
Benchmarking Deep Learning Models for Instance Segmentation



Abstract
:1. Introduction
2. Related Work
3. Background
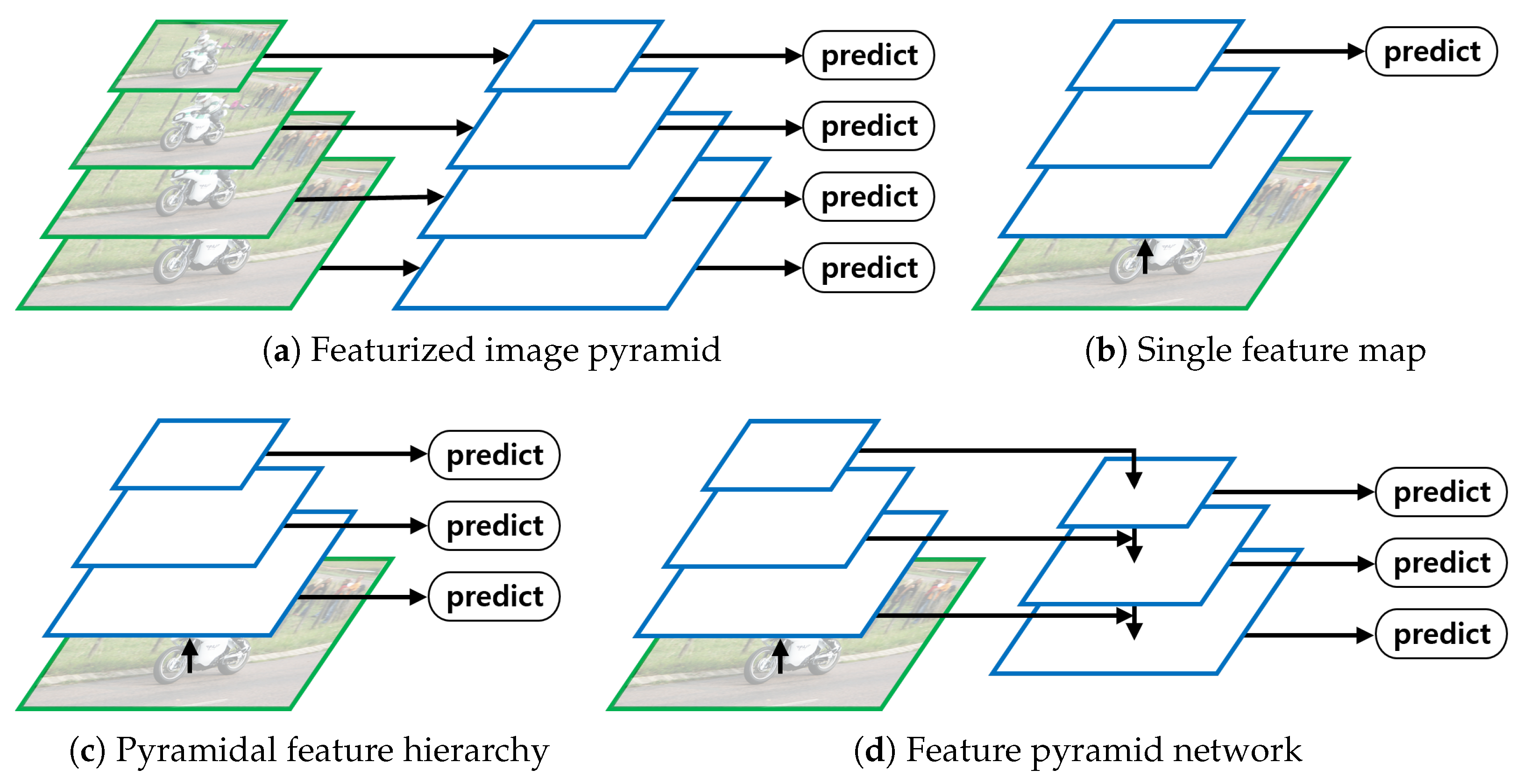
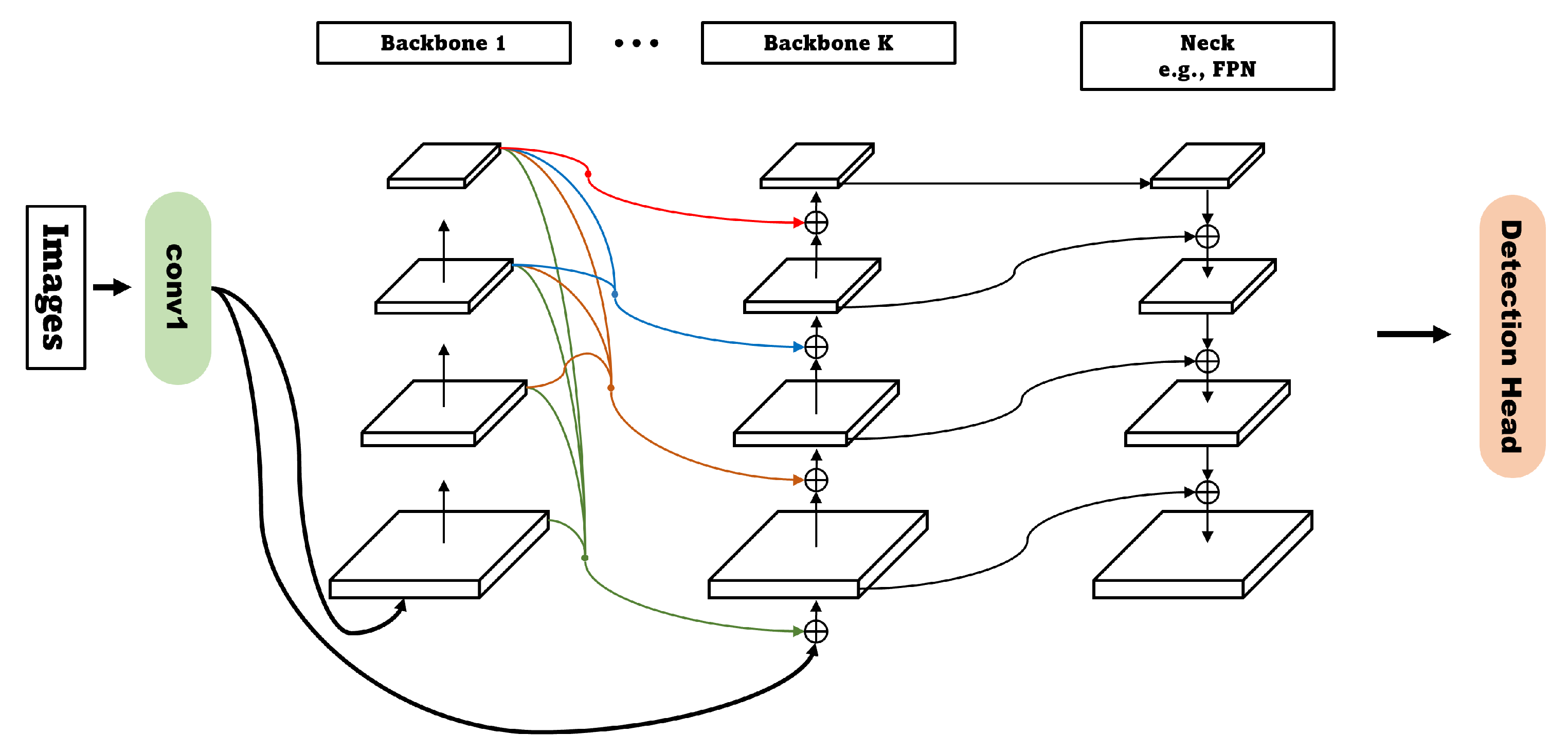
