

Code-Switching in Automatic Speech Recognition: The Issues and Future Directions

 ,
,
Abstract
:1. Introduction
2. Research Background
2.1. Existing Reviews of Automatic Speech Recognition Systems
2.2. CS in Bilingual and Multilingual Speech Recognition Systems
3. Research Aim and Approach
3.1. Formulation of Research Questions
3.2. Search Methodology
- −
- Science Direct;
- −
- IEEE Explore Digital Library;
- −
- Springer Link;
- −
- Google Scholar.
- −
- multilingual speech recognition;
- −
- bilingual speech recognition;
- −
- code-switching.
- −
- Search domain: Science, technology or computer science;
- −
- Types of publication: Journals, proceedings, and transactions;
- −
- Article type: Full text;
- −
- Language: English.
- −
- Papers that do not focus explicitly on bilingual and multilingual speech recognition.
- −
- Papers that discuss bilingual and multilingual speech recognition as a side topic.
- −
- Papers with no details of experiments or experimental design.
- −
- The full text of the paper is not available (physical and electronic forms).
- −
- Opinions, viewpoints, keynotes, discussions, editorials, tutorials, comments, prefaces, anecdotal papers and presentations in slide format without any associated papers.
3.3. Search Outcome and Analysis
4. Results of Review
4.1. Research Question 1: What Issues Affect the Recognition Performance of CS ASR Systems in Bilingual and Multilingual Settings?
- Database Sparsity
- Recognising CS
4.2. Research Question 2: What Is the Direction in the Development of CS ASR in Terms of Focus, Databases, Acoustics and Language Modelling, and Evaluation Metrics?
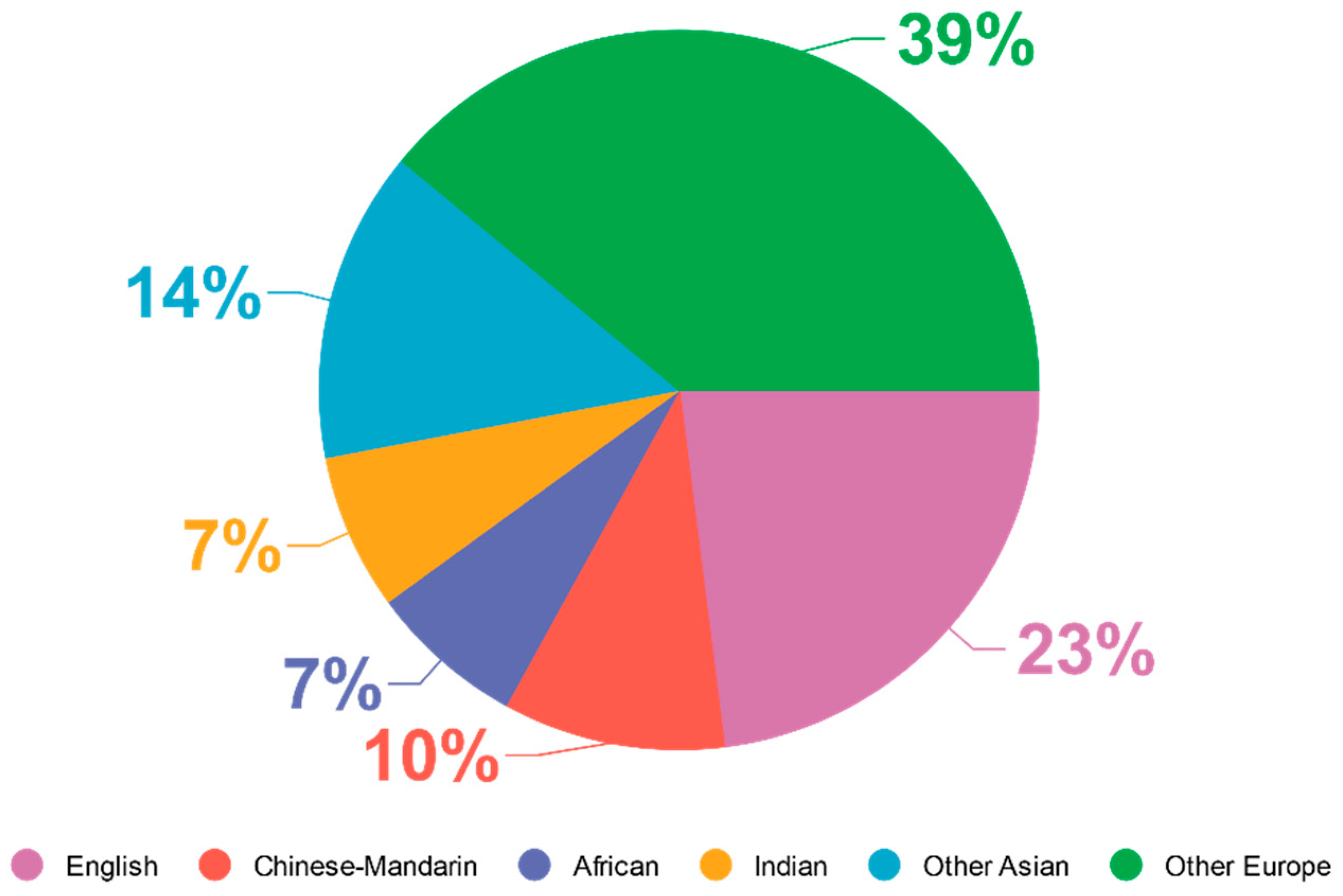
4.2.1. Databases
4.2.2. Acoustic and Language Modelling
- Combining
- Merging
- Mapping
- Other techniques
4.2.3. Evaluation Metrics
5. Discussion
6. Conclusions
7. Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Al-Qatab, B.A.; Mustafa, M.B. Classification of Dysarthric Speech According to the Severity of Impairment: An Analysis of Acoustic Features. IEEE Access 2021, 9, 18183–18194. [Google Scholar] [CrossRef]
- Modipa, T.I.; Davel, M.H. Predicting vowel substitution in code-switched speech. In Proceedings of the Pattern Recognition Association of South Africa and Robotics and Mechatronics International Conference (PRASA-RobMech), Port Elizabeth, South Africa, 26–27 November 2015. [Google Scholar]
- Shen, H.-P.; Wu, C.-H.; Yang, Y.-T.; Hsu, C.-S. CECOS: A Chinese-English code-switching speech database. In Proceedings of the International Conference on Speech Database and Assessments (Oriental COCOSDA), Hsinchu, Taiwan, 26–28 October 2011. [Google Scholar]
- Yılmaz, E.; van den Heuvel, H.; Van Leeuwen, D. Code-switching detection using multilingual DNNs. In Proceedings of the IEEE Spoken Language Technology Workshop (SLT), San Diego, CA, USA, 13–16 December 2016. [Google Scholar]
- Yue, X.; Lee, G.; Yılmaz, E.; Deng, F.; Li, H. End-to-end code-switching ASR for low-resourced language pairs. In Proceedings of the IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019. [Google Scholar]
- Nakayama, S.; Tjandra, A.; Sakti, S.; Nakamura, S. Speech chain for semi-supervised learning of Japanese-English code-switching ASR and TTS. In Proceedings of the IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018. [Google Scholar]
- Alharbi, S.; Alrazgan, M.; Alrashed, A.; AlNomasi, T.; Almojel, R.; Alharbi, R.; Alharbi, S.; Alturki, S.; Alshehri, F.; Almojil, M. Automatic speech recognition: Systematic literature review. IEEE Access 2021, 9, 131858–131876. [Google Scholar] [CrossRef]
