GT images is the highest. Finally, the counting accuracy achieved 96.97%, which shows the satisfactory counting performance of the PID-Net. Hence, the segmentation and counting performance of PID-Net is the best by referring to all evaluation metrics.
4.3.2. Comparison with Other Methods
In this part, some comparative experiments are applied for the yeast cell counting task. Some classical methods proposed in
Section 2 and deep-learning-based methods proposed in
Section 3 are compared, consisting Hough transformation [
83], Otsu thresholding, Watershed, SegNet and U-Net-based segmentation approaches. Furthermore, we conduct some extra experiments using state-of-the-art approaches, containing Attention U-Net [
66], Trans U-Net [
67] and Swin U-Net [
68].
Due to the determination of
k in clustering methods, such as
k-means, is still an insoluble problem while counting; therefore, the clustering-based approaches cannot be applied here for dense tiny object counting. All comparative experiments have the same experimental setting, which can be referred to
Section 4.1 for details. After image segmentation and object counting, the average evaluation indices are summarized in
Table 4, and the example images of segmentation are shown in
Figure 9.
From the evaluation indices summarized in
Table 4, we can find that the PID-Net has the highest Accuracy, Dice, Jaccard, Precision and Counting Accuracy and the lowest Hausdorff distance, which means the proposed model performs best in the task of dense tiny object counting by comparing with other models. Even more, the Jaccard of PID-Net is higher than the YeaZ who proposed this yeast cell dataset. In general, the approaches based on deep learning perform better than the classical approaches.
We find that the Counting Accuracy of several methods are very low abnormally, which may caused by the enormous difference between the GT and the predicted image. For instance, the single yeast cell image in
Figure 9 performs unsatisfactory when the segmentation is not accurate. The segmentation results of SegNet and Attention-UNet have a large number of False Positive pixels, and the counting approach is based on the connected domain detection; hence, the value of
is much higher than normal.
From the best performance of the proposed PID-Net in the task of dense tiny object counting, we can infer that the down-sampling and skip connection part of PID-Net, which combines max-pooling and pixel interval down-sampling can obtain the feature maps of dense tiny objects and reconstruct the images better.
4.4. Repeatability Tests
Five additional experiments were repeated based on the original PID-Net model for repeatability tests. The evaluation indices are given in
Table 5. From
Table 5, we find that all evaluation indices of repeated PID-Nets are approximate, which shows satisfactory and stable counting performance for the dense tiny object counting task.
4.5. Computational Time
The training time, mean training time, test time and mean test time are listed in
Table 6. There are 1470 images in the training dataset and 489 images in the test dataset. The mean training time of PID-Net model is approximately 2.9 s higher than the time of U-Net, and the test time is about 0.4 s higher than U-Net. The memory cost of PID-Net is about 20MB, which is about 6 MB more than the cost of U-Net model, meanwhile, the PID-Net has better counting performance and lower memory cost than Swin-UNet (41 MB). The counting accuracy is increased about 6%; hence, the PID-Net has satisfactory counting performance and a tolerable computational time, which can be widely applied in accurate dense tiny object counting tasks.
4.6. Discussion
Deep learning is essentially to build a probability distribution model driven by data. Therefore, as the deep-learning-network architecture becomes deeper, the quantity and quality of training data will have a greater impact on the performance of the model. However, in the imaging process of microorganism images, the amount of satisfactory data is relatively small due to some objective reasons, such as the impurities in the acquisition environment, uneven natural light and other adverse factors, which leads to insufficient training and poor performance in various tasks. Though the proposed PID-Net has excellent segmentation and counting performance for images with dense tiny objects, there still exists some mis-segmentation, causing the decrease of counting accuracy. Several incorrect segmentation results are shown in
Figure 10.
There are three main problems for segmentation and counting, which are illustrated in
Figure 10. The blue circle refers to the situation of under segmentation—that is, the neighbor yeast cells cannot be segmented, and the edges cannot be detected. Due to the counting method is based on the eight neighborhood search algorithm, the situation leads to under estimation of the real count of yeast cells. The green circle refers to a part of background is classified as yeast cells. As shown in
Figure 10, most of the images are full of dense tiny yeast cells with irregular shapes, and the limitation of small dataset leads to inadequate training.
Therefore, the background between yeast cells with irregular shape is easily classified as a yeast cell, which results in over estimation of the real count of yeast cells. On the contrary, the red circle represents the part of yeast cell is classified as background. There are 1 to 256 yeast cells with different sizes in a single image in this dataset, and thus the shape and size of yeast cells have a great difference. Therefore, the tiny yeast cell between the larger cells has a great similarity with the background, which is difficult for models to discriminate especially in a small dataset. The situation leads to under estimation of the real count of yeast cells.
The situations of adherent yeast cells and mis-segmentation lead to counting error. Moreover, the training data is limited due to the small dataset; therefore, the models cannot be trained perfectly. The small dataset is a limitation of the yeast counting task. However, despite some cases of mis-segmentation, most of the yeast cells in the test dataset could be detected and segmented with other cells. The segmented region might be small but has little effect on the counting results calculated using the eight neighborhood search algorithm.
5. Conclusions and Future Work
In this paper, a CNN-based PID-Net was proposed for dense tiny objects (yeast) counting task. The PID-Net is an end-to-end model based on an encoder–decoder structure, and we proposed a new down-sampling model consisting of pixel interval down-sampling and max-pooling, which can serve to extract the dense and sparse features in the task of dense tiny object counting. By comparing with the proposed PID-Net and classical U-Net-based yeast counting results, the evaluation indices of Accuracy, Dice, Jaccard, Precision, Counting Accuracy and Hausdorff Distance of PID-Net were 97.51%, 95.86%, 92.10%, 96.02%, 96.97% and 4.6272, which are improved by 0.04%, 0.15%, 0.26%, 0.4% and 5.7%, respectively, and the Hausdorff Distance decreased by 0.0394.
Although the small image dataset resulted in some cases of mis-segmentation, the proposed PID-Net showed a more satisfactory segmentation performance than the other models in the task of dense tiny object counting on a small dataset.
In the future, we plan to apply PID-Net for more dense tiny object counting tasks, such as the
streptococcus counting task and blood-cell-counting task. We will further optimize the PID-Net for better counting performance. For instance, object separation is one of the most significant parts in object counting; therefore, the Contour Loss [
84] can be used by referring to our work to distinguish inner texture and contour boundaries for more accurate counting. We also consider using Knowledge Distillation [
85] to reduce the memory cost of PID-Net, which can help to deploy the model on portable equipment.



 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}