3.1. Feature Pyramid Network (FPN)
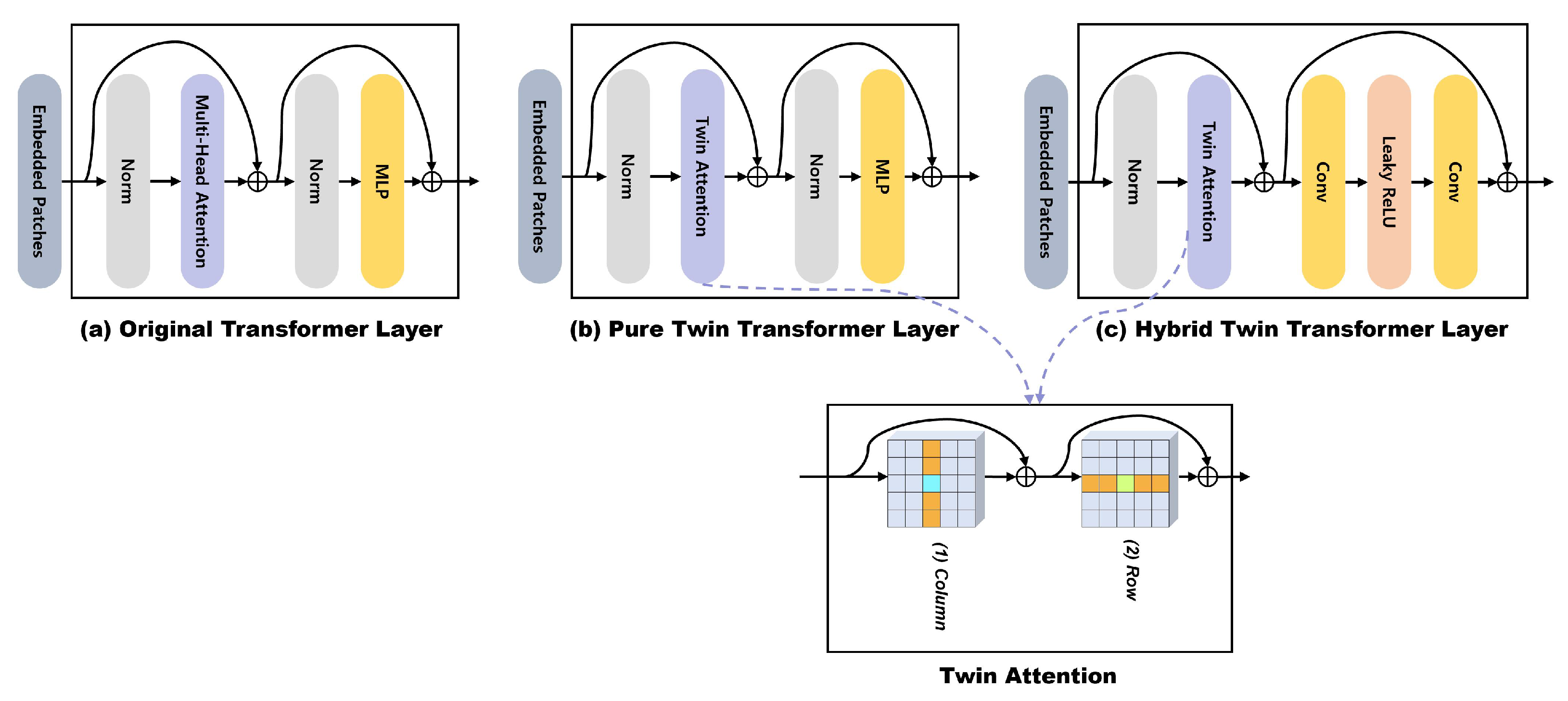
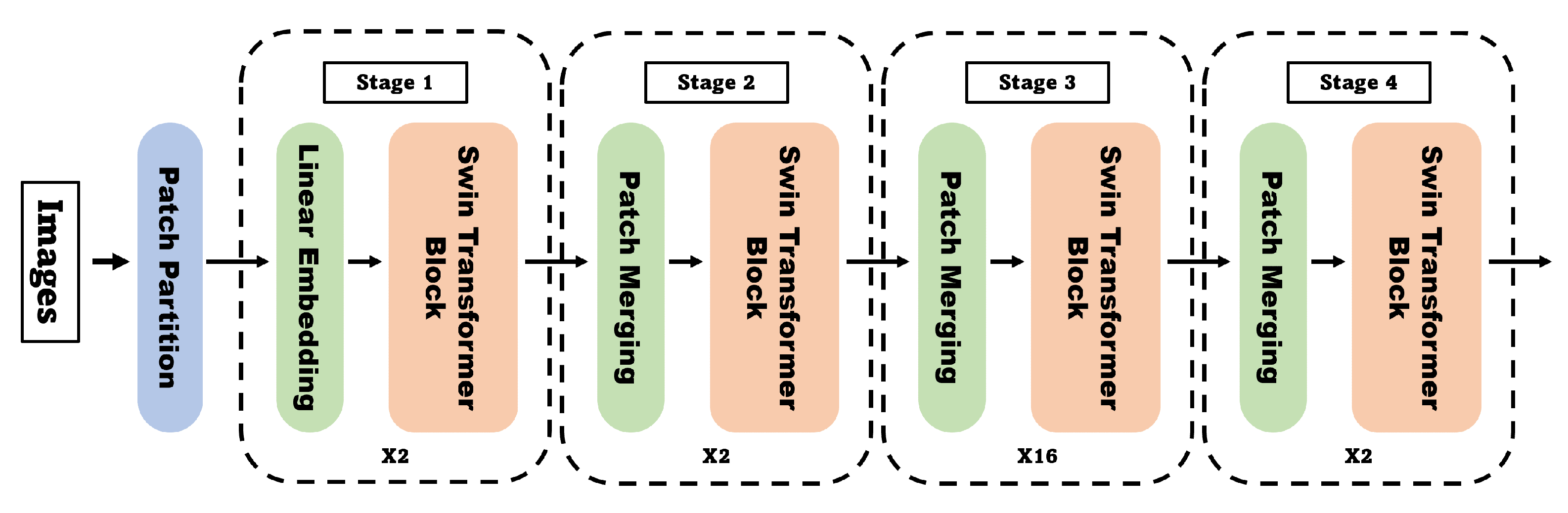
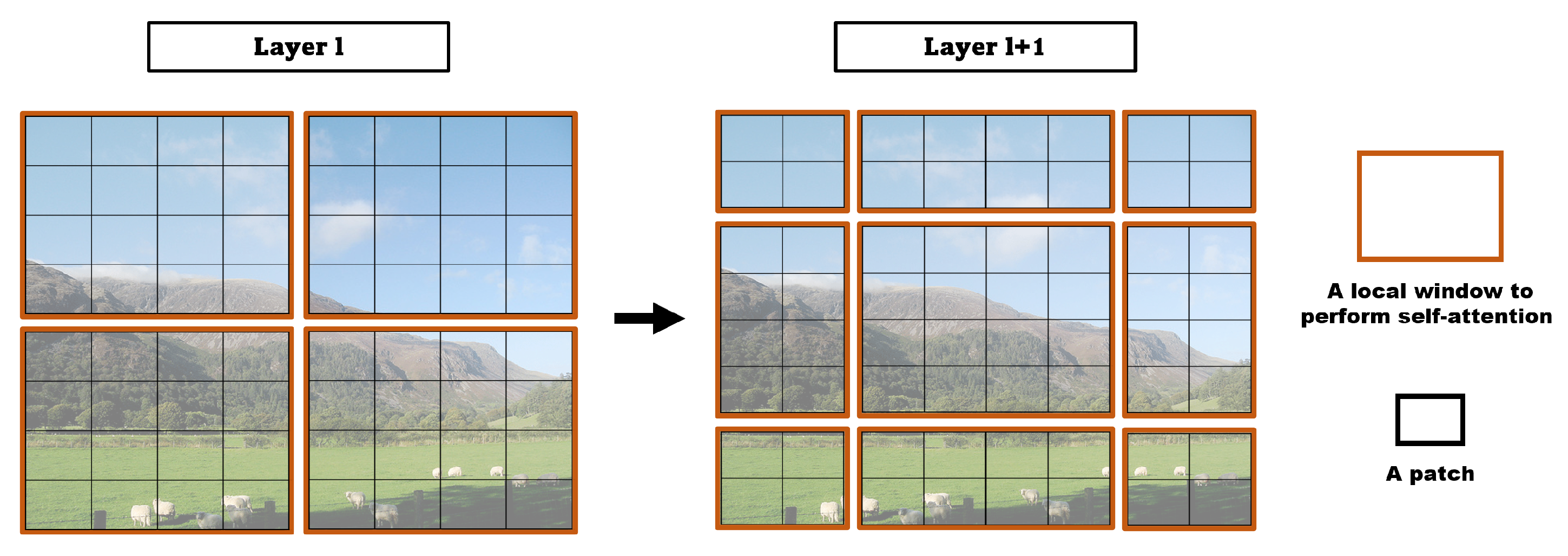
3.2. Vision Transformer
3.3. Non-Maximum Suppression (NMS)
