
A Novel Embedding Model Based on a Transition System for Building Industry-Collaborative Digital Twin





Abstract
:1. Introduction
- (1)
- Transition system based embedding technology to easily extract process characteristics from event logs is proposed, and this technology can help interpret numerous log data accumulated by manufacturing companies.
- (2)
- Creating a digital twin model requires a lot of technology and is costly, and in most cases additional professional manpower and costs are required to reflect real data in the created twin. In this paper, we tried to implement this process through artificial intelligence learning, and it can satisfy the need for cost reduction.
- (3)
- By providing a cloud computing style digital twin architecture, our setup can help small companies with insufficient technical skills to realize digital twin methods.
2. Related Work
2.1. Digital Twin Overview
2.2. Log Data Analysis
2.3. AI for Manufacturing
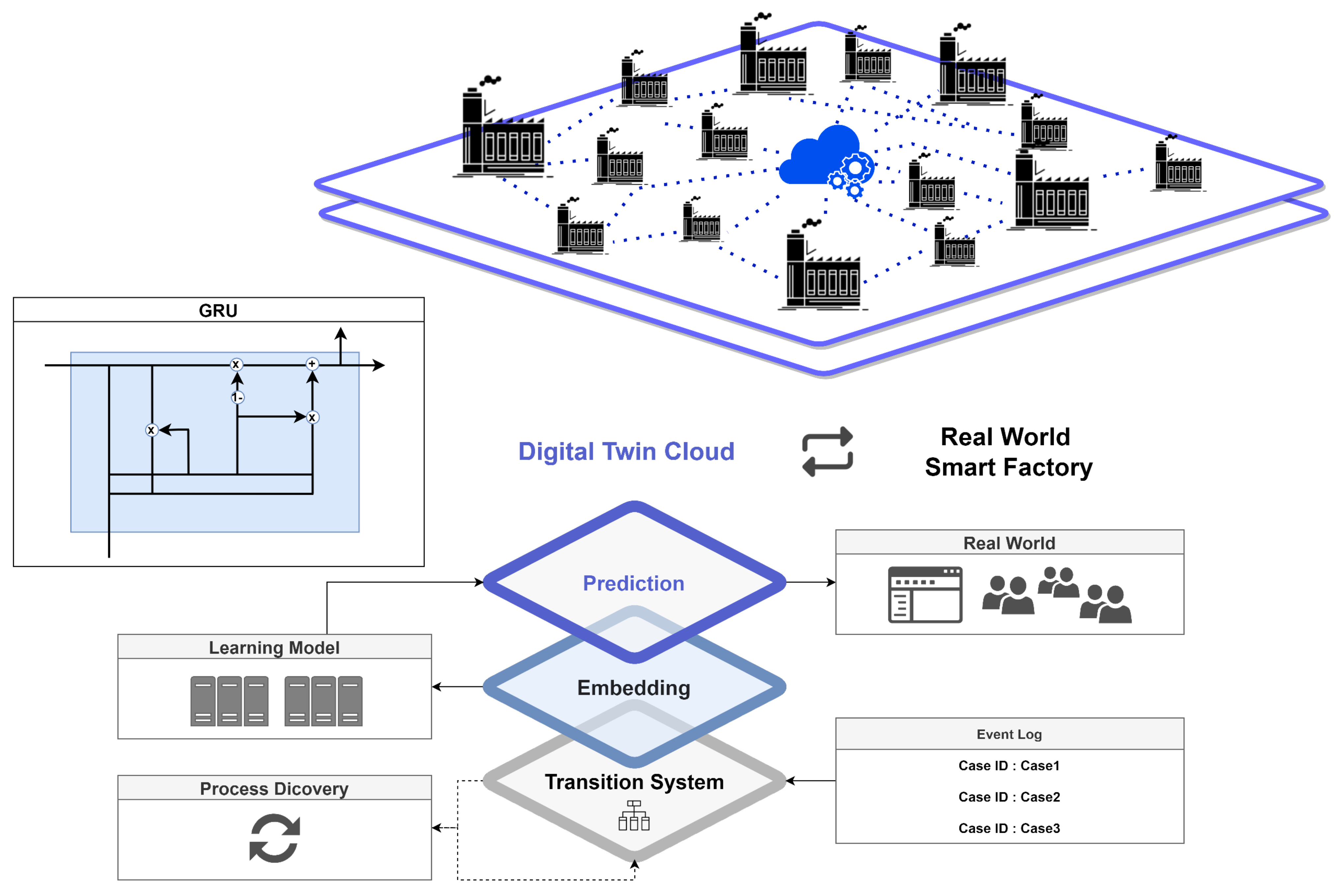
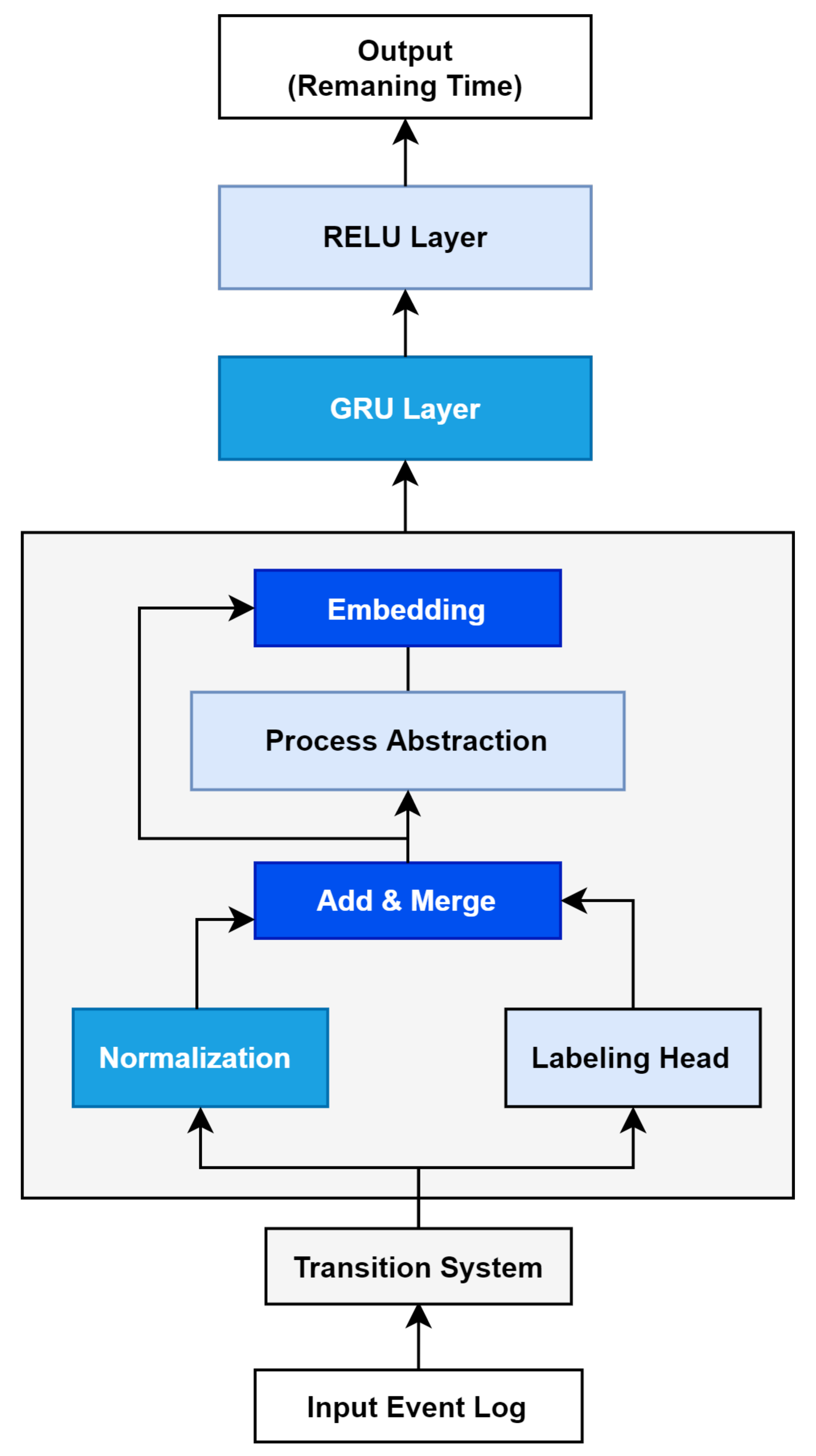
3. TED: Transition System Based Embedding for Digital Twin
3.1. System Architecture
3.2. Modeling Procedures
3.3. Training Procedures
4. Experiments and Results
4.1. Experiment Environment
4.2. Real World Dataset
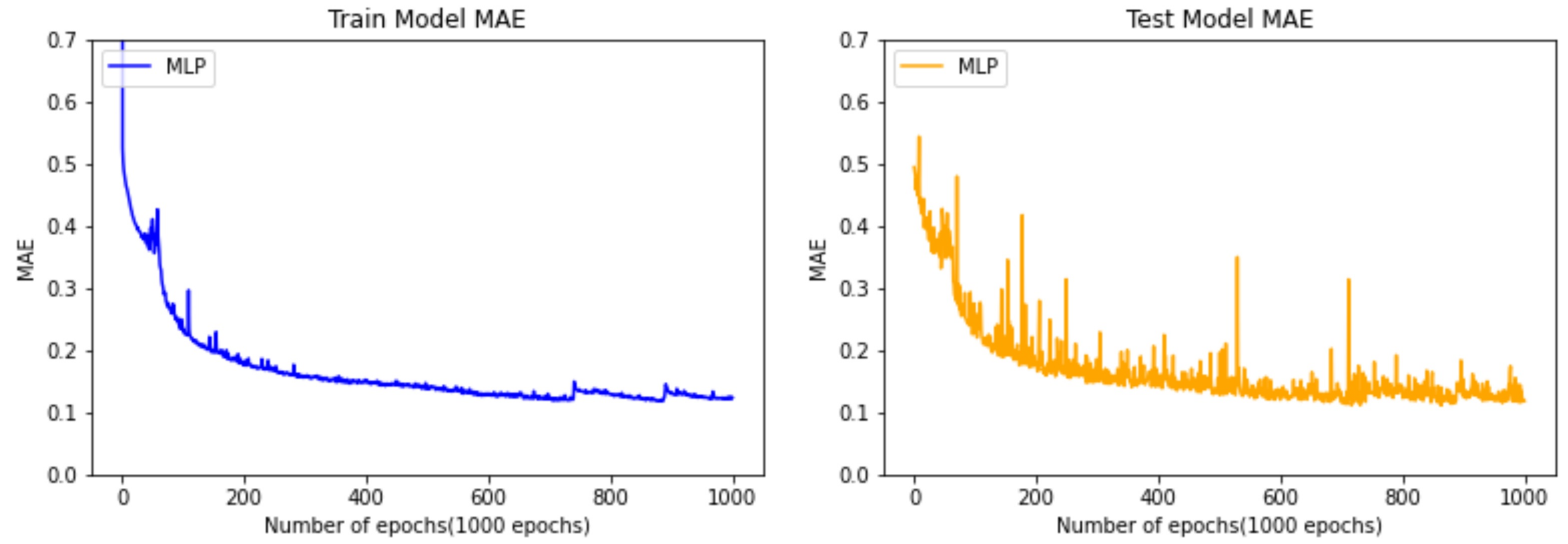
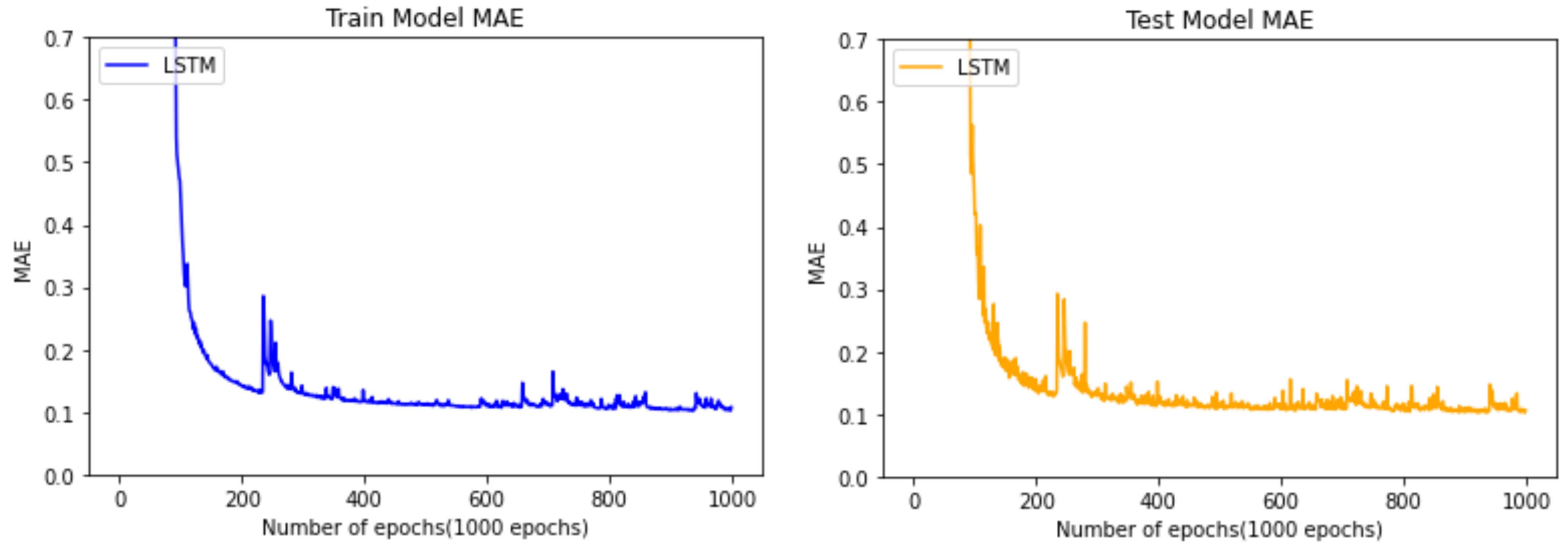
4.3. Model EvaluationResults
