
Cloud Gaming Video Coding Optimization Based on Camera Motion-Guided Reference Frame Enhancement

Abstract
:1. Introduction
- We propose a coding optimization algorithm for cloud gaming videos applying deep learning techniques to optimize traditional video codecs, which generates an enhanced reference frame with high relation to the frame to be encoded and adds it to the reference frame list for better compression;
- Our proposed CMGNet for generating enhanced reference frames uses camera motions as guidance to estimate more accurate pixel-level motions for frame alignment, significantly enhancing the quality of the reference frame;
- We have established a game video dataset containing sufficient rendering frames and camera motions to promote research on game video compression;
- Experimental results demonstrated the effectiveness of the proposed coding optimization algorithm for cloud gaming videos.
2. Related Work
2.1. Video Compression
2.2. Video Quality Enhancement
3. The Proposed Coding Optimization Algorithm and Network Architecture
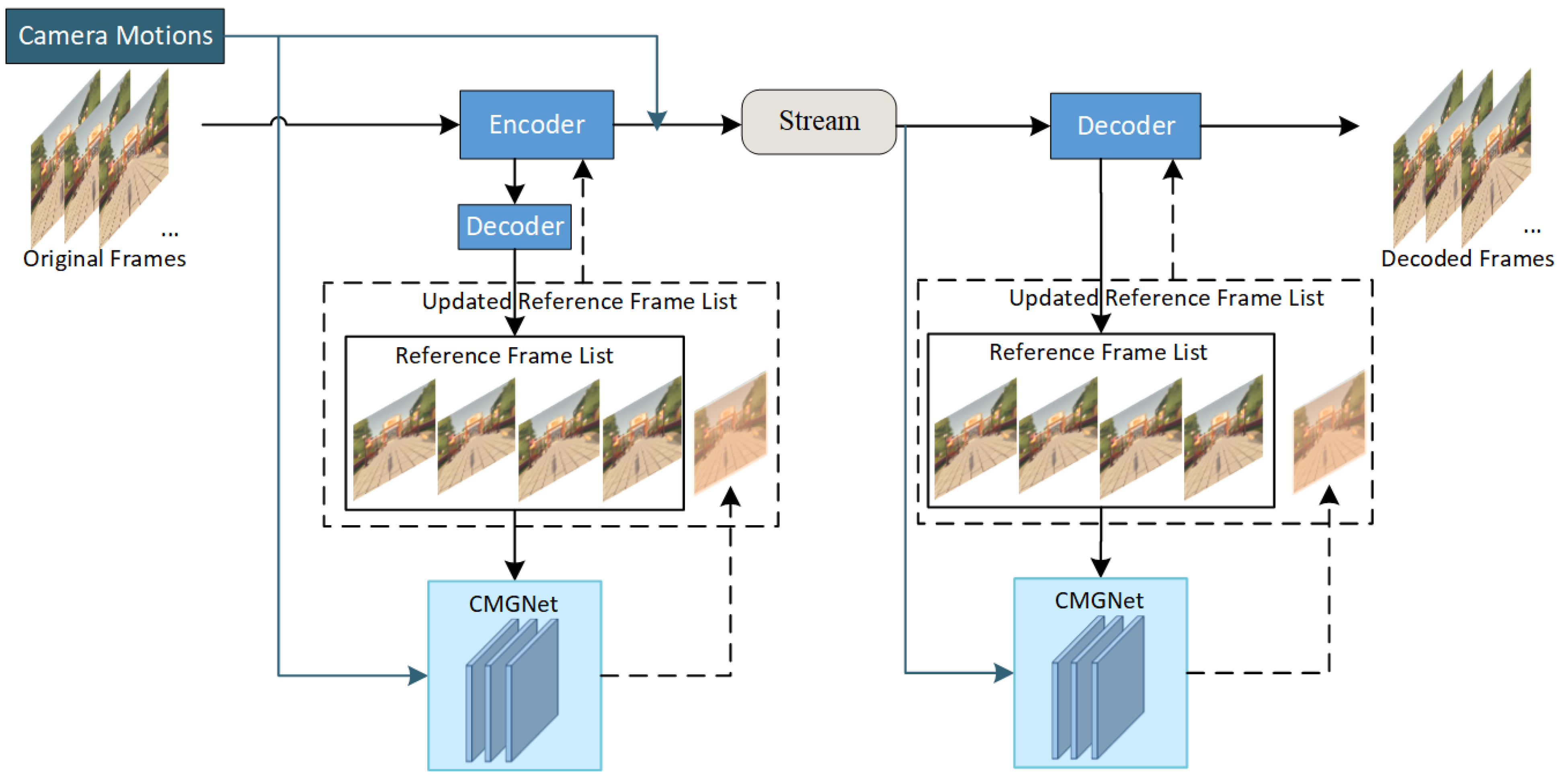
3.1. Algorithm Overview
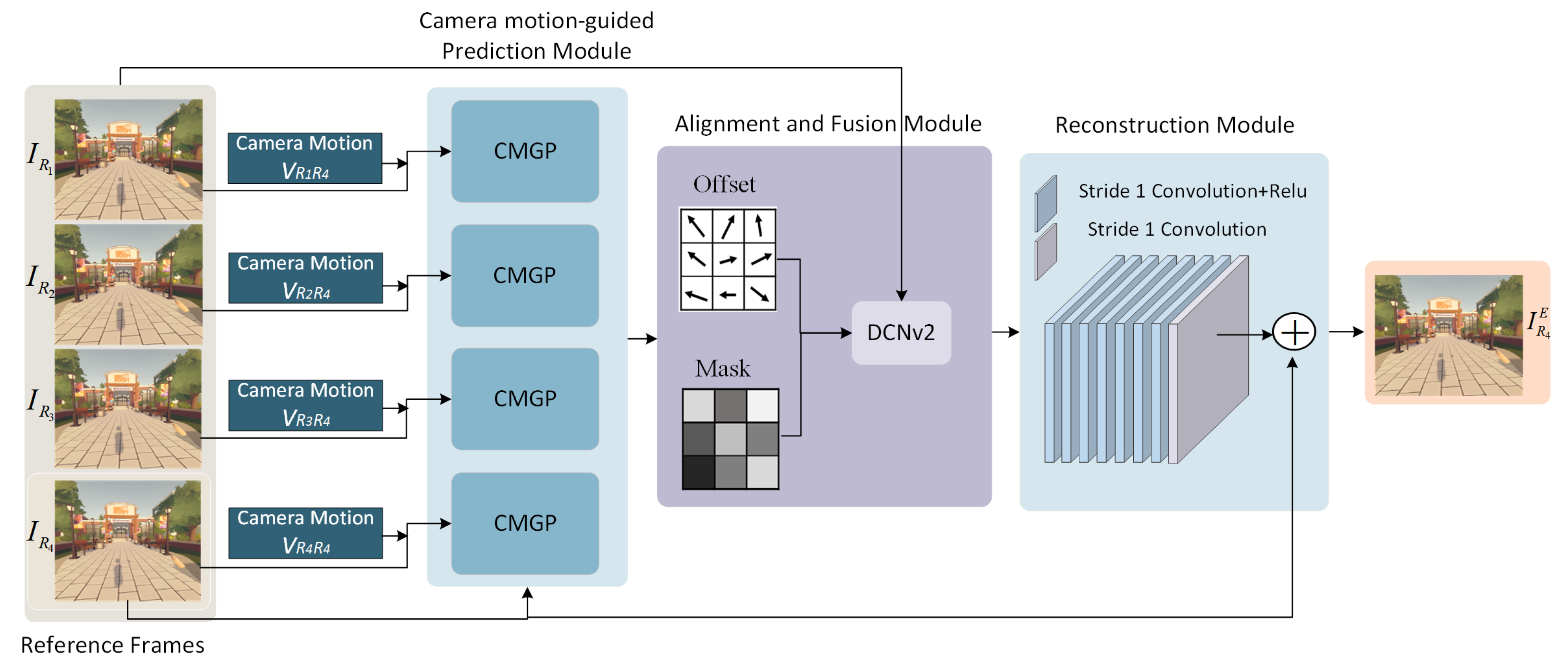
3.2. Network Architecture
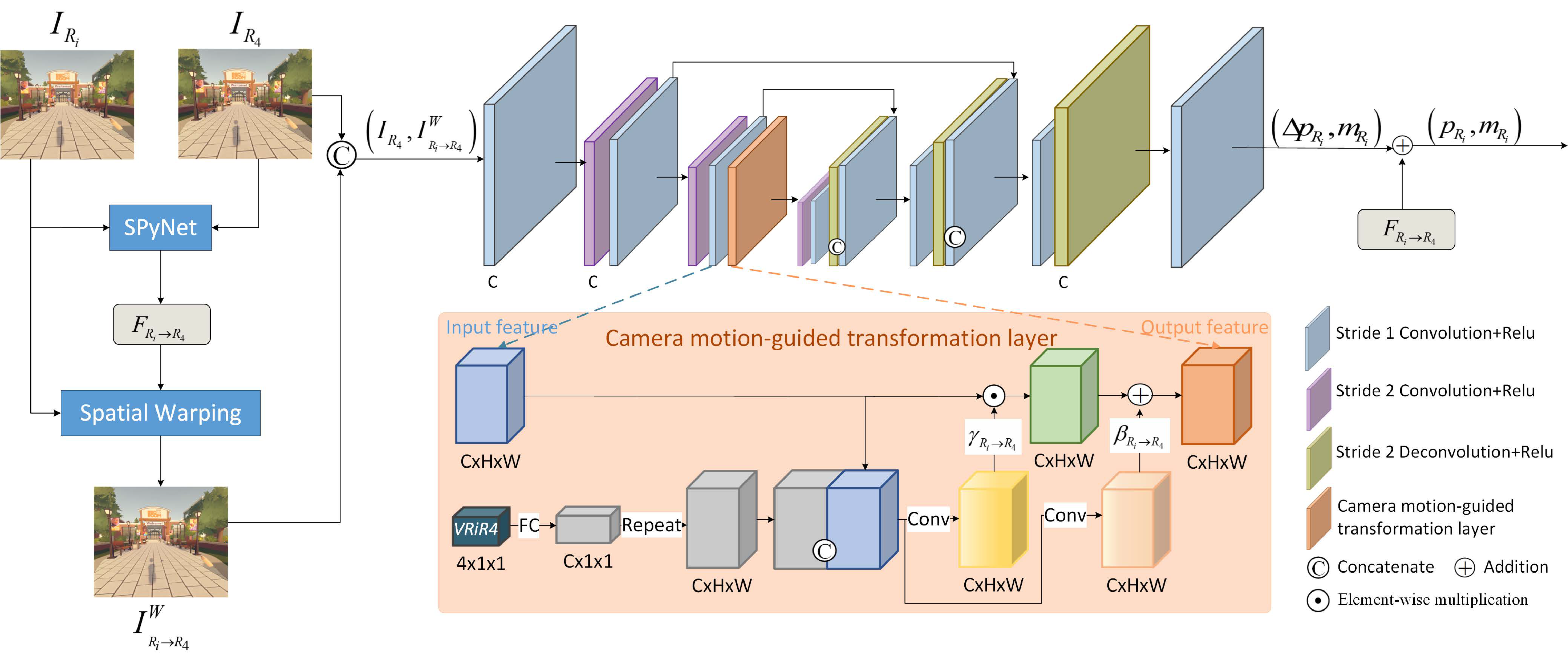
3.2.1. Camera Motion-Guided Prediction (CMGP)
3.2.2. Loss Function
4. Experiments
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Implementation Details
4.2. Experimental Results
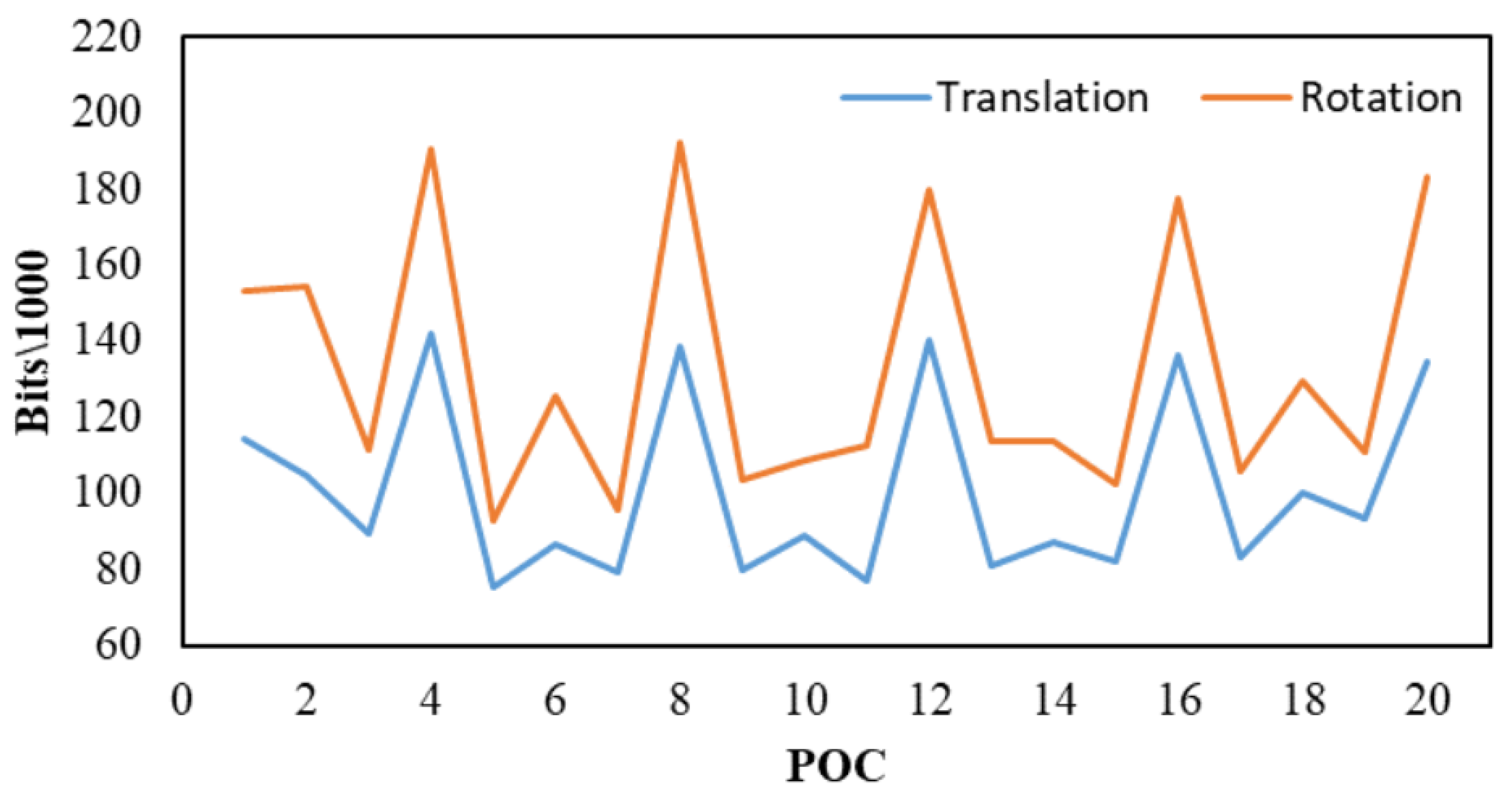
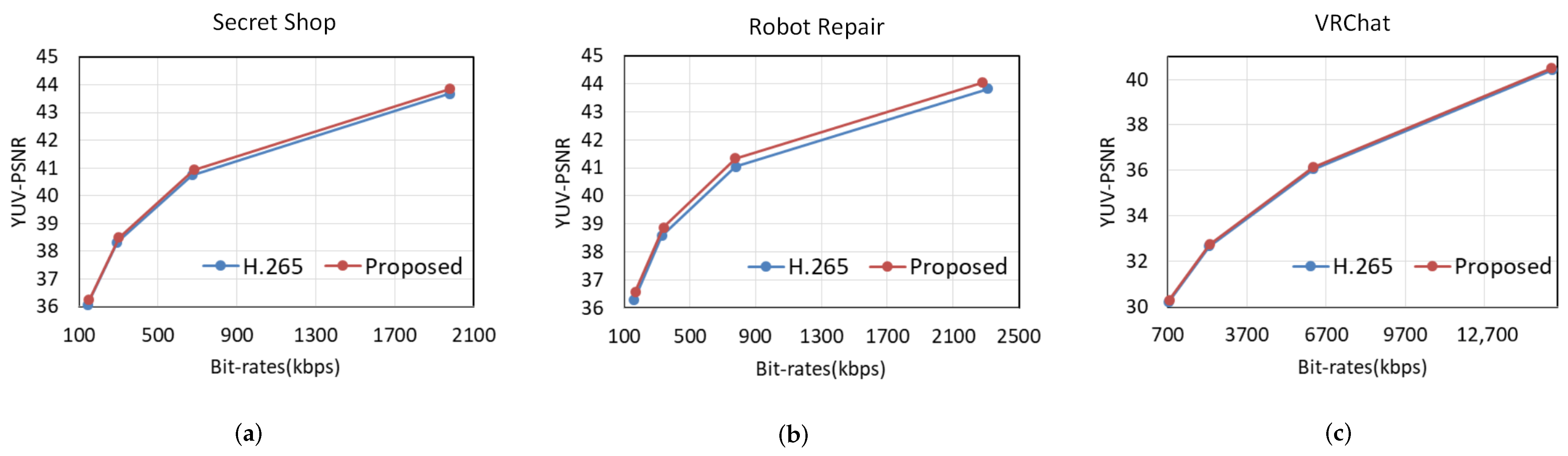
4.2.1. Compression Performance of the Coding Optimization Algorithm
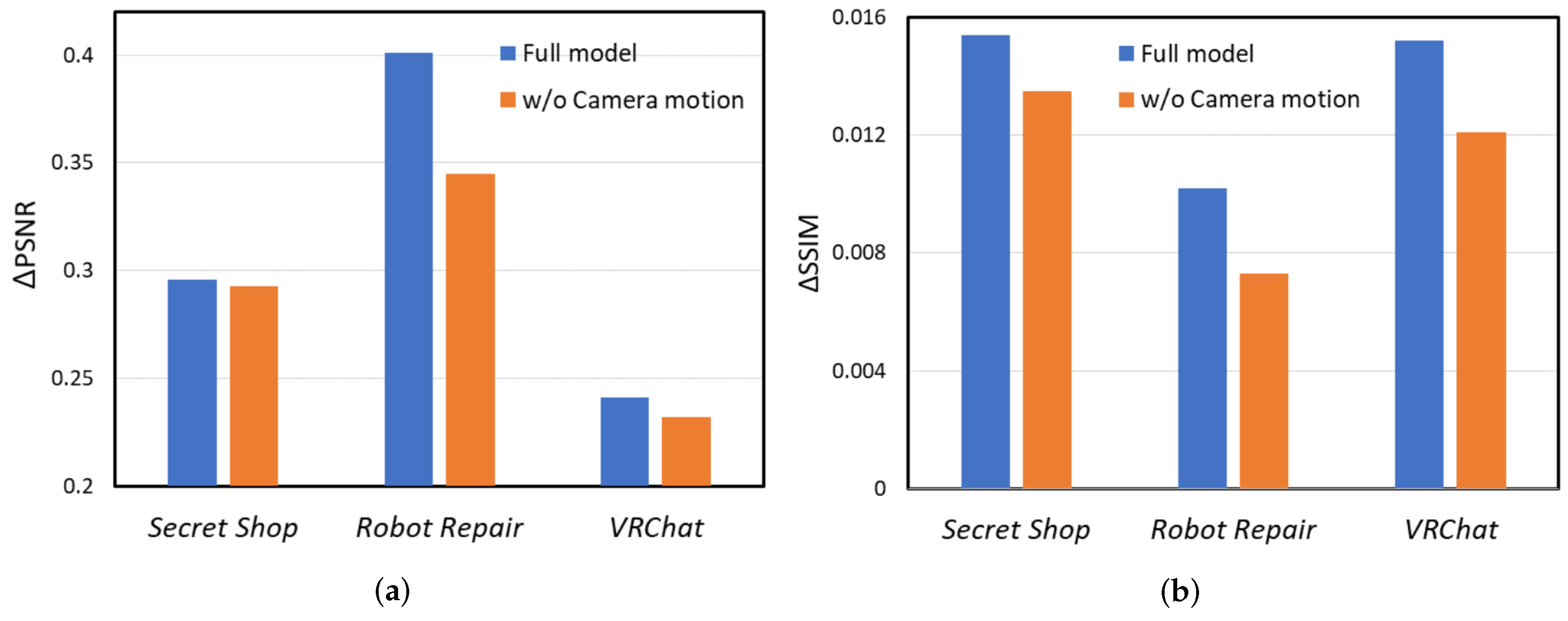
4.2.2. Quality Enhancement of the Proposed CMGNet
4.2.3. Comparison to State-of-the-Arts
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cai, W.; Shea, R.; Huang, C.Y.; Chen, K.T.; Liu, J.; Leung, V.C.; Hsu, C.H. A survey on cloud gaming: Future of computer games. IEEE Access 2016, 4, 7605–7620. [Google Scholar] [CrossRef]
- Mossad, O.; Diab, K.; Amer, I.; Hefeeda, M. DeepGame: Efficient Video Encoding for Cloud Gaming. In Proceedings of the Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 1387–1395. [Google Scholar]
