
Understanding and Predicting the Usage of Shared Electric Scooter Services on University Campuses

 ,
,  , , ,
, , , 
Abstract
:1. Introduction
2. Related Works
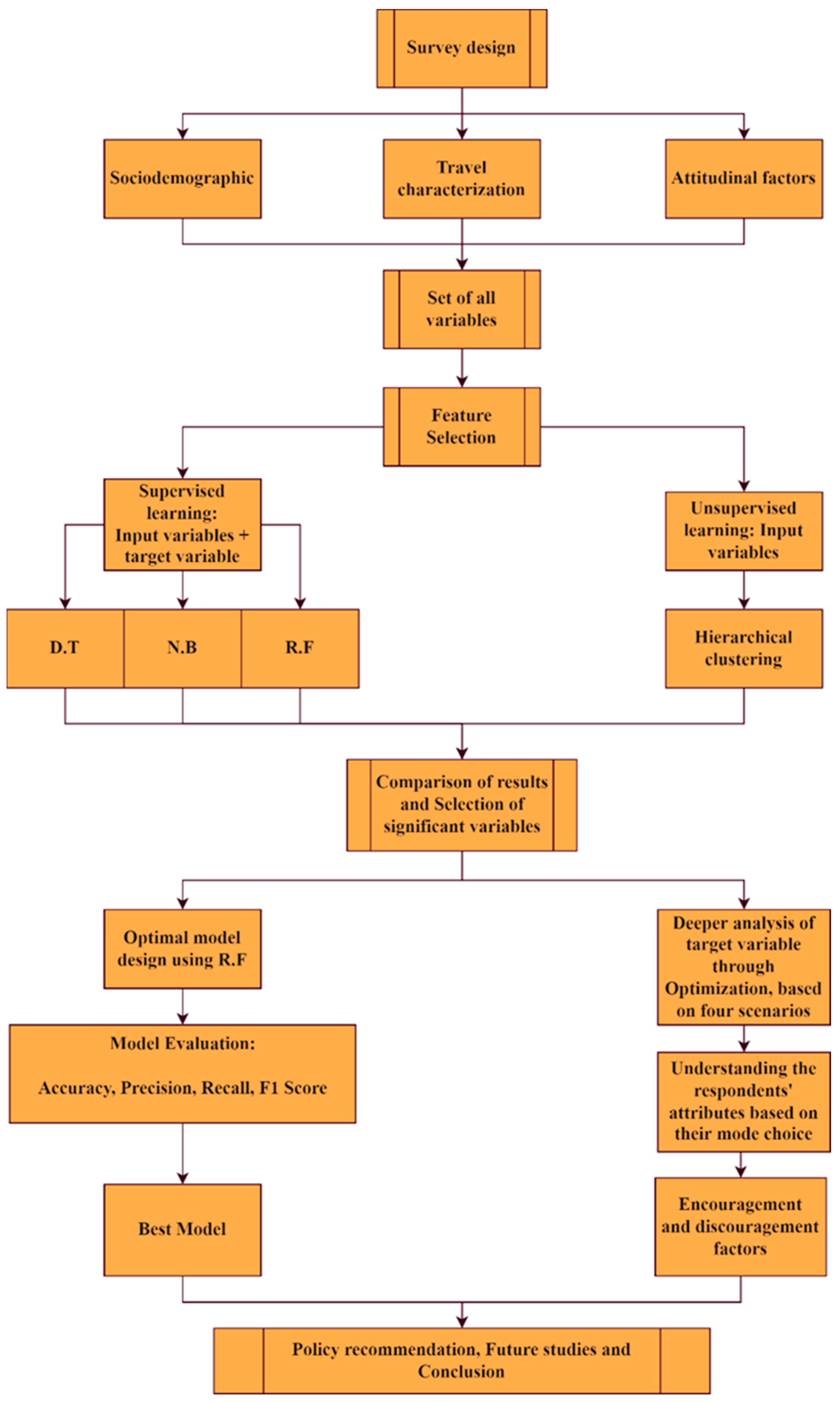
3. Methodology
3.1. Survey Design and Data Collection
- Sociodemographic information, including information about age, gender, marital status, residential area, highest level of education, employment status, race, household monthly income, private vehicle ownership, shared mobility and membership and frequency of usage of e-hailing services.
- Commuting characteristics, including commuting mode to and from the campus, and the travel mode, frequency, distance, time and cost on campus.
- Perceptions and choices regarding the SFFES service, including (1) perceptions regarding using SFFESs and concerns of safety, equity, costs, comfort, and social distancing due to COVID-19; (2) service attributes, such as accessibility, payment methods, and the advantages and disadvantages of shared e-scooters compared to other transport modes; and (3) infrastructure and built environment, such as separated lanes for scooters, green spaces, quality of road surfaces and connectivity.
- Usage frequency of the SFFES service, including four levels of response: (1) not using an e-scooter at all; (2) using an e-scooter as a mode of transport occasionally (sometimes but infrequently); (3) using an e-scooter frequently; and (4) using an e-scooter regularly as a main mode of transport. (Table 1 presents the information on the data and attributes used in this study).
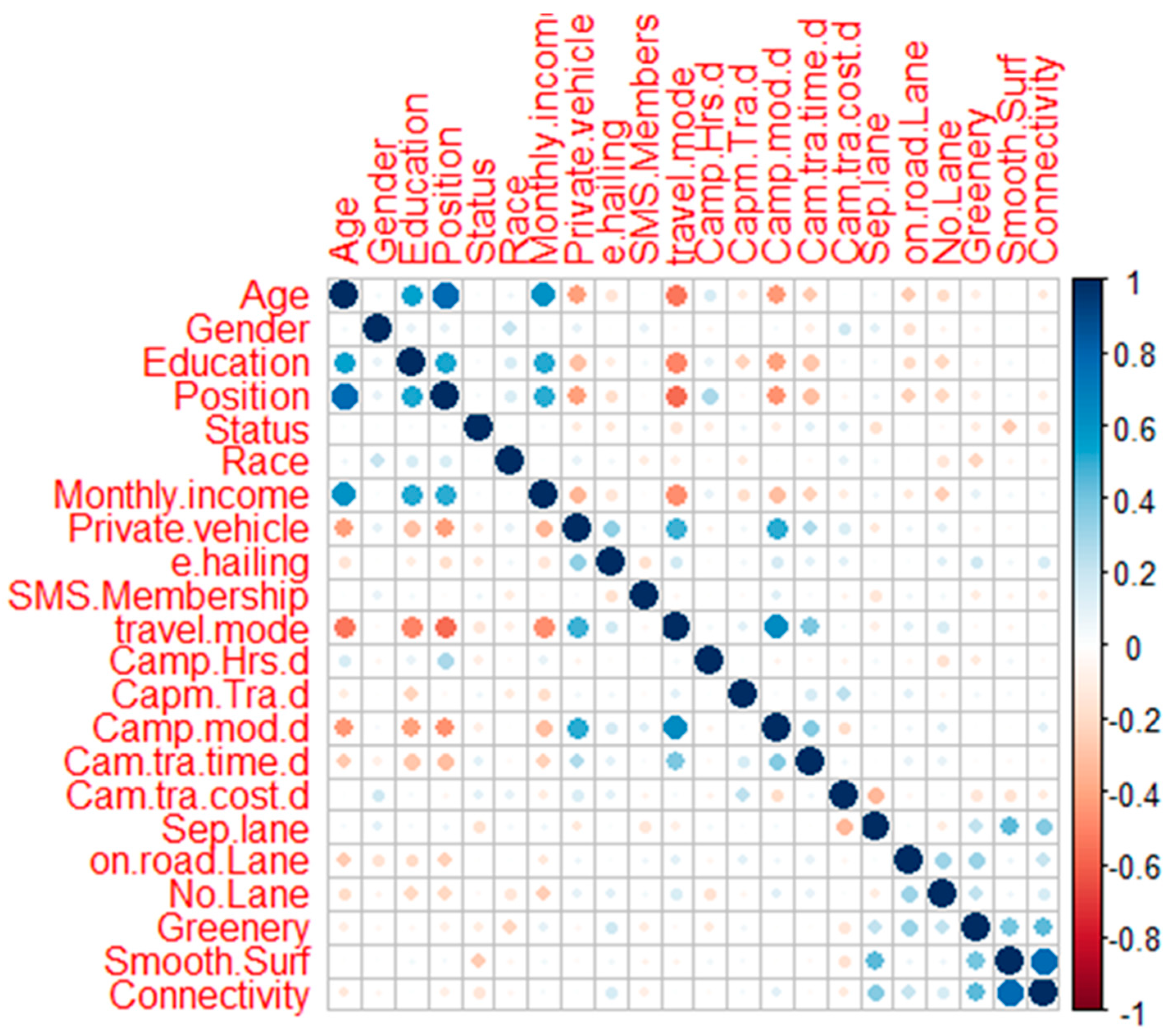
3.2. Feature Selection
Clustering
- The observed data of 1000 samples with variables is analyzed by changing the number of clusters from , and the total within intra-cluster variation is computed.
- reference datasets with a random uniform distribution is generated. Each reference dataset is clustered with varied number of clusters , and the corresponding total within intra-cluster variation is computed.
- The estimated gap statistic is computed as the deviation of the observed value from its expected value, under the null hypothesis: Gap(k) = 1B∑b = 1Blog(W ∗ kb) − log(Wk). The standard deviation of the statistics is also computed.
- The number of clusters is chosen as the smallest value of such that the gap statistic is within one standard deviation of the gap at k + 1: Gap(k) ≥ Gap(k + 1) − sk + 1.
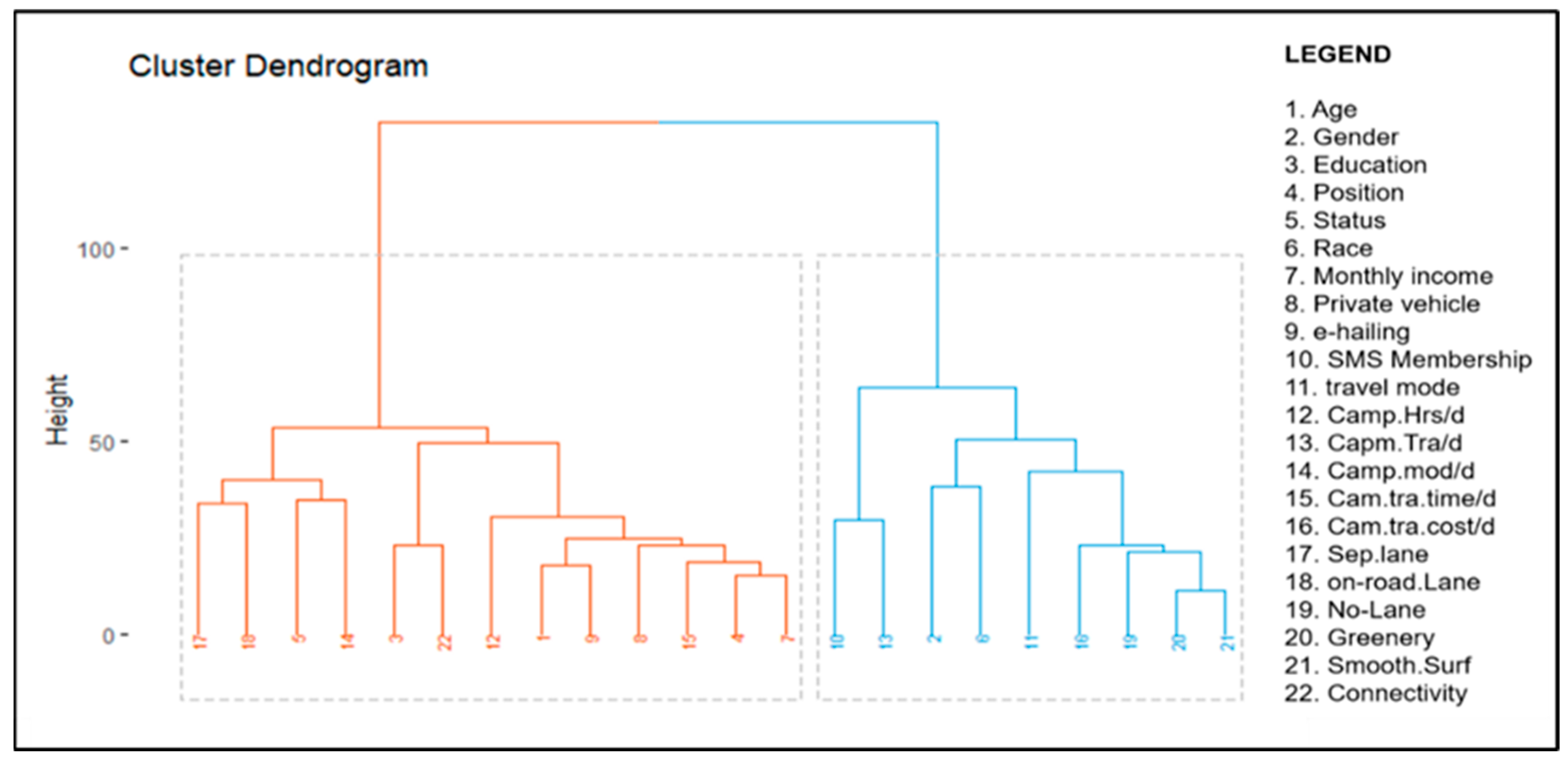
- Divide variables into groups by cutting at a desired similarity level.