- Bell, P.; Fainberg, J.; Klejch, O.; Li, J.; Renals, S.; Swietojanski, P. Adaptation algorithms for neural network-based speech recognition: An overview. IEEE Open J. Signal Process. 2020, 2, 33–66. [Google Scholar] [CrossRef]
- Desai, N.; Dhameliya, K.; Desai, V. Feature extraction and classification techniques for speech recognition: A review. Int. J. Emerg. Technol. Adv. Eng. 2013, 3, 367–371. [Google Scholar]
- Sarma, M.; Sarma, K.K. Acoustic modeling of speech signal using artificial neural network: A review of techniques and current trends. In Intelligent Applications for Heterogeneous System Modeling and Design; IGI Global: Hershey, PA, USA, 2015; pp. 282–299. [Google Scholar]
- Errattahi, R.; El Hannani, A.; Ouahmane, H. Automatic speech recognition errors detection and correction: A review. Procedia Comput. Sci. 2018, 128, 32–37. [Google Scholar] [CrossRef]
- Padmanabhan, J.; Johnson Premkumar, M.J. Machine learning in automatic speech recognition: A survey. IETE Tech. Rev. 2015, 32, 240–251. [Google Scholar] [CrossRef]
- Deng, L.; Li, X. Machine learning paradigms for speech recognition: An overview. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 1060–1089. [Google Scholar] [CrossRef]
- Li, J.; Deng, L.; Gong, Y.; Haeb-Umbach, R. An overview of noise-robust automatic speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 745–777. [Google Scholar] [CrossRef]
- Wang, D.; Wang, X.; Lv, S. An overview of end-to-end automatic speech recognition. Symmetry 2019, 11, 1018. [Google Scholar] [CrossRef]
- de Lima, T.A.; Da Costa-Abreu, M. A survey on automatic speech recognition systems for Portuguese language and its variations. Comput. Speech Lang. 2020, 62, 101055. [Google Scholar] [CrossRef]
- Singh, A.; Kadyan, V.; Kumar, M.; Bassan, N. ASRoIL: A comprehensive survey for automatic speech recognition of Indian languages. Artif. Intell. Rev. 2020, 53, 3673–3704. [Google Scholar] [CrossRef]
- Ghai, W.; Singh, N. Literature review on automatic speech recognition. Int. J. Comput. Appl. 2012, 41, 42–50. [Google Scholar] [CrossRef]
- Aldarmaki, H.; Ullah, A.; Ram, S.; Zaki, N. Unsupervised automatic speech recognition: A review. Speech Commun. 2022, 139, 76–91. [Google Scholar] [CrossRef]
- Anusuya, M.; Katti, S. Front end analysis of speech recognition: A review. Int. J. Speech Technol. 2011, 14, 99–145. [Google Scholar] [CrossRef]
- Arora, S.J.; Singh, R.P. Automatic speech recognition: A review. Int. J. Comput. Appl. 2012, 60, 34–44. [Google Scholar]
- Cutajar, M.; Gatt, E.; Grech, I.; Casha, O.; Micallef, J. Comparative study of automatic speech recognition techniques. IET Signal Process. 2013, 7, 25–46. [Google Scholar] [CrossRef]
- Karpagavalli, S.; Chandra, E. A review on automatic speech recognition architecture and approaches. Int. J. Signal Process. Image Process. Pattern Recognit. 2016, 9, 393–404. [Google Scholar]
- Young, V.; Mihailidis, A. Difficulties in automatic speech recognition of dysarthric speakers and implications for speech-based applications used by the elderly: A literature review. Assist. Technol. 2010, 22, 99–112. [Google Scholar] [CrossRef]
- Sitaram, S.; Chandu, K.R.; Rallabandi, S.K.; Black, A.W. A survey of code-switched speech and language processing. arXiv 2019, arXiv:1904.00784. [Google Scholar]