- Xu, L.; Guo, X.; Lu, Y.; Li, S.; Au, O.C.; Fang, L. A low latency cloud gaming system using edge preserved image homography. In Proceedings of the 2014 IEEE International Conference on Multimedia and Expo (ICME), Chengdu, China, 14–18 July 2014; pp. 1–6. [Google Scholar]
- Lin, J.; Liu, D.; Li, H.; Wu, F. Generative adversarial network-based frame extrapolation for video coding. In Proceedings of the 2018 IEEE Visual Communications and Image Processing (VCIP), Taichung, Taiwan, 9–12 December 2018; pp. 1–4. [Google Scholar]
- Zhao, L.; Wang, S.; Zhang, X.; Wang, S.; Ma, S.; Gao, W. Enhanced ctu-level inter prediction with deep frame rate up-conversion for high efficiency video coding. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 206–210. [Google Scholar]
- Zhao, L.; Wang, S.; Zhang, X.; Wang, S.; Ma, S.; Gao, W. Enhanced motion-compensated video coding with deep virtual reference frame generation. IEEE Trans. Image Process. 2019, 28, 4832–4844. [Google Scholar] [CrossRef]
- Sullivan, G.J.; Ohm, J.R.; Han, W.J.; Wiegand, T. Overview of the high efficiency video coding (HEVC) standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Wiegand, T.; Sullivan, G.J.; Bjontegaard, G.; Luthra, A. Overview of the H. 264/AVC video coding standard. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 560–576. [Google Scholar] [CrossRef]
- Zhao, T.; Wang, Z.; Kwong, S. Flexible mode selection and complexity allocation in high efficiency video coding. IEEE J. Sel. Top. Signal Process. 2013, 7, 1135–1144. [Google Scholar] [CrossRef]
- Zhang, J.; Kwong, S.; Zhao, T.; Pan, Z. CTU-level complexity control for high efficiency video coding. IEEE Trans. Multimed. 2017, 20, 29–44. [Google Scholar] [CrossRef]
- Zhang, J.; Kwong, S.; Zhao, T.; Wang, X.; Wang, S. Complexity Control for HEVC Inter Coding Based on Two-Level Complexity Allocation and Mode Sorting. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3628–3632. [Google Scholar]
- Correa, G.; Assuncao, P.; Agostini, L.; da Silva Cruz, L.A. Complexity scalability for real-time HEVC encoders. J. Real-Time Image Process. 2016, 12, 107–122. [Google Scholar] [CrossRef]