- Calculate the dissimilarity matrix between variables using function dist () in hclust package.
- Plot the dendrogram using fviz_dend () function in factoextra package with dissimilarity matrix as the input.
3.3. The Optimal Model Design
3.4. Model Evaluation
4. Results
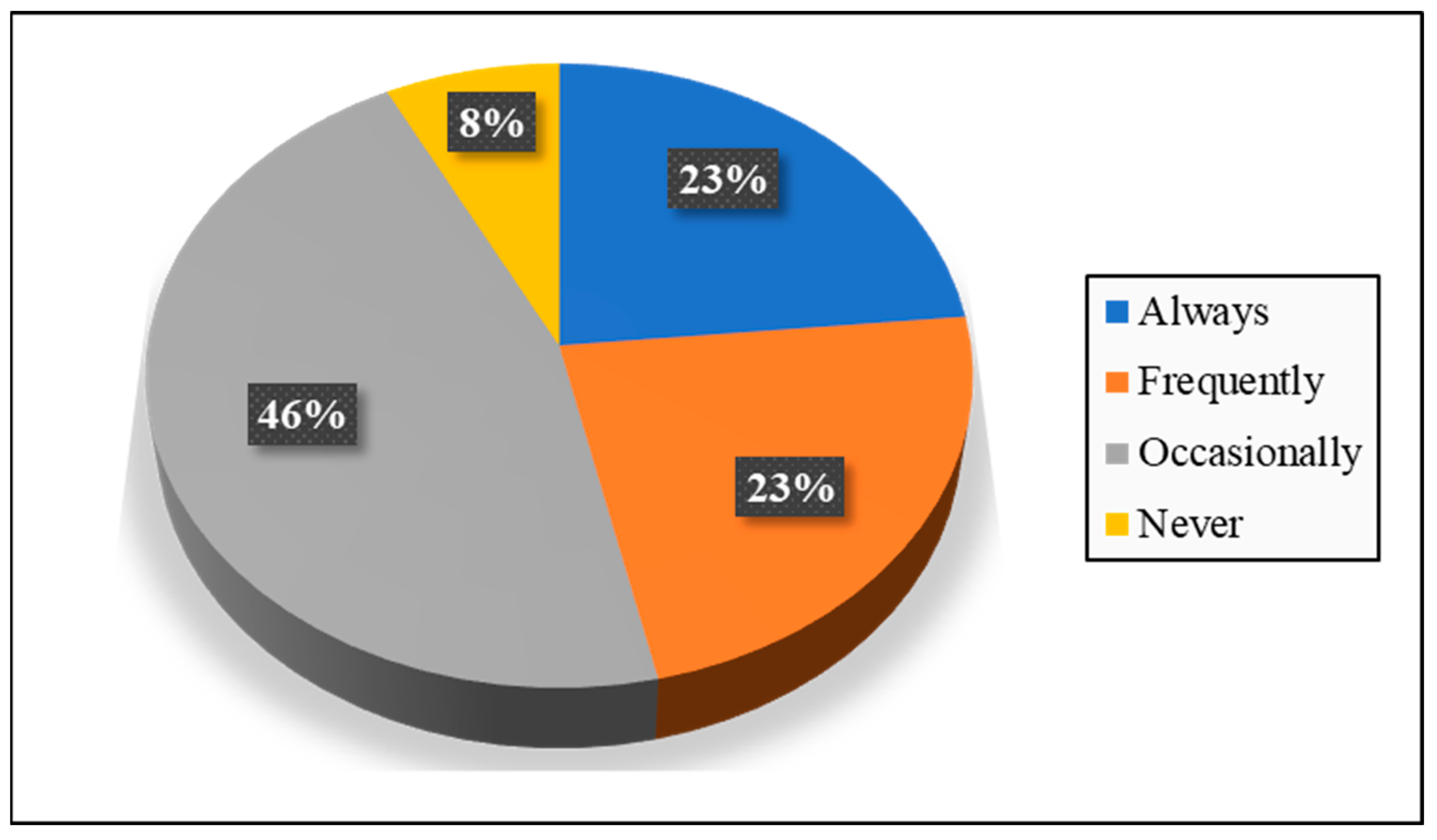
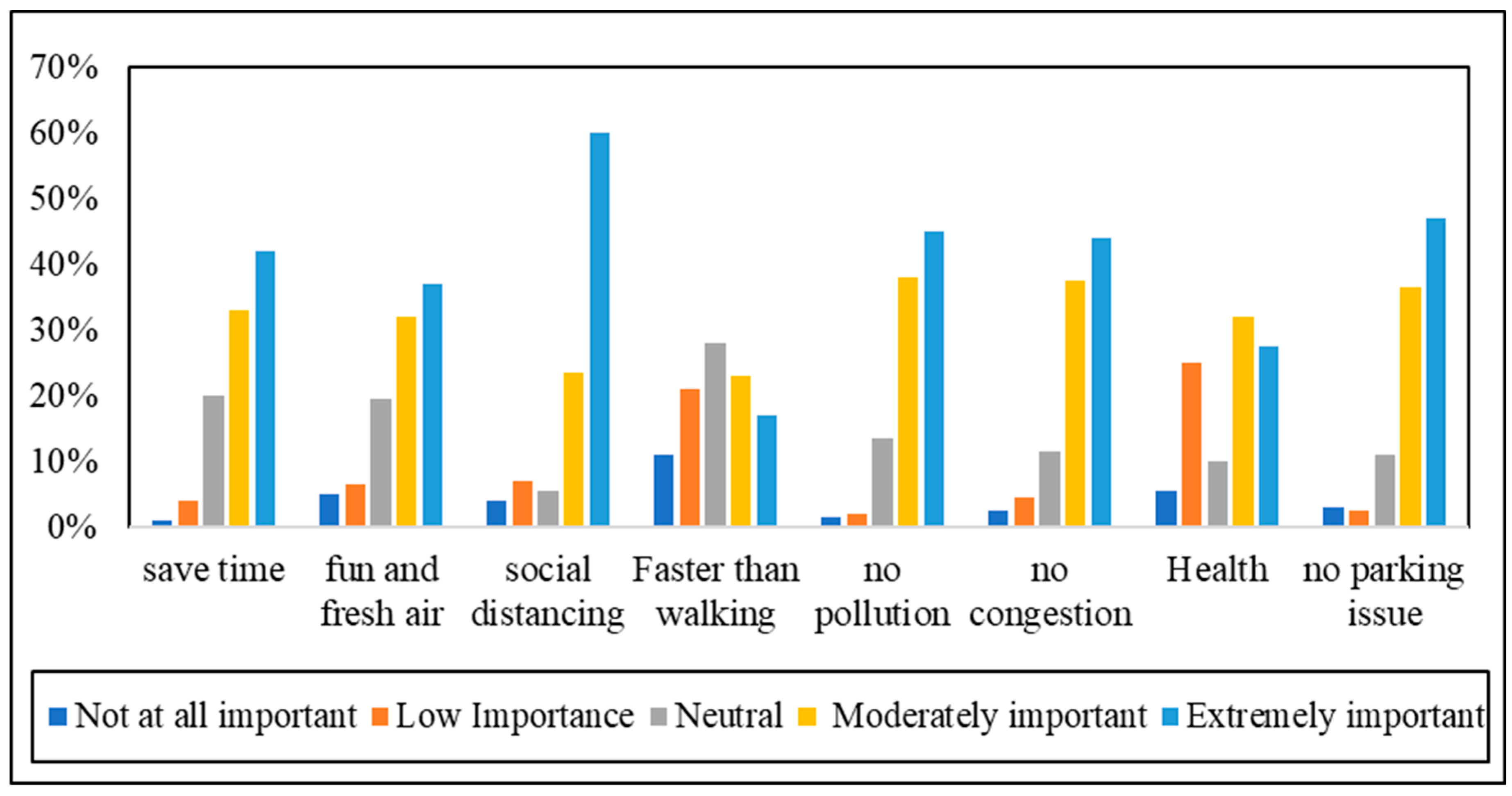
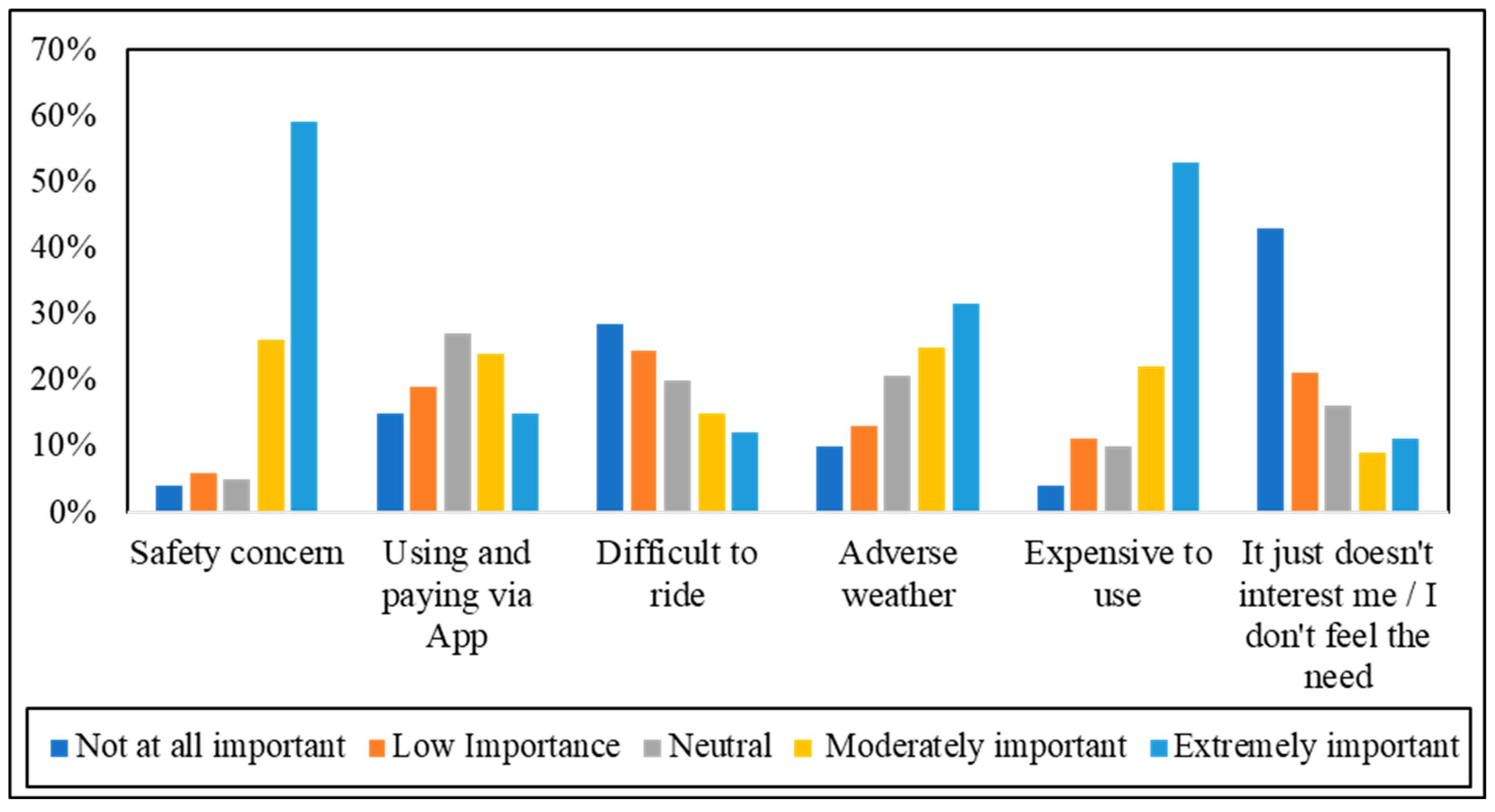
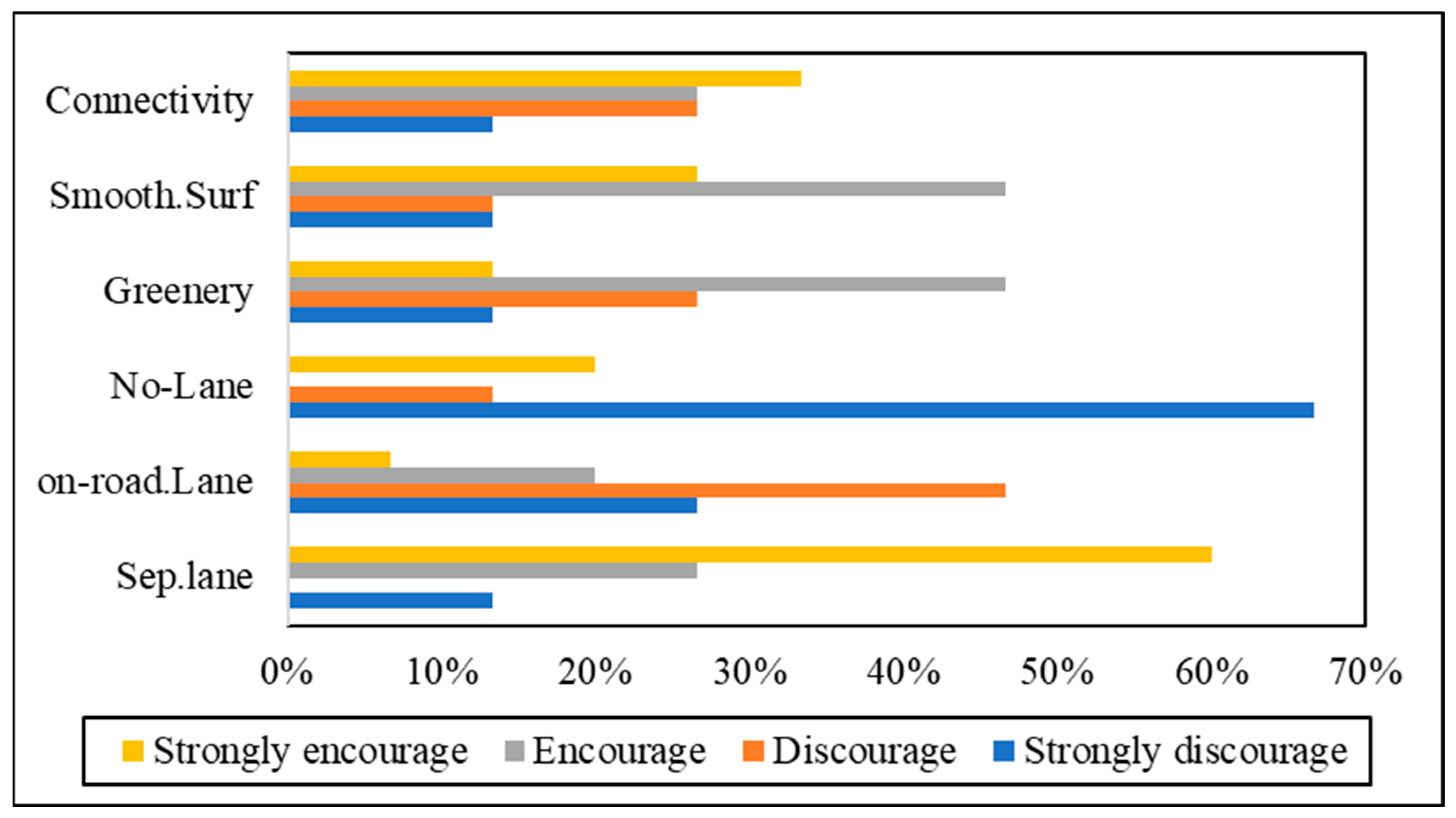
