1. Introduction
Learning from imbalanced data [
1] has proven its significance through the efforts devoted by the research community over the last couple of years. Most real-world applications such as medical diagnosis, protein classification, activity recognition, target detection, target detection, microarray research, video streaming, and mining are imbalanced [
1]. In an imbalanced distribution, the samples of one class outperform the other class or classes of samples with numbers, obviously a hurdle for the traditional classifiers to learn from multi-class problems. Most traditional classifiers [
2], such as k-nearest neighbor (kNN), naive Bayes (NB), artificial neural network (ANN), decision tree (TD), support vector machine (SVM), and logistic regression (LR) designed for the balanced and linear distribution of the instances in the training dataset between the classes. In the scenarios, multi-class imbalance learning requires more expertise and skills, since as with the number of classes in the problem domain increases, so do the challenges of representing the whole problem space accurately. Several problems reported in learning from multi-class imbalance data are the majority and minority class and classes problems [
1], issues of overlapping class boundaries [
3], a small sample size in the minority class [
4], and small disjuncts issues [
5], which must be taken into account before applying any multi-class imbalance classifier. Different papers discussed these four-fold reasons as a challenge when conventional classifiers are subject to learning from the imbalanced nature of data.
Traditional classifiers are well designed and indeed have better performance and accuracy over the balanced training set, resulting in sub-optimal classification performance when applied to imbalanced problems [
6].
With the skewed distribution, the predicted accuracy persuades a bias to the class having a greater number of samples, by ignoring the rare class instances, even with the best overall precision produced by the prediction model [
7].
Both the noise and minority class samples are least represented, and the learning models are sometimes confused with each other, whilst noise may be incorrectly recognized as minority instances [
8].
Learning from imbalanced distribution is somehow comfortable if the classes are linearly separable from each other. However, in multi-class imbalanced problems, minority instances are overlapped with each other’s boundaries where the earlier likelihood of both the majority and minority classes are nearly equal [
9].
Several approaches were reported in the literature to cope with this imbalanced data problem based on the data level methods [
10], algorithm adaptation methods [
11], and ensemble-based methods [
12]. However, the majority of these approaches focused on handling the binary class imbalance problem apparently cannot be directly applied to multi-class imbalance problems, since the decision boundary involves distinguishing between more classes. At the data-level method, the original data are amended to relive the overlapping impact, either by introducing complementary features or data cleansing methods to separate the overlapping classes or merging overlapping classes to form meta classes [
13]. However, using the data-level approaches exclusively to address the imbalance and overlapping issues may result in the model overfitting [
14] or may lose some useful information [
15]. The fundamental changed algorithm cannot be applied as a general method to effectively tackle the overlapping issues in algorithm-based techniques, which modify the current algorithm to deal with the uneven nature of the information and improve the learning of the underlying classifier [
16,
17]. The choice of base classifiers, the decision-making process, the number of classifiers used for the construction of an ensemble, the accuracy of individual models, the diversity among the individual models in an ensemble, and the number of classifiers used are some main factors to be carefully studied in an ensemble-based method [
18].
Parameter hyper-tuning [
19] in the selected model is the process of ascertaining some particular parameters to optimize the performance of learning algorithms on a specific set. Parameter tuning has proven its vital role in improving the accuracy and overall model performance both for ensemble and non-ensemble classifiers [
20,
21]. Every classifier has its own set of parameters and needs to tune following the different tuning steps by performing an exhaustive grid search. There are two types of model parameters in every machine-learning algorithm, conventional parameters and hyper-parameters. Conventional parameters are optimized during the training phase of the underlying model, whereas the users, depending upon the problem dataset before the training phase of the model, set hyper-parameter values. In the more complex structure, i.e., with the increasing overlapping samples, the needs for the optimal set of parameters become more in order to maximize the visibility of the minority class samples [
22].
The key contribution of the underlying paper is to focus on analyzing the learning performance of ensemble and non-ensemble classifiers over multi-class imbalanced and overlapped data. A detailed investigation of ensemble and non-ensemble approaches was presented to provide deep insight into the nature of multi-class learning strategies. An exhaustive experiment on the hyper-tuning of six state-of-the-art ensemble and non-ensemble classifiers, to efficiently address the multi-class imbalance datasets issue and comprehensively compare and improve their performance, was performed using four different evaluation metrics for accuracy, namely the overall accuracy (ACC), geometric mean (G-mean) [
23], F-measure [
12], and the area under curve (AUC) metrics [
24]. As a third contribution, an algorithm was designed to synthetically generate overlapping samples in the existing dataset by 20% of the existing samples to make it more complex and overlap to highlight the impact of parameter tuning. The comparison of ensemble and non-ensemble classifiers was carried out on 15 publicly available multi-class imbalanced and overlapped datasets.
The underlying research article is comprised of the following sections. The literature survey is covered in
Section 2. The background of ensemble and non-ensemble-based methods are covered in
Section 3 and
Section 4. In
Section 5, we discussed the hyper-tuning of the parameters of the used classifiers in
Section 6, and
Section 7 discusses the algorithm to synthetically generate the overlapping samples.
Section 8 highlights the experimental setup, dataset, and evaluation methods,
Section 9 covers the results and discussion. We compare the ensemble and non-ensemble approaches in
Section 10 and the article is concluded in
Section 11.
2. Related Works
The authors in [
25] argued for the significance of ensemble approaches as compared to the sampling methods and individual classifiers when applied to a multi-class imbalanced dataset. The authors compared the ensemble-based approach with the non-ensemble to prove the robustness of ensemble methods. Yao and Wang in [
26] combined AdaBoost.NC and AdaBoost with sampling techniques either augmented with or without the decomposition techniques to address the multi-class imbalance problem and highlight that the ensemble approach is more effective than the oversampling and decomposition techniques. Without class decomposition, AdaBoost.NC shows better performance as compared to AdaBoost, but with the increasing number of classes, their performance also decreased gradually. The authors in [
26] showed that the shortcomings of sampling methods cannot be avoided by using standard ensemble approaches if the dataset has multiple classes. Despite the increasing number of samples in the positive class by adding some samples through oversampling, the distribution of classes in the data space is still imbalanced, which is dominated by the majority class. Chawla et al. [
27] proposed SMOTEBoost, an ensemble-based sampling technique to enhance the conventional SMOTE [
28] by mingling it with AdaBoost.M2. The authors applied SMOTE before the base classifier evaluation, and thus, the new instance’s weight is relative to the numbers of samples in the new dataset. After producing the new instances, the original instance’s weight is standardized to generate the new distribution. In every iteration, the instance weight of the minority class increases. The authors in [
29] highlighted the outclass performance of bagging as compared to boosting in a multi-class and noisy environment. Furthermore, bagging techniques have to be quickly developed and become more powerful if properly ensemble. Similarly, OverBagging [
30] combines the data preprocessing and bagging techniques to manage the class imbalance issue by increasing the positive class cardinality by the duplication of original examples; at the same time, the instance in the majority of negative class is considered in every bag to increase multiplicity.
In [
31], SMOTEBagging was proposed to counter multi-class imbalance learning issues by creating every individual bag to be expressively diverse. In every iteration during bag creation, the SMOTE resampling rate is defined and this ratio specifies the positive class instances randomly resampled from the original dataset, and the remaining positive class instances are generated by SMOTE. Barandela et al. proposed UnderBagging for the first time in [
31], wherein the negative class instances are arbitrarily condensed at every bootstrap sample to make it equal to the cardinality of the positive class. The basic, simple version of undersampling when merged with bagging-based techniques proves that it is more significant than the more composite solution, such as BalanceCascade [
32] and EasyEnsemble [
33]. In [
34], the authors highlighted an important problem with the ensemble size and ensemble cardinality (number of component classifiers in the final ensemble), as it affects the predictive performance, time, and memory for the classification algorithm when applied to imbalance data and diversity among the component classifier. The boosting ensemble method presented in [
35] is one of the prominent methods explicitly based on the complementarity among the component classifier. Through the boosting process, a strong learner built from the collection of different weak learners (weak in the sense of accuracy while being applied on the classification task). In [
35], the authors proposed a new ensemble method, twin bounded weighted relaxed support vector machines (TBWRSVM), which is an extension of the weighted relaxed support vector machine (WRSVM) classifier used for class imbalance problems and outliers. The resulting classifier utilizes twin bounded support vector machines (TBSVM), which provides a quick classification method. The authors in [
36] have suggested a novel ensemble approach, “Dynamic Ensemble Selection for Multi-class Imbalanced the dataset (DES-MI)” to handle the multi-class problem’s challenge. To improve learning from multi-class problems, the DES-MI model first creates a balanced training set before choosing an appropriate classifier. To compare the accuracy and computational cost of the well-known boosting-based ensemble classifier Xgboost (ensemble-based method), the authors in [
37] looked at its general performance, efficiency, competence, and effectiveness while taking into account its sensitivity to the sample size and feature space. The performance of statistical analysis, according to the authors, is greatly improved when parameterizing Xgboost using a Bayesian approach as opposed to utilizing “random forests” and “support vector machines” that are operated on larger sample size.
