1. Introduction
ADS-B is the next-generation Air Traffic Control (ATC) surveillance system identified by the International Civil Aviation Organization (ICAO) [
1]. The space-based ADS-B system places the ADS-B receivers on low-orbiting satellites to overcome the limitations of traditional radar and ground-based ADS-B systems [
2]. Each aircraft in the airspace can be monitored and located in the shortest time. Then, the accidents such as MH370 and AF447 can be effectively avoided. However, the number of aircraft covered by a space-based receiver is becoming larger with the development of aviation industry [
3]. It is easy for different ADS-B signals reaching the receiver simultaneously and overlapping. Thus, the signal separation methods are essential in the space-based ADS-B system. Depending on the type of antennas required, the ADS-B signal separation methods can be classified into single-antenna based and array-antenna based separation methods. At present, array-antenna based separation algorithms [
4,
5,
6] are widely studied. They use the spatial characteristics of ADS-B signals for signal separation. However, if the direction difference of arrival between overlapping signals is less than the array resolution or the receiver only has single antenna, the array-antenna based separation methods will fail. In this case, single-antenna based separation algorithms can be used to separate the overlapped signals.
So far, the ADS-B signal separation algorithms based on a single antenna can be divided into three categories. The first approach is to utilize the power difference between overlapping signals. At present, this approach can only separate two signals, and cannot separate the overlapping signals with a small power difference effectively. For example, Wu et al. [
7] proposed an accumulation and classification algorithm. The signals are separated based on k-means algorithm by using the power difference. Moreover, this method has a high accuracy when the power difference between signals is over 3 dB. Yu et al. [
8] proposed a reconstruction and cancellation algorithm. This method fails when the input SNR of overlapped signals are low or the power difference between two signals is large. Furthermore, Li et al. [
9] proposed a time-domain ADS-B blind signal separation (TDBSS) algorithm. Since the amplitude values of the two signals need to be estimated, the method requires a certain relative time delay between the overlapped signals, and it fails when the signals completely overlap. The second approach is to utilize the carrier frequency difference between overlapped signals. This approach can separate multiple overlapping signals, but large carrier frequency difference is needed. For instance, Galati et al. [
10] proposed a projection algorithm single antenna (PASA). It converts a single antenna signal into a array antenna signal and uses projection algorithm to separate signals. However, the PASA can only separate two signals with a certain relative time delay and over 240 kHz carrier frequency difference correctly. In order to solve the problem of time delay, Shao et al. [
11] proposed an improved PASA. Two signals can be separated as long as their relative time delay is greater than 0.5 μs, but their carrier frequency difference is no less than 300 kHz. Lu et al. [
12] proposed a single-antenna separation method based on empirical mode decomposition (EMD). This method can separate multiple overlapped signals, but the minimum separable carrier frequency difference is 300 kHz and the problem of the mode aliasing needs to be solved. The third approach utilizes other characteristics of ADS-B signal to separate overlapped signals, such as sparse [
13] and pulse position modulation (PPM) [
14] characteristics. In general, traditional single-antenna based ADS-B signal separation methods are limited by the power difference, carrier frequency difference or relative time delay between overlapped signals. When all three parameters are small, it has difficulty in separating the overlapped signals.
In recent years, deep convolutional networks have made breakthroughs in many areas such as hand gesture recognition [
15]. In general, it consists of a convolutional layer, normalized layer, pooling layer and activation function in deep convolutional networks. Moreover, the different sizes of convolutional kernels are used to extract local spatial information. The commonly used framework of deep convolutional networks is ResNet [
16] and DenseNet [
17]. This paper applies the deep convolutional networks to ADS-B signal separation. By learning the feature relationship between the overlapping and separated signals, the ADS-B overlapped signals are better separated. The single antenna ADS-B signal separation problem is similar to the speech separation problem. In speech separation based on deep learning methods, the framework including the encoder, separation and decoder is commonly used. The separation model can be divided into three approaches depending on the network types. The first approach [
18,
19,
20] uses 1D convolution network with different size kernels to extract separation mask. However, the long temporal information cannot be effectively exploited. The second approach [
21] uses the Recurrent Neural Network (RNN) to capture temporal features. However, the sequence is too long, and the RNN cannot be used to process the signal sequence directly. Generally, the long sequence is divided into many segments and generate the matrix. Therefore, spatial information in matrix is ignored and it has high complexity using two RNNs. The third approach [
22] utilizes the transformer framework to extract mask features. However, it has higher complexity. Compared with RNN and the transformer-based framework, Conv-TasNet has low computational complexity. Thus, we improve the Conv-TasNet for ADS-B signal separation in this paper.