4.1. Descriptive Analysis (Encouragement and Discouragement Factors)
4.2. Policy Recommendation
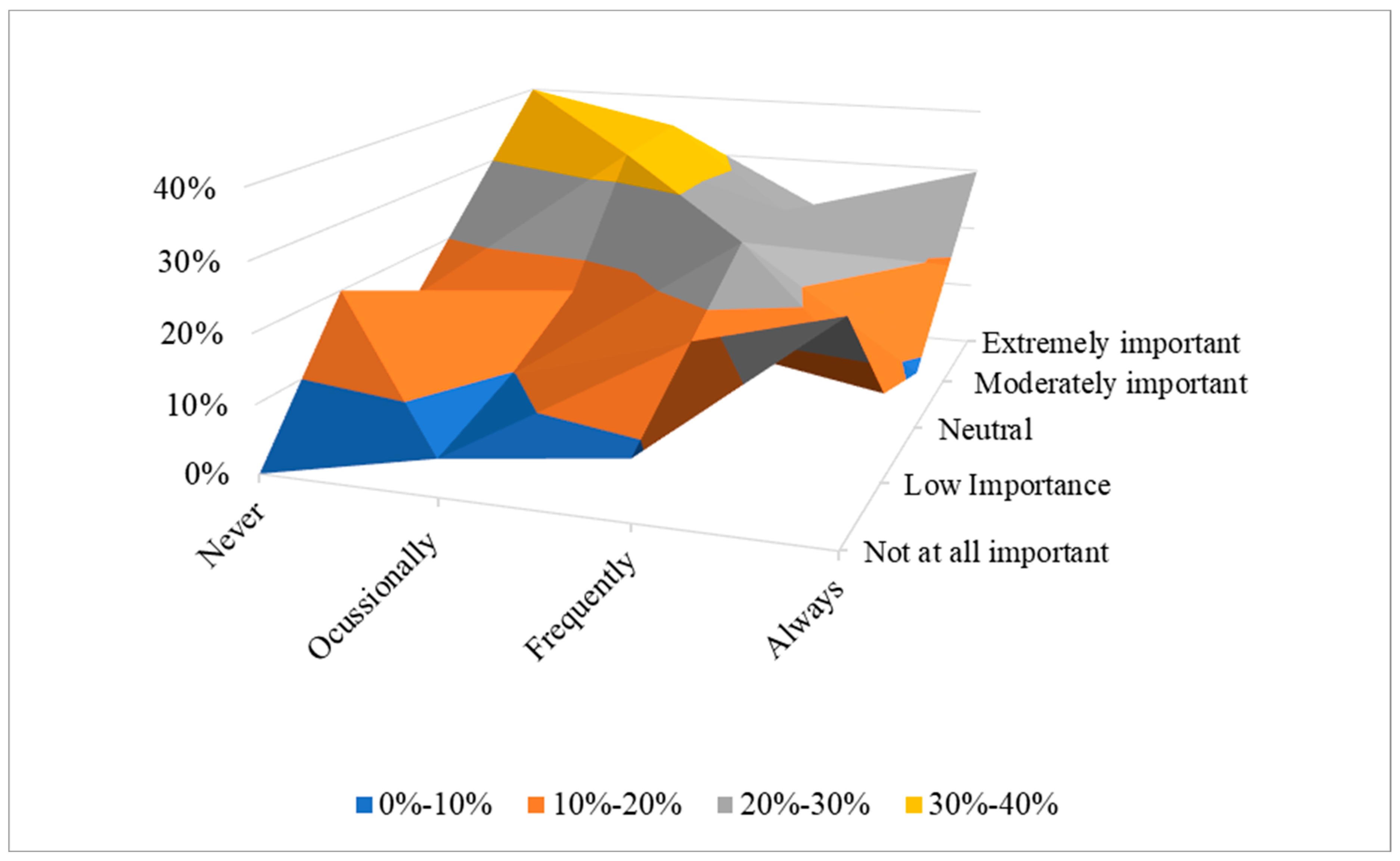
4.3. Selection of Significant Variables through Unsupervised Clustering
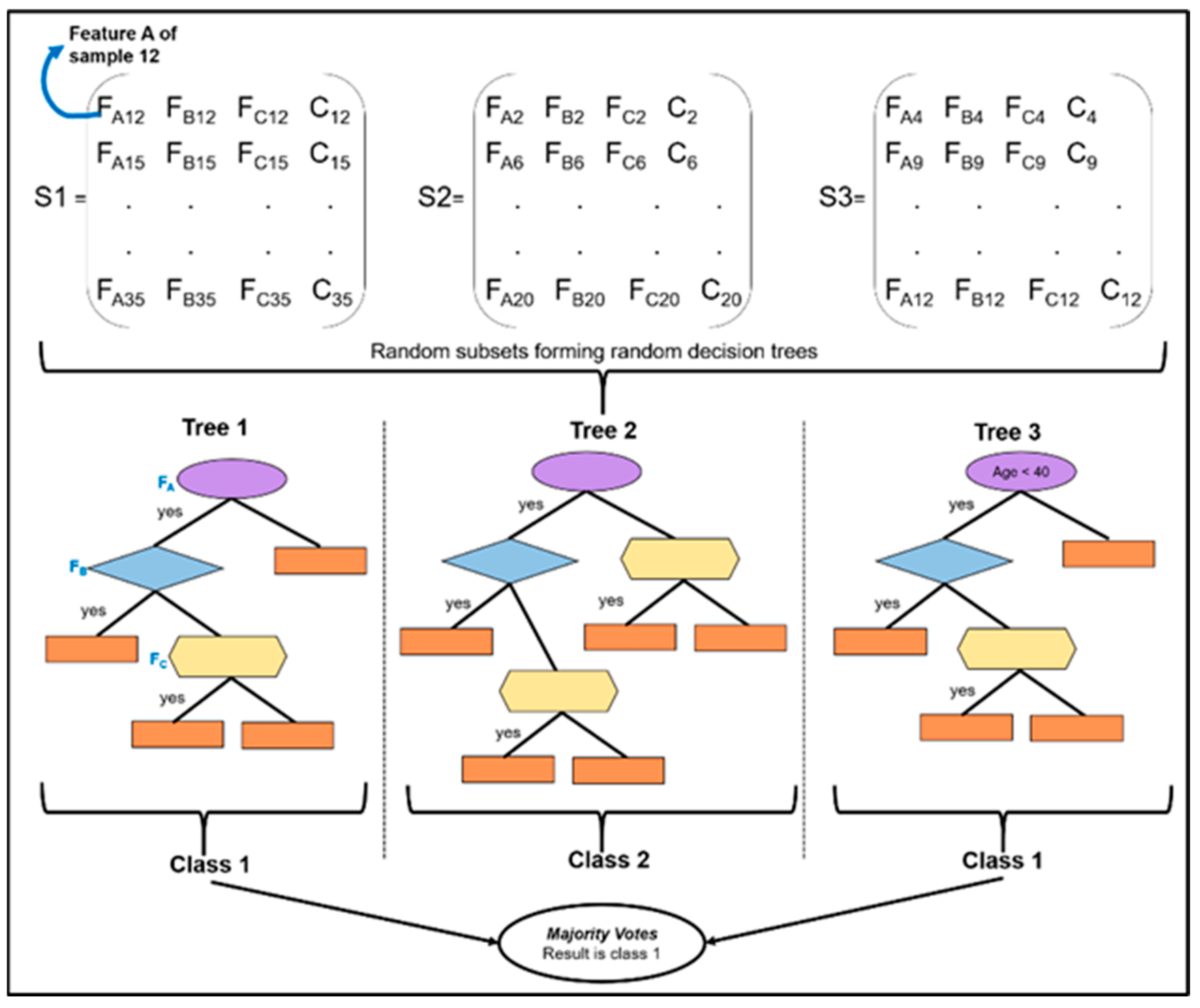
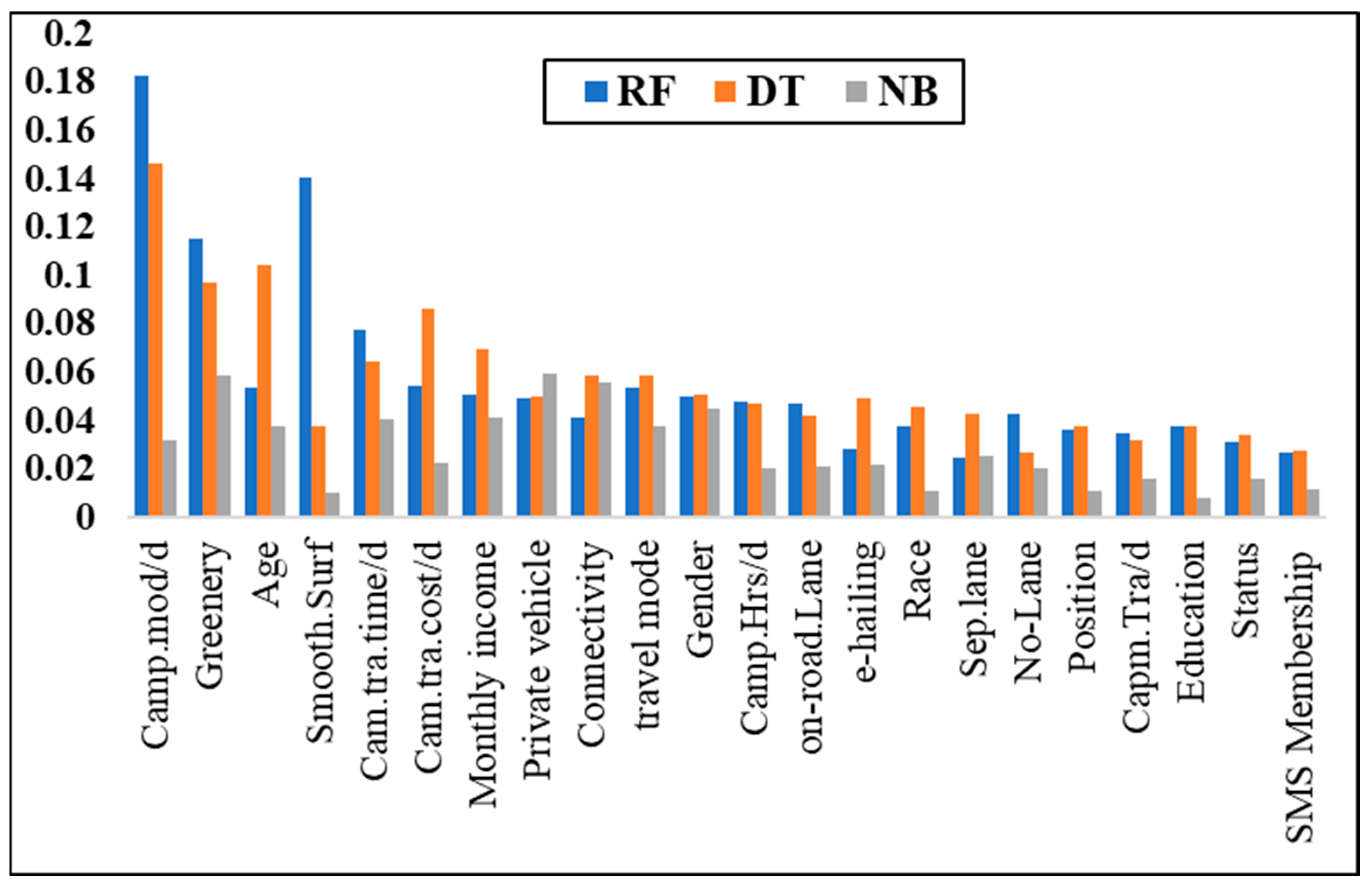
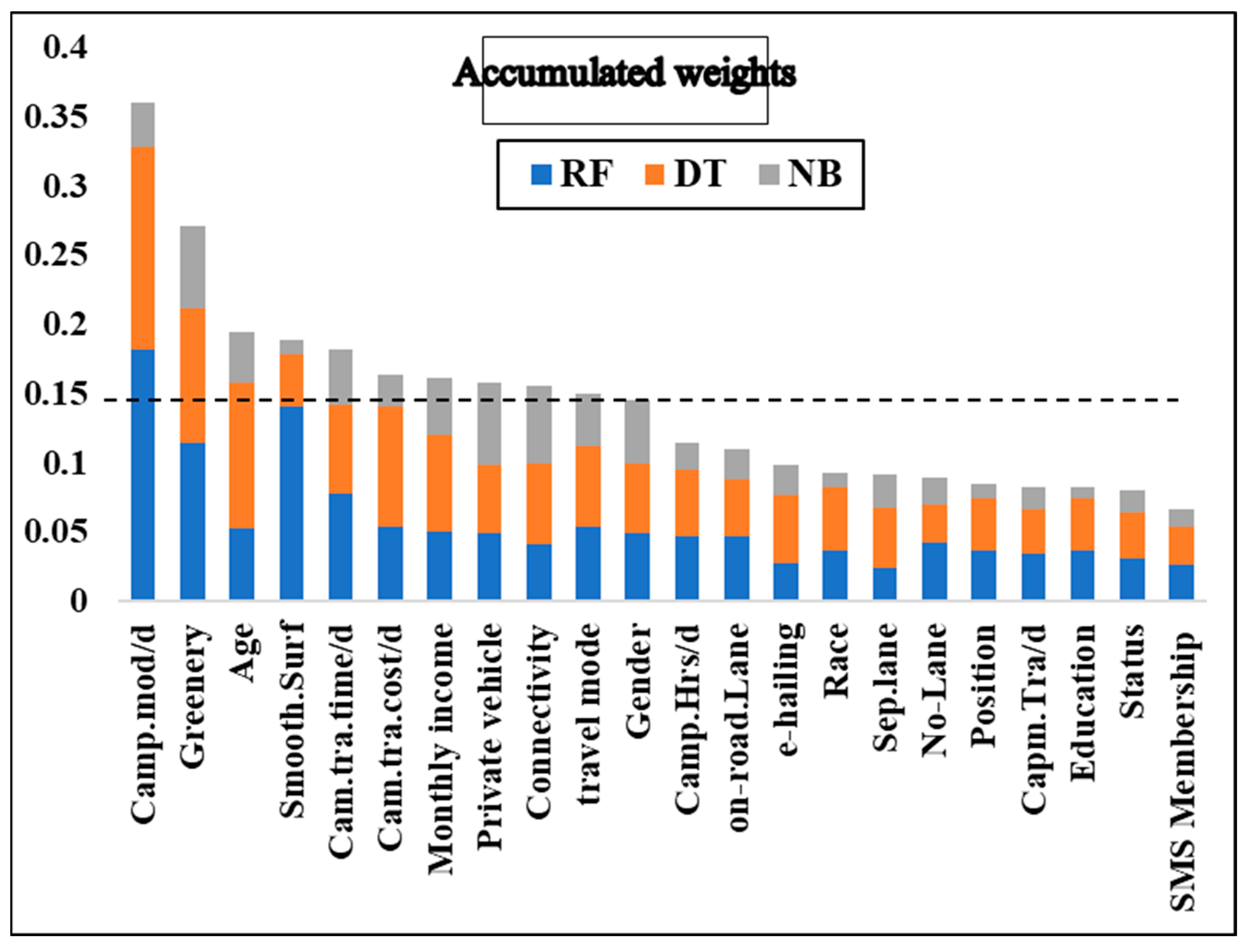
4.4. Selection of Significant Variables Using Supervised Learning Models
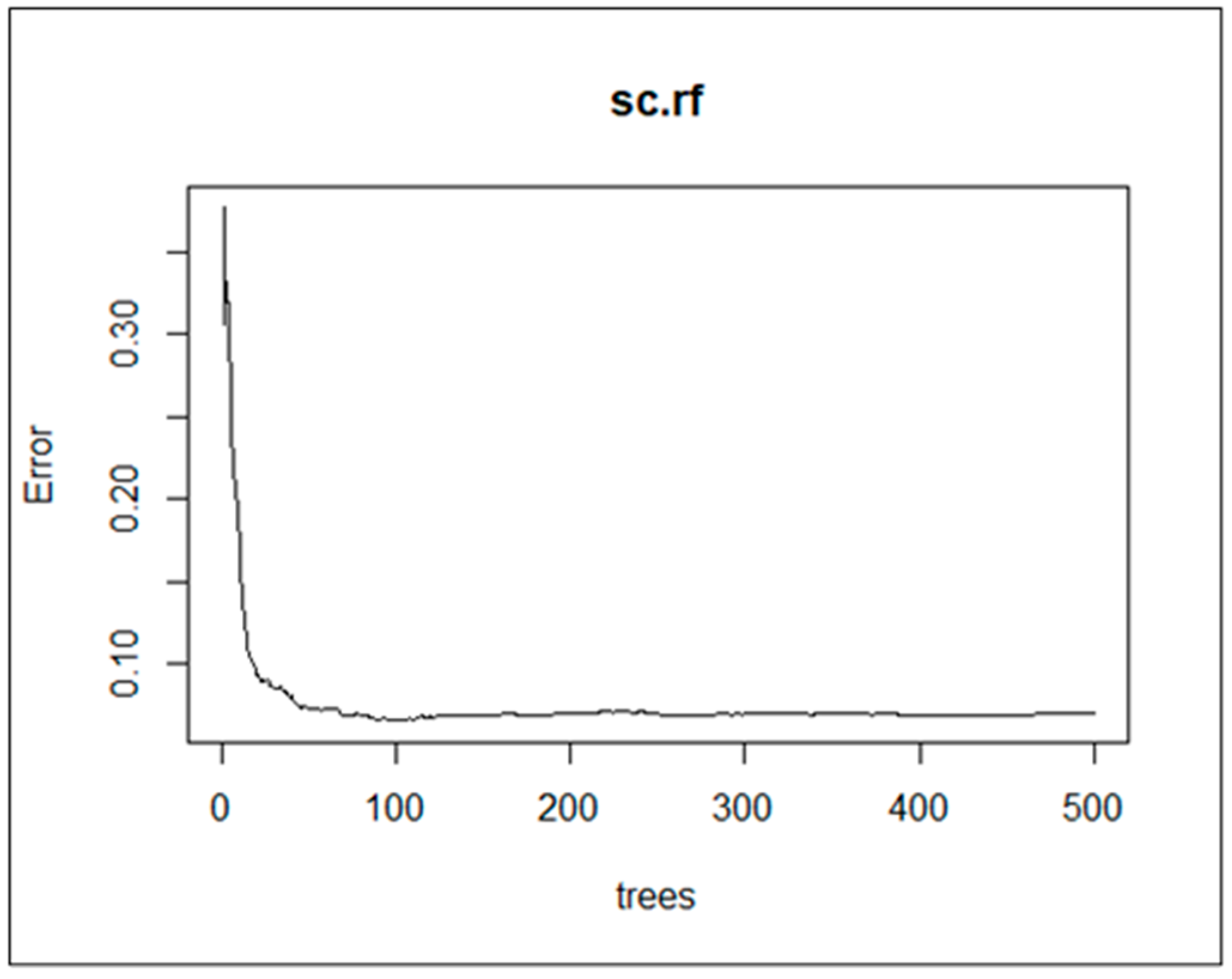
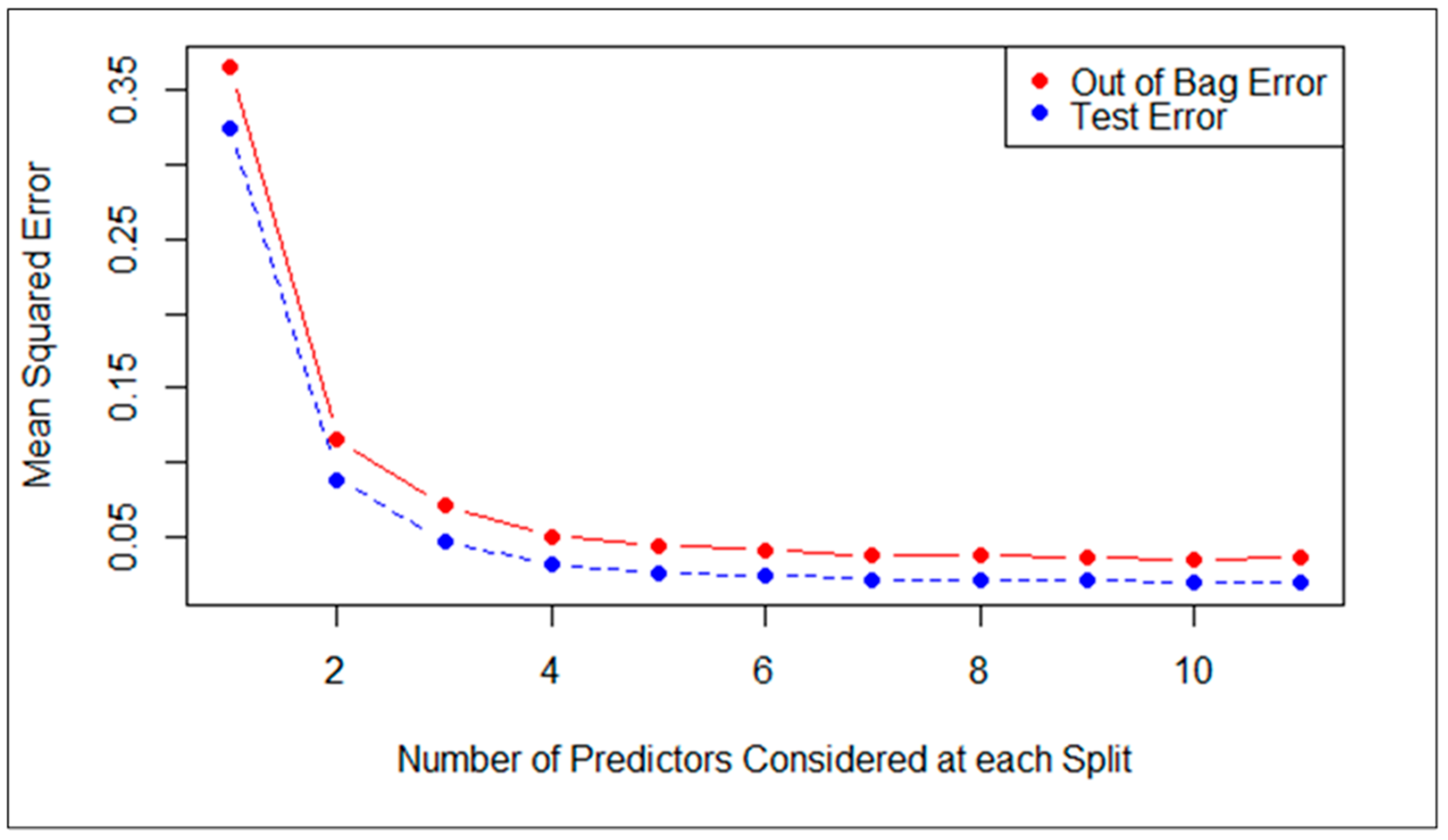