3.4. NVIDIA TensorRT
3.5. Quantization
4. Review Method
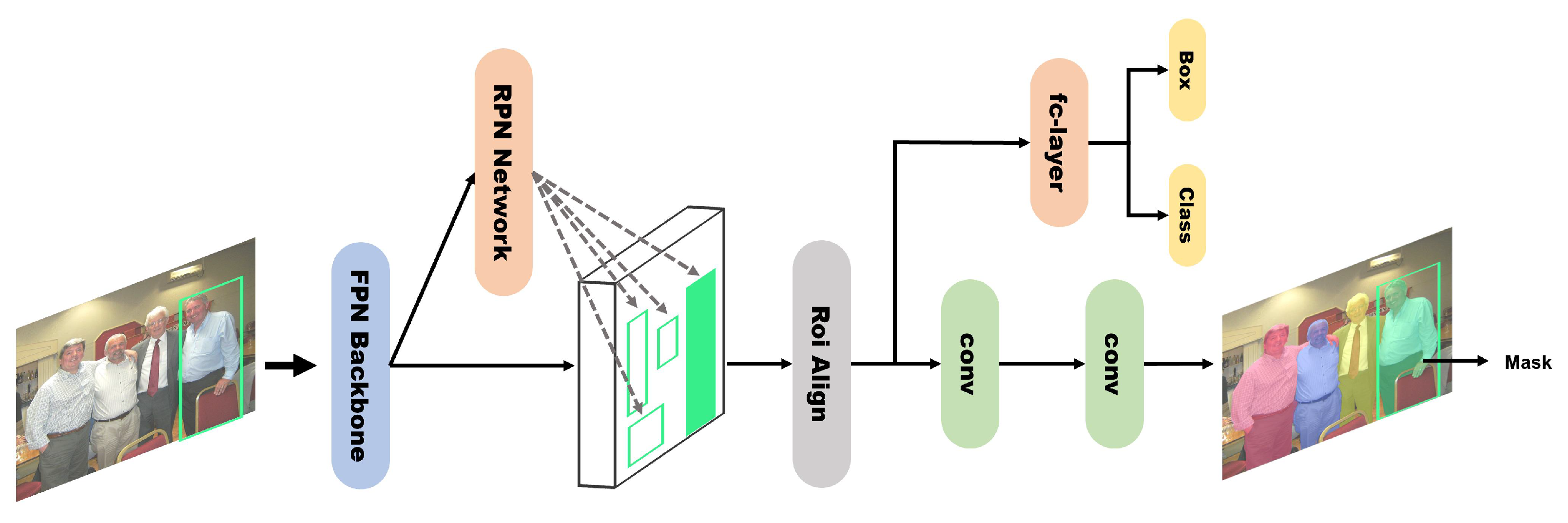
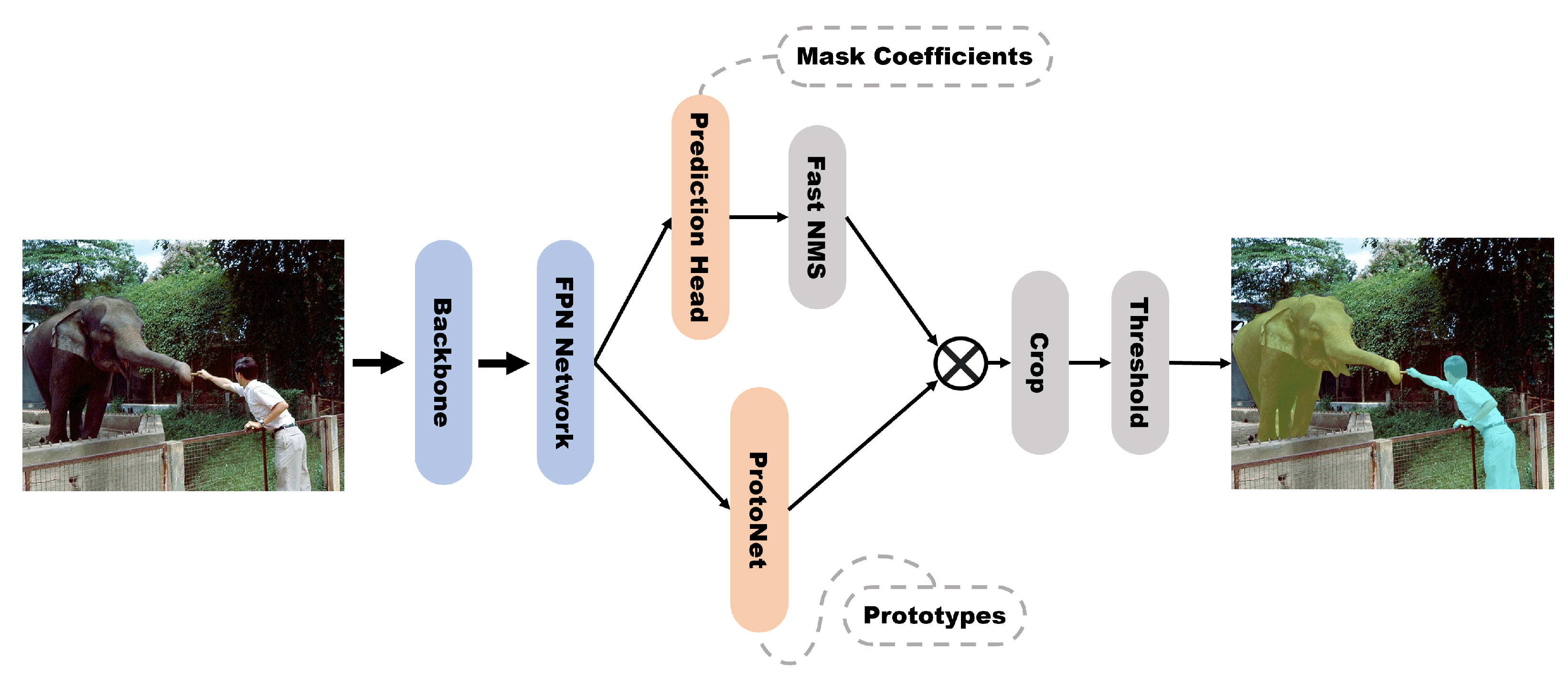
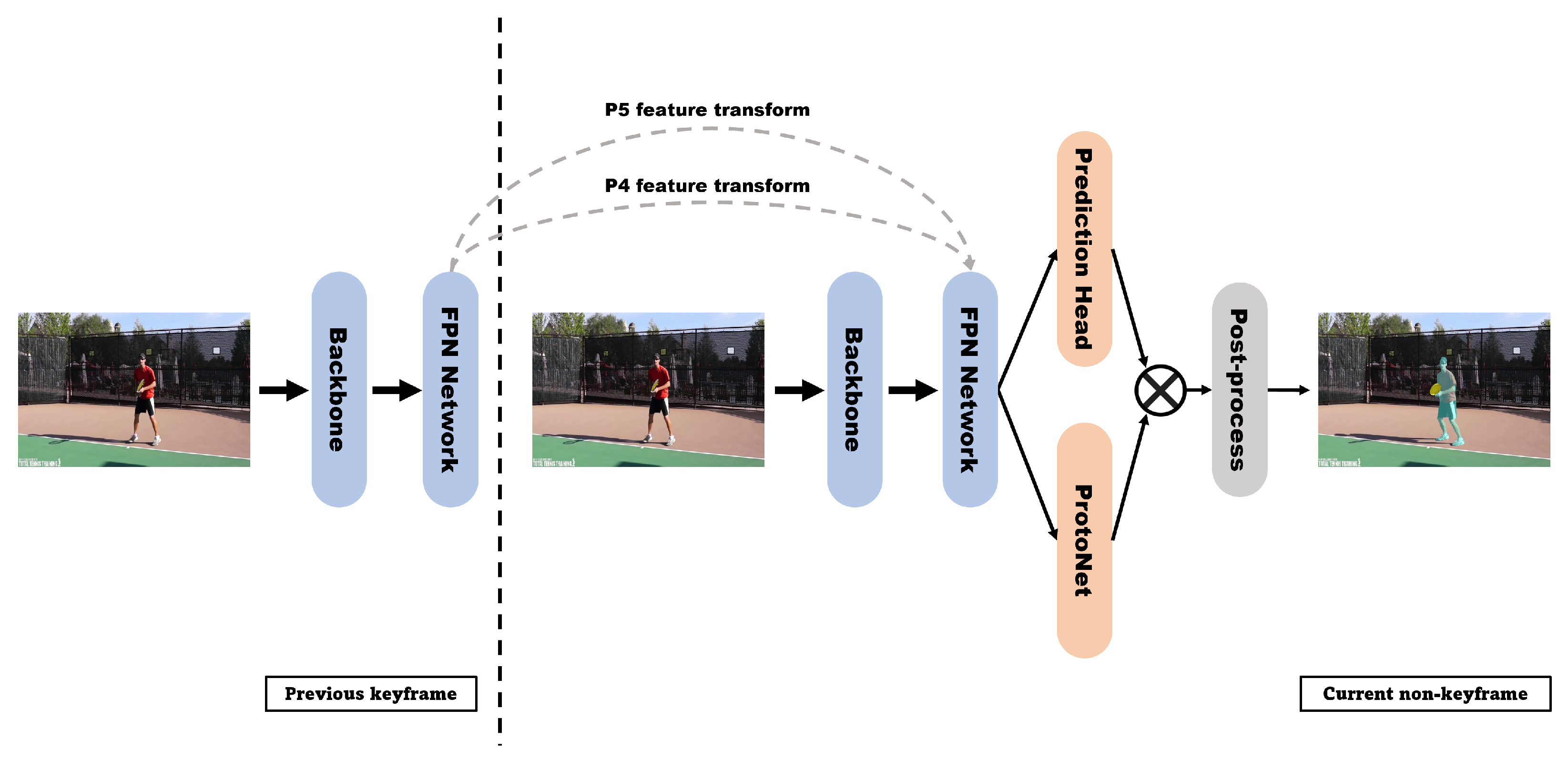
