Appendix A
Based on the YOLOX-Tiny model, the key techniques of backbone feature extraction network (Backbone), enhanced feature extraction network (Neck), and prediction sections of ECA-YOLOX-Tiny (decoupled head, anchor-free, and simplified dynamic label matching strategy SimOTA) are described in the following.
The backbone network is used to preliminarily extract the feature and obtain three initial effective feature layers for multi-scale feature fusion. The backbone network of ECA-YOLOX-Tiny in
Figure 3 is CSPDarknet, for which the CSP structure (CSPLayer) of cross-stage partial network (CSPNet) is adopted. A series of small residual units (Res Units) in a stacked structure are adopted in the backbone branch of CSPLayer, and the larger residual edges are built on the side branches. Through the large residual edges, the input and output of the backbone branch are directly connected by the simple channel dimension adjustment method. The main branch of the residual unit is a 1 × 1 convolution connected to a 3 × 3 convolution, and there is no special treatment for residual edges and the direct addition operation between inputs and outputs of the main branch is designed. The structure of the CSPLayer as well as the Res Unit is shown in
Figure A1a,b.
Figure A1.
The structure diagram of CSPLayer and Res Unit: (a) CSPLayer structure (b) Res Unit.
Figure A1.
The structure diagram of CSPLayer and Res Unit: (a) CSPLayer structure (b) Res Unit.
The abundant gradient combination can be achieved by using cross-stage splitting and merging strategies in the CSPLayer module, and the excessive and repetitive gradient information can be prevented by the method of gradient flow truncation. The CSPLayer module not only has a small amount of calculation and memory consumption, but also enhances the learning ability of the network. In the CSPLayer module, the residual units are easy to optimize, and the shortcut connections are used to improve the feature extraction ability of the model, by which the problems of gradient disappearance, gradient explosion and model degradation caused by the increase in network depth can be alleviated.
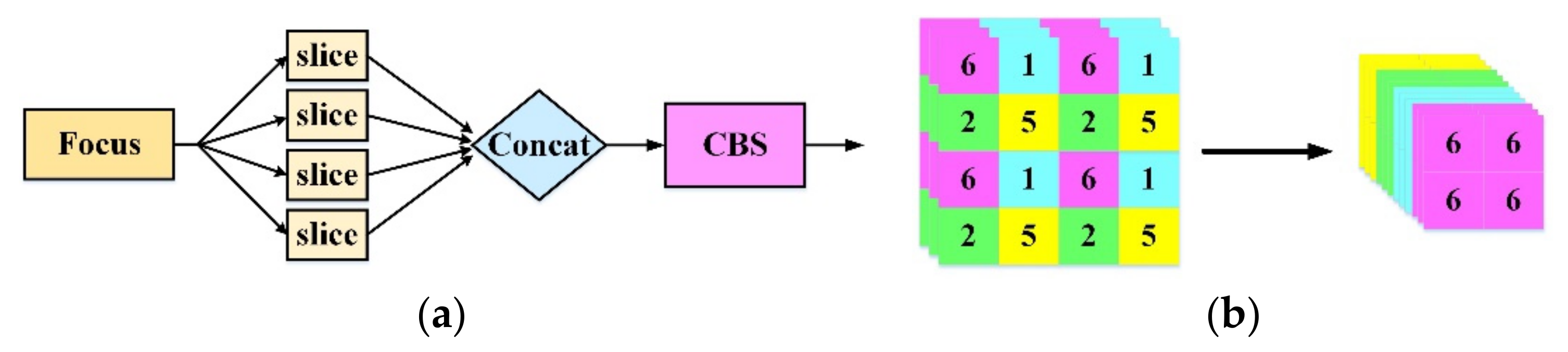
Similar to the neighboring down-sampling, a special down-sampling method (focus network structure) is introduced in YOLOV5, for which four independent low-resolution feature maps are firstly reconstructed from a high-resolution image by taking a value every other pixel, and then four independent feature maps are stacked. Additionally, the number of feature map channels increases four times, the length and width of the feature maps are half that of the original feature maps, the width and height information of the feature points are stacked on the channel space, and the receptive field of the feature points is improved. The problem of information loss caused by down-sampling of the original images can be solved by the special down-sampling method, and two-fold down-sampling feature maps without information loss can finally be obtained. The focus network structure is borrowed in ECA-YOLOX-Tiny to reduce model computation and memory occupation as well as improve model speed. The focus network structure and its corresponding feature map transformations are shown in
Figure A2a,b.