4.5. Model Assessment and Evaluation
- Call:
- Number of trees: 500
- No. of variables tried at each split: 3
- Mean of squared residuals: 0.07049505
- % Var explained: 93.02
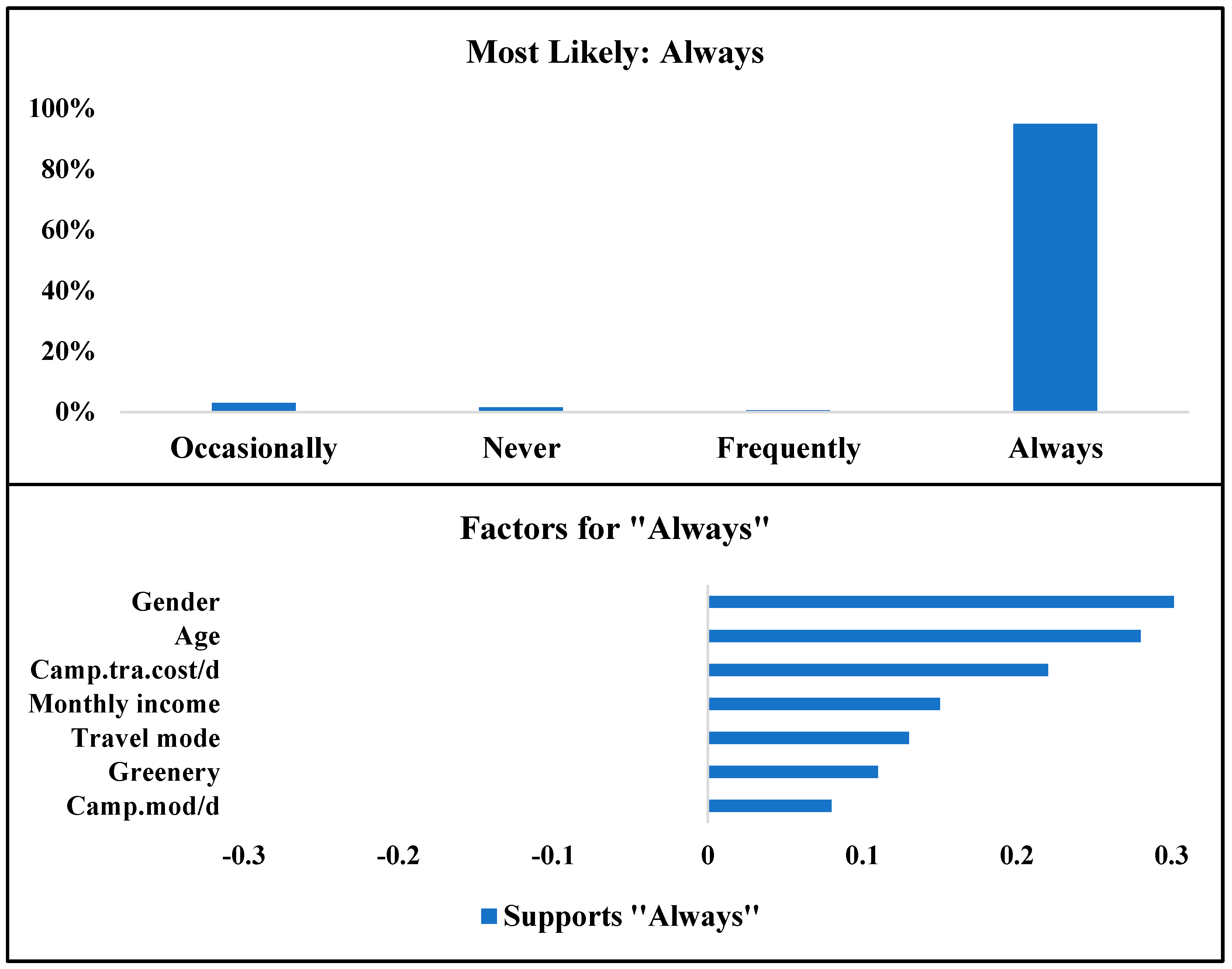
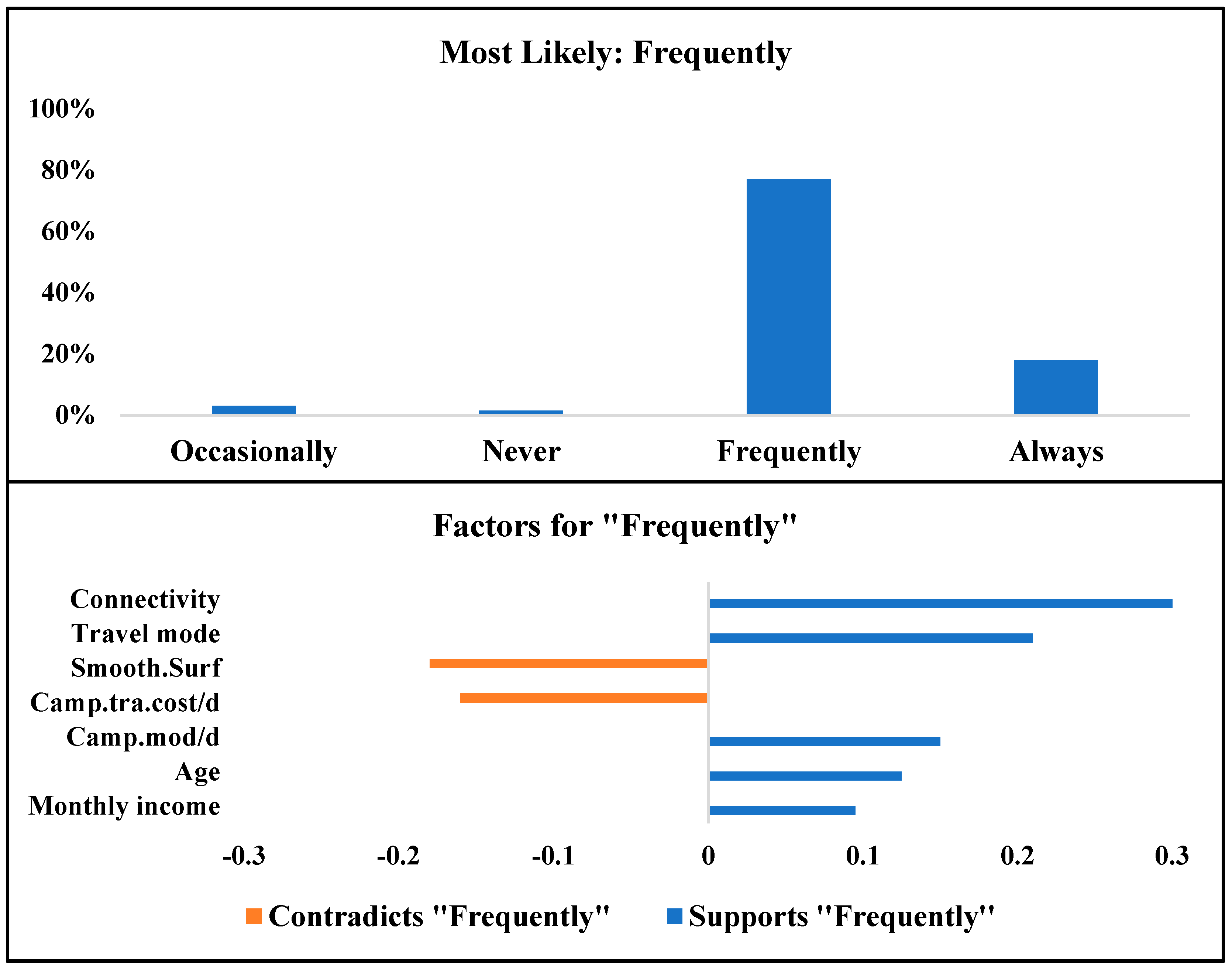
4.6. Simulation-Based Optimization Analysis
5. Discussion
- Shared micromobility is new in Malaysia, and most people have limited knowledge about it. The university community is a natural laboratory to test new mobility services.
- The shared e-scooter companies such as BEAM, TRYKE and Myscooter are very interested in providing their services to university campuses in this initial stage.
- UM is the biggest university in Malaysia, with more than 30,000 students and staff. In addition, more than 5000 international students and staff are on UM campus of different races, ethics, nations and generations. The diversity of the population fits the study requirements well.
