
Density Estimates as Representations of Agricultural Fields for Remote Sensing-Based Monitoring of Tillage and Vegetation Cover


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Present a method for off-season tillage and vegetation cover detection on crop field parcels, which is a challenging task due to the heterogeneous size of the objects and a limited amount of training observations;
- Propose a representation of a free-form raster image object as a non-parametric probability density estimate, to be used for increasing robustness to variability in object size, count and missing pixel data;
- Introduce an easy-to-use framework for multi-sensor raster data fusion for sources of varying spatial resolution, applicable also outside the specific task considered here.
2. Materials and Methods
2.1. Materials
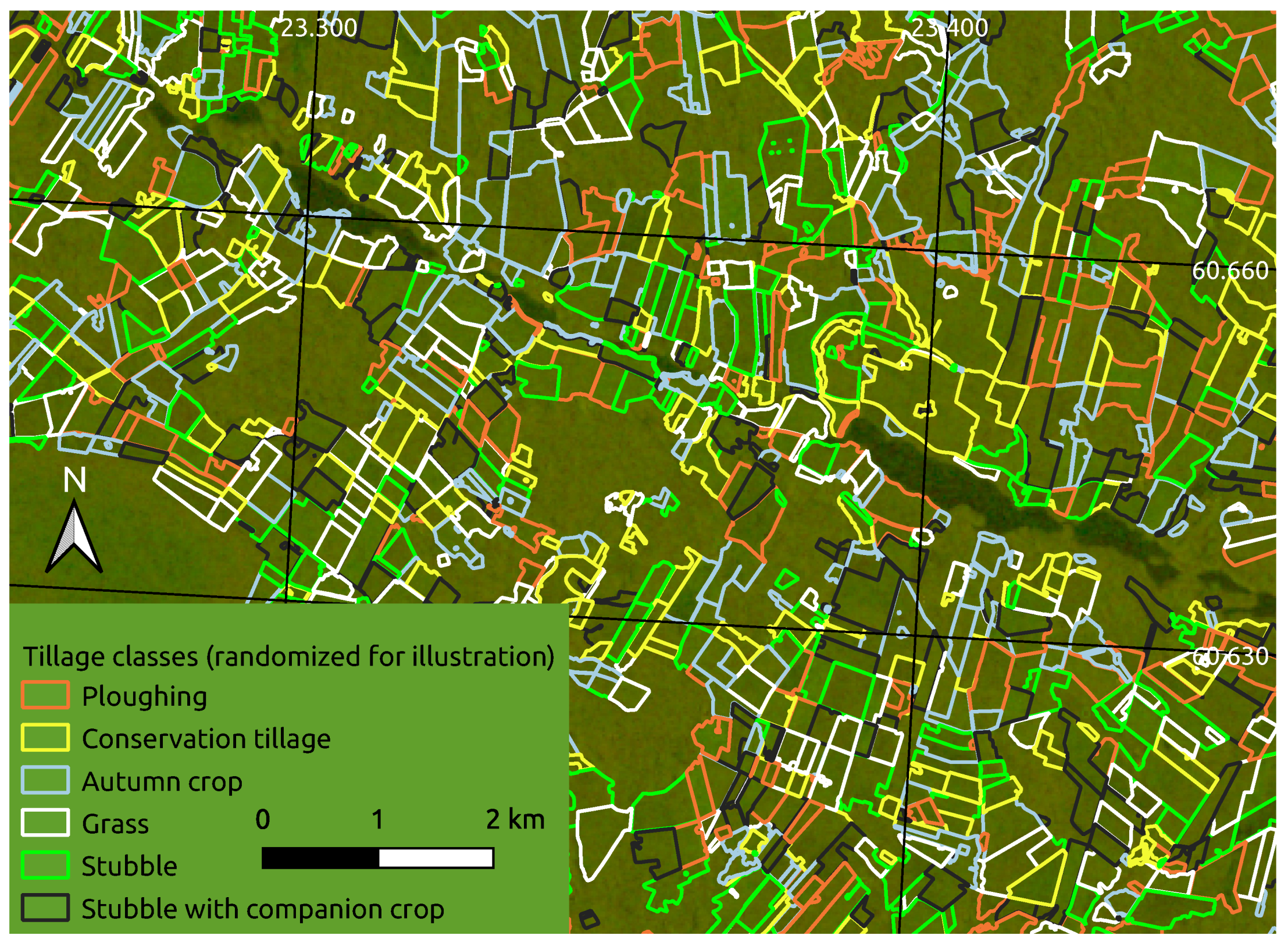
2.1.1. Crop Field Parcels and Annotations
2.1.2. Satellite Imagery
2.2. Methods
2.2.1. Problem Formulation
2.2.2. Data Flow: From Objects to Representations and Classification
2.2.3. Density Estimate as a Representation
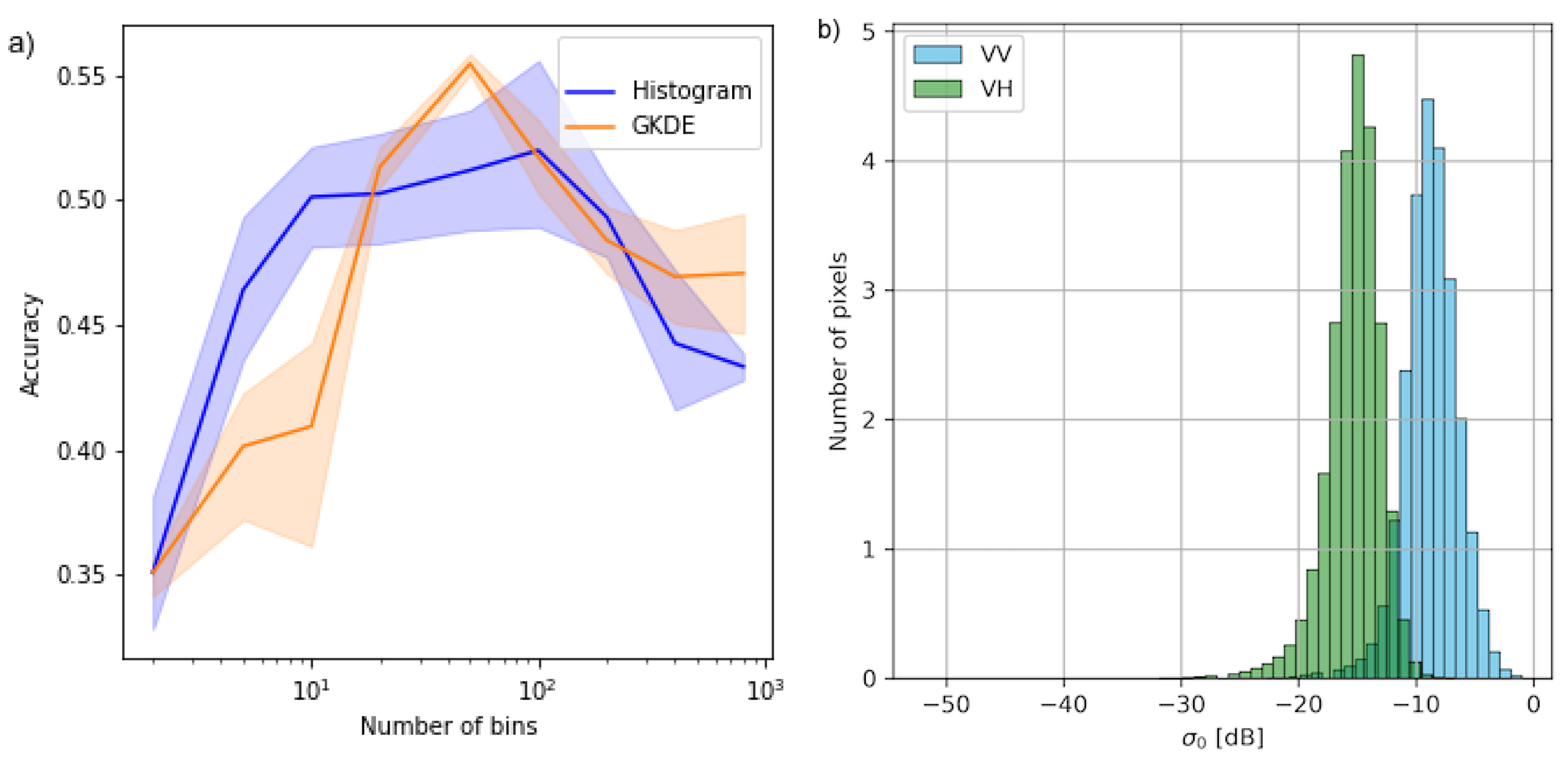
Multivariate Histogram
Kernel Density Estimation
Logistic Gaussian Process Density Estimation
3. Results
3.1. Technical Validation
3.1.1. Comparison of Representations
3.1.2. Effects of Object Size
3.1.3. Data Fusion
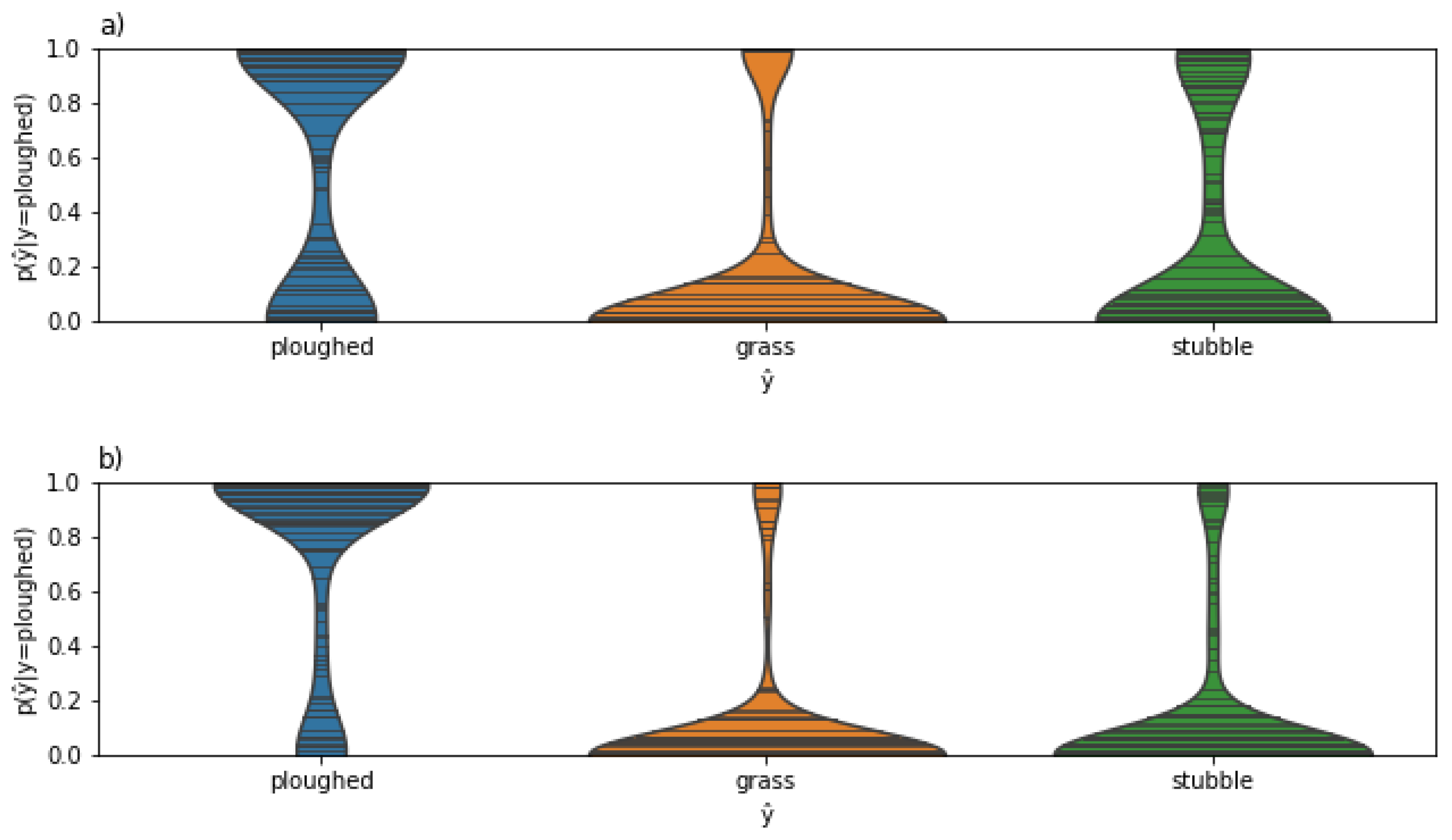
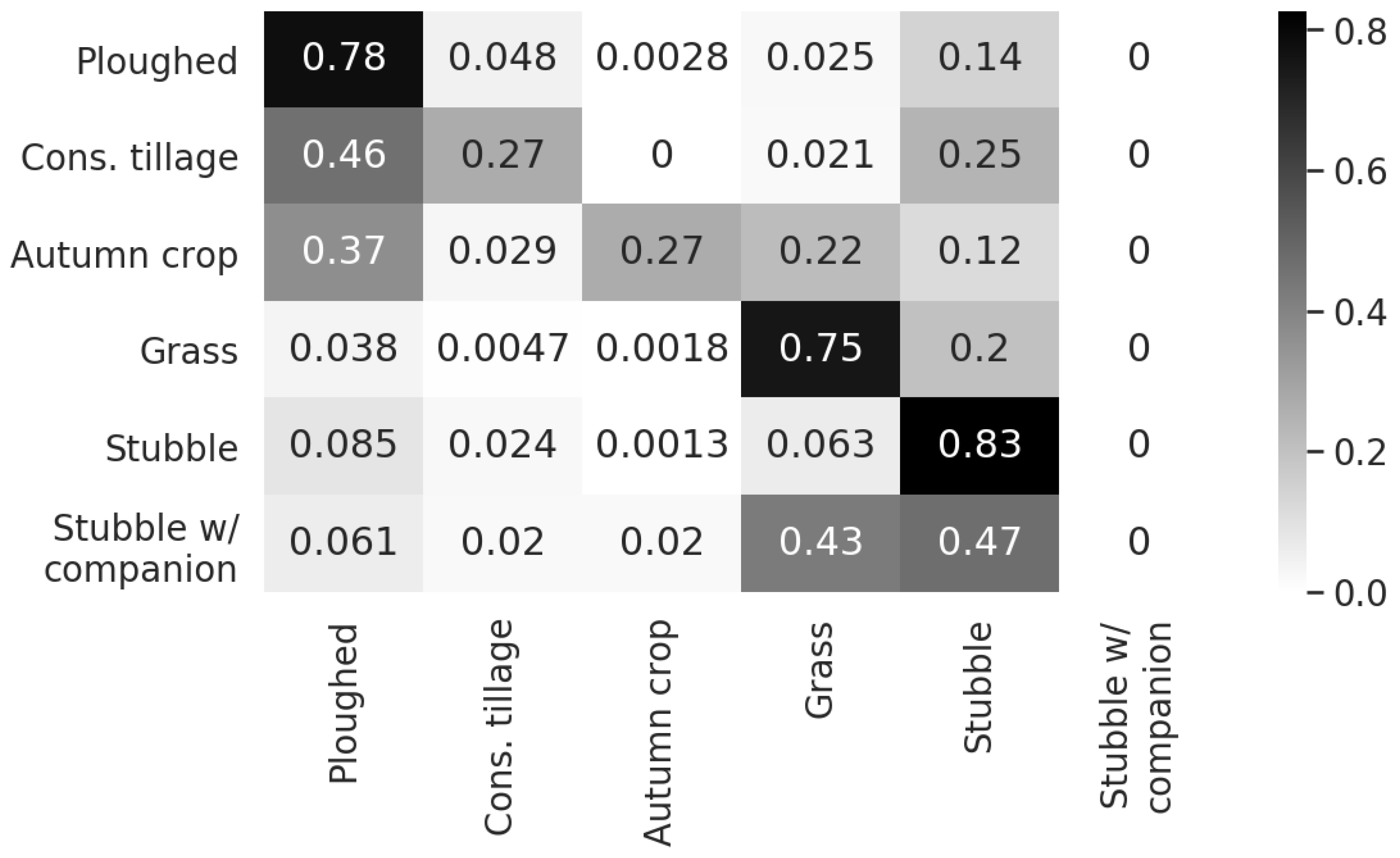
3.2. Soil Tillage Detection
4. Discussion
4.1. Soil Tillage Detection
4.2. Modelling Aspects