- Norkin, A.; Bjontegaard, G.; Fuldseth, A.; Narroschke, M.; Ikeda, M.; Andersson, K.; Zhou, M.; Van der Auwera, G. HEVC deblocking filter. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1746–1754. [Google Scholar] [CrossRef]
- Fu, C.M.; Alshina, E.; Alshin, A.; Huang, Y.W.; Chen, C.Y.; Tsai, C.Y.; Hsu, C.W.; Lei, S.M.; Park, J.H.; Han, W.J. Sample adaptive offset in the HEVC standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1755–1764. [Google Scholar] [CrossRef]
- Helle, P.; Oudin, S.; Bross, B.; Marpe, D.; Bici, M.O.; Ugur, K.; Jung, J.; Clare, G.; Wiegand, T. Block merging for quadtree-based partitioning in HEVC. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1720–1731. [Google Scholar] [CrossRef]
- Lainema, J.; Bossen, F.; Han, W.J.; Min, J.; Ugur, K. Intra coding of the HEVC standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1792–1801. [Google Scholar] [CrossRef]
- Belyaev, E.; Forchhammer, S. An efficient storage of infrared video of drone inspections via iterative aerial map construction. IEEE Signal Process. Lett. 2019, 26, 1157–1161. [Google Scholar] [CrossRef]
- Wang, X.; Hu, R.; Wang, Z.; Xiao, J. Virtual background reference frame based satellite video coding. IEEE Signal Process. Lett. 2018, 25, 1445–1449. [Google Scholar] [CrossRef]
- Li, H.; Ding, W.; Shi, Y.; Yin, W. A double background based coding scheme for surveillance videos. In Proceedings of the 2018 Data Compression Conference, Snowbird, UT, USA, 27–30 March 2018; p. 420. [Google Scholar]
- Wang, G.; Li, B.; Zhang, Y.; Yang, J. Background modeling and referencing for moving cameras-captured surveillance video coding in HEVC. IEEE Trans. Multimed. 2018, 20, 2921–2934. [Google Scholar] [CrossRef]
- Yan, N.; Liu, D.; Li, H.; Wu, F. A convolutional neural network approach for half-pel interpolation in video coding. In Proceedings of the 2017 IEEE international symposium on circuits and systems (ISCAS), Baltimore, MD, USA, 28–31 May 2017; pp. 1–4. [Google Scholar]