Strength, Limitations and Next Steps
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kalda, K.; Pizzagalli, S.-L.; Soe, R.-M.; Sell, R.; Bellone, M. Language of Driving for Autonomous Vehicles. Appl. Sci. 2022, 12, 5406. [Google Scholar] [CrossRef]
- Shaheen, S.; Cohen, A.; Chan, N.; Bansal, A. Sharing strategies: Carsharing, shared micromobility (bikesharing and scooter sharing), transportation network companies, microtransit, and other innovative mobility modes. In Transportation, Land Use, and Environmental Planning; Elsevier: Amsterdam, The Netherlands, 2019; pp. 237–262. [Google Scholar]
- Fitt, H.; Curl, A. The early days of shared micromobility: A social practices approach. J. Transp. Geogr. 2020, 86, 102779. [Google Scholar] [CrossRef]
- Kou, Z.; Wang, X.; Chiu, S.F.A.; Cai, H. Quantifying greenhouse gas emissions reduction from bike share systems: A model considering real-world trips and transportation mode choice patterns. Resour. Conserv. Recycl. 2020, 153, 104534. [Google Scholar] [CrossRef]
- Li, W.; Kamargianni, M. Providing quantified evidence to policy makers for promoting bike-sharing in heavily air-polluted cities: A mode choice model and policy simulation for Taiyuan-China. Transp. Res. Part A Policy Pract. 2018, 111, 277–291. [Google Scholar] [CrossRef]
- Lazarus, J.; Pourquier, J.C.; Feng, F.; Hammel, H.; Shaheen, S. Micromobility evolution and expansion: Understanding how docked and dockless bikesharing models complement and compete–A case study of San Francisco. J. Transp. Geogr. 2020, 84, 102620. [Google Scholar] [CrossRef]
- McKinsey & Co. Sizing the Micro Mobility Market|McKinsey. McKinsey & Co. 2021. Available online: https://www.mckinsey.com/industries/automotive-and-assembly/our-insights/micromobilitys-15000-mile-checkup (accessed on 7 February 2021).
- Berg Insight. The Bike and Scootersharing Telematics Market. 2020, pp. 2–5. Available online: http://www.berginsight.com/ReportPDF/ProductSheet/bi-micromobilitytelematics2-ps.pdf (accessed on 1 March 2020).
- Tuncer, S.; Laurier, E.; Brown, B.; Licoppe, C. Notes on the practices and appearances of e-scooter users in public space. J. Transp. Geogr. 2020, 85, 102702. [Google Scholar] [CrossRef]
- Sgarbossa, F.; Peron, M.; Fragapane, G. Cloud material handling systems: Conceptual model and cloud-based scheduling of handling activities. Int. Ser. Oper. Res. Manag. Sci. 2020, 289, 87–101. [Google Scholar] [CrossRef]
- Lolli, F.; Coruzzolo, A.M.; Peron, M.; Sgarbossa, F. Age-based preventive maintenance with multiple printing options. Int. J. Prod. Econ. 2022, 243, 108339. [Google Scholar] [CrossRef]
- Mont, O.; Palgan, Y.V.; Bradley, K.; Zvolska, L. A decade of the sharing economy: Concepts, users, business and governance perspectives. J. Clean. Prod. 2020, 269, 122215. [Google Scholar] [CrossRef]
- Nguyen-Phuoc, D.Q.; Amoh-Gyimah, R.; Tran, A.T.P.; Phan, C.T. Mode choice among university students to school in Danang, Vietnam. Travel Behav. Soc. 2018, 13, 1–10. [Google Scholar] [CrossRef]
- Rotaris, L.; Danielis, R.; Maltese, I. Carsharing use by college students: The case of Milan and Rome. Transp. Res. Part A Policy Pract. 2019, 120, 239–251. [Google Scholar] [CrossRef]
- Sanders, R.L.; Branion-Calles, M.; Nelson, T.A. To scoot or not to scoot: Findings from a recent survey about the benefits and barriers of using E-scooters for riders and non-riders. Transp. Res. Part A Policy Pract. 2020, 139, 217–227. [Google Scholar] [CrossRef]
- Stylianou, K.; Dimitriou, L.; Abdel-Aty, M. Big data and road safety: A comprehensive review. In Mobility Patterns, Big Data and Transport Analytics; Elsevier: Amsterdam, The Netherlands, 2019; pp. 297–343. [Google Scholar]
- Yang, H.; Song, K.; Zhou, J. Automated Recognition Model of Geomechanical Information Based on Operational Data of Tunneling Boring Machines. Rock Mech. Rock Eng. 2022, 55, 1499–1516. [Google Scholar] [CrossRef]
- Yang, H.; Wang, Z.; Song, K. A new hybrid grey wolf optimizer-feature weighted-multiple kernel-support vector regression technique to predict TBM performance. Eng. Comput. 2020, 38, 2469–2485. [Google Scholar] [CrossRef]
- Du, K.; Liu, M.; Zhou, J.; Khandelwal, M. Investigating the slurry fluidity and strength characteristics of cemented backfill and strength prediction models by developing hybrid GA-SVR and PSO-SVR. Min. Metall. Explor. 2022, 39, 433–452. [Google Scholar] [CrossRef]
- Zhou, J.; Qiu, Y.; Khandelwal, M.; Zhu, S.; Zhang, X. Developing a hybrid model of Jaya algorithm-based extreme gradient boosting machine to estimate blast-induced ground vibrations. Int. J. Rock Mech. Min. Sci. 2021, 145, 104856. [Google Scholar] [CrossRef]
- Zhou, J.; Li, X.; Mitri, H.S. Classification of rockburst in underground projects: Comparison of ten supervised learning methods. J. Comput. Civ. Eng. 2016, 30, 4016003. [Google Scholar] [CrossRef]
- Parsajoo, M.; Armaghani, D.J.; Mohammed, A.S.; Khari, M.; Jahandari, S. Tensile strength prediction of rock material using non-destructive tests: A comparative intelligent study. Transp. Geotech. 2021, 31, 100652. [Google Scholar] [CrossRef]
- Hasanipanah, M.; Monjezi, M.; Shahnazar, A.; Armaghani, D.J.; Farazmand, A. Feasibility of indirect determination of blast induced ground vibration based on support vector machine. Measurement 2015, 75, 289–297. [Google Scholar] [CrossRef]
- Toch, E.; Lerner, B.; Ben-Zion, E.; Ben-Gal, I. Analyzing large-scale human mobility data: A survey of machine learning methods and applications. Knowl. Inf. Syst. 2019, 58, 501–523. [Google Scholar] [CrossRef]
- Xu, C.; Ji, J.; Liu, P. The station-free sharing bike demand forecasting with a deep learning approach and large-scale datasets. Transp. Res. Part C Emerg. Technol. 2018, 95, 47–60. [Google Scholar] [CrossRef]
- Gao, X.; Lee, G.M. Moment-based rental prediction for bicycle-sharing transportation systems using a hybrid genetic algorithm and machine learning. Comput. Ind. Eng. 2019, 128, 60–69. [Google Scholar] [CrossRef]
- Aghaabbasi, M.; Shekari, Z.A.; Shah, M.Z.; Olakunle, O.; Armaghani, D.J.; Moeinaddini, M. Predicting the use frequency of ride-sourcing by off-campus university students through random forest and Bayesian network techniques. Transp. Res. Part A Policy Pract. 2020, 136, 262–281. [Google Scholar] [CrossRef]
- Čuš-Babič, N.; de Oliveira, S.F.G.; Tibaut, A. Interoperability of Infrastructure and Transportation Information Models: A Public Transport Case Study. Appl. Sci. 2022, 12, 6234. [Google Scholar] [CrossRef]
- Bokolo, A.J. Green campus paradigms for sustainability attainment in higher education institutions—A comparative study. J. Sci. Technol. Policy Manag. 2020, 12, 117–148. [Google Scholar] [CrossRef]
- Zakaria, R.; Alqaifi, G.; Rahim, A.; Hamid, A.R.A.; Mansur, S.A.; Resang, A.; Zen, I.S.; Bandi, M.; Khalid, M.S. UTM sustainable living laboratory campus; Are the implementations effective? In Proceedings of the Regional Conference in Engineering Education, Kuala Lumpur, Malaysia, 9–10 August 2016; pp. 1–6. [Google Scholar]
- Humblet, E.M.; Owens, R.; Roy, L.P.; McIntyre, D.; Meehan, P.; Sharp, L. Roadmap to a Green Campus; U.S. Green Building Council: Washington, DC, USA, 2010. [Google Scholar]
- Anthony, J.; Majid, M.A.; Romli, A. Emerging case oriented agents for sustaining educational institutions going green towards environmental responsibility. J. Syst. Inf. Technol. 2019, 21, 186–214. [Google Scholar] [CrossRef]
- Baek, K.; Lee, H.; Chung, J.H.; Kim, J. Electric scooter sharing: How do people value it as a last-mile transportation mode? Transp. Res. Part D Transp. Environ. 2021, 90, 102642. [Google Scholar] [CrossRef]
- Liu, M.; Seeder, S.; Li, H. Analysis of E-scooter trips and their temporal usage patterns. Inst. Transp. Eng. ITE J. 2019, 89, 44–49. [Google Scholar]
- McKenzie, G. Spatiotemporal comparative analysis of scooter-share and bike-share usage patterns in Washington, D.C. J. Transp. Geogr. 2019, 78, 19–28. [Google Scholar] [CrossRef]
- Kowald, M.; Gutjar, M.; Röth, K.; Schiller, C.; Dannewald, T. Mode Choice Effects on Bike Sharing Systems. Appl. Sci. 2022, 12, 4391. [Google Scholar] [CrossRef]
- Eccarius, T.; Lu, C.-C. Adoption intentions for micro-mobility–Insights from electric scooter sharing in Taiwan. Transp. Res. Part D Transp. Environ. 2020, 84, 102327. [Google Scholar] [CrossRef]
- Younes, H.; Zou, Z.; Wu, J.; Baiocchi, G. Comparing the temporal determinants of dockless scooter-share and station-based bike-share in Washington, DC. Transp. Res. Part A Policy Pract. 2020, 134, 308–320. [Google Scholar] [CrossRef]
- Portland Bureau of Transportation. E-Scooter Findings Report. 2018. Available online: https://www.portlandoregon.gov/transportation/article/709719 (accessed on 15 June 2018).
- Denver Dockless Mobility Program. Pilot Interim Report—February 2019. Available online: https://www.denverinc.org/wp-content/uploads/2019/05/Denver-Dockless-Mobility-Update-Feb-2019.pdf (accessed on 1 February 2019).
- The Nunatak Group. New Urban Mobility. 2019. Available online: https://www.nunatak.com/en/topics/new-urban-mobility (accessed on 20 July 2019).
- 6t-Bureau de Recherche. Usages et Usagers des Trottinettes Electriques en Free-Floating en France. 2019. Available online: https://6-t.co/etudes/usages-usagers-trottinettes-ff/ (accessed on 1 February 2019).