4.4. Model Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, X.; Wang, Y.; Tao, F.; Liu, A. New paradigm of data-driven smart customisation through digital twin. J. Manuf. Syst. 2021, 58, 270–280. [Google Scholar] [CrossRef]
- Tao, F.; Qi, Q.; Liu, A.; Kusiak, A. Data-driven smart manufacturing. J. Manuf. Syst. 2018, 48, 157–169. [Google Scholar] [CrossRef]
- Söderberg, R.; Wärmefjord, K.; Carlson, J.S.; Lindkvist, L. Toward a Digital Twin for real-time geometry assurance in individualized production. CIRP Ann. 2017, 66, 137–140. [Google Scholar] [CrossRef]
- Zhang, C.; Chen, D.; Tao, F.; Liu, A. Data driven smart customization. Procedia CIRP 2019, 81, 564–569. [Google Scholar] [CrossRef]
- Saldivar, A.A.F.; Li, Y.; Chen, W.-n.; Zhan, Z.-h.; Zhang, J.; Chen, L.Y. Industry 4.0 with cyber-physical integration: A design and manufacture perspective. In Proceedings of the 2015 21st International Conference on Automation and Computing (ICAC), Glasgow, UK, 11–12 September 2015; pp. 1–6. [Google Scholar]
- Singh, V.; Willcox, K.E. Engineering design with digital thread. AIAA J. 2018, 56, 4515–4528. [Google Scholar] [CrossRef]
- Tuegel, E.J.; Ingraffea, A.R.; Eason, T.G.; Spottswood, S.M. Reengineering aircraft structural life prediction using a digital twin. Int. J. Aerosp. Eng. 2011, 2011, 154798. [Google Scholar] [CrossRef] [Green Version]
- Bevilacqua, M.; Bottani, E.; Ciarapica, F.E.; Costantino, F.; Di Donato, L.; Ferraro, A.; Mazzuto, G.; Monteriù, A.; Nardini, G.; Ortenzi, M.; et al. Digital twin reference model development to prevent operators’ risk in process plants. Sustainability 2020, 12, 1088. [Google Scholar] [CrossRef] [Green Version]