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Orynbaikyzy, A.; Gessner, U.; Conrad, C. Crop type classification using a combination of optical and radar remote sensing data: A review. Int. J. Remote Sens. 2019, 40, 6553–6595. [Google Scholar] [CrossRef]
- Felegari, S.; Sharifi, A.; Moravej, K.; Amin, M.; Golchin, A.; Muzirafuti, A.; Tariq, A.; Zhao, N. Integration of Sentinel 1 and Sentinel 2 Satellite Images for Crop Mapping. Appl. Sci. 2021, 11, 10104. [Google Scholar] [CrossRef]
- Garioud, A.; Valero, S.; Giordano, S.; Mallet, C. Recurrent-based regression of Sentinel time series for continuous vegetation monitoring. Remote Sens. Environ. 2021, 263, 112419. [Google Scholar] [CrossRef]
- Mateo-García, G.; Gómez-Chova, L.; Camps-Valls, G. Convolutional neural networks for multispectral image cloud masking. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium, Fort Worth, TX, USA, 23–28 July 2017; pp. 2255–2258. [Google Scholar]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Luotamo, M.; Metsämäki, S.; Klami, A. Multiscale Cloud Detection in Remote Sensing Images Using a Dual Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4972–4983. [Google Scholar] [CrossRef]
- Fu, G.; Liu, C.; Zhou, R.; Sun, T.; Zhang, Q. Classification for high resolution remote sensing imagery using a fully convolutional network. Remote Sens. 2017, 9, 498. [Google Scholar] [CrossRef] [Green Version]
- Salehi, B.; Daneshfar, B.; Davidson, A.M. Accurate crop-type classification using multi-temporal optical and multi-polarization SAR data in an object-based image analysis framework. Int. J. Remote Sens. 2017, 38, 4130–4155. [Google Scholar] [CrossRef]