- Zhang, H.; Song, L.; Luo, Z.; Yang, X. Learning a convolutional neural network for fractional interpolation in HEVC inter coding. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Yan, N.; Liu, D.; Li, H.; Li, B.; Li, L.; Wu, F. Convolutional neural network-based fractional-pixel motion compensation. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 840–853. [Google Scholar] [CrossRef]
- Yan, N.; Liu, D.; Li, H.; Xu, T.; Wu, F.; Li, B. Convolutional neural network-based invertible half-pixel interpolation filter for video coding. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 201–205. [Google Scholar]
- Zhao, Z.; Wang, S.; Wang, S.; Zhang, X.; Ma, S.; Yang, J. Enhanced bi-prediction with convolutional neural network for high-efficiency video coding. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 3291–3301. [Google Scholar] [CrossRef]
- Dong, C.; Deng, Y.; Loy, C.C.; Tang, X. Compression artifacts reduction by a deep convolutional network. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 11–18 December 2015; pp. 576–584. [Google Scholar]
- Park, W.S.; Kim, M. CNN-based in-loop filtering for coding efficiency improvement. In Proceedings of the 2016 IEEE 12th Image, Video, and Multidimensional Signal Processing Workshop (IVMSP), Bordeaux, France, 11–12 July 2016; pp. 1–5. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef]
- Dai, Y.; Liu, D.; Wu, F. A convolutional neural network approach for post-processing in HEVC intra coding. In Proceedings of the International Conference on Multimedia Modeling, Reykjavik, Iceland, 4–6 January 2017; pp. 28–39. [Google Scholar]
- Zhang, Y.; Shen, T.; Ji, X.; Zhang, Y.; Xiong, R.; Dai, Q. Residual highway convolutional neural networks for in-loop filtering in HEVC. IEEE Trans. Image Process. 2018, 27, 3827–3841. [Google Scholar] [CrossRef]
- Xia, J.; Wen, J. Asymmetric convolutional residual network for av1 intra in-loop filtering. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 1291–1295. [Google Scholar]
- Zhang, S.; Fan, Z.; Ling, N.; Jiang, M. Recursive residual convolutional neural network-based in-loop filtering for intra frames. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1888–1900. [Google Scholar] [CrossRef]