- Luo, W.; Hu, T.; Zhang, C.; Wei, Y. Digital twin for CNC machine tool: Modeling and using strategy. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 1129–1140. [Google Scholar] [CrossRef]
- Ghosh, A.K.; Ullah, A.; Kubo, A.; Akamatsu, T.; D’Addona, D.M. Machining phenomenon twin construction for industry 4.0: A case of surface roughness. J. Manuf. Mater. Process. 2020, 4, 11. [Google Scholar] [CrossRef] [Green Version]
- Aheleroff, S.; Xu, X.; Zhong, R.Y.; Lu, Y. Digital twin as a service (DTaaS) in industry 4.0: An architecture reference model. Adv. Eng. Inform. 2021, 47, 101225. [Google Scholar] [CrossRef]
- Zhou, H.; Yang, C.; Sun, Y. Intelligent Ironmaking Optimization Service on a Cloud Computing Platform by Digital Twin. Engineering 2021, 7, 1274–1281. [Google Scholar] [CrossRef]
- Chen, J.; Hu, K.; Wang, Q.; Sun, Y.; Shi, Z.; He, S. Narrowband internet of things: Implementations and applications. IEEE Internet Things J. 2017, 4, 2309–2314. [Google Scholar] [CrossRef]
- Lugaresi, G.; Matta, A. Real-time simulation in manufacturing systems: Challenges and research directions. In Proceedings of the 2018 Winter Simulation Conference (WSC), Gothenburg, Sweden, 9–12 December 2018; pp. 3319–3330. [Google Scholar]