Figure A2.
The focus network structure and its feature map transformations: (a) focus network structure, (b) the transformation of feature maps.
Figure A2.
The focus network structure and its feature map transformations: (a) focus network structure, (b) the transformation of feature maps.
A new SiLU activation function [
32] expressed in (A1) is employed in ECA-YOLOX-Tiny.
where
x is the inputs of model.
Compared with ReLU, the smooth output of SiLU is more ergodic, and the sensitivity of model initialization and learning rate is reduced. The non-monotonicity of SiLU increases the model expressiveness and improves the gradient flow, the robustness can be provided in light of the different initialization and learning rate. When the function lies in the saturation region, the training is very slow due to the small gradient, but the loss function saturation condition can be avoided because there is no compression gradient of SiLU.
In ECA-YOLOX-Tiny model, the SPPBottleneck module is applied to the end of the backbone network, and the different scales’ feature information is mixed together through the parallel maximum pooling layers with different kernel sizes. The kernel sizes of four parallel branches are 1 × 1, 5 × 5, 9 × 9 and 13 × 13, respectively. Through the SPPBottleneck module, the information dimension of the feature maps is increased from 1024 to 4096 without changing the size of the feature maps, by which the receptive field of the network is expanded and the global information of the target can be captured more effectively. In addition, the multi-stage pooling operation is more robust, aiming at different sized targets and improving the accuracy of target identification. The structure of SPPBottleneck is shown in
Figure A3.
Figure A3.
The structure diagram of SPPBottleneck.
Figure A3.
The structure diagram of SPPBottleneck.
- 2.
Enhanced Feature Extraction Network (Neck)
In practice, the detection effect of small target defect areas is poor through the convolution neural network model, the main reasons are analyzed as follows. Firstly, small targets have the characteristics of low-resolution and small pixel proportion, so the effective information extracted by the target detection network is limited. Secondly, the information loss situation of the small targets is serious after the input images are down-sampled several times. In addition, the large-scale datasets of small target defects are inadequate. At present, the small target detection accuracy can be improved by data augmentation, multi-scale features fusion, and super-resolution techniques, etc.
In the ECA-YOLOX-Tiny model, three enhanced effective feature layers are obtained through enhanced feature extraction of the Neck module. The enhanced feature extraction module is composed of FPN (feature pyramid networks) up-sampling and PAN (path aggregation network) down-sampling. Through FPN up-sampling, the shallow high-resolution information is fused with deep high semantic information features, and the detection accuracy of the model for small target defective insulators can be improved. Through PAN down-sampling, the feature information is extracted repeatedly, and the different scales’ extraction feature information is fully exploited so as to improve the accuracy of model detection. The enhanced feature extraction module fixed by FPN and PAN is shown in
Figure A4.
Figure A4.
The enhanced feature extraction module fixed by FPN and PAN.
Figure A4.
The enhanced feature extraction module fixed by FPN and PAN.
- 3.
Prediction
In order to classify and regression localize the effective feature layers of three different scales, the original coupled head is discarded in the precision part of ECA-YOLOX-Tiny, meanwhile, the decoupled head, anchor-free mechanism and simplified optimal transport assignment (SimOTA) strategy are introduced innovatively.
- (a)
Decoupled Head
In the past YOLO series, the classification and regression are realized by a 1 × 1 convolution layer in the detection head (coupled head). However, there is a difference between classification and regression, the classification problem mainly considers the difference between each target object, and the regression problem mainly considers the characteristics of object contour boundary. Compared with coupled head (shown in
Figure A5), the 1 × 1 convolution layer is used to reduce the channel dimension in decoupled head, and two parallel branches are added behind the 1 × 1 convolution layer for classification and regression, respectively, by which the convergence speed and model detection accuracy can be effectively improved at a lower computational cost.
Figure A5.
The comparison between coupled head and decoupled head.
Figure A5.
The comparison between coupled head and decoupled head.