- Sarker, I.H.; Colman, A.; Han, J.; Khan, A.I.; Abushark, Y.B.; Salah, K. BehavDT: A behavioral decision tree learning to build user-centric context-aware predictive model. Mob. Netw. Appl. 2019, 25, 1151–1161. [Google Scholar] [CrossRef]
- Toraih, E.A.; Elshazli, R.M.; Hussein, M.H.; Elgaml, A.; Amin, M.; El-Mowafy, M.; El-Mesery, M.; Ellythy, A.; Duchesne, J.; Killackey, M.T.; et al. Association of cardiac biomarkers and comorbidities with increased mortality, severity, and cardiac injury in COVID-19 patients: A meta-regression and decision tree analysis. J. Med. Virol. 2020, 92, 2473–2488. [Google Scholar] [CrossRef]
- Ganggayah, M.D.; Taib, N.A.; Har, Y.C.; Lio, P.; Dhillon, S.K. Predicting factors for survival of breast cancer patients using machine learning techniques. BMC Med. Inform. Decis. Mak. 2019, 4, 48. [Google Scholar] [CrossRef]
- Lu, H.; Ma, X. Hybrid decision tree-based machine learning models for short-term water quality prediction. Chemosphere 2020, 249, 126169. [Google Scholar] [CrossRef] [PubMed]
- Mosca, E.; Alfieri, R.; Merelli, I. A multilevel data integration resource for breast cancer study. BMC Syst. Biol. 2010, 4, 76. [Google Scholar] [CrossRef]
- Genuer, R.; Poggi, J.-M.; Tuleau-Malot, C. VSURF: An R Package for Variable Selection Using Random Forests. R J. 2015, 7, 19–33. [Google Scholar] [CrossRef]
- Lebedev, A.V.; Westman, E.; Van Westen, G.J.P.; Kramberger, M.G.; Lundervold, A.; Aarsland, D.; Soininen, H.; Kloszewska, I.; Mecocci, P.; Tsolaki, M.; et al. Random Forest ensembles for detection and prediction of Alzheimer’s disease with a good between-cohort robustness. NeuroImage Clin. 2014, 6, 115–125. [Google Scholar] [CrossRef]
- Khalilia, M.; Chakraborty, S.; Popescu, M. Predicting disease risks from highly imbalanced data using random forest. BMC Med. Inform. Decis. Mak. 2011, 11, 51. [Google Scholar] [CrossRef]
- Chen, S.; Webb, G.I.; Liu, L.; Ma, X. A novel selective naïve Bayes algorithm. Knowl.-Based Syst. 2020, 192, 105361. [Google Scholar] [CrossRef]
- Ding, S.; Zhao, H.; Zhang, Y.; Xu, X.; Nie, R. Extreme learning machine: Algorithm, theory and applications. Artif. Intell. Rev. 2015, 44, 103–115. [Google Scholar] [CrossRef]
- Tibshirani, R.; Walther, G.; Hastie, T. Estimating the number of clusters in a data set via the gap statistic. J. R. Stat. Soc. Ser. B Stat. Methodol. 2001, 63, 411–423. [Google Scholar] [CrossRef]
- Nidheesh, N.; Nazeer, K.A.A.; Ameer, P.M. A Hierarchical Clustering algorithm based on Silhouette Index for cancer subtype discovery from genomic data. Neural Comput. Appl. 2020, 32, 11459–11476. [Google Scholar] [CrossRef]
- Rai, P. Data clustering: K-means and hierarchical clustering. CS5350 6350 Mach. Learn. Oct. 2011, 4, 24. [Google Scholar]
- Raschka, S. Model Evaluation, Model Selection, and Algorithm Selection in Machine Learning. arXiv 2018, arXiv:1811.12808. [Google Scholar]
- Ramli, N.A.; Zen, I.S.; Bandi, M.; Tajuddin, H.A. Reduction in carbon dioxide emissions and global climate in campus: From policy into action. In Proceedings of the 2nd International Conference on Emerging Trends in Scientific Research, Kuala Lumpur, Malaysia, 1–2 November 2014; pp. 1–23. [Google Scholar]
- Nejati, M.; Nejati, M. Assessment of sustainable university factors from the perspective of university students. J. Clean. Prod. 2013, 48, 101–107. [Google Scholar] [CrossRef]
- Taghavi, M.; Bakhtiyari, K.; Taghavi, H.; Attar, V.O.; Hussain, A. Planning for sustainable development in the emerging information societies. J. Sci. Technol. Policy Manag. 2014, 5, 178–211. [Google Scholar] [CrossRef]
- Foo, K.Y. A vision on the role of environmental higher education contributing to the sustainable development in Malaysia. J. Clean. Prod. 2013, 61, 6–12. [Google Scholar] [CrossRef]
- Junior, B.A.; Majid, M.A.; Romli, A. Green information technology for sustainability elicitation in government-based organisations: An exploratory case study. Int. J. Sustain. Soc. 2018, 10, 20–41. [Google Scholar] [CrossRef]
- Abdul-Azeez, I.A.; Ho, C.S. Realizing low carbon emission in the university campus towards energy sustainability. Open J. Energy Effic. 2015, 4, 15. [Google Scholar] [CrossRef]
- Azlin, A.Z.B.; Er, A.C.; Rahman, N.B.A.; Alam, A.S.A. Consumers’ roles and practices towards sustainable UKM campus. Int. J. Adv. Appl. Sci. 2016, 3, 30–34. [Google Scholar]
- Peter, C.J.; Libunao, W.H.; Latif, A.A. Extent of education for sustainable development (ESD) integration in Malaysian community colleges. J. Tech. Educ. Train. 2016, 8, 1–13. [Google Scholar]
- Junior, B.A. A retrospective study on green ICT deployment for ecological protection pedagogy: Insights from field survey. World Rev. Sci. Technol. Sustain. Dev. 2019, 15, 17–45. [Google Scholar] [CrossRef]
- Hardt, C.; Bogenberger, K. Usage of e-Scooters in Urban Environments. Transp. Res. Procedia 2019, 37, 155–162. [Google Scholar] [CrossRef]
- Laa, B.; Leth, U. Survey of E-scooter users in Vienna: Who they are and how they ride. J. Transp. Geogr. 2020, 89, 102874. [Google Scholar] [CrossRef]
- Gössling, S. Integrating e-scooters in urban transportation: Problems, policies, and the prospect of system change. Transp. Res. Part D Transp. Environ. 2020, 79, 102230. [Google Scholar] [CrossRef]
- Willmott, A.G.B.; Maxwell, N.S. The metabolic and physiological responses to scootering exercise in a field-setting. J. Transp. Health 2019, 13, 26–32. [Google Scholar] [CrossRef]
- De Bortoli, A.; Christoforou, Z. Consequential LCA for territorial and multimodal transportation policies: Method and application to the free-floating e-scooter disruption in Paris. J. Clean. Prod. 2020, 273, 122898. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Description | Values |
|---|---|---|
| Sociodemographic | ||
| Age | Age | (1) 18 to 29; (2) 30 to 44; (3) 45 to 60; (4) Over 60 |
| Gender | Gender | (1) Male; (2) Female |
| Education | Highest education level | (1) Secondary; (2) Diploma; (3) Bachelor’s degree; (4) Master’s degree; (5) Doctorate degree |
| Position | Job position | (1) Undergraduate student; (2) Postgraduate student; (3) Academic staff; (4) Non-academic staff |
| Status | Employment/education status | (1) Full-time; (2) Part-time |
| Race | Race | (1) Chinese; (2) Malay; (3) Indian; (4) Other |
| Monthly Income | Monthly household income | (1) Less than RM 2000; (2) Between RM 2000 RM 4000; (3) Between RM 4000 and RM 6000; (4) Between RM 6000 and RM 12,000; (5) More than RM 12,000 |
| Private vehicle | Private vehicle ownership | (1) Yes; (2) No |
| E-hailing | Usage of e-hailing services per week | (1) Not using at all; (2) Less than 3 times; (3) 3 to 6 times; (4) More than 6 times |
| SMS Membership | Membership of shared mobility services | (1) Yes; (2) No |
| Travel characterization | ||
| Travel mode | Usual travel mode for going to campus | (1) E-hailing taxi; (2) Private car; (3) Private motorcycle; (4) Public transportation; (5) Walking/cycling |
| Camp.Hrs/d | Hours usually spent on the campus per day | (1) 1 to 3 h; (2) 3 to 5 h; (3) 5 to 8 h; (4) More than 8 h |
| Camp.Tra/d | Number of journeys onto or to outside of the campus per day | (1) Less than 2 journeys; (2) 2 to 4 journeys; (3) 4 to 6 journeys; (4) More than 6 journeys |