- van der Aalst, W.M. Process mining and simulation: A match made in heaven! In Proceedings of the SummerSim, Bordeaux, France, 9–12 July 2018; pp. 1–4. [Google Scholar]
- Bergmann, S.; Feldkamp, N.; Strassburger, S. Approximation of dispatching rules for manufacturing simulation using data mining methods. In Proceedings of the 2015 Winter Simulation Conference (WSC), Huntington Beach, CA, USA, 6–9 December 2015; pp. 2329–2340. [Google Scholar]
- Ferreira, D.R.; Vasilyev, E. Using logical decision trees to discover the cause of process delays from event logs. Comput. Ind. 2015, 70, 194–207. [Google Scholar] [CrossRef]
- Moon, J.; Park, G.; Jeong, J. POP-ON: Prediction of Process Using One-Way Language Model Based on NLP Approach. Appl. Sci. 2021, 11, 864. [Google Scholar] [CrossRef]
- Lugaresi, G.; Matta, A. Automated manufacturing system discovery and digital twin generation. J. Manuf. Syst. 2021, 59, 51–66. [Google Scholar] [CrossRef]
- Pan, Y.; Zhang, L. A BIM-data mining integrated digital twin framework for advanced project management. Autom. Constr. 2021, 124, 103564. [Google Scholar] [CrossRef]
- Tran, T.a.; Ruppert, T.; Eigner, G.; Abonyi, J. Real-time locating system and digital twin in Lean 4.0. In Proceedings of the 2021 IEEE 15th International Symposium on Applied Computational Intelligence and Informatics (SACI), Timisoara, Romania, 19–21 May 2021; pp. 000369–000374. [Google Scholar]