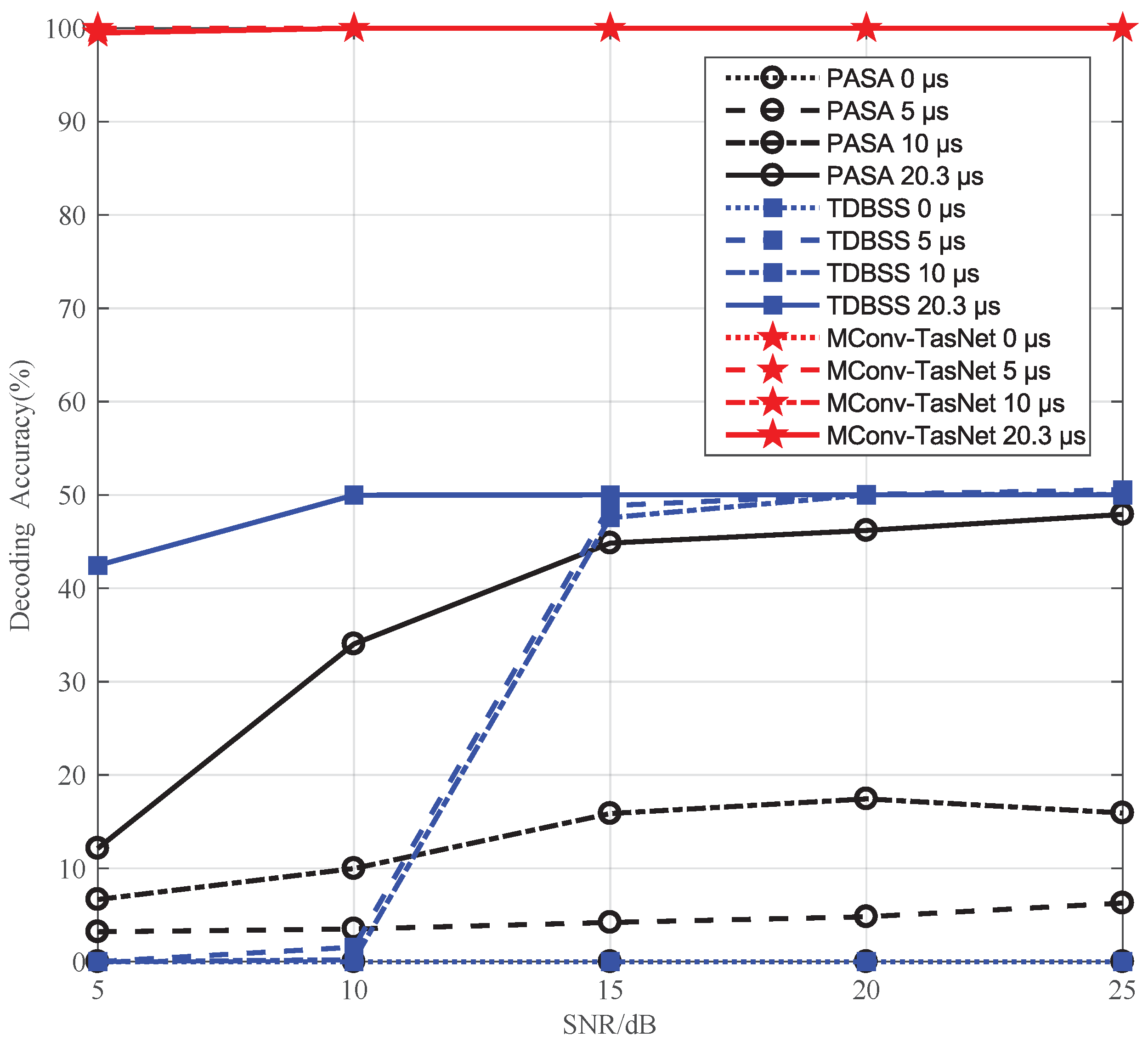
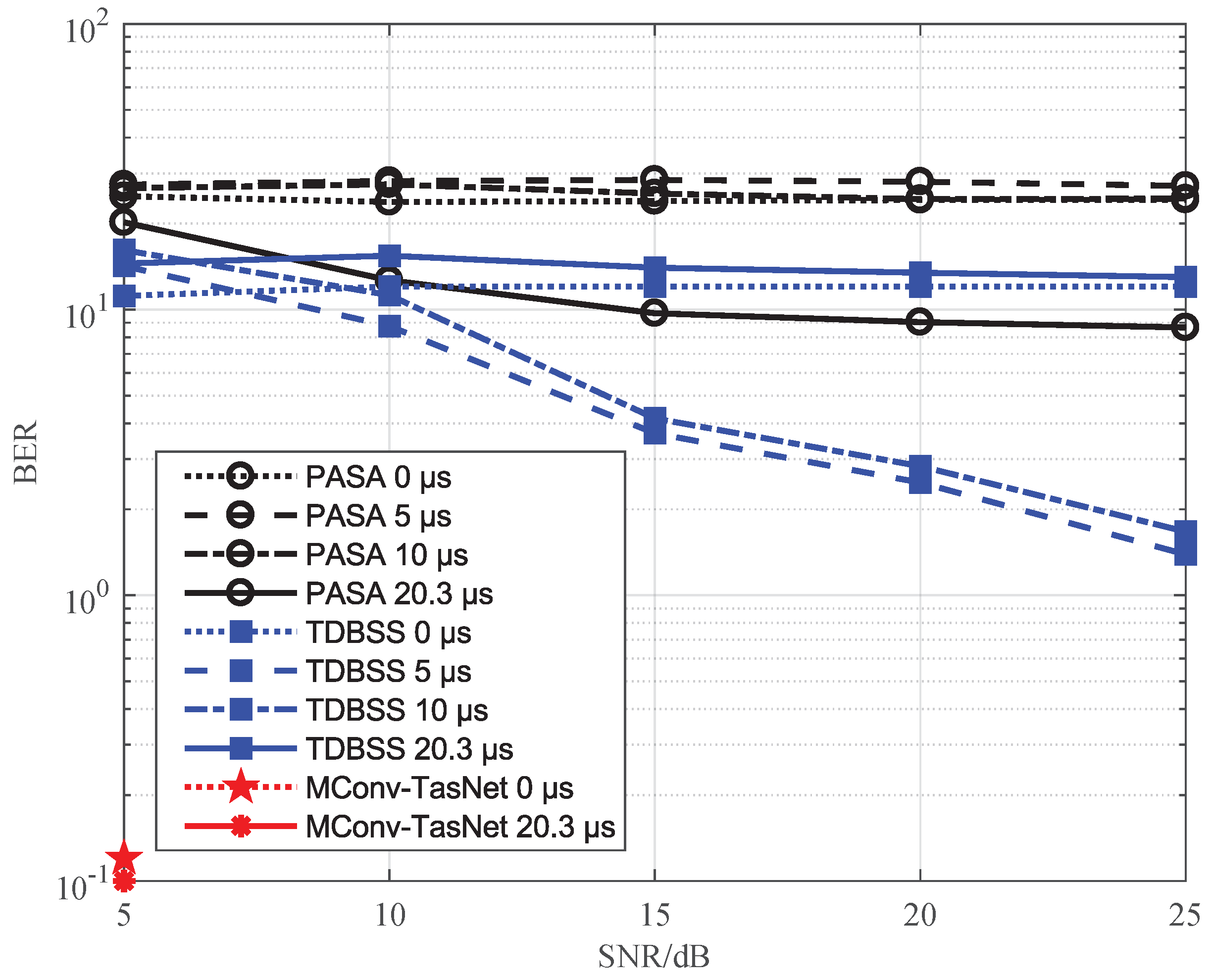
ADS-B signal separation based on deep learning is rarely focused due to lacking actual dataset. In order to solve this problem, a large semi-real ADS-B dataset (SR-ADSB) with two signals overlapping is created. The real ADS-B messages collected around Tianjin Airport are used to form overlapped signals by combining different signal parameters such as SNR, carrier frequency and relative time delay. Moreover, a multi-scale convolutional separation network is proposed to solve the problem that the Conv-TasNet cannot effectively capture long temporal information. In the separation network, the multi-scale temporal information is extracted by using the convolutional layer with different convolutional strides, and the deconvolution is used to restore the multi-scale under- sampled signal. Finally, the different temporal scale features are fused to generate the separation mask. The proposed method is verified on the SR-ADSB dataset and the average decoding accuracy on the test set is 90.34% and the BER is 0.27%.