- McNairn, H.; Ellis, J.; Van Der Sanden, J.; Hirose, T.; Brown, R. Providing crop information using RADARSAT-1 and satellite optical imagery. Int. J. Remote Sens. 2002, 23, 851–870. [Google Scholar] [CrossRef]
- Rußwurm, M.; Körner, M. Self-attention for raw optical Satellite Time Series Classification. ISPRS J. Photogramm. Remote Sens. 2020, 169, 421–435. [Google Scholar] [CrossRef]
- Voormansik, K.; Zalite, K.; Sünter, I.; Tamm, T.; Koppel, K.; Verro, T.; Brauns, A.; Jakovels, D.; Praks, J. Separability of Mowing and Ploughing Events on Short Temporal Baseline Sentinel-1 Coherence Time Series. Remote Sens. 2020, 12, 3784. [Google Scholar] [CrossRef]
- De Vroey, M.; Radoux, J.; Defourny, P. Grassland Mowing Detection Using Sentinel-1 Time Series: Potential and Limitations. Remote Sens. 2021, 13, 348. [Google Scholar] [CrossRef]
- Planque, C.; Lucas, R.; Punalekar, S.; Chognard, S.; Hurford, C.; Owers, C.; Horton, C.; Guest, P.; King, S.; Williams, S.; et al. National Crop Mapping Using Sentinel-1 Time Series: A Knowledge-Based Descriptive Algorithm. Remote Sens. 2021, 13, 846. [Google Scholar] [CrossRef]
- Swain, M.J.; Ballard, D.H. Color indexing. Int. J. Comput. Vis. 1991, 7, 11–32. [Google Scholar] [CrossRef]
- Schiele, B.; Crowley, J.L. Probabilistic object recognition using multidimensional receptive field histograms. In Proceedings of the IEEE 13th International Conference on Pattern Recognition, Washington, DC, USA, 25–29 August 1996; Volume 2, pp. 50–54. [Google Scholar]