- Lugaresi, G.; Zanotti, M.; Tarasconi, D.; Matta, A. Manufacturing Systems Mining: Generation of Real-Time Discrete Event Simulation Models. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 415–420. [Google Scholar]
- Ghahramani, M.; Qiao, Y.; Zhou, M.; Hagan, A.O.; Sweeney, J. AI-based modeling and data-driven evaluation for smart manufacturing processes. IEEE/CAA J. Autom. Sin. 2020, 7, 1026–1037. [Google Scholar] [CrossRef]
- Lee, J.; Singh, J.; Azamfar, M.; Pandhare, V. Industrial AI and predictive analytics for smart manufacturing systems. In Smart Manufacturing; Elsevier: Amsterdam, The Netherlands, 2020; pp. 213–244. [Google Scholar]
- Ding, H.; Gao, R.X.; Isaksson, A.J.; Landers, R.G.; Parisini, T.; Yuan, Y. State of AI-based monitoring in smart manufacturing and introduction to focused section. IEEE/ASME Trans. Mechatron. 2020, 25, 2143–2154. [Google Scholar] [CrossRef]
- Kotsiopoulos, T.; Sarigiannidis, P.; Ioannidis, D.; Tzovaras, D. Machine Learning and Deep Learning in Smart Manufacturing: The Smart Grid Paradigm. Comput. Sci. Rev. 2021, 40, 100341. [Google Scholar] [CrossRef]
- Huang, Z.; Shen, Y.; Li, J.; Fey, M.; Brecher, C. A Survey on AI-Driven Digital Twins in Industry 4.0: Smart Manufacturing and Advanced Robotics. Sensors 2021, 21, 6340. [Google Scholar] [CrossRef]
- Mostafa, F.; Tao, L.; Yu, W. An effective architecture of digital twin system to support human decision-making and AI-driven autonomy. Concurr. Comput. Pract. Exp. 2021, 33, e6111. [Google Scholar] [CrossRef]