- Kang, J.; Kim, S.; Lee, K.M. Multi-modal/multi-scale convolutional neural network based in-loop filter design for next generation video codec. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 26–30. [Google Scholar]
- Wang, D.; Xia, S.; Yang, W.; Hu, Y.; Liu, J. Partition tree guided progressive rethinking network for in-loop filtering of HEVC. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 2671–2675. [Google Scholar]
- Li, D.; Yu, L. An in-loop filter based on low-complexity CNN using residuals in intra video coding. In Proceedings of the 2019 IEEE International Symposium on Circuits and Systems (ISCAS), Sapporo, Japan, 26–29 May 2019; pp. 1–5. [Google Scholar]
- Zhu, H.; Xu, X.; Liu, S. Residual convolutional neural network based in-loop filter with intra and inter frames processed, respectively, for Avs3. In Proceedings of the 2020 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Lu, M.; Cheng, M.; Xu, Y.; Pu, S.; Shen, Q.; Ma, Z. Learned quality enhancement via multi-frame priors for HEVC compliant low-delay applications. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 934–938. [Google Scholar]
- Tong, J.; Wu, X.; Ding, D.; Zhu, Z.; Liu, Z. Learning-based multi-frame video quality enhancement. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 929–933. [Google Scholar]
- Meng, X.; Deng, X.; Zhu, S.; Zhang, X.; Zeng, B. A robust quality enhancement method based on joint spatial-temporal priors for video coding. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 2401–2414. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Van Der Smagt, P.; Cremers, D.; Brox, T. Flownet: Learning optical flow with convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 2758–2766. [Google Scholar]
- Sun, D.; Yang, X.; Liu, M.Y.; Kautz, J. Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8934–8943. [Google Scholar]
- Yang, R.; Xu, M.; Wang, Z.; Li, T. Multi-frame quality enhancement for compressed video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6664–6673. [Google Scholar]