- Barla, A.; Odone, F.; Verri, A. Histogram intersection kernel for image classification. In Proceedings of the IEEE 2003 International Conference on Image Processing, Barcelona, Spain, 14–18 September 2003; Volume 3, pp. 3–513. [Google Scholar]
- Zhang, G.; Jia, X.; Kwok, N.M. Super pixel based remote sensing image classification with histogram descriptors on spectral and spatial data. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 4335–4338. [Google Scholar]
- Yang, W.; Hou, K.; Liu, B.; Yu, F.; Lin, L. Two-stage clustering technique based on the neighboring union histogram for hyperspectral remote sensing images. IEEE Access 2017, 5, 5640–5647. [Google Scholar] [CrossRef]
- Demir, B.; Bruzzone, L. Histogram-based attribute profiles for classification of very high resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2015, 54, 2096–2107. [Google Scholar] [CrossRef]
- Simonoff, J.S. Smoothing Methods in Statistics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Scott, D.W. Multivariate Density Estimation: Theory, Practice, and Visualization; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Riihimäki, J.; Vehtari, A. Laplace approximation for logistic Gaussian process density estimation and regression. Bayesian Anal. 2014, 9, 425–448. [Google Scholar] [CrossRef]
- Baker, J.; Laflen, J. Water quality consequences of conservation tillage: New technology is needed to improve the water quality advantages of conservation tillage. J. Soil Water Conserv. 1983, 38, 186–193. [Google Scholar]
- Bechmann, M.E.; Bøe, F. Soil tillage and crop growth effects on surface and subsurface runoff, loss of soil, phosphorus and nitrogen in a cold climate. Land 2021, 10, 77. [Google Scholar] [CrossRef]