The authors in [
38] described the suitability of data preprocessing techniques to address the data imbalance issues. The authors of this study are of the opinion that a balanced training dataset is more robust for improving the overall performance of the classifier for several base classifiers. Zhang and Mani in [
39] proposed a new technique by achieving undersampling through the kNN classifier. Based on the data features of the data distribution, four undersampling methods based on kNN are proposed, namely
and the “most distant” method, in which a small subset of training data is selected to minimize the skewness in the reaming data. The authors in [
40] highlighted that sampling techniques are very clever in dealing with the binary classification problems with two target variables, facing some difficulties when directly applied to solve multi-class classification problems. The authors used the “Mahalanobis Distance-based Over-sampling (MDO)” [
41] technique to handle the imbalanced class data with a mixed attribute, introduce generalized singular value decomposition (GSVD) for complex and mixed-type data, augmenting with a resampling scheme applied on the mixed type of attributes to optimize the synthesis of samples. In [
42], the authors presented a combination of k-means clustering and “(SMOTE)”, which results in an effective “oversampling method” and effectively overcomes the imbalance ratio between and within classes and avoids noise generation. K-means clustering is a three-step method: clustering, filtering, and sampling to enhance learning from multi-class classification problems. To address the imbalance classification problems, the authors combine “random oversampling” and “random under sampling techniques” in [
43] to propose a hybrid sampling SVM approach. By using the undersampling technique, the samples with the least significance were deleted, followed by the oversampling technique to generate some samples in the minority class. In [
44], the authors first proposed an optimization classification model (OCM) to deal with the classification problems using evolutionary computation (EC) techniques. In the second step, the authors proposed a novel algorithm, the self-adaptive fireworks algorithm (SaFWA) based on swarm intelligence, to address the optimization problems. To increase the diversity/range of solutions, four candidate solution generation strategies (CSGSs) were merged with SaFWA. In [
45], the authors highlighted the multi-class problem solution strategies (decomposition strategies), i.e., transforming imbalance multi-class problems into several classes and designing a separate classifier for each class (binary decomposition is considered to be the most prominent approach for multi-class decomposition). The proposed model has the flexibility to discard the non-competent classifier to improve the robustness of the combination phase. The competency of the classifier is measured by considering the neighborhood of each sample augmenting with selection criteria (with a threshold option) for a classifier corresponding to the minority class in this neighborhood. The authors in [
46], proposed the Bayesian learning probabilistic model to improve the performance of Bayesian classification using the combination of a Kalman filter and K-means. The method is applied to a small dataset just for establishing the fact that the proposed algorithm can reduce the time for computing the clusters from the data. The authors in [
47] proposed a deep image analysis–based model for glaucoma diagnosis that uses several features to detect the formation of glaucoma in the retinal fundus. The proposed model is combined with SVM, KNN, and NB to investigate the various aspects related to the prediction of glaucoma in retinal fundus images that help the ophthalmologist make better decisions for the human eye. Some of the prominent existing techniques reported in the literature are listed in
Table 1.
3. Ensemble-Based Methods
Ensemble learning, also known as multiple classifier systems, has become an influential solution overshadowing not only multi-class imbalance learning but also two-class imbalance problems and standard classification, as discussed in [
48] with regard to the boosting algorithms primarily designed for binary classification. In the literature, different researchers agreed on the versatility and effectiveness of ensemble-based learning techniques, where several component classifier predictions were combined to make a final prediction report, improving the performance of individual weak learners with a small training dataset to build an improved classification-learning model. Ensemble approaches were initially introduced in [
49,
50] in the early 1990s, who presented their view in [
51] by arguing that combining multiple classifiers (via an ensemble process) could yield better performance as compared to individual classifiers. Mathematically [
52], the performance of each individual classifier over dataset D with M classes is given in Equation (
1) as:
where
represents the performance of an individual classifier with
being evaluated on
D and a
matrix
W which is defined as:
Each element of
is defined in Equation (
3), where
is the set of instances of the dataset belonging to the class
j, and
is the number of accurate predications of the classifiers
on
, and
are the false or incorrect predications of
that an instance belongs to class
j. Subsequently, the target class
of each unknown instance
x in the test set is computed by Equation (
3):
where function
returns the value of the corresponding index to the largest value from the array,
is the set of unique class labels and
is the characteristic function which takes into account the prediction
of a classifier
on an instance
x and creates a vector in which the
j coordinate takes a value of 1 and the rest takes the value of 0. After several alternatives and improved versions for ensemble classifiers, ensemble methods are nevertheless categorized into three main types, namely boosting, bagging, and stacking. Through the boosting process, a strong learner is built from the collection of different weak learners (weak in the sense of accuracy when applied to the classification task). In boosting-based methods [
44], an individual classifier iteratively learns to become specialized on a specific set of the training dataset. The weighted samples from a subset of the training dataset were used to train a component classifier in such a way which emphasizes previously misclassified samples. In boosting methods, experiments piloted on the training set using different learning models to prompt classifiers to produce output. The weight assigning concept is used in the boosting process to assign higher weights or higher costs for each classifier that misclassified the underlying example. Using the approach of the weighted average, the output of each classifier is updated to generate the final output [
53]. The basic idea of a boosting-based method is to combine the weak learner to build a strong learner to improve the overall accuracy and performance. Among the boosting family, AdaBoost [
54] and Gradient tree boosting [
55] are well-known methods of boosting ensemble methods. In a boosting-based method, the resulting ensemble model is defined as the weighted sum of weak learners, as shown in the Equation (
4).
where
are coefficients and
are weak learners. Using Equation (
4) and finding the best ensemble model is somehow a difficult optimization problem. Instead of using this model approach, we can use an iterative optimization process to find all the coefficients and weak learners that give the best overall additive model by adding the weak learners one by one, looking at each iteration for the best possible pair (coefficient, weak learner) to add to the current ensemble model. We recurrently define the
as shown in Equation (
5):
where
and
are chosen such that
is the model that best fits the training data and therefore is the best possible improvement over
. We can then denote this in Equation (
6):
where
is the fitting error of the given model and
is the loss/error function. Thus, instead of “globally” optimizing over all the
L models in the sum, we approximate the optimum by optimizing “locally” building and adding the weak learners to the strong model one by one.
Bagging methods based on bootstrap aggregation minimize the prediction variance by producing additional examples from the original data for the training set. The training of several base classifiers was carried out on the bootstrap instances of a refined subset of the training dataset, and by using the simple aggregation (majority voting), combines the output of these base classifiers into the final output, thus resulting in a more diverse ensemble, a key factor for an ensemble to work efficiently and effectively. A separate classifier is introduced for each example in the training set, thus having
k numbers of a classifier for each iteration of the training set. From the bagging family, the most prominent methods reported in the literature are random forest, which is a flexible and easy-to-use ensemble-based machine-learning algorithm. Most of the time random forest gives very good results, even without hyper-tuned parameters. Because of its simplicity, it can be widely used for both regression and classification tasks. A variation of the bagging scheme, UnderBagging [
2], under samples the underlying subset of the instance before the bagging iteration for multi-class imbalance problems by keeping all the minority class samples in each iteration. Another variation of bagging schemes is random forest [
5], where the base classifier trained via the bootstrap samples of the underlying training dataset has been randomly reduced to a small subset of dataset samples. In voting-based ensemble methods, predictions from various individual models are combined. In the voting method using an ensemble approach, two or more component models were created separately with a dataset, following an ensemble model to wrap the previously created models and the prediction of those models then aggregated. The resulting model was used to predict new data. Assuming that we have
L, bootstrap samples (approximations of
L independent datasets) of size
B are denoted in Equation (
7):
where
observation of the
bootstrap sample. We can fit
L almost independent weak learners (one on each dataset) as given in Equation (
8):
All the weak learners of Equation (
8) are then combined into some kind of averaging process to obtain an ensemble model with a lower variance. For example, we can define our strong model given in Equation (
9):
Apart from accuracy improvements and being accuracy oriented, most of the standard techniques for creating ensembles face difficulties in identifying the subset of the dataset with the minority class. To cope with such difficulties, special attention has to pay to designing ensemble algorithms to handle the class imbalance problem. The effective combination of imbalanced learning, ensemble learning techniques with a base learner, and sampling strategies to confront the imbalance class issue put forward many possible proposals for prominent results in the literature by putting aside the conventional categories such as cost-based and kernel-based methods in the imbalanced domain [
56]. Regardless of the popularity, versatility, and effectiveness of ensemble methods (by using an independent baseline classifier) as compared to cost-sensitive and improved algorithm-based methods, in an ensemble process, however, transforming dissimilar classifiers by ensuring their stability and regularity using the underlying training dataset is still a crucial factor for ensured accuracy while dealing with the multi-class classification problems. All the symbols used in this article are described in
Table 2.