- Örs, E.; Schmidt, R.; Mighani, M.; Shalaby, M. A Conceptual Framework for AI-based Operational Digital Twin in Chemical Process Engineering. In Proceedings of the 2020 IEEE International Conference on Engineering, Technology and Innovation (ICE/ITMC), Cardiff, UK, 15–17 June 2020; pp. 1–8. [Google Scholar]
- Rojek, I.; Mikołajewski, D.; Dostatni, E. Digital Twins in Product Lifecycle for Sustainability in Manufacturing and Maintenance. Appl. Sci. 2021, 11, 31. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Tello-Leal, E.; Roa, J.; Rubiolo, M.; Ramirez-Alcocer, U.M. Predicting activities in business processes with LSTM recurrent neural networks. In Proceedings of the 2018 ITU Kaleidoscope: Machine Learning for a 5G Future (ITU K), Santa Fe, Argentina, 26–28 November 2018; pp. 1–7. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case ID | Start Time | End Time | Product | Machine | Qtty |
|---|---|---|---|---|---|
| Case 01 | 3 July 2021: 13:00 | 3 July 2021: 13:10 | A | 1 | 10 |
| Case 01 | 3 July 2021: 13:20 | 3 July 2021: 13:40 | A | 2 | 10 |
| Case 01 | 3 July 2021: 13:55 | 3 July 2021: 14:10 | A | 3 | 10 |
| Case 01 | 3 July 2021: 14:20 | 3 July 2021: 14:30 | A | 4 | 10 |
| Case 02 | 3 July 2021: 15:00 | 3 July 2021: 15:30 | B | 1 | 20 |
| Case 02 | 3 July 2021: 15:40 | 3 July 2021: 16:20 | B | 3 | 20 |
| Case 02 | 3 July 2021: 16:30 | 3 July 2021: 17:10 | B | 2 | 20 |
| Case 02 | 3 July 2021: 17:20 | 3 July 2021: 18:00 | B | 4 | 20 |