- Daughtry, C. Discriminating Crop Residues from Soil by Shortwave Infrared Reflectance. Agron. J. 2001, 93, 125–131. [Google Scholar] [CrossRef]
- Daughtry, C.; Doraiswamy, P.; Hunt, E.; Stern, A.; McMurtrey, J.; Prueger, J. Remote sensing of crop residue cover and soil tillage intensity. Soil Tillage Res. 2006, 91, 101–108. [Google Scholar] [CrossRef]
- Quemada, M.; Daughtry, C.S.T. Spectral Indices to Improve Crop Residue Cover Estimation under Varying Moisture Conditions. Remote Sens. 2016, 8, 660. [Google Scholar] [CrossRef] [Green Version]
- McNairn, H.; Boisvert, J.; Major, D.; Gwyn, Q.; Brown, R.; Smith, A. Identification of Agricultural Tillage Practices from C-Band Radar Backscatter. Can. J. Remote Sens. 1996, 22, 154–162. [Google Scholar] [CrossRef]
- McNairn, H.; Duguay, C.; Boisvert, J.; Huffman, E.; Brisco, B. Defining the Sensitivity of Multi-Frequency and Multi-Polarized Radar Backscatter to Post-Harvest Crop Residue. Can. J. Remote Sens. 2001, 27, 247–263. [Google Scholar] [CrossRef]
- McNairn, H.; Duguay, C.; Brisco, B.; Pultz, T. The effect of soil and crop residue characteristics on polarimetric radar response. Remote Sens. Environ. 2002, 80, 308–320. [Google Scholar] [CrossRef]
- Zhang, J. Multi-source remote sensing data fusion: Status and trends. Int. J. Image Data Fusion 2010, 1, 5–24. [Google Scholar] [CrossRef] [Green Version]
- Haas, J.; Ban, Y. Sentinel-1A SAR and Sentinel-2A MSI data fusion for urban ecosystem service mapping. Remote Sens. Appl. Soc. Environ. 2017, 8, 41–53. [Google Scholar] [CrossRef]