4. Non-Ensemble-Based Methods
Different research papers have empirically and experimentally reported that the classification of a balanced dataset is somewhat elementary and comfortable to perform, but it becomes difficult when the data are not balanced [
57]. The standard machine learning algorithm assumes a balanced distribution of classes in a subset of the dataset used for classification; however, the distribution of instances in classes is not uniform in many real-life situations [
58]. Traditional classifiers, initially designed for the classification of balanced datasets, show a significant performance for the underlying problem of having a balanced dataset. On the other hand, real-world data are messy with an unequal distribution of samples, where the traditional classifiers fail to properly identify the relevant target class.
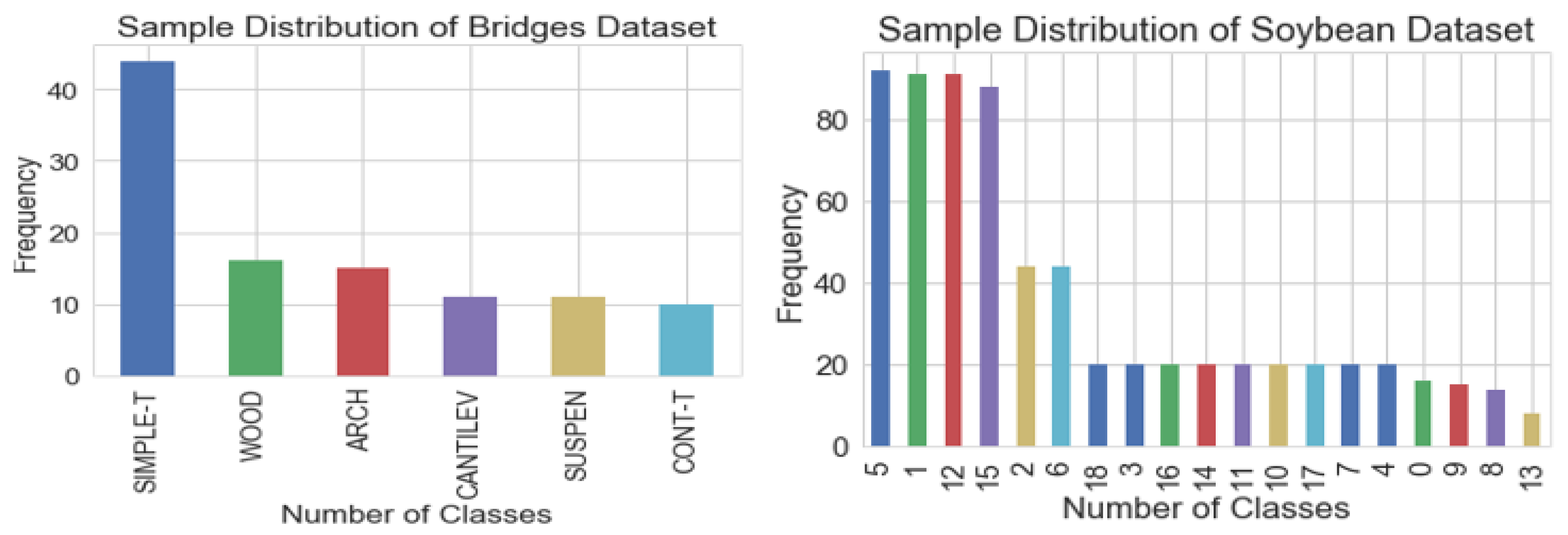
Figure 1 shows the imbalanced distribution of samples. This imbalance distribution of instances causes biases toward the majority group, thus creating difficulty for the standard learning algorithm to correctly predict an unseen sample. The ignorance of the minority class will lead to building a poor model, as sometimes, this leased-focused class carries important information, thus providing an impractical classifier for our proposed use case. Many standard classification algorithms, namely the SVM, ANN, DT, NB classifier, and KNN, which are designed based on balanced training datasets, become less effective due to skewed distribution in imbalance classes [
59]. Although some of them can use for a small dataset as imbalanced data, if we apply the traditional algorithms to multi-class and multi-label problems with an imbalanced dataset, a good performance in terms of accuracy [
60] is not necessarily achieved, as standard algorithms are built with the assumption that the distribution is balanced. Therefore, when presented with large imbalanced datasets, these algorithms fail to properly represent the distributive characteristics of data [
1]. Classification problems in many real-world applications and scenarios involve multiple classes both in a balanced and in an imbalanced dataset. The learning environment becomes more complex and challenging when the number of classes increases in the domain and multiple classes overlap with each other’s, making it difficult to establish a clear decision boundary between any two classes or among the classes.
4.1. Support Vector Machine Classifier
Using SVM, in the experiment section, we used both the linear and kernel SVM on the stated datasets to classify multi-class imbalanced data. The RBF kernel is used for a decision function in nonlinear SVM [
61], as the data are not linearly separable. A set of parameters [
62] that need to be hyper-tuned to improve the performance of kernel SVM on multi-class imbalance data are
C (a regularisation parameter used to manage or balance the low testing and training error to make a more general algorithm on unseen data), to adjust the decision boundary curvature and hyperplane shape for the class dividing, the gamma
(also known as kernel width parameter), and the decision function (decision function shape) and assigning any weight to a class or classes. Thes small values of
C may cause the model to estimate constantly and make it difficult to understand the data; on the other hand, big values of
C may cause the model to overfit the training data. Similar to this, the class splitting hyper-shape planes will change for very large values of
. If the data in the dataset are not balanced, class-weight balance is employed. The decision function shape decides the decomposition strategy, whether to apply one-versus-one or one-versus-rest. The parameter search range and optimal parameters are shown in
Table 3 and
Table 4.
4.2. Random Forest Classifier
To improve the overall model performance via the RF classification model, a set of four parameters needs to be hyper-tuned [
63]: the number of
(number of trees), maximum depth, maximum features, and minimum sample split. With regard to the number of tree different opinions there are, some researchers have suggested using the default number of trees to obtain more stable results, whereas some authors argue that a large number of trees should be used. The maximum depth specifies how long the node is expended; if it is not specified, then all nodes will be expended until the leaf node. To achieve the best split, the optimal number of features should be hyper-tuned in the value for ‘max-features’. ‘Minimum-sample-split’ specifies the splitting criteria of an internal node. The parameter search range and optimal parameters are shown in
Table 3 and
Table 4.
4.3. K-Nearest Neighbor
The basic working procedure of kNN is to find a cluster (subset) of
k instances which is the nearest to the predicted sample in the underlying training space, thus showing the independence from the structure of the data. The set of parameters [
64] that needs to be tuned to improve the performance of kNN is
k, ‘
’, and ‘
’. The distance between two points is calculated using the Euclidean distance function. The class having majority
k-nearest neighbors is the predicted class for the new predicted sample.
K is the key parameter to be tuned (after exhaustive grid search) to obtain a satisfactory result. Other important parameters are ‘
’ and ‘
’, which are weights of two types, namely uniform and distance; for a better prediction accuracy, the uniform weight is considered for the multi-class classification problem, and the ‘
’ parameter is a key indicator for the speedy construction, query and memory requirement to store the tree.
4.4. Gradient Boosting Algorithm
The parameters of the boosting-based model [
65] are sub-categorized into three types, namely parameters specific to a tree structure, boosting specific parameters, and miscellaneous parameters. Since a decision tree is used as a default base learner, parameters specific to the tree structure are allied with each base learner, for example, the sample (minimum number) is requisite to split an interior node or the ‘
’ for each tree. ‘
’ and ‘
’ are the boosting parameters, directly related to the underlying boosting algorithm.
4.5. Decision Tree Algorithm
Decision trees can apply to both balanced and imbalanced (multi-class) classification and regression problems; however, it best employs a nonlinear decision, with a pre-defined class variable or target label. The decision tree enables a predictive classification model with refined accuracy and precision, and provides better stability to the model with the ease of classification. During our experiment, we hyper-tuned these six parameters [
66] to make a significant change to the overall performance of the model, and ‘
’, ‘
’, ‘
’, ‘
’, ‘
’, ‘
’ and ‘
’. The criterion function will decide the quality of the split; to decide the split at each node, the splitter function is used, and how long the tree should grow will be decided by the maximum depth function, the required sample for an internal node to split will be based on
, the
required at the leaf node will be decided by the
, and
determines the number of features to be considered when looking for the best split.
4.6. Logistic Regression
Logistic regression can be used for both binary and multi-class imbalance problems [
41], although it was initially designed for binary classification, using the one-versus-rest decomposition strategy or modifying the loss function to cross-entropy loss, and logistic regression can be used for multi-class classification. To set the logistic regression for multi-class classification, a parameter called “multi-class” value will be enabled to be multi-class. For multi-class classification, the training model requires the “one-versus-rest” decomposition strategy in case the “multi-class” option is set to “OVR’, and if the “multi-class” option has a “multinomial” value, then “cross-entropy-loss” will be used [
67]. The default value of “multi-class” is ‘ovr’, and currently, the ‘multinomial’ can have one of the four possible values as a solver, namely newton-cg, sag, and lbfgs. During the multi-class classification using exhaustive grid search, the two following parameters have proven to be effective for multi-class classification, penalty, and solver with the values, ‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, and ‘saga’. ‘liblinear’ is a better option for a dataset that has a lesser number of classes, and if the dataset have a large number of classes ‘saga’ and ‘sag’ are the best choice to use. For multiclass problems, only ‘newton-cg’, ‘sag’, ‘saga’, and ‘lbfgs’ can handle multinomial loss; ‘liblinear’ is limited to one-versus-rest schemes.