- Nakayama, S.; Tjandra, A.; Sakti, S.; Nakamura, S. Zero-shot code-switching ASR and TTS with multilingual machine speech chain. In Proceedings of the IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019. [Google Scholar]
- Chen, Y.-C.; Hsu, J.-Y.; Lee, C.-K.; Lee, H.-Y. DARTS-ASR: Differentiable architecture search for multilingual speech recognition and adaptation. arXiv 2020, arXiv:2005.07029. [Google Scholar]
- Biswas, A.; Yılmaz, E.; De Wet, F.; van der Westhuizen, E.; Niesler, T. Semi-supervised development of ASR systems for multilingual code-switched speech in under-resourced languages. arXiv 2020, arXiv:2003.03135. [Google Scholar]
- Du, C.; Li, H.; Lu, Y.; Wang, L.; Qian, Y. Data augmentation for end-to-end code-switching speech recognition. In Proceedings of the IEEE Spoken Language Technology Workshop (SLT), Shenzhen, China, 19–22 January 2021. [Google Scholar]
- Emond, J.; Ramabhadran, B.; Roark, B.; Moreno, P.; Ma, M. Transliteration-based approaches to improve code-switched speech recognition performance. In Proceedings of the IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018. [Google Scholar]
- Hara, S.; Nishizaki, H. Acoustic modeling with a shared phoneme set for multilingual speech recognition without code-switching. In Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017. [Google Scholar]
- Huang, Z.; Li, P.; Xu, J.; Zhang, P.; Yan, Y. Context-dependent Label Smoothing Regularization for Attention-based End-to-End Code-Switching Speech Recognition. In Proceedings of the 12th International Symposium on Chinese Spoken Language Processing (ISCSLP), Hong Kong, China, 24–27 January 2021. [Google Scholar]
- Imseng, D.; Bourlard, H.; Garner, P.N. Using KL-divergence and multilingual information to improve ASR for under-resourced languages. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012. [Google Scholar]
- Kannan, A.; Datta, A.; Sainath, T.N.; Weinstein, E.; Ramabhadran, B.; Wu, Y.; Bapna, A.; Chen, Z.; Lee, S. Large-scale multilingual speech recognition with a streaming end-to-end model. arXiv 2019, arXiv:1909.05330. [Google Scholar]
- Lin, H.; Deng, L.; Yu, D.; Gong, Y.-f.; Acero, A.; Lee, C.-H. A study on multilingual acoustic modeling for large vocabulary ASR. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009. [Google Scholar]
- Liu, C.; Zhang, Q.; Zhang, X.; Singh, K.; Saraf, Y.; Zweig, G. Multilingual graphemic hybrid ASR with massive data augmentation. arXiv 2019, arXiv:1909.06522. [Google Scholar]
- Pratap, V.; Sriram, A.; Tomasello, P.; Hannun, A.; Liptchinsky, V.; Synnaeve, G.; Collobert, R. Massively multilingual asr: 50 languages, 1 model, 1 billion parameters. arXiv 2020, arXiv:2007.03001. [Google Scholar]
- Xiao, Y.; Gong, K.; Zhou, P.; Zheng, G.; Liang, X.; Lin, L. Adversarial meta sampling for multilingual low-resource speech recognition. arXiv 2020, arXiv:2012.11896. [Google Scholar]
- Yılmaz, E.; Biswas, A.; van der Westhuizen, E.; de Wet, F.; Niesler, T. Building a unified code-switching ASR system for South African languages. arXiv 2018, arXiv:1807.10949. [Google Scholar]
- Adel, H.; Vu, N.T.; Kraus, F.; Schlippe, T.; Li, H.; Schultz, T. Recurrent neural network language modeling for code switching conversational speech. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Sreeram, G.; Sinha, R. Exploration of end-to-end framework for code-switching speech recognition task: Challenges and enhancements. IEEE Access 2020, 8, 68146–68157. [Google Scholar] [CrossRef]