- Ban, Y.; Jacob, A. Object-based fusion of multitemporal multiangle ENVISAT ASAR and HJ-1B multispectral data for urban land-cover mapping. IEEE Trans. Geosci. Remote Sens. 2013, 51, 1998–2006. [Google Scholar] [CrossRef]
- Veloso, A.; Mermoz, S.; Bouvet, A.; Le Toan, T.; Planells, M.; Dejoux, J.F.; Ceschia, E. Understanding the temporal behavior of crops using Sentinel-1 and Sentinel-2-like data for agricultural applications. Remote Sens. Environ. 2017, 199, 415–426. [Google Scholar] [CrossRef]
- Orynbaikyzy, A.; Gessner, U.; Mack, B.; Conrad, C. Crop type classification using fusion of Sentinel-1 and Sentinel-2 data: Assessing the impact of feature selection, optical data availability, and parcel sizes on the accuracies. Remote Sens. 2020, 12, 2779. [Google Scholar] [CrossRef]
- Azzari, G.; Grassini, P.; Edreira, J.I.R.; Conley, S.; Mourtzinis, S.; Lobell, D.B. Satellite mapping of tillage practices in the North Central US region from 2005 to 2016. Remote Sens. Environ. 2019, 221, 417–429. [Google Scholar] [CrossRef]
- Denize, J.; Hubert-Moy, L.; Betbeder, J.; Corgne, S.; Baudry, J.; Pottier, E. Evaluation of Using Sentinel-1 and -2 Time-Series to Identify Winter Land Use in Agricultural Landscapes. Remote Sens. 2019, 11, 37. [Google Scholar] [CrossRef] [Green Version]
- Finnish Meteorological Institute. Sentinel-1 SAR-Image Mosaic (S1sar). Available online: https://ckan.ymparisto.fi/dataset/sentinel-1-sar-image-mosaic-s1sar-sentinel-1-sar-kuvamosaiikki-s1sar (accessed on 8 February 2021).