5. Parameter Tuning
Parameter tuning is the process of ascertaining some particular parameters to optimize the performance of learning algorithms on a specific set [
68] to improve the accuracy and the overall model’s performance both for ensemble and non-ensemble classifiers. Every classifier has its own set of parameters, and needs to tune following the different tuning steps by performing an exhaustive grid search. Most of the time, we assess and compare the underlying models’ performance for the best hyper-parameter settings using the grid search technique and response surface methodology (RSM). However, some researchers [
69] have preferred the mean absolute error (MAE) to compare the performance, which is given in Equation (
10):
where
and
and denote the actual value and predicted value of observation
i, respectively,
denotes the prediction error of observation
i, and
N denotes the total number of observations in the data. The lower the MAE, the better the model performance.
In this article for the individual classifier, we tested a series of values using ten-fold cross-validation [
70] and a grid search mechanism for parameter tuning until an optimal parameter set showing the overall highest classification accuracy and precision for each classifier was obtained. In the result section, each classifier was compared with and without tuned parameters on 20 publicly available datasets. The comparison of eight state-of-the-art classifiers (ensemble and non-ensemble) is highlighted in
Table 5,
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10.
Table 5 and
Table 6 show the comparison with conventional parameters by showing their overall accuracy, precision, recall, and
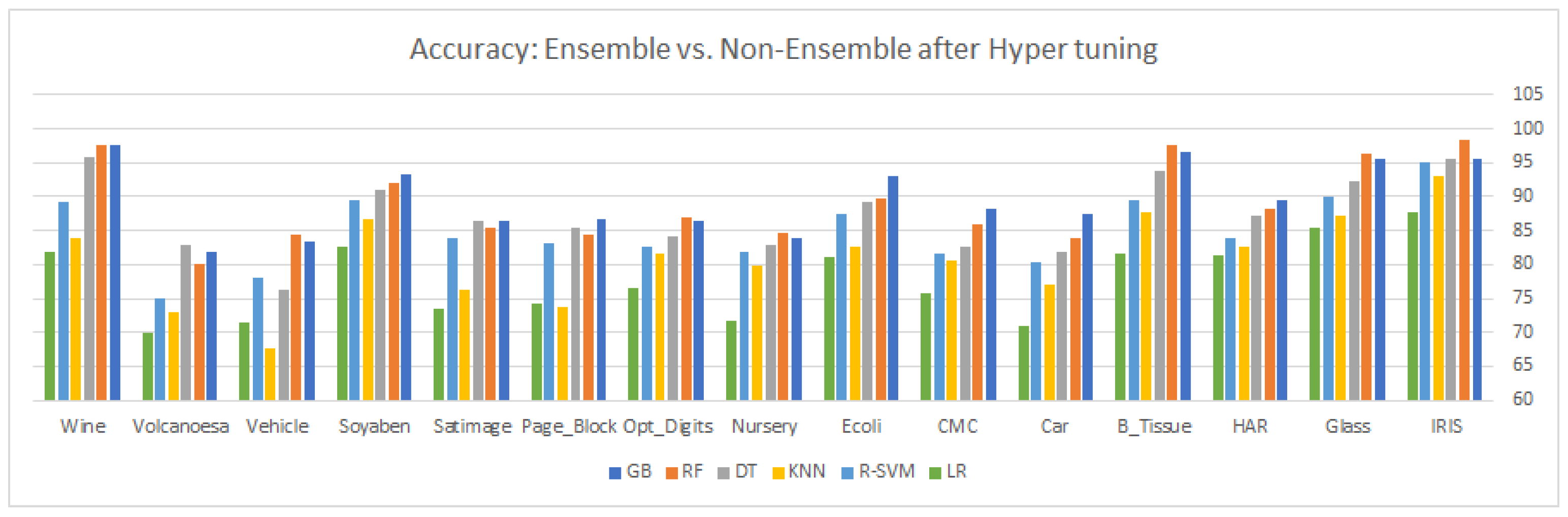
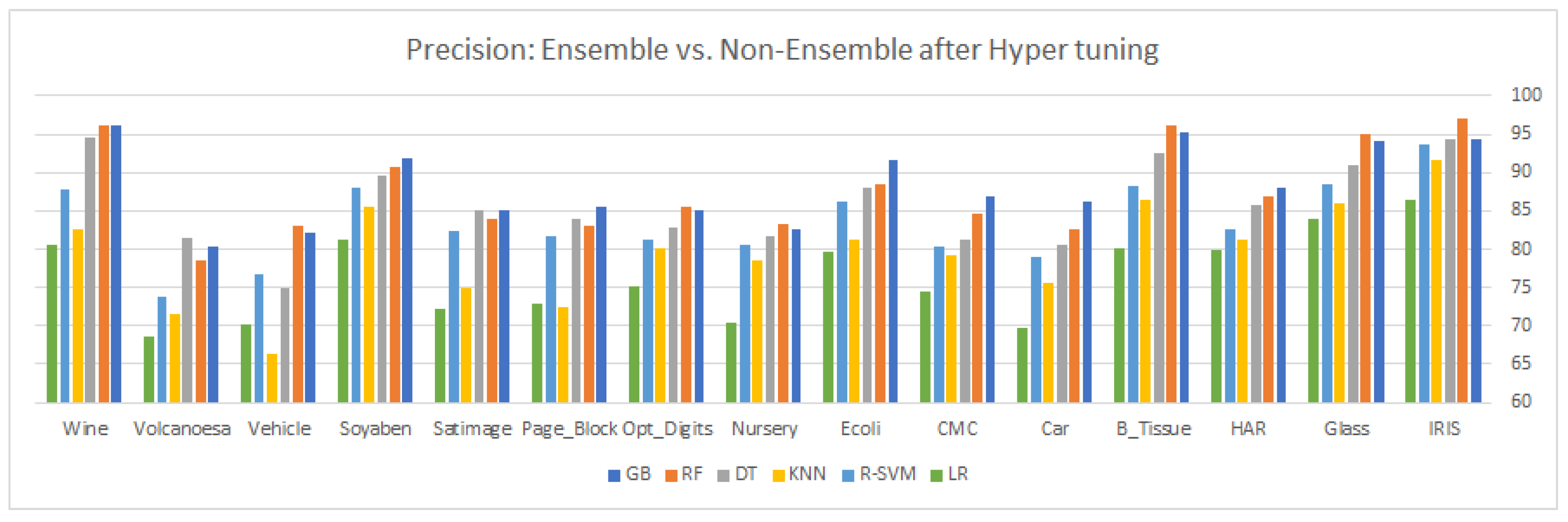
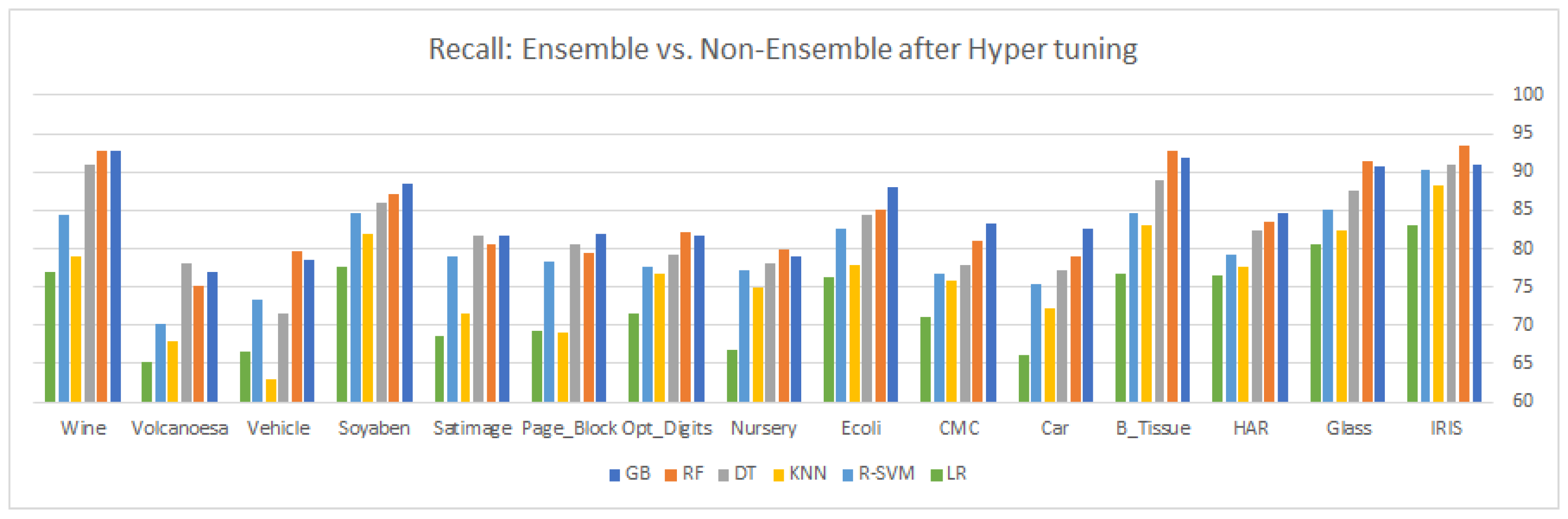
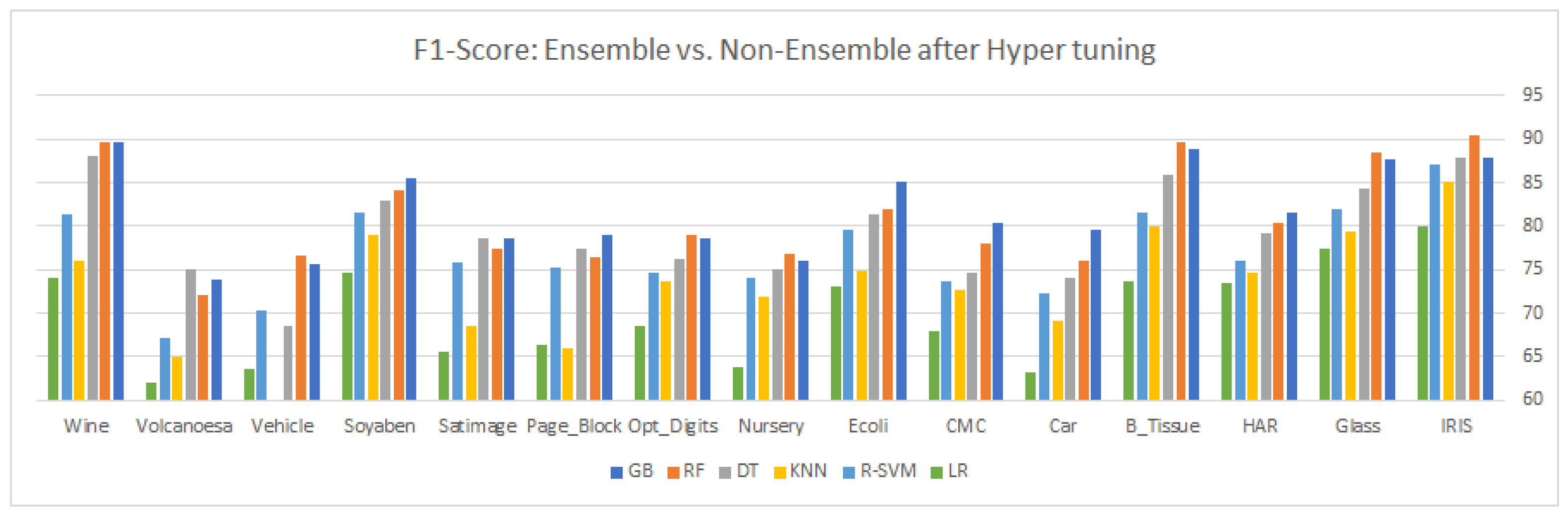
. After carefully observing the different values of the evaluation matrix, six classifiers, GB, RF, DT, KNN, R-SVM, and LR were selected for hyper-tuning, based on their overall significant performance for the same datasets.
Table 7 and
Table 8 shows the comparison of the six selected classifiers after the hyper-tuning of their parameters, while
Table 9 and
Table 10 show the performance comparison after the synthetically controlled overlapping and hyper-tuning.