2. Single Antenna ADS-B Signal Model
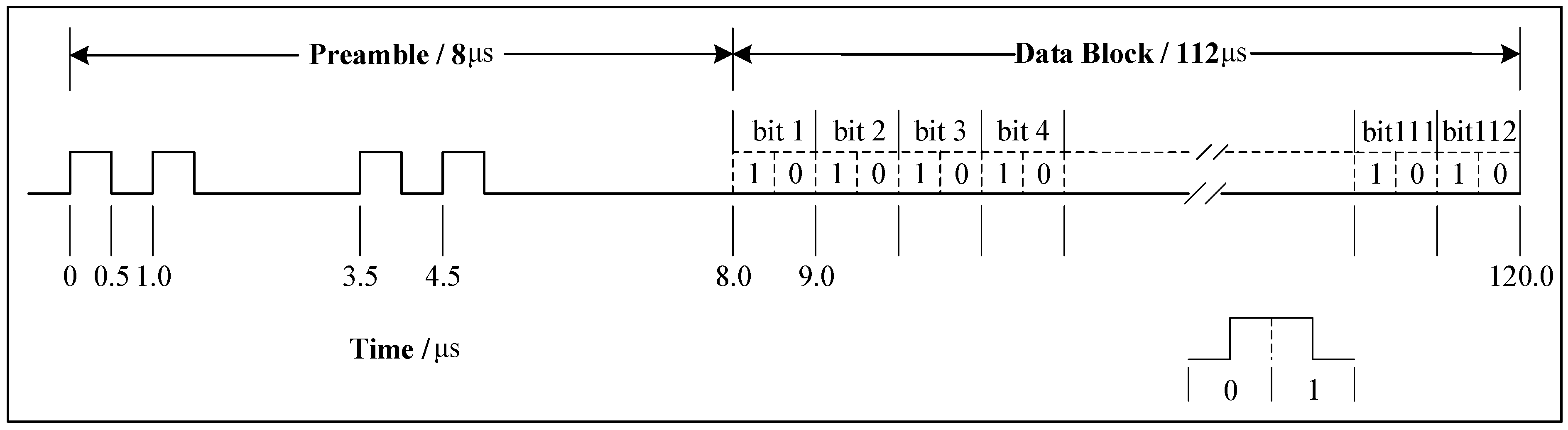
The ADS-B 1090 MHz Extended Squitter (1090ES) baseband signal is composed of an 8 bit fixed preamble and 112 bit data block, with a duration of 120 μs. The 8 bit preamble contains four fixed position pulses at 0, 1, 3.5 and 4.5 μs, respectively, while the remaining 112 bit data block vary with the content of the message. ADS-B signal is modulated by PPM technique, and each bit data is composed of two pulses with a duration of 0.5 μs. When the previous pulse is 0 and the next pulse is 1, it represents 0, and 1 otherwise. Therefore, every ADS-B signal has 240 pulses. The structure of an ADS-B baseband signal is shown in
Figure 1.
ADS-B baseband signal
at initial time (0 μs) is expressed as
where
k is number of ADS-B signal pulse,
.
is the value of the
kth impulse and can be 0 or 1.
is the unit pulse width of ADS-B baseband signals,
= 0.5 μs.
is unit rectangular pulse with the
pulse width at −0.5 μs starting position.
The ADS-B baseband signal is modulated to the carrier frequency using the Amplitude Shift Keying (ASK) modulation. ICAO allows the carrier frequency of ADS-B 1090ES signal to be (1090 ± 1) MHz. Therefore, the modulated ADS-B signal in the time-domain can be expressed as
where
A is the signal amplitude.
is the baseband signal and
f is the carrier frequency.
In the case of single antenna, an ADS-B overlapping signal is linearly superimposed by
d independent signals, and the ADS-B overlapped signal can be expressed as:
The Formula (
2) can be further obtained by substituting Formula (
3):
where
is single antenna ADS-B overlapped signal.
d is the number of overlapping signals.
,
,
, and
are the amplitude, baseband signal, time of arrival, and carrier frequency of
ith signal, respectively.
is the received Gaussian white noise.