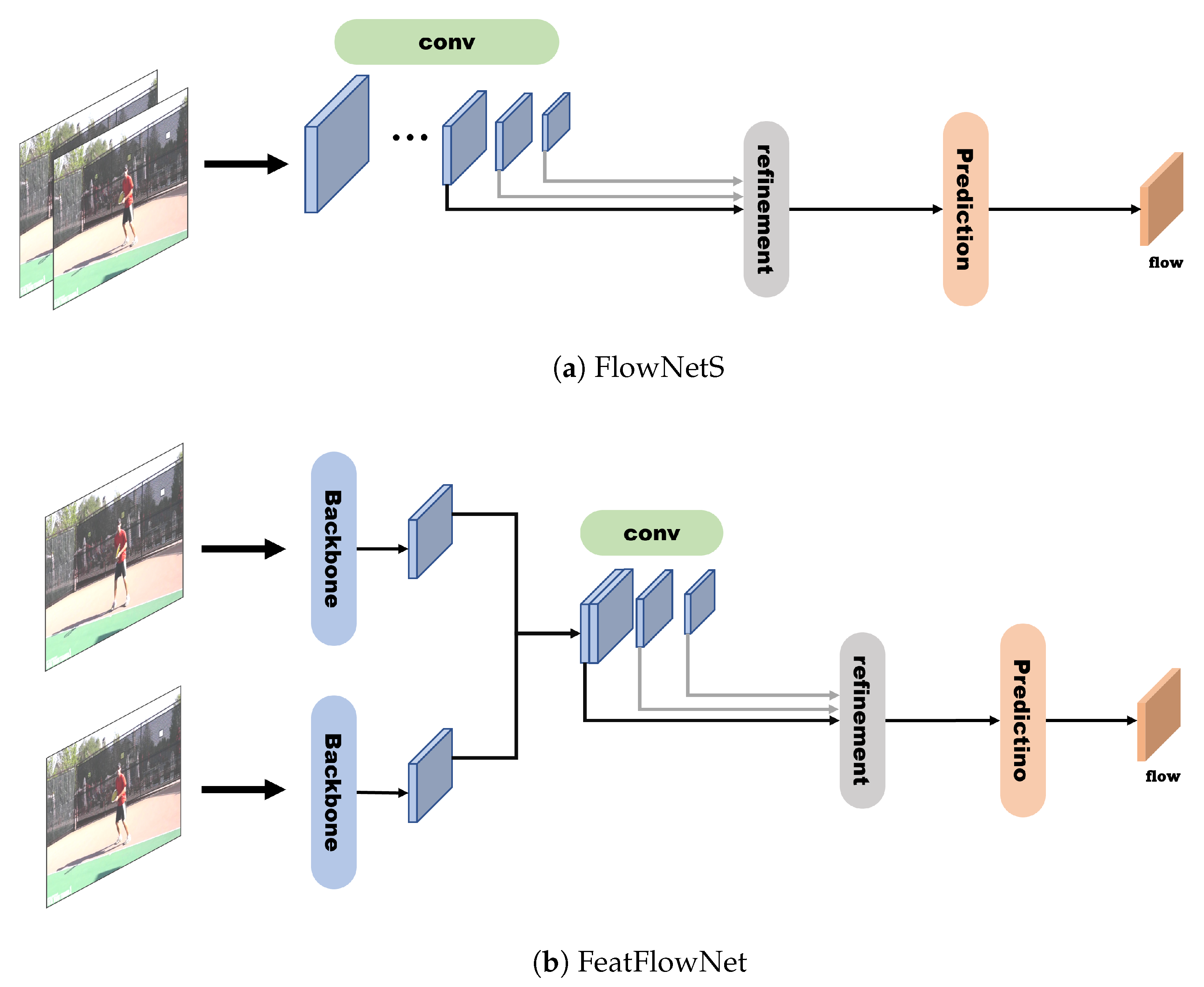
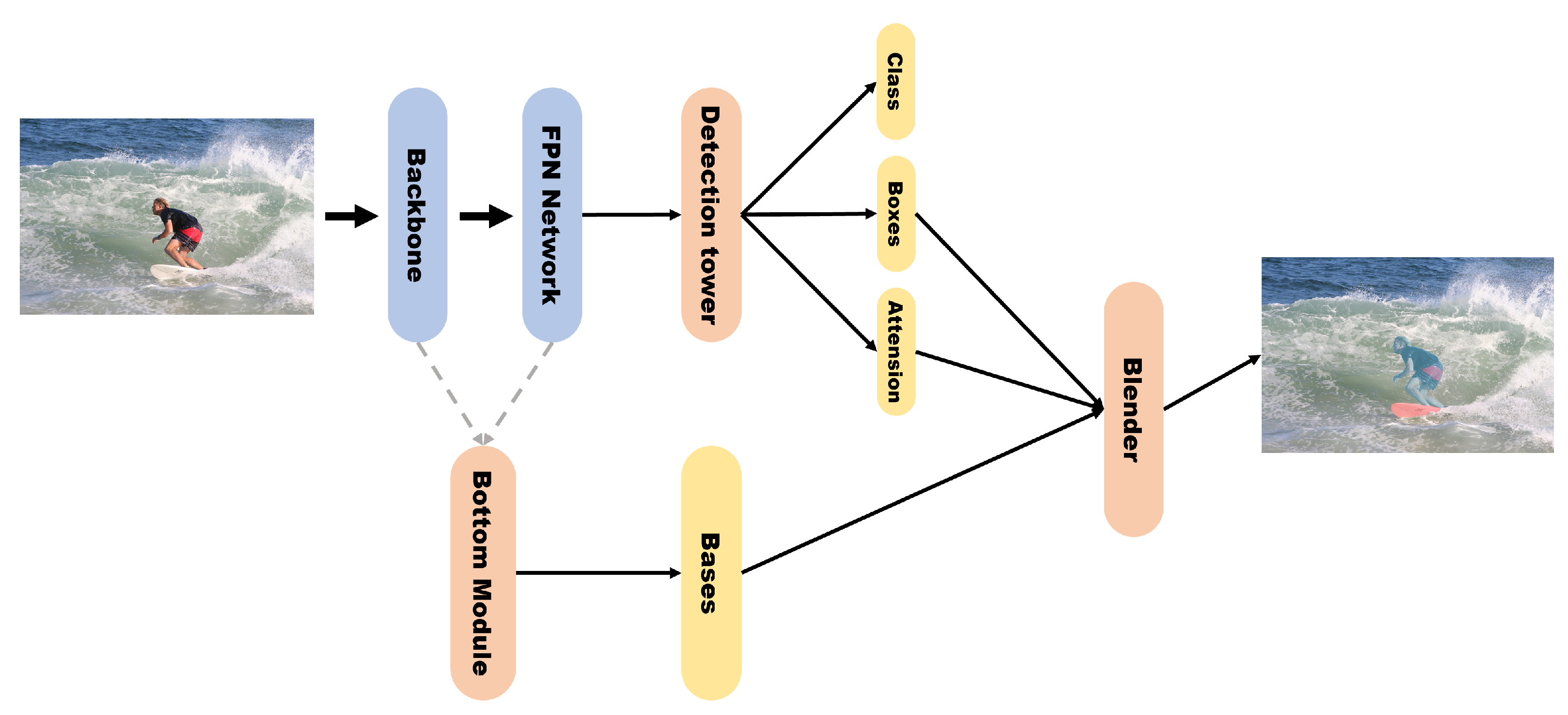
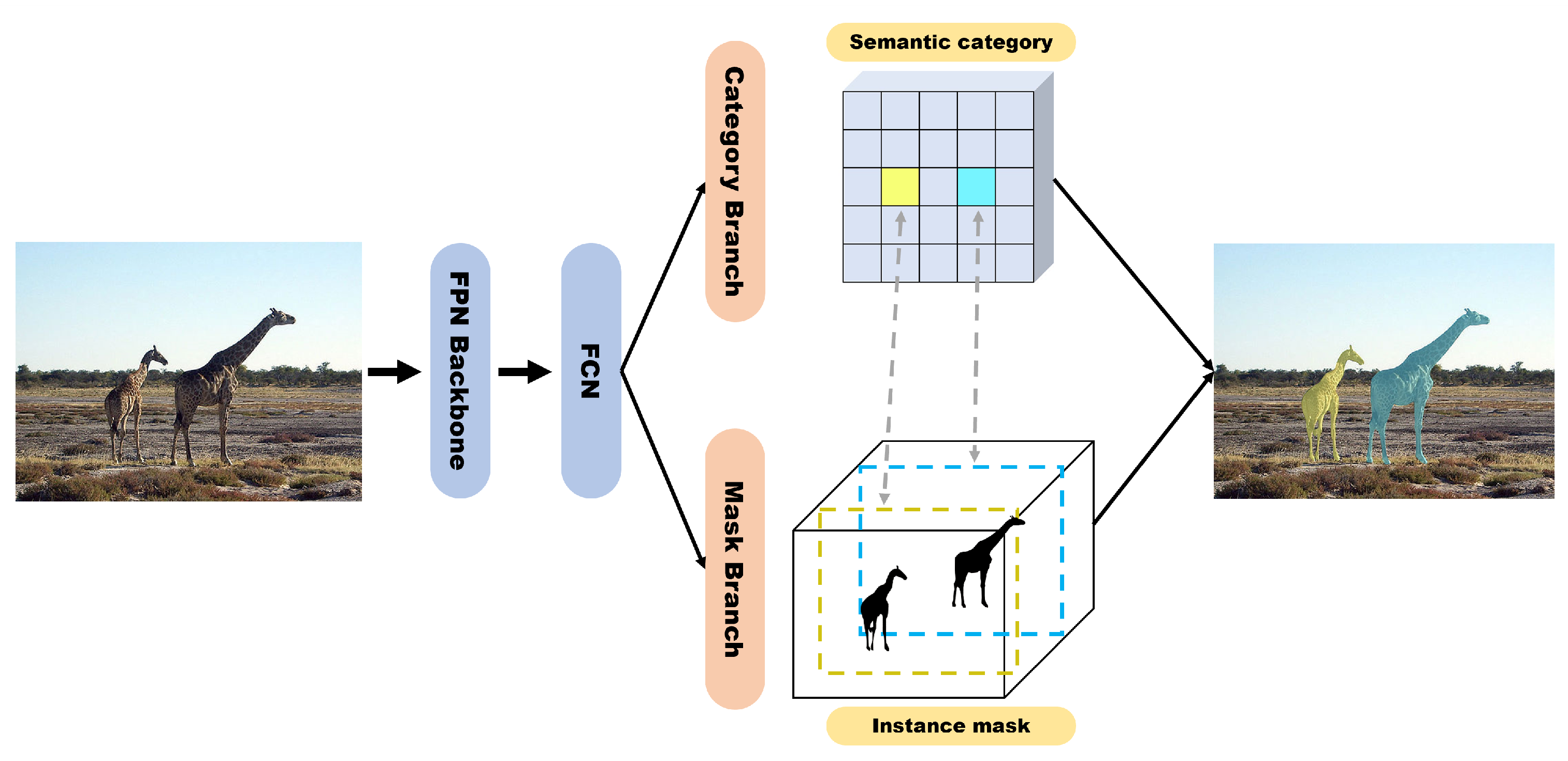
4.1. Accuracy-Focused Models
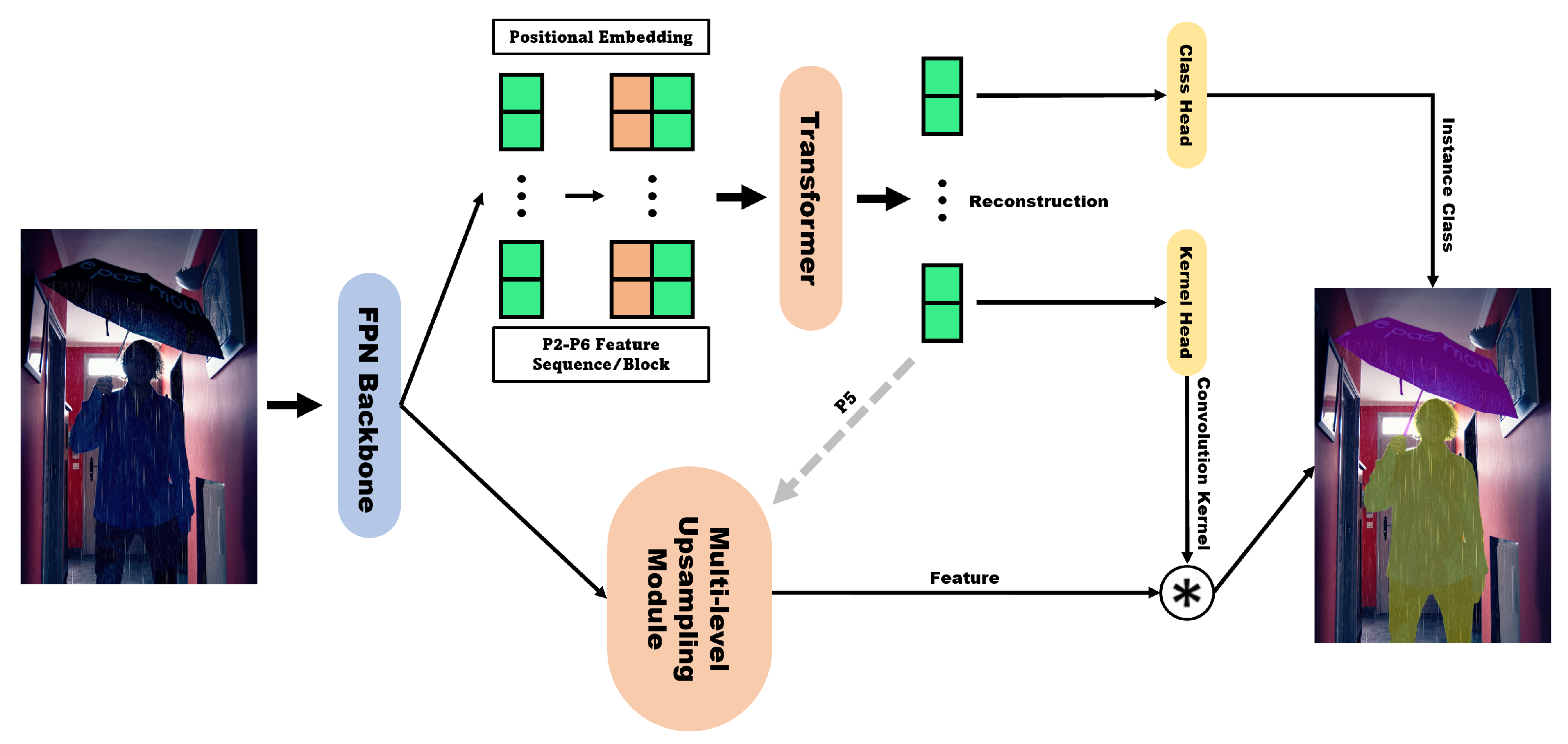