Before the parameter tuning process, a grid of parameters is specified to evaluate each algorithm and every subset of the parameter; 10-fold cross-validation is performed to evaluate the model. Within the 10-fold cross-validation, 9-fold cross-validation is used to train the model and 1-fold cross-validation is used to validate the model. The process of validation using a grid search is repeated 10 times so that every fold has a fair chance to use as a validation set and the scores from each run are averaged. To save time and space for the hyper-tuning process, we divided the twenty datasets into two groups, namely group 1 wherein datasets contain five classes or less, as shown in
Table 3; and group 2, wherein datasets consist of more than 5 classes, as shown in
Table 4.
6. Quantification of Class Overlapping
Most real-world imbalanced problems exhibit overlapping issues, while the joint effect of imbalanced and overlapping samples severely affects the classification performance [
71]. Overlapping issues and the classification of the imbalance nature of data have significantly gained in popularity for their focus on real-world problems, however, a well-defined mathematical explanation of overlapping is still lacking [
72], despite different studies in the literature [
72,
73] having suggested estimating the class overlapping level. However, a major drawback of these methods is the prior assumption of the normal distribution of data, which is not possible in the majority of real-world datasets. We modified the formula used in [
74] in Equation (
11) to approximate the overlapping region based on the imbalanced distribution of data, originally designed for binary classification problems with 2D features space.
The overlapping level for the majority class negative instances in the overlapping region affects the classification performance and is calculated via Equation (
12).
The overlapping region is the shared feature space of the majority and minority class samples with similar attributes, and the majority class area is calculated using the Euclidean distance and nearest neighbor rule. A class overlap region for two-class
and
can be described using Equations (
13) and (
14).