- Wu, C.-H.; Shen, H.-P.; Yang, Y.-T. Chinese-English phone set construction for code-switching ASR using acoustic and DNN-extracted articulatory features. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 858–862. [Google Scholar] [CrossRef]
- Petersen, K.; Vakkalanka, S.; Kuzniarz, L. Guidelines for conducting systematic mapping studies in software engineering: An update. Inf. Softw. Technol. 2015, 64, 1–18. [Google Scholar] [CrossRef]
- Tong, S.; Garner, P.N.; Bourlard, H. Multilingual training and cross-lingual adaptation on CTC-based acoustic model. arXiv 2017, arXiv:1711.10025. [Google Scholar]
- Tüske, Z.; Schlüter, R.; Ney, H. Multilingual hierarchical MRASTA features for ASR. In Proceedings of the Interspeech, Lyon, France, 25–29 August 2013. [Google Scholar]
- Zhou, S.; Xu, S.; Xu, B. Multilingual end-to-end speech recognition with a single transformer on low-resource languages. arXiv 2018, arXiv:1806.05059. [Google Scholar]
- Yilmaz, E.; McLaren, M.; van den Heuvel, H.; van Leeuwen, D.A. Language diarization for semi-supervised bilingual acoustic model training. In Proceedings of the IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017. [Google Scholar]
- Barik, R.E.; Lestari, D.P. Text corpus and acoustic model addition for Indonesian-Arabic code-switching in automatic speech recognition system. In Proceedings of the International Conference of Advanced Informatics: Concepts, Theory and Applications (ICAICTA), Yogyakarta, Indonesia, 20–21 September 2019. [Google Scholar]
- Masekwameng, M.S.; Mokgonyane, T.B.; Modipa, T.I.; Manamela, M.J.; Mogale, M.M. Effects of Language Modelling for Sepedi-English Code-Switched Speech in Automatic Speech Recognition System. In Proceedings of the International Conference on Artificial Intelligence, Big Data, Computing and Data Communication Systems (icABCD), Durban, South Africa, 6–7 August 2020. [Google Scholar]
- Shah, S.; Sitaram, S. Using monolingual speech recognition for spoken term detection in code-switched hindi-english speech. In Proceedings of the 2019 International Conference on Data Mining Workshops (ICDMW), Beijing, China, 8–11 November 2019. [Google Scholar]
- Li, K.; Li, J.; Ye, G.; Zhao, R.; Gong, Y. Towards code-switching ASR for end-to-end CTC models. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Seki, H.; Watanabe, S.; Hori, T.; Le Roux, J.; Hershey, J.R. An end-to-end language-tracking speech recognizer for mixed-language speech. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Shan, C.; Weng, C.; Wang, G.; Su, D.; Luo, M.; Yu, D.; Xie, L. Investigating end-to-end speech recognition for mandarin-english code-switching. In Proceedings of the ICASSP 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Vu, N.T.; Lyu, D.-C.; Weiner, J.; Telaar, D.; Schlippe, T.; Blaicher, F.; Chng, E.-S.; Schultz, T.; Li, H. A first speech recognition system for Mandarin-English code-switch conversational speech. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012. [Google Scholar]
- Lee, D.; Kim, D.; Yun, S.; Kim, S. Phonetic Variation Modeling and a Language Model Adaptation for Korean English Code-Switching Speech Recognition. Appl. Sci. 2021, 11, 2866. [Google Scholar] [CrossRef]
- Mabokela, K.R. A multilingual ASR of Sepedi-English code-switched speech for automatic language identification. In Proceedings of the 2019 International Multidisciplinary Information Technology and Engineering Conference (IMITEC), Vanderbijlpark, South Africa, 21–22 November 2019. [Google Scholar]