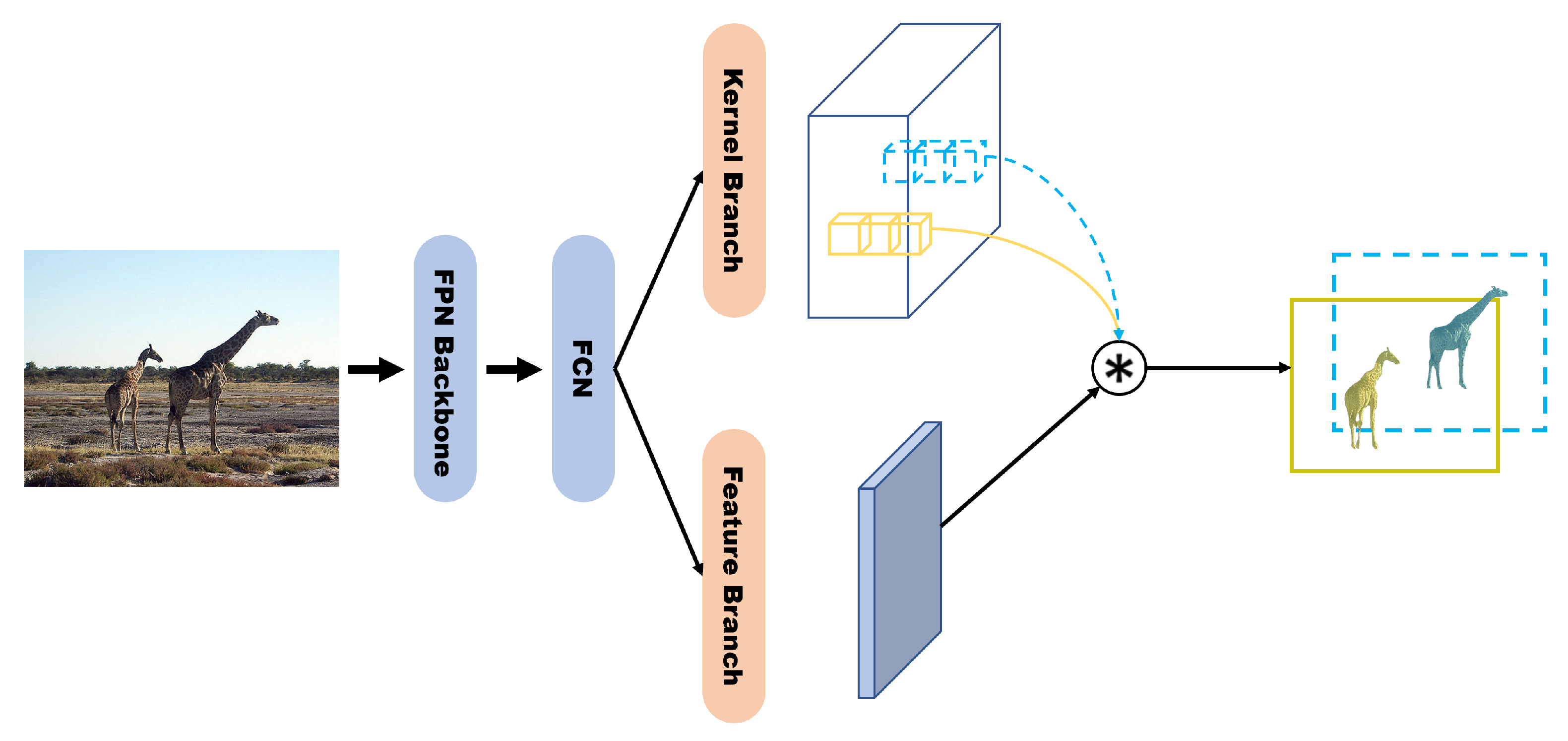
4.2. Speed-Focused Models
5. Experiments
- (1)
- RTX 3090 + Intel i9 10900X + CUDA 11.3 + PyTorch 1.10.1;
- (2)
- GTX 1080 Ti + Intel i9 10900X + CUDA 10.2 + PyTorch 1.10.1.