- European Space Agency. Sentinel-1 SAR Interferometric Wide Swath. Available online: https://sentinels.copernicus.eu/web/sentinel/user-guides/sentinel-1-sar/acquisition-modes/interferometric-wide-swath (accessed on 8 February 2021).
- European Space Agency. Level-2A Algorithm Overview/NDVI. Available online: https://sentinels.copernicus.eu/web/sentinel/technical-guides/sentinel-2-msi/level-2a/algorithm (accessed on 26 March 2021).
- Van Deventer, A.; Ward, A.; Gowda, P.; Lyon, J. Using thematic mapper data to identify contrasting soil plains and tillage practices. Photogramm. Eng. Remote Sens. 1997, 63, 87–93. [Google Scholar]
- Zhang, H.; Kang, J.; Xu, X.; Zhang, L. Accessing the temporal and spectral features in crop type mapping using multi-temporal Sentinel-2 imagery: A case study of Yi’an County, Heilongjiang province, China. Comput. Electron. Agric. 2020, 176, 105618. [Google Scholar] [CrossRef]
- Parzen, E. On estimation of a probability density function and mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- O’Brien, T.A.; Kashinath, K.; Cavanaugh, N.R.; Collins, W.D.; O’Brien, J.P. A fast and objective multidimensional kernel density estimation method: FastKDE. Comput. Stat. Data Anal. 2016, 101, 148–160. [Google Scholar] [CrossRef] [Green Version]
- Leonard, T. Density estimation, stochastic processes and prior information. J. R. Stat. Soc. Ser. B (Methodol.) 1978, 40, 113–132. [Google Scholar] [CrossRef]
- Tokdar, S.T. Towards a faster implementation of density estimation with logistic Gaussian process priors. J. Comput. Graph. Stat. 2007, 16, 633–655. [Google Scholar] [CrossRef]
- Carpenter, B.; Gelman, A.; Hoffman, M.D.; Lee, D.; Goodrich, B.; Betancourt, M.; Brubaker, M.A.; Guo, J.; Li, P.; Riddell, A. Stan: A probabilistic programming language. J. Stat. Softw. 2017, 76, 1–32. [Google Scholar] [CrossRef] [Green Version]
- Van Tricht, K.; Gobin, A.; Gilliams, S.; Piccard, I. Synergistic Use of Radar Sentinel-1 and Optical Sentinel-2 Imagery for Crop Mapping: A Case Study for Belgium. Remote Sens. 2018, 10, 1642. [Google Scholar] [CrossRef] [Green Version]
- Vreugdenhil, M.; Wagner, W.; Bauer-Marschallinger, B.; Pfeil, I.; Teubner, I.; Rüdiger, C.; Strauss, P. Sensitivity of Sentinel-1 Backscatter to Vegetation Dynamics: An Austrian Case Study. Remote Sens. 2018, 10, 1396. [Google Scholar] [CrossRef] [Green Version]
- Vreugdenhil, M.; Navacchi, C.; Bauer-Marschallinger, B.; Hahn, S.; Steele-Dunne, S.; Pfeil, I.; Dorigo, W.; Wagner, W. Sentinel-1 Cross Ratio and Vegetation Optical Depth: A Comparison over Europe. Remote Sens. 2020, 12, 3404. [Google Scholar] [CrossRef]
- Ho Tong Minh, D.; Ienco, D.; Gaetano, R.; Lalande, N.; Ndikumana, E.; Osman, F.; Maurel, P. Deep Recurrent Neural Networks for Winter Vegetation Quality Mapping via Multitemporal SAR Sentinel-1. IEEE Geosci. Remote Sens. Lett. 2018, 15, 464–468. [Google Scholar] [CrossRef]
- Denize, J.; Hubert-Moy, L.; Pottier, E. Polarimetric SAR Time-Series for Identification of Winter Land Use. Sensors 2019, 19, 5574. [Google Scholar] [CrossRef] [Green Version]
- McNairn, H.; Champagne, C.; Shang, J.; Holmstrom, D.; Reichert, G. Integration of optical and Synthetic Aperture Radar (SAR) imagery for delivering operational annual crop inventories. ISPRS J. Photogramm. Remote Sens. 2009, 64, 434–449. [Google Scholar] [CrossRef]
- Inglada, J.; Vincent, A.; Arias, M.; Marais-Sicre, C. Improved Early Crop Type Identification By Joint Use of High Temporal Resolution SAR And Optical Image Time Series. Remote Sens. 2016, 8, 362. [Google Scholar] [CrossRef] [Green Version]