If the probability density of class is greater than or equal to zero, the same must be true for class , where , i.e., the sample of the class has similar characteristics to the sample of class .
To measure the overlap among the features of a different class in a multiclass dataset, it is necessary to evaluate the discriminative power of the features. If there are any features with discriminative characteristics, the problem is thus considered a simple problem. To measure the overlap among the different classes, we used Fisher’s maximum discriminative ratio [
75], denoted by
and given by Equation (
15):
where
is the discriminative ratio for the feature
listed in the dataset. Originally, the largest discriminative ratio value was stored in
.
can also be calculated as presented by Orrial in their research article [
76], and as given by Equation (
16):
represent the respective samples in classes
and
, respectively, where
and
denote the means of the features of class samples
and
, and
shows the standard deviation of those samples. Both Equations (
5) and (
6) are employed for the binary classification, where the underlying dataset should be decomposed into a binary classification problem using the one-versus-one approach. An alternative computation of the discriminative ratio for both multiclass and binary classification problems is presented by Molliendia [
77] and is given by Equation (
17):
where
represents the respective samples in class
and
denote the mean of the sample
across the samples of class
.
is the mean of the
values across all classes, and
represents the individual value of the feature
from a sample of class
.
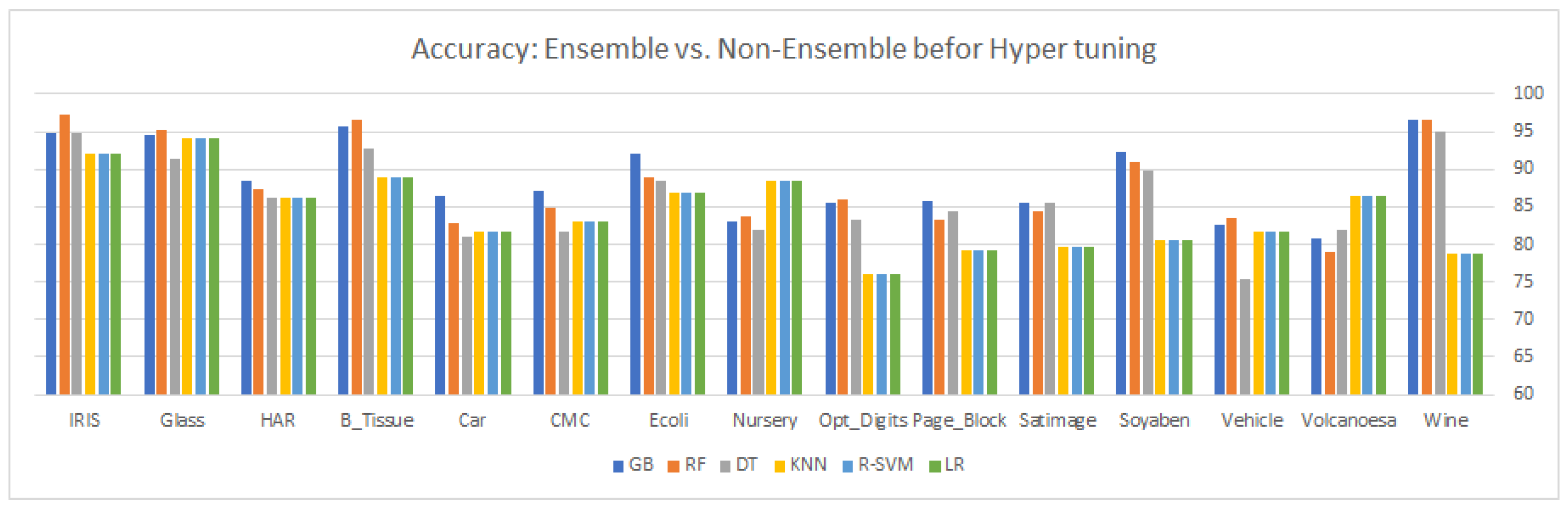
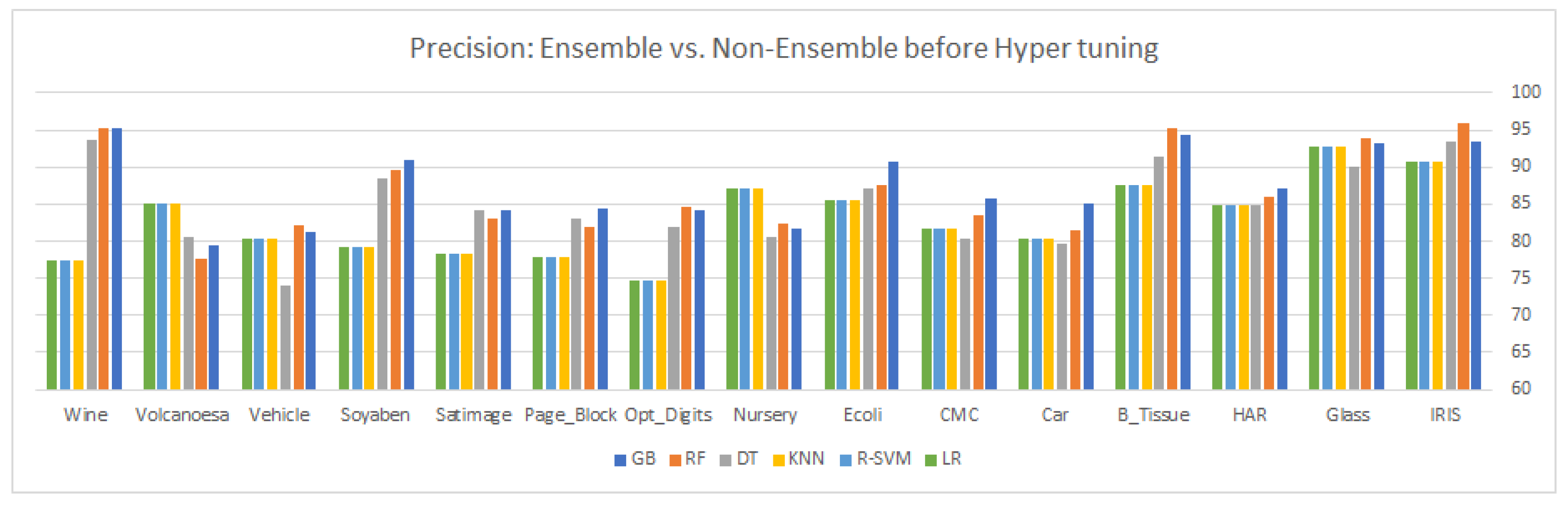
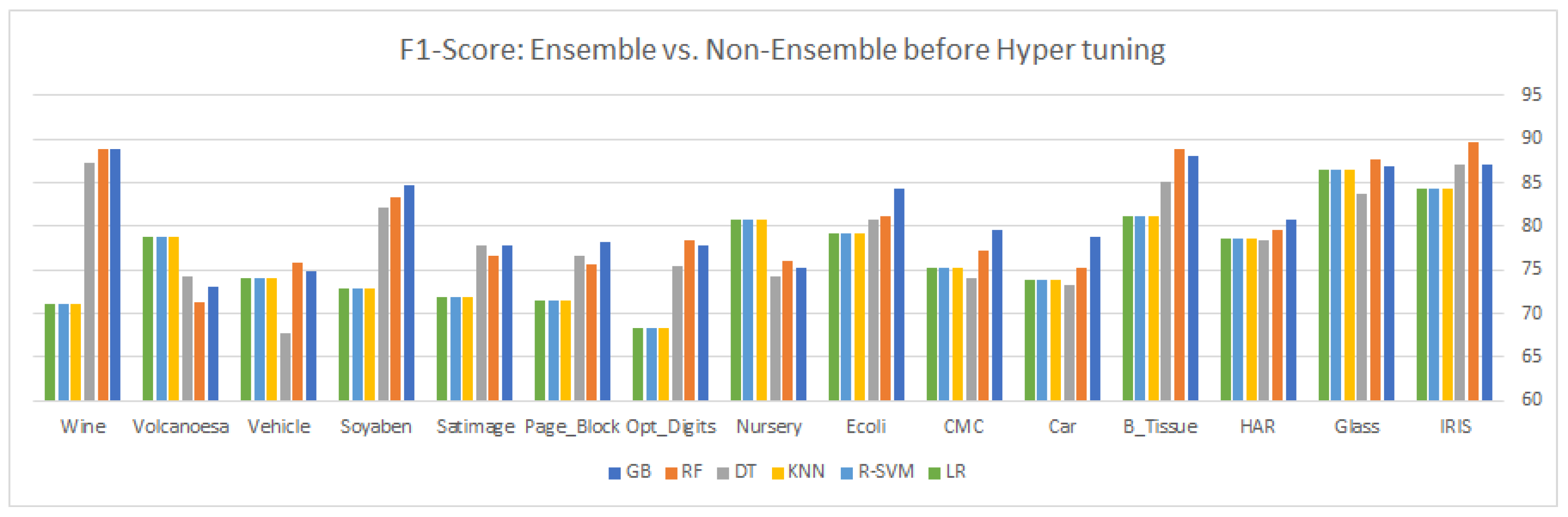
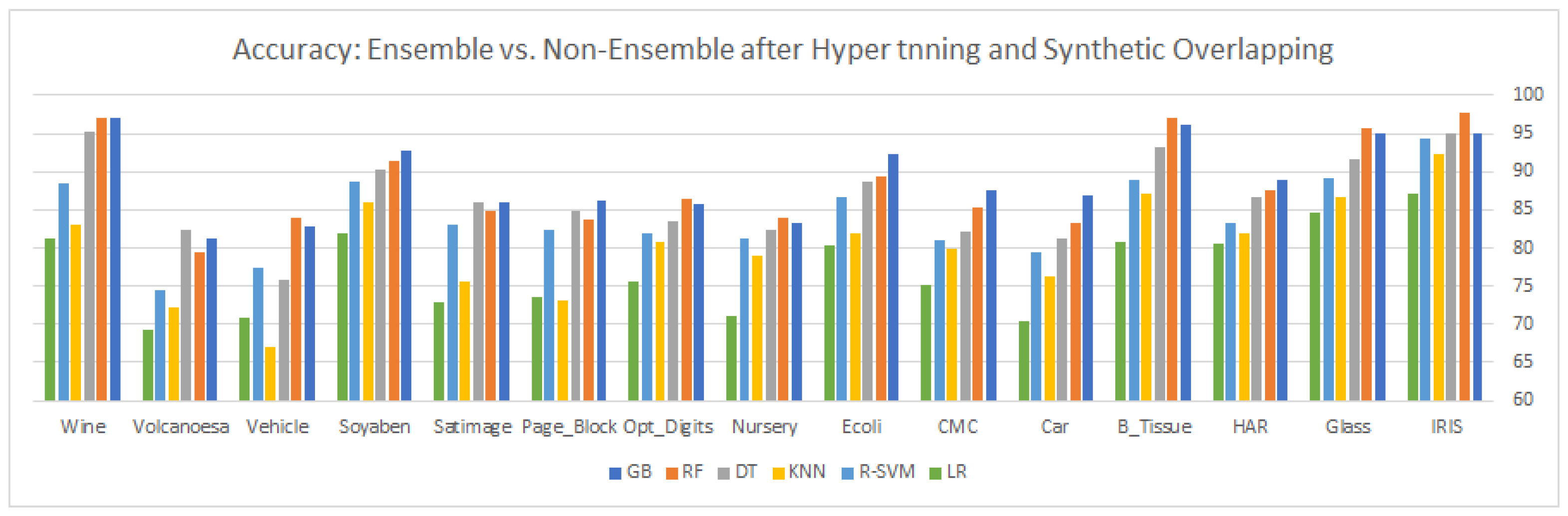
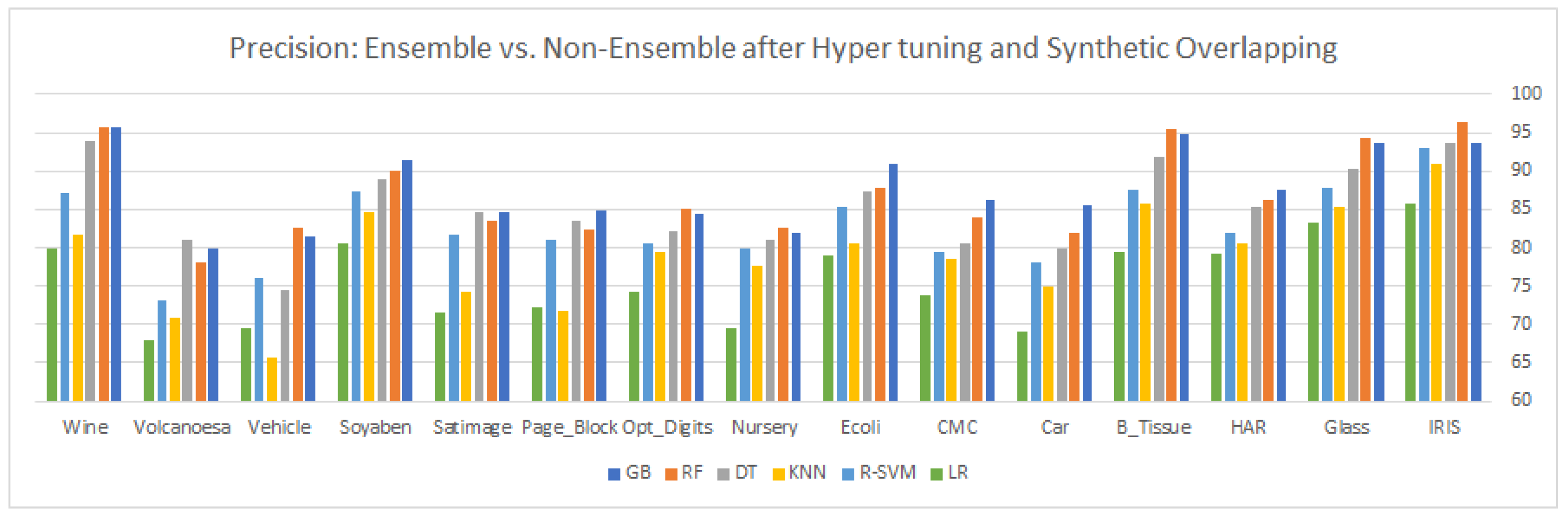
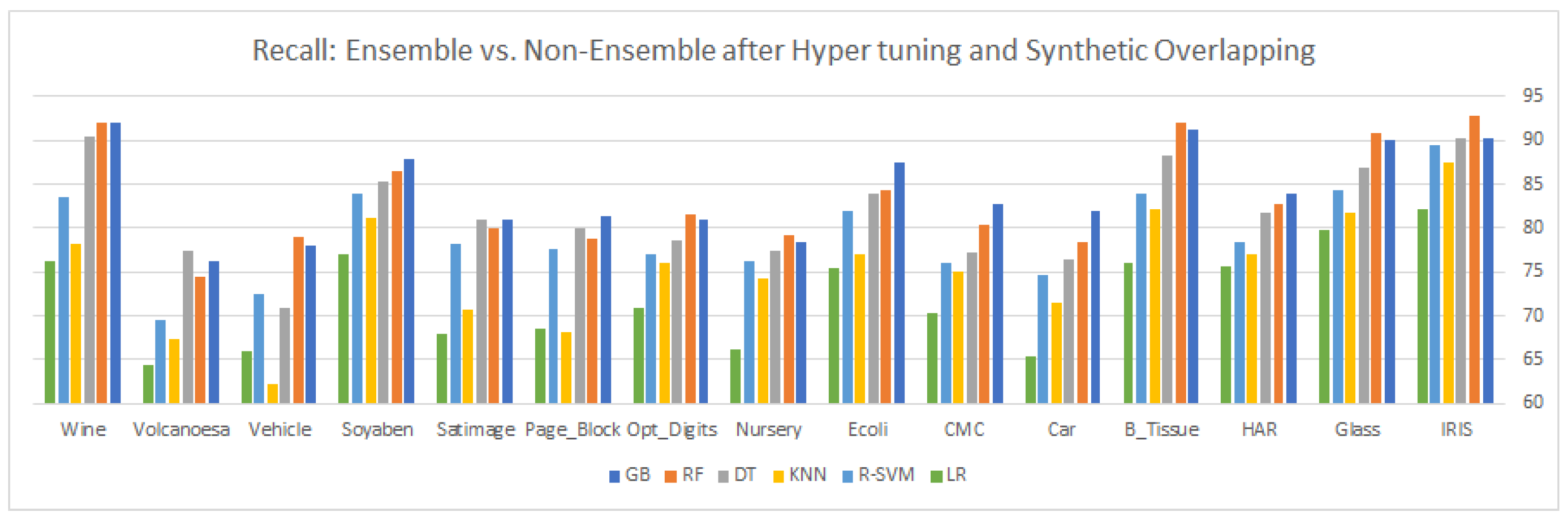
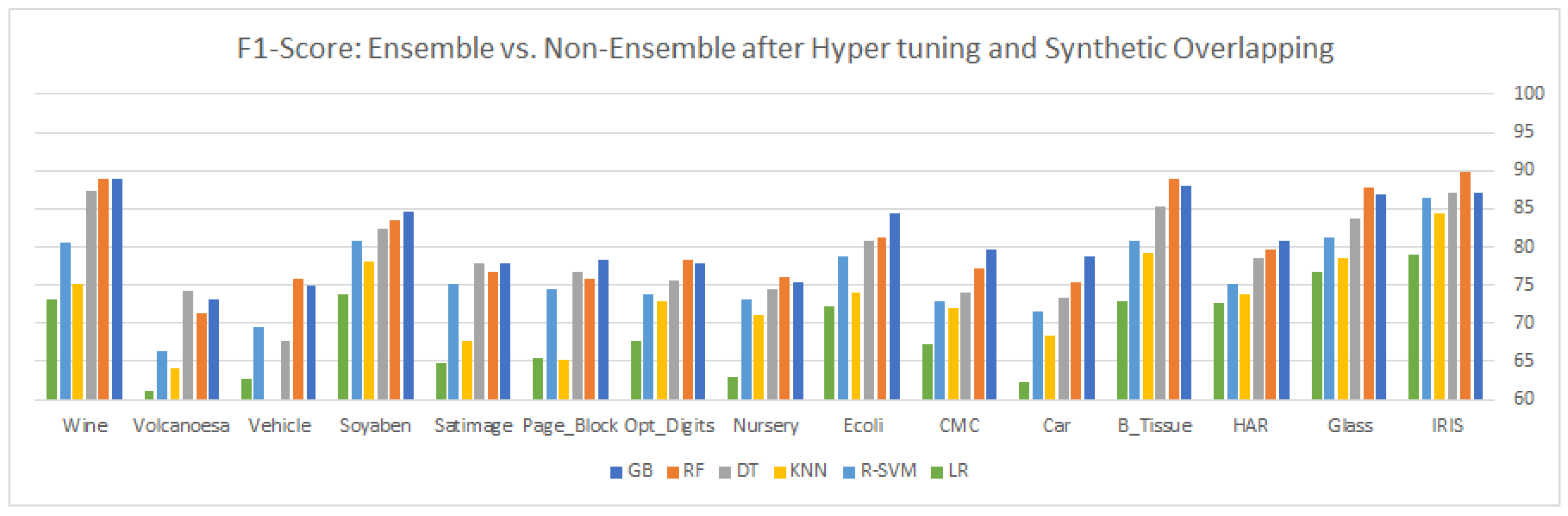
9. Results and Discussion
This article highlights three different aspects of ensemble and statistical classifiers depicted in
Table 5,
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10 supplemented by the relevant graphical presentation in
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8,
Figure 9,
Figure 10,
Figure 11,
Figure 12 and