- Lin, H.; Deng, L.; Droppo, J.; Yu, D.; Acero, A. Learning methods in multilingual speech recognition. In Proceedings of the Proc. NIPS, Vancouver, BC, Canada, 12–13 December 2008. [Google Scholar]
- Song, X.; Zou, Y.; Huang, S.; Chen, S.; Liu, Y. Investigating multi-task learning for automatic speech recognition with code-switching between Mandarin and English. In Proceedings of the 2017 International Conference on Asian Language Processing (IALP), Singapore, 5–7 December 2017. [Google Scholar]
- Biswas, A.; de Wet, F.; van der Westhuizen, E.; Yilmaz, E.; Niesler, T. Multilingual Neural Network Acoustic Modelling for ASR of Under-Resourced English-isiZulu Code-Switched Speech. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018. [Google Scholar]
- Tong, S.; Garner, P.N.; Bourlard, H. An investigation of multilingual ASR using end-to-end LF-MMI. In Proceedings of the ICASSP 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Toshniwal, S.; Sainath, T.N.; Weiss, R.J.; Li, B.; Moreno, P.; Weinstein, E.; Rao, K. Multilingual speech recognition with a single end-to-end model. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Miiller, M.; Stiiker, S.; Waibel, A. Multilingual adaptation of RNN based ASR systems. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Song, T.; Xu, Q.; Ge, M.; Wang, L.; Shi, H.; Lv, Y.; Lin, Y.; Dang, J. Language-specific Characteristic Assistance for Code-switching Speech Recognition. arXiv 2022, arXiv:2206.14580. [Google Scholar]
- Mustafa, M.B.; Mohd Don, Z.; Ainon, R.; Zainuddin, R.; Knowles, G. Developing an HMM-Based Speech Synthesis System for Malay: A Comparison of Iterative and Isolated Unit Training. IEICE Trans. Inf. Syst. 2014, 97, 1273–1282. [Google Scholar] [CrossRef] [Green Version]
- Mustafa, M.; Ainon, R. Emotional speech acoustic model for Malay: Iterative versus isolated unit training. J. Acoust. Soc. Am. 2013, 134, 3057–3066. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, P.; Wang, J.; Miao, H.; Xu, J.; Zhang, P. mproving Transformer Based End-to-End Code-Switching Speech Recognition Using Language Identification. Appl. Sci. 2021, 11, 9106. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Article No. | Focus | Database | Acoustics & Language Modelling | Evaluation Metrics | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bilingual | Multilingual | Well-Resourced | Under-Resourced | CS | Existing | Self- Develop | Mapping | Combining | Merging | Word Error Rate | Character Error Rate | CS Ratio | Mixed Error Rate/Confusion Matrix | Phoneme Error Rate | |
| [2] | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [3] | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [4] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| [5] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||
| [6] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| [26] | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [27] | ✓ | ✓ | ✓ | ✓ | |||||||||||
| [28] | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [29] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| [30] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| [31] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| [32] | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [33] | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [34] | ✓ | ✓ | ✓ | ✓ | |||||||||||
| [35] | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [36] | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [37] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| [38] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| [39] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| [40] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||