- Guan, Z.; Xing, Q.; Xu, M.; Yang, R.; Liu, T.; Wang, Z. MFQE 2.0: A new approach for multi-frame quality enhancement on compressed video. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 949–963. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Wang, L.; Pu, S.; Zhuo, C. Spatio-temporal deformable convolution for compressed video quality enhancement. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10696–10703. [Google Scholar]
- Zhao, M.; Xu, Y.; Zhou, S. Recursive fusion and deformable spatiotemporal attention for video compression artifact reduction. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 5646–5654. [Google Scholar]
- Lin, J.; Huang, Y.; Wang, L. FDAN: Flow-guided deformable alignment network for video super-resolution. arXiv 2021, arXiv:2105.05640. [Google Scholar]
- Chan, K.C.; Zhou, S.; Xu, X.; Loy, C.C. BasicVSR++: Improving video super-resolution with enhanced propagation and alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 5972–5981. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9308–9316. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on cOmputer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Ranjan, A.; Black, M.J. Optical flow estimation using a spatial pyramid network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4161–4170. [Google Scholar]
- Chen, P.; Yang, W.; Wang, M.; Sun, L.; Hu, K.; Wang, S. Compressed Domain Deep Video Super-Resolution. IEEE Trans. Image Process. 2021, 30, 7156–7169. [Google Scholar] [CrossRef] [PubMed]
- ALVR. Available online: https://github.com/alvr-org (accessed on 8 May 2022).
- The Lab. Available online: https://store.steampowered.com/app/450390/The_Lab/ (accessed on 23 May 2022).
- Half-Life: Alyx. Available online: https://store.steampowered.com/app/546560/HalfLife_Alyx/ (accessed on 23 May 2022).
- Hover The Edge. Available online: https://store.steampowered.com/app/1822130/Hover_The_Edge/ (accessed on 23 May 2022).
- Rec Room. Available online: https://store.steampowered.com/app/471710/Rec_Room/ (accessed on 23 May 2022).