Figure 13, respectively. This section carried out a detailed comparison to highlight the imbalance and overlapping nature of multi-class classification by applying traditional and ensemble approaches followed by some statistical analysis. Here, we applied different ensemble classifiers (GB, RF, and DT) and non-ensemble approaches (KNN, linear, kernel SVM, and NB) on 15 multi-class datasets. Each dataset consists of a different number of samples, features, and classes, i.e., the instances vary in the range of 150–12,960, while the number of features ranges from 4 to 65 and the number of classes varies between 3 and 20. Our results consist of three parts; first, we explore the six different classifiers on 15 multi-class datasets with default parameters and without synthetic overlapping, using confusion matrix values to gain insight into the different performance measures such as
,
,
, and
as depicted in
Table 5 and
Table 6. In the second step, the six algorithms, namely GB, RF, DT, KNN, R-SVM, and LR are hyper-tuned (hyper-tuning the set of parameters) to improve the overall performance of the classification model, using 10-fold cross-validation in an exhaustive grid search technique experiment shown in
Table 7 and
Table 8.
In the third part, the existing datasets (the majority class of each dataset) are synthetically overlapped by 20% of the original samples to glorify the impact of hyper-tuning the parameters, as shown in
Table 9 and
Table 10. After examining the results, we come up with these observations: gradient boosting an ensemble approach based on boosting shows remarkable performance in all categories (with and without hyper-tuning parameters for existing and synthetically overlapped datasets) for most of the multi-class imbalanced datasets. GB is an ensemble method, which combines many weak learners to produce a strong learner to deliver improved accuracy. A lower weight and a higher weight are assigned to the predicted outcome if it is correctly classified and misclassified, respectively. Each new tree is a fit on the reproduced subset of the original dataset during the boosting process. We tuned the tree-specific parameters during the hyper-tuning, boosting specific parameters and miscellaneous parameters. For some datasets in the experiment, all the classifiers
and
show power performance in terms of both accuracy and precision.