| Case 03 | 3 July 2021: 04:00 | 3 July 2021: 04:25 | A | 1 | 5 |
| Case 03 | 3 July 2021: 04:32 | 3 July 2021: 04:44 | A | 3 | 5 |
| Case 03 | 3 July 2021: 04:55 | 3 July 2021: 05:20 | A | 2 | 5 |
| Case 03 | 3 July 2021: 05:30 | 3 July 2021: 05:55 | A | 4 | 5 |
| Case 04 | 3 July 2021: 07:00 | 3 July 2021: 07:30 | B | 1 | 10 |
| Case 04 | 3 July 2021: 07:42 | 3 July 2021: 07:55 | B | 2 | 10 |
| Case 04 | 3 July 2021: 08:05 | 3 July 2021: 09:45 | B | 3 | 10 |
| Case 04 | 3 July 2021: 10:00 | 3 July 2021: 10:30 | B | 4 | 10 |
| Case Id | Trace | Product | Qtty | End Time |
|---|---|---|---|---|
| Case 01 | A | 10 | 90 | |
| Case 02 | B | 20 | 180 | |
| Case 03 | A | 5 | 115 | |
| Case 04 | B | 10 | 190 | |
| Case05 | B | 10 | ?? |
| Product | 1 | 2 | 3 | 4 | 5 | Remaining Time |
|---|---|---|---|---|---|---|
| A | 0 | 0 | 0 | 0 | 0 | 9.00 |
| A | 1 | 0 | 0 | 0 | 0 | 7.00 |
| A | 1 | 1 | 0 | 0 | 0 | 3.50 |
| A | 1 | 1 | 1 | 0 | 0 | 1.00 |
| Parameter | Value |
|---|---|
| epochs | 1000 |
| batch size | 40 |
| optimizer | AdaGrad |
| GRU units | 128 |
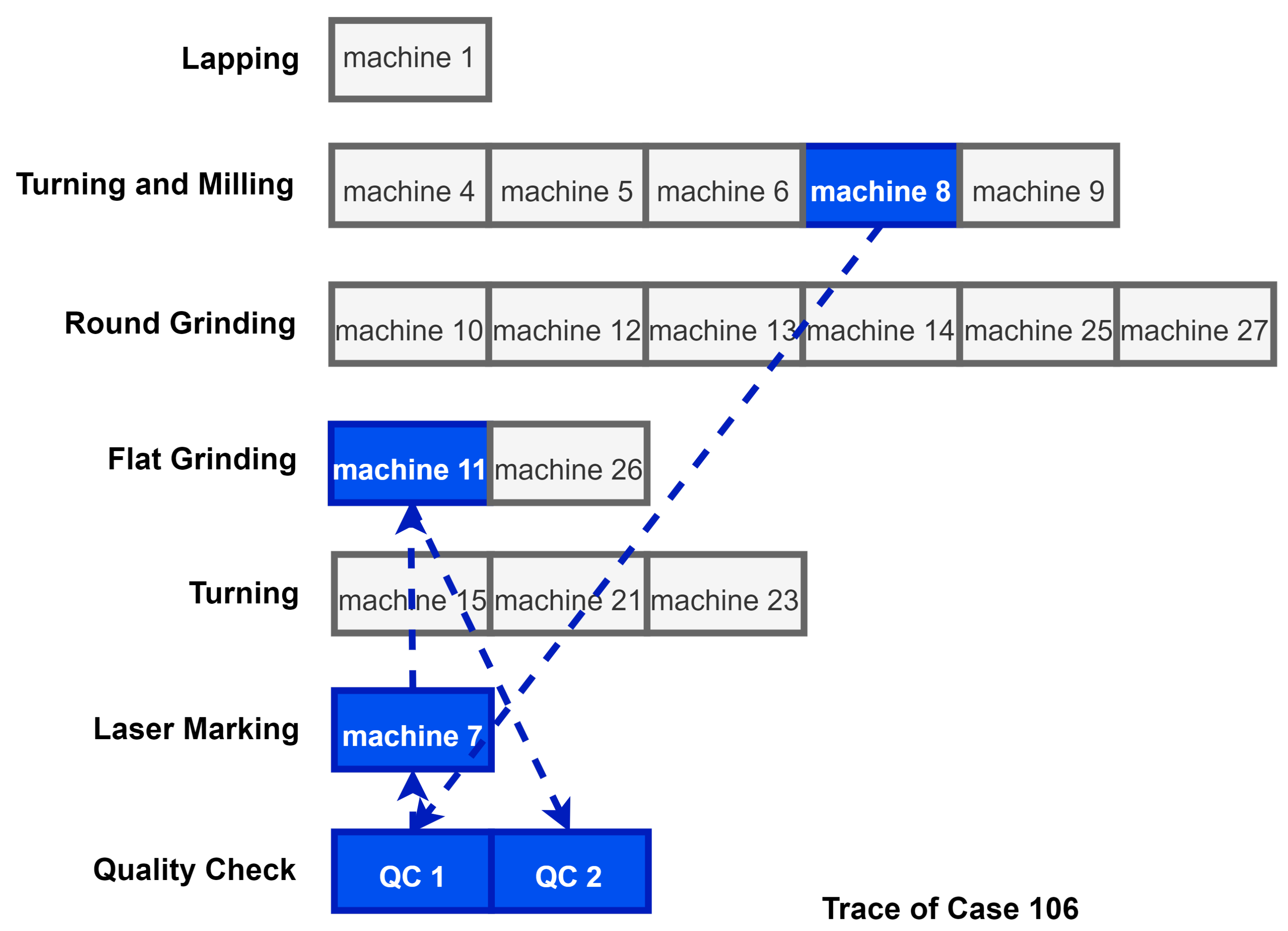
| Case ID | ActivityMachine | Start Time | Complete Time | Qtty |
|---|---|---|---|---|
| Case 106 | Turning/Milling–Machine 8 | 15 March 2012: 10:14 | 15 March 2012: 15:44 | 39 |
| Case 106 | Turning/Milling–Machine 8 | 15 March 2012: 16:55 | 15 March 2012: 20:38 | 39 |
| Case 106 | Turning/Milling Q.C. | 19 March 2012: 7:00 | 19 March 2012: 7:28 | 39 |