- VRChat. Available online: https://store.steampowered.com/app/438100/VRChat/ (accessed on 23 May 2022).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Bjøntegaard, G. Calculation of average PSNR differences between RD-curves. VCEG-M33 2001, 16090, 1520–9210. [Google Scholar]
- Tian, Y.; Zhang, Y.; Fu, Y.; Xu, C. Tdan: Temporally-deformable alignment network for video super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3360–3369. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequences | BD-Rate | BD-PSNR |
|---|---|---|
| Secret Shop | −4.03% | 0.1210 |
| Robot Repair | −8.51% | 0.2540 |
| VRChat | −2.20% | 0.0761 |
| Avreage | −4.91% | 0.1503 |
| Sequences | Δ | Δ | Δ |
|---|---|---|---|
| Secret Shop | 142% | 11,023% | 164% |
| Robot Repair | 140% | 11,796% | 163% |
| VRChat | 130% | 6747% | 144% |
| Avreage | 137% | 9856% | 157% |
| Sequences | Methods PSNR(dB) | QP = 22 | QP = 27 | QP = 32 | QP = 37 | ||||
|---|---|---|---|---|---|---|---|---|---|
| SSIM | PSNR(dB) | SSIM | PSNR(dB) | SSIM | PSNR(dB) | SSIM | |||
| Secret Shop | H.265 | 43.754 | 0.9417 | 40.845 | 0.9071 | 38.419 | 0.8642 | 36.183 | 0.8121 |
| CMGNet | 44.214 | 0.9477 | 41.320 | 0.9169 | 38.815 | 0.8743 | 36.479 | 0.8275 | |
| Robot Repair | H.265 | 43.850 | 0.9572 | 41.105 | 0.9347 | 38.677 | 0.9051 | 36.405 | 0.8648 |
| CMGNet | 44.372 | 0.9613 | 41.606 | 0.9409 | 39.145 | 0.9139 | 36.806 | 0.8750 | |
| VRChat | H.265 | 40.494 | 0.9453 | 36.169 | 0.8931 | 32.763 | 0.8217 | 30.267 | 0.7382 |
| CMGNet | 40.856 | 0.9493 | 36.518 | 0.9013 | 33.055 | 0.8318 | 30.508 | 0.7534 | |
| Average | H.265 | 42.699 | 0.9481 | 39.373 | 0.9116 | 36.620 | 0.8637 | 34.285 | 0.8050 |
| CMGNet | 43.147 | 0.9528 | 39.815 | 0.9197 | 37.005 | 0.8733 | 34.598 | 0.8186 | |
| QP | Sequences | MFQE 2.0 (408.03 K) | STDF (540.51 K) | TDAN (2.74 M) | CMGNet (Proposed) (1.96 M) | ||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||
| 22 | Secret Shop | 44.210 | 0.9487 | 44.193 | 0.9476 | 44.199 | 0.9471 | 44.214 | 0.9477 |
| Robot Repair | 44.258 | 0.9599 | 44.352 | 0.9613 | 44.332 | 0.9612 | 44.372 | 0.9613 | |
| VRChat | 40.829 | 0.9513 | 40.864 | 0.9500 | 40.793 | 0.9492 | 40.856 | 0.9493 | |