3. Proposed Method
Compared with speech signal, it has higher sampling rate for ADS-B signal. However, the length of ADS-B signal is short and fixed 120 μs. It has similar sampling points with a currently used speech dataset. Thus, we improve the Conv-TasNet [
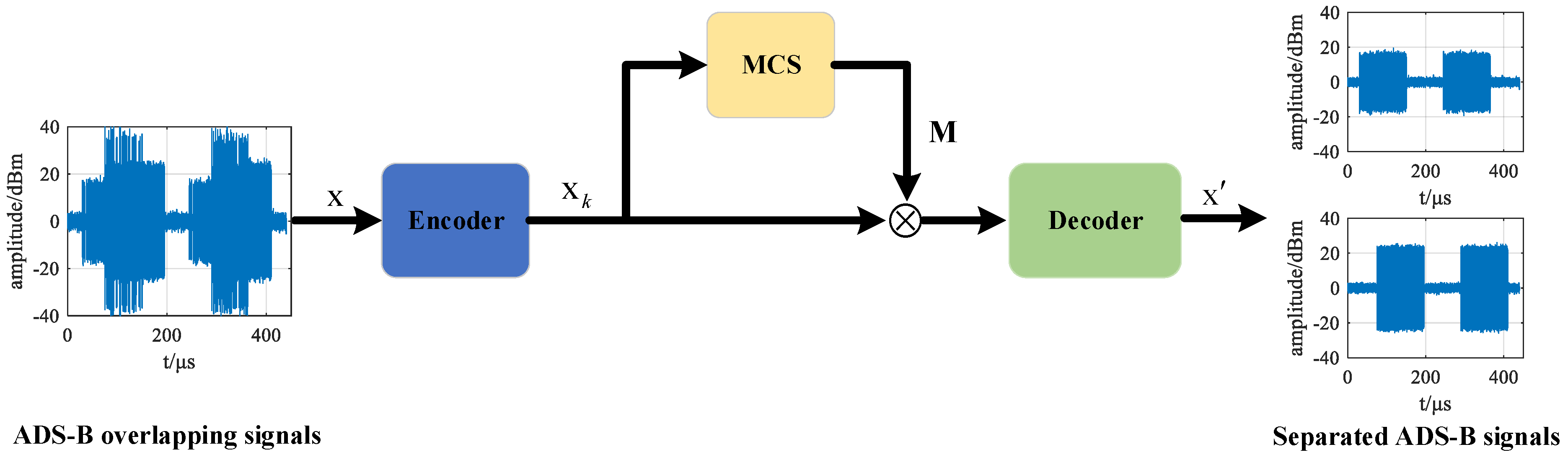
18] framework used in the speech signal separation to construct a multi-scale Conv-TasNet (MConv-TasNet), as shown in
Figure 2. From the
Figure 2, it can be observed that the framework consists of three models. The encoder model is to extract the features from the ADS-B signal and the MCS network is to estimate the separation masks. The decoder is to separate the overlapped signals. In the following, the description of the model is detailed.
3.1. Encoder-Decoder
We follow the Conv-TasNet [
18] to build the encoder and decoder model. For the encoder, a 1-D convolution operation with kernel size
K is used to extract the features. Moreover, the convolutional stride is
to reduce the length of ADS-B signal, which can reduce the computational complexity. The output of 1-D convolution is fed into the rectified linear unit (ReLU). The ADS-B signal
is encoded into feature
by the encoder model.
C is the number of convolutional kernel.
The decoder model is a reverse process of the encoder model and utilizes the 1-D transposed convolution operation to generate the separated ADS-B signals. The feature
is fed into MCS network to extract the separation masks
.
d is the number of separation signals. The element-wise multiplication between feature
and mask
is used to get the input of decoder. The whole process can be expressed:
where
is
ith separated signal and
is activate function.
3.2. Multi-Scale Convolutional Separation Network
From the Formula (
5), it can be observed that
greatly affects the separation accuracy. It is significant to generate effective masks by using discriminative temporal information in the separation model. In order to capture long temporal information, the temporal convolutional network (TCN) including 1-D convolutional blocks with increasing dilation is used in Conv-TasNet. However, the signals is so long and the dilation factors can not adequately exploit the long temporal information.