- (b)
Anchor-free
The target detection networks based on the anchor-free mechanism are at present considered as a new type and friendly networks for industrial applications. Compared with the anchor-based mechanism, the anchor-free mechanism detects targets through key points without anchor boxes, by which the number of model parameters and the computational complexity can be significantly reduced, meanwhile, the work of model training and detection phases is quite simple and the same performance as the anchor-based mechanism is obtained. Therefore, the anchor-free mechanism is adopted in the ECA-YOLOX-Tiny model to reduce the prediction quantity of each position from three (coordinate offset, confidence, and classification) to one (coordinate offset), and the four parameters of predicted bounding boxes (the offsets of the x and y axes, height and width) are directly predicted.
- (c)
SimOTA
In the convolution neural network model, the intersection over union (IoU) between the truth bounding boxes and the predicted bounding boxes is used to divide the positive and negative samples. Under the different condition of sizes, shapes and occlusions, etc., the assignment of positive and negative samples needs to be considered globally. Generally, the predicted bounding boxes assignment problem is regarded as an optimal transport problem of linear programming. The optimal transport assignment (OTA) solves the predicted bounding boxes allocation problem from the global perspective so as to match the truth bounding boxes with the predicted bounding boxes at the lowest overall cost. Supposed that there are K truth bounding boxes and M predicted bounding boxes, the cost matrix size is K × M, and the elements in the matrix are the loss values of the truth bounding boxes and predicted bounding boxes. The smaller the loss is, the smaller the cost of selecting the truth bounding boxes and predicted bounding boxes. Based on OTA, the Sinkhorn–Knopp algorithm is eliminated in the dynamic label assignment strategy (SimOTA), which not only reduces the training time of the model and makes the distribution of positive and negative samples more balanced, but also avoids the extra hyperparameters problem brought by the Sinkhorn–Knopp algorithm.
Appendix B
Based on the proposed model in the paper, the missing images are further analyzed and the following typical missing cases are founded.
The defective areas of insulators are obscured by stronger and similar background information and leads to detections being missed, as shown in
Figure A6a. The missed detections are caused by the too-small insulator targets, excessive overlap, highly similar backgrounds, and darker light, etc., as shown in
Figure A6b,c. The missed detections are caused by serious target occlusion as shown in
Figure A6d. The above typical missed detection situations are given in
Appendix B, and the missed detection targets are marked by red boxes in the figure.
Figure A6.
Some detections missed by ECA-YOLOX-Tiny: (a) the missing detection of insulator defect target, (b) The missing detection of overlap small target 1, (c) the missing detection of overlap small target 2, (d) the missing detection of serious occlusion target.
Figure A6.
Some detections missed by ECA-YOLOX-Tiny: (a) the missing detection of insulator defect target, (b) The missing detection of overlap small target 1, (c) the missing detection of overlap small target 2, (d) the missing detection of serious occlusion target.
In order to enable readers to have a clearer understanding of the research on lightweight target detection models, the current mainstream lightweight models and their characteristics are analyzed and summarized in
Table A1.
Table A1.
Summary of mainstream lightweight models and their characteristics.
Table A1.
Summary of mainstream lightweight models and their characteristics.
| Models | Characteristics | Who and When | References |
|---|
| SSD-MobileNetV1 | The accuracy was 59.29%, which was relatively low | Ghoury, S. et al. (2019) | [16] |
| SSD-MnasNet | The accuracy was 93.8%, which was high. The model size was 43.73 MB, FPS reached to 36.85 on Server, and the FPS reached to 8.27 on TX2. | Liu, X. et al. (2020) | [21] |
| YOLOV3-Tiny | The accuracy was 92.10%, the recall rate was 92.20%, and FPS reached 30. | Han, J. et al. (2020) | [33] |
| YOLOV4-Tiny | The mAP was 92.04%, and FPS reached 40. | Qiu, Z. et al. (2021) | [23] |
| YOLOV4-MobileNetV1 | The mAP was 97.26%, and FPS reached 53. | Qiu, Z. et al. (2022) | [22] |
| YOLOV4-MobileNetV3 | The mAP was 91.3%, and the model size was 116 MB. | Wu, J. et al. (2022) | [34] |











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



































