| Average | 43.099 | 0.9533 | 43.136 | 0.9530 | 43.108 | 0.9525 | 43.147 | 0.9528 | |
| 27 | Secret Shop | 41.269 | 0.9170 | 41.245 | 0.9156 | 41.210 | 0.9124 | 41.320 | 0.9169 |
| Robot Repair | 41.527 | 0.9383 | 41.540 | 0.9403 | 41.373 | 0.9380 | 41.606 | 0.9409 | |
| VRChat | 36.476 | 0.9026 | 36.496 | 0.9010 | 36.375 | 0.8981 | 36.518 | 0.9013 | |
| Average | 39.757 | 0.9193 | 39.760 | 0.9190 | 39.653 | 0.9162 | 39.815 | 0.9197 | |
| 32 | Secret Shop | 38.809 | 0.8751 | 38.761 | 0.8747 | 38.740 | 0.8626 | 38.815 | 0.8743 |
| Robot Repair | 39.118 | 0.9094 | 39.185 | 0.9141 | 39.173 | 0.9133 | 39.145 | 0.9139 | |
| VRChat | 33.030 | 0.8334 | 33.044 | 0.8326 | 32.990 | 0.8300 | 33.055 | 0.8318 | |
| Average | 36.986 | 0.8726 | 36.997 | 0.8738 | 36.967 | 0.8687 | 37.005 | 0.8733 | |
| 37 | Secret Shop | 36.479 | 0.8130 | 36.410 | 0.8244 | 36.235 | 0.7825 | 36.479 | 0.8275 |
| Robot Repair | 36.670 | 0.8615 | 36.767 | 0.8723 | 36.767 | 0.8730 | 36.806 | 0.8750 | |
| VRChat | 30.502 | 0.7450 | 30.507 | 0.7528 | 30.505 | 0.7532 | 30.508 | 0.7534 | |
| Average | 34.550 | 0.8065 | 34.561 | 0.8165 | 34.502 | 0.8029 | 34.598 | 0.8186 | |
| Average | 38.598 | 0.8879 | 38.614 | 0.8906 | 38.558 | 0.8851 | 38.641 | 0.8911 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Wang, H.; Wang, K.; Zhang, W. Cloud Gaming Video Coding Optimization Based on Camera Motion-Guided Reference Frame Enhancement. Appl. Sci. 2022, 12, 8504. https://doi.org/10.3390/app12178504
Wang Y, Wang H, Wang K, Zhang W. Cloud Gaming Video Coding Optimization Based on Camera Motion-Guided Reference Frame Enhancement. Applied Sciences. 2022; 12(17):8504. https://doi.org/10.3390/app12178504
Chicago/Turabian StyleWang, Yifan, Hao Wang, Kaijie Wang, and Wei Zhang. 2022. "Cloud Gaming Video Coding Optimization Based on Camera Motion-Guided Reference Frame Enhancement" Applied Sciences 12, no. 17: 8504. https://doi.org/10.3390/app12178504
APA StyleWang, Y., Wang, H., Wang, K., & Zhang, W. (2022). Cloud Gaming Video Coding Optimization Based on Camera Motion-Guided Reference Frame Enhancement. Applied Sciences, 12(17), 8504. https://doi.org/10.3390/app12178504