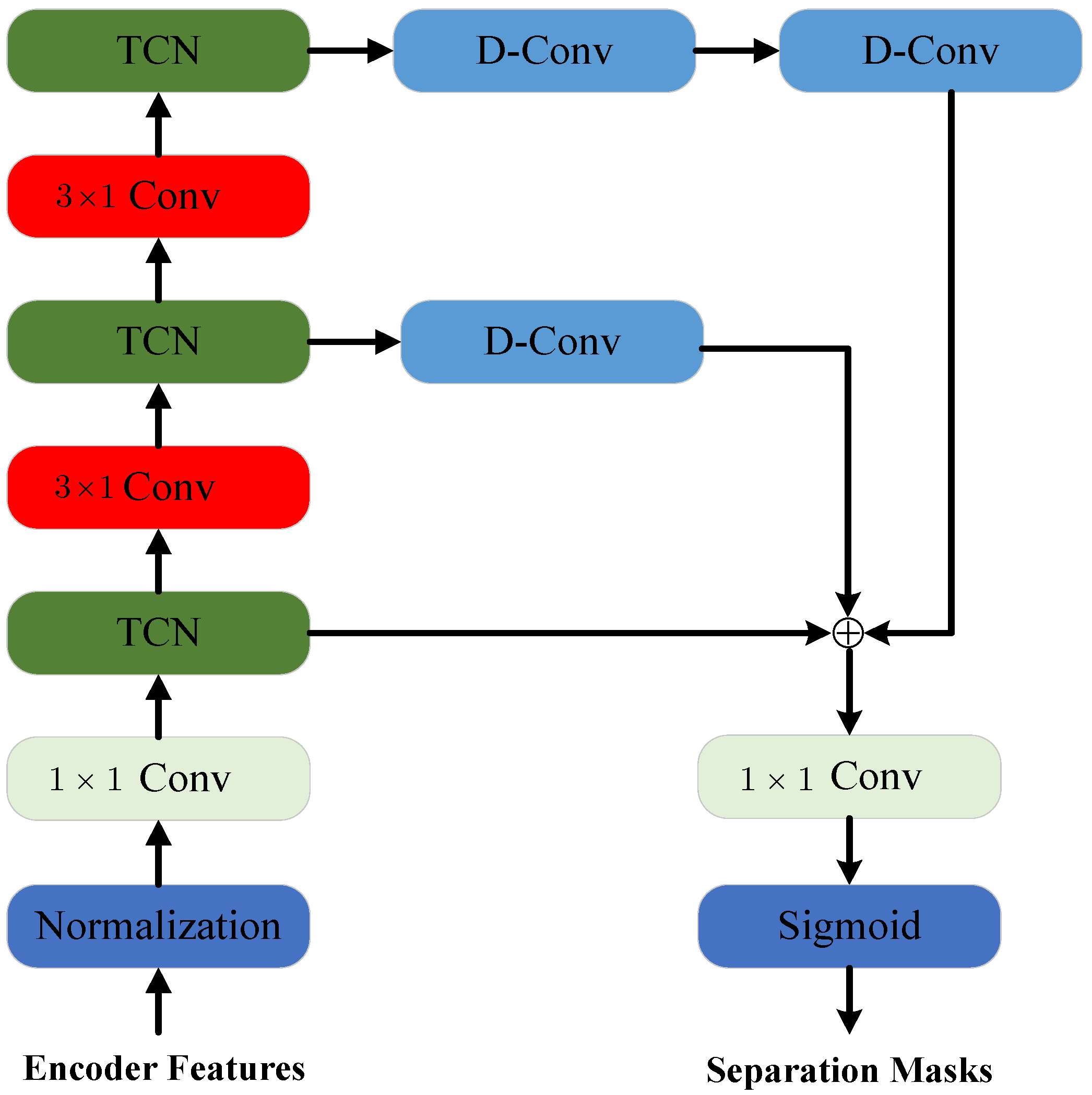
In order to solve this issue, MCS network is designed as shown in
Figure 3. The MCS network consists of four convolutional layers, three TCN model and three deconvolution layers. The output of encoder model is the input of the MCS network. First, the convolutional layers with
kernel size is used to further extract features. Then, the TCN is utilized to capture long temporal information. The
convolution with stride 2 is used to compress the length of ADS-B signal. The more long temporal information is captured by this temporal compression. After the compression, the temporal information of the next scale is exploited using the TCN. In order to keep the same size of multi-scale features, the 1-D transposed convolution is utilized in the second and third TCN. Moreover, the multi-scale temporal information is fused to generate the separation masks using the
convolution. Compared with Conv-TasNet, our proposed MCS network can capture more temporal information and reduce the computational complexity.
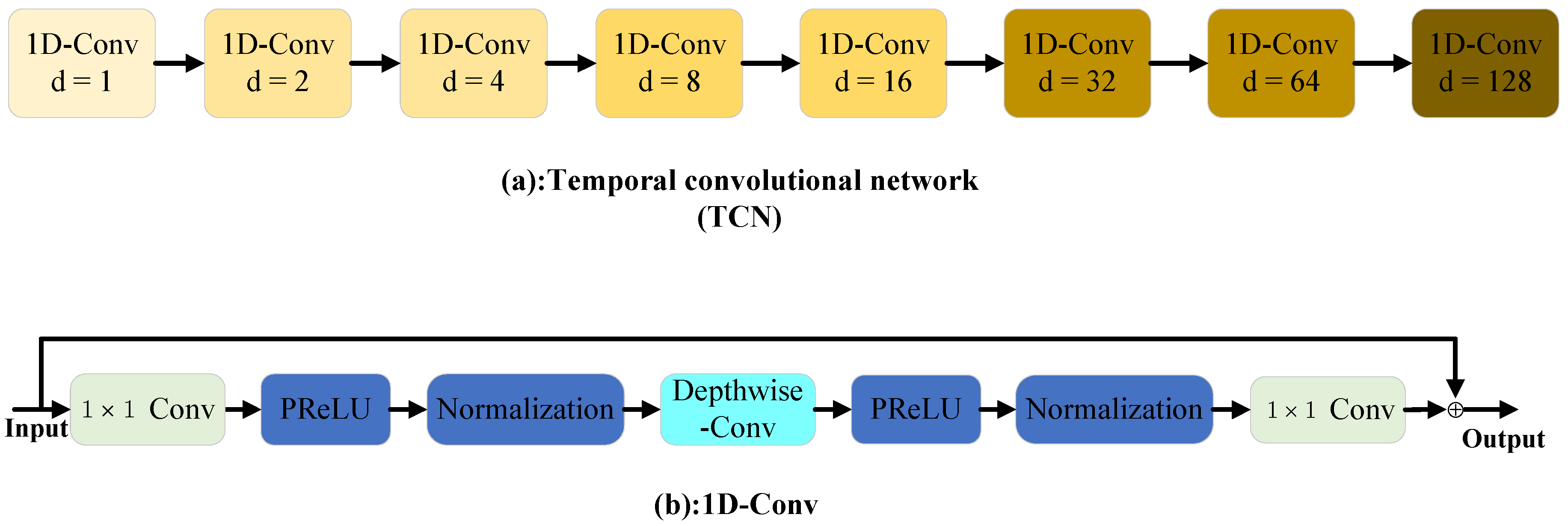
In TCN, eight 1-D convolutional blocks are used as shown in
Figure 4a. Moreover, each block uses the different dilation factors to capture the relationship between different time-stamps. Each block consists of three convolution layer and uses residual structure as shown in
Figure 4b. First, the
convolution followed by nonlinear activation function and normalization is used to improve feature dimensions. Then depth-wise convolution is used to decrease the number of parameters. Finally, the feature dimensions is changed to the same dimension of input using the
convolution. The dilation factors are used in the depth-wise convolution.