| Case 106 | Laser Marking–Machine 7 | 19 March 2012: 9:38 | 19 March 2012: 10:51 | 39 |
| Case 106 | Flat Grinding–Machine 11 | 19 March 2012: 14:42 | 19 March 2012: 15:20 | 39 |
| Case 106 | Final Inspection Q.C. | 21 March 2012: 15:27 | 21 March 2012: 17:57 | 39 |
| Case 106 | Packing | 22 March 2012: 0:00 | 22 March 2012: 1:00 | 39 |
| Case 106 | Final Inspection Q.C. | 22 March 2012: 11:50 | 22 March 2012: 13:05 | 39 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, M.; Moon, J.; Jeong, J.; Sin, S.; Kim, J. A Novel Embedding Model Based on a Transition System for Building Industry-Collaborative Digital Twin. Appl. Sci. 2022, 12, 553. https://doi.org/10.3390/app12020553
Yang M, Moon J, Jeong J, Sin S, Kim J. A Novel Embedding Model Based on a Transition System for Building Industry-Collaborative Digital Twin. Applied Sciences. 2022; 12(2):553. https://doi.org/10.3390/app12020553
Chicago/Turabian StyleYang, Minyeol, Junhyung Moon, Jongpil Jeong, Seokho Sin, and Jimin Kim. 2022. "A Novel Embedding Model Based on a Transition System for Building Industry-Collaborative Digital Twin" Applied Sciences 12, no. 2: 553. https://doi.org/10.3390/app12020553
APA StyleYang, M., Moon, J., Jeong, J., Sin, S., & Kim, J. (2022). A Novel Embedding Model Based on a Transition System for Building Industry-Collaborative Digital Twin. Applied Sciences, 12(2), 553. https://doi.org/10.3390/app12020553