| [41] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| [42] | ✓ | ✓ | ✓ | ||||||||||||
| [44] | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [45] | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [46] | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [47] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||
| [48] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| [49] | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [50] | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [51] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| [52] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||
| [53] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| [54] | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [55] | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [56] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| [57] | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [58] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||
| [59] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| [60] | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [61] | ✓ | ✓ | ✓ | ✓ | |||||||||||
| [62] | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [63] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| ∑ | 21 | 21 | 34 | 13 | 23 | 26 | 14 | 2 | 22 | 7 | 29 | 4 | 3 | 6 | 2 |
| Article No. | Database | ||||
|---|---|---|---|---|---|
| Existing Database | Self-Developed | Size (HOURS) | Number of Speakers | Number of Languages | |
| [2] | ✓ | NP | NP | 2 | |
| [4] | ✓ | 11.8 | NP | 3 | |
| [5] | ✓ | 11.8 | NP | 2 | |
| [6] | ✓ | NP | NP | 2 | |
| [26] | ✓ | NP | NP | 3 | |
| [29] | ✓ | 200 | NP | 2 | |
| [30] | ✓ | NP | NP | 10 | |
| [32] | ✓ | 62.8 | 157 | 2 | |
| [39] | ✓ | 14.3 | NP | 6 | |
| [40] | ✓ | 62.8 | 157 | 2 | |
| [41] | ✓ | 25 | 101 | 2 | |
| [47] | ✓ | 11.8 | NP | 2 | |
| [48] | ✓ | 2.8 | 11 | 2 | |
| [49] | ✓ | 20 | 10 | 2 | |
| [50] | ✓ | NP | NP | 2 | |
| [55] | ✓ | 62.8 | 157 | 2 | |
| [51] | ✓ | 300 | NP | 2 | |
| [52] | ✓ | 622.3 | NP | 10 | |
| [53] | ✓ | 1000 | NP | 2 | |
| [56] | ✓ | 6.5 | 143 | 2 | |
| [58] | ✓ | 62.8 | 157 | 2 | |
| [59] | ✓ | 14.3 | NP | 6 | |
| [63] | ✓ | 250 | NP | 2 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mustafa, M.B.; Yusoof, M.A.; Khalaf, H.K.; Rahman Mahmoud Abushariah, A.A.; Kiah, M.L.M.; Ting, H.N.; Muthaiyah, S. Code-Switching in Automatic Speech Recognition: The Issues and Future Directions. Appl. Sci. 2022, 12, 9541. https://doi.org/10.3390/app12199541
Mustafa MB, Yusoof MA, Khalaf HK, Rahman Mahmoud Abushariah AA, Kiah MLM, Ting HN, Muthaiyah S. Code-Switching in Automatic Speech Recognition: The Issues and Future Directions. Applied Sciences. 2022; 12(19):9541. https://doi.org/10.3390/app12199541
Chicago/Turabian StyleMustafa, Mumtaz Begum, Mansoor Ali Yusoof, Hasan Kahtan Khalaf, Ahmad Abdel Rahman Mahmoud Abushariah, Miss Laiha Mat Kiah, Hua Nong Ting, and Saravanan Muthaiyah. 2022. "Code-Switching in Automatic Speech Recognition: The Issues and Future Directions" Applied Sciences 12, no. 19: 9541. https://doi.org/10.3390/app12199541
APA StyleMustafa, M. B., Yusoof, M. A., Khalaf, H. K., Rahman Mahmoud Abushariah, A. A., Kiah, M. L. M., Ting, H. N., & Muthaiyah, S. (2022). Code-Switching in Automatic Speech Recognition: The Issues and Future Directions. Applied Sciences, 12(19), 9541. https://doi.org/10.3390/app12199541