3.3. ADS-B Signal Dataset
Currently, it is difficult to obtain a large number of ADS-B overlapped signals in practice. Thus, we created a semi-real ADS-B dataset (SR-ADSB) with two signals overlapping in this paper. Firstly, the ADS-B data of Tianjin Airport from 21 April to 21 May 2021 were collected. The abnormal data and duplicate information of the longitude, latitude and altitude were removed. A total of 171,850 ADS-B messages of 2315 aircraft were obtained. Among them, 600 ADS-B messages with different aircraft number (AA), longitude, latitude and altitude were randomly selected as the initial samples.
The overlapping signals parameters of the dataset are set according to the single antenna ADS-B overlapped signal model in
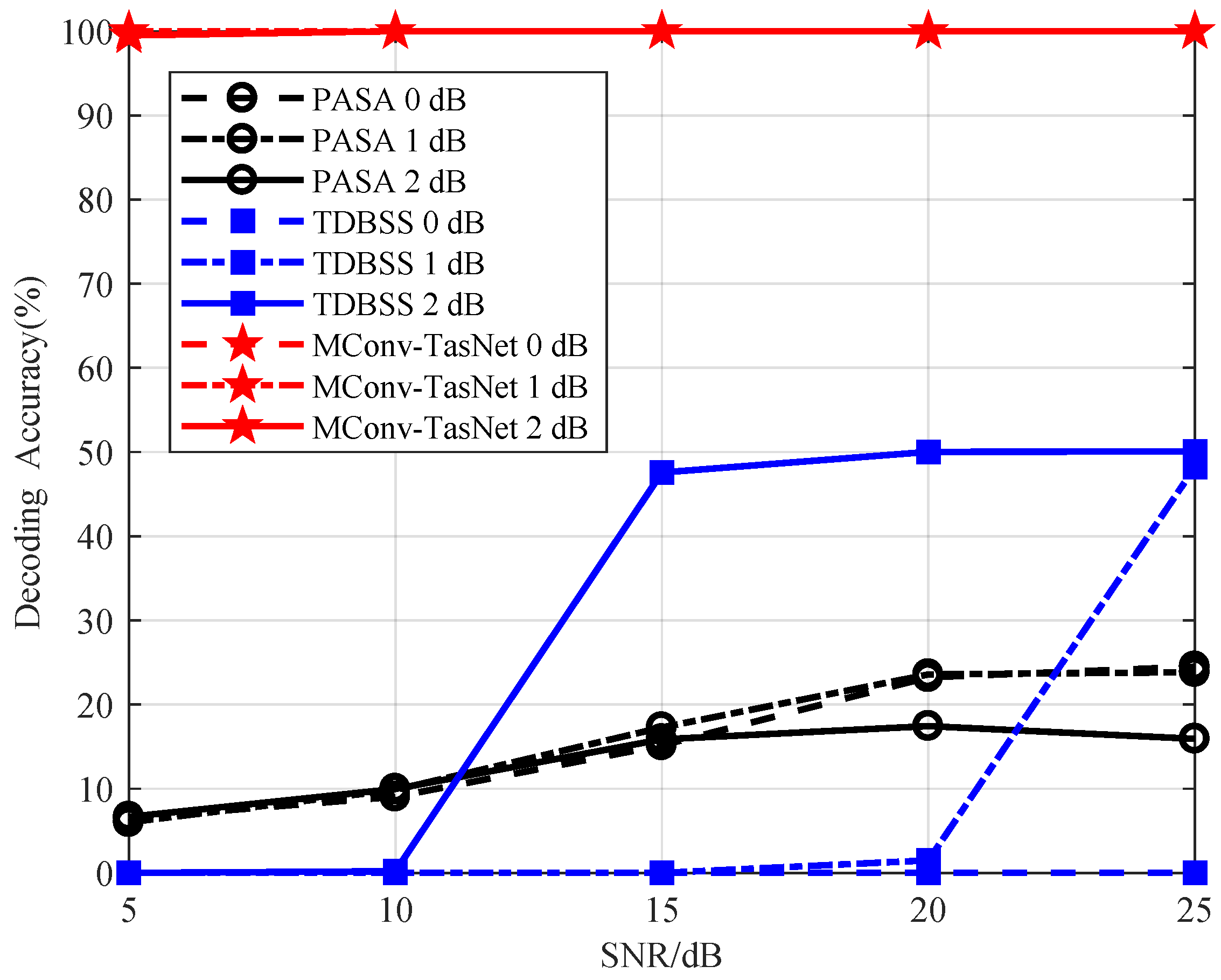
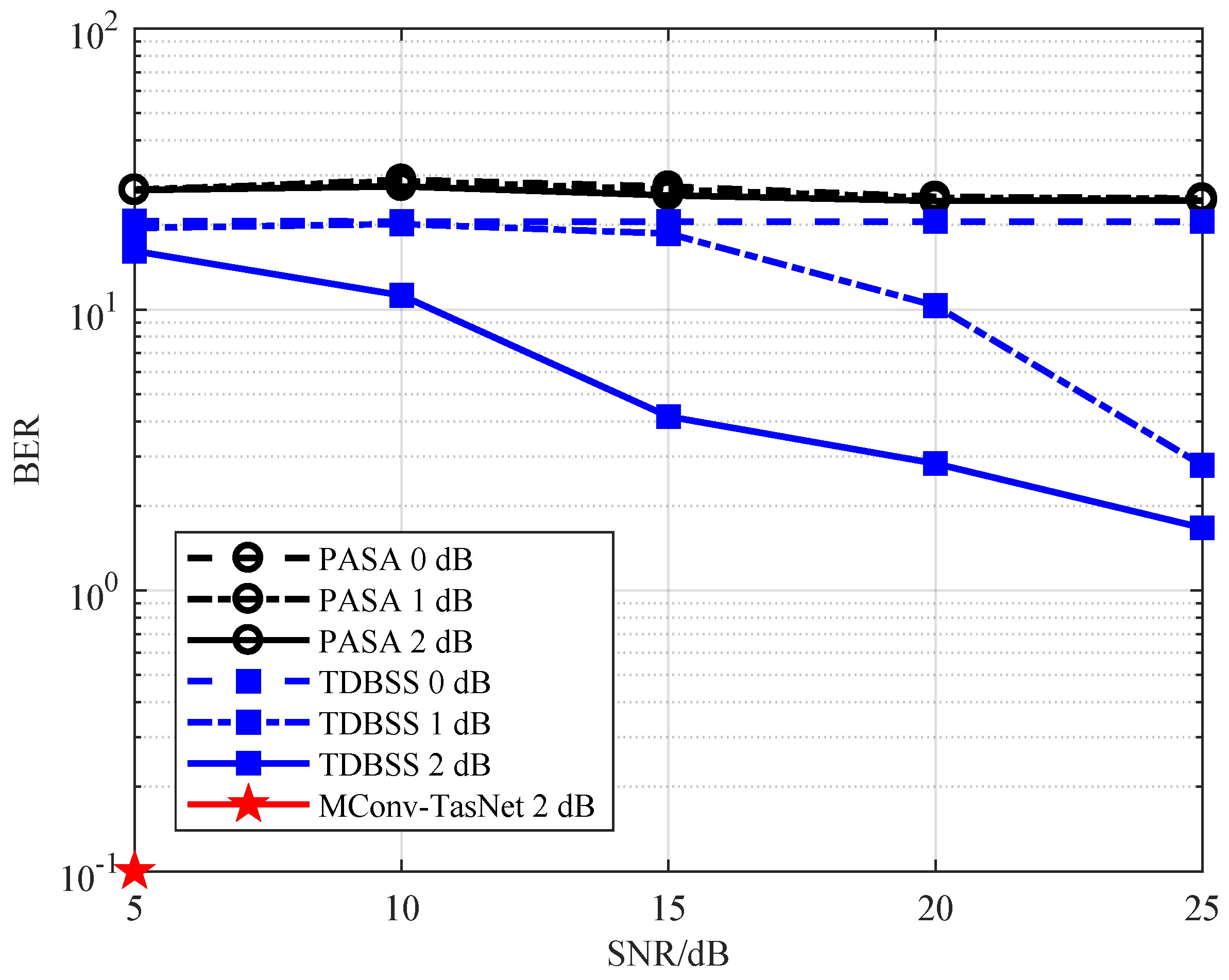
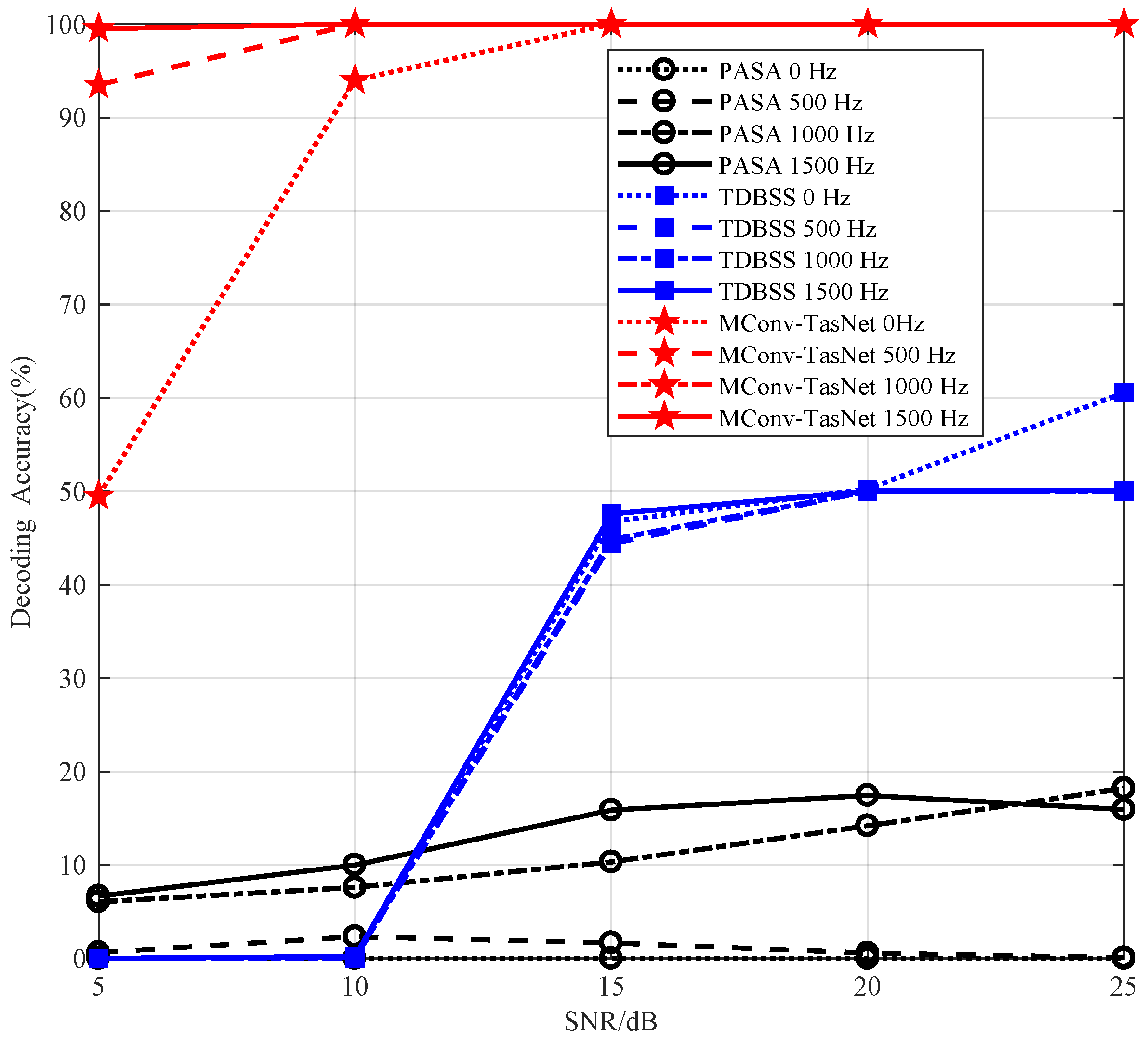
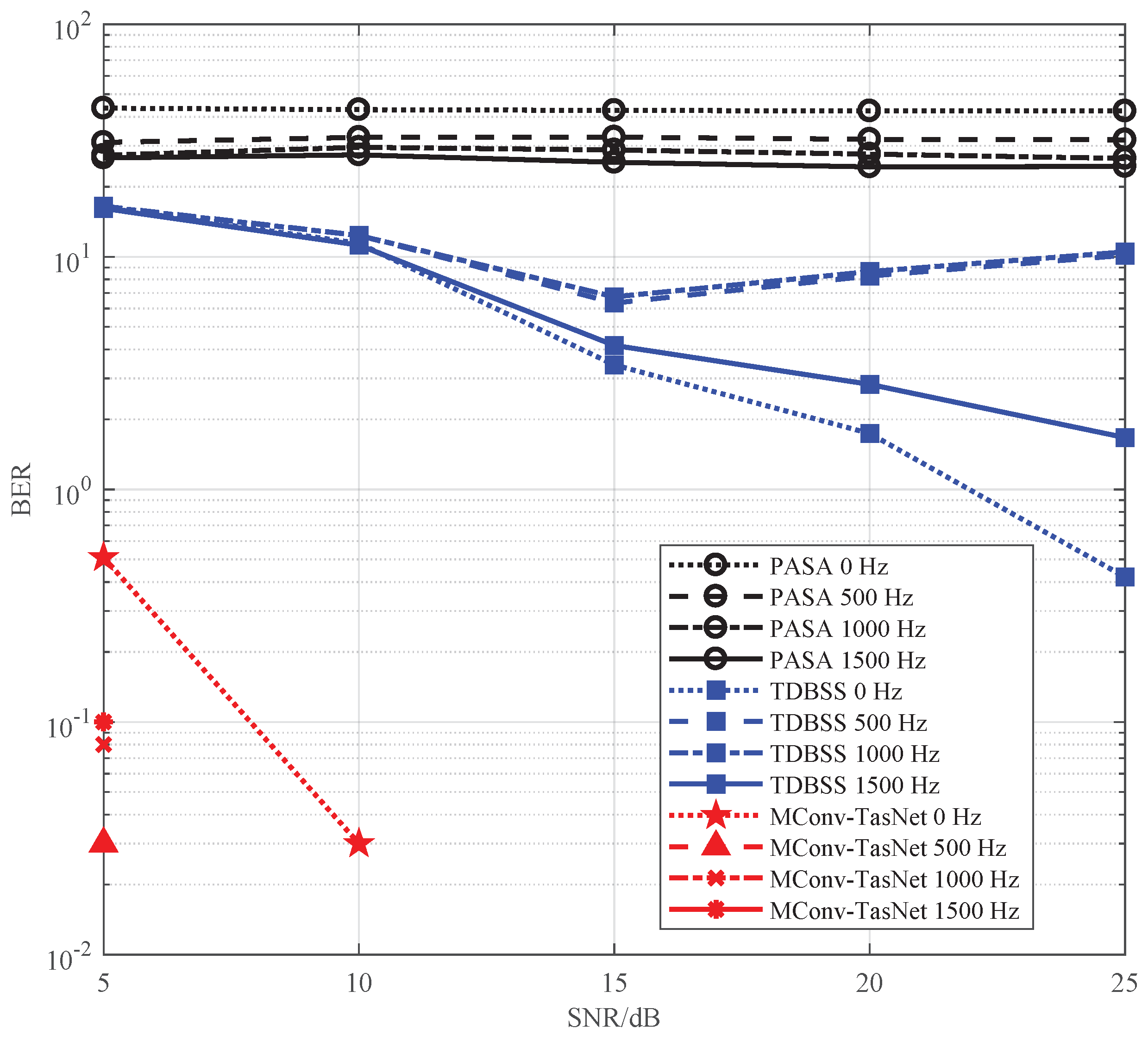
Section 2. The range of SNR is 5–25 dB, and the interval step is 5 dB. The power difference between the signals is set to 0 dB, 1 dB and 2 dB. The carrier frequency of the signals is set as the intermediate frequency 9–11 MHz, the interval step is 0.5 MHz, and the carrier frequency difference between signals is set as 0 Hz, 500 Hz, 1000 Hz, and 1500 Hz. For the relative time delay between signals, 0 μs, 5 μs, 10 μs, 20.3 μs are used. It can generate 1200 kinds of overlapping signals with different SNR, carrier frequency, relative delay for a pair-wise signal. From the initial sample, 400 ADS-B signals are selected and two signals are used as a group. Hence, 240,000 samples were obtained as the training data for the SR-ADSB. The remaining 200 ADS-B signals are used to generate 120,000 test samples.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}