5.1. Quantitative Results
5.1.1. Accuracy Rate
5.1.2. Inference Speed
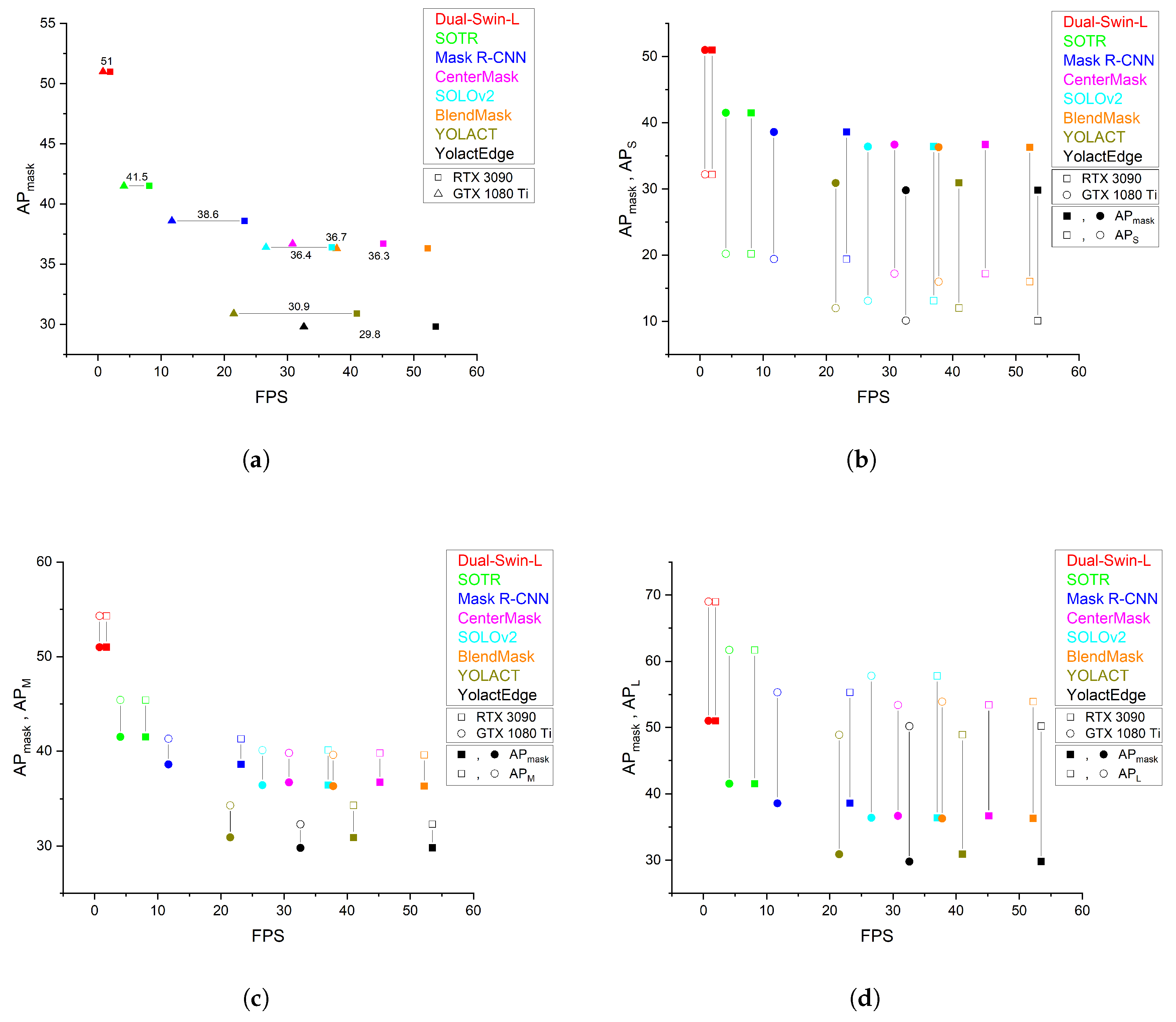
5.1.3. Accuracy Rate versus Inference Speed
5.1.4. RTX 3090 versus GTX 1080 Ti
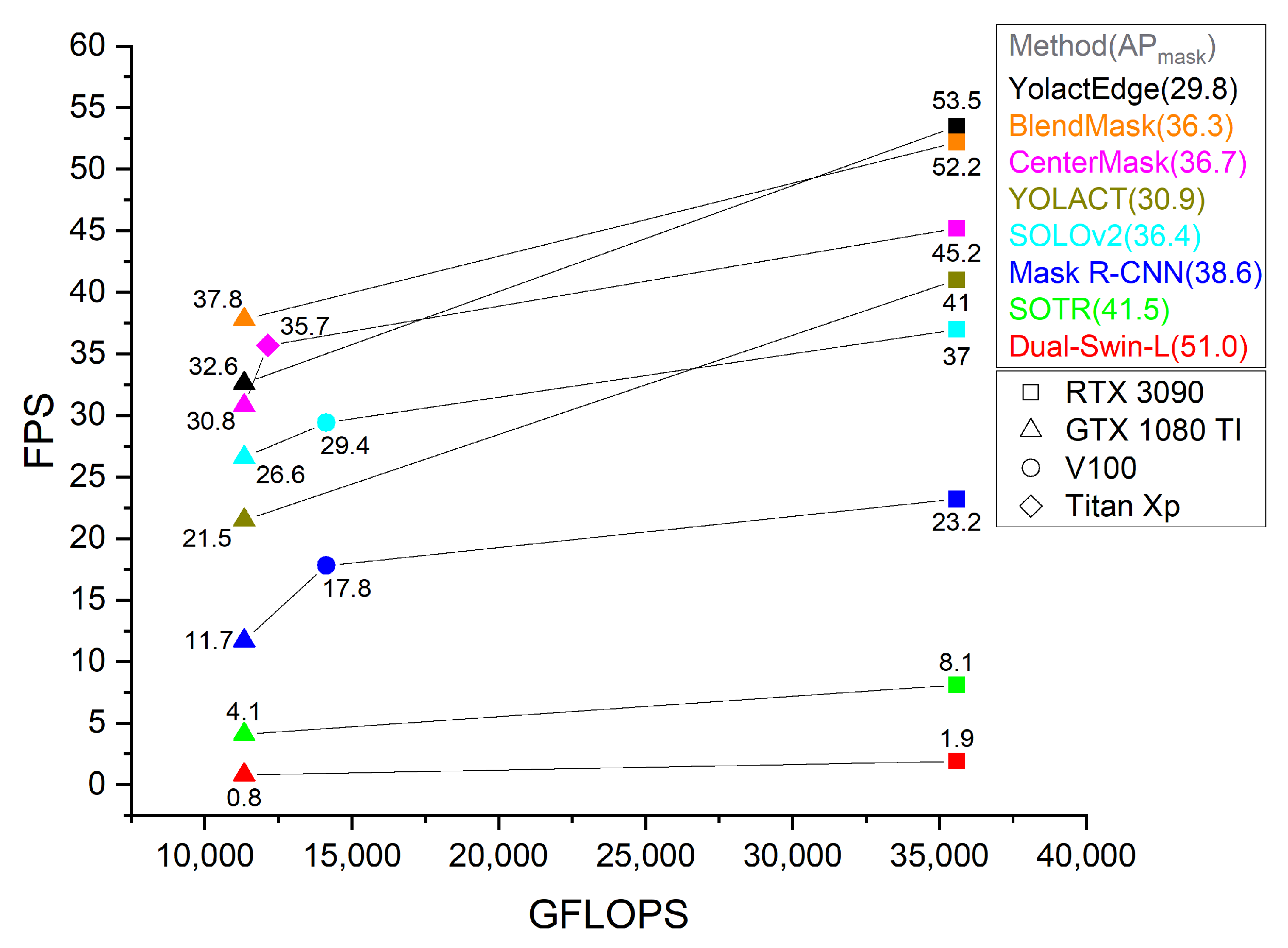
5.1.5. GPU GFLOPS versus Inference Speed
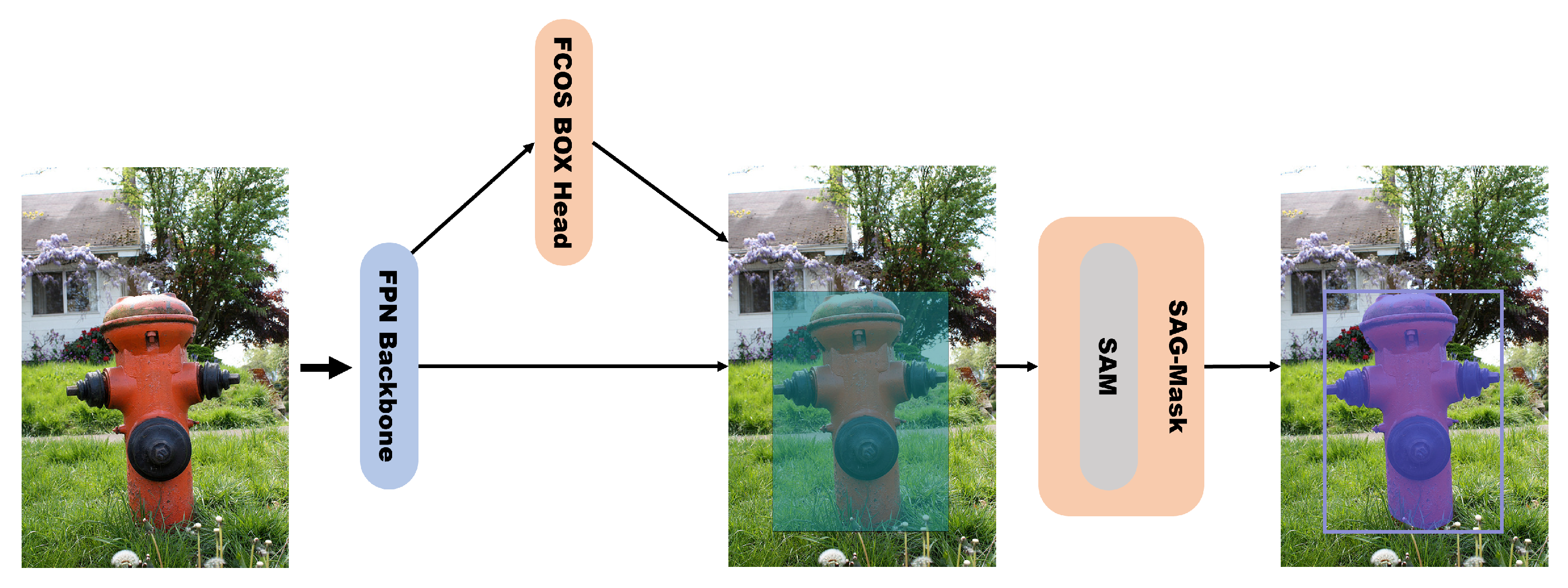
5.2. Qualitative Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kirillov, A.; He, K.; Girshick, R.; Rother, C.; Dollár, P. Panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9404–9413. [Google Scholar]
- Liang, T.; Chu, X.; Liu, Y.; Wang, Y.; Tang, Z.; Chu, W.; Chen, J.; Ling, H. Cbnetv2: A composite backbone network architecture for object detection. arXiv 2021, arXiv:2107.00420. [Google Scholar]
- Guo, R.; Niu, D.; Qu, L.; Li, Z. SOTR: Segmenting Objects with Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 7157–7166. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Lee, Y.; Park, J. CenterMask: Real-Time Anchor-Free Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Wang, X.; Zhang, R.; Kong, T.; Li, L.; Shen, C. Solov2: Dynamic and fast instance segmentation. Adv. Neural Inf. Process. Syst. 2020, 33, 17721–17732. [Google Scholar]
- Chen, H.; Sun, K.; Tian, Z.; Shen, C.; Huang, Y.; Yan, Y. Blendmask: Top-down meets bottom-up for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 8573–8581. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-time instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar]
- Liu, H.; Soto, R.A.R.; Xiao, F.; Lee, Y.J. Yolactedge: Real-time instance segmentation on the edge. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 9579–9585. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Ignatov, A.; Timofte, R.; Kulik, A.; Yang, S.; Wang, K.; Baum, F.; Wu, M.; Xu, L.; Van Gool, L. Ai benchmark: All about deep learning on smartphones in 2019. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 3617–3635. [Google Scholar]
- Luo, C.; He, X.; Zhan, J.; Wang, L.; Gao, W.; Dai, J. Comparison and Benchmarking of AI Models and Frameworks on Mobile Devices. arXiv 2020, arXiv:2005.05085. [Google Scholar]
- Bianco, S.; Cadene, R.; Celona, L.; Napoletano, P. Benchmark Analysis of Representative Deep Neural Network Architectures. IEEE Access 2018, 6, 64270–64277. [Google Scholar] [CrossRef]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7310–7311. [Google Scholar]
- Wang, Y.E.; Wei, G.Y.; Brooks, D. Benchmarking TPU, GPU, and CPU platforms for deep learning. arXiv 2019, arXiv:1907.10701. [Google Scholar]
- Ammirato, P.; Poirson, P.; Park, E.; Košecká, J.; Berg, A.C. A dataset for developing and benchmarking active vision. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1378–1385. [Google Scholar]