The reason for the power performance is the high variance and poor feature engineering makes it impossible for some algorithms to show a remarkable performance. Although boosting-based ensembles are prominent to control both bias and variance, sometimes with high variance and poor features, engineering them also fails to show a better performance. Along with the gradient boosting algorithm, random forest and decision tree also show some significance as compared to the other used classifier on most of the classifiers, particularly in the dataset with a greater number of features. The main reason for its significance is automatically reducing the number of features through its probabilistic entropy calculation approach. All three ensemble methods, GB, RF, and DT outperform the non-ensemble classifiers with both conventional hyper-tuned parameters for almost all the multi-class datasets. The error or misclassification rate can be dramatically reduced by averaging the component classifiers’ prediction report to produce an optimal final classification report both in a random forest and in the decision tree classifier. In the RFC, multiple trees are used in the ensemble to construct a sample drawn with a replacement from the training set. Moreover, a tree-based RFC ensemble selects a subset of features rather than using all the features of the data in the training set, resulting in the randomization of the tree. A decision tree break downs the classification process into multiple choices about each entry in our feature vector, starting with the root node and going downwards to the leaf where actual classification (prediction) is made. Unlike the traditional algorithm (black box learning algorithm), a decision tree is quite natural, as it visualizes and interprets the choices regarding how the tree is formed, and then follows a suitable path to the leaf node where actual predication or classification is performed. On the other hand, random forest, a collection of decision trees that vaccinate randomness at a certain level, makes it different from the decision tree classifier. The better performance of RF as compared to DT is because injecting randomness at two levels, in bootstrapping and during node splitting, causes a reduction in overfitting and resulting in an accurate model compared to the DT model. RF trains each distant DT on a bootstrapped sample drawn from the initial training dataset. Logistic regression is a linear classifier which can be applied to both linear and nonlinear problems, but as compared to ensemble approaches and SVM with an rbf kernel, the performance of LR is not good, as in other approaches. SVM in both versions (linear and kernel) is one of the most powerful models of machine learning with appropriate skills in separating the hyperplane on both the linear and nonlinear datasets. Sitting a hyperplane for a linear dataset is quite simple, by doing through the linear or rbf kernel, but for nonlinear data, the kernel tricks are used for sitting the hyperplane by projecting the data point in a higher dimension (in this N-dimension, the data points can easily be linearly separable). During the hyper-tuning process, when we set the decision function value to “one-versus-rest”, it decomposes the multi-class problem into several binary class problems, making it convenient for the SVM to find an optimal hyperplane, thus improving its overall model performance. To obtain the most successful results, proper feature engineering and feature scaling must be applied to the training dataset, as the LR model is greatly affected by different value ranges across dependent variables. On the majority of datasets, the poor performance of NB is because of the assumption that instances’ features are conditionally independent, but as we know in the case of the multi-class problem, features depend on each other, thus making this hypothesis wrong, which causes the degradation of the overall performance of the NB model. The basic working mechanism of the KNN model is based on the optimal value selected for k; whenever a new sample is subject to prediction, it simply examines the k-nearest neighbors from the training set, and the majority class among the k nearest neighbors are taken to be class for the test sample. Since the boundary regions of different classes in multi-class classification problems overlap with each other, it becomes difficult to examine the k-nearest neighbors from the training set.
As a final comment about the comparison, if we divide the classifiers between the ensemble and non-ensemble classifiers, the ensemble classifiers outperform the non-ensemble classifier on almost all the datasets with conventional and hyper-tuned parameters. Among the ensemble classifier, there is no constant winner for all the datasets, but overall gradient boosting beats all the classifiers for both categories. In non-ensemble methods, R-SVM shows a remarkable performance with the rbf kernel for both the conventional and tuned parameters, as SVM selects a small subset of training data from the original training data to construct the model. During the hyper-tuning process, when we set the decision function value to “one-versus-rest”, it decomposes the multi-class problem into several binary class problems, making it convenient for the SVM to find an optimal hyperplane, thus improving its overall model performance.
As we stated earlier in
Section 9 about the synthetic generation of controlled overlapping samples in the existing dataset, if we look at the results of
Table 5,
Table 7 and
Table 9, which show the accuracy and precision of the stated classifiers, respectively, the results of
Table 5 are based on the scenarios in which we tested the ensemble and non-ensemble classifiers over the existing multi-class and overlapped dataset to highlight their performance. The result of
Table 7 is based on the scenarios wherein we hyper-tuned the selected parameters of the classifiers using a 10-fold cross-validation and grid search technique, and then applied the selected classifiers to highlight the impact of parameters hyper-tuning over the multi-class and overlapped datasets. After comparing both tables, it is clear that, after hyper-tuning the parameter set, the underlying classifier improved its performance, as discussed in
Section 9. For the third scenario, we synthetically generated overlapping samples and 20% of these samples are inserted into the majority class of each dataset to increase the overlapping region of each dataset generation of synthetic samples is discussed in
Section 10. After inserting the synthetic samples, the samples of majority and minority classes are more overlapped near the boundary region, resulting in a decrease in the visibility of the minority class. After compromising on the visibility of the minority class samples, the underlying classifier cannot predict the relevant target class effectively, hence decreasing the overall classifier performance. If we look at the results of
Table 9, we se the accuracy and precision after the synthetic generation of samples and tuning of the parameters. If we compare the results in
Table 9 with those in
Table 5 and
Table 7, there is a slight change in the classifier performance, even after the insertion of the synthetic samples in the majority of classes. The same justification is for recall and
as depicted in
Table 6,
Table 8 and
Table 10.
10. Resultant Summary for Ensemble and Non-Ensemble Classifiers
As a final comment about the comparison, if we divide the classifiers into ensemble and non-ensemble (traditional) classifiers, the ensemble classifiers outperform the non-ensemble classifiers on almost all the datasets with conventional and hyper-tuned parameters.
Among the ensemble classifier, there is no constant winner for all the datasets, but overall, gradient boosting beats all the classifiers for both categories. In non-ensemble methods, R-SVM shows a remarkable performance with the rbf kernel for both the conventional and tuned parameters, as SVM selects a small subset of training data from the original training data to construct the model. The increasing size and dimensions of the problem space make it difficult for traditional or non-ensemble classifiers to correctly predict the unseen samples for multi-class classification data. The main reason behind the poor performance of traditional classifiers is the inability to tackle the high bias and variance. Despite so many machine-learning algorithms, the data to be processed need to be carefully examined, as every time, the data are biased, have high variance, or are sometimes noisy. When these unprocessed data (data with bias, variance, and noise) are subject to classification using the traditional algorithms, most of the time, we obtain a specialized model based on the training set, which yields low accuracy and loses of results. Due to the high bias, the underlying machine learning algorithm is unable to make a meaningful relation between the target variables (class labels) and the features, causing underfitting, which will reduce the overall performance of the classifiers on the testing set. On the other hand, high variance results in the random noise as a part of the training dataset, rather than the intended outputs, because the high variance in the underlying model tends to overfit on training data, resulting in a non-generalized model for the prediction. Compared to traditional classifiers, ensemble approaches try to reduce the variance and bias in the training data, resulting in a more robust and generalized model for the multi-class classification problem. The variance–bias tradeoff is a significant problem in almost all machine learning classifiers, particularly in the case of multi-class classification, where the boundaries of different classes are overlaps with each other’s, making it difficult to draw a clear hyperplane to separate the samples of multi classes. To correctly classify the unseen data during the validation process, ideally one can desire to choose such a machine-learning model, which apprehends the consistencies in its training dataset (effectively addressing the high variance and bias), also avoiding the under-fitting and over-fitting issues. Unfortunately, for most traditional classifiers, it is not an easy task to simultaneously reduce the high variance and bias. On the other hand, the ensemble approaches follow the ‘component-classifiers’ approach, wherein at each iteration, the misclassified sample (caused by high variance and bias) is again subject to the training subset. Ensemble classifiers are working in a parallel mode by assigning individual base learners to a ‘different-different machine’. In short, ensemble approaches are just like a ‘meta-algorithm’ by combining different learning models into a more robust single model to improve the overall performance of the underlying model. The high bias in the training data was reduced via the boosting approach and the high variance was reduced via the bagging approach. All the acronyms used in this article are defined in
Table 12.
11. Conclusions
In this paper, we applied six different algorithms (ensemble and non-ensemble) on 15 multi-class datasets with default parameters, and then compared the results with hyper-tuned parameters. The results highlight the significant improvement in the categories of the algorithm after both hyper-tuning a set of parameters and performing an exhaustive grid search technique. However, ensemble approaches outperform the non-ensemble approaches for the majority of multi-class classification datasets. Before applying classification algorithms to the stated imbalanced dataset, we did not apply any data-level approach to balance the dataset. Similarly, after synthetically overlapping the existing datasets, ensemble classifiers show the same results compared to statistical approaches. The results can be further improved if we augment the data level approaches with the ensemble and non-ensemble approaches.
As a future direction, if we perform proper feature engineering on the multi-class imbalanced dataset, the results will surely improve. A combination of ensemble classifiers with a cost-sensitive approach (assigning misclassification cost) can significantly improve the overall performance of the different classifiers. One-class learners, within-class imbalance, small disjuncts, feature selection, stacked ensembles, sophisticated over-sampling techniques, and within-class imbalance are among the research gaps that need to be specially addressed in a future study.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}