- Torbick, N.; Huang, X.; Ziniti, B.; Johnson, D.; Masek, J.; Reba, M. Fusion of Moderate Resolution Earth Observations for Operational Crop Type Mapping. Remote Sens. 2018, 10, 1058. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Azzari, G.; Lobell, D.B. Crop type mapping without field-level labels: Random forest transfer and unsupervised clustering techniques. Remote Sens. Environ. 2019, 222, 303–317. [Google Scholar] [CrossRef]
- John, G.H.; Langley, P. Estimating continuous distributions in Bayesian classifiers (orig. 1995). arXiv 2013, arXiv:1302.4964. [Google Scholar]
- Gramacki, A. Nonparametric Kernel Density Estimation and Its Computational Aspects; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Titsias, M.K. Variational Learning of Inducing Variables in Sparse Gaussian Processes. In Proceedings of the 12th International Conference on Artificial Intelligence and Statistics, Clearwater Beach, FL, USA, 16–18 April 2009; pp. 567–574. [Google Scholar]
- Escobar, M.D.; West, M. Bayesian density estimation and inference using mixtures. J. Am. Stat. Assoc. 1995, 90, 577–588. [Google Scholar] [CrossRef]
- Deng, X.; López-Martínez, C.; Chen, J.; Han, P. Statistical Modeling of Polarimetric SAR Data: A Survey and Challenges. Remote Sens. 2017, 9, 348. [Google Scholar] [CrossRef] [Green Version]
- Shuai, Y.; Sun, H.; Xu, G. SAR image segmentation based on level set with stationary global minimum. IEEE Geosci. Remote Sens. Lett. 2008, 5, 644–648. [Google Scholar] [CrossRef]
- Nielsen, A.A.; Skriver, H.; Conradsen, K. Complex Wishart Distribution Based Analysis of Polarimetric Synthetic Aperture Radar Data. In Proceedings of the IEEE 2007 International Workshop on the Analysis of Multi-temporal Remote Sensing Images, Leuven, Belgium, 18–20 July 2007; pp. 1–6. [Google Scholar]
- Sánchez, S.; Marpu, P.R.; Plaza, A.; Paz-Gallardo, A. Parallel implementation of polarimetric synthetic aperture radar data processing for unsupervised classification using the complex Wishart classifier. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 5376–5387. [Google Scholar] [CrossRef]
- Goumehei, E.; Tolpekin, V.; Stein, A.; Yan, W. Surface water body detection in polarimetric SAR data using contextual complex Wishart classification. Water Resour. Res. 2019, 55, 7047–7059. [Google Scholar] [CrossRef] [Green Version]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luotamo, M.; Yli-Heikkilä, M.; Klami, A. Density Estimates as Representations of Agricultural Fields for Remote Sensing-Based Monitoring of Tillage and Vegetation Cover. Appl. Sci. 2022, 12, 679. https://doi.org/10.3390/app12020679
Luotamo M, Yli-Heikkilä M, Klami A. Density Estimates as Representations of Agricultural Fields for Remote Sensing-Based Monitoring of Tillage and Vegetation Cover. Applied Sciences. 2022; 12(2):679. https://doi.org/10.3390/app12020679
Chicago/Turabian StyleLuotamo, Markku, Maria Yli-Heikkilä, and Arto Klami. 2022. "Density Estimates as Representations of Agricultural Fields for Remote Sensing-Based Monitoring of Tillage and Vegetation Cover" Applied Sciences 12, no. 2: 679. https://doi.org/10.3390/app12020679
APA StyleLuotamo, M., Yli-Heikkilä, M., & Klami, A. (2022). Density Estimates as Representations of Agricultural Fields for Remote Sensing-Based Monitoring of Tillage and Vegetation Cover. Applied Sciences, 12(2), 679. https://doi.org/10.3390/app12020679