| Camp.mod/d | Travel mode on the campus | (1) E-hailing taxi; (2) Private car; (3) Private motorcycle; (4) Public transportation; (5) Walking/cycling |
| Camp.tra.time/d | Duration of daily travel on the campus | (1) Less than 10 min; (2) 10 to 20 min; (3) 20 to 30 min; (4) More than 30 min |
| Camp.tra.cost/d | Daily travel cost on the campus | (1) Less than RM 5; (2) Between RM 5 and RM15; (3) Between RM15 and RM 25; (4) More than RM25 |
| Attitudinal factors: impact of infrastructure | ||
| Sep.lane | Bike/scooter lane separate from road traffic | (1) Strongly discourage; (2) Discourage; (3) Encourage; (4) Strongly encourage |
| On-road.Lane | Bike/scooter lane on the road with traffic | (1) Strongly discourage; (2) Discourage; (3) Encourage; (4) Strongly encourage |
| No-Lane | Road with no bike/scooter lane | (1) Strongly discourage; (2) Discourage; (3) Encourage; (4) Strongly encourage |
| Greenery | Green Space (e.g., road-side trees, greenery, water) | (1) Strongly discourage; (2) Discourage; (3) Encourage; (4) Strongly encourage |
| Smooth.Surf | A smooth road surface | (1) Strongly discourage; (2) Discourage; (3) Encourage; (4) Strongly encourage |
| Connectivity | Pathways/roads connectivity | (1) Strongly discourage; (2) Discourage; (3) Encourage; (4) Strongly encourage |
| e-scooter Usage (Target variable) | Shared e-scooter frequency of usage | (1) Not using at all; (2) Sometimes/infrequently; (3) Frequently; (4) Regularly as the main mode of transport. |
| Socio-Demographics | Total Sample (n = 1000) | UM University | All Universities in Malaysia |
|---|---|---|---|
| Gender | |||
| Male | 45.6 | 49.0 | 47.0 |
| Female | 54.4 | 51.0 | 53.0 |
| Occupation | |||
| Undergraduate students | 51.5 | 51.7 | 48.5 |
| Graduate students | 36.5 | 27.6 | 33.5 |
| Part-time graduate students | 2.1 | 6.3 | 6.3 |
| Faculty and staff | 9.9 | 16.3 | 11.7 |
| RF | DT | NB | ||||
|---|---|---|---|---|---|---|
| No. | Attribute | Weight | Attribute | Weight | Attribute | Weight |
| 1 | Camp.mod/d | 0.1825 | Camp.mod/d | 0.14634 | Private vehicle | 0.059752 |
| 2 | Smooth.Surf | 0.1409 | Age | 0.10431 | Greenery | 0.058748 |
| 3 | Greenery | 0.1151 | Greenery | 0.09712 | Connectivity | 0.056134 |
| 4 | Cam.tra.time/d | 0.0777 | Cam.tra.cost/d | 0.08648 | Gender | 0.04504 |
| 5 | Cam.tra.cost/d | 0.0547 | Monthly income | 0.06964 | Monthly income | 0.041161 |
| 6 | Travel mode | 0.0538 | Cam.tra.time/d | 0.06434 | Cam.tra.time/d | 0.040235 |
| 7 | Age | 0.0534 | Travel mode | 0.0588 | Travel mode | 0.037877 |
| 8 | Monthly income | 0.0509 | Connectivity | 0.05861 | Age | 0.037555 |
| 9 | Gender | 0.0498 | Gender | 0.05055 | Camp.mod/d | 0.032029 |
| 10 | Private vehicle | 0.0490 | Private vehicle | 0.04992 | Sep.lane | 0.025078 |
| 11 | Camp.Hrs/d | 0.0477 | e-hailing | 0.04938 | Cam.tra.cost/d | 0.022726 |
| 12 | on-road.Lane | 0.0469 | Camp.Hrs/d | 0.04726 | e-hailing | 0.021732 |
| 13 | No-Lane | 0.0429 | Race | 0.0454 | on-road.Lane | 0.021263 |
| 14 | Connectivity | 0.0415 | Sep.lane | 0.04247 | No-Lane | 0.020533 |
| 15 | Race | 0.0376 | on-road.Lane | 0.04189 | Camp.Hrs/d | 0.019974 |
| 16 | Education | 0.0374 | Position | 0.03798 | Capm.Tra/d | 0.016223 |
| 17 | Position | 0.0366 | Smooth.Surf | 0.03751 | Status | 0.015691 |
| 18 | Capm.Tra/d | 0.0351 | Education | 0.0374 | SMS Membership | 0.011859 |
| 19 | Status | 0.0308 | Status | 0.03386 | Position | 0.010624 |
| 20 | e-hailing | 0.0280 | Capm.Tra/d | 0.03175 | Race | 0.010495 |
| 21 | SMS membership | 0.0268 | SMS Membership | 0.02767 | Smooth.Surf | 0.010309 |
| 22 | Sep.lane | 0.0248 | No-Lane | 0.02676 | Education | 0.0082 |
| No. | Attribute | Accumulated Weight | Mean Decrease Gini |
|---|---|---|---|
| 1 | Camp.mod/d | 0.360867959 | 72.26206 |
| 2 | Greenery | 0.270941347 | 62.26634 |
| 3 | Age | 0.195234017 | 61.92460 |
| 4 | Smooth.Surf | 0.188729931 | 60.28623 |
| 5 | Cam.tra.time/d | 0.182241979 | 59.64285 |
| 6 | Cam.tra.cost/d | 0.16393153 | 57.96135 |
| 7 | Monthly income | 0.161725573 | 57.71634 |
| 8 | Private vehicle | 0.158708056 | 53.55493 |
| 9 | Connectivity | 0.156257276 | 51.93130 |
| 10 | Travel mode | 0.150511383 | 44.97282 |
| 11 | Gender | 0.145347998 | 44.94371 |
| No | Number of Trees | Accuracy (%) |
|---|---|---|
| 1 | 390 | 93.42 |
| 2 | 400 | 93.26 |
| 3 | 410 | 93.28 |
| 4 | 420 | 93.19 |
| 5 | 430 | 93.29 |
| 6 | 440 | 93.51 |
| 7 | 450 | 93.14 |
| 8 | 460 | 93.15 |
| 9 | 470 | 93.28 |
| Model | Algorithm | Accuracy (%) | Precision | Recall | F1 Score | ||||
|---|---|---|---|---|---|---|---|---|---|
| 11 Variable | 22 Variable | 11 Variable | 22 Variable | 11 Variable | 22 Variable | 11 Variable | 22 Variable | ||
| Decision tree | rpart from “caret” | 54.13 | 57.130 | 0.29 | 0.318 | 0.38 | 0.4000 | 0.32 | 0.325 |
| Random Forest | rf from “caret” | 93.51 | 99.49 | 0.85 | 0.890 | 0.82 | 0.850 | 0.72 | 0.760 |
| Naïve Bayes | nb from “e1071” package | 61.00 | 64.50 | 0.51 | 0.530 | 0.45 | 0.480 | 0.52 | 0.540 |
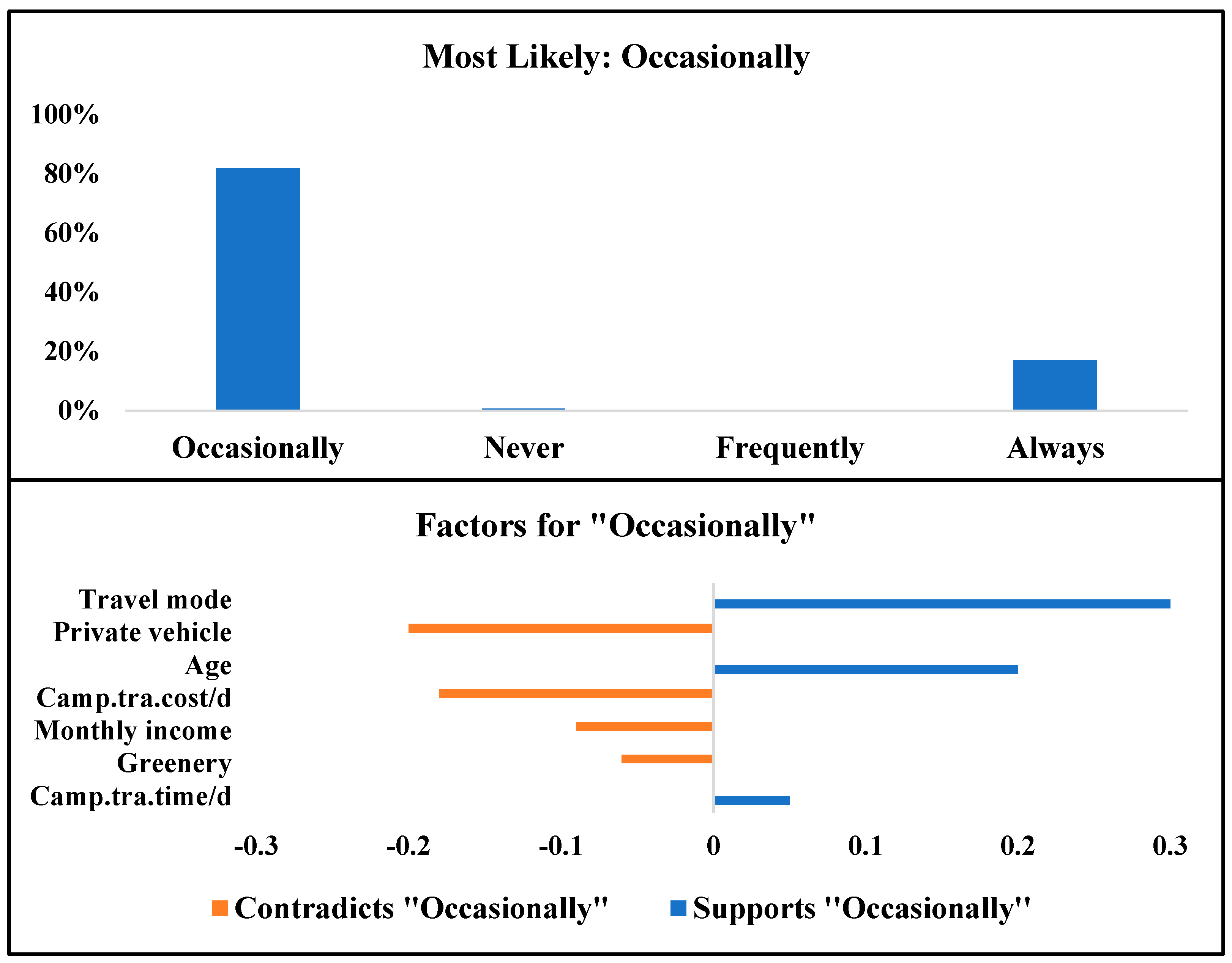
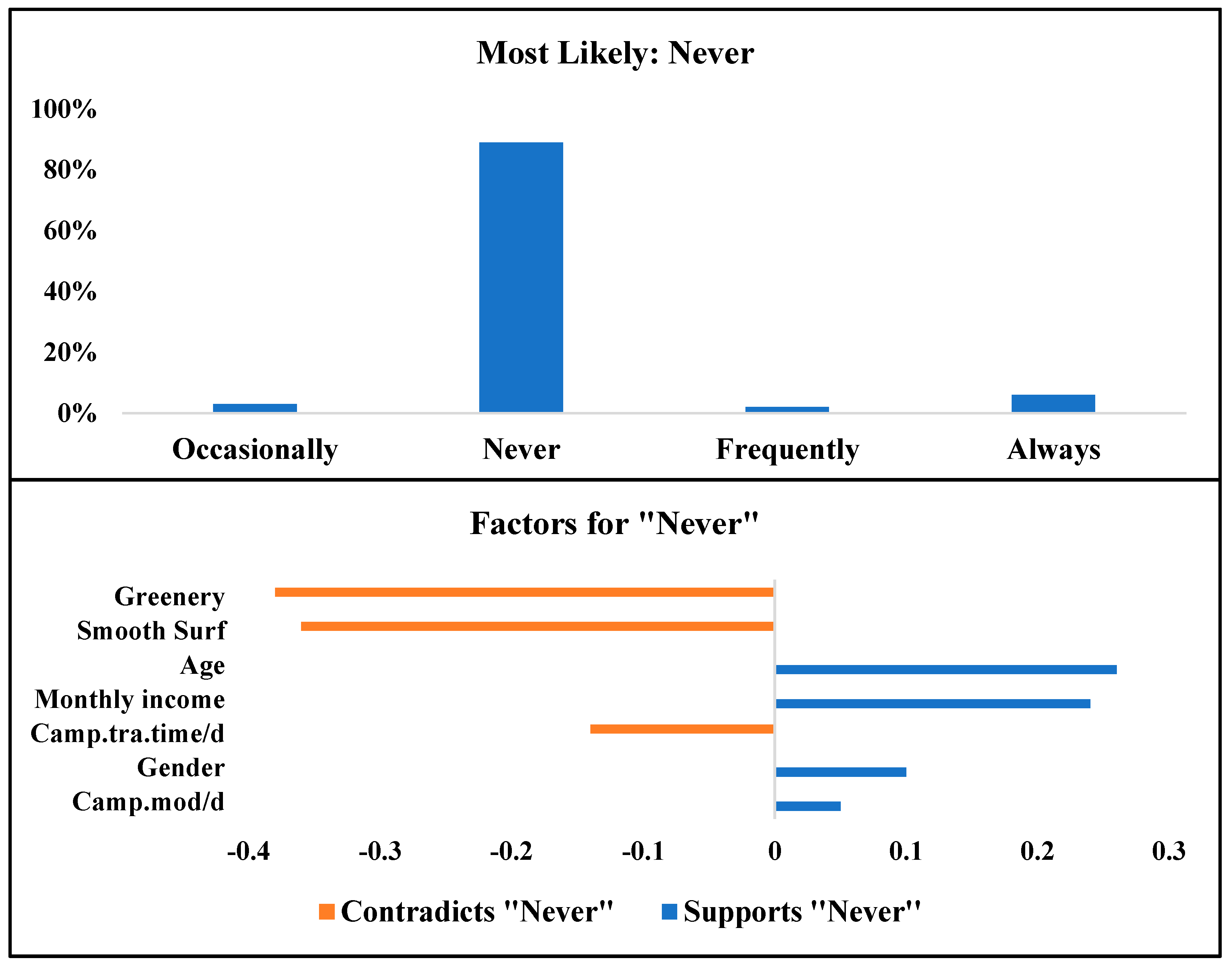
| Attribute | Always | Frequently | Occasionally | Never |
|---|---|---|---|---|
| Gender | Female | Female | Male | Male |
| Age | 18 to 29 | 30 to 44 | 45 to 60 | 45 to 60 |
| Monthly income | Between RM 4000 and RM 6000 | Between RM 6000 and RM 12,000 | Between RM 2000 RM 4000 | Between RM 6000 and RM 12,000 |
| Travel mode | Walking/cycling | Public transportation | Private car | Private car |
| Private vehicle | No | Yes | Yes | Yes |
| Camp.mod/d | Walking/cycling | E-hailing | Public Transport | Private car |
| Cam.tra.cost/d | Between RM 5 and RM15 | Between RM 15 and RM 25 | Less than RM 5 | Less than RM 5 |
| Cam.tra.time/d | 20 to 30 min | Less than 10 min | 10 to 20 min | Less than 10 min |
| Greenery | Encourage | Strongly encourage | Strongly discourage | Encourage |
| Smooth.Surf | Encourage | Discourage | Encourage | Encourage |
| Connectivity | Encourage | Encourage | Discourage | Encourage |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moosavi, S.M.H.; Ma, Z.; Armaghani, D.J.; Aghaabbasi, M.; Ganggayah, M.D.; Wah, Y.C.; Ulrikh, D.V. Understanding and Predicting the Usage of Shared Electric Scooter Services on University Campuses. Appl. Sci. 2022, 12, 9392. https://doi.org/10.3390/app12189392
Moosavi SMH, Ma Z, Armaghani DJ, Aghaabbasi M, Ganggayah MD, Wah YC, Ulrikh DV. Understanding and Predicting the Usage of Shared Electric Scooter Services on University Campuses. Applied Sciences. 2022; 12(18):9392. https://doi.org/10.3390/app12189392
Chicago/Turabian StyleMoosavi, Seyed Mohammad Hossein, Zhenliang Ma, Danial Jahed Armaghani, Mahdi Aghaabbasi, Mogana Darshini Ganggayah, Yuen Choon Wah, and Dmitrii Vladimirovich Ulrikh. 2022. "Understanding and Predicting the Usage of Shared Electric Scooter Services on University Campuses" Applied Sciences 12, no. 18: 9392. https://doi.org/10.3390/app12189392
APA StyleMoosavi, S. M. H., Ma, Z., Armaghani, D. J., Aghaabbasi, M., Ganggayah, M. D., Wah, Y. C., & Ulrikh, D. V. (2022). Understanding and Predicting the Usage of Shared Electric Scooter Services on University Campuses. Applied Sciences, 12(18), 9392. https://doi.org/10.3390/app12189392