- Perazzi, F.; Pont-Tuset, J.; McWilliams, B.; Van Gool, L.; Gross, M.; Sorkine-Hornung, A. A benchmark dataset and evaluation methodology for video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 724–732. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5999–6009. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Nvidia TensorRT. Available online: https://developer.nvidia.com/tensorrt (accessed on 14 July 2022).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Yang, L.; Fan, Y.; Xu, N. Video instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2019; pp. 5188–5197. [Google Scholar]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Van Der Smagt, P.; Cremers, D.; Brox, T. Flownet: Learning optical flow with convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2758–2766. [Google Scholar]
- Wang, X.; Kong, T.; Shen, C.; Jiang, Y.; Li, L. Solo: Segmenting objects by locations. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 649–665. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 14 July 2022).
- Trained Model of DB-Swin-L. Available online: https://github.com/VDIGPKU/CBNetV2 (accessed on 14 July 2022).
- Trained Model of SOTR_R101_DCN. Available online: https://github.com/easton-cau/SOTR (accessed on 14 July 2022).
- Trained Model of R101-FPN. Available online: https://github.com/facebookresearch/detectron2/blob/main/MODEL_ZOO.md (accessed on 14 July 2022).
- Trained Model of centermask2-lite-V-39-eSE-FPN-ms-4x. Available online: https://github.com/youngwanLEE/centermask2 (accessed on 14 July 2022).
- Trained Model of SOLOv2_Light_512_DCN_R50_3x. Available online: https://github.com/WXinlong/SOLO (accessed on 14 July 2022).
- Trained Model of DLA_34_4x. Available online: https://github.com/aim-uofa/AdelaiDet/tree/master/configs/BlendMask (accessed on 14 July 2022).
- Trained Model of yolact_im700_54_800000. Available online: https://github.com/dbolya/yolact (accessed on 14 July 2022).
- Trained Model of yolact_edge_54_800000. Available online: https://github.com/haotian-liu/yolact_edge (accessed on 14 July 2022).
- Specifications of RTX 3090. Available online: https://www.nvidia.com/content/PDF/nvidia-ampere-ga-102-gpu-architecture-whitepaper-v2.pdf (accessed on 14 July 2022).
- GPU Clocks of Tesla V100. Available online: https://images.nvidia.com/content/tesla/pdf/Tesla-V100-PCIe-Product-Brief.pdf (accessed on 14 July 2022).
- CUDA Cores of Tesla V100. Available online: https://images.nvidia.com/content/technologies/volta/pdf/tesla-volta-v100-datasheet-letter-fnl-web.pdf (accessed on 14 July 2022).
- Specifications of RTX 2080, Ti. Available online: https://www.nvidia.com/en-me/geforce/graphics-cards/rtx-2080-ti/ (accessed on 14 July 2022).
- Specifications of Titan, Xp. Available online: https://www.nvidia.com/en-us/titan/titan-xp/ (accessed on 14 July 2022).
- Specifications of GTX 1080, Ti. Available online: https://www.nvidia.com/en-gb/geforce/graphics-cards/geforce-gtx-1080-ti/specifications/ (accessed on 14 July 2022).
- Specifications of HiSilicon Kirin 9000. Available online: https://www.cpu-monkey.com/en/cpu-hisilicon_kirin_9000 (accessed on 14 July 2022).
- Specifications of Snapdragon8 Gen 1. Available online: https://www.cpu-monkey.com/en/cpu-qualcomm_snapdragon_8_gen_1 (accessed on 14 July 2022).
- Specifications of Google Tensor. Available online: https://www.cpu-monkey.com/en/cpu-google_tensor (accessed on 14 July 2022).
- Specifications of Snapdragon 888. Available online: https://www.cpu-monkey.com/en/cpu-qualcomm_snapdragon_888 (accessed on 14 July 2022).
- Specifications of Snapdragon 870. Available online: https://www.cpu-monkey.com/en/cpu-qualcomm_snapdragon_870 (accessed on 14 July 2022).
- Specifications of Samsung Exynos 2100. Available online: https://www.cpu-monkey.com/en/cpu-samsung_exynos_2100 (accessed on 14 July 2022).
- Cao, J.; Anwer, R.M.; Cholakkal, H.; Khan, F.S.; Pang, Y.; Shao, L. Sipmask: Spatial information preservation for fast image and video instance segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 1–18. [Google Scholar]
- Du, W.; Xiang, Z.; Chen, S.; Qiao, C.; Chen, Y.; Bai, T. Real-time Instance Segmentation with Discriminative Orientation Maps. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 7314–7323. [Google Scholar]
- Specifications of Jetson AGX Orin Developer Kit. Available online: https://developer.nvidia.com/embedded/jetson-agx-orin-developer-kit (accessed on 14 July 2022).
- Specifications of Jetson AGX Xavier Developer Kit. Available online: https://developer.nvidia.com/embedded/jetson-agx-xavier-developer-kit (accessed on 14 July 2022).























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Model | Reference GPU | Tested GPU | Tested FPS | AP | AP | AP | AP | AP |
|---|---|---|---|---|---|---|---|---|---|
| Dual-Swin-L | DB-Swin-L [32] | NVIDIA V100 [2] | RTX 3090 | 1.9 | 51.0 | 59.1 | 32.2 | 54.3 | 69.0 |
| GTX 1080 Ti | 0.8 | ||||||||
| SOTR | SOTR_R101_DCN [33] | NVIDIA V100 [3] | RTX 3090 | 8.1 | 41.5 | - | 20.2 | 45.4 | 61.7 |
| GTX 1080 Ti | 4.1 | ||||||||
| Mask R-CNN | R101-FPN [34] | NVIDIA V100 (17.8 FPS) [34] | RTX 3090 | 23.2 | 38.6 | 42.9 | 19.4 | 41.3 | 55.3 |
| GTX 1080 Ti | 11.7 | ||||||||
| Centermask | centermask2-lite-V-39-eSE- FPN-ms-4x [35] | NVIDIA Titan Xp (35.7 FPS) [35] | RTX 3090 | 45.2 | 36.7 | 40.9 | 17.2 | 39.8 | 53.4 |
| GTX 1080 Ti | 30.8 | ||||||||
| SOLOv2 | SOLOv2_Light_512_DCN_ R50_3x [36] | NVIDIA V100 (29.4 FPS) [36] | RTX 3090 | 37.0 | 36.4 | - | 13.1 | 40.1 | 57.8 |
| GTX 1080 Ti | 26.6 | ||||||||
| Blendmask | DLA_34_4x [37] | GTX 1080 Ti (32.1 FPS) [37] | RTX 3090 | 52.2 | 36.3 | 40.8 | 16.0 | 39.6 | 53.9 |
| GTX 1080 Ti | 37.8 | ||||||||
| YOLACT | yolact_im700_54_800000 [38] | NVIDIA Titan Xp [8] | RTX 3090 | 41.0 | 30.9 | 33.4 | 12.0 | 34.3 | 48.9 |
| GTX 1080 Ti | 21.5 | ||||||||
| YolactEdge | yolact_edge_54_800000 [39] | RTX 2080 Ti [9] | RTX 3090 | 53.5/177.3 * | 29.8/29.9 * | 32.5/32.4 * | 10.1/9.9 * | 32.3/31.9 * | 50.2/50.4 * |
| GTX 1080 Ti | 32.6/81.6 * |
| Method | Tested GPU | Mean | SD | Min | Max | Median |
|---|---|---|---|---|---|---|
| YolactEdge | RTX 3090 | 53.5/177.3 * | 0.929/0.653 * | 51.9/176.2 * | 54.7/178.2 * | 53.9/177.5 * |
| GTX 1080TI | 32.6/81.6 * | 0.179/0.331 * | 32.4/80.8 * | 32.9/81.9 * | 32.6/81.8 * | |
| Blendmask | RTX 3090 | 52.2 | 0.231 | 51.9 | 52.6 | 52.2 |
| GTX 1080TI | 37.8 | 0.069 | 37.7 | 37.9 | 37.9 | |
| Centermask | RTX 3090 | 45.2 | 0.134 | 45.0 | 45.4 | 45.2 |
| GTX 1080TI | 30.8 | 0.035 | 30.8 | 30.9 | 30.8 | |
| YOLACT | RTX 3090 | 41.0 | 0.658 | 39.6 | 41.4 | 41.3 |
| GTX 1080TI | 21.5 | 0.205 | 21.1 | 21.7 | 21.6 | |
| SOLOv2 | RTX 3090 | 37.0 | 0.187 | 36.8 | 37.4 | 37.0 |
| GTX 1080TI | 26.6 | 0.064 | 26.5 | 26.7 | 26.6 | |
| Mask R-CNN | RTX 3090 | 23.2 | 0.024 | 23.1 | 23.2 | 23.2 |
| GTX 1080TI | 11.7 | 0.011 | 11.7 | 11.7 | 11.7 | |
| SOTR | RTX 3090 | 8.1 | 0.017 | 8.0 | 8.1 | 8.1 |
| GTX 1080TI | 4.1 | 0.008 | 4.1 | 4.2 | 4.1 | |
| Dual-Swin-L | RTX 3090 | 1.9 | 0.030 | 1.9 | 2.0 | 1.9 |
| GTX 1080TI | 0.8 | 0.030 | 0.7 | 0.8 | 0.8 |
| Method | Tested GPU | Tested FPS | Relative Performance (%) RTX 3090/GTX 1080 Ti |
|---|---|---|---|
| YolactEdge | RTX 3090 | 53.5/177.3 * | 164/217 * |
| GTX 1080 Ti | 32.6/81.6 * | ||
| Blendmask | RTX 3090 | 52.2 | 138 |
| GTX 1080 Ti | 37.8 | ||
| Centermask | RTX 3090 | 45.2 | 147 |
| GTX 1080 Ti | 30.8 | ||
| YOLACT | RTX 3090 | 41 | 191 |
| GTX 1080 Ti | 21.5 | ||
| SOLOv2 | RTX 3090 | 37 | 139 |
| GTX 1080 Ti | 26.6 | ||
| Mask R-CNN | RTX 3090 | 23.2 | 198 |
| GTX 1080 Ti | 11.7 | ||
| SOTR | RTX 3090 | 8.1 | 198 |
| GTX 1080 Ti | 4.1 | ||
| Dual-Swin-L | RTX 3090 | 1.9 | 238 |
| GTX 1080 Ti | 0.8 |
| Device | GPU Clock (GHz) | GFLOPS (FP32) | Relative GFLOPS (%) |
|---|---|---|---|
| RTX 3090 [40] | 1695 | 35,581 | 313.7 |
| Tesla V100 [41,42] | 1380 | 14,131 | 124.6 |
| RTX 2080 Ti [43] | 1545 | 13,447 | 118.5 |
| Titan Xp [44] | 1582 | 12,149 | 107.1 |
| GTX 1080 Ti [45] | 1582 | 11,339 | 100 |
| HiSilicon Kirin 9000 [46] (ARM Mali-G78 MP24) | 760 | 2332 | 20.5 |
| Snapdragon8 gen 1 [47] (Qualcomm Adreno 730) | 820 | 2236 | 19.7 |
| Google Tensor [48] (ARM Mali-G78 MP20) | 760 | 1943 | 17.1 |
| Snapdragon 888 [49] (Qualcomm Adreno 660) | 840 | 1720 | 15.1 |
| Snapdragon 870 [50] (Qualcomm Adreno 650) | 670 | 1418 | 12.5 |
| Samsung Exynos 2100 [51] (ARM Mali-G78 MP14) | 760 | 1360 | 11.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, S.; Heo, H.; Park, S.; Jung, S.-U.; Lee, K. Benchmarking Deep Learning Models for Instance Segmentation. Appl. Sci. 2022, 12, 8856. https://doi.org/10.3390/app12178856
Jung S, Heo H, Park S, Jung S-U, Lee K. Benchmarking Deep Learning Models for Instance Segmentation. Applied Sciences. 2022; 12(17):8856. https://doi.org/10.3390/app12178856
Chicago/Turabian StyleJung, Sunguk, Hyeonbeom Heo, Sangheon Park, Sung-Uk Jung, and Kyungjae Lee. 2022. "Benchmarking Deep Learning Models for Instance Segmentation" Applied Sciences 12, no. 17: 8856. https://doi.org/10.3390/app12178856
APA StyleJung, S., Heo, H., Park, S., Jung, S. -U., & Lee, K. (2022). Benchmarking Deep Learning Models for Instance Segmentation. Applied Sciences, 12(17), 8856. https://doi.org/10